







目录
1. 读取数据的入口函数readQueryFromClient
2. 命令执行的入口函数processInputBuffer
5. 数据发送给客户端的时刻 和 注册客户端写事件处理器的时机
1. postponeClientRead把待读client加入到server.clients_pending_read
2. 把server.clients_pending_read中的client分发给子线程
我们知道redis 是单线程的,但是严格意义来说只有 命令处理部分 是单线程,redis 的网络读取命令和解析、发送客户端数据是多线程的。所以,Redis 的命令处理部分 是单线程,整个redis 内部是多线程。
1. Redis命令执行部分为什么使用单线程
- 抛开持久化不说,那Redis是纯内存操作的,其执行速度是极快的,所以其性能瓶颈不是cpu执行速度,而是网络延迟。因此,多线程并不会带来巨大的性能提升。
- 而多线程会导致过多的上下文切换,可能会带来不必要的开销。
- 引入多线程会面临线程安全问题,那就会引入线程互斥锁等这样的安全处理手段,实现复杂度就会增高,性能也可能会大打折扣。
2. 单线程下,Redis如何实现高性能的?
除了是操作内存极快,剩下就要归功于IO多路复用了。IO多路复用是利用单个线程来同时监听多个文件描述符,并在某个文件描述符可读、可写时得到唤醒,从而避免无效的等待,减少线程之间的切换所带来的开销,充分利用CPU资源,。
Redis提供多种不同的多路复用实现,并且将这些实现进行了封装,提供了统一的API。linux中是使用epoll,该文章讲解的也是使用epoll实现的多路复用。

reactor模型
Redis的网络框架是reactor模型的。若是不太了解reactor模型的实现,这里推荐下本人写的0.仿造muduo,实现linux服务器开发思路
该文章专栏编写了个cppServer程序,实现了reactor模型,有很详细的章节解说。
需要了解reactor模型,才能较好地明白Redis的网络框架。
本文章不会讲解Redis中关于网络部分的结构体,主要是讲解器网络的交互流程。
3. 单线程部分
从main()开始着手。在main()函数中,目前主要关注两个函数initServer,aeMain。
int main(int argc, char **argv) {
initServer(); //初始化服务
..................
InitServerLast(); //调用initThreadedIO(),初始化多线程
aeMain(server.el); //开始事件循环
return 0;
}函数initServer
其是做一些对Redis服务的初始化。
- 先调用aeCreateEventLoop去创建epoll红黑树,之后创建服务端fd,并将该fd注册到epoll红黑树上进行监听。
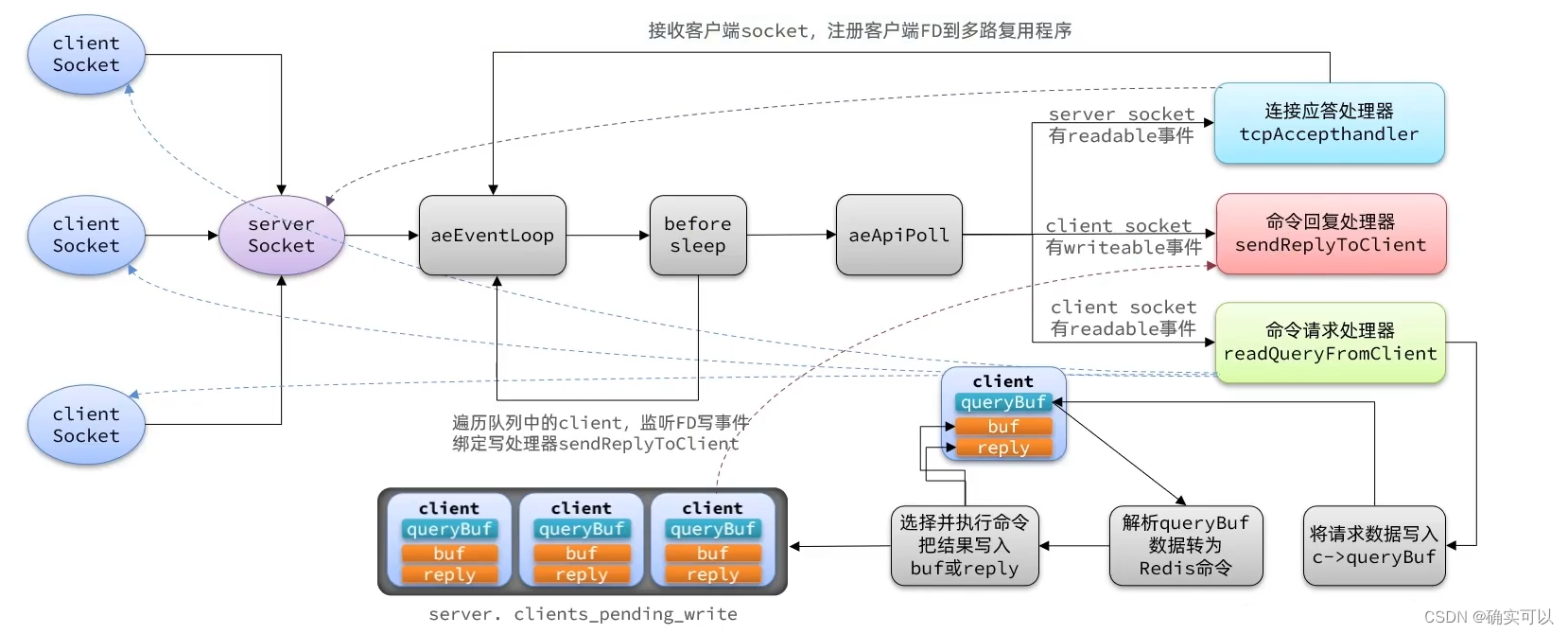
- 注册acceptTcpHandler连接应答处理器给服务端fd。当有新客户来连接,acceptTcpHandler被调用,其通过accpet得到客户端fd,并将readQueryFromClient命令读取处理器绑定到新连接对应的fd上。(即是客户端可读就绪的话,则readQueryFromClient被调用进行处理)。
readQueryFromClient是如何注册给客户端的,讲解acceptTcpHandler的时候会讲到的。
void initServer(void) {
//内部会调用 aeApiCreate(eventLoop),就类似epoll_crate
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
.............
