







在第10节,我们实现了单Reactor模式,这是已经比较完善的了。但是也还可能会有问题。
单Reactor模式中,也就是单个EventLoop,它需要管理建立连接的,也需要管理与客户端进行通信的,当IO压力比较大的时候,响应就可能不会这么及时。
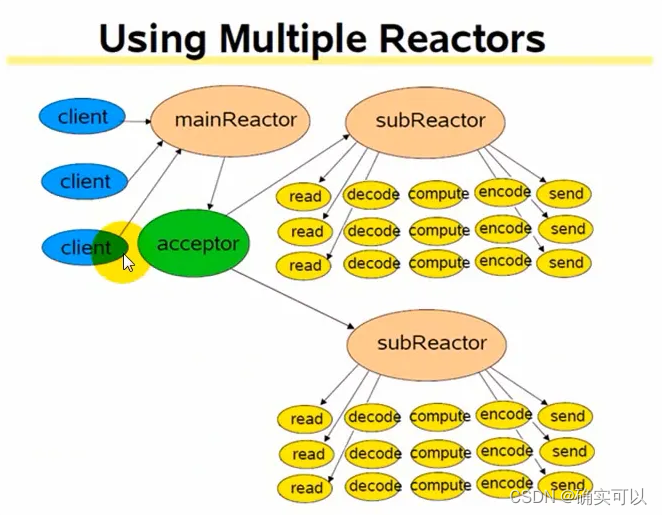
我们可以使用多个Reactor,一个主Reactor就负责与客户端建立连接的,其他的从Reactor就负责与客户端通信的。
这分工明确,IO的压力也会分担开来,更能适应高性能的需求。其结构可以用下图来表示。
我们还需要添加几个关于线程的类 。
1.EventLoopThread类
该类主要是封装了EventLoop和Thread,方便我们的使用。
class EventLoopThread
{
public:
EventLoopThread();
~EventLoopThread();
EventLoop* startLoop(); //启动IO线程函数中的loop循环, 返回IO线程中创建的EventLoop对象地址(栈空间)
private:
void threadFunc(); // IO线程函数
EventLoop* loop_; // 绑定的EventLoop对象指针
std::thread thread_; //线程, 用于实现IO线程中的线程功能
std::mutex mutex_;
std::condition_variable cond_;
};成员变量thread_是开始loop()的线程。
EventLoopThread::EventLoopThread()
:loop_(nullptr)
{}
EventLoopThread::~EventLoopThread()
{
if (loop_) {
loop_->quit();
}
if (thread_.joinable())
thread_.join();
}
EventLoop* EventLoopThread::startLoop()
{
thread_ = std::thread([this]() {threadFunc(); });
{
std::unique_lock<std::mutex> lock(mutex_);
while (loop_ == nullptr) {
cond_.wait(lock);
}
}
return loop_;
}
IO线程函数主要工作:创建EventLoop局部对象, 运行loop循环。
void EventLoopThread::threadFunc()
{
EventLoop loop;
{
std::lock_guard<std::mutex> lock(mutex_);
loop_ = &loop;
cond_.notify_one();
}
loop.loop();
std::lock_guard<std::mutex> lock(mutex_);
loop_ = nullptr;
}这里主要的流程是,先调用startLoop()函数,在其内部会新创建IO线程thread_,执行IO线程函数threadFunc(),最终通过startLoop()返回该EventLoop对象指针loop_。
这里可能会有疑惑:为什么这里的的EventLoop对象指针loop_,需要互斥锁保护呢。
在startLoop()函数中,thread_线程开启了,那这时就有两个线程在执行了(一个是执行startLoop()的线程,一个是执行threadFunc()的子线程),这两个线程可能会存在同时读写loop_的情况,所以需要互斥锁来保护。
还有一个疑问:IO线程函数threadFunc()最后为什么要清除loop_?
