










今天力扣每日一题遇到了一个648有趣的单词替换,其实哈希表就很容易秒杀,但因本题知道了一个专门处理此类问题的高级数据结构,特此总结一下!因为labuladong大佬已经总结好了(但JAVA搞得其实不好直接化成cpp模板),因此本文主要是对其大佬发布的文章进行总结,并转到c++后加上自己的注释。
引用自https://labuladong.github.io/algo/2/22/60/
文章目录
前言
常见的 Map 和 Set 的底层实现原理有哈希表和二叉搜索树两种,比如C++ 的 unorderd_map/unordered_set 底层就是用哈希表实现,而C++ 的 map/set 底层使用红黑树这种自平衡 BST 实现的。
而本文实现的 trie_set/trie_map 底层则用 Trie 树这种结构来实现。
本质上 Set 可以视为一种特殊的 Map,Set 其实就是 Map 中的键。所以本文先实现 trie_map,然后在 trie_map 的基础上封装出 trie_set。
由于 Trie 树原理,我们要求 trie_map 的键必须是字符串类型,值的类型 V 可以随意。
Trie树的原理
Trie 树本质上就是一棵从二叉树衍生出来的多叉树。
普通的多叉树如下图所示:
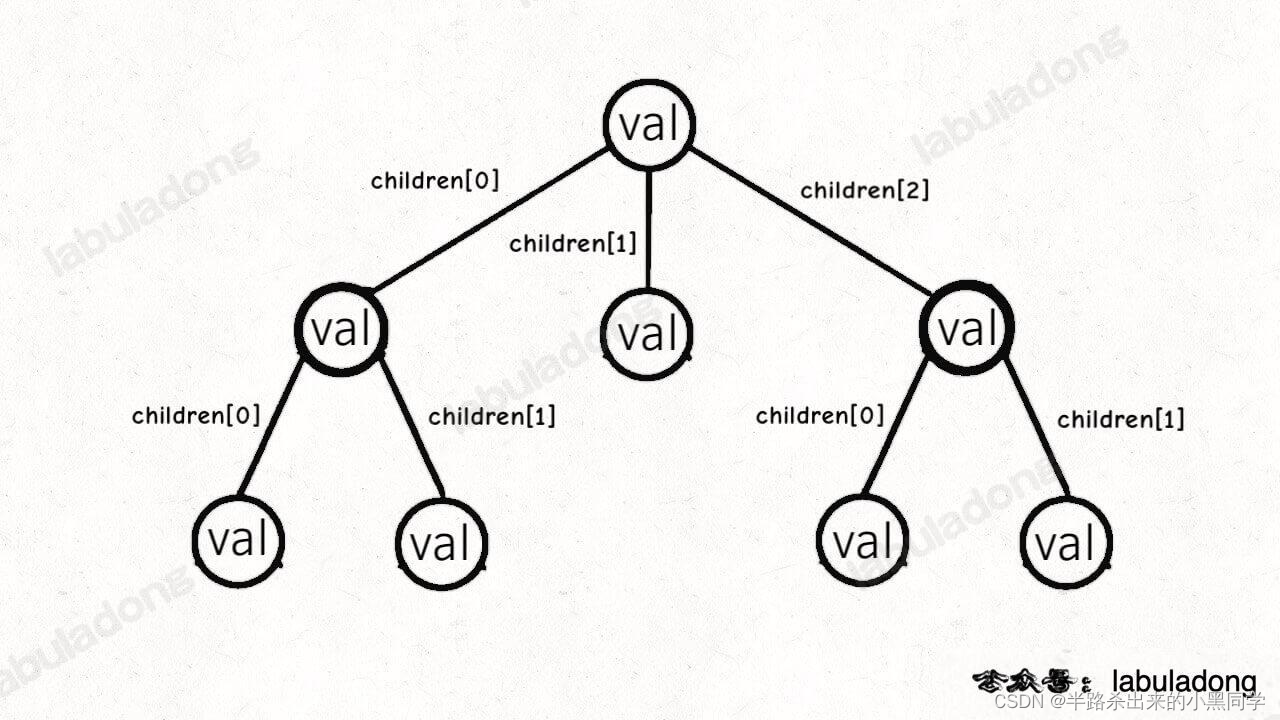
但是字典树是和之前的普通多叉树节点不同的,TrieNode 中 children 数组的索引是有意义的,代表键中的一个字符。比如说 children[97] 如果非空,说明这里存储了一个字符 ‘a’,因为 ‘a’ 的 ASCII 码为 97。
