






前言
本文用于多级表头Excel,并且表头字段顺序不确定的情况下的导入实现。在表头固定的情况下可使用poi逐行获取数据。
Excel示例
 该示例中存在一级表头”可研总投资“下存在多个二级表头,针对此种情况可采用分段多次读取Excel内容的方法获取全文数据。
该示例中存在一级表头”可研总投资“下存在多个二级表头,针对此种情况可采用分段多次读取Excel内容的方法获取全文数据。
实际使用
案例使用EasyExcel实现
1. 创建一级表头Excel实体类
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class FirstExcel {
@ExcelProperty("项目名称")
private String projectName;
@ExcelProperty("项目编码")
private String projectCode;
}
2. 创建二级表头Excel实体类,此处使用easyExcel中多级表头的注解实现方式
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class SecondExcel {
@ExcelProperty({"可研总投资","建筑"})
private String buildingCost;
@ExcelProperty({"可研总投资","安装"})
private String installingCost;
}
在@ExcelProperty注解中传入一个表头的Set集合,按顺序放入一级表头、二级表头…。
3. 编写测试导入接口代码
@PostMapping("/import-dempose")
public R importDempost(MultipartFile file){
List<SecondExcel> read = ExcelUtil.read(file, SecondExcel.class);
List<FirstExcel> read1 = ExcelUtil.read(file, FirstExcel.class);
int removePosition = read1.size() - read.size();
for(int i = removePosition; i >= 1; i -- ){
read1.remove(0);
}
Map<String,Object> map = new HashMap<>();
map.put("一级表头",read1);
map.put("二级表头",read);
return R.data(map);
}
在代码处理中分别通过两个表头实体类读取Excel数据,获取二级表头数据read和一级表头数据集合read1,
int removePosition = read1.size() - read.size();
for(int i = removePosition; i >= 1; i -- ){
read1.remove(0);
}
这一段代码主要用来处理两个表头数据集数量差的问题,以Excel示例来说,一级表头”项目名称“和”项目编码“其实是将第一行和第二行通过合并单元格形成,在读取时合并空的单元格也会被读取到,也就是说read1集合中第一个元素是全为null的,该行数据需要被剔除以保证多个表头数据集数据行一一对应。
以此延伸出来,如果存在三级表头的情况需要分别与一级表头和二级表头分别进行差异处理,保证数据行准确性。
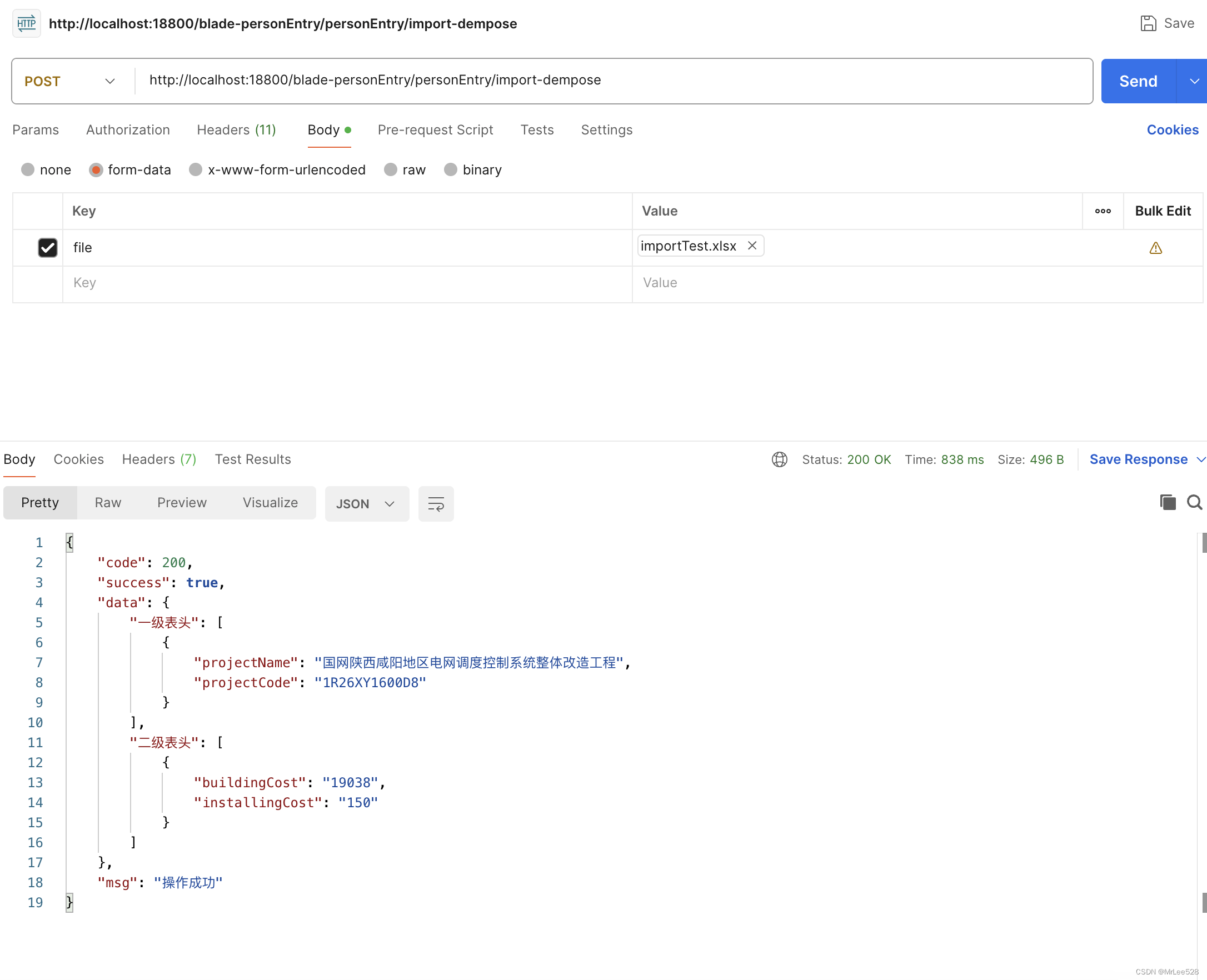
4. 调用接口查看结果
