







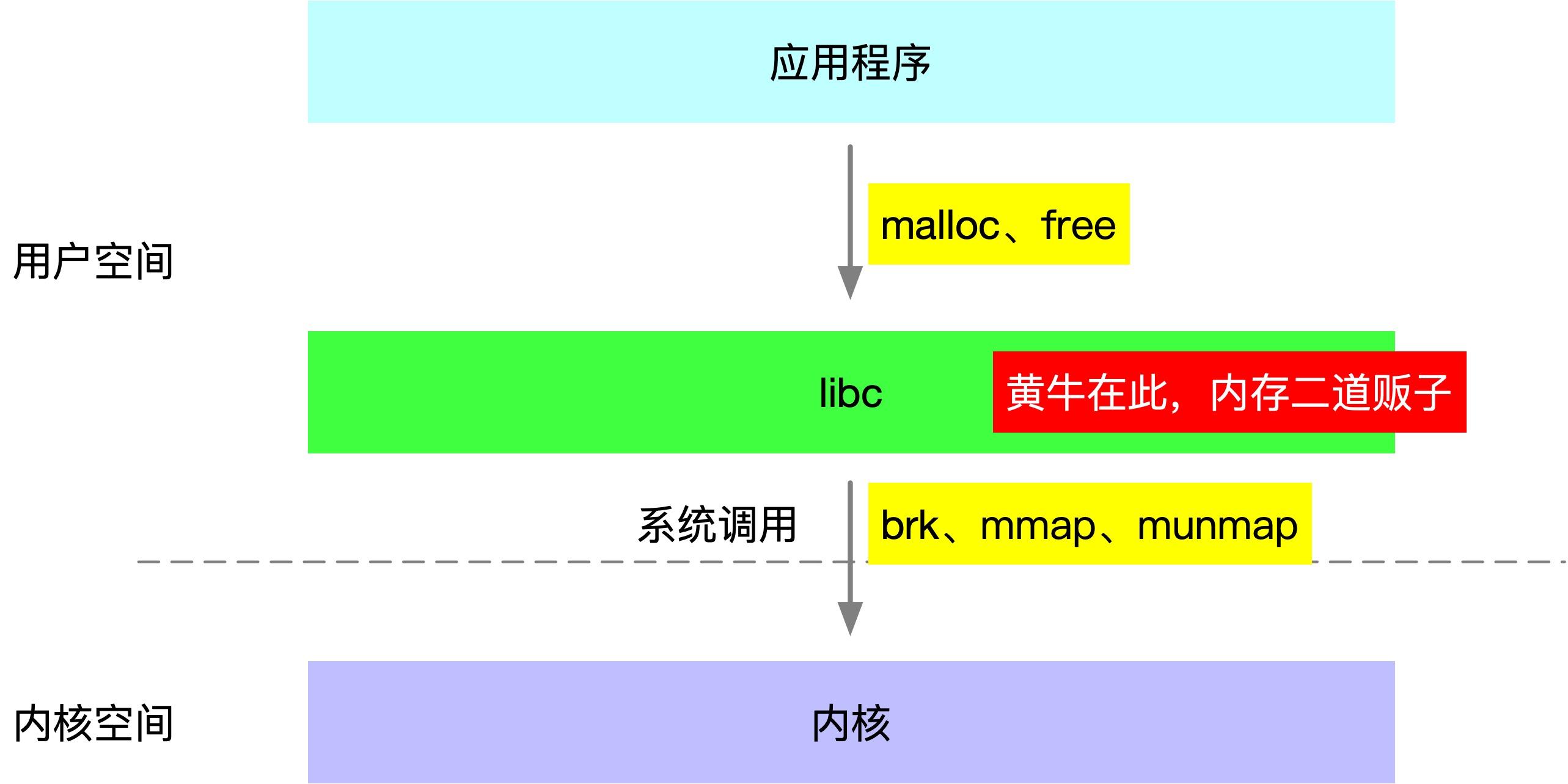
第二个原因是为了编程上的统一,比如有些时候用 brk,有些时候用 mmap,不太友好,brk 在多线程下还需要进行加锁,用一个 malloc 就很香。
Linux 内存分配器
Linux 的内存分配器有很多种,一开始是 Doug Lea 大神开发的 dlmalloc,这个分配器对多线程支持不友好,多线程下会竞争全局锁,随后有人基于 dmalloc 开发了 ptmalloc,增加了多线程的支持,除了 linux 官方的 ptmalloc,各个大厂有开发不同的 malloc 算法,比如 facebook 出品的 jemalloc,google 出品的 tcmalloc。