其结构如下:
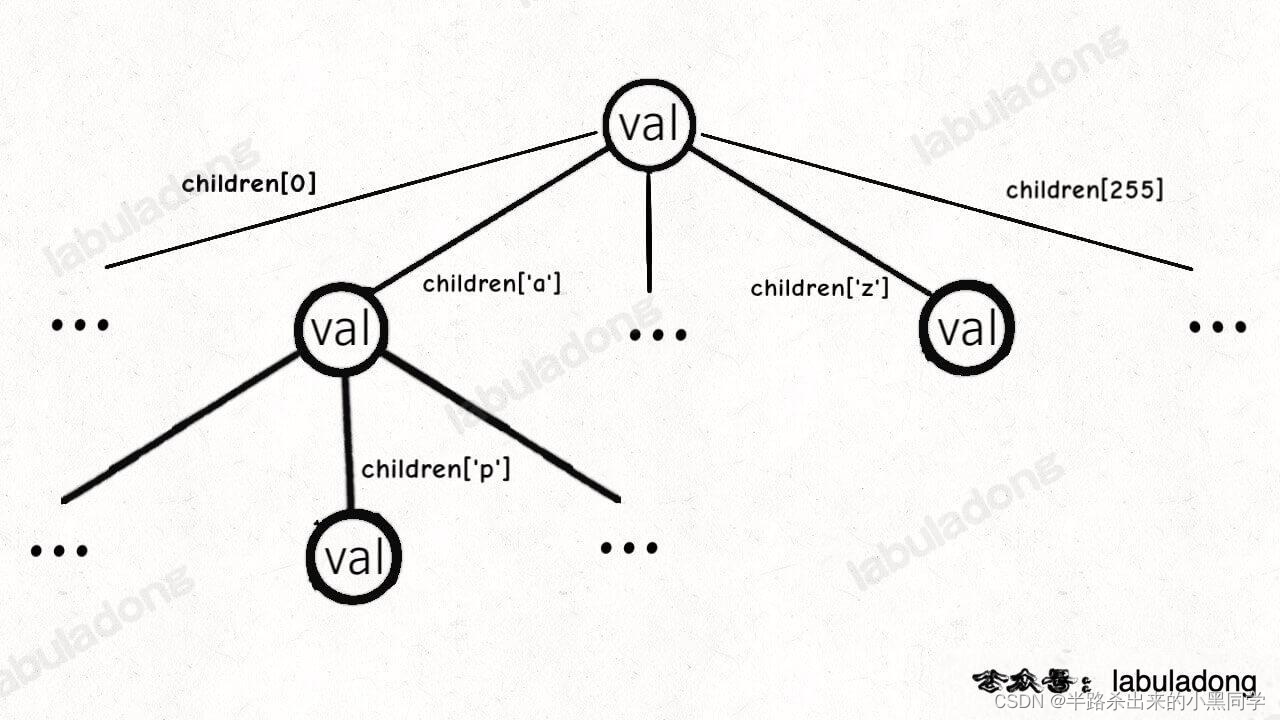
一个节点有 256 个子节点指针(主要符合ascii码规律,这是方便理解,实际框架我们不使用这种数组),但大多数时候都是空的,可以省略掉不画,所以一般你看到的 Trie 树长这样:
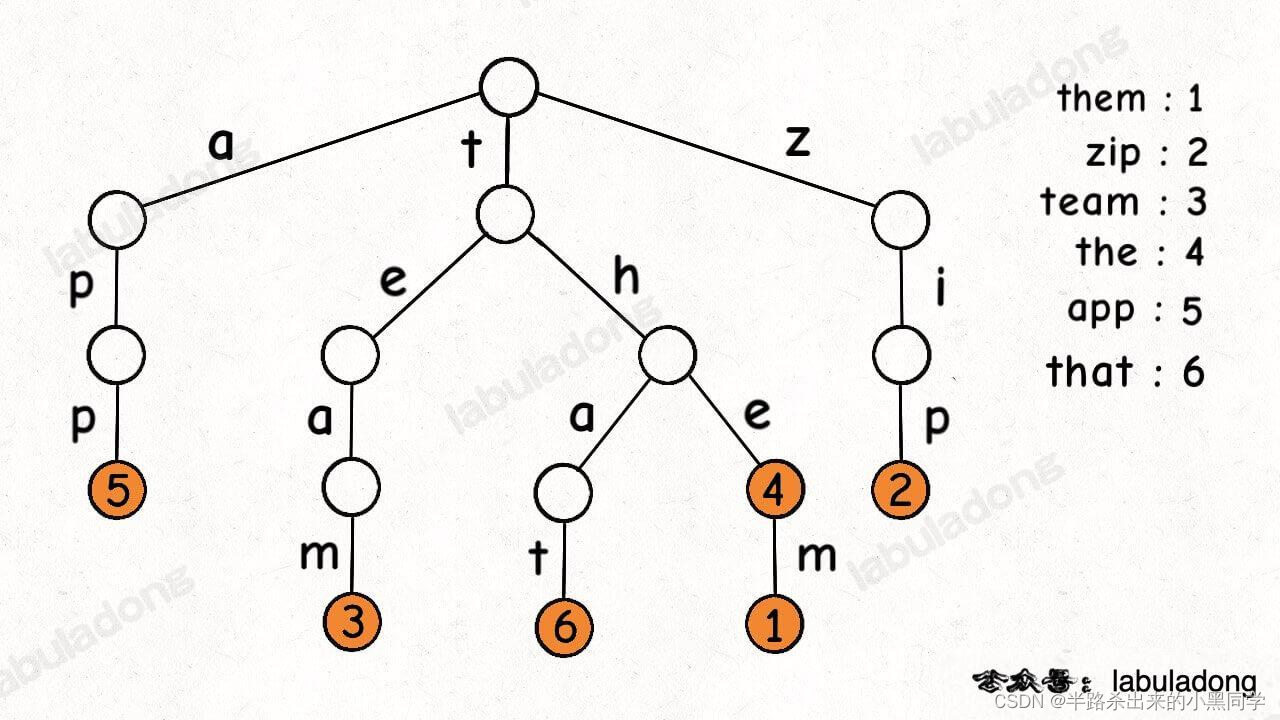
这是在 trie_map 中插入一些键值对后的样子,白色节点代表 val 字段为空,橙色节点代表 val 字段非空。
这里要特别注意,TrieNode 节点本身只存储 val 字段,并没有一个字段来存储字符,字符是通过子节点在父节点的 children 数组中的索引确定的。
形象理解就是,Trie 树用「树枝」存储字符串(键),用「节点」存储字符串(键)对应的数据(值)。所以我在图中把字符标在树枝,键对应的值 val 标在节点上:
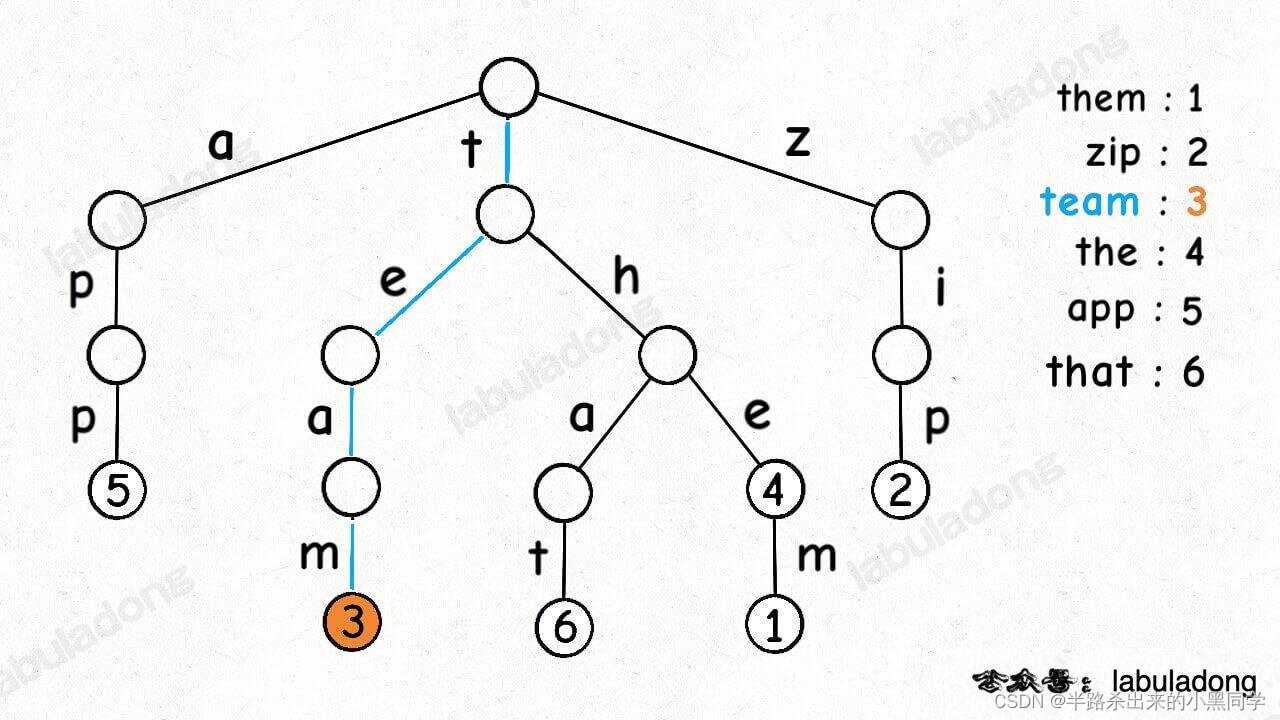
看上图应该可以理解Trie 树也叫前缀树了,因为其中的字符串共享前缀,相同前缀的字符串集中在 Trie 树中的一个子树上,给字符串的处理带来很大的便利。理解了上面的图,对接下来出模板的帮助就很大了。
Trie树的map模块化原理代码
其核心就是如上图所示,其路上的树枝是键,而节点是值。
数据结构
首先,我们可以先像前文中的线段树一样,直接先建立好一个tree数组。这里原因引用力扣上宫水三叶大佬的话:
除非某些语言在启动时,采用虚拟机的方式,并且预先分配了足够的内存,否则所有的 new 操作都需要反映到 os 上,而在 linux 分配时需要遍历红黑树,因此即使是总空间一样,一次性的 new 要比多次小空间的 new 更省时间,同时集中性的 new 也比分散性的 new 操作要更快,这也就是为什么我们不无脑使用 TrieNode 的原因。
//1、先建立节点的数据结构
struct Node
{
int val;//如果仅是set其实不要也行。这个是map中的值
int next[26];
Node():val(-1),next{0}{}//数组初始化0
//这里值初始化-1(随题目修改),代表超出数值范围,其没有值。
};
//2、提前建立好申请过内存的一个数组
constexpr static int M = 500000;
//这里就是提前申请的内存数,如果WA了,此处就可以在修改
Node Tree[M];
int idx = 0;//这个是精髓,它会和pushdown的第一步一起完成动态开点
模板的基础–根据key找节点(是否含有前缀和为key的键)
理解了下面这段函数,根本不用背模板,只需修改下面这个就能写出来所有函数
下面很多的功能都需要用到这个!! 该函数功能,是根据key来返回节点下标(其实就是代表着返回节点啦),如果没有就返回-1。
int p = 0;//相当于root拿出来
// 根据key找节点部分
for(int i = 0 ;i < key.size(); i++)
{
int u = s[i] - 'a';
// 节点已经无法向下搜索了--这个条件无论如何别忘记!!
