






一、前言
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
二、Redis是什么
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
三、Redis能干嘛
1、内存存储、持久化,内存中是断电即失、所以说持久化很重要(rdb、aof)
2、效率高,可以用于高速缓存
3、发布订阅系统
4、地图信息分析
5、计时器、计数器(浏览量!)
四、Redis的五大数据类型
String
添加值
set key value
set key value EX 10 //EX是设置过期时间 单位是秒
set key value NX //NX键如果不存在就设置成功,存在的话就失败
获取值
get key
删除键
del key
适用于缓存,全局计数器
list
list采用的是双向链表的结构,是有序的,可重复的。
添加
lpush students zhangsan //从左边添加
rpush students zhangsan //从右边添加
取出
lpop students //左边取出
rpop students //右边取出
读取数据
lrange students stat end //stat和end是开始和结束位置(-1 代表全部)
set
set是无序的,不可重复的集合。
添加
sadd students zs
读取
smembers students
是否是其中元素
sismember students zs
取交集
sinter key1 key2 ...
取差集
sdiff key1 key2 ...
取并集
sunion key1 key2 ...
Hash
一个hash下有多个key-value

设置对象属性
student是对象名称,name和age是属性名称
hmset student name zhangsan age 20
读取对象属性
hmget student name
读取对象所有属性
hgetall student
删除对象属性
hdel student age
Zset
zset是有序的、不可重复的集合。
应用场景:
-
排行榜
添加数据,要添加一个score数字,按score排序
zadd key score value
读取数据
-
zrangebyscore ,start和end是score最小和最大值
-
zrevrangebyscore 反向读取zrangebyscore
zrangebyscore key start end
-
zrange ,start和end是开始和结束位置 zrevrange 反向读取zrange
zrange key start end
五、Redis中的事务
Redis提供的事务是将多个命令打包,然后一次性,按照FIFO的有序的执行。在执行过程中不会被打断。Redis事务不具有原子性,只有命令具有原子性。
事务的相关命令
-
multi 启动事务
-
exec 提交事务
-
discard 放弃事务
-
watch 监视一个或多个键,如果有其他客户端修改键的值,事务将失败
事务操作
案例1:开启事务,正常执行,提交事务

案例2:开启事务,放弃事务,事务中的操作没有执行
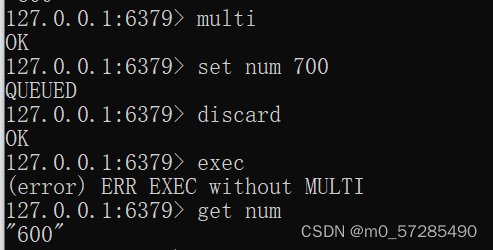
案例3:编译时异常,代码有问题,或者命令有问题,所有的命令都不会被执行

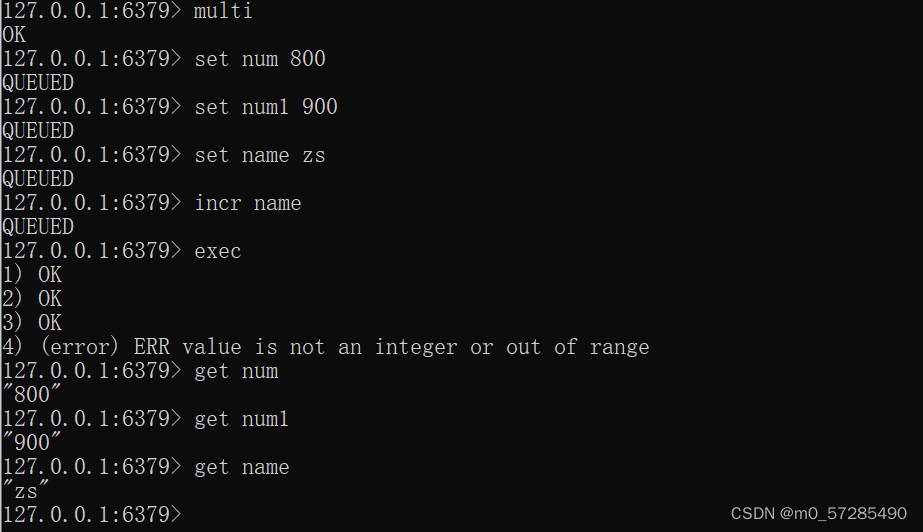
案例4:运行时异常,除了语法错误不会被执行且抛出异常后,其他的正确命令可以正常执行
六、Redis开发
编程式缓存
1.导入Redis依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.添加配置文件
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.database=0
spring.redis.jedis.pool.max-active=100
spring.redis.jedis.pool.max-wait=100ms
spring.redis.jedis.pool.max-idle=100
spring.redis.jedis.pool.min-idle=10
3.配置类
@Configuration
public class RedisConfig {@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
// 配置序列化器
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson序列化器
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
声明式缓存
1.在启动类上添加注解
//启动缓存
@EnableCaching
2.Redis的配置类
@Configuration
public class RedisConfig {@Bean
public RedisCacheConfiguration provideRedisCacheConfiguration(){
//加载默认配置
RedisCacheConfiguration conf = RedisCacheConfiguration.defaultCacheConfig();
//返回Jackson序列化器
return conf.serializeValuesWith(
RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer()));
}
}
3.缓存相关注解
@CacheConfig 使用在Service类上,可以配置缓存名称,如: @CacheConfig(cacheNames = "books")
@Cacheable 使用在查询方法上,让方法优先查询缓存
@CachePut 使用在更新和添加方法上,数据库更新和插入数据后同时保存到缓存里
@CacheEvict 使用在删除方法上,数据库删除后同时删除缓存
七、Redis的缓存击穿、穿透和雪崩
1.缓存雪崩
缓存雪崩指的是在某个时间点,缓存中的大量数据同时失效或过期或者Redis出现故障,导致大量请求直接访问后端系统,造成后端系统压力剧增,甚至崩溃。这通常是由于缓存中的数据设置了相同的过期时间,当缓存中的数据同时过期时,大量的请求无法从缓存中获取数据,而需要访问底层系统获取数据。

