







前言
Dubbo用起来就和EJB、WebService差不多,调用一个远程的服务(或者JavaBean)的时候在本地有一个接口,就像调用本地的方法一样去调用,它底层帮你实现好你的方法参数传输和远程服务运行结果传回之后的返回,就是RPC的一种封装
当然,这个只是Dubbo的最基本的功能,它的特点是:
- 它主要是使用高效的网络框架和序列化框架,让分布式服务之间调用效率更高。
- 采用注册中心管理众多的服务接口地址,当你想调用服务的时候只需要跟注册中心询问即可,不用像使用WebService一样每个服务都得记录好接口调用方式。
- 监控中心:实现对服务方和调用方之间运行状态的监控,还能控制服务的优先级、权限、权重、上下线等,让整个庞大的分布式服务系统的维护和治理比较方便。
- 高可用:有个服务宕机了?注册中心就会从服务列表去掉该节点。还是调用到了?客户端会向注册中心请求另一台可用的服务节点重新调用。注册中心宕机?注册中心也能实现高可用(ZooKeeper)。
- 负载均衡:采用软负载均衡算法实现对多个相同服务的节点的请求负载均衡。
相信不少去面试阿里的朋友都有被面试官问到了Dubbo的相关问题,小编在这里将阿里面试官问的最频繁的那些Dubbo面试题整理了出来,以供大家参考

一面:
先是问了问项目,然后就开始问一些问题
1、每个请求耗时100ms,机器的配置是4核8G,问要达到10000TPS需要多少台机器?
没答上来,问了问是IO密集型还是CPU密集型,然后面试官说我想得太复杂了
2、怎么实现网页的自动跳转
答301 302的Location字段,然后又问了我这两个有什么区别
3、有一个10G大小的文件,里面都是32位的无符号整数,但是内存大小只有1G,问如何找出里面重复的数字
一开始说用hash,先hash到小文件。面试官说有没有更简单的,答位图,又问你觉得位图会占用多大的内存空间。算了一会,答512M
然后就是算法题,一个Unix的路径,简化这个路径,Leetcode上有原题
一面大概36分钟
二面:
围绕项目问了很多问题,和我讨论了怎么保证双写的一致性、消息队列中消息积压了怎么办、为什么要用到分布式锁、ZK的分布式锁的使用流程、ZK的选主策略、同步策略然后又围绕Kafka问了一些问题。
1、Kafka怎么保证顺序消费?
2、Kafka的架构是什么样的?
3、Kafka可以保证一个主题所有的分区都顺序消费吗?
算法,给一个数n,求所有和等于这个数的连续子序列,比如15=1+2+3+4+5=4+5+6=8+7,所以输出3.
三面:
主要是围绕着基础的知识问了一些问题:
1、Java的GC
2、反射,反射是怎么实现的。
没看过是怎么实现的,现场猜想了一下,应该答错了
3、讲一下乐观锁和悲观锁
4、网络协议的分层,每一层是干嘛用的
5、DNS是哪一层的,域名解析的过程是什么样的?
6、进程间通信的方式,什么情况下需要进程间通信?
这个题答得也不太好,讲了管道、信号、共享内存区域
7、volatile关键字
8、Synchronized和Lock
这个地方我是想等他来问我底层的原理,所以说的时候没说完。不过说完他也没反馈,也许知道什么就应该全部说出来?
做一道算法题,序列化和反序列化二叉树
9、内核态和用户态介绍一下
最后面试官和我聊了聊平时是怎么学习的,最近学什么东西比较有心得,以后的职业规划是什么。
Docker步步实践
目录文档:


①Docker简介
②基本概念
③安装Docker

④使用镜像:

⑤操作容器:

⑥访问仓库:

⑦数据管理:

⑧使用网络:

⑨高级网络配置:

⑩安全:

⑪底层实现:

⑫其他项目:
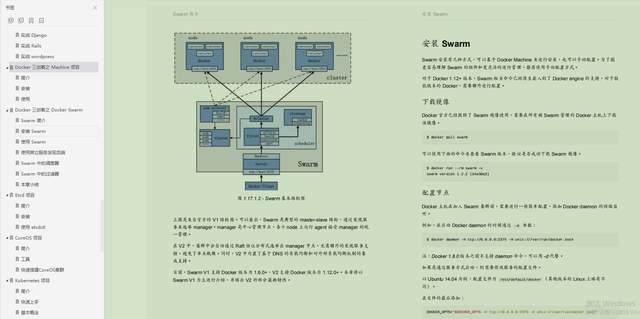
-1623845457778)]
⑪底层实现:
[外链图片转存中…(img-I3zqZ1Js-1623845457779)]
⑫其他项目:
[外链图片转存中…(img-ip7nteXw-1623845457780)]
有需要完整版源码+笔记的朋友点击这里免费获取















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









