









前言
这个真的是拖了很久,主要当初急着学完计算机网络,从而刷完基础题后马不停蹄的总结计网去了,结果一总结就是半个月。之后总结一直就懒得搞,万事开头难!最终三天搞完这个总结,打算最近看一下labuladong!拿下算法!其实本来打算一周总结完的,但是真的,做题时写的笔记都很详细,也大大加快了总结的节奏和效率,希望以后做题,及时总结记录笔记的好习惯也能一直保持住!
内容
一、数组总结
1、vector数组
1、二维数组不用创建一个临时变量tem来存数再往里放,可以直接往二维数组塞数,仅需要大括号{}
ans.push_back({1,2,3})
2、vector可以利用成员函数erase()可以删除由一个iterator指出的元素
3、【vector动态扩展尺寸】一开始resize是会造成空间冗余的,可以在每次循环的时候加个resize(i+1),这样每次要新增的时候再申请空间就可以了
4、vector可以直接赋值复制。如:pre = cur
5、vector的尾数查看为.rbegin();尾删除为.pop_back();
2、构造哈希表—数组里面存LIST
【1、首先审查一下专业术语】
哈希函数:能够将集合中任意可能的元素映射到一个固定范围的整数值,并将该元素存储到整数值对应的地址上。
冲突处理:由于不同元素可能映射到相同的整数值,因此需要在整数值出现「冲突」时,需要进行冲突处理。总的来说,有以下几种策略解决冲突:
a、链地址法:为每个哈希值维护一个链表,并将具有相同哈希值的元素都放入这一链表当中。(本题打算采用的方法)
b、开放地址法:当发现哈希值 hh 处产生冲突时,根据某种策略,从 hh 出发找到下一个不冲突的位置。例如,一种最简单的策略是,不断地检查 h+1,h+2,h+3,… 这些整数对应的位置。
c、再哈希法:当发现哈希冲突后,使用另一个哈希函数产生一个新的地址。
d、扩容:当哈希表元素过多时,冲突的概率将越来越大,而在哈希表中查询一个元素的效率也会越来越低。因此,需要开辟一块更大的空间,来缓解哈希表中发生的冲突。
由于我们使用整数除法作为哈希函数,为了尽可能避免冲突,应当将base 取为一个质数。在这里,我们取 base=769。
【2、构造方法】
1、我用的是二维数组,其实最好的答案是用数组里面套list。根据哈希函数来找到其相应存储在数组中的链表。然后列表里面查找、替换啥的。一方面利用数组的查找快,另一方面又利用了链表中的插入删除快,只能说歪瑞古德!
2、哈希集合就是纯纯list,哈希映射就是list里面放pair<int,int>!
注意list里面pair的访问方法----->
(*it).first = key;
(*it).second;
二、字符串总结
1、int与char的转换
1、首先是char到int的转换。int(num1[i]-'0') 这样才算换到int型,才可以参加运算。
2、其次是int到char的转换。sum + ‘0’!!(别写成char sum = sum+‘0’)sum一会char一会int就爆炸。
2、字符串相加
【前言】
此类字符串/链表的加法运算,建立个概念—在双指针移动的时候前就先循环补0,否则不好统一。
【题解】首先string的对于char字符插入有两种(若是string插入string,直接+=尾插即可),尾插就push_back没什么好说的
但是头插或者其他位置插入数字都可以用insert。具体用法:insert( pos, element)
【此类题很简单】仅需要注意
首先是翻转函数。这种string翻转比insert插入快多了:
reverse(ans.begin(), ans.end());
其次是 不需要判断其是否大于10再选择是否求余。
求进位直接就 i/10
求个位直接就 i%10
3、字符串相乘-----大数运算
此类字符串运算,建立个概念—在双指针移动的时候前就先循环补0,否则不好统一。而本题不用补0嘿嘿
【大数运算】其实这个也是间接考到了大数运算–123456789*987654321.就算你用longlong都放不下。因此就需要考虑到该按位乘的办法了。本题我也是这样的。此时可以存字符串,比存数组简单!!然后字符串相加最后再reverse即可。----这样也不用10的几次方了,根据放入字符串的顺序大家就心之肚明了
【技巧】在c++中^代表着异或,如果真的需要用此方,应用math.h库中的pow(10,2)代表10的2次方
4、快速抽出以空格为间隔的字符串–学会抽子字符串
a、while (j < m && str[j] != ' ') j++;
b、const string &tmp = str.substr(i, j - i);//这样创建的临时字符串还大大节省了空间,简直完美。
【格式】s.substr( int a, int b);
1、s 需要截取的字符串
2、a 截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取)
3、b 要截取的字符串的长度
5、循环中删除字符串的当前字符
s.erase(i,1)//删掉当前字符。这个方法虽然删除了,但也会影响for循环中string序列与字符对应的序号!!!