if(Tree[p].next[u] == 0) return -1;//要么返回,要么开点(见插入功能)
//继续向下搜索
p = Tree[p].next[u];
}
return p;
功能1–查询
首先,先实现一个查询节点功能,其能根据键key来返回该节点的值(由于化成数组,因此返回索引)。
int query(string s){
int p = 0;//相当于root拿出来
// 根据key找节点部分
for(int i = 0 ;i < s.size(); i++)
{
int u = s[i] - 'a';
// 节点已经无法向下搜索了
if(Tree[p].next[u] == 0) return -1;
p = Tree[p].next[u];
}
// p 为空(节点为空,见上面)或者
// p 的 val 字段为空(map中没值)都说明 key 没有对应的值
if(Tree[p].val == -1) return false;
return Tree[p].val;
}
功能2–插入
其实也是根据key找节点,只不过找不到的时候就idx++来动态加点。
// 定义:向以 p 为根的 Trie 树中插入 key[i..],返回插入完成后的根节点
private TrieNode<V> put(string key, int val) {
int p = 0;//相当于root拿出来
for(int i =0;i<key.size();++i)
{
int u = key[i] - 'a';
if(Tree[p].next[u] == 0) Tree[p].next[u] = ++idx;
p = Tree[p].next[u];
}
Tree[p].val = val;
return p;
}
功能3–删除
一样,还是根据key来找节点
// 定义:在以 p为根的 Trie 树中删除 key[i..]
void erase(String word) {
int p = 0 ;
for (int i = 0 ;i< word.size();i++){
int u = key[i] - 'a';
if (Tree[p].next[u] == 0) return ;
p = Tree[p].next[u];
}
// 到达最后一个位置,单词计数改成无效即可
Tree[p].val = -1;
}
功能4–最短前缀
在 Map 的所有键中搜索s的最短前缀,例如含有键”the“和”avs“则在s为"themxyz"的情况下,输出”the“。其实就是根据key找节点的过程遇到第一次存有val的节点返回就行了!
string shortestPrefix(string s) {
int p = 0;//相当于root拿出来
// 从节点 node 开始搜索 key
for (int i = 0; i < s.size(); i++) {
int u = s[i] - 'a';
// 找到一个键是 query 的前缀--加了这句话
// 注意先后顺序,应该先判断能不能返回,在判断能不能向下走
if (tree[p].val != -1) return s.substr(0, i);//注意是i!因为走边!
// 无法向下搜索
if (Tree[p].next[u] == 0) return "";
// 向下搜索
p = Tree[p].next[u];
}
// 如果 query 本身就是一个键
if (p != 0 && Tree[p].val != -1) return s;
//否则就是没找到
return "";
}
这里需要注意一下, for 循环结束之后我们还需要额外检查一下!
