






Flink 大并发任务(超过 500 并发)在使用 keyBy 或者 rebalance 的情况下,将 bufferTimeout 设置为 1s 可以节省 30~50% 的 CPU 消耗。中等并发任务也会有不少收益。
Flink在处理网络传输时,通过 NetworkBuffer来实现攒批,权衡吞吐和延迟的关系。Flink 1.10 及以后的版本直接通过配置参数 execution.buffer-timeout: 100ms 可以设置,Flink 1.10 之前通过代码 env.setBufferTimeout(100)设置 。当设置为 0 时表示没有 timeout 策略,即:每条数据来了都认为 buffer 满了,将这一条数据单独发送给下游。保障了实时性,但吞吐可能会下降。要想吞吐不下降,就需要消耗更多的资源。100ms 是 Flink 权衡过的 timeout 默认值,既能保证吞吐,又能保障延迟控制在 100ms 以内。
1、 Flink 如何权衡吞吐与延迟的关系
TM 是真正处理数据的进程,上游 Task 1 的输出做为下游 Task 2 的输入,必然会产生 shuffle,也就是网络间数据交换。如果 Task1 每处理一条数据就通过网络发送一条数据给 Task2,显然数据传输效率比较低。为了提高吞吐,Flink 设计了 NetworkBuffer 来实现攒批。即:Task1的每个 subtask 内部都会缓存一批数据再发送给下游 Task2。