因为loop_可能在其他地方访问,而IO线程函数退出时,线程已经不能继续运行,代表IO线程EventLoop的loop_也就没有了存在意义。如果不清空,析构函数可能会导致重复调用loop_->quit(),让IO线程loop循环重复退出。
2.EventLoopThreadPool类
这是事件循环线程池类,内部所有的线程都是EventLoopThread。该类也是为了我们的使用方便的。
class EventLoopThreadPool
{
public:
EventLoopThreadPool(EventLoop* base);
~EventLoopThreadPool()
{ // Don't delete loop, it's stack variable }
void setThreadNum(int numThreads) { numThreads_ = numThreads; }
void start();
EventLoop* getNextLoop() //只是简单地循环取用
{
EventLoop* loop = baseLoop_;
if (!loops_.empty()) {
loop = loops_[next_];
next_ = (next_ + 1) % numThreads_;
}
return loop;
}
bool start()const { return started_; }
private:
EventLoop* baseLoop_; // 与Acceptor所属EventLoop相同
bool started_;
int numThreads_;
int next_; //新连接到来,所选择的EventLoopThread下标
std::vector<std::unique_ptr<EventLoopThread>> threads_;// IO线程列表
std::vector<EventLoop*> loops_; //EventLoop列表, 指向的是EventLoopThread线程函数创建的EventLoop对象
};从getNextLoop()函数可知为什么需要有成员变量baseLoop_。因为有可能该线程池是空的,那也要放回一个EventLoop的嘛,所需就需要使用Acceptor所属EventLoop。
这里也解答一个疑惑:baseLoop_明明是也是指针,那为什么不用智能指针管理呢。
因为这个baseLoop_是在main()函数中传递进来的,是使用该库去编程程序的用户创建的,可能在main()函数中写EventLoop loop;那这就是栈上的变量,当离开作用域时,栈变量会自动释放。所以不需要用智能指针管理。
同样也还有为什么该析构函数不delete数组loops_中的元素呢,这就要想清楚,通过EventLoopThread::threadFunc()创建的是局部的栈上的EventLoop变量,当离开该线程作用域时,栈变量会自动释放。所以Don't delete loop。
start() 启动IO线程池
创建用户指定线程组,启动线程组线程,并记录子线程对应EventLoop;
void EventLoopThreadPool::start()
{
started_ = true;
for (int i = 0; i < numThreads_; ++i) {
auto t = std::make_unique<EventLoopThread>();
threads_.push_back(std::move(t)); // 将EventLoopThread对象指针放入threads_数组
loops_.push_back(t->startLoop()); // 启动IO线程,并将线程函数创建的EventLoop对象地址 插入loops_数组
}
}3.结合EventLoop::runInLoop()和EventLoopThreadPool实现主从Reactor模型
那就要来看看最上层的类Server,在该类中添加成员
public:
void start(int IOThreadNum=0,int ComputeThreadNum=0);
private:
// 在对应的loop中移除,不会发生多线程的错误
void removeConnectionInLoop(const ConnectionPtr& conn);
std::unique_ptr<EventLoopThreadPool> threadPool_;
std::atomic_int32_t started_;首先添加成员变量threadPool_,还有要修改下start()函数,要是只使用单Reactor模式,就直接使用server.start()即可,如要使用多Reactor模式,就使用server.start(4),4是开启IO线程的数量,如要使用线程池的进行计算的线程,也是这样类似的操作。
来看看Server::start()函数实现
if (started_++ == 0) //防止一个Server对象被启动多次
{
threadPool_->setThreadNum(IOThreadNum);
threadPool_->start();
acceptor_->listen();
}主Reactor是我们Accepor所属的EventLoop,即是在主线程创建的EventLoop。
那从Reactor如何使用。这就需要改动下Server::newConnection()了。accept一个新客户端后,就把该客户端sockfd给到IO线程池的IO线程中,即是在创建Connecion中使用ioLoop,见代码。
void Server::newConnection(int sockfd, const InetAddr& peerAddr)
{
//轮循,选择一个subLoop
EventLoop* ioLoop = threadPool_->getNextLoop();
InetAddr localAddr(sockets::getLocalAddr(sockfd));
//auto conn = std::make_shared<Connection>(loop_, sockfd, localAddr,peerAddr);
//把loop_ 换成 ioLoop
auto conn = std::make_shared<Connection>(ioLoop, sockfd, localAddr,peerAddr);
connections_[sockfd] = conn;
//其他代码省略.......
//conn->connectEstablished(); //建立连接
//改成下面的, 转移到该IO线程来调用connectEstablished()
ioLoop->runInLoop([conn]() {conn->connectEstablished(); });
//可以使用引用吗?????
//ioLoop->runInLoop([&conn]() {conn->connectEstablished(); });
}这里留个疑问:最后代码那可以使用引用吗(&conn),留到下一节讲解智能指针的引用计数的变化再详细来说哈,读者也可以先思考下哈。
connectEstablished()让该ioLoop线程去调用。(connectEstablished()内部会调用用户定义的ConnectionCallback)
connectEstablished()这个函数的执行要放到它所属的那个事件驱动循环线程做,不要阻塞TcpServer线程(这个地方不是为了线程安全性考虑,因为Connection本身就是在Server线程创建的,暴露给Server线程很正常,而且Server中也记录着所有创建的Connection,这里的主要目的是不阻塞Server线程,让它继续监听客户端请求)
one loop per thread。每个线程只有一个循环,在每个线程内也只能操控一个loop,不能操控其他线程内的loop。在该loop的操作就只能在该loop中执行,不能在其他loop中执行。
那么连接的销毁也需要转移到该ioloop线程中。来看看原来的Server::removeConnection()。
void Server::removeConnection(const ConnectionPtr& conn)
{
auto n = connections_.erase(conn->fd()); //在Server类中
conn->connectDestroyed();
}Connection销毁时,会在其ioLoop线程调用removeConnection()函数,而其内部的connections_.erase(conn->fd()) 是在主Reactor线程的Server类成员connections_,那就需要转移到Server所在的线程(就是主线程,也就是主Reactor所在的线程)去执行,为了线程安全,不然就可能同时有两个线程去修改同一变量。
可以把原来的removeConnection()函数拆成两个函数。
void Server::removeConnection(const ConnectionPtr& conn)
{
loop_->runInLoop([this,conn]() {removeConnectionInLoop(conn); });
//以前的实现
//auto n = connections_.erase(conn->fd()); //在Server类中
//conn->connectDestroyed();
}
// 在对应的loop中移除,不会发生多线程的错误
void Server::removeConnectionInLoop(const ConnectionPtr& conn)
{
auto n = connections_.erase(conn->fd());
auto ioLoop = conn->getLoop();
//这里使用queuInLoop()比较好
ioLoop->queueInLoop([conn]() {conn->connectDestroyed(); });
}疑惑来了哈:为啥在removeConnectionInLoop中不是直接使用runInLoop()呢?