功能5–最长前缀
与最短前缀类似,只不过不要立马return,而是统计一个最长长度,最后一起返回。
string shortestPrefix(string s) {
int p = 0;//相当于root拿出来
// 记录前缀的最大长度
int max_len = 0;
// 从节点 node 开始搜索 key
for (int i = 0; i < s.size(); i++) {
int u = s[i] - 'a';
// 找到一个键是 query 的前缀--加了这句话
if (tree[p].val != -1) max_len = i;
// 无法向下搜索
if (Tree[p].next[u] == 0) break;
// 向下搜索
p = Tree[p].next[u];
}
// 如果 query 本身就是一个键
if (p != 0 && Tree[p].val != -1) return query;
//最后统一返回
return query.substr(0, max_len);
}
功能6–根据前缀找所有键
接下来,我们来实现keysWithPrefix方法,得到所有前缀为prefix的键,其效果应该如下图所示:

其过程一共就两步:
1、先利用“根据key找节点”函数在 Trie 树中找到prefix对应的节点x
2、通过多叉树的遍历算法,遍历x为根的这棵 Trie 树,找到所有键值对。但是因为我们需要遍历的是“树枝”而不是”节点“,因此使用的是类似回溯的操作。
// 搜索前缀为 prefix 的所有键
vector<string>ans;//先定义好,毕竟接下来要使用递归
vector<string> keysWithPrefix(string prefix) {
// 找到匹配 prefix 在 Trie 树中的那个节点
int p = 0;//相当于root拿出来
// 根据key找节点部分
for(int i = 0 ;i < key.size(); i++)
{
int u = s[i] - 'a';
// 节点已经无法向下搜索了
if(Tree[p].next[u] == 0) return ans;
//继续向下搜索
p = Tree[p].next[u];
}
// DFS 遍历以 x 为根的这棵 Trie 树(建议配合下面应用力扣211一起“食用”)
traverse(p, ans,prefix);
return ans;
}
// 遍历以 p 节点为根的 Trie 树,找到所有键
void traverse(int p, string path) {
// 到达 Trie 树底部叶子结点
if (p == 0) return;
// 找到一个 key,添加到结果列表中
if (Tree[p].val != -1) ans.push_back(path);
// 回溯算法遍历框架
for (int i = 0; i < 26; i++) {
// 做选择
path.push_back(i+'a');
traverse(Tree[p].next[i], path);
// 撤销选择
path.pop_back();
}
}
应用
力扣208 实现前缀树I–涉及查询、插入、根据key找节点

class Trie {
public:
Trie() {
}
int idx = 0;
void insert(string word) {
int p = 0;
for(int i=0;i<word.size();++i)
{
int u = word[i] - 'a';
if(Tree[p].next[u] == 0) Tree[p].next[u] = ++idx;
p = Tree[p].next[u];
}
Tree[p].val = 1;
}
bool search(string word) {
int p = 0;
for(int i=0;i<word.size();++i)
{
int u = word[i] - 'a';
if(Tree[p].next[u] == 0) return false;
p = Tree[p].next[u];
}
if(Tree[p].val == -1) return false;
return true;
}
bool startsWith(string prefix) {
int p = 0;
for(int i=0;i<prefix.size();++i)
{
int u = prefix[i] - 'a';
if(Tree[p].next[u] == 0) return false;
p = Tree[p].next[u];
}
return true;
}
private:
struct Node
{
int val;
int next[26];
Node():val(-1),next{0}{};
};
constexpr static int M = 40000;
Node Tree[M];
};
