






题主python爬虫小白一个,不仅爬虫不会,而且python的使用也不太熟练,此文的目的就是简单记录爬虫实战中的点点滴滴,完全不懂得当个教学思路,略懂得当个笑话看。无违法违规内容!
视频里的内容都是程序自己在实现,现在只要一开始按一次执行,就直接放到云服务器后台就自己执行了,每天固定时间向群里发送谁没有打卡,真的是一劳永逸捏!
项目需求:
题主的女朋友是班里监督打卡的同学,每天都需要登陆某个网站看谁没有打卡,并在微信群里提醒。为了解放女朋友,这个项目需要爬取打卡的数据网站,将每天早上的没有打卡的同学的名字提取出来,并且发送到微信群里提醒他们打卡,实现自动化处理。
过程:
分成两个部分:爬取数据+用微信发送
爬取数据:
因为题主是个小白,只是在mooc中学习了的爬虫课,掌握了这样的一个爬虫框架。只是会暴力爬取,输出了一些经过美化但是依然没有有效数据的文本。
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
return soup.prettify()
except:
return '产生异常'
if __name__=="__main__":
url=''
print(getHTMLText(url))结果类似于:
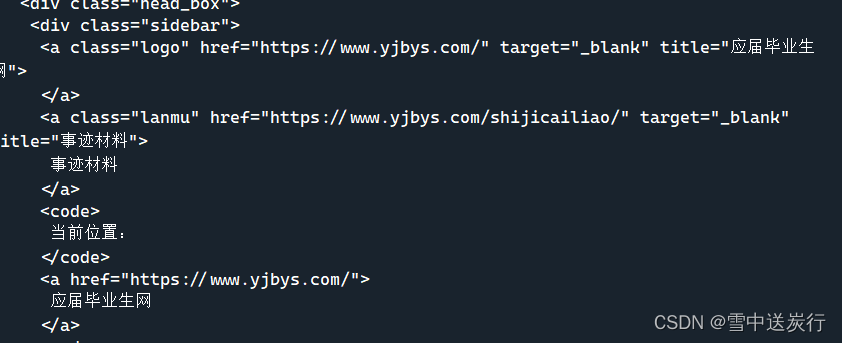
代码和有效数据往往参杂在一起,要是直接将这些东西发到群里,会很尴尬。
这时就需要提取有效数据,要到需要爬取的网站进行web分析(按F12)->找到网络里面的XHR->点重新载入->找到相关的内容->把消息头和响应头的全部内容复制到你的脚本里面。
就是下面的内容(火狐浏览器)
找到消息头里面的get (这个是我们爬取需要的链接,还有响应头headers用来反爬)这个是应对网站反爬的关键
找到响应里面的数据,根据这些数据的结构编写有效的提取过程,比如我想得到student这个字符,就要写类似于这样的:demm=demo1['rows'][i]['role]的语句。这个是获取有效数据的关键。
所以我们整个爬虫内容就变成了:
def getHTMLText(headers):
try:
url='"}'
r=requests.get(url,timeout=30,headers=headers)
demoo=r.text
demo11=json.loads(demoo)
demmm=demo11['total']
if (demmm%10!=0):
dem3=[]
for j in range(demmm//10):#爬取的页数
url1='"}'
dem3.append([])
r=requests.get(url1,timeout=30,headers=headers)
demo=r.text
demo1=json.loads(demo)
for i in range(10):#每一页爬取的人数
demm=demo1['rows'][i]['truename']#如果是已经打卡的人名,就加上【‘yiusers’】
dem3[j].append(demm)
url2='"}'
r=requests.get(url2,timeout=30,headers=headers)
demo=r.text
demo1=json.loads(demo)
dem3.append([])
for i in range(demmm%10):
demm=demo1['rows'][i]['truename']#如果是已经打卡的人名,就加上【‘yiusers’】
dem3[(demmm//10)].append(demm)
else:
dem3=[]
for j in range(demmm):#爬取的页数
url3='"}'
dem3.append([])
r=requests.get(url3,timeout=30,headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
demo1=json.loads(demo)
for i in range(10):#每一页爬取的人数
demm=demo1['rows'][i]['truename']#如果是已经打卡的人名,就加上【‘yiusers’】
dem3[j].append(demm)
return dem3
except:
return '爬取错误,可能是没有登陆'
if __name__=="__main__":
headers={
'Host':'',
'Connection':'keep-alive',
'Accept':'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36',