//因此如果是for循环里面删除,应加个
--i;
6、在字符串加入字符串
如果s要加字符串可以直接用+=运算符!或者+。这样直接不用字符的push_back!非常的方便。
7、字符串和数字的转换
【1】就是利用stream进行字符串和数字的转换
stringstream stream; //声明一个stringstream变量(包含sstream库)
int转string的方法:
stream << 1234; //向stream中插入整型数1234
stream >> str; //从steam中提取刚插入的整型数
string转int的方法:
stream << "1234"; //向stream中插入字符串"1234"
stream >> n; //从stream中提取刚插入的字符串"1234"
但注意,每次使用完不要忘记进行stream.clear()
【2】数字转string用to_string函数;而string转数字可以用stoi函数。
三、链表总结
1、对于入门阶段的题目就出现过的“环形链表”
本题其实用快慢指针也能做:
【快慢指针解题】这个题可以记住,也可以数学推导(见题解)
1、快指针走过的距离( a+n(b+c)+b=a+(n+1)b+nc)
2、慢指针肯定在第一圈环没走完就被快指针碰到(因为快指针每次领先慢指针一个,当慢指针刚进入环时,慢指针需要走 L 步才能走完一圈,此时快指针距离慢指针的最大距离为 L-1,因此一定第一圈被追上),因此慢指针走过的距离(a+b)
3、因此快指针走过的距离=2倍慢指针走过的距离便可得⟹a=c+(n−1)(b+c))
因此慢指针跑完c那么正好n=1,也就是a的距离。而a、c交点便为入环点。因此当快慢相遇的时候,再定义一个慢指针从a跑,这样两个慢指针相遇就是ac的入环点。

3、【可记住的技巧】
当快慢指针相遇时,此刻定义一个从头指针出发的指针pre,当慢指针与pre相遇时,那便是入环点。
当然快慢指针如果没相遇,快指针就nullptr了那么就不是环路返回null。
2、相交链表
就像环路快慢指针一样。这个找相交链表的也有技巧,就是一块跑,有一个跑到头就指向另一边的头指针再继续跑。
【原理分析】设相交后路程为c,相交前第一个链表要经过a,相交前第二个链表要经过b。
a、若同时跑,第一次跑到头 一个走a+c,一个走b+c。那么如果a+b就会直接相遇,如a!=b,那么去另一边的头再跑也可以一起达到a+b+c,也就是说会注定再相遇。
b、若不相交,设第一个链表全程a,第二个全长b。则掉头跑后
a+b,也一定会同时到达null。此时也返回a就可以了。
【总结】
就是直接while(a!=b)循环就行。但是记得前提条件,即a和b不能为空,这个不加前提条件,会报错其实也无所谓嘻嘻。
3、删除链表的重复元素
我一开始做,用了哈希表,其实不该用哈希表,那样很简单单调。而比较这种排好序的,就是直接用一次遍历就行。
【一次排序的重点】直接就是比较cur.next 与 cur.next.next 对应的元素(没必要双指针!!)再结合x去掉完全重复
1、如果相等,那么用个x记录一下,然后如果值为x,那么cur.next就一直往下指(这有易错点,如果cur->next为空会报错)
2、如果不相等,那表明没毛病,直接cur往下跑就可以。
【写代码的时候,花费了差不多一小时】
主要循环结构要搞清楚:
外面嵌套大循环是->next和->next->next。里面if判断,一但发现下一个和下下个相等,立马就是记录值while直到下一个跳出值,然后x相等即可。
【总结】
1、链表的指针逻辑真的很繁琐,能用哈希表快速秒杀还是用哈希表吧。哈希表记忆一边之后,然后用next判断,如果出现大于2直接next=next->next。也不需要双指针存在!
2、解决头节点不固定的问题!指头节点在设立的时候一般使下一个为head。而此时可以直接使pre为指头节点,这样pre的next在判断修改的时候,指头节点也是会跟着变的。
4、两两交换链表的节点
【总结】
1、中断条件:换剩下一个或者剩下多个:因此直接->next && ->next->next即可。
2、其实很简单的模拟三个点就可以了。**链表题学会设变量才不会绕进去,**设了变量,改变量只有next会被改变,会十分方便!!
架设 1->2->3 需要变成 1-> 3->2
直接就是 3.next = 1.next;1.next = 2.next; 1 = 2在循环即可,就这么简单,但是多个next就会晕。
【易混点】
1、可以让head当下次迭代1自然就变成了上面的2了,就不用管了。
2、自己老想不通如何让2指向5,其实这是个陷阱。不需要让2故意指向5,2和3 交换完了,把2当头节点,4和5交换完自然而然就指向5了。
5、重排链表—寻找链表中点 + 链表逆序 + 合并链表
【链表思路大学习】寻找链表中点 + 链表逆序 + 合并链表
比较是找到中点,把后面的翻转,然后合并起来!
直接来个大总结!
【寻找链表的中点】–跟检测环形链表一样,就是利用快慢指
快指针一次跑两步,慢指针一次跑一步,当快指针到终点的时候(快慢节点都从哨兵节点出发),奇数个节点慢指针指向的就是中点,偶数个节点慢指针指向中心左边的节点。
【链表逆序】核心思想是利用双指针
双指针就ok,一个cur从head开始,每次将next指向pre。而pre就是从nullptr开始,然后每次都等于cur。但注意迭代的时候cur是要迭代到原本的next,因此找个指针暂存一下。
【合并指针】两个暂存指针,而且还是相同长度(仅差1),换着指就完了。
【分成两个链】其实,很简单,就是定义好两个头节点!
6、K个一组翻转链表
【自己的ide】
1、加个计数整型变量n以及一个记录每个子链头节点的数组ans
第一次直接一个head的循环,完成上述初始化
2、利用n/k,求出要翻转的子链个数。
3、for循环–其实就是子链的翻转
3.1 先确定cur的值,之前整条翻转的初始值是nullptr,而这次挨个翻转,就是要取下一个子链的尾巴节点or如果下一组构不成子链个数了,就直接取子链尾巴节点的next(为空或者不翻转,到这个条件,就是最后一个子链,它来找cur了(也就是最后一条子链中翻转前的最后一个的指向))
3.2 正常翻转流程了,不多bb!
【官方优化】
优化了我思想里面的空间复杂度,通过一个指针就完成了!
