






在市场购物分析中,频繁项集挖掘是帮助发现商品之间关联的重要技术。Apriori算法是一种广泛应用于关联规则挖掘的经典算法,其核心任务是找出在给定事务数据库中频繁出现的项集。为了有效地控制结果的数量,Apriori算法通常需要设置最小支持度(min_support)阈值。
最小支持度是定义一个项集在整个数据库中至少出现的比例,只有满足此条件的项集才能被认为是频繁项集。支持度的设置会直接影响频繁项集的数量和关联规则的有效性。
-
较低的最小支持度阈值会导致较多的频繁项集,这些项集可能代表了一些较为稀有但仍具有潜在价值的商品组合。这样的设置可能会导致算法产生大量的频繁项集,增加计算复杂度,但也可能揭示一些细粒度的市场趋势。
-
较高的最小支持度阈值会筛选掉不常出现的项集,从而减少频繁项集的数量,专注于那些在较大比例的事务中出现的常见商品组合。这通常可以帮助我们识别更具有普遍性和市场潜力的商品关联,但可能会遗漏一些较为特殊的、但依然有商业价值的组合。
通过调整最小支持度,我们能够更好地控制频繁项集的数量和质量,从而进行更加精细的市场分析和策略制定。
算法中的最小支持度对频繁项集的结果有很大影响。通过调整最小支持度,分析频繁项集的变化,理解支持度阈值如何影响结果的选择。
1. 使用Apriori算法在数据集中挖掘频繁项集,设置不同的最小支持度阈值(10%、20%、30%、40%、50%)进行挖掘。
2. 统计每个支持度阈值下的频繁项集数量。
import pandas as pd
from mlxtend.frequent_patterns import apriori
import matplotlib.pyplot as plt
#import warnings
# 忽略字体警告
#warnings.filterwarnings("ignore", category=UserWarning, module="matplotlib")
# 定义不同的支持度阈值
supports = [0.1, 0.2, 0.3, 0.4, 0.5]
frequent_itemsets_list = []
# 创建交易数据集
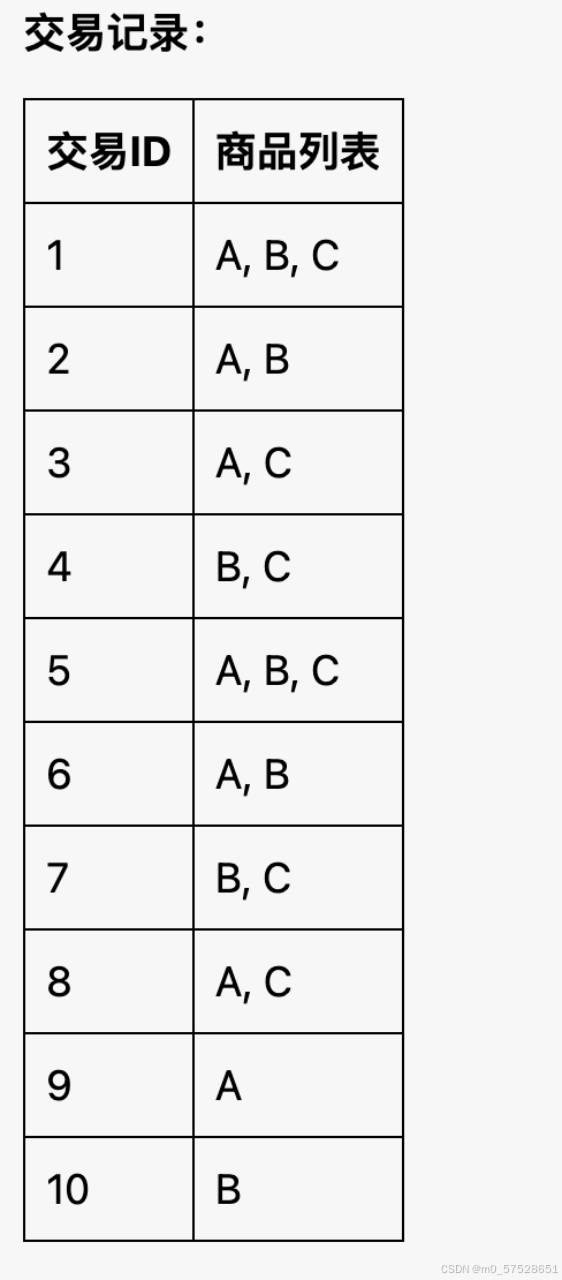
df = pd.DataFrame([['A', 'B', 'C'], ['A', 'B'], ['A', 'C'], ['B', 'C'], ['A', 'B', 'C'],
['A', 'B'], ['B', 'C'], ['A', 'C'], ['A'], ['B']])