'Content-Type': 'application/json',
'Referer': '',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie':'keeplogin=145%7C86400%7C1653610958%7C13f4555127d60a15a2724a2ced89f1e7; PHPSESSID=d941060d296b473b921278117080b8dc'}#这个头是必要增加进去的
#如果每天的cookie可以自动更新,则爬取过程没有问题。
shuju=getHTMLText(headers)现在就可以有效的爬取出简介明了的结果:【‘张三’、‘李四’、‘王五’】
用微信发送:
经过题主大量的前期调查发现,想用微信发送谁没有打卡是个难度很大的事情,因为原来有的网页版微信已经被取消了,所以这里使用模拟鼠标键盘的方法进行操作。
pg.PAUSE = 1
name = '文件传输助手'
msgg = " ".join('%s' %id for id in shuju)
items=re.findall(r"['].*?[']",msgg)
jieguo=weixinfasong(name,items)
def weixinfasong(name,items):
name=name
items=items
try:
pg.hotkey('ctrl', 'alt', 'w')#打开微信的快捷键
pg.hotkey('ctrl', 'f')
pc.copy(name)
pg.hotkey('ctrl', 'v')
pg.press('enter')
# 发送消息
for item in items:
item=item.replace("'","")
item="@"+item+" (≧∇≦)/"+"该打卡了!"
pc.copy(item)
pg.hotkey('ctrl', 'v')#cv大法
pg.press('enter')
# 隐藏微信
pg.hotkey('ctrl', 'alt', 'w')
return "发送成功"
except:
return "发送失败"至此呢。所有的需求都已经被满足了。可是又出现了新的问题需要我们一一解决。
1、实现自动化,不能每次想看谁没有打卡都打开电脑执行脚本吧。这和女朋友自己看谁没有打卡有什么区别。
2、每次爬取的链接都会发生改变,而且cookie也会发生变化,网址的会话不能一直保持,每次都需要自己重新登陆。(网站的反爬策略)
1、实现自动化
我的解决办法是,将整个程序部署到云服务器上,在加上定时任务,完美解决。
1、云服务器,我选择的是腾讯云,3个月18元,超级有性价比的一款。系统就选择最基本的windows19,因为需要安装微信。当然,系统是可以后期重装的。安装必要的软件如下:

定时任务用的schedule库,这是一个轻量级的定时任务库。
schedule.every().day.at("08:47").do(firstremind)
#利用循环,试一下,datetime
#部署在每天的10:30执行job()函数的任务
schedule.every().day.at("00:21").do(mainfun) #部署在每天的10:30执行job()函数的任务
schedule.every().day.at("08:36:30").do(mainfun) #部署在每天的10:30执行job()函数的任务
schedule.every().day.at("11:00").do(mainfun)
schedule.every().day.at("11:30").do(mainfun)
schedule.every().day.at("12:00").do(mainfun)
while True:
schedule.run_pending()
time.sleep(1) 2、解决第二个问题时,先观察链接:
~~~~?addtabs=1&sort=user_id&order=desc&offset=0&limit=10&filter={"createtime":"2022-06-01 00:00:00 - 2022-06-01 23:59:59"}这个链接的createtime每天都会发生改变,比如这是今天的链接
所以,我们使用datetime库每天更新时间,为什么不用time.gmtime,是因为后者是格林尼治时间,前者是系统时间,我因为这个bug,半夜两点都没有睡着。呜呜呜~
time = str(datetime.datetime.now())
m=time[5:7]
n=time[8:10]