通过postman模拟调用接口,查看结果可以发现Excel示例中的数据已经被正确读取出来,后续只需要按业务需求重新装数据入库就可以了。
5. 三级表头示例(上个示例的基础上)
(1)Excel示例:

(2)三级表头实体类示例:
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class ThirdExcel {
@ExcelProperty({"表头1","表头2-1","表头3-1"})
private String data1;
@ExcelProperty({"表头1","表头2-1","表头3-2"})
private String data2;
@ExcelProperty({"表头1","表头2-2","表头3-3"})
private String data3;
@ExcelProperty({"表头1","表头2-2","表头3-4"})
private String data4;
}
(3)接口处理示例:
@PostMapping("/import-dempose")
public R importDempost(MultipartFile file){
List<SecondExcel> secondExcels = ExcelUtil.read(file, SecondExcel.class);
List<FirstExcel> firstExcels = ExcelUtil.read(file, FirstExcel.class);
List<ThirdExcel> thirdExcels = ExcelUtil.read(file, ThirdExcel.class);
int removePosition1 = secondExcels.size() - thirdExcels.size();
for(int i = removePosition1; i >= 1; i -- ){
secondExcels.remove(0);
}
int removePosition2 = firstExcels.size() - thirdExcels.size();
for(int i = removePosition2; i >= 1; i -- ){
firstExcels.remove(0);
}
Map<String,Object> map = new HashMap<>();
map.put("一级表头",firstExcels);
map.put("二级表头",secondExcels);
map.put("三级表头",thirdExcels);
return R.data(map);
}
此处简写,实际使用可将差异处理部分代码单独抽成方法使用。
(4)请求结果示例:
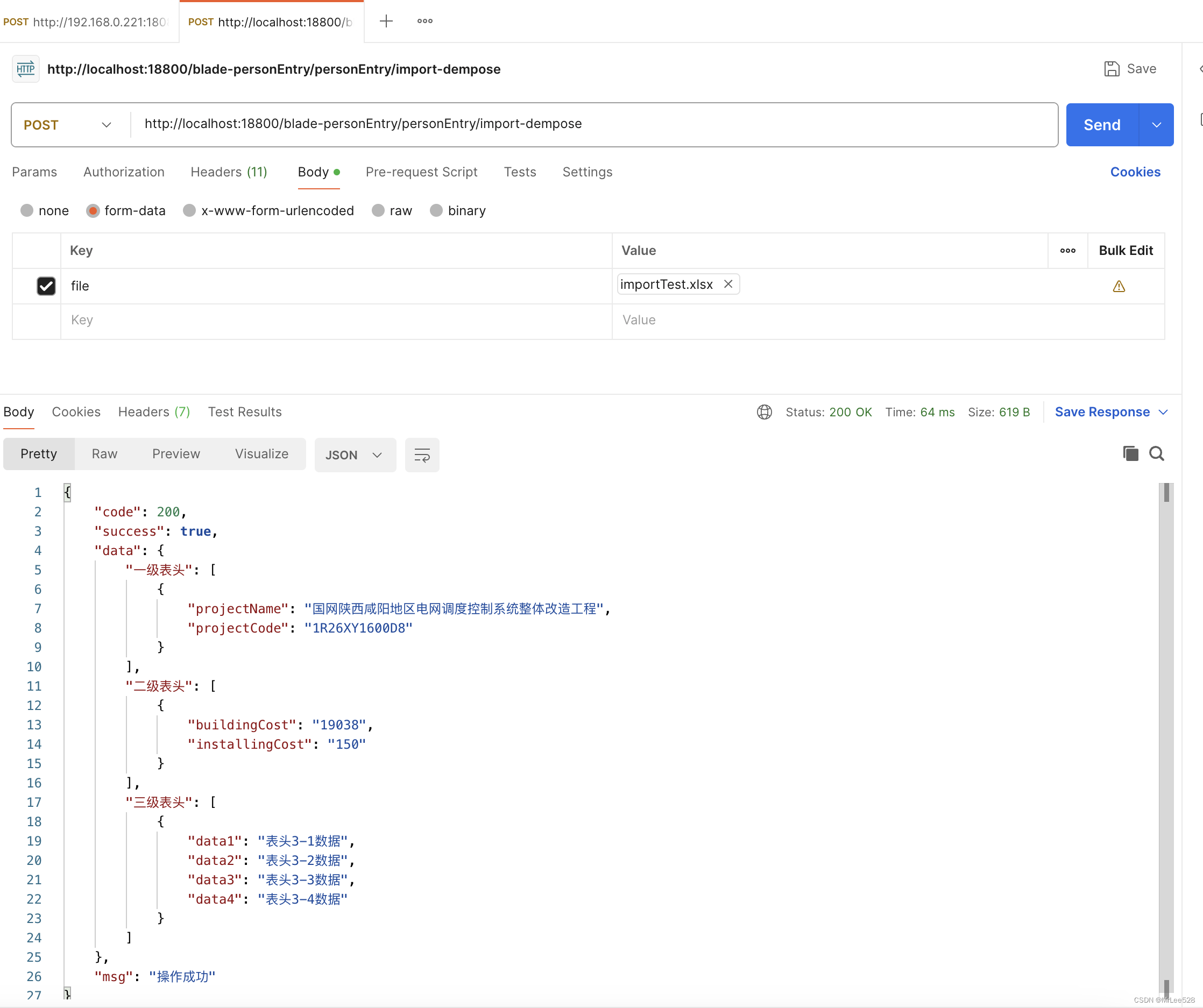
补充
针对简单的多级表头模板可采用上述方法进行最小代码量的实现,但上述方法也有局限性,例如以下这种模板使用上述方法导入就会出现值取不到的问题:

在这个模板中存在多级表头名称相同的情况,比如一级表头可研总投资和可研总投资1下均存在建筑和安装两个同名的二级表头。这种情况下按之前的方法建立实体类时只能取到最后一个可研总投资1(跟表头顺序有关)的两个二级内容。
针对此种情况我想应该是有统一的、针对此类复杂表头拿来就能用的解决方案。尝试了一下方法后,最终采用注解+反射+监听器的方式解决这种情况。
1、实现思路
整体还是基于EasyExcel去实现excel的读取工作。
实体类仍然使用@ExcelProperty注解,注解使用方法仍然跟之前相同。
通过java反射机制获取实体类注解中的表头属性。