缓解缓存雪崩的方法有:
- 设置缓存的过期时间时分散开,避免在同一时间点同时失效。
- 为缓存数据添加随机的过期时间,使得缓存数据失效时间更加分散。
- 使用多级缓存架构,减少单一缓存单元失效对整个系统的影响。
2.缓存击穿
缓存击穿指的是在缓存中没有找到需要的数据,导致大量的请求直接访问后端系统获取数据,这些请求对后端系统造成了严重的压力。通常,缓存击穿发生在某个热点数据的缓存失效时,此时大量的请求需要从后端系统中获取数据,并导致对后端的频繁访问。
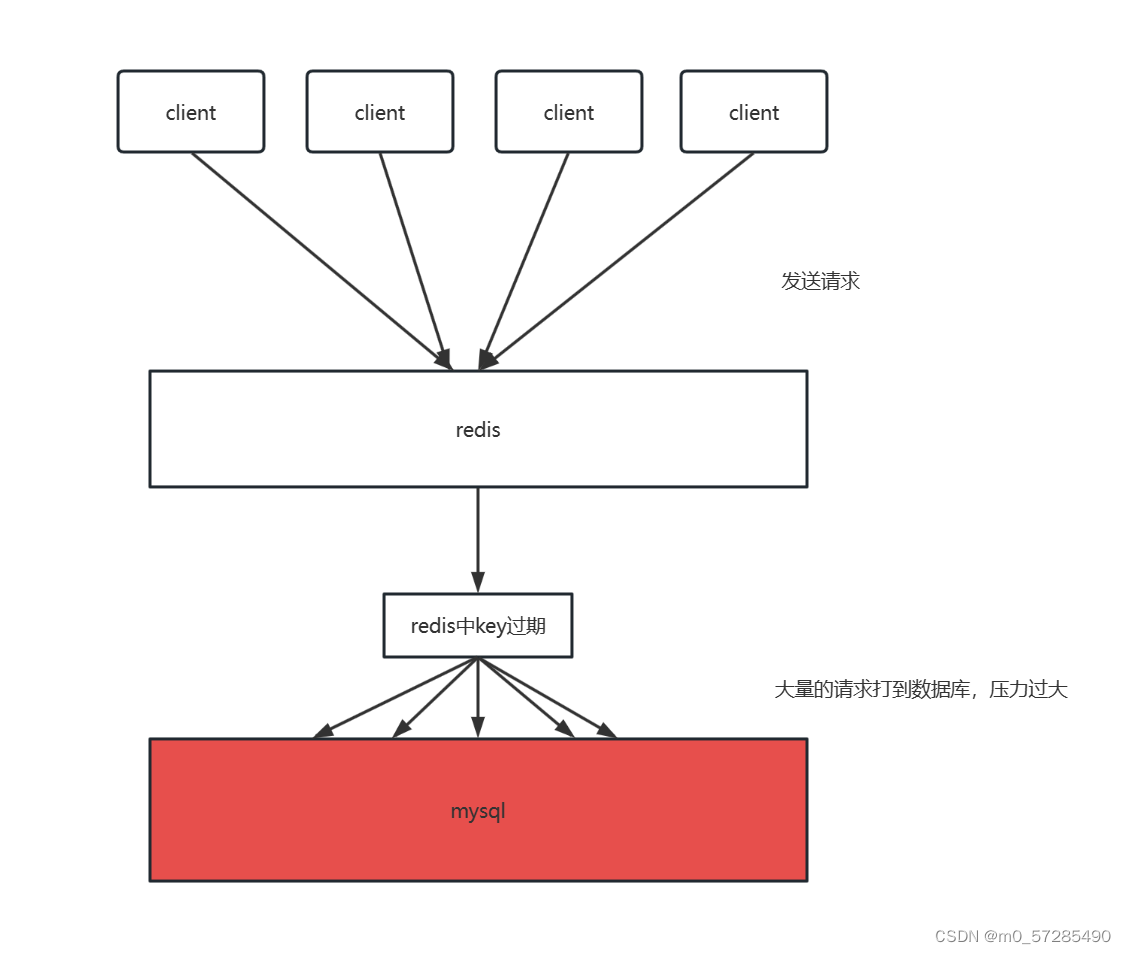
缓解缓存击穿的方法有:
- 使用互斥锁(如分布式锁)来保护缓存穿透的热点数据,当多个请求同时访问缓存未命中时,只有一个请求能够访问后端系统,其他请求等待并获取锁后再获取缓存数据。
- 针对缓存未命中的数据,可以设置一个较短的过期时间,避免同时多个请求访问后端系统。
3.缓存穿透
缓存穿透指的是恶意请求访问缓存中不存在的数据,这些请求绕过了缓存直接访问后端系统,导致后端系统承受了大量无效的请求。缓存穿透可能是因为恶意攻击、非法数据访问或者误操作等原因。