力扣209 实现前缀树II–涉及插入、查询、删除、根据前缀找所有键
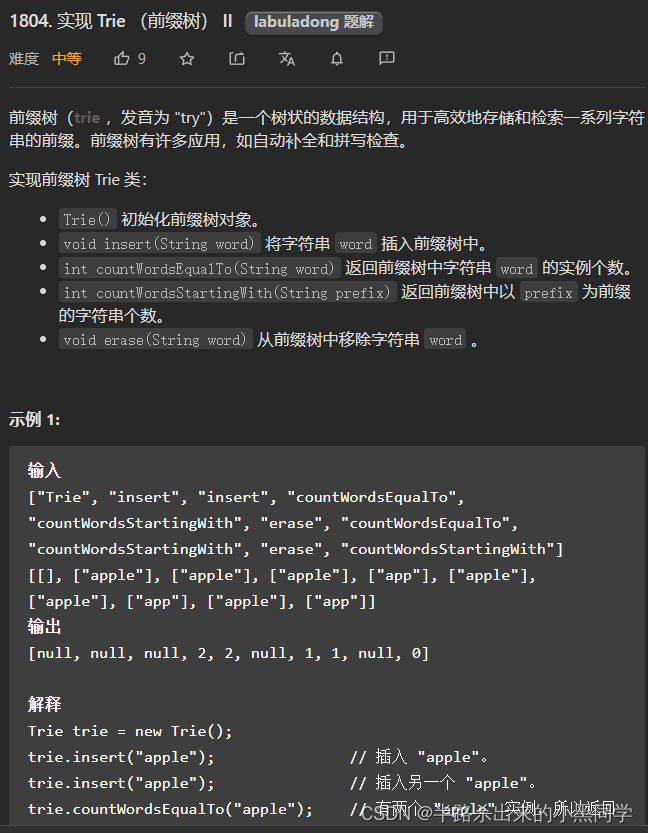
class Trie {
public:
Trie() {
}
void insert(string word) {
int p = 0;
for(int i=0; i<word.size();++i)
{
int u = word[i] - 'a';
if(Tree[p].next[u]==0) Tree[p].next[u] = ++idx;
p = Tree[p].next[u];
}
++Tree[p].val;
return;
}
int countWordsEqualTo(string word) {
int p = 0;
for(int i=0; i<word.size();++i)
{
int u = word[i] - 'a';
if(Tree[p].next[u]==0) return 0;
p = Tree[p].next[u];
}
return Tree[p].val;
}
int countWordsStartingWith(string prefix) {
int p = 0;
for(int i=0; i<prefix.size();++i)
{
int u = prefix[i] - 'a';
if(Tree[p].next[u]==0) return 0;
p = Tree[p].next[u];
}
return traverse(p);
}
void erase(string word) {
int p = 0;
for(int i=0; i<word.size();++i)
{
int u = word[i] - 'a';
p = Tree[p].next[u];
}
Tree[p].val--;
return;
}
private:
struct Node
{
int val;
int next[26];
Node():val(0),next{0}{};
};
constexpr static int M=40000;
Node Tree[M];
int idx = 0;
int ans = 0;
int traverse(int p)
{
int ans = 0;
if(p==0) return ans;
if(Tree[p].val!=0) ans+=Tree[p].val;
for(int i=0;i<26;++i) ans += traverse(Tree[p].next[i]);
return ans;
}
};
力扣211 添加与搜索单词–涉及“递归”地根据key找节点(.通配符)
毕竟涉及了通配符,就是要开始遍历尝试的节奏,因此这里要学会递归的模板基础!其步骤如下:
1、首先递归有三个输入变量:a、查找的词 b、下一次递归的节点 c、a中下一个字的索引。(这里注意一下,学会控制输入变量!以《力扣676.实现一个魔法字典》为例,如果说允许字符串出现N个不同的情况,那么就可以再加一个变量,每次26个字母递归的时候,如果与字符串的字母与递归进去字母不用时,减去这个变量即可!千万别想着定义全局,递归好多种情况,都会重复减这个的,除非你用回溯那套)
2、首先确立好basecase,即上面输入变量c若是超过a的长度,那么就返回其值。
3、分类讨论即可,若不是“。”就正常递归进去。若是“。”那么就遍历所有可能的情况,进行往下遍历。
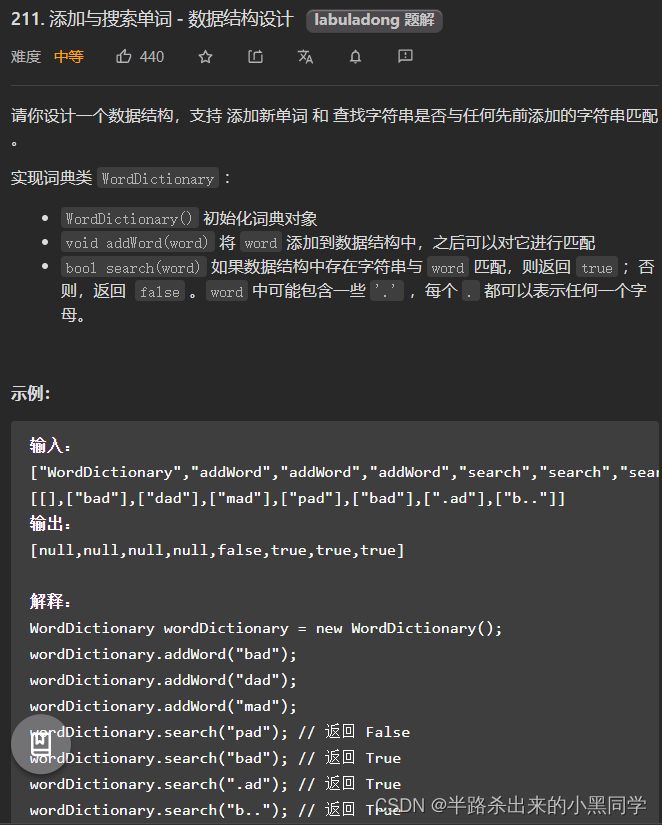
class WordDictionary {
public:
WordDictionary() {
}
void addWord(string word) {
int p = 0;
for(int i = 0;i<word.size();++i)
{
int u = word[i] - 'a';
if(Tree[p].next[u] == 0) Tree[p].next[u] = ++idx;
p = Tree[p].next[u];
}
Tree[p].is_word = true;
}
bool search(string word) {
return dfs(word,0,0);//就是这里!!
}
private:
struct Node{
bool is_word;
int next[26];
Node():is_word(false),next{0}{};
};
constexpr static int M = 500000;
Node Tree[M];
int idx = 0;
bool dfs(string word,int start, int index)
{
int p = start;
//basecase。当超过序列长度直接返回没毛病!
if(index == word.size()) return Tree[p].is_word;
//其实下面两个一样的,只不过为。的时候,选择十分多罢了。
if(word[index]=='.')