这些内存分配器致力于解决两个问题:多线程下锁的粒度问题,是全局锁,还是局部锁还是无锁。第二个问题是小内存回收和内存碎片问题,比如 jemalloc 在内存碎片上有显著的优势。
ptmalloc 的核心概念
接下来我们来看 Linux 默认的内存分配器 ptmalloc,我总结了一下它有关的四个核心概念:Arena、Heap、Chunk、Bins。
Arena
先来看 Arena,Arena 的中文翻译的意思是主战场、舞台,对应在内存分配这里,指的是内存分配的主战场。 
Arena 的出现首先用来解决多线程下全局锁的问题,它的思路是尽可能的让一个线程独占一个 Arena,同时一个线程会申请一个或多个堆,释放的内存又会进入回收站,Arena 就是用来管理这些堆和回收站的。
Arena 的数据结构长啥样?它是一个结构体,可以用下面的图来表示。
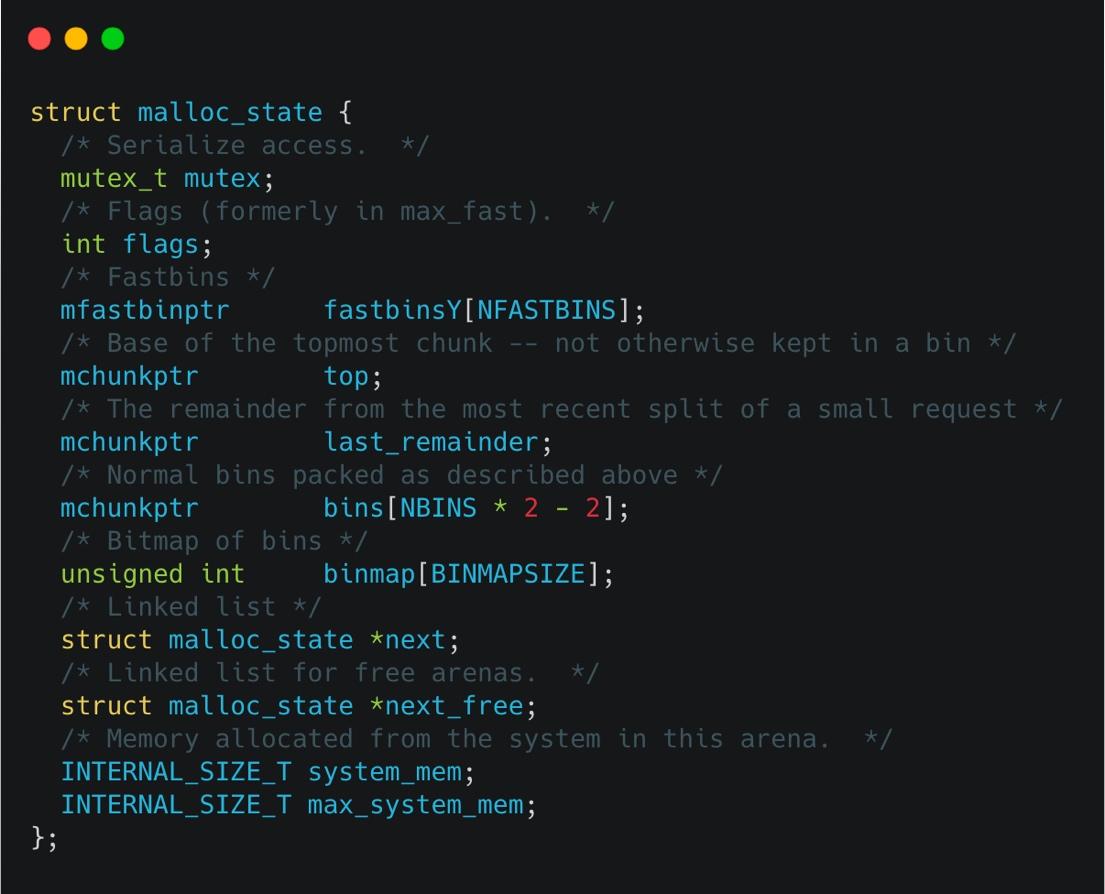
它是一个单向循环链表,使用 mutex 锁来处理多线程竞争,释放的小块内存会放在 bins 的结构中。
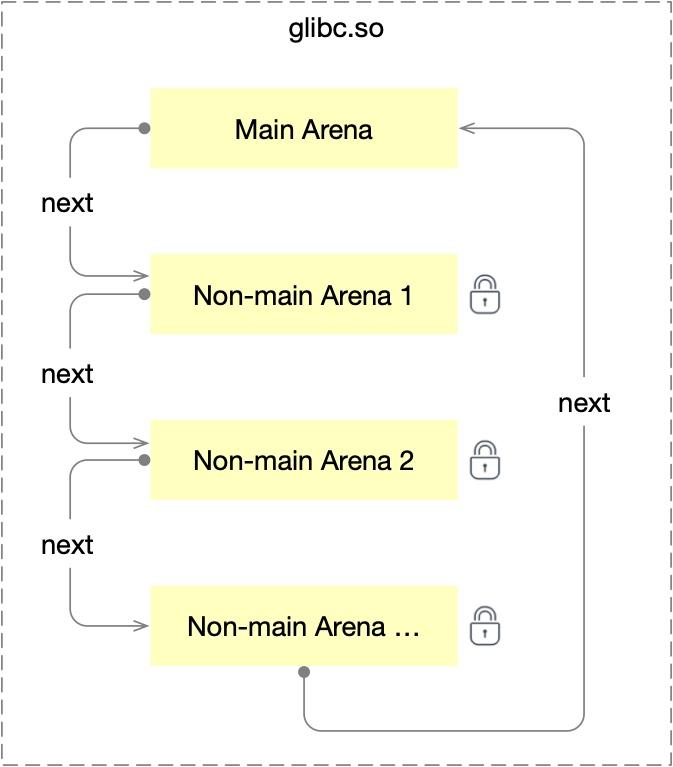
前面提到,Arena 会尽量让一个线程独占一个锁,那如果我有几千个线程,会生成几千个 Arena 吗?显然是不会的,所有跟线程有关的瓶颈问题,最后都会走到 CPU 核数的限制这里来,分配区的个数也是有上限的,64 位系统下,分配区的个数大小是 cpu 核数的八倍,多个 Arena 组成单向循环链表。
我们可以写个代码来打印 Arena 的信息。它的原理是对于一个确定的程序,main_arena 的地址是一个位于 glibc 库的确定的地址,我们在 gdb 调试工具中可以打印这个地址。也可以使用 ptype 命令来查看这个地址对应的结构信息,如下图所示。