1、专门定义一个翻转函数,以此来翻转子链表。(输入是待翻转的头和尾;返回新头和新尾)
PS:正常翻转head是动得,而要封装到一个函数中,并要求新尾返回回来,因此需要定义一个新纪录来记住翻转head,因为他就是新尾。
(此里面就有妙招了,因为传入头和尾就ok,那么其实cur就是传入的尾+1,根本不需要再记忆了)
2、 由于传入的函数就要求个头和尾,所以在完整while(head)的循环中,只来个for-k循环找尾巴就行,一旦发现空了,就直接返回哨兵节点即可。
2。1、注意翻转完有一部是要求接回来的:
接回来时,注意新头不用动,头变成旧尾的next即可
但新的next注意要换成旧尾指向的。
以上为接起来的逻辑实现,但是我的感觉告诉我不用那么麻烦。
PS:可能需要担心第一个头如何与哨兵节点结合,其实直接用pre=哨兵节点,然后不断更新pre的next就可以了(注意逻辑,pre->next肯定等于新头,而pre更新要为新尾,因为它下一步要指向新头。这样才不会乱,否则会乱)仅仅为了哨兵节点,也算是多多少少有些浪费吧
四、二叉树总结
1、数组构造二叉树—从前序与中序遍历序列构造二叉树
【数组构造二叉树的基础】二叉树的构造问题一般都是使用「分解问题」的思路:构造整棵树 = 根节点 + 构造左子树 + 构造右子树。根据索引递归调用左右数组构造左右子树即可其实就是递归,然后不断找根节点(记住这句话,是找根节点)。因此该题应该有四个变量:用来限定范围,找到左右数组。
【递归法思路】前序遍历:[ 根节点, [左子树的前序遍历结果], [右子树的前序遍历结果] ]
中序遍历:[ [左子树的中序遍历结果], 根节点, [右子树的中序遍历结果] ]
因此可以根据前序遍历的第一个确定根节点,然后再根据中序遍历确定左子树和右子树,这样不断递归下去。因此四个变量,来分别圈定前序遍历和中序遍历的范围。
【实现过程】
1、在主函数直接一个for循环记录下中序遍历中各元素的对应下标放入哈希表中,这样以便快速查找。
2、先确定空指针的返回条件
3、赋好根节点(其实就是前序遍历的第一个)
4、查找到根节点在中序遍历的位置,以方便计算出前序遍历的长度
5、从中序节点出发根据其位置减去开头,得到左子树的长度(仅由这个长度就可以找到完整的边界表示,其实左右计算一个就行,哪个方便计算哪个)
6、由此可以得到下一次左子树或者右子树所需要的四个变量(前两个变量是左/右子树对应在前序列表中的范围,后两个变量是左/右子树对应在中序列表的范围),带进去递归即可。
【技巧】
注意if(pre_left>pre_right)rerurn nullptr; 可以当作大多数缩区域迭代的空指针返回条件(构造二叉树常用)。
【迭代法思想】其实就是拿前序来找左右节点,而中序就是验证的。因为中序的第一个左子树是最底部,因此可以拿它来找边界!因此我们用堆栈存左子树,通过临时指针从中序遍历中找左子树的范围。
【实现过程】
1、我们用一个栈和一个指针辅助进行二叉树的构造。初始时栈中存放了根节点(前序遍历的第一个节点),指针指向中序遍历的第一个节点;
2、我们依次枚举前序遍历中除了第一个节点以外的每个节点。
2.1、如果 index 和栈顶节点不同,我们将当前节点作为栈顶节点的左儿子;
2.2、如果 index 恰好指向栈顶节点,那么我们不断地弹出栈顶节点并向右移动 index(直到index 和栈顶节点不同),并将当前节点作为最后一个弹出的节点的右儿子;
3、无论是哪一种情况,我们最后都将当前的节点入栈。而最后得到的二叉树即为答案。
【拓展】可以通过前序或者后序遍历结果找到根节点,然后根据中序遍历结果确定左右子树。而对于已知前序和后序,该如何去构造呢?其实和上面的思路一样,仍然是四个变量,然后通过区域来找根节点,只不过,上面的左右子树范围是确定的,而我们这次构造的范围是不确定的(毕竟没中序),因此我们可以假设前序序列第二个一定是根节点的左孩子,并通过映射到后序遍历的数组中,从而找到左右子树的范围。这里借用labuladong的一张图为例。

TreeNode* build(vector<int>& preorder, vector<int>& postorder,int preleft,int preright, int postleft, int postright)
{
if(preleft > preright) return nullptr;
TreeNode* root = new TreeNode(preorder[preleft]);
if(preleft == preright) return root;//多这么一句,因为不一定总有左节点呀
int left_node_val = preorder[preleft+1];
int left_index_post = record[left_node_val];
int leftnum = left_index_post - postleft +1;
root->left = build(preorder,postorder,preleft+1,preleft+leftnum,postleft,postleft+leftnum-1);
root->right = build(preorder,postorder,preleft+leftnum+1,preright,postleft+leftnum,postright-1);
return root;
}
};
2、层序二叉树放二维数组的快速分拣方法
【二维数组层序技巧】主要是分割符的使用:
1、其实很简单,就是最开始头节点+分隔符插入进队列。
2.1、每次从队头取出的不是分隔符的时候,就插入左右子节点
2.2、如果取出的是分割符,那么判断是否队列为空,不为空就再插入分割符(因为当取出分隔符的时候,其实这一层已经结束了)。
3、当取出分隔符的时候,因为一层已经结束,那么可以将tem暂存的数据放入二维数组里面了
3、二叉树的右视图
其实就是每层从右边看到的第一个。
【尝试】那么直接就尽量往右走,右走不动再尝试往左走,一直走到头就ok了。(该思路也不行,如果出现左子树有更多层就gg)
【自己的思路】直接层序输出分隔符前面的一个。这样层序的时候保证序列是从左有右往队列里存就ok了。为了能够输出分割符前面的一个,我使用了堆栈!