//监听tcp端口,创建serverSocket,得到服务器端的fd
listenToPort(server.tls_port,&server.tlsfd)
//注册回调函数, 当有客户连接时,内部会调用函数acceptTcpHandler
//该函数是调用accept,之后再调用aeApiAddEvent(&server.ipfd)来监听新连接的客户端fd
createSocketAcceptHandler(&server.ipfd, acceptTcpHandler)
//注册调用ae_api_poll前的回调函数,即是在执行epoll_wait前,会执行函数beforeSleep
aeSetBeforeSleepProc(server.el,beforeSleep);
..........................
}先跳过函数beforeSleep的内容,当前只需知道其是在每次epoll_wait前先执行的即可。
函数aeMain
其是开始事件循环。前面已经设置好回调函数,那在返回就绪fd时:
- 若是服务端fd读就绪,就会调用acceptTcpHandler
- 若是客户端fd读就绪,那就执行readQueryFromClient
- 若是客户端fd写就绪,就执行sendReplyToClient
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
aeProcessEvents(eventLoop, AE_ALL_EVENTS | AE_CALL_BEFORE_SLEEP|
AE_CALL_AFTER_SLEEP);
}
}
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
....................
//执行之前设置的回调函数,即是会在epoll_wait执行前的beforSleep
if (eventLoop->beforesleep != NULL && flags & AE_CALL_BEFORE_SLEEP)
eventLoop->beforesleep(eventLoop);
//等待fd就绪,并返回就绪的fd,就是调用epoll_wait
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
//遍历所有就绪的fd,调用其对应的回调函数
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int fired = 0; /* Number of events fired for current fd. */
if (!invert && fe->mask & mask & AE_READABLE) { //读事件就绪
fe->rfileProc(eventLoop,fd,fe->clientData,mask); //调用对应的读回调
fired++;
fe = &eventLoop->events[fd]; /* Refresh in case of resize. */
}
/* Fire the writable event. */
if (fe->mask & mask & AE_WRITABLE) { //写事件就绪
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->wfileProc(eventLoop,fd,fe->clientData,mask); //调用对应的写回调
fired++;
}
}
}
...................
}服务端可读,执行acceptTcpHandler
该函数不仅建立新连接(新cleint),也将readQueryFromClient命令读取处理器绑定到新连接对应的fd上。
注册客户端的命令读取处理器readQueryFromClient的流程:acceptTcpHandler--->acceptCommonHandler--->createClient--->connSetReadHandler--->readQueryFromClient。
#define MAX_ACCEPTS_PER_CALL 1000
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
while(max--) { //每次最多处理1000条连接
//其就是调用accpet
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
.............
acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip);
}
}
static void acceptCommonHandler(connection *conn, int flags, char *ip) {
client *c;
.......................................
/* Create connection and client */ //客户端的连接打包成为一个客户端,创建client对象
c = createClient(conn)
.............................
}
client *createClient(connection *conn) {
client *c = zmalloc(sizeof(client));
if (conn) {
....................
connSetReadHandler(conn, readQueryFromClient); //注册客户端的读事件回调函数
//当客户端有事件到来时会调用readQueryFromClient这个函数
}
...............................
if (conn) linkClient(c); //把该客户端添加到服务器server.client链表中保存
return c;
}客户端可读,执行readQueryFromClient
1. 读取数据的入口函数readQueryFromClient
读取到的数据是保存到结构体client的querybuf中的,其是sds类型变量。
void readQueryFromClient(connection *conn) {
//获取当前客户端,客户端中有缓冲区用来读和写
client *c = connGetPrivateData(conn);
............
