









创建线程的四种方式
1.继承Thread类
class MyThread extends Thread{
@Override
public void run() {
System.out.println("Thread");
}
}
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyThread());
t.start();
}
}
2.继承Runable接口
class MyThread extends Thread{
@Override
public void run() {
System.out.println("Thread");
}
}
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyThread());
t.start();
}
}
3.匿名内部类实现
public class Test4 {
public static void main(String[] args) {
Thread t = new Thread(()->{
while (true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
while (true){
System.out.println("hello main ");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
4.线程池创建
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test3 {
public static void main(String[] args) {
//创建固定个数的线程池
ExecutorService service = Executors.newFixedThreadPool(10);
for(int i =0;i<2;i++){
//执行任务
service.execute(new Runnable() {
@Override
public void run() {
System.out.println("线程名:" +Thread.currentThread().getName());
//说明是使用线程池来创建线程
}
});
}
}
}
这里的线程池创建其实也挺奇怪,其实原理几乎都是调用Runnable对象的run方法。
线程的生命周期
1.调用new方法新建一个线程,此时的线程处于新建状态。
2.调用start之后的线程,就处于可以运行的状态,可运行状态又分为就绪(Ready)和运行中(Running)。
处于就绪状态的线程通过某种竞争手段获取到CPU资源,线程就会调用run方法到运行状态。如果想中断该线程使用yield方法
会使其失去资源。再次进去就绪状态。
3.处于运行状态的线程在执行sleep方法,I\O阻塞,等待同步锁,会进入阻塞状态。阻塞状态由于时间到了,i\o方法返回,会再次进入可运行状态,等待CPU时间片的访问。
4.线程在调用Object.wait(),Object.join()后会进入等待状态,等待线程调用Object.notify(),后再次进入可执行状态。
5.处于可运行状态的线程调用Thread.sleep(long),Object.wait(long)后会进入超时等待状态,等待时间到了或者调用Object.notify()会再次进入可运行状态。
6.处于可运行状态的线程,调用run方法或call方法正常执行完成(或线程抛出一个Error),调用stop退出,会进入终止状态。
这里的阻塞和等待状态容易混淆,
阻塞就是在运行状态下的线程主动或者释放资源(CPU的使用权),因为有可能混入优先级不是非常高的一些资源,需要释放让优先级高的上。
等待状态,处于等待状态的线程会等待另一个线程执行指定的操作。
中断线程的方式
1、可以手动的设置一个标志位(自己创建一个变量,boolean 和 int 类型都行),来控制线程是否要执行的结果。
public class Test5 {
private static boolean isQuit = false;
public static void main(String[] args) {
Thread t = new Thread(()->{
while (!isQuit){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程终止");
isQuit=true;
}
}
2.使用 Thread 中内置的一个标志位来进行判断来进行判定(比第一种方式要好得多)
这时候,我们就需要使用 第二种方法:使用 Thread 中内置的一个标志位来进行判断来进行判定:
1、Thread.interrupted(); 【这是一个静态方法】
2、Thread currentThread().isInterrupted() 【这是一个实例方法,其中 currentThread 能够获取当前线程的实例】
推荐使用第二种方法!!
public class Test6 {
public static void main(String[] args) {
Thread t = new Thread(()->{
while (!Thread.currentThread().isInterrupted()){
System.out.println("Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
System.out.println("结束");
break;
}
}
});
t.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程结束");
t.interrupt();
}
}
常见的线程池?参数?运行流程?
