







网页链接:【软科排名】2023年最新软科中国大学排名|中国最好大学排名
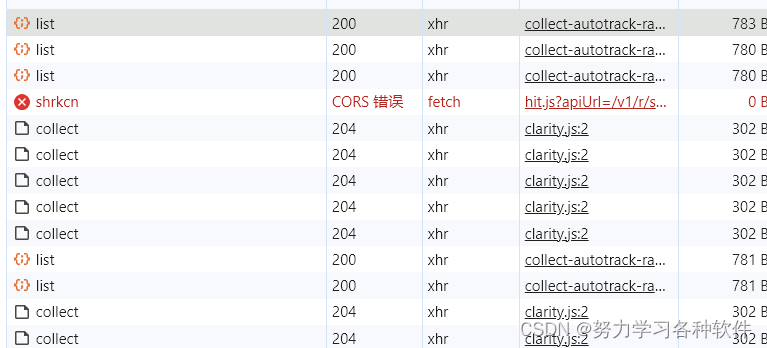
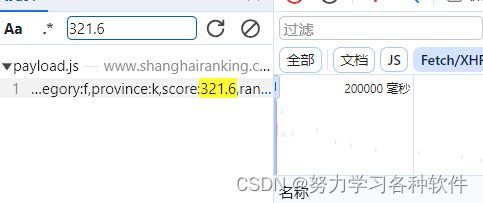
点击xhr后发现数据不存在,在搜索框(尽量搜索数字和字母)搜索,发现数据在js文件中,这是一个JSONP的格式,相对于json的格式
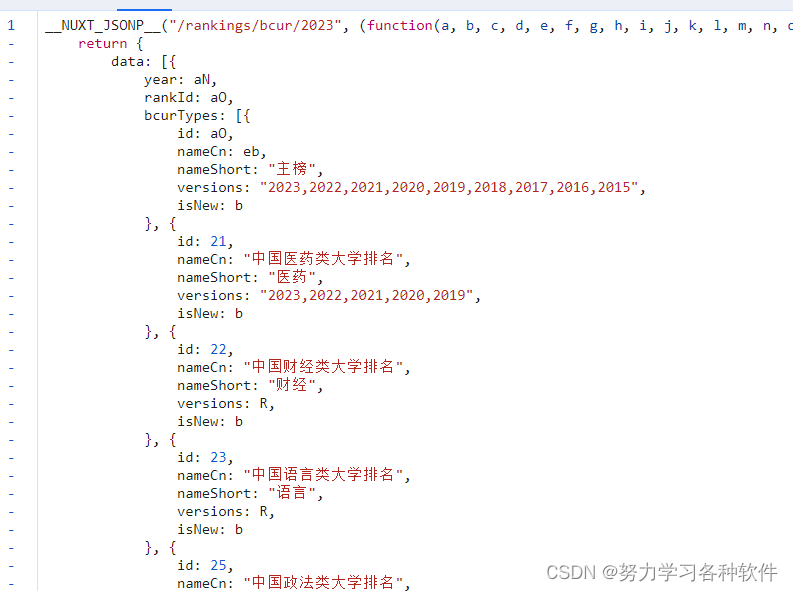
对js文件进行分析, 它定义了一个函数__NUXT_JSONP__,控制台中复制,发现其为一个函数,点击进入另一个js文件
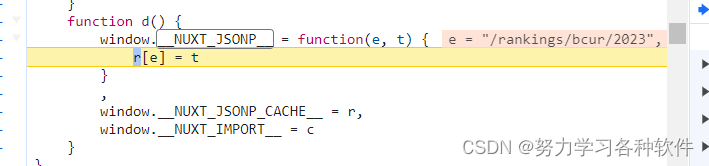
在re处打上断点,刷新网站,继续执行脚本得到
网页链接:【软科排名】2023年最新软科中国大学排名|中国最好大学排名
点击xhr后发现数据不存在,在搜索框(尽量搜索数字和字母)搜索,发现数据在js文件中,这是一个JSONP的格式,相对于json的格式
对js文件进行分析, 它定义了一个函数__NUXT_JSONP__,控制台中复制,发现其为一个函数,点击进入另一个js文件
在re处打上断点,刷新网站,继续执行脚本得到
 1万+
6207
1万+
6207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


