url=urls+'0&limit=10&filter={"createtime":"2022-'+m+'-'+n+' 00:00:00 - 2022-'+m+'-'+n+' 23:59:59"}'3、会话时间太短怎么办?那就每次都重新登陆一次,这里使用的是selenium模拟登陆
首先需要安装火狐的驱动GeckoDriver
相关链接:
GitHub:https://github.com/mozilla/geckodriver
下载地址:https://github.com/mozilla/geckodriver/releases
事先安装Firefox 浏览器。
同样也可以在阿里云镜像网站下载,地址:http://npm.taobao.org/mirrors/geckodriver/
下载后将解压的geckodriver.exe放入一个已经加入环境变量的目录中。根据
from selenium import webdriver
browser = webdriver.Firefox()的报错提示,将驱动exe文件放到你的编译器的制指定文件夹中,需要用到的检索定位功能,自行查阅selenium的介绍,csdn就有很多。然后模拟登陆:
因为登陆页面是这个样子的,模拟登陆前也需要对网页进行分析。(其实整个爬虫过程就相当于:第一使用selenium模拟登陆,获取cookies后传递给requests,再进行爬取,实际上使用了两次爬虫)
对网页进行分析,找到输入账号和密码的位置--input username~。
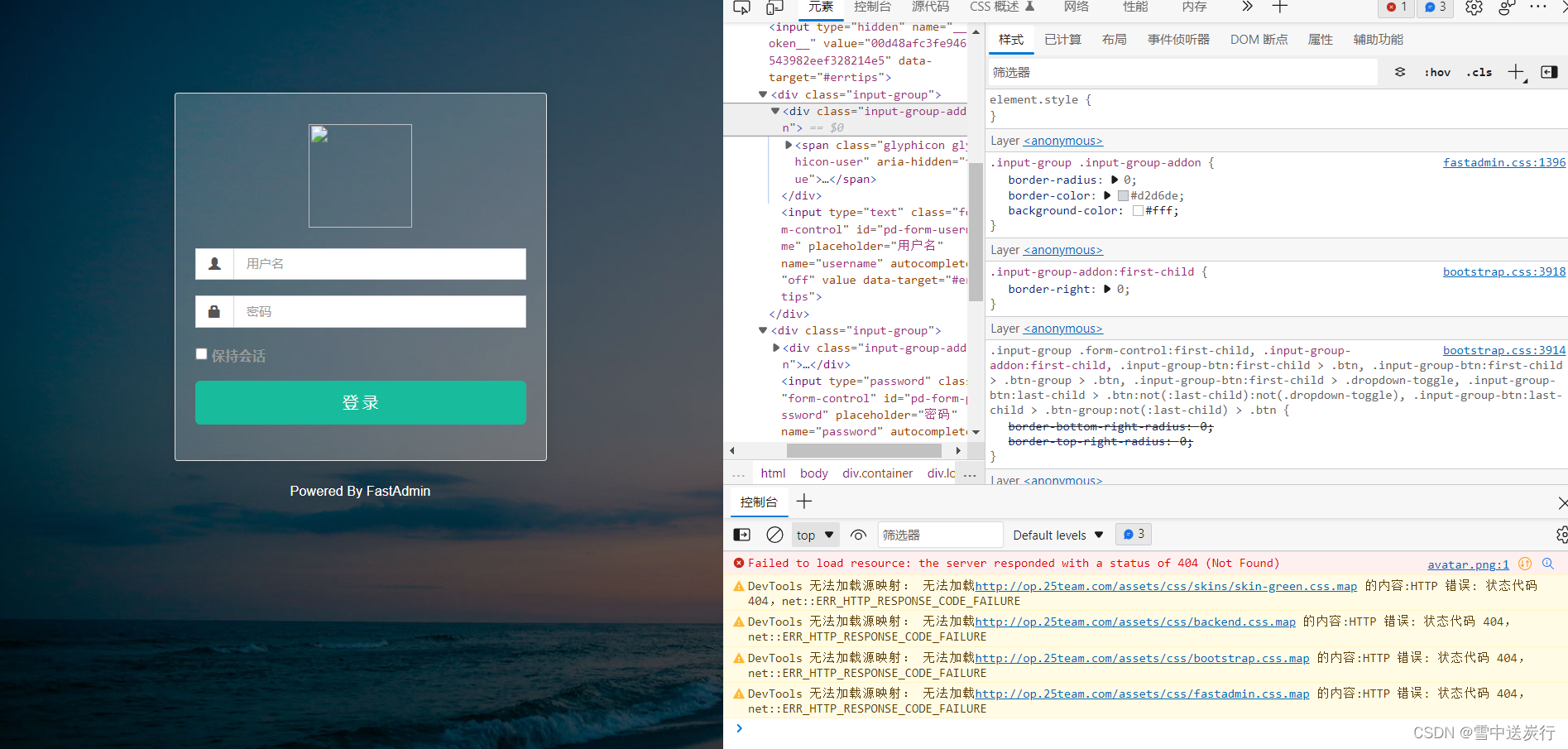
然后编写代码找到对应的位置,利用机器模拟人的操作登陆进去。
def getHTMLText(urls,deluurls,username,password):
import time
urls=urls
deluurls=deluurls
username=username
password=password
driver = webdriver.Firefox()
driver.get(deluurls)
c=driver.find_element_by_id('keeplogin')
c.click()
driver.find_element_by_id('pd-form-username').clear()
driver.find_element_by_id('pd-form-username').send_keys(username)
driver.find_element_by_id('pd-form-password').clear()
driver.find_element_by_id('pd-form-password').send_keys(password+Keys.RETURN)现在只剩下最后一个问题啦。如何获取cookies,并且在爬取前添加到headers中,利用
cookies=driver.get_cookies()#获取cookies
添加到headers中:
'Cookie': 'keeplogin='+cookies[1]['value']+'; PHPSESSID='+cookies[0]['value'],
至此,所有的问题被完美解决。
希望我提供的一些解决思路可以对大家有所帮助!源码在下面,为了不暴露同学们的隐私,所有的链接都被删除了,请自己分辨。而且本人是个菜鸡,看到我代码写的很烂,就别骂了,因为我也只是非计算机专业的学生,自己的兴趣爱好分享罢了。
# -*- coding: utf-8 -*-
"""
Created on Tue May 31 22:27:53 2022
@author: 18705
"""
import requests
import json
#下面的用来控制鼠标和键盘
import pyautogui as pg
import pyperclip as pc
import re
import schedule
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import datetime
def getHTMLText(urls,deluurls,username,password):
import time
urls=urls
deluurls=deluurls
username=username
password=password
driver = webdriver.Firefox()
driver.get(deluurls)
c=driver.find_element_by_id('keeplogin')
c.click()
driver.find_element_by_id('pd-form-username').clear()
driver.find_element_by_id('pd-form-username').send_keys(username)