【技巧】注意stack清空只能pop
4、找出所有“从根节点到叶子节点”路径总和等于给定目标和的路径。
【DFS思路】dfs不仅仅只有用堆栈模拟出来的中序遍历,前序后序也均为dfs!
这个一看就是回溯法,而且我忙了很久,原因是一直想用中序遍历去解题,反而耽误了大把时间,就直接前序递归秒杀即可。
1、首先创个空函数,用于递归操作
2、首先确定递归结束的条件:直接就碰到空指针就可以,由于空函数,直接return。
3、碰到个指针,先给他sum-val,然后放入tem,接着判断是否为叶子节点
4.1、如果是叶子节点,则判断其sum是否已经减成0了,如果是,那么tem放回ans
4.2如果不是,不用操作即可,因为你在左右遍历完返回的时候也会pop的。
5、判断左右节点是否为空,进入迭代即可
6、pop一下,因为这个通常是都走完了,开始堆栈返回了!
【哈希表BFS思路】—应学会!
1、设两个队列,分别记录每个节点的地址和到达它时的值。
2、在层序时,用哈希表记录好,到达每个点的之前是哪个点,键为子,值为父。
(这样专门设个函数,就可以哈希表一直往回倒,倒的过程,把点扔进vector就可以了。)
3、当判断为叶子节点的时候,就可以看看他的值怎么样,不行就不理了,如果正好ok,那么用上面的函数(通过哈希映射)来找到到达该节点的path。
5、二叉搜索树第k小的元素
【官方题解】
1、因为左子树一定是小的,因此可以分三种情况(设node为根节点)
2.1、左子树的节点数小于k-1.那么该第k个最小值一定在右子树。另node等于k-node-1
2.2 左子树的节点数等于k-1,那么node就是该第k个最小值。
2.3如果左子树节点数大于k-1,那么一定在左子树,令node为左子节点,然后继续搜索就行。
3、实现过程可以用哈希表+递归的方法提前记录一下根节点的左右子树总节点数。这样根节点的左右子树也可以得到。
【官方题解2】
AVL平衡二叉搜索树也ok,方便更改,但是知道了解即可,几百行不可能手撸的!
6、删除二叉搜索树中的节点
首先正常思路,既然要删除就要去找到要删除的点以及它的父类,这样才能对应的修改删除后的父节点以及子节点的问题,但是如果统一一下思想,整个题就变得规整起来
【思路】
1、根据root值和key的大小,就可以直接进行递归,从而直接不需要找到父节点,进入递归处理要删除的节点即可(靠着返回新节点来覆盖原来的旧节点)。若root的val小于key进入右子树递归,否则进入左子树递归
2、若root的val等于key,那么就可以进行处理了。分为三类情况
2.1若root的左子树不在,那么直接返回root的右子树就可以了(若为叶子节点,此处已经返回nullptr了)
2.2若root的右子树不在,那么直接返回root的左子树就可以了
2.3若都在,那么可以记录root->left(不记录跑完就找不到了),进入左节点后,一直往右跑,最后跑到空了后,把右子树接过来即可。即跑到最后,再head->right = root->right;随后把root指针指向改好的root->left,返回return root即可。
7、二叉树的最近公共祖先
【方法一:记录下来到达两个节点的路】(由于条件说所有节点的值不同,因此不用哈希表,用数组就可以了),然后最后一个一样的元素就是祖先!
dfs找路的代码还是记忆一下吧。—上面那段的思想是错误的。
【正确个人思路】不跟入门中的搜索树一样,别想着直接找到一条路通往某个节点。还是利用哈希表把所有的节点的父节点记住,然后也别找数组放了,麻烦四,直接再搞个bool的哈希表,第一遍遍历经过的搞为true,然后第二遍遍历当遇到第一个ture时,直接返回就行了。
【整体思路&技巧】
1、首先先创立一个遍历找父亲函数,但一定注意!不要在函数体内传入map数据结构,你调用递归的时候map会乱,你现在的水平还不配,也就是说吧map在函数体外定义好。
2、遍历找父亲函数其实很简单,直接先判断有无左节点再判断有无右节点即可:有左节点就map【root->left】= root,然后往左进入递归。有右节点也同上面的操作。
3、主函数中,先经过遍历函数,随后勿忘!!!
给根节点root也加到哈希表,指出他的父亲为null
4、随后两个while即可。一个为:从q的父亲直到跑到null,记录所有经过的为true。
第二个为,从p的父亲直到跑到null,若能碰到true就返回那个点就行
【方法二:递归】利用p、q是位于祖先节点的两侧。十分简单
1、首先两个判断,如果root为nullptr返回nullptr
2、如果root的值为p或者q就返回root。
3、直接左递归,把p和q也传进去
4、再右递归,把p和q也传进去
5、上面两个操作已经到了底部,随后开始找公共祖先即可三个if(没有else)
5.1 if(left == NULL)return right;//左边没有那么两个点肯定在右子树
5.2 if(right == NULL)return left;//右边没有那么两个点肯定在左子树
5.3 if((left && right)return root;//左右子树都找到了,由于递归的性质,这是最先找到的了,因此该root是祖先
6、因为必须有返回值,因此返回一个NULL即可。
五、栈/队列
1、设计最小栈—在常数时间内检索到最小元素的栈
设计两个堆栈,一个放最小值一个正常放。当push时,检查是否进入正常堆栈的值时最小值,如果不是的话,往放最小值继续放最小值即可。这样pop的时候一块pop也行。
妙不可言!