先来看看EventLoop::loop函数中的框架(简化后的):
void EventLoop::loop()
{
//执行channel的回调
for(....){
activeChannel[i]->handleEvent();
}
//执行当前EventLoop事件循环需要处理的回调任务操作
doPendingFunctors();
}直接使用queueInLoop() 就是说即使就是在该loop_所在的线程,也一定要把回调函数放置在任务队列中,等到所有的channel[i]->handleEvent()结束后才会执行doPendingFunctors函数(也即是执行任务回调函数)。
首先要知道connectDestroyed函数会析构Connection类对象,那该对象内部的Channel对象也会进行析构。
而在第十节中有说到Connection对象和handleEvent()函数这两者的生命周期的关系。
若是调用runInLoop()函数,就有可能直接执行cb(),那就是在activeChannel[i]->handleEvent();中执行cb(),即是connectDestroyed函数了呢。
这问题就来了哈。此时Channel正在调用handleEvent()去删除Connection对象,那么该Connection对象成员channel_ 也会被析构,那就会产生core dump错误。所以要让Connection对象生命周期要长于handleEvent()函数,就一定要把connectDestroyed放在doPendingFunctors()中去执行。
明白EventLoop::loop()的流程框架就好懂了。
继续说回函数转移到该IO线程的事情哈。
这样把removeConnectionInLoop()函数转移到Server的loop_线程,是为了可以在Server的主线程进行erase该connection。
接着再把connectDestroyed()转移到Connection的ioLoop线程执行,是为了保证Connection的用户设置的ConnectionCallback始终在该ioLoop执行的。(要牢记one loop per thread的含义)
总而言之,Server和Connection的代码都只处理单线程的情况(甚至都没有mutex成员),而我们借助EventLoop::runInLoop()函数并引入了EventLoopThreadPool,这样很容易地实现了多线程Server。注意ioLoop和主loop_间的线程切换都是发生在连接建立和断开的时刻,这不会影响正常业务的性能。
接着还有两处地方还需要使用runInLoop()的。
void Connection::shutdown()
{
if (state_ == StateE::kConnected) {
setState(StateE::kDisconnecting);
//以前是直接调用的,现在使用runInLoop()函数去调用
loop_->runInLoop([this]() {
if (!channel_->isWrite())
sockets::shutdownWrite(fd()); // 关闭写端
});
}
}
void Connection::forceClose()
{
if (state_ == StateE::kConnected || state_ == StateE::kDisconnecting){
setState(StateE::kDisconnecting);
//handleClose();
//现在调用queueInLoop(),为什么使用queueInLoop(),而不使用runInLoop()的原因
//和之前的调用connectDestroyed是差不多一个原因的。
loop_->queueInLoop([this]() { shared_from_this()->forceCloseInLoop(); });
}
}
void Connection::forceCloseInLoop()
{
if (state_ == StateE::kConnected || state_ == StateE::kDisconnecting){
setState(StateE::kDisconnecting);
handleClose();
}
}Connection::forceClose()中为什么使用shared_from_this()呢,这样可以让其引用计数加1,延长其生命期,让其在执行该函数过程中,保证该connetion对象是存活的。具体的有关其引用指数的使用情况会在下一节详细介绍。
这一节在Epoll类有需要修改的。之前的考虑不全面,Epoll::updateChannel函数和Epoll::del函数是需要修改的。Epoll::del函数需要先判断该channel是否已被epoll监听的,具体的可查看源代码。不修改这些,这节多线程的主从Reactor模式就不能很好的实现。
到这里,我们的主从Reactor模式就可以了。
完整源代码:https://github.com/liwook/CPPServer/tree/main/code/server_v13















 4140
4140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