//开启IO多线程优化,这里就先不展开讲解,(先讲解单线程的)
if (postponeClientRead(c)) return;
.............................
//读取请求数据到 c->querybuf 缓冲区中
nread = connRead(c->conn, c->querybuf+qblen, readlen);
//解析缓冲区字符串,
processInputBuffer(c);
}2. 命令执行的入口函数processInputBuffer
processInputBuffer会根据Redis协议解析客户端请求:
- 若客户端的请求类型是
PROTO_REQ_INLINE,调用processInlineBuffer()函数解析命令 - 若是
PROTO_REQ_MULTIBULK时,调用processMultibulkBuffer()函数进行处理
将客户的命令相关参数转换为Redis命令参数存入c->argv数组和c->arge中,并调用processCommandAndResetClient处理命令。
Redis 客户端有两种请求类型:
PROTO_REQ_INLINE内联请求:通常为 telnet 等测试工具的请求类型,请求直接以普通文本形式发送。PROTO_REQ_MULTIBULK多批量请求:表示 Redis 官方客户端的请求类型,请求会通过 RESP 协议进行封装。该类型数据包的开头都为 * 字符,这也是Redis判断请求类型的依据。
void processInputBuffer(client *c) {
//循环,直到处理完读取缓冲区中的数据
while(c->qb_pos < sdslen(c->querybuf)) {
....................................
//根据Redis 客户端的请求类型,调用不同函数解析请求命令
if (c->reqtype == PROTO_REQ_INLINE) {
if (processInlineBuffer(c) != C_OK) break;
if (server.gopher_enabled && !server.io_threads_do_reads &&
((c->argc == 1 && ((char*)(c->argv[0]->ptr))[0] == '/') ||
c->argc == 0)){
processGopherRequest(c);
resetClient(c);
c->flags |= CLIENT_CLOSE_AFTER_REPLY;
break;
}
} else if (c->reqtype == PROTO_REQ_MULTIBULK) {
if (processMultibulkBuffer(c) != C_OK) break;
}
//如果启用了I/0线程,则跳出循环先不处理,就不执行命令
if (c->flags & CLIENT_PENDING_READ) { //这个是开启多线程后需要看的,单线程可以先跳过
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
//否则先执行命令,再重置客户端
if (processCommandAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid exiting this
* loop and trimming the client buffer later. So we return
* ASAP in that case. */
return;
}
}
}
int processCommandAndResetClient(client *c) {
....................
if (processCommand(c) == C_OK) {
commandProcessed(c); // 执行成功后,做一些收尾工作
}
..............
}
int processCommand(client *c) {
//根据命令名称,寻找该命令对应的Command,例如:函数setCommand 就对应命令set name jack
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
.........................
//执行命令
//断当前客户端是否有 CLIENT_MULTI 标记,如果有的话,就表明要处理的是 Redis 事务的相关命令,
//所以它会按照事务的要求,调用 queueMultiCommand 函数将命令入队保存,等待后续一起处理。
//而如果没有,processCommand 函数就会调用 call 函数来实际执行命令了。
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand &&
c->cmd->proc != resetCommand)
{
// 将命令入队保存,后续一起处理
queueMultiCommand(c);
addReply(c,shared.queued);
} else {
call(c,CMD_CALL_FULL); //真正执行命令的函数
...............................
}
return C_OK;
}processInputBuffer内部是循环调用processCommandAndResetClient。所以这样认为,processInputBuffer会执行client的所有命令,而processCommandAndResetClient是只执行一条命令就返回的。
3. 执行命令
真正执行命令的函数就是call。
/* Call() is the core of Redis execution of a command.*/
void call(client *c, int flags) { //执行命令的核心函数
//执行命令,比如是调用函数setCommand
c->cmd->proc(c);
...........................
}Redis中的命令都是独立封装的,每个命令及对应的处理函数注册保存在 redisCommandTable 数组中的。
//server.c
//这是个命令数组,pingCommand是函数
struct redisCommand redisCommandTable[] = {
....
{"ping",pingCommand,-1,
"ok-stale fast @connection",
0,NULL,0,0,0,0,0,0},
........
}假设前面通过解析,发现是ping命令,执行c->cmd->proc(c)即是 执行pingCommand。
/* The PING command. It works in a different way if the client is in Pub/Sub mode. */
void pingCommand(client *c) {
//省略了发布订阅模式的回复格式,还有一些校验......................
if (c->argc == 1)
addReply(c,shared.pong); //把执行结果写出。
else
addReplyBulk(c,c->argv[1]);
}4. 执行结果返回给客户端
每个命令在处理完后,都会有addReplyXXXX类似的方法调用。其实这就是Redis在向客户端返回执行结果。但是,并不是直接发送给客户端,而是将响应结果保存在客户端的response buf中。那先简单看下结构体client的定义。
// src/server.c
#define PROTO_REPLY_CHUNK_BYTES (16*1024) /* 16k output buffer */
typedef struct client {
...
connection *conn;
sds querybuf; // 从客户端读取的数据保存在querybuf中
int argc; // 命令参数的个数 3
robj **argv; // 命令的具体参数 set "msg" "hello world"
...
uint64_t flags; /* Client flags: CLIENT_* macros. *///标识,读写
list *reply; /* List of reply objects to send to the client. */
...