即:我们可以使用一个辅助栈,与元素栈同步插入与删除,每次插入存储已存入元素里面的的最小值。
【技巧】其中不用另起int来存最小值,只需要
min(val,sub_ans.top())
2、找出游戏获胜者—需要循环起始的圈类问题
像此类一圈,循环起始的直接就用deque即可!
其实就是同队列模拟一个环。
取出头,将头放入尾。
而题目就是k-1次这样的操作后,把头给删除掉。
最后删除的只剩下一个,返回即可!
2、移除无效的括号
【题目】给你一个由 ‘(’、‘)’ 和小写字母组成的字符串 s。
你需要从字符串中删除最少数目的 ‘(’ 或者 ‘)’ (可以删除任意位置的括号),使得剩下的「括号字符串」有效。
【易错点】本文犯了一个傻瓜错误。我时想着一遍检测就随测随删除,结果发现不可以,因为每次删除字符串,i索引都会变化。我本人为了解决这个问题,专门创了个哈希表,这样直接把不要的下标记录下来,然后将原字符串赋予一个新字符串就可以了。
我的方法挺好的,跟官方题解差不多,现在简单整理下自己的思路:
1、先建立个set,用来记录需要删除的索引(由于erase删除的时候会改变字符串里面的索引,因此应赋给新字符串而删掉旧字符串)
2、遍历字符串
2.1、创建个堆栈,目的就是只存放(的索引,只要是(就放进去。
2.2、一旦发现字符串里面是),就判断堆栈是否为空,不为空就减去一个(,否则就将索引放入set
3、遍历结束后,此时堆栈里面全是多余的(,此时将堆栈内存放的索引放入set
4、一个遍历,除set内的索引外全赋给新字符串返回即可。
六、图总结
1、找到小镇的法官
官方的题解】用图结构来计算入度和出度即可。
因为法官不信任别人,且别人都信任他,因此他的入度位n-1,出度为0.
而trust就是一个边的集合,可以通过遍历trust来计算每个节点的入度和出度
---------做法-------
1、就是建立两个数组,分别在遍历二维数组的时候,储存下来每个点的入度和出度。这两个数组是要赋初值为0的,因此一定要注意是n+1而不仅仅是n。
2、从1开始,随后遍历n,然后当这个数组同一个i的入度和出度符合上面的情况时,输出i即可。
2、可以到达所有点的最少点数目
图的问题中,入度和出度很重要,其需要在边集集合中定义好。
寻找入度为零的节点即可秒杀此题
七、优先队列
1、桶排序
桶排序的意思是为每个值设立一个桶,桶内记录这个值出现的次数(或其它属
性),然后对桶进行排序。
【思路】
首先遍历一遍 得出数字和次数的关系(map)
然后定义一个数组(桶) 由于k不会大于第一个最大的次数。所以桶的长度len(nums)+1即可
第k(k-1, k-2, k-3 …)大的次数就是第k个桶。 值就是对应的数字。(tmp[v] = num)。考虑到可能出现相同频率的数字(例如 11122212364 1和2的频率相同),所以桶是个二维数组。用来存放频率相同的数字(tmp[v] = append(tmp[v], num))
1、第一次遍历建立一个map,并从中找到最大的max次数
2、建立一个二维数组,将次数作为第一个维度,把相应数组存入进去。
3、从后往前遍历二维数组的第一维度,输出的就是那几个次数最大的了。(假设测试集4,2.1,1)其中就是没有次数3,所以他的第二维度为空,就判断空过去。
【总结】其实桶排序就是三部曲
1、遍历建立map
2、将按次数放入二维数组,次数就是下表,数组里面是该次数的字符
3、遍历二维数组输出结果。
2、最接近原点的K个点
我用的priority_queue解决的,其中开方会用到double类型而我用了int,所以失败了一次,总的十分成功!下面我将对该最队列的排序重载进行总结:
1、首先本题用到了pair<double,vector>因为double是距离,而vector是坐标
2、 因此再构建的时候需要这样定义
priority_queue<pair<double,vector>, vector<pair<double,vector>>, myComparison> a;
中间那个其实就是在第一个基础上套了个vector,可以联想堆的原理(固定格式哈)。而myComparison便是自己定义的排序结构了,下面详讲
3、首先要注意是定义一个结构体:内容就是重载()也就是仿函数
3.1其实就是重载() 如下面比较pair中第一个double值比较大的返回。
bool operator()(pair<double,vector<int>>&p1,pair<double,vector<int>>&p2)
{
return p1.first>p2.first;//小顶堆是大于号
}
3.2要注意大小号的问题,由于堆原理中,默认是下面的左右子节点大于上面的父节点,便让父节点跟最大的那个换一下,而此处修改便是找最大的那个条件,即该结构中源代码是<,而编写的新仿函数或者重载<,使其return 大于的才对,就是将<变成了>。因此就会从默认的由小到大排转成了由大到小排!
就因此记得到时候调反一下逻辑。注意不要跟sort中的匿名函数混了,因为这里面不能装匿名函数,其是有本质区别的。
八、算法总结
1、判断出现次数的奇偶
可以使用本身进行异或来看1或者0的次数--------异构的运算符 ^。
2、查看二维数组是否有重复数组的方法
查看二维数组ans中是否有tem一维数组,没有就尾插进去
auto it = find(ans.begin(),ans.end(),tem);
if(it==ans.end())ans.push_back(tem);
3、三数之和—找出所有和为 0 且不重复的三元组
难点在于去重!
其实就是三个指针跑,不要三重for去遍历。我们挨个分析三个指针:
1、从负数到正,正了就退出,因为正数相加出不来0。
2、第二个指针指向最左,第三个指针指向最右。判断与第一个指针的数相加是否为零。大就左走,小就右走,easy~
3、【重点】排序才能去重!!