driver.find_element_by_id('pd-form-password').clear()
driver.find_element_by_id('pd-form-password').send_keys(password+Keys.RETURN)
time.sleep(3.5)
cookies=driver.get_cookies()
headers={
'Host':'',
'Connection':'keep-alive',
'Accept':'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36',
'Content-Type': 'application/json',
'Referer': '',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
#'Cookie': 'PHPSESSID=8da17afa30e55052a1e5d30074471fa4; keeplogin=145%7C86400%7C1639439370%7Cfbddda0ff51baaf83b064832c47e626b',
#'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:100.0) Gecko/20100101 Firefox/100.0',
#'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cookie': 'keeplogin='+cookies[1]['value']+'; PHPSESSID='+cookies[0]['value'],
#这个cookie才是每次需要更新的东西·。
}
try:
#if time.gmtime()[1]>=10:
#m=str(time.gmtime()[1])
#else:
#m='0'+str(time.gmtime()[1])
#if time.gmtime()[2]>=10:
#n=str(time.gmtime()[2])
#else:
#n='0'+str(time.gmtime()[2]) #这个是格林尼治时间,比北京时间慢7小时
time = str(datetime.datetime.now())
m=time[5:7]
n=time[8:10]
url=urls+'0&limit=10&filter={"createtime":"2022-'+m+'-'+n+' 00:00:00 - 2022-'+m+'-'+n+' 23:59:59"}'
r=requests.get(url,timeout=30,headers=headers)
demoo=r.text
demo11=json.loads(demoo)
demmm=demo11['total']
if (demmm%10!=0):
dem3=[]
for j in range(demmm//10):#爬取的页数
url1=urls+str(10*j)+'&limit=10&filter={"createtime":"2022-'+m+'-'+n+' 00:00:00 - 2022-'+m+'-'+n+' 23:59:59"}'
dem3.append([])
r=requests.get(url1,timeout=30,headers=headers)
demo=r.text
demo1=json.loads(demo)
for i in range(10):#每一页爬取的人数
demm=demo1['rows'][i]['truename']#如果是已经打卡的人名,就加上【‘yiusers’】
dem3[j].append(demm)
url2=urls+str(10*(demmm//10))+'&limit=10&filter={"createtime":"2022-'+m+'-'+n+' 00:00:00 - 2022-'+m+'-'+n+' 23:59:59"}'
r=requests.get(url2,timeout=30,headers=headers)
demo=r.text
demo1=json.loads(demo)
dem3.append([])
for i in range(demmm%10):
demm=demo1['rows'][i]['truename']#如果是已经打卡的人名,就加上【‘yiusers’】
dem3[(demmm//10)].append(demm)
else:
dem3=[]
for j in range(demmm):#爬取的页数