/* Response buffer */
int bufpos;
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;/* Add the object 'obj' string representation to the client output buffer. */
void addReply(client *c, robj *obj) {
//该函数会把c存放到server.clients_pending_write,这样函数beforeSleep执行时候,就从中获得待写的客户进行回写
if (prepareClientToWrite(c) != C_OK) return;
if (sdsEncodedObject(obj)) { //字符串编码类型
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK) //写到client的缓冲区c->buf中
_addReplyProtoToList(c,obj->ptr,sdslen(obj->ptr)); //如果c->buf写不下,则写到c->reply中,这是个链表,容量无上限
} else if (obj->encoding == OBJ_ENCODING_INT) { //整数类型
char buf[32];
size_t len = ll2string(buf,sizeof(buf),(long)obj->ptr);
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK) //写到client的缓冲区中
_addReplyProtoToList(c,obj->ptr,sdslen(obj->ptr)); //如果c->buf写不下,则写到c->reply中,这是个链表,容量无上限
}
}_addReplyToBuffer 是将回复数据保存到client对象的输出缓冲区c->buf,_addReplyProtoToList 是保存到输出链表c->reply。而前者的优先级更高,一般是存在c->buf中是足够的了。
5. 数据发送给客户端的时刻 和 注册客户端写事件处理器的时机
从前面可以看到Redis执行完命令后,只是把回复给客户端的数据存储到缓冲区中,没有直接发出去。
那么它是什么时候发送给客户端呢?就是上面说的在调用beforeSleep中发送出去的。在beforeSleep中遍历server.clients_pending_write链表去获得待写的客户端进行回写。
而也是在这时刻去注册客户端读事件处理器sendReplyToClient的。
void beforeSleep(struct aeEventLoop *eventLoop) {
.......................
///* Handle writes with pending output buffers. */
//将客户端分发到每个线程的队列当中只不过是写事情
handleClientsWithPendingWritesUsingThreads();
......................
}
int handleClientsWithPendingWritesUsingThreads(void) {
................................
// 如果没有开启io多线程写,或者待处理的客户端数量较少时,直接由主线程执行写操作
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
..................................
}
int handleClientsWithPendingWrites(void) {
.........................
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) { //遍历链表
client *c = listNodeValue(ln); //得到cleint
c->flags &= ~CLIENT_PENDING_WRITE;
/* Try to write buffers to the client socket. */
//给客户端发送数据
if (writeToClient(c,0) == C_ERR) continue;
if (clientHasPendingReplies(c)) { //表示还有数据在缓冲区待写,一次写不完
int ae_barrier = 0;
//注册写事件处理器
connSetWriteHandlerWithBarrier(c->conn, sendReplyToClient, ae_barrier)
}
}
}而client对象是什么时候被加入到server.clients_pending_write链表的呢?
是在addReply中设置的。该函数开头调用 prepareClientToWrite,进而调用到 clientInstallWriteHandler,将待写客户端加入到全局变量 server 的clients_pending_write列表。
void addReply(client *c, robj *obj) {
//该函数会把c存放到server.clients_pending_write,这样函数beforeSleep执行时候,就从中获得待写的客户进行回写
if (prepareClientToWrite(c) != C_OK) return;
................................
}
int prepareClientToWrite(client *c) {
.............................
if (!clientHasPendingReplies(c) && !(c->flags & CLIENT_PENDING_READ))
clientInstallWriteHandler(c);
/* Authorize the caller to queue in the output buffer of this client. */
return C_OK;
}
void clientInstallWriteHandler(client *c) {
if (!(c->flags & CLIENT_PENDING_WRITE) &&
(c->replstate == REPL_STATE_NONE ||
(c->replstate == SLAVE_STATE_ONLINE && !c->repl_put_online_on_ack)))
{
c->flags |= CLIENT_PENDING_WRITE; //设置标志位并且将client加入到 clients_pending_write 队列中
//添加 c 到链表server.clients_pending_write头部
listAddNodeHead(server.clients_pending_write,c);
}
}客户端可写,执行sendReplyToClient
该函数主要分成两步骤:
- 通过函数connWrite发送数据给客户端socket
- 若是数据发送完毕后,就把写回调函数置空,即写事件就不就绪
/* Write event handler. Just send data to the client. */
void sendReplyToClient(connection *conn) {
client *c = connGetPrivateData(conn);
writeToClient(c,1);
}
int writeToClient(client *c, int handler_installed) {
ssize_t nwritten = 0, totwritten = 0;
clientReplyBlock *o;
//1. 通过write写数据给客户端
while(clientHasPendingReplies(c)) { //表示缓冲区还留有数据
if (c->bufpos > 0) { //回写给客户端的数据是存在 c->buf 中的情况
//该函数就是调用write
nwritten = connWrite(c->conn,c->buf+c->sentlen,c->bufpos-c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
if ((int)c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
} else { //回写给客户端的数据存在c->reply链表中的情况
o = listNodeValue(listFirst(c->reply)); //获取链表的头结点
objlen = o->used;
//write回写给客户端
nwritten = connWrite(c->conn, o->buf + c->sentlen, objlen - c->sentlen);
.................................