首先处理最难的第一个指针,第一个指针要瞄着不可以跟前面的一样。一定记住,瞄前面(看目前指的跟前面的一样吗)才算是走过,不行才接着往下走!!瞄后面成了行不行先走一会了!(此处为什么不瞄后面?因为你如果瞄后面,递进过去你左指针指不到重复的元素直接gg)
其次,第二三个指针是比较好解决的,主要记得先把三个指针的内容先排进二维数组之后,才能再去跳,让左右指针不去重复。
4、合并区间—排序+双指针
我想总结一下我的思路吧,我的思路感觉比官方稳一些。官方直接对原数组左边开始排序,
思路:
1、我是抽出来一个最小值的数组,一个最大值的数组。
2、然后先给两个数组排序
3、最小的和最大的肯定放进去,故一个在for循环前面,一个在for循环后面
4、双指针,跑就完了,最小值大于最大值,就先放进去最大值(与前面最小值构成一个完整区间),然后再放进去最小值(与后面最大值构成一个完整的区间)。如果大于或者等于,就把这两个都扔了就行了,因为肯定是能合并的!
5、旋转图像—顺时针和逆时针90°旋转矩阵
【顺时针90°旋转】将 n x n 矩阵 matrix 按照左上到右下的对角线进行镜像对称,,随后将每行进行reverse反转即可。
【逆时针90°旋转】将 n x n 矩阵 matrix 按照右上到左下的对角线进行镜像对称,,随后将每行进行reverse反转即可。
【难点】左上到右下的对角线翻转,直接两个嵌套的for循环(注意第一个for循环遍历所有行,第二个for循环要j<i,毕竟是对角线嘛),swap【i】【j】–【j】【i】即可
【难点】右上到左下的对角线翻转,直接两个嵌套的for循环(注意第一个for循环遍历所有行,第二个for循环要j<n-i,毕竟是对角线嘛),swap【i】【j】–【n-1-j】【n-1-i】即可
【总结】其实上面两个难点不用去专门记忆,到时候看着对角线,只要能用i和j指示一边就行,另一边直接i和j的位置调换就是对角线对称的那个!
6、螺旋矩阵
其实就是找迭代条件,可以用while(num<n*n),这样就是一轮轮的四个步骤轮番跑。
1、定义上下左右边界.(就靠这四个变量来四个步骤模拟呢)
int t=0;
int l=0;
int r=n-1;
int b=n-1;
2、四个步骤创造矩阵的时候,每搞完一个步骤,相应边界就往里缩即可!!
while(num<=(n*n))
{
for(int j=l;j<=r;j++)
{
matrix[t][j] = num++;
}
t++;//往里缩
for(int j=t;j<=b;j++)
{
matrix[j][r] = num++;
}
r--;//往里缩
for(int j=r;j>=l;j--)
{
matrix[b][j] = num++;
}
b--;//往里缩
for(int j=b;j>=t;j--)
{
matrix[j][l] = num++;
}
l++;//往里缩
}
7、矩阵搜索—Z字形查找(找到最大的再所小就行了)
本题的矩阵满足以下条件:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
直接三步骤秒杀:
1、先把指针指到第一行最右边,
2、如果目标比他大,调整x轴向下跑就行
3、如果目标比他小,调整y轴向左跑就行
8、无重叠区间——贪心之区间调度问题
虽说区间有许多数据结构帮忙解决,但是关于区间之间的重叠多少个、去除几个不重叠之类的问题还得靠贪心。其实就是找最早结束的区间,然后通过最早结束的区间把重叠的搞掉,随后继续贪心下去,就是去掉最少的了!
其核心就是四步:
0、先给区间集合 intvs排序,只需要第二维度升序!毕竟只需要比较第二维度和第一维度找交集,千万别排第一维度,因为我们贪心就是找最早结束的,跟最早开始没关系。
1、从区间集合 intvs 中选择一个区间 x,这个 x 是在当前所有区间中结束最早的(end 最小)。
2、把所有与 x 区间相交的区间从区间集合 intvs 中删除,若不重合则更新x为最新的不相交区间(查是否相交,靠区间end和start的比较)
3、重复步骤 1 和 2,直到 intvs 为空为止。之前选出的那些 x 就是最大不相交子集。
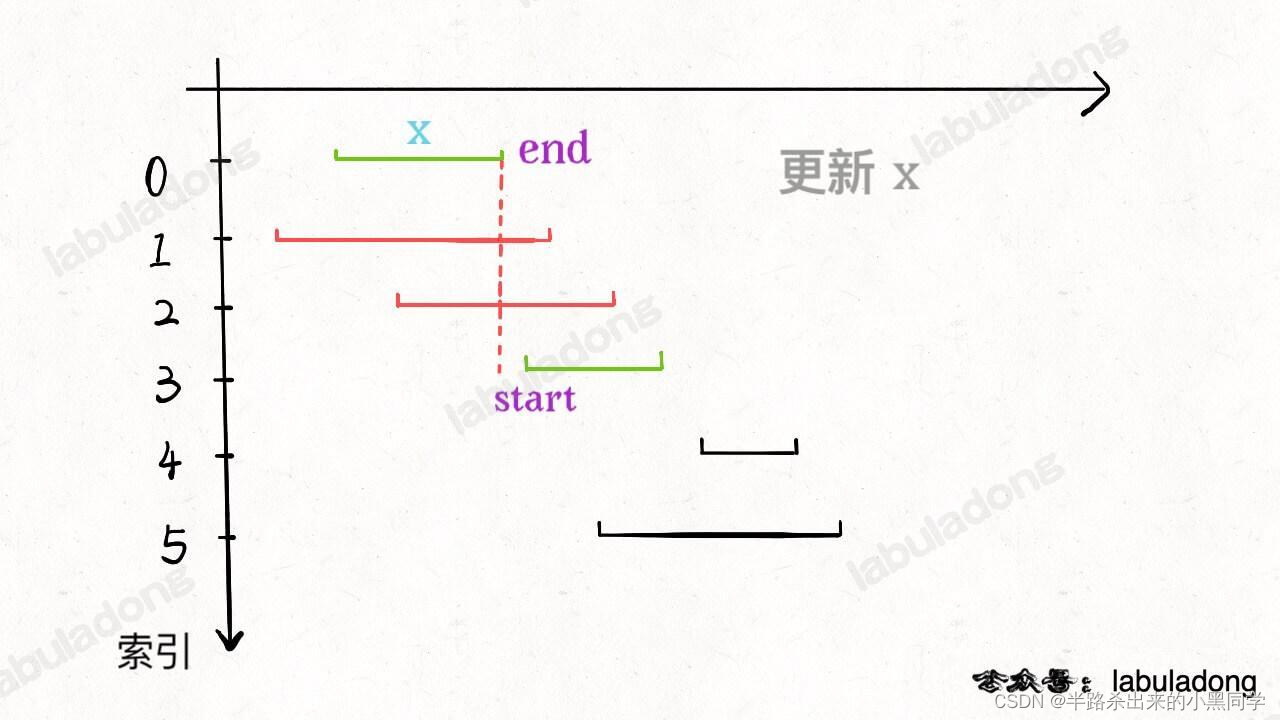