1.1 网络传输 buffer 实现原理
假设一个任务有两个 Task,分别是 TaskA 和 TaskB,TaskA 的并行度为 2,TaskB 的并行度为 3,且 TaskA 和 TaskB 之间的连接方式是 keyBy。总共有 2 * 3 = 6 个连接。
上游每个 subtask 中会有 3 个 resultSubPartition,连接下游算子的 3 个 subtask。下游每个 subtask 中会有 2 个 InputChannel,连接上游算子的 2 个 subtask。一个个彩色的小圆圈就是一个个 buffer,buffer 生成以后,就可以发送到下游 TaskB。
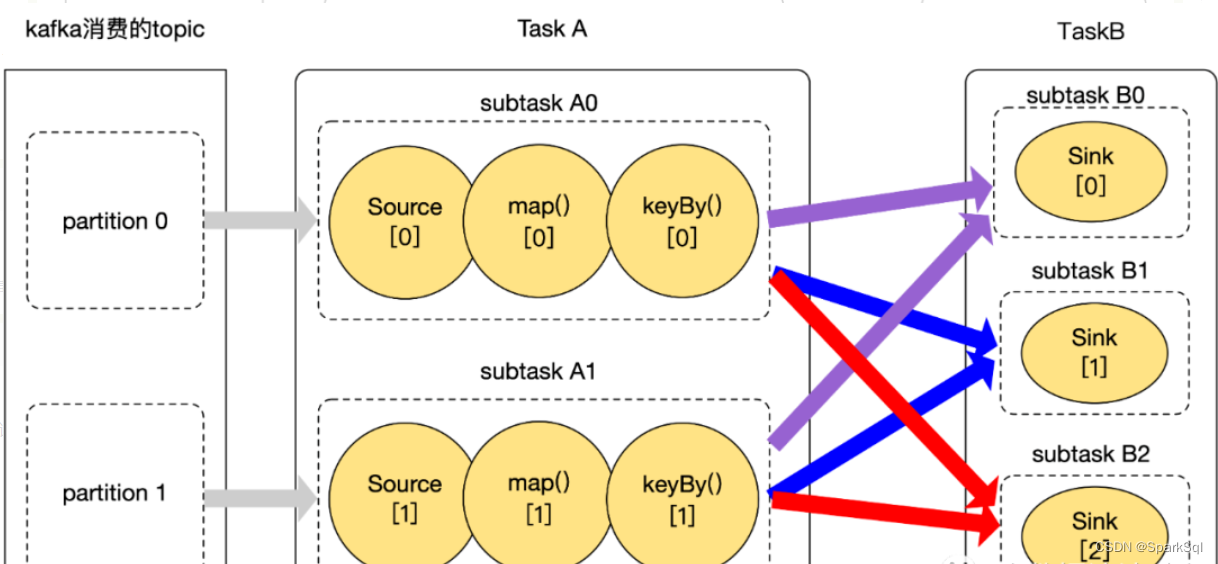
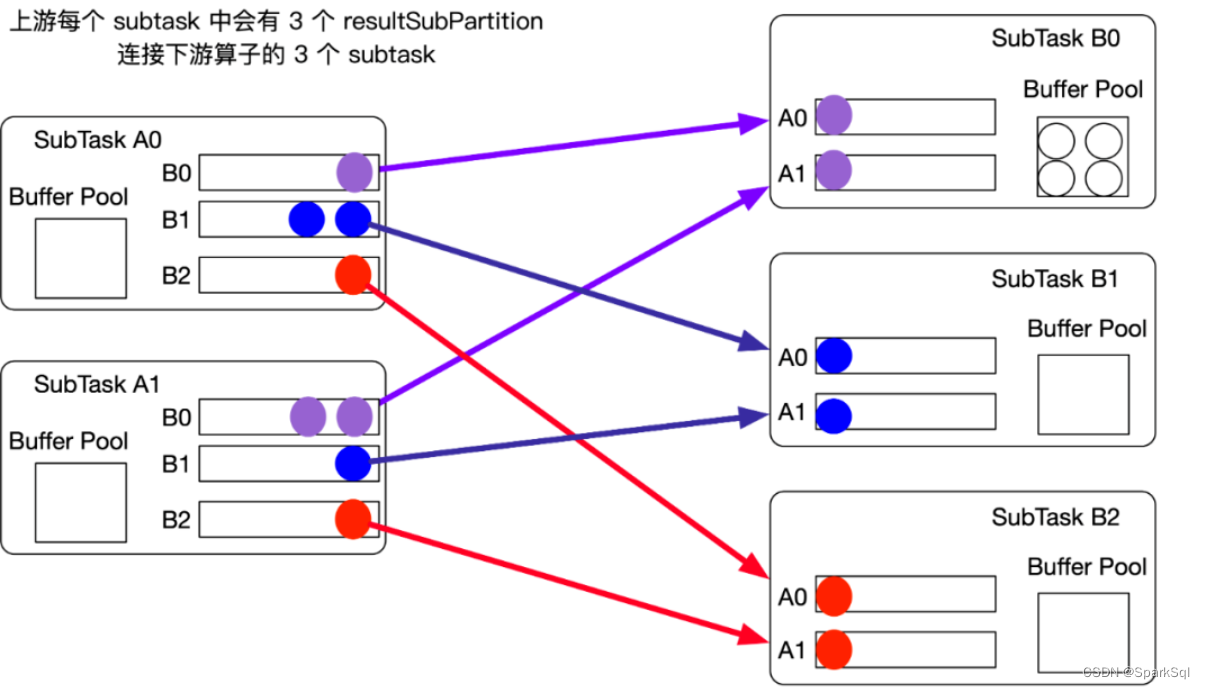
Note:Subtask 中 buffer 生成好以后,会被 Netty 消费,由 Netty Server 负责将数据发送给下游 Subtask B。SubtaskB 的 Netty Client 将接收到的 buffer 写到 InputChannel 中,下游的 Subtask 就可以开始反序列化处理数据了。
1.2 生成 buffer 的规则
Netty Server 会消费 SubtaskA resultSubPartition 产生的 buffer 数据,那 NettyServer 什么时候能消费到 buffer 呢?