}
}
//2. 数据发送完毕后,就把写回调函数置为空
if (!clientHasPendingReplies(c)) {
//把写回调函数置为空
if (handler_installed) connSetWriteHandler(c->conn, NULL);
}
return C_OK;
}单线程网络模型
4. Redis 6.0 之后多线程网络
Redis6强调引入了多线程。那使用多线程在哪部分可以提升性能呢?
在单线程中,对于事件的派发性能是较好的,但是在对客户端数据进行读取和写入时候回收到IO网络读写的影响。
所以Redis6引入了多线程,为了提高网络IO读写效率。因此是在读取数据和解析客户端命令、写响应结果时采用了多线程,而核心的命令执行还是在主线程对每个命令逐个执行。
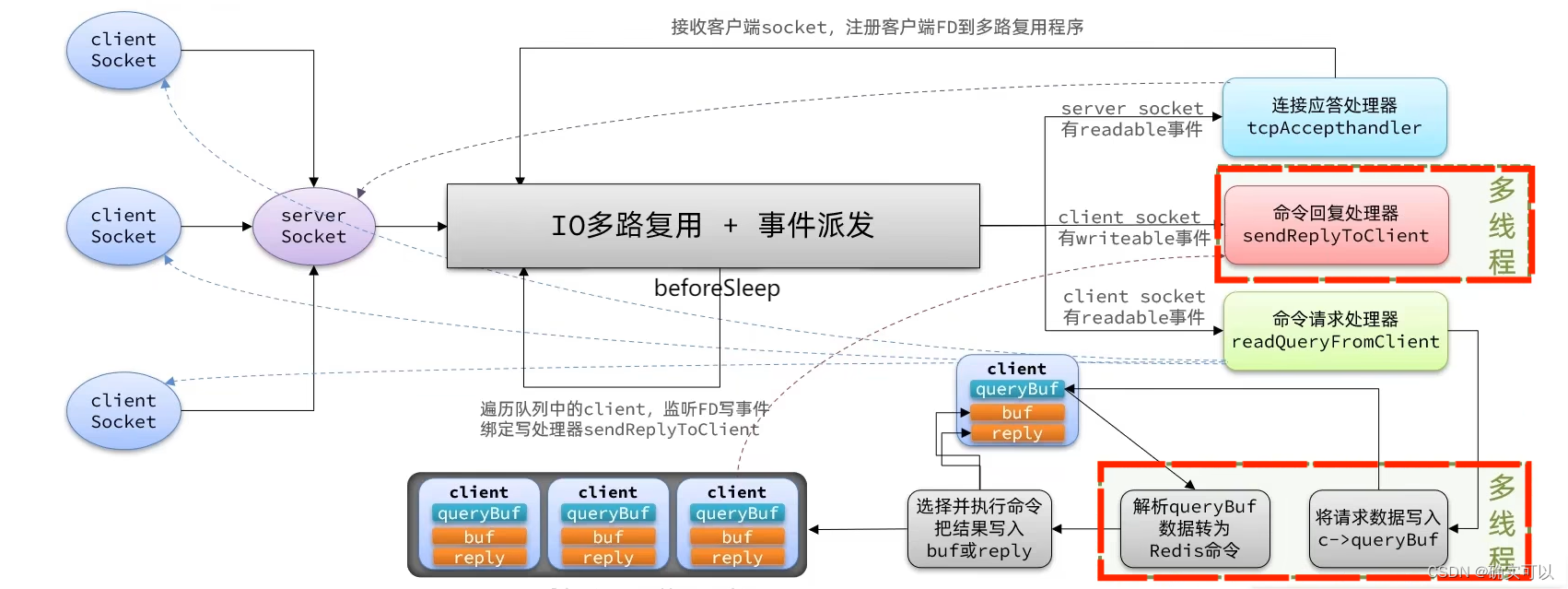
从main()函数入手
可知在启用多线程后,每个线程都有个专属自己的队列io_threads_list[id]。
int main(int argc, char **argv) {
InitServerLast(); //调用initThreadedIO(),初始化多线程
...................
}
void InitServerLast() {
initThreadedIO();
.............