【注意】 sort(intervals.begin(),intervals.end(),[](const vector<int> &rhs,const vector<int> &abs){ return rhs[1]<abs[1]; });这句排序中,如果不加&也会超时,所以一定要注意细节,必须引用起来!!!
9、除自身以外数组的乘积–不可以使用除法
【笨方法】
1、就是左边递乘,形成一个左边数组
2、右边递乘,形成一个右边数组
3、然后最后在搞answer数组的时候,直接左右数组抽出来相乘就行了!!
【空间复杂度1】—就是改进笨方法,看不懂别看了,个人认为浪费时间
把answer先左边递归形成左边数组,(因为这样answer可以不用管右边,右边消失就消失)然后右边循环递乘的时候不储存至num了,直接利用num更新answer。
10、和为K的子数组
【题意】做这个题,首先要理解题意!!子数组,其隐含的条件就是一个连续的数组,其长度是连续的。
【滑动窗口法】由于是子数组,可往滑动窗口那里想,其实就是一个双指针。固定左边的,里面的和小了,右边就往右走一位。直到和等于k,则左边再跑。和大于k就退出。
但这个复杂度是n的三次方,本题用这个方法必超时
【前缀和+哈希表】首先,关于这种加和的,其实能一个for解决。就是用后面的累和减去前面的累和。这是一个很重要的思想!!(而哈希表是因为要统计个数,否则set也可以,利于查找)下面是详细步骤:
1、因为要找和为k。假设j<i,那么其实就是找sum[i]-sum[j]=k
2、建立一个for循环,那么其实i在增大的时候,可以直接找sum[j]----其实就是看看前面有没有和是k-sum[i]大小的。
基于1和2.那怎么找呢。因为一次循环其实就可以得到sum所有了!这时候就用到哈希表(存有sum[j])了(毕竟涉及到查找嘛)。但注意是用map而不是set,是因为要记录次数嘛,有可能里面有正负数,sum会重复的。然后count就是要加等于sum[j]出现的次数(即count可不是正常加1而是对哈希表里面的计数相加)!
【易错点】这里注意,要提前给map赋值map【0】=1。因为这是隐含条件,毕竟0也可以加1嘛!!
11、单词规律
【题目】给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。即 dog cat dog -----aba
【题解】双射—其实可以直接字符对应一串唯一的字符串来不断验证。
那么就是两个哈希表了。一个a,b的;一个b,a的;
那么为何要两个呢:
假设只有1个a,b,那么一旦发现是新的b就会再赋给a,这样就发生了a的重复。也就是说 哈希map也只能保证键为不重复的,而题目里两边都需要唯一。因此两个哈希表,没毛病吧
12、划分字母区间
【题目】字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
【自己的思想总结】因为划分尽可能多,又因为一个字母只能出现一次,其实就是从第一个字母开始,从0开始遍历到最后,只要字母的总次数耗尽,就赶紧输出一波。然后再找下一个字母,知道总次数都输出完毕。其中比较草的就是因为第一个字母出现的总次数没耗尽之前。遍历的过程会产生新的字母,那么那些字母有可能也好不尽,那么此时第一个字母即便次数耗尽,也不可以输出,要等所有新遇到的字母都耗尽才行。这个比较草的点我用双指针解决了!
1、首先把所有字母放在哈希表里,哈希表需要记录每个字母出现的次数。
2、建立双指针i和j。i从第一个开始,让j从第二个开始。只有i出现的总次数不是1,那么就开始判断i和j是否相等。
3、那么为何要判其相等呢,其实就是让j去往后走,然后边走边减去总次数,直到i减完次数,那么i就可以前进了。此时相等的目的便出来了
4、因为j在往后走的时候可能会遇到新的字母,那么为了处理好他们,我选择让i再走。
5、此时如果新出的字母也耗尽了,那么j也就不用前进,只会发生i前进。如果新出的字母没有耗尽,那么再继续让j走就行。直到i和j重合。
6、重合也就代表着。从第一次i的位置到j的位置,这个区间的字母已经满足全部出现的条件了,那么立刻输出。
7、但是由于i也在变换,第一次i的位置是需要记录的,因此设置一个num即可!
