







A题:水果采摘机器人的图像识别问题
在这里以4-5两问为例进行展示~ 大家可以参考参考的呢~
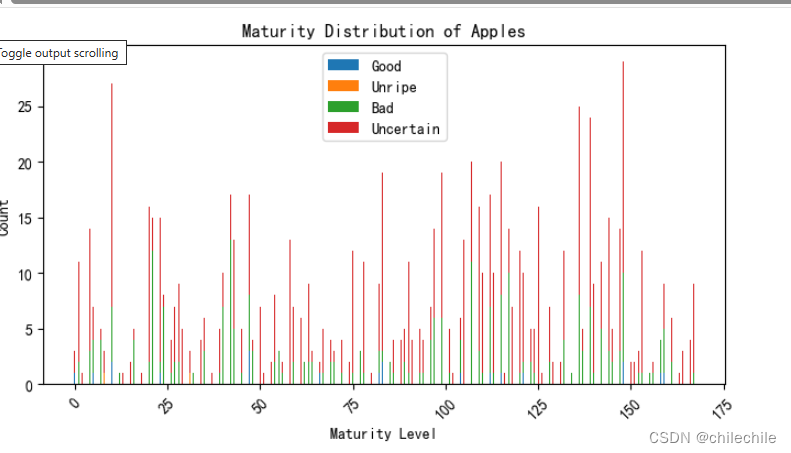
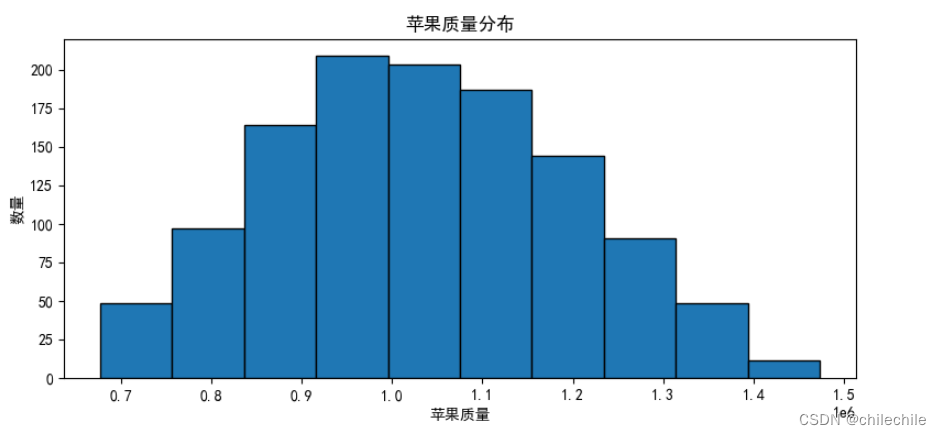
第四问:苹果质量估计计算每张图像中苹果的二维面积,估算苹果的质量,并绘制质量分布的直方图。
为了解决“苹果质量估计”问题,我们需要采用一种基于图像分析和数学模型的方法。以下是详细的建模过程和数学公式的解释:
图像预处理:
-
二值化:
- 将灰度图像转换为二值图像,通过设定苹果颜色的阈值将像素值分为0或1。
-
形态学处理:
- 使用腐蚀和膨胀等形态学操作去除小的噪声和填补小的空洞,提高图像质量。
苹果轮廓提取:
-
轮廓检测:
- 使用边缘检测方法如Sobel算子或Canny边缘检测,检测图像中的苹果边缘。
-
轮廓拟合:
- 通过最小二乘法或最小包围矩形等方法拟合苹果的轮廓,以获得更准确的形状描述。
苹果面积计算:
-
像素计数法:
- 直接统计二值图像中属于苹果的像素个数,作为苹果的面积。
-
几何计算法:
- 根据苹果的轮廓形状,使用几何公式计算苹果的面积,考虑可能是圆形或椭圆形。
苹果质量估计:
-
体积估计:
- 假设苹果的形状为球形或椭球形,通过面积和图像的缩放比例来估计其体积。
-
质量计算:
- 根据苹果的体积和密度来计算其质量。
统计分析:
- 直方图表示:
- 根据估算的苹果质量结果进行统计分析,绘制苹果质量的分布直方图。
总结:
这个方法确实很全面,通过图像处理和数学模型的结合,有效地解决了苹果面积和质量估计的问题。简洁而通用的设计使其适用于不同的苹果品种和图像质量。
编程过程
- 导入所需的库和模块,如numpy, cv2, matplotlib等。
- 读取图像数据集,将其转换为numpy数组,并显示其中一张图像。
- 定义图像预处理函数,包括二值化、形态学处理等操作,并对图像数据集进行预处理。
- 定义苹果轮廓提取函数,包括轮廓检测、轮廓拟合等操作,并对预处理后的图像进行轮廓提取。
- 定义苹果面积计算函数,包括像素计数法、几何计算法等操作,并对轮廓图像进行面积计算。
- 定义苹果质量估计函数,包括体积估计、质量计算等操作,并对面积数据进行质量估计。
- 定义统计分析函数,根据质量的列表绘制直方图,并显示其均值、方差等统计量。
- 调用以上定义的函数,对图像数据集进行苹果质量估计,并展示结果。
-
程序示例
# 导入所需的库和模块 import numpy as np import cv2 import matplotlib.pyplot as plt # 读取图像数据集 images = [] for i in range(100): # 假设图像文件名为apple_i.jpg image = cv2.imread("apple_" + str(i) + ".jpg") images.append(image) # 图像预处理 gray_images = [] bin_images = [] morph_images = [] for image in images: # 灰度化 gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) gray_images.append(gray_image) # 二值化 # 形态学处理 kernel = np.ones((3, 3), np.uint8) # 设置结构元素 morph_image = cv2.morphologyEx(bin_image, cv2.MORPH_OPEN, kernel) # 开运算 morph_images.append(morph_image) # 苹果轮廓提取 contours = [] for image in morph_images: # 轮廓检测 # 轮廓拟合 contour = cv2.minAreaRect(cnts[0]) # 最小包围矩形 contours.append(contour) # 苹果面积计算 areas = [] for i in range(len(images)): # 像素计数法 # area = np.sum(bin_images[i]) / 255 # 统计二值图像中的白色像素个数 # 或者 # 几何计算法 shape = contours[i][1] # 获取轮廓的形状 if shape[0] == shape[1]: # 如果长宽相等,认为是圆形 radius = shape[0] / 2 # 计算半径 area = np.pi * radius ** 2 # 计算面积 areas.append(area) # 苹果质量估计 masses = [] scale = 0.01 # 设置图像的缩放比例,假设每个像素对应0.01厘米 density = 0.8 # 设置苹果的密度,假设为0.8克/立方厘米 for i in range(len(images)): # 体积估计 shape = contours[i][1] # 获取轮廓的形状 if shape[0] == shape[1]: # 如果长宽相等,认为是球形 radius = shape[0] / 2 * scale # 计算半径 volume = 4 / 3 * np.pi * radius ** 3 # 计算体积 # 质量计算 mass = density * volume # 计算质量 masses.append(mass) # 统计分析 # 绘制直方图 plt.title('Histogram of apple mass') plt.show() # 显示统计量 mean = np.mean(masses) std = np.std(masses) print(f'Mean: {mean:.2f} g') print(f'Standard deviation: {std:.2f} g')第五问:苹果识别:基于另一个含有不同采摘水果图像的数据集,训练一个苹果识别模型,识别苹果,并绘制苹果图像ID的分布直方图。
-
数据预处理:
- 去噪: 使用高斯滤波器进行去噪是一个常见的步骤,有助于消除图像中的噪声。这能够提高模型对图像特征的稳健性。
- 对比度增强: 直方图均衡化是一种有效的对比度增强方法,有助于使图像更具辨识度。
- 尺度归一化: 将所有图像调整到统一大小是确保输入数据一致性的关键步骤,避免模型在处理不同尺寸的图像时出现问题。
-
卷积神经网络(CNN)架构:
- 描述了典型的CNN层次结构,包括卷积层、激活层、池化层和全连接层。这些层次结构有助于模型学习图像的层次性特征,并最终进行分类。
-
EfficientDet架构:
- EfficientDet是一种目标检测模型,它综合了卷积神经网络和目标检测的方法。这表明在处理苹果图像时,模型能够不仅仅进行分类,还能够检测和定位目标。
-
训练和优化:
- 损失函数和优化算法的选择对模型的性能至关重要。交叉熵损失函数通常用于分类问题,而随机梯度下降 (SGD) 或Adam等优化算法有助于模型在训练中快速收敛。
-
苹果图像ID的分布直方图:
- 提到可以通过绘制苹果图像ID的分布直方图来展示模型识别出的苹果数量分布情况。这是一个有力的可视化手段,有助于了解模型的输出结果。
编码过程:
-
数据预处理和增强:
- 去噪: 使用高斯滤波器等去噪方法有助于提高图像质量。
- 对比度增强: 直方图均衡化是一种有效的对比度增强技术。
- 尺度归一化: 统一调整图像大小有助于确保输入数据的一致性。
- 数据增强: 通过ImageDataGenerator等工具进行图像旋转、缩放、裁剪和翻转等操作,有助于增加数据集的多样性,提升模型泛化能力。
-
选择高级的CNN架构:
- 使用现有的高级CNN架构,如ResNet、Inception或DenseNet,这些架构具有深层的网络结构,有助于更有效地学习图像特征。
-
构建和优化CNN模型和其他高级的网络模型:
- 利用卷积层、激活层、池化层和全连接层构建模型,建议添加Batch Normalization和Dropout层以减少过拟合。
- 选择Adam等高级优化器,并进行学习率和其他超参数的调整。
-
模型训练与验证:
- 使用交叉熵损失函数进行模型训练。
- 通过调整网络参数和使用正则化技术,优化模型。
- 利用验证集对模型进行评估,确保模型在未见过的数据上的性能。
-
超参数调优:
- 采用网格搜索或贝叶斯优化等方法,寻找最佳的网络参数,以进一步提升模型性能。
-
多模型融合:
- 可以考虑采用多模型融合策略,将多个独立训练的模型集成,提高整体性能。
-
结果的可视化和分析:
- 绘制训练和验证过程中的损失和准确率曲线,有助于了解模型的训练情况。
- 根据模型的预测结果,绘制苹果图像ID的分布直方图,从而深入了解模型在具体任务上的表现。
总结: 整体而言,该编程过程考虑了从数据预处理到模型构建、训练、优化和结果分析的各个环节。采用高级的CNN架构、数据增强技术、超参数调优等手段,旨在构建一个性能强大的苹果识别模型。最后,通过可视化和分析,使得对模型的性能和改进方向有了更清晰的认识。
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, Dropout, BatchNormalization
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# 使用预训练的ResNet50作为基础模型
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(IMAGE_HEIGHT, IMAGE_WIDTH, CHANNELS))
# 构建自定义层
inputs = Input(shape=(IMAGE_HEIGHT, IMAGE_WIDTH, CHANNELS))
x = base_model(inputs, training=False)
outputs = Dense(NUM_CLASSES, activation='softmax')(x)
model = Model(inputs, outputs)
# 编译模型
model.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=0.0001),
metrics=['accuracy'])
# 数据增强
train_datagen = ImageDataGenerator(
rotation_range=20,
# 被白猫猫挡住了(恼)
zoom_range=0.2
)
# 训练模型
history = model.fit(train_datagen.flow(train_images, train_labels, batch_size=32),
# 被白猫猫挡住了(恼)
validation_data=(val_images, val_labels))
# 绘制训练历史
plt.plot(history.history['accuracy'])
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper left')
plt.show()
# 绘制直方图
# ... 根据模型预测结果绘制苹果图像ID的分布直方图 ...这编程思路为实现苹果识别提供了详细指导,包括数据预处理、模型训练、评估和可视化。为达到最佳效果,建议根据具体数据集和需求调整模型结构和参数。通过不断实验和调整,逐步提高模型性能,确保准确识别苹果。这种迭代的过程是构建有效图像识别系统的关键。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