}
//全局变量, Redis多线程中却不对这些变量进行加锁保护,却不会出问题,后面会讲解为什么
pthread_t io_threads[IO_THREADS_MAX_NUM];
pthread_mutex_t io_threads_mutex[IO_THREADS_MAX_NUM];
redisAtomic unsigned long io_threads_pending[IO_THREADS_MAX_NUM];
int io_threads_op; /* IO_THREADS_OP_WRITE or IO_THREADS_OP_READ. */
list *io_threads_list[IO_THREADS_MAX_NUM]; //链表数组,即是每个线程都有一个链表
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
if (server.io_threads_num == 1) return;
//初始化多个线程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate(); //创建每个线程的专属队列
if (i == 0) continue; //因为0是主线程的
/* Things we do only for the additional threads. */
pthread_t tid;
pthread_mutex_init(&io_threads_mutex[i],NULL);
setIOPendingCount(i, 0); //设置每个线程的队列长度为0,用来记录当前遗留的任务数量
// 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。
pthread_mutex_lock(&io_threads_mutex[i]);
//创建线程,线程函数是IOThreadMain
pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i)
io_threads[i] = tid;
}
}Redis 的多线程模式默认是关闭的,需要用户在 redis.conf 配置文件中开启:
io-threads 4
io-threads-do-reads yes
#io-threads-do-reads没有设置yes,那么读事件不会开启多线程的。这个可以从后面的代码看出的
客户端可读,执行readQueryFromClient
1. postponeClientRead把待读client加入到server.clients_pending_read
在以前的单线程模型下,这个方法会直接读取解析客户端命令并执行。函数postponeClientRead会判断是否开启了多线程,若是开启了多线程,会把client的flags置为待读,并将client加入到server.clients_pending_read。
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
//就是通过该函数把c存放到某个子线程的队列
if (postponeClientRead(c)) return;
//前面的符合条件,就return,后面的代码就不执行的了
......................
}
//注意: 只有c->flags标识没有被设置了CLIENT_PENDING_READ,才会被添加到队列的
int postponeClientRead(client *c) {
//当多线程模式开启、主线程没有在处理阻塞任务时,将client加入异步队列
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED)))
{
//设置客户端的flag是待读,表示该client需要被多线程处理
//后序在子线程中会在读取和解析完客户端命令后判断该标识并放弃执行命令,让主线程去执行命令
c->flags |= CLIENT_PENDING_READ;
listAddNodeHead(server.clients_pending_read,c); //加入到server.clients_pending_read
return 1;
} else {
return 0;
}
}2. 把server.clients_pending_read中的client分发给子线程
这里就需要回到在epoll_wait前执行的函数beforeSleep,其内部调用handleClientsWithPendingReadsUsingThreads。
void beforeSleep(struct aeEventLoop *eventLoop) {
................
handleClientsWithPendingReadsUsingThreads(); //将待读的client分发到每个线程的队列中
.......................
handleClientsWithPendingWritesUsingThreads(); //将待写的client分发到每个线程的队列中
......................
}
int handleClientsWithPendingReadsUsingThreads(void) {
.......................
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) { //遍历获取clients_pending_read链表中的client
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c); //往子线程的专属队列中添加该client
item_id++;
}
io_threads_op = IO_THREADS_OP_READ; //设置当前I/O操作位读取操作
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count); //设置每个子线程队列的任务个数
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙轮询,累加所有 I/O 线程的原子任务计数器,直到所有计数器的遗留任务数量都是 0,
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break; // 表示所有任务都已经执行完成,结束轮询。
}
// 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ 和 CLIENT_PENDING_COMMAND 标记
//然后,主线程(当前就是主线程)解析并执行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
//client的第一条命令已经被解析好了,直接尝试执行
if (processPendingCommandsAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
//前面已经说过了,这个函数是执行client的所有命令的,内部是个循环,循环调用processPendingCommandsAndResetClient
processInputBuffer(c); //继续解析并执行cleint命令
//命令执行完成之后,若 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
return processed;
}
//我在看源码的时候,很困惑为什么要这样写,使用processPendingCommandsAndResetClient后,又要使用processInputBuffer?为什么是两步的呢?为什么不是直接使用processInputBuffer?
