







1. CPU密集型、I/O密集型?
博客地址:https://www.cxy96.top/
CPU密集型
- CPU密集型也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高
- 例如:压缩解压缩、加密解密、正则表达式搜索
I/O密集型
- I/O密集型指的是系统运作大部分的状况是CPU在I/O(硬盘/内存)的读/写操作,CPU占用率仍然较低。
- 文件处理程序、网络爬虫程序、读写数据库程序
2. 多种并发方式对比
多进程
- 优点:可以利用多核CPU并行运算
- 缺点:占用资源最多,可启动数目比线程少
- 适用于:CPU密集型计算
多线程
-
优点:相比进程,更轻量级,占用资源少
-
缺点:
-
相比进程:多线程只能并发执行,不能利用多CPU(GIL)
-
相比协程:启动数目有限制,占用内存资源,有线程切换开销
-
-
适用于:I/O密集型计算
多协程
- 优点:内存开销最少、启动协程数量最多
- 缺点:支持的库有限制(aiohttp vs requests)、代码实现复杂
- 适用于:I/O密集型计算 但有现成库支持的场景
3. python运行慢的原因
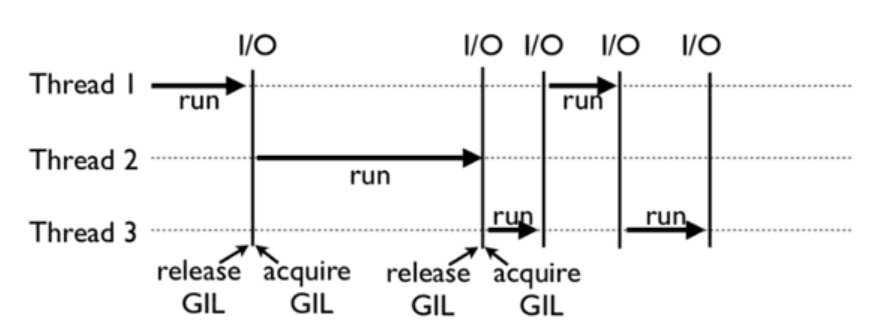
-
全局解释器锁(Global Interpreter Lock)
- 每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
- 导致了python的多线程是伪多线程,不能同时调用多个线程
-
Python是解释型语言而不是编译型语言
- 程序不需要编译,程序在运行时才翻译成机器语言,每执 行一次都要翻译一次。因此效率比较低
-
Python是一门动态类型的语言
- 运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。
4. 代码实现
多进程
-
创建进程方式
import multiprocessing # 创建一个进程 process1 = multiprocessing.Process(target=函数名,args=(参数1,)) #(参数1)是字符串 (参数1,)是元组 # 执行进程 process1.start() # 等待子进程结束,才继续执行主进程下面的代码 process1.join() -
多进程示例
import multiprocessing # 进程列表放置进程 processes = [] # 创建十个进程 for i in range(10): processes.append( multiprocessing.Process(target=函数名,args=(参数1,)) #(参数1)是字符串 (参数1,)是元组 ) # 执行线程 for process in processes: process.start() for process in processes: process.join() -
进程池
from concurrent.futures import ProcessPoolExecutor # 第一种map方法按顺序返回 max_workers 指定最大进程数 # 只能传递一个参数 with ProcessPoolExecutor(max_workers=5) as pool: results=pool.map(函数名,[线程1参数,线程2参数]) #每个参数对应一个线程 map一下子执行 返回顺序按参数顺序 for result in results: print(result) # 第二种as_completed 方法 先执行完先返回 from concurrent.futures import ProcessPoolExecutor,as_completed with ProcessPoolExecutor() as pool: futures=[pool.submit(函数名,参数) for 参数 in 参数列表] # 按顺序返回 for future in futures: print(future.result()) # 先执行完先返回 for future in as_completed(futures): print(result)
多线程
-
创建线程方式
import threading # 创建一个线程 thread1 = threading.Thread(target=函数名,args=(参数1,)) #(参数1)是字符串 (参数1,)是元组 # 执行线程 thread1.start() # 等待子线程结束,才继续执行下面的代码 thread1.join() -
多线程示例
import threading # 线程列表放置线程 threads = [] # 创建一千个线程 for i in range(1000): threads.append( threading.Thread(target=函数名,args=(参数1,)) #(参数1)是字符串 (参数1,)是元组 ) # 执行线程 for thread in threads: thread.start() for thread in threads: thread.join() -
线程池管理
优点:
- 提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源;
- 适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短