第一个表格是常用的五种线程池
| newCachedThreadPool | 可缓存的线程池 |
|---|---|
| newFixedThreadPool | 固定大小的线程池 |
| newScheduledThreadPool | 可做任务调度的线程池 |
| newSingleExector | 单个线程的线程池 |
| newWorkStealingPool | 使用ForkJoinPool实现的线程池 |
第二个表格是线程池常用的一些参数
| corePoolSize | 线程池中核心线程的数量 |
|---|---|
| maximumPoolSize | 线程池中最大的线程数量 |
| keepAliveTime | 当前线程数量超过corePoolSize时,空闲线程的存活时间 |
| unit | keepAliveTime的时间单位 |
| workQueue | 任务队列,被提交但尚未执行的任务存放的地方 |
| threadFactor | 线程工厂,用于创建线程,可以使用默认的线程工厂或自定义线程工厂 |
| handler | 由于任务过多或者其他原因导致线程池无法处理时的任务拒绝策略 |
线程池的工作流程:
线程池刚刚被创建的时候,只是向系统申请一个用于执行线程队列和管理线程池的线程资源。在调用execute()添加任务后,线程池会按照如下进行任务的创建。
1.如果正在运行的线程数量少于corePoolSize,线程池会立马创建线程并执行该任务。
2.如果正在运行的线程数量大于或等于corePoolSize,该任务将被放入阻塞队列中。
3.在阻塞队列已满且正在运行的线程数少于maximumPoolSize时,线程池会创建非核心线程并立马执行该线程任务。
4.在阻塞队列已满且正在运行的线程数量大于或等于maximumPoolSize时,线程池将拒绝执行并且抛出RejectExecutionException异常。
5.在线程任务执行完毕后,该任务将被从线程池队列中移除,线程池从队列中取下一个线程继续执行。
6.在线程处于空闲的时间超过keepAliveTime时间时,正在运行的线程的数量超过corePoolSize,该线程将会被认定为空闲线程并停止。因此线程池中的所有线程执行完毕后,线程池会收缩到corePoolSize大小。
线程不安全的类
ArrayList
LinkedList
HashMap
TreeMap
HashSet
TreeSet
StringBuilder
优点:快,但是不支持高并发。
线程安全的类
Vector (不推荐使用)
HashTable (不推荐使用)
ConcurrentHashMap
StringBuffer
String(它没有 synchronized。内部是final定义的字符数组)
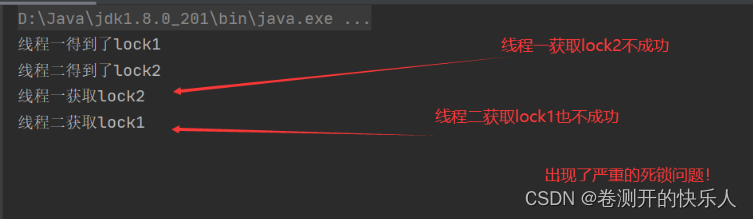
死锁实现的代码
创建两个线程同时进行获取锁的操作分别让各自的到一个锁,然后尝试获取再获取下一个锁会发现获取不成功。
public class main {
public static void main(String[] args) {
Object lock1 = new Object();
Object lock2 = new Object();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock1){
System.out.println("线程一得到了lock1");
try{
Thread.sleep(1000);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println("线程一获取lock2");
synchronized (lock2){
System.out.println("线程一得到了lock2");
}
}
}
});
thread1.start();
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock2){
System.out.println("线程二得到了lock2");
try {
Thread.sleep(1000);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println("线程二获取lock1");
synchronized (lock1){
System.out.println("线程二得到了lock1");
}
}
}
});
thread2.start();
}
}
数据中的锁
1.乐观锁:
默认别人在每次读取的时候不会修数据,所以不会加锁。
使用方法:
是读取到当前版本然后加锁,判断当前版本,和上个版本是否一致,如果一致,就更新,如果不一致,就重复读,写操作。
JAVA中的乐观锁大多数都是通过思想(CAS)比较和交换。
2.悲观锁:
默认别人在每次读取的时候修改数据,直接加锁,这样别人就会被阻塞知道重新获取到锁。
这样别人想读取时就会阻塞,等待直到获取到锁。
使用方法:
先用乐观锁的方式获取锁,如果获取不到就会转换成悲观锁。
3.自旋锁:
如果获取到锁的线程可以很快的释放锁,线程会排在获取到锁的线程后面等一等,等上一个线程释放出来锁,这样就避免了线程在用户态和内核态的转换中资源的浪费。
优点:没有用户态到内核态之间的转换,减少了不必要的消耗。
缺点:自旋竞争过于激烈或者,线程占用锁的时间过长会导致大量线程处于自旋状态。
4.可重入锁:
这里的可重入锁,就是指可以递归的锁。据说,防止程序员手欠上俩锁。
5.公平锁和非公平锁:
公平锁:指在分配锁前检查是否有线程排队等待,优先把锁给排队时间长的线程。
非公平锁:就是锁不考虑排队情况,直接获取锁。
6.重量级锁和轻量级锁:
重量级锁是基于操作系统的互斥量实现的锁,会导致进程在用户态与内核态之间转换,开销比较大。
轻量锁是在没有多线程竞争的前提下,减小锁的重量级锁的使用以提高体统性能。如果同时有多个线程访问会膨胀成重量级锁。
7.共享锁和独占锁:
独占锁:每次只允许应该线程持有该锁。
共享锁:允许多个线程同时获取该锁,并发访问共享资源。
volatile和synchronized的区别
1.volatile可以保证内存可见性,和防止指令重排序,但是volatile不能满足非原子性的操作,当我们使用了非原子的i++(如果i++多的话,操作就会直接被省略,此时使用synchronized才不会省略)。
2.volatile仅能使用在 变量 级别,synchronized则可以使用在变量、方法、和类级别的。(volatile修饰的俗称volatile变量)
3. volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
类的加载机制(static关键字啥时候被加载的)
1加载:加载指的是JVM读取Class文件。并根据Class文件描述创建java.lang.class对象的过程,
将需要加载的Class文件加载到运行时的方法区,在堆中创建java.lang.class对象,并封装类在方法去的数据结构,读取时可以通过JAR包,WAR包读取。
2验证:确保当前的Class符合当前虚拟机的需求,保障虚拟机的自身安全,只有通过验证的Class文件才能被JVM加载。
1.文件格式验证
2.元数据验证
3.字节码验证:通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的。
4.符号引用验证:确保解析动作能正确执行。
3准备:在方法区中为变量分配空间并设置类的初始值。非final的静态变量在准备阶段的初始值是0,赋值是初始化的时候进行的,如果加上final的变量会直接在准备阶段被赋值。
4.JVM
JVM会将常量池中的引用符号替换为直接应用。
5.初始化
主要通过执行类构造器的方法将类初始化。
什么是分布式缓存
当用户需要频繁的访问一些基本数据,比如用户信息,系统字典信息等热数据时,为了加快系统访问速度,往往会选择把数据缓存再内存中,这样用户再次访问数据时,直接从内存中获取数据即可。
优点:减少了数据库的负载,缩短了系统的访问时间。
热数据:是需要被计算节点频繁访问的在线类数据。
冷数据:是对于离线类不经常访问的数据,比如企业备份数据、业务与操作日志数据、话单与统计数据。
流程:
客户端 写请求 --》服务端 写数据库 --》写缓存
客户端 读请求–》服务端 读缓存–》写数据库
Servlet与Spring的区别
1.不需要配置Tomcat,Spring Boot内置了Web容器。
2.快速添加外部jar包。
3.快速发布项目。
4.对象自动装配。
spring的步骤
1.创建Spring项目
创建Maven项目–》添加 Spring 框架支持(spring-context、spring-beans)–》添加启动类
2.储存Bean对象
创建Bean–》将Bean注册到容器
3.获取到Bean对象
得到Spring上下文对象,对象都将给,Spring管理了,所以获取对象,要从Spring中获取,那么就要先得到Spring中的上下文。
通过Spring上下文,获取某一个指定的Bean对象。
使用Bean对象。
ApplicationContext VS BeanFactory
继承关系和功能方面来说:Spring 容器有两个顶级的接口:BeanFactory 和 ApplicationContext。
其中 BeanFactory 提供了基础的访问容器的能力,而 ApplicationContext 属于 BeanFactory 的子
类,它除了继承了 BeanFactory 的所有功能之外,它还拥有独特的特性,还添加了对国际化支持、
资源访问支持、以及事件传播等方面的支持。
从性能方面来说:ApplicationContext 是一次性加载并初始化所有的 Bean 对象,而 BeanFactory
是需要那个才去加载那个,因此更加轻量。
添加注解存储Bean对象
要想将对象存储在Spring中,有两种注解类型可以实现。
@Autowired和@Resource有什么区别

@Autowired如果想使用属性的话需要加入熟悉的注解@Qualifier
















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