{
for(int i=0;i<26;++i)
{
if(Tree[p].next[i] != 0 && dfs(word, Tree[p].next[i], index + 1)) return true;
}
}
else
{
int u = word[index] - 'a';
if(Tree[p].next[u] != 0 && dfs(word, Tree[p].next[u], index + 1)) return true;
}
return false;
}
};
力扣648 单词替换–涉及最短前缀
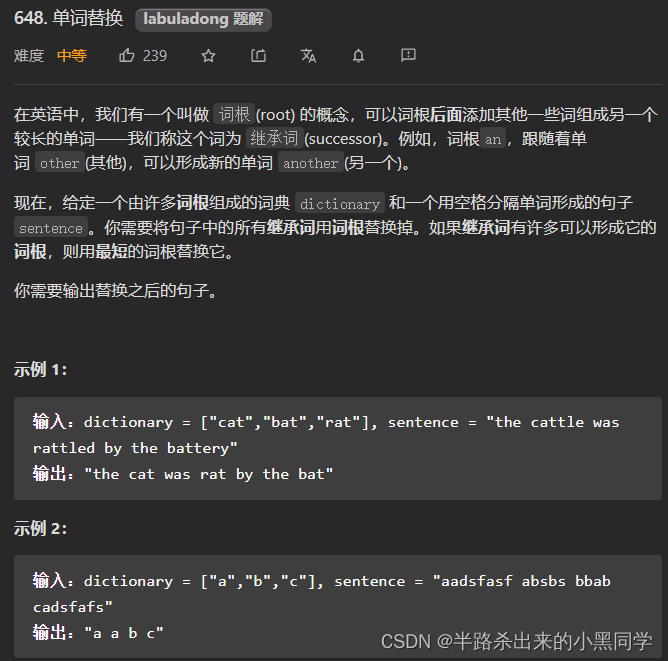
class Solution {
public:
string replaceWords(vector<string>& dictionary, string sentence) {
int start = 0;
//插入线段树
for(auto word:dictionary)
{
insert(word);
}
//找最短前缀并修改
string ans;
int n = sentence.size();
for(int i=0;i<n;++i)
{
if(sentence[i] == ' ' || i == n-1)
{
if(i==n-1) ++i;
string change = find_minl(sentence.substr(start,i-start));
if(change!="") ans += change;
else ans += sentence.substr(start,i-start);
//加空格
if(i!=n)ans+=" ";
start = i+1;
}
}
return ans;
}
private:
struct Node{
bool is_word;
int next[26];
Node():is_word(false),next{0}{};
};
constexpr static int M = 50000;
Node Tree[M];
int idx = 0;
void insert(string word)
{
int p = 0;
for(int i=0;i<word.size();++i)
{
int u = word[i] - 'a';
if(Tree[p].next[u] == 0) Tree[p].next[u] = ++idx;
p = Tree[p].next[u];
}
Tree[p].is_word = true;
}
string find_minl(string word)
{
int p = 0;
for(int i=0;i<word.size();++i)
{
int u = word[i] - 'a';
if(Tree[p].is_word) return word.substr(0,i);
if(Tree[p].next[u] == 0) return "";
p = Tree[p].next[u];
}
if(Tree[p].is_word) return word;
return "";
}
};
力扣745 前缀和后缀搜索—涉及后缀怎么办?
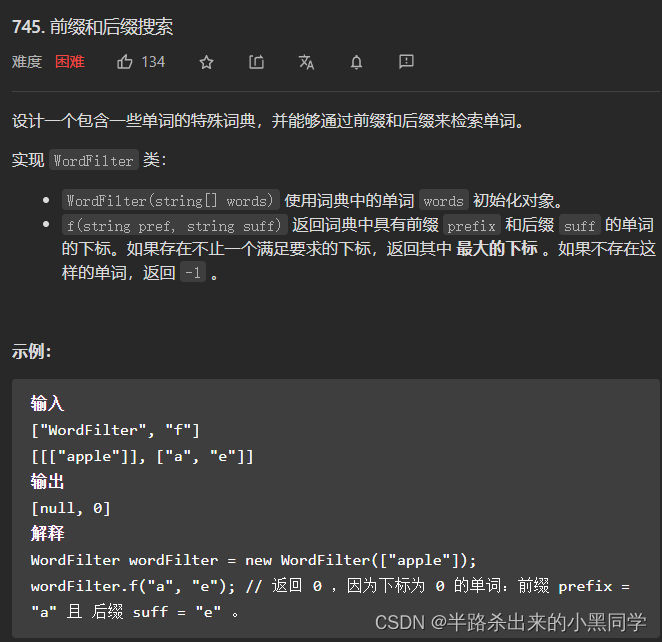
【题解】
本题其实就是搜寻前缀+…+后缀的一个字符串,而中间的内容可以省略。因此本题有两个方法:
【前缀树+后缀树+双指针】首先说结果,本题会TLE(关键看看下一个《后缀+‘#’+前缀》的方法,对于前后缀思考还挺有意义的),但是其可以返回前后缀单词的所有下标,具体步骤就是:
- 将Node结构中的val换成index数组,进行下标的记录。
- 正常单词放入前缀树,单词翻转后放入后缀树。
- 随后查前缀和查反转后的后缀即可,得到的两个index数组,进行双指针找到最大下标(只要从小到大的插入下标,其index数组也一定是从小到大的顺序,push_back嘛)
代码如下:
class WordFilter {
public:
WordFilter(vector<string>& words) {
int n = words.size();
for (int i=0; i<n; i++)
{
string word = words[i];
insert_pre(word, i);
reverse(word.begin(),word.end());
insert_later(word, i);
}
}
int f(string pref, string suff) {
vector<int> index1 = query_pre(pref);
if(index1.empty()) return -1;
reverse(suff.begin(),suff.end());
vector<int> index2 = query_later(suff);
int i = index1.size()-1,j = index2.size()-1;
while(i>=0 && j>=0)
{
if(index1[i] == index2[j]) return index1[i];
else if (index1[i] > index2[j]) i--;
else j--;
}
return -1;
}
private:
struct Node{
int next[26];
vector<int> index;
Node():next{0}{};
};
const static int M = 25000;
Node Tree_pre[M];
Node Tree_later[M];
int idx1 = 0;
int idx2 = 0;
void insert_pre(string &word, int index)
{