# 转换为独热编码
df = df.stack().str.get_dummies().groupby(level=0).sum()
df = df.astype(bool) # 转换为布尔类型
# 挖掘不同支持度下的频繁项集
for min_support in supports:
frequent_itemsets = apriori(df, min_support=min_support, use_colnames=True)
frequent_itemsets_list.append((min_support, len(frequent_itemsets)))
# 输出频繁项集数量
for support, count in frequent_itemsets_list:
print(f"支持度阈值:{support * 100}% 频繁项集数量:{count}")
import matplotlib.pyplot as plt
supports_percent = [s * 100 for s in supports]
counts = [count for _, count in frequent_itemsets_list]
plt.figure(figsize=(8, 5))
plt.plot(supports_percent, counts, marker='o')
plt.title('支持度阈值与频繁项集数量关系图')
plt.xlabel('最小支持度阈值(%)')
plt.ylabel('频繁项集数量')
plt.grid(True)
plt.show()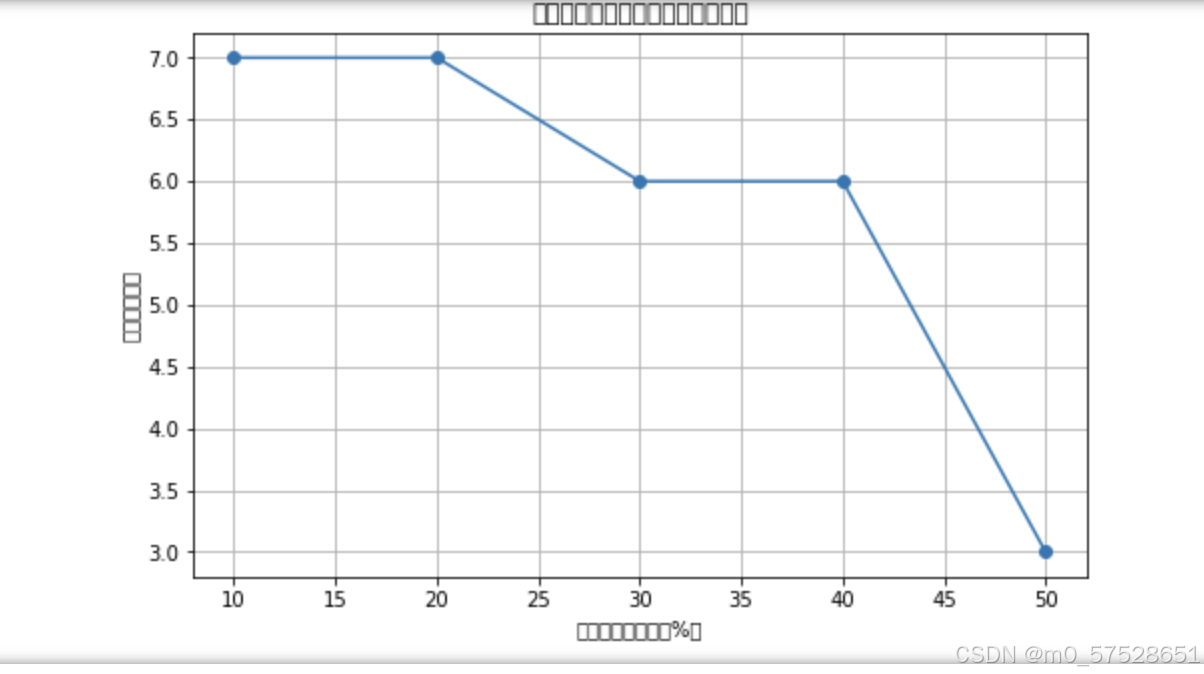 分析: 随着支持度的提高,频繁项集的数量减少。 在不同支持度下仍然频繁的项集:如项集{'B'},在高支持度下依然频繁。 支持度阈值影响:较低的支持度阈值能够发现更多的频繁项集,但可能包含不够重要的关联;较高的支持度阈值则能突出更强的关联,但可能遗漏一些有价值的模式。
分析: 随着支持度的提高,频繁项集的数量减少。 在不同支持度下仍然频繁的项集:如项集{'B'},在高支持度下依然频繁。 支持度阈值影响:较低的支持度阈值能够发现更多的频繁项集,但可能包含不够重要的关联;较高的支持度阈值则能突出更强的关联,但可能遗漏一些有价值的模式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