url3=urls+str(10*j)+'&limit=10&filter={"createtime":"2022-'+m+'-'+n+' 00:00:00 - 2022-'+m+'-'+n+' 23:59:59"}'
dem3.append([])
r=requests.get(url3,timeout=30,headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
demo=r.text
demo1=json.loads(demo)
for i in range(10):#每一页爬取的人数
demm=demo1['rows'][i]['truename']#如果是已经打卡的人名,就加上【‘yiusers’】
dem3[j].append(demm)
print(dem3)
driver.quit()
return dem3
except:
return '爬取错误,可能是没有登陆'
def weixinfasong(name,items):
name=name
items=items
pg.hotkey('ctrl', 'alt', 'w')
pg.hotkey('ctrl', 'f')
pc.copy(name)
pg.hotkey('ctrl', 'v')
pg.press('enter')
# 发送消息
if items=="全体成员打卡完成":
item='统计20-1'+items+'辉辉爱你'
pc.copy(item)
pg.hotkey('ctrl', 'v')
pg.press('enter')
elif items=="全体成员":
item='家人们开始打卡了!@全体成员'
pc.copy(item)
pg.hotkey('ctrl', 'v')
pg.press('enter')
else:
for item in items:
item=item.replace("'","")
item="@"+item+" (≧∇≦)/"+"该打卡了!"
pc.copy(item)
pg.hotkey('ctrl', 'v')
pg.press('enter')
# 隐藏微信
pg.hotkey('ctrl', 'alt', 'w')
def firstremind():
pg.PAUSE = 1
name = '文件传输助手'
items='全体成员'
weixinfasong(name,items)
def finishremind():
pg.PAUSE = 1
name = '文件传输助手'
items='全体成员打卡完成'
weixinfasong(name,items)
def mainfun():
urls=''
deluurls="/login"
username=''
password=''
shuju=getHTMLText(urls,deluurls,username,password)
if type(shuju)==str:
print(shuju)
else:
if not shuju:
finishremind()
time.sleep(7200)#可能阻塞了,下一个任务依然会执行
else:
pg.PAUSE = 1
name = '文件传输助手'
msgg = " ".join('%s' %id for id in shuju)
items=re.findall(r"['].*?[']",msgg)
weixinfasong(name,items)
#增加定时任务,定时任务命令只能把函数作为参数,分装主函数里面的任务。
schedule.every().day.at("00:14").do(firstremind)
#利用循环,试一下,datetime
#部署在每天的10:30执行job()函数的任务
schedule.every().day.at("00:46:30").do(mainfun) #部署在每天的10:30执行job()函数的任务
schedule.every().day.at("08:36:30").do(mainfun) #部署在每天的10:30执行job()函数的任务
schedule.every().day.at("11:00").do(mainfun)
schedule.every().day.at("11:30").do(mainfun)
schedule.every().day.at("12:00").do(mainfun)
while True:
schedule.run_pending()
time.sleep(1)















 4402
4402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