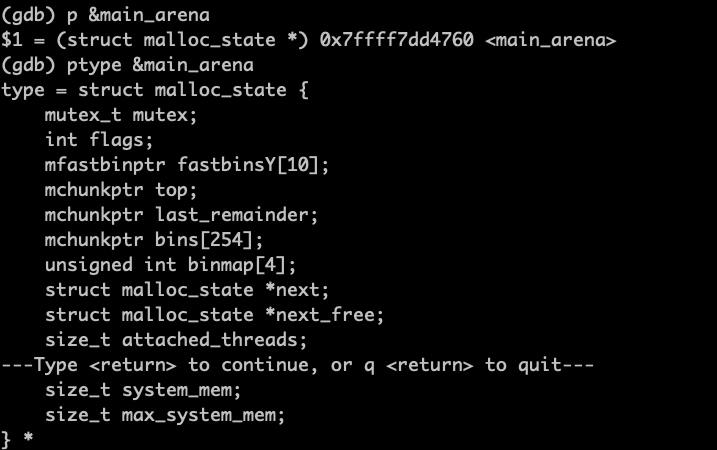
有了这个基础,我们就可以写一个 do while 来遍历这个循环链表了。我们把 main_arena 的地址转为 malloc_state 的指针,然后 do while 遍历,直到遍历到链表头。
struct malloc_state {
int mutex;
int flags;
void *fastbinsY[NFASTBINS];
struct malloc_chunk *top;
struct malloc_chunk *last_remainder;
struct malloc_chunk *bins[NBINS * 2 - 2];
unsigned int binmap[4];
struct malloc_state *next;
struct malloc_state *next_free;
size_t system_mem;
size_t max_system_mem;
};
void print_arenas(struct malloc_state *main_arena) {
struct malloc_state *ar_ptr = main_arena;
int i = 0;
do {
printf(“arena[%02d] %p\n”, i++, ar_ptr);
ar_ptr = ar_ptr->next;
} while (ar_ptr != main_arena);
}
#define MAIN_ARENA_ADDR 0x7ffff7bb8760
int main() {
…
print_arenas((void*)MAIN_ARENA_ADDR);
return 0;
}
复制代码
输出结果如下。