通过EasyExcel监听器实现表头和列自动匹配读取数据。
2、具体实现
(1)创建实体类
这次直接创建所有列的实体类:
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class SecondExcel {
@ExcelProperty("项目名称")
private String projectName;
@ExcelProperty("项目编码")
private String projectCode;
@ExcelProperty({"表头1","表头2-1","表头3-1"})
private String data1;
@ExcelProperty({"表头1","表头2-1","表头3-2"})
private String data2;
@ExcelProperty({"表头1","表头2-2","表头3-3"})
private String data3;
@ExcelProperty({"表头1","表头2-2","表头3-4"})
private String data4;
@ExcelProperty({"可研总投资","建筑"})
private String buildingCost;
@ExcelProperty({"可研总投资","安装"})
private String installingCost;
@ExcelProperty({"可研总投资1","建筑"})
private String buildingCost1;
@ExcelProperty({"可研总投资1","安装"})
private String installingCost1;
}
(2)创建监听器
此处的监听器分为两种,一个是监听excel中合并单元格、一个是用来读取数据。原本一个监听器可以将两种工作都做了,但是由于合并单元格监听的触发在读取数据之后,而且合并单元格需要作为基础参数参与数据读取。所以只能建立两个监听器,第一个监听器获取合并单元格的情况,第二个监听器将前一个结果作为参数获取组装数据。
合并事件监听器如下:
class ExtraListener extends AnalysisEventListener<Map<Integer, String>> {
public List<CellExtra> cellExtraList;
public Integer maxHeadLevel;
public Integer headerRowNum;
public ExtraListener(List<CellExtra> cellExtraList, Integer maxHeadLevel,Integer headerRowNum) {
this.cellExtraList = cellExtraList;
this.maxHeadLevel = maxHeadLevel;
this.headerRowNum = headerRowNum;
}
@Override
public void invoke(Map<Integer, String> integerStringMap, AnalysisContext analysisContext) {
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
}
@Override
public void extra(CellExtra extra, AnalysisContext context) {
switch (extra.getType()) {
case MERGE:
if (extra.getRowIndex() - headerRowNum < maxHeadLevel) {