from concurrent.futures import ThreadPoolExecutor # 第一种map方法按顺序返回 max_workers 指定最大线程数 # 只能传递一个参数 with ThreadPoolExecutor(max_workers=5) as pool: results=pool.map(函数名,[线程1参数,线程2参数]) #每个参数对应一个线程 map一下子执行 返回顺序按参数顺序 for result in results: print(result) # 第二种as_completed 方法 先执行完先返回 from concurrent.futures import ThreadPoolExecutor,as_completed with ThreadPoolExecutor() as pool: futures=[pool.submit(函数名,参数) for 参数 in 参数列表] # 按顺序返回 for future in futures: print(future.result()) # 先执行完先返回 for future in as_completed(futures): print(result)
多协程
实现:
import asyncio
# 获取事件循环
loop = asyncio.get_event_loop()
# 定义协程
async def func(参数):
await func2(参数)
# 创建task列表
tasks = [loop.create_task(func(参数)) for 参数 in 参数列表]
# 执行事件列表
loop.run_until_complete(asyncio.wait(tasks))
5. 高阶应用
5.1 多组件Pipeline架构
使复杂的程序,分为多个中间步骤完成
实现:
import queue
# 1.创建Queue对象 入参 maxsize 是一个整数,如果 maxsize 设置为小于或等于零,则队列的长度没有限制。
q = queue.Queue(maxsize=0)
# 2.添加元素(空间不足时会阻塞)
q.put(item)
# 3.获取元素(没有数据时会阻塞)
item = q.get()
# 4.状态查询
# 查看元素数量
q.qsize()
# 判断是否为空
q.empty()
# 判断是否已满
q.full()
示例:
import queue
q = queue.Queue() # 创建 Queue 队列
for i in range(3):
q.put(i) # 在队列中依次插入0、1、2元素
for i in range(3):
print(q.get()) # 依次从队列中取出插入的元素,数据元素输出顺序为0、1、2
5.2 线程安全
线程安全是指某个函数、函数库在多线程环境中被调用时,能正确处理多个线程之间的共享变量,使程序功能正常完成
不安全示例:
import time
import threading
class Account:
def __init__(self,balance):
self.balance=balance
def draw(account,amount):
if account.balance>=amount:
time.sleep(0.1)
account.balance-=amount
print("取钱成功,当前账户余额:",account.balance)
else:
print("取钱失败,当前账户余额不足")
if __name__=="__main__":
account=Account(1000)
t1=threading.Thread(target=draw,args=(account,600))
t2=threading.Thread(target=draw,args=(account,600))
t1.start()
t2.start()
输出结果:
取钱成功,当前账户余额: 400
取钱成功,当前账户余额: -200
解决方式:线程锁
import threading
# 方式一:with模式
lock=threading.Lock()
with lock:
#do something
# 方式二:try-finally
lock=threading.Lock()
lock.acquire()
try:
#do something
finally:
#执行完释放锁
lock.release()
加锁后程序:
import threading
import time
lock=threading.Lock()
class Account:
def __init__(self,balance):
self.balance=balance
def draw(account,amount):
#即使切换线程但是锁没释放依然不能运行
with lock:
if account.balance>=amount:
time.sleep(0.1)
account.balance-=amount
print("取钱成功,当前账户余额:",account.balance)
else:
print("取钱失败,当前账户余额不足")
if __name__=="__main__":
account=Account(1000)
t1=threading.Thread(target=draw,args=(account,600))
t2=threading.Thread(target=draw,args=(account,600))
t1.start()
t2.start()
输出结果:
取钱成功,当前账户余额: 400
取钱失败,当前账户余额不足
















 1519
1519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