那为什么还要区分一个主分配,一个非主分配区呢?
这有点像皇上和王爷的关系, 主分配区只有一个,它还有一个特权,可以使用靠近 DATA 段的 Heap 区,它通过调整 brk 指针来申请释放内存。
从某种意义上来讲,Heap 区不过是 DATA 段的扩展而已。

非主分配区呢?它更像是一个分封在外地,自主创业的王爷,它想要内存时就使用 mmap 批发大块内存(64M)作为子堆(Sub Heap),然后在慢慢零售给上层应用。
一个 64M 用完,再开辟一个新的,多个子堆之间也是使用链表相连,一个 Arena 可以有多个子堆。在接下的内容中,我们还会继续详细介绍。

Heap
接下来我们来看 ptmalloc2 的第二个核心概念 ,heap 用来表示大块连续的内存区域。
主分配区的 heap 没有什么好讲的,我们这里重点看「非主分配」的子堆(也称为模拟堆),前面提到过,非主分配批发大块内存进行切割零售的。
那如何理解切割零售这句话呢?它的实现也非常简单,先申请一块 64M 大小的不可读不可写不可执行(PROT_NONE)的内存区域,需要内存时使用 mprotect 把一块内存区域的权限改为可读可写(R+W)即可,这块内存区域就可以分配给上层应用了。

以我们前面 java 进程的内存布局为例。

这中间的两块内存区域是属于一个子堆,它们加起来的大小是 64M,然后其中有一块 1.3M 大小的内存区域就是使用 mprotrect 分配出去的,剩下的 63M 左右的区域,是不可读不可写不可执行的待分配区域。
知道这个有什么用呢?太有用了,你在 google 里所有 Java 堆外内存等问题,有很大可能性会搜到 Linux 神奇的 64M 内存问题。有了这里的知识,你就比较清楚到底这 64M 内存问题是什么了。