cellExtraList.add(extra);
}
break;
default:
}
}
}
ExtraListener中重写的extra方法是用来监听单元格合并的,接受CellExtra对象,该对象包含单元格合并的起止行和起止列信息。
监听器构造器需要传入三个参数,List cellExtraList用来接收单元格合并信息传递到监听器外部,maxHeadLevel为excel表头最大层级深度,headerRowNum为表头开始行,这两个参数用来控制excel读取的开始行数和单元格读取的范围。例如headerRowNum=2、maxHeadLevel=3表示从excel第3行开始读取往下3行的单元格合并。
数据读取监听器
public class DataListener extends AnalysisEventListener<Map<Integer, String>> {
//excel实体类
public Object classObject;
//返回结果
public List<Object> result;
//最大表头层级
public Integer maxHeadLevel;
//字段-表头对应关系
public Map<String, String[]> fieldHeadMap;
//字段-excel列索引对应关系
public Map<String, Integer> fieldIndexMap;
//历史行数据缓存
public List<Map<Integer, String>> lastRowMap;
//单元格合并列表
public List<CellExtra> cellExtraList;
//表头起止行
public Integer headerRowNum;
//构造方法
public DataListener(Object classObject, List<Object> list, Integer maxHeadLevel, List<CellExtra> cellExtraList, Integer headerRowNum) {
this.classObject = classObject;
this.result = list;
this.maxHeadLevel = maxHeadLevel;
this.headerRowNum = headerRowNum;
this.cellExtraList = cellExtraList;
//通过反射获取对象每个属性@ExcelProperty注解中的value值,形成对应关系
Map<String, String[]> map = new HashMap<>();
Field[] declaredFields = classObject.getClass().getDeclaredFields();
for (Field declaredField : declaredFields) {
ExcelProperty annotation = declaredField.getAnnotation(ExcelProperty.class);
if (Func.notNull(annotation)) {
String[] value = annotation.value();
map.put(declaredField.getName(), value);
}
}
this.fieldHeadMap = map;
this.fieldIndexMap = new HashMap<>();
this.lastRowMap = new ArrayList<>();
}