正在写入的 buffer 肯定不能被 Netty 消费到,只有写完的 buffer 才能被消费到。在 Flink 中有三种情况会认为 buffer 写完了,可以被 Netty Server 消费:
-
buffer 写满了
-
buffer 超时了
-
遇到特殊的 Event,例如:Checkpoint barrier
默认 buffer 大小是 32KB,如果 32KB 写满就认为当前 buffer 写完了,可以将当前 buffer 发送到下游 Task,也就是条件1。
如果低峰期数据量比较小,1 分钟也没有将 32KB 的 buffer 写满,那么数据将一直缓存在 buffer 中,从而导致大量的延迟。为了解决数据延迟的问题,Flink 增加了一个时间策略,默认是 100ms。如果 100ms buffer 还没写满,为了保障数据的实时性,也认为 buffer 写完了,可以将当前 buffer 发送到下游 Task,也就是条件 2。
遇到一些特殊的事件,例如遇到 Checkpoint barrier,为了加快 Checkpoint 效率,会直接认为 buffer 写完了,可以将当前 buffer 发送到下游 Task,也就是条件 3。
当然条件 2 的 100ms 是可以调节的,Flink 1.10 及以后的版本直接通过配置参数 execution.buffer-timeout: 100ms 可以设置,Flink 1.10 之前通过代码 env.setBufferTimeout(100); 可以设置。
1.3 小结
Flink 通过 buffer-timeout 参数对吞吐和延迟做权衡,当设置为 0 时表示没有 timeout 策略,即:每条数据来了都认为 buffer 满了,将这一条数据单独发送给下游。保障了实时性,但吞吐可能会下降。要想吞吐不下降,就需要消耗更多的资源。
100ms 是 Flink 权衡过的 timeout 默认值,既能保证吞吐,又能保障延迟控制在 100ms 以内。
2、 大并发任务为什么会消耗更多的 CPU?
假设 TaskA 有 1000 个并发,下游 TaskB 也有1000 个并发,意味着 SubtaskA0 总共有 1000 个 resultSubPartition,分别对应 SubtaskB0、B1 ... B999。如下所示是 SubtaskA0 的 resultSubPartition 图,其他的 SubtaskA1、A2 ... A999 也是同样的图示,图中可以看到 SubtaskA0 中会有 1000 个 resultSubPartition。
2.1大并发情况,每个 buffer 中会缓存多少条数据?
buffer 是为了缓存一批数据,批量发送,提高效率。如果是大并发情况,到底每个 buffer 会缓存多少条数据做为一个批次呢?
默认 bufferTimeout = 100ms 意味着 100ms 必须将 buffer 中的数据发送到下游 Task。假设 SubtaskA0 每秒处理 1 万条数据,则 100ms 平均处理 10000 / 10 = 1000 条数据。这 1000 条数据要发送给 1000 个 resultSubPartition,所以平均一个 resultSubPartition 中只会有 1 条数据,每个 resultSubPartition 有自己独立的 buffer,也就是说每个 buffer 其实只缓存了 1 条数据。跟没有 buffer 没什么区别。。。
如果 TaskB 的并发为 2000,则 SubtaskA0 内部会有 2000 个 resultSubPartition。100ms 产生 1000 条数据,则只有 1000 个 resultSubPartition 中有数据,仍然是 100ms 发送 1000个 buffer 给下游 TaskB,每个 buffer 中只有 1 条数据。
2.2 大并发任务消耗 CPU 小结
生产环境很多任务的并发远大于 1000,所以造成很多 buffer 仅仅只缓存 1 条数据就被 timeout 策略触发发送给下游 Task。每条数据做为 1 个 buffer,每秒处理 1 万条数据,则后台线程每秒需要 flush 1 万个 buffer 到 NettyServer,从而大量消耗 CPU。
不仅是发送方效率降低,下游的 Subtask B 接受数据的效率也会降低。每秒接受 1 万的 buffer,每个 buffer 里 1 条数据。大量的小 buffer,大量的读取小数据,消耗大量的 CPU 资源.
2.3 小并发任务会存在 buffer 攒批效果不好的问题吗?
假设 TaskA 和 Task B 的并发是 50,SubtaskA 对应 50 个 resultSubPartition。每秒产生 1 万条数据,则 100ms 需要会处理 1000 条数据,平均每个 resultSubPartition 能攒 1000 / 50 = 20 条数据。相对而言攒批效果还算可以。
如果单条消息比较大,可能 20 条数据早就将 buffer 占满了,buffer 如果占满会直接发送到下游 Task,无需等待 timeout 超时才发送。















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