与前面的 Arena 一样,我们同样可以在代码中,遍历所有 Arena 的所有的 heap 列表,代码如下所示。
struct heap_info {
struct malloc_state *ar_ptr;
struct heap_info *prev;
size_t size;
size_t mprotect_size;
char pad[0];
};
void dump_non_main_subheaps(struct malloc_state *main_arena) {
struct malloc_state *ar_ptr = main_arena->next;
int i = 0;
while (ar_ptr != main_arena) {
printf(“arena[%d]\n”, ++i);
struct heap_info *heap = heap_for_ptr(ar_ptr->top);
do {
printf(“arena:%p, heap: %p, size: %d\n”, heap->ar_ptr, heap, heap->size);
heap = heap->prev;
} while (heap != NULL);
ar_ptr = ar_ptr->next;
}
}
#define MAIN_ARENA_ADDR 0x7ffff7bb8760
dump_non_main_subheaps((void*)MAIN_ARENA_ADDR);
复制代码
Chunk
接下来我们来看分配的基本单元 chunk,chunk 的字面意思是「厚块; 厚片」,chunk 是 glibc 中内存分配的基础单元。以一个简单的例子来开头。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
void *p;
p = malloc(1024);
printf(“%p\n”, p);
p = malloc(1024);
printf(“%p\n”, p);
p = malloc(1024);
printf(“%p\n”, p);
getchar();
return (EXIT_SUCCESS);
}
复制代码
这段代码逻辑是连续调用三次 malloc,每次分配 1k 内存,然后我们来观察它的内存地址。
./malloc_test
0x602010
0x602420
0x602830
复制代码
可以看到内存地址之间差了 0x410,1024 是等于 0x400,那多出来的 0x10 字节是什么?我们先按下不表。
再来回看 malloc 和 free,那我们不禁问自己一个问题,free 函数的参数只有一个指针,它是怎么知道要释放多少内存的呢?
#include <stdlib.h>
void *malloc(size_t size);
void free(void *ptr);
复制代码
香港作家张小娴说过,「凡事皆有代价,快乐的代价便是痛苦」。为了存储 1k 的数据,实际上还需要一些数据来记录这块内存的元数据。这块额外的数据被称为 chunk header,长度为 16 字节。这就是我们前面看到的多出来 0x10 字节。 
这种通过在实际数据前面添加 head 方式使用的非常普遍,比如 java 中 new Integer(1024),实际存储的数据大小远不止 4 字节,它有一个巨大无比的对象头,里面存储了对象的 hashcode,经过了几次 GC,有没有被当做锁同步。

害,说 java 臃肿并不是没有道理。
在我们继续来看这个 16 字节的 header 里面到底存储了什么,它的结构示意图如下所示。

它分为两部分,前 8 字节表示前一个 chunk 块的大小,接下来的 8 字节表示当前 chunk 块的大小,因为 chunk 块要按 16 字节对齐,所以低 4 字节都是没用的,其中三个被用来当做标记位来使用,这三个分别是 AMP,其中 A 表示是否是主分配区,M 表示是否是 mmap 分配的大 chunk 块,P 表示前一个 chunk 是否在使用中。
以前面的例子为例,我们可以用 gdb 来查看这部分的内存。