//赋值合并单元格内容属性
private String checkIsMerge(Integer rowIndex, Integer columnIndex, String text) {
for (CellExtra item : cellExtraList) {
if ((rowIndex >= item.getFirstRowIndex() && rowIndex <= item.getLastRowIndex())
&& (columnIndex >= item.getFirstColumnIndex() && columnIndex <= item.getLastColumnIndex())) {
if (Func.isNotBlank(text)) {
item.setText(text);
}
return item.getText();
}
}
return text;
}
//数据读取监听
@Override
public void invoke(Map<Integer, String> integerStringMap, AnalysisContext analysisContext) {
//获取当前相对行号,analysisContext.readRowHolder().getRowIndex()获取的是整体行号,跟headerRowNum取差值获取相对行号
Integer currentRowIndex = analysisContext.readRowHolder().getRowIndex() - headerRowNum;
if (currentRowIndex < maxHeadLevel) {
HashMap<Integer, String> newRowData = new HashMap<>();
//遍历当前行,通过和合并单元格对比替换内容
integerStringMap.forEach((key, item) -> {
newRowData.put(key, checkIsMerge(analysisContext.readRowHolder().getRowIndex(), key, item));
});
//遍历字段表头关系,设置字段-列索引关系
fieldHeadMap.forEach((key, item) -> {
if (item.length == currentRowIndex + 1) {
newRowData.forEach((index, header) -> {
if (item[currentRowIndex].equals(header)) {
if (currentRowIndex == 0) {
fieldIndexMap.put(key, index);
} else {
boolean flag = false;
for (int i = currentRowIndex; i > 0; i--) {
if (lastRowMap.get(i - 1).get(index).equals(item[i - 1])) {
flag = true;
} else {
flag = false;
break;
}
}
if (flag) {
fieldIndexMap.put(key, index);
}
}
}
});
}
});
lastRowMap.add(newRowData);
} else {
//处理正式数据
if (fieldIndexMap.size() > 0) {
Map<String, Object> map = new HashMap<>();
fieldIndexMap.forEach((key, index) -> {