int p = 0;
for(int i=0; i<word.size(); i++)
{
int u = word[i] - 'a';
if(Tree_pre[p].next[u] == 0) Tree_pre[p].next[u] = ++idx1;
p = Tree_pre[p].next[u];
Tree_pre[p].index.push_back(index);
}
}
void insert_later(string &word, int index)
{
int p = 0;
for(int i=0; i<word.size(); i++)
{
int u = word[i] - 'a';
if(Tree_later[p].next[u] == 0) Tree_later[p].next[u] = ++idx2;
p = Tree_later[p].next[u];
Tree_later[p].index.push_back(index);
}
}
vector<int> query_pre(string &word)
{
int p = 0;
for(int i=0; i<word.size(); i++)
{
int u = word[i] - 'a';
if(Tree_pre[p].next[u] == 0) return {};
p = Tree_pre[p].next[u];
}
return Tree_pre[p].index;
}
vector<int> query_later(string &word)
{
int p = 0;
for(int i=0; i<word.size(); i++)
{
int u = word[i] - 'a';
if(Tree_later[p].next[u] == 0) return {};
p = Tree_later[p].next[u];
}
return Tree_later[p].index;
}
};
【后缀+‘#’+前缀】由于前缀+…+后缀,我们是不好找到…省略哪些内容的,因此不妨反转一下思考,我们可以通过存放后缀+前缀+…以此达到找到字符串的目的,通过一个前缀树来无视掉包含…的过程。为了区分前缀和后缀,需要后缀加个’#'号再加前缀。因此以abcd为例,其有以下后缀+前缀的组合方法:
d#abcd
cd#abcd
bcd#abcd
abcd#abcd
看到这里,可能有一些疑问,难道前缀一定是abcd吗,其实并不是,abcd是前缀+…的内容只不过我们并不需要关心…是什么。因为我们在查找的过程中,知道后缀,也知道前缀,因此便可能通过这两个信息来找到后缀+前缀的节点位置,那个位置正好存放着整个字符串的下标(也正是因此,在插入时,需要对路上的每个节点都赋下标值),那么就够了!因为这样,即便插入时,后面的也出现相同的前缀后缀,那么同一个位置的下标值将被改为最新的,也就是题目要求最大的,很完美。
class WordFilter {
public:
WordFilter(vector<string>& words) {
for (int i=0;i<words.size();++i)
{
string tem("#"+words[i]);
for(int j=words[i].size()-1; j>=0; --j)
{
tem = words[i][j] + tem;
insert(tem, i);
}
}
}
int f(string pref, string suff) {
return query(suff + '#' + pref);
}
private:
struct Node{
int next[27];
int val;
Node():next{0},val(-1){};
};
const static int M = 500000;
Node Tree[M];
int idx = 0;
void insert(string &word, int index)
{
int p = 0;
for(int i=0; i<word.size(); i++)
{
//注意处理前后缀分割的标记
int u = word[i] == '#'?26:(word[i] - 'a');
if(Tree[p].next[u] == 0) Tree[p].next[u] = ++idx;
p = Tree[p].next[u];
//反正只需要返回最大的标号,因此注意调用插入时,下标从小到大覆盖即可
Tree[p].val = index;
}
}
int query(string word)
{
int p = 0;
for(int i=0; i<word.size(); i++)
{
int u = word[i] == '#'?26:(word[i] - 'a');
if(Tree[p].next[u] == 0) return -1;
p = Tree[p].next[u];
}
return Tree[p].val;
}
};
总结
其实有了树的基础就好理解本文的代码了,本文为了实现一次性new完,特意将节点的形式改为了数组,注意M的取值小心MLE即可。其实如果没有TLE的限制,写成树的节点形式更好理解,如果真的不理解本文code,建议看看力扣上宫水三叶大佬的文章。最后,其实在查看本文的时候,最重要的是理解原理后,“背过”《数据结构》以及《模板的基础》(注意最后一个应用题中,递归来遍历的方法)两个部分,其他的理解看看即可,其实都是粘贴复制模板的基础进行修改。
PS:如果上文的map和set把你搞晕了,可以直接就记map,毕竟set就是val=1或0的map,可以直接这么记!














 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