//这个原因是在函数processInputBuffer中的。内部是个while循环的,循环调用processPendingCommandsAndResetClient。
//processPendingCommandsAndResetClient就是只执行一条命令的。而客户端的读缓冲区中可能有多个命令存在一起的。
//server.client_pend_read分配任务给子线程后,子线程去读取和解析,会调用readQueryFromClient,readQueryFromClient内部会调用processInputBuffer。
//processInputBuffer内部有个判断的,要是client->flags是read,就break。
//而这时client->flags已是read,所以就break,会退出循环
//那么就导致子线程只能读取到第一个命令,要是后面还有命令是读取不了的。
该函数的核心内容是:
- 遍历队列server.client_pending_read,把所有任务分配给子线程和主线程去读取和解析客户端的命令。设置io_threads_op为read,并设置子线程的任务个数。
- 主线程也需要进行读取和解析客户端命令。
- 之后主线程忙轮询等待所有子线程完成任务。
- 最后主线程遍历server.client_pending_read,执行所有client的命令
3. 执行命令后,数据发送的时刻
执行命令后,会调用addReply函数,把回复客户端的数据存到缓冲区,并把待写的client加入到server.clients_pending_write链表中。之后又回到beforeSleep函数。其会调用handleClientsWithPendingWritesUsingThreads把clients_pending_write中的client分发给 子线程,让子线程去回复客户端。
int handleClientsWithPendingWritesUsingThreads(void) {
// 现在是多线程了,这个if就不成立了
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 唤醒正在休眠的 I/O 线程(如果有的话)。
if (!server.io_threads_active) startThreadedIO();
/ 遍历队列 server.clients_pending_write,
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) { //遍历队列
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE; //去掉pending_write标识
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);// 通过 RR 轮询均匀地分配给 I/O 线程和主线程自己(编号0)。
item_id++;
}
// 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程开始工作,把写出缓冲区中的响应数据回写到客户端。
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行回复客户端的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
// 忙轮询,累加所有 I/O 线程的原子任务计数器,直到所有计数器的遗留任务数量都是 0。
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;// 表示所有任务都已经执行完成,结束轮询。
}
//最后再遍历一次clients_pending_write 队列,检查client的写出缓冲区中是否还有残留数据
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 检查 client 的写出缓冲区是否还有遗留数据
//若有,就为client注册命令回复器sendReplyToClient,等待客户端写就绪再继续把数据回写
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR){
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
}其核心内容是:
- 检查当前任务负载,若当前任务数量不足够让多线程处理,则休眠子线程并直接同步将响应客户的数据写回到客户端。
- 唤醒正在休眠的子线程(有的话).
- 遍历队列server.client_pending_write,把任务均分给子线程和主线程去将响应数据写给客户端,设置op_threads_op为write,并设置每个子线程的任务个数。让子线程去回复客户端。
- 主线程自己也会去执行回复客户端的任务。(分发任务时候也发给了主线程的队列)
- 忙轮询等待所有子线程完成任务。
- 最后再遍历server.client_pending_write,为那些还有响应数据的cleint注册回复处理器sendReplyToClient,这样可以等待客户端可写时候在事件循环中继续回写剩余的响应数据。
IOThreadMain子线程执行的函数
前面说了这么多子线程工作,那其工作内容是什么呢?
主要流程:
1.子线程启动后,会先进入忙轮询判断列表的任务数量,若是非0则表示有任务,可以开始执行任务。否则就一直忙轮询一百万次等待。
2.忙轮询结束后再查看计数器,若还是0,则尝试加本地锁。因为主线程在启动子线程之时就已经提前锁住了所有子线程的本地锁,因此子线程会进行休眠,等待主线程唤醒。
3.主线程会在每次事件循环中尝试调用startTrheadIO唤醒子线程去执行任务。若是接收到客户端请求命令,则子线程会被唤醒开始工作。子线程遍历自己的本地任务队列io_thread_list[id],根据主线程设置的io_threads_op标识去执行命令读取和解析或者回写响应数据的任务:
- 若是写操作,则调用weriteToClient,把client->buf或client->reply里的响应数据写回给客户端
- 若是读操作,则调用readQueryFromClient,读取客户端的命令,存入client->querybuf,然后调研processInputBufer去解析命令,这里最终只会解析到第一条命令,然后就结束,不会去执行命令。(为什么只会解析到第一条命令,在讲解handleClientsWithPendingReadsUsingThreads中有说到)
4.在全部任务执行完后把自己的任务个数置为0,告知主线程,自己已经完成任务。
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is
* used by the thread to just manipulate a single sub-array of clients. */
long id = (unsigned long)myid;
while(1) {
/* Wait for start */ //死循环的空转
for (int j = 0; j < 1000000; j++) {
if (getIOPendingCount(id) != 0) break; //判断自己的队列当中有没有东西
}
/* Give the main thread a chance to stop this thread. */
if (getIOPendingCount(id) == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
//如果走到了这里说明队列当中有东西了,开始从自己的队列当中处理请求
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) { //遍历队列
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) { //是写操作
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) { //是读操作
readQueryFromClient(c->conn);
}
}
listEmpty(io_threads_list[id]); //队列置空
setIOPendingCount(id, 0); //队列个数设置为0
}
}5. 多线程情况中,真正执行命令是从哪个函数开始的呢?