map.put(key, integerStringMap.get(index));
});
result.add(map);
}
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
}
}
构造方法中classObject对象对应需要解析的excel对象,通过反射获取该对象字段和注解内容。
获取相对行号的目的是为了跟表头层级对应,字段-表头关系map中表头是以String[]形式存储,可直接用String[相对行号]取到对应行的表头。按示例excel中来说,headerRowNum应该是3,创建的是实体类中projectName字段通过反射获取的表头是[“项目名称”],此时读取excel是从第四行开始对应rowIndex为3,rowIndex-headerRowNum=0,相对行号为0,此时可以直接String[0]获取projectName这个字段对应行数的标题。
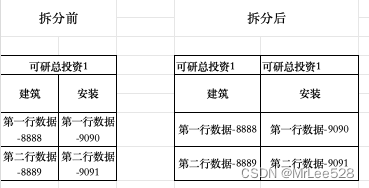
通过将数据行和合并单元格进行对比,重新赋值,可以理解为拆分单元格的过程,示例如下:
匹配最大层级的表头对应关系,如
@ExcelProperty({"可研总投资1","建筑"})
private String buildingCost1;
这个字段进过反射后会变成buildingCost1-[“可研总投资1”,“建筑”] 的key-value键值对,当相对行号=1时正好对应value的最大长度,此时通过获取value[1]="建筑"跟这一行每一个单元格对比,如果内容相同,则继续比对上一行相同位置的内容是否跟value[相对行号-1]相同,全部匹配成功则记录当前字段和对应的index。
(3)测试接口编写
@PostMapping("/import-dempose")
public R importDempost(MultipartFile file) throws IOException {
List<Object> result = new ArrayList<>();
List<CellExtra> cellExtraList = new ArrayList<>();
EasyExcel.read(file.getInputStream(), new ExtraListener(cellExtraList, 3,3)).extraRead(CellExtraTypeEnum.MERGE).headRowNumber(3).doReadAll();
EasyExcel.read(file.getInputStream(), new DataListener(new SecondExcel(), result, 3, cellExtraList,3)).headRowNumber(3).doReadAll();
eturn R.data(result);
}
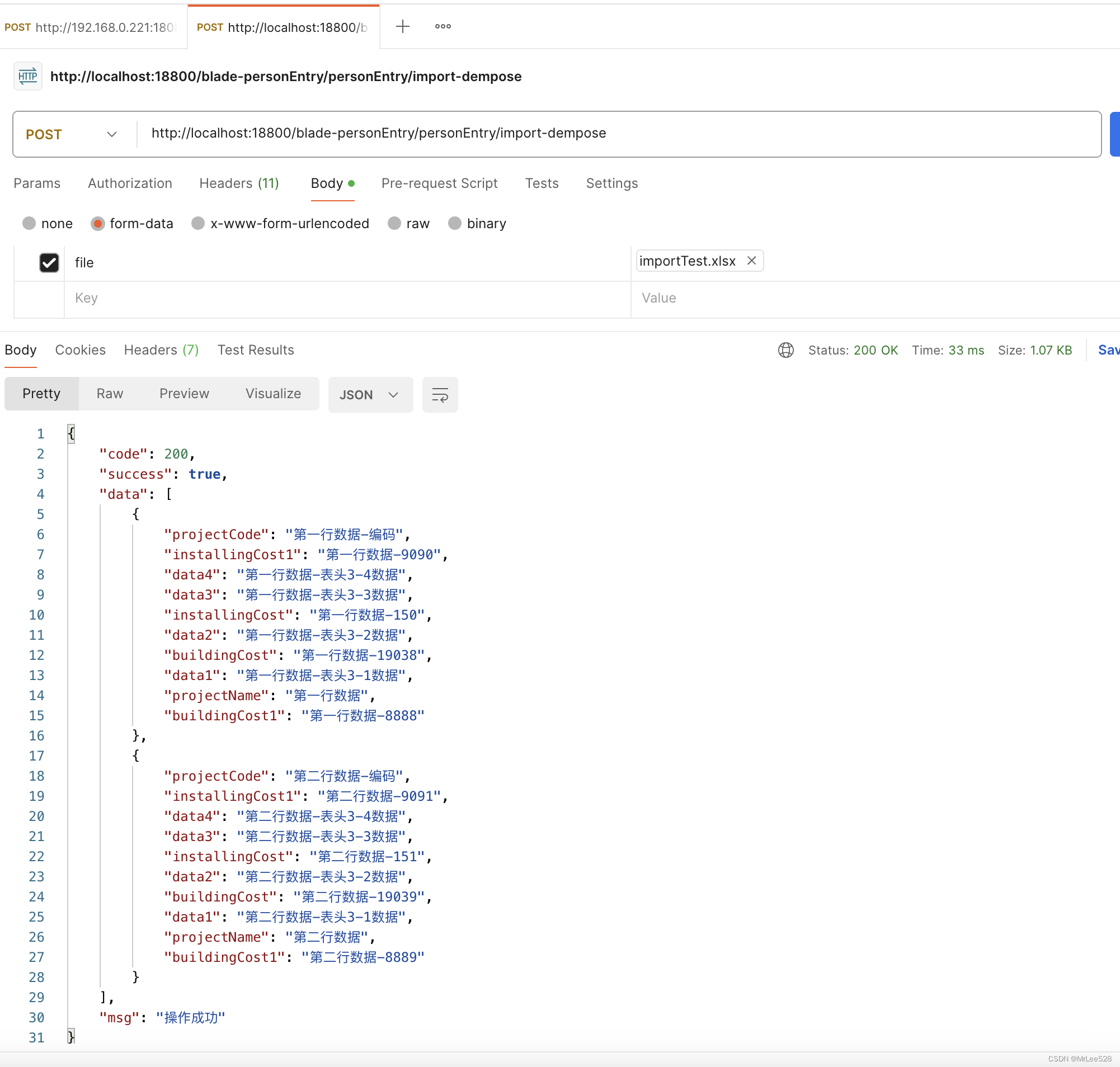
resutl结果严格来说是个List格式,可以通过map2bean的方式转换成对应数据库实体。
第一个EasyExcel.read是用来获取单元格合并事件,需要按照实际修改**new ExtraListener()**中的参数,参数介绍在上面。
第二个EasyExcel.read是用来获取结果集的,构造参数同上按实际修改。
两个read的.headRowNumber()都需要按实际修改。
(4)结果展示















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