【官解思路】
其实可以不使用双指针往前走。
在i的遍历里面,设立一个start和一个end:end一直该案就可以。就是end= max(end,end[s[i]])
这样end就会自动更新了!
然后输出完,start=end+1即可!!
13、最长回文子串—DP解决
回文子串的特性:翻转后字符串相等!
【动态规划】因为一个回文串,如果前后所加的元素相等,那么新构成的字符串也将是回文串,因此可以思考用动态规划一步步找。
1、得到状态转移方程:P(i,j)=P(i+1,j-1)&& s[i]==s[j]
2、再去考虑边界条件:P(i,i)为true。
P(i,i+1) = (s[i],s[i+1])
最终答案就是里面j-i+1最大的值(可以用二维矩阵来承接i和j区间是否为回文–0 or 1)。
3、【重点!如何把迭代公式和边界条件应用到代码里】
由于本代码是从长度短的转移到长度长的,因此不如直接循环长度,这样j可以有i+L-1得到!
3.1首先长度如果小于2直接返回就行。注意这类边界情况。
3.2迭代前,先处理好边界条件。先将长度为1的直接赋值为1。
3.3迭代(重点!!如何实现呢)
其实还是依靠for循环来完成迭代,最开始也提到过了,直接选择按长度循环,然后确定好起点即可。
3.3.1直接确定两个循环
3.3.2先判断迭代的共同先决条件,即s[i]==s[j]吗?
3.3.3等于后再判断L是否为2,2就直接置1
3.3.3不为2,就进入迭代公式,是否ans[i-1][j+1]==1,为1则最终ans【i】【j】就置1
3.4 每次循环完,查看一下是否最大就可以了,如果长度为最大,那么就更新最大长度以及其下标。
九、语法总结
1、广义的排序算法sort()
广义的排序,sort()----对于STL,几乎所有的容器都可以使用该函数来排序,一定要掌握。首先看普通的sort()
sort(nums.begin(),nums.end()); // nums是vector<int>
其次是不用怎么操作的对vector直接升降序排序
升序:sort(begin, end, less<int>());
降序:sort(begin, end, greater<int>())
//注意后面的(),像堆和有序容器这类都无需()。
//而sort函数,不仅仅在这里,自定义结构体重构()等,都需要加()
sort如何对二维中的数组们进行排序,此处就要用到lambda虚函数了:下面的例子就是以二维数组中的第一个值进行对数组的排序。这就是sort中最常用的定义比较函数法
sort(intervals.begin(), intervals.end(), [](const auto& u, const auto& v) { return u[0] < v[0]; });//此例就是从小到大排序!
重构max_element的比较规则
max_element类似于大根堆和小根堆。因此,注意升降序的定义跟sort正好相反:
【案例】取一个map<char, int>cnt里面的所记录字母个数的最大值:
int N = max_element(cnt.begin(),cnt.end(),[](auto &a,auto &b){
return a.second<b.second;
})->second;
2、不熟悉的函数
1、abs()是取绝对值的函数。
2、find()广义函数返回迭代器。返回指针!!
3、使用 return;可以直接结束void为返回类型的函数
4、二分查找的函数调用:auto it = lower_bound(row.begin(), row.end(), target);
5、找一个区间的最大值,可以直接用max_element方法,只不过返回迭代器,需要解引用*max_element(f.begin(), f.end());
6、ListNode *pA = headA, *pB = headB; 加个逗号,这种一个数据类型的可以一起初始化
7、std::tie 可用于解包 std::pair ,因此
pair<ListNode*, ListNode*> result = myReverse(head, tail);
可简化为tie(head, tail) = myReverse(head, tail);
此时head 和 tail就是函数返回的ListNode*指针。
8、一个函数返回两个值得方法:return {tail, head};
9、开根号的函数—sqrt(),平方函数----pow(n,2)
10、 min_element()和max_element()将返回vector数组中的最大最小元素的指针因此勿忘加*把元素提取出来
十、BUG总结
1、c++中有unordered_map和unordered_set这两个数据结构,其内部实现是哈希表,这就要求作为键值的类型必须是可哈希的,比如常见的数据类型int、string等。
2、以后双指针别以相等不等为判别条件了,要以left<right为条件!!。还有如果left和right用while大动,就勿忘加上动完依旧left<right。
3、记住c++中int的3/2是向下取整为1的
4、用到ceil(向上取整)或者floor(向下取整)或者round的时候,要记得注意2处:a、不用int型相除,将一个转化成double型,如:ceil(double(3)/2);b、记得包含头文件<math>
5、注意if并列问题,有些题目中,如果else if改成if 直接指针爆炸
6、对于字符串/链表运算类的运算题
【nt1】这种运算题,因为用到for,所以千万别忘记,for走完,如果还有进位,该怎么办!!for完加个判断呀!
【nt2】一定要看好数的范围,特别是乘法此类的。本次出错就是因int放不下有的数字。像此种直接longlong冲!但是涉及到10的n次方,建议就是放数组,防止大数出现这种麻烦!
7、对于在递归中放入数据类型
此时一定要用&符号(使其引用起来),即
string s-> string &s而list<string> key -> list<string>&key这样才行,否则每次递归都会乱掉。
十一、技巧
1、像此类
if(i<n) return false;
return true;//这个防止str比pattern长的
其实像这样就可以化简成一句话
return i>=n就行了!
2、遍历二维数组中的快速方法:
auto& edge : trust
然后edge[0]就是一维数组














 857
857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