还是在beforeSleep函数中的handleClientsWithPendingReadsUsingThreads。
- 客户端连接后,再次开始事件循环,客户端可读,调用readQueryFromClient。该函数中的postponeClientRead判断要是该客户端的flags还没有设置CLIENT_PENDING_READ,会把该客户端加入到server的pend_read队列,并设置该客户端的flags为CLIENT_PENDING_READ。
- 第二次循环,来到beforeSleep,因为server的clients_pend_read队列有了client,就把server队列中的所有client分发给线程(主/子线程都有)。主线程也要执行读取和解析数据的任务,之后等待所有子线程执行完读取和解析数据任务。子线程读取和解析:
- 这时io_threads_op是读的,所以会调用readQueryFromClient。这时client的flags已有read,所以postponeClientRead返回失败,不会再次把client加入到队列中,之后执行后面的单线程流程。
- 在processInputBuffer函数中,也是因为该client的flags是read,这里是有判断的,若是read,就break,不执行命令,解析完就返回了。因为前面是设置了read,所以不执行命令。
- 这时所有client都被解析完了,主线程就开始执行命令。
所以说,多线程情况中,是在beforeSleep中执行命令的。主要函数流程:beforeSleep--->handleClientsWithPendingReadsUsingThreads--->processInputBuffer。
//注意: 只有c->flags标识没有被设置了CLIENT_PENDING_READ,才会被添加到队列的
int postponeClientRead(client *c) {
//当多线程模式开启、主线程没有在处理阻塞任务时,将client加入异步队列
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED)))
{
//设置客户端的flag是待读,表示该client需要被多线程处理
//后序在子线程中会在读取和解析完客户端命令后判断该标识并放弃执行命令,让主线程去执行命令
c->flags |= CLIENT_PENDING_READ;
listAddNodeHead(server.clients_pending_read,c); //加入到server.clients_pending_read
return 1;
} else {
return 0;
}
}
//该函数,client的flags有read的话,就不会执行命令
void processInputBuffer(client *c) {
/* Keep processing while there is something in the input buffer */
while(c->qb_pos < sdslen(c->querybuf)) {
....................................
// 判断 client 是否具有 CLIENT_PENDING_READ 标识,如果是处于多线程 I/O 的模式下,
//那么此前已经在 readQueryFromClient -> postponeClientRead 中为 client 打上该标识,
// 则立刻跳出循环结束,此时第一条命令已经解析完成,但是不执行命令。
if (c->flags & CLIENT_PENDING_READ) { //这个是开启多线程后需要看的,单线程可以先跳过
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
//这里是真正地处理命令的
if (processCommandAndResetClient(c) == C_ERR) {
return;
}
}
}6. 多线程不加锁的疑惑
阅读源码后,可能会有不少读者有疑惑,在Redis的多线程模式下,似乎没有对数据进行锁保护。主线程和子线程之间共享的变量有3个:io_threads_pending任务计数器、io_threads_op 读写标识器、io_threads_list线程本地任务队列。
而事实上Redis的多线程模型是全程无锁的。这个是通过原子操作和交错访问来实现的。(要结合源码来看)
- 首先,io_threads_pending是原子变量,所以不需要加锁保护(代码中其声明就是原子变量).。
- 而io_threads_op和io_threads_list这两个变量则是通过控制主线程和子线程交错访问来规避共享数据竞争问题的。(就是保证主/子线程不可能在同一时刻访问同一变量)
- 子线程启动后会通过忙轮询和锁休眠的方式等待主线程的信号,在有信号来之前,它都不会去访问自己的本地任务队列io_thread_list[id],而主线程会在分配完任务给所有子线程后,才去唤醒子线程。并且主线程在子线程执行任务过程中不会去访问子线程的队列。这就保证了主线程永远是在子线程之前访问io_thread_list并且之后不再访问,保证了交错访问。
- io_threads_op同理,主线程在唤醒子线程之前就先设置好了io_threads_op值,并在子线程运行期间不会去访问这个变量。
7. Redi多线程模型缺陷
标准的reactor模型一般使用Multi-Reactors模型。而Redis的是只使用一个reactor。
- 标准的Multi-Reactors模型,会有main-reactor和sub-reactors。主reactor就负责建立新连接,把该新连接给任一sub-reactor,这个就是分发。之后该新连接读写就绪后,就由这个sub-reactor处理。即是main-reactor负责分发,sub-reactor就负责 网络读 -> 数据解析 -> 命令执行 -> 网络写 整套流程。
- 而Redis中,子线程仅仅是读取客户端请求命令并解析,却没有真正执行命令,所有客户端命令还是需要回到主线程去执行,再由子线程发送响应数据给客户端。
从上面的分析可知,标准的reactor是每个线程都会真正去执行命令,而Redis是只有唯一一个线程去执行命令(执行命令是串行的)。
应该是为了兼容性。以前使用的数据结构都是非线程安全的。而要是多个线程都可以执行命令,那应该就需要进行加锁或者重构这些数据结构,工作量应该会比较大。
所以采用了这样的reactor模式,这样保持了原系统的兼容性(还是只有唯一一个线程执行命令),又可以利用多核提升I/O性能。
但是,其内部的多线程通信稍微过于粗暴:直接是用忙轮询的。
- 子线程通过忙轮询等待主线程分配任务给自己。
- 主线程通过忙轮询等待子线程处理完所有任务。
而通过自旋忙轮询进行等待,可能会导致 Redis 在启动的时候以及运行期间偶尔出现短暂的 CPU 空转引起的高占用率问题。















 1706
1706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