缓解缓存穿透的方法有:
- 对于缓存未命中的数据,可以将空值也缓存在缓存中,设置一个较短的过期时间,避免对未命中数据的重复访问。
- 对请求参数进行合法性校验,过滤掉恶意或非法的请求。
- 使用布隆过滤器(Bloom Filter)等技术进行缓存层的过滤,减少对不存在数据的后端访问。
布隆过滤器
布隆过滤器(Bloom Filter)是一种快速且高效的数据结构,用于判断一个元素是否属于一个集合。
布隆过滤器的核心思想是使用一系列独立的哈希函数和一个位数组来表示存在的元素。它通过将元素哈希到位数组的位置上,并将对应位置的位标记为1来表示此元素存在,若某个位置上的位为0,则可以确定该元素一定不存在。由于位数组的大小是固定的,因此布隆过滤器的空间开销相对较小。

1.引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.6</version>
</dependency>
2. 创建布隆过滤器
@Configuration
public class RedissonConfig {@Bean
public RBloomFilter<String> bloomFilter(){
Config config = new Config();
config.setTransportMode(TransportMode.NIO);
SingleServerConfig singleServerConfig = config.useSingleServer();
//可以用"rediss://"来启用SSL连接
singleServerConfig.setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
//创建布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("student-filter");
//初始化 参数1 向量长度 参数2 误识别率
bloomFilter.tryInit(10000000L,0.03);
return bloomFilter;
}
}
3. 将数据的id保存到过滤器中
@Autowired
private RBloomFilter<String> rBloomFilter;/**
* 初始化布隆过滤器
* @return
*/
@GetMapping("init-student-filter")
public ResponseResult<String> initStudentFilter(){
List<Student> list = studentService.list();
//将所有id保存到过滤器中
list.forEach(student -> {
rBloomFilter.add(String.valueOf(student.getStuId()));
});
return ResponseResult.ok("ok");
}
4.使用过滤器排除不存在的数据
@Autowired
private RBloomFilter<String> rBloomFilter;@Override
public Student getStudentById(Long id) {
//获得字符串操作对象
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
//先查询Redis
Student stu = (Student) ops.get(PREFIX + id);
if(stu == null) {
synchronized (this) {
System.out.println("进入了同步锁");
//先查询Redis
stu = (Student) ops.get(PREFIX + id);
//如果Redis缓存存在数据,就直接返回
if (stu != null) {
System.out.println("Redis查到,返回" + stu);
return stu;
}
//使用布隆过滤器判断数据库中是否存在该id
if(rBloomFilter.contains(String.valueOf(id))) {
//如果Redis没有查到数据,就查询MySQL
stu = studentMapper.selectById(id);
//MySQL查到数据,就保存到Redis
if (stu != null) {
System.out.println("MySQL查到,返回" + stu);
ops.set(PREFIX + id, stu);
return stu;
}
}else{
System.out.println("布隆过滤器判断id数据库不存在,直接返回");
}
}
}else {
System.out.println("没有执行同步锁");
}
return stu;
}















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