可以看到对应 size 的 8 个字节是 0x0411,这个值是怎么来的呢?其实是按 size + 8 对齐到 16B 再加上低三位的 B001。
0x0400 + 0x10 + 0x01 = 0x0411
复制代码
因为当一个 chunk 正在被使用时,它的下一个 chunk 的 prev_size 是没有意义的,这 8 个字节可以被这个当前 chunk 使用。别奇怪,就是这么抠。接下来我们来看看 chunk 中 prev_size 的复用。测试的代码如下。
#include <stdlib.h>
#include <string.h>
void main() {
char *p1, *p2;
p1 = (char *)malloc(sizeof(char) * 18); // 0x602010
p2 = (char *)malloc(sizeof(char) * 1); // 0x602030
memcpy(p1, “111111111111111111”, 18);
}
复制代码
编译这个源文件,然后使用 gdb 调试单步运行,查看 p1、p2 的地址。
p/x p1
$2 = 0x602010
(gdb) p/x p2
$3 = 0x602030
复制代码
然后输出 p1、p2 附近的内存区域。
(gdb) x/64bx p1-0x10
0x602000: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602008: 0x21 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602010: 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
0x602018: 0x31 0x31 0x31 0x31 0x31 0x31 0x31 0x31
0x602020: 0x31 0x31 0x00 0x00 0x00 0x00 0x00 0x00
0x602028: 0x21 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602030: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x602038: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
复制代码
布局如下图所示。
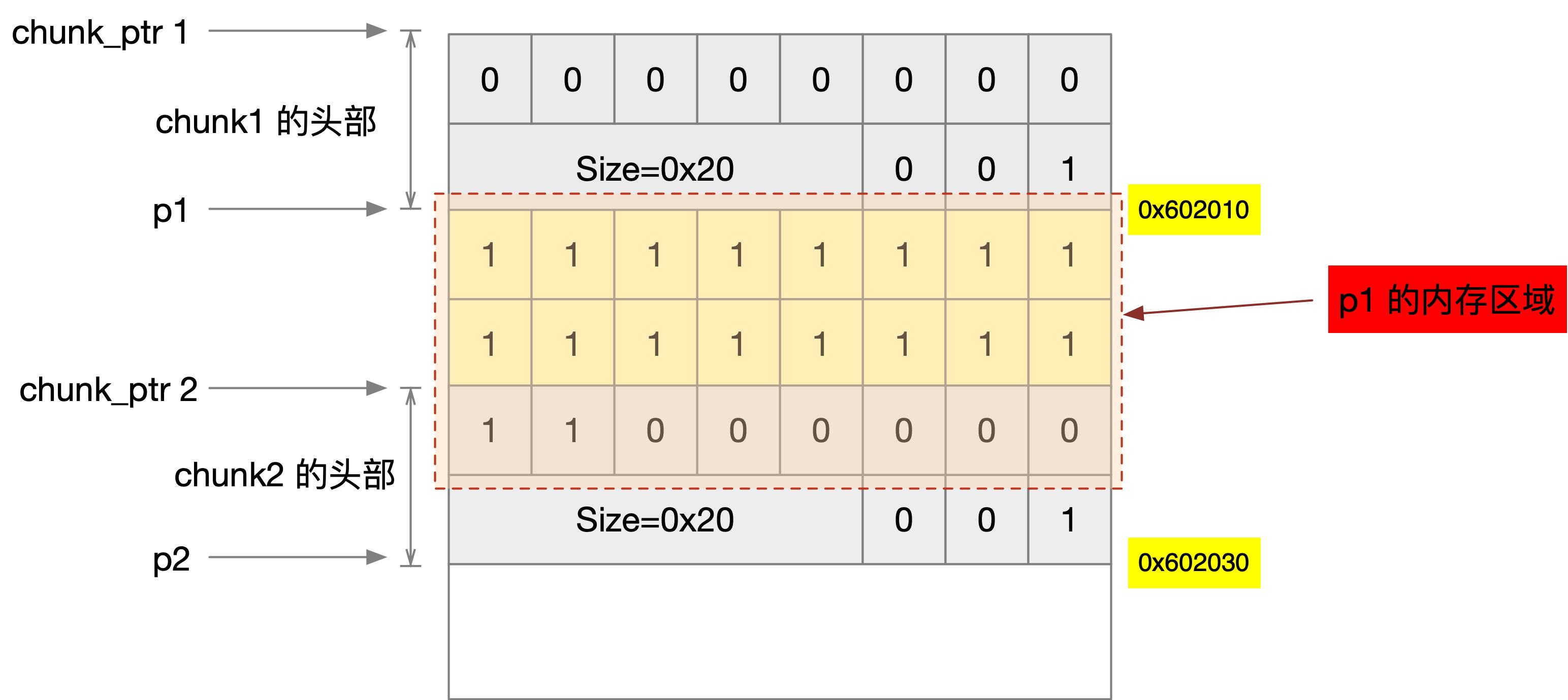
篇幅有限,我这里只展示了 malloc chunk 的结构,还有 Free chunk、Top chunk、Last Remainder chunk 没有展开,可以参考其它的资料。
Bins
我们接下来看最后一个概念,小块内存的回收站 Bins。
内存的回收站分为两大类,第一类是普通的 bin,一类是 fastbin。
-
fastbin 采用单向链表,每条链表的中空闲 chunk 大小是确定的,插入删除都在队尾进行。
-
普通 bin 根据回收的内存大小又分为了 small、large 和 unsorted 三种,采用双向链表存储,它们之间最大的区别就是它们存储的 chunk 块的大小范围不一样。
接下来我们看这两种 bin 的细节。
普通 bin 采用双向链表存储,以数组形式定义,共 254 个元素,两个数组元素组成一个 bin,通过 fd、bk 组成双向循环链表,结构有点像九连环玩具。
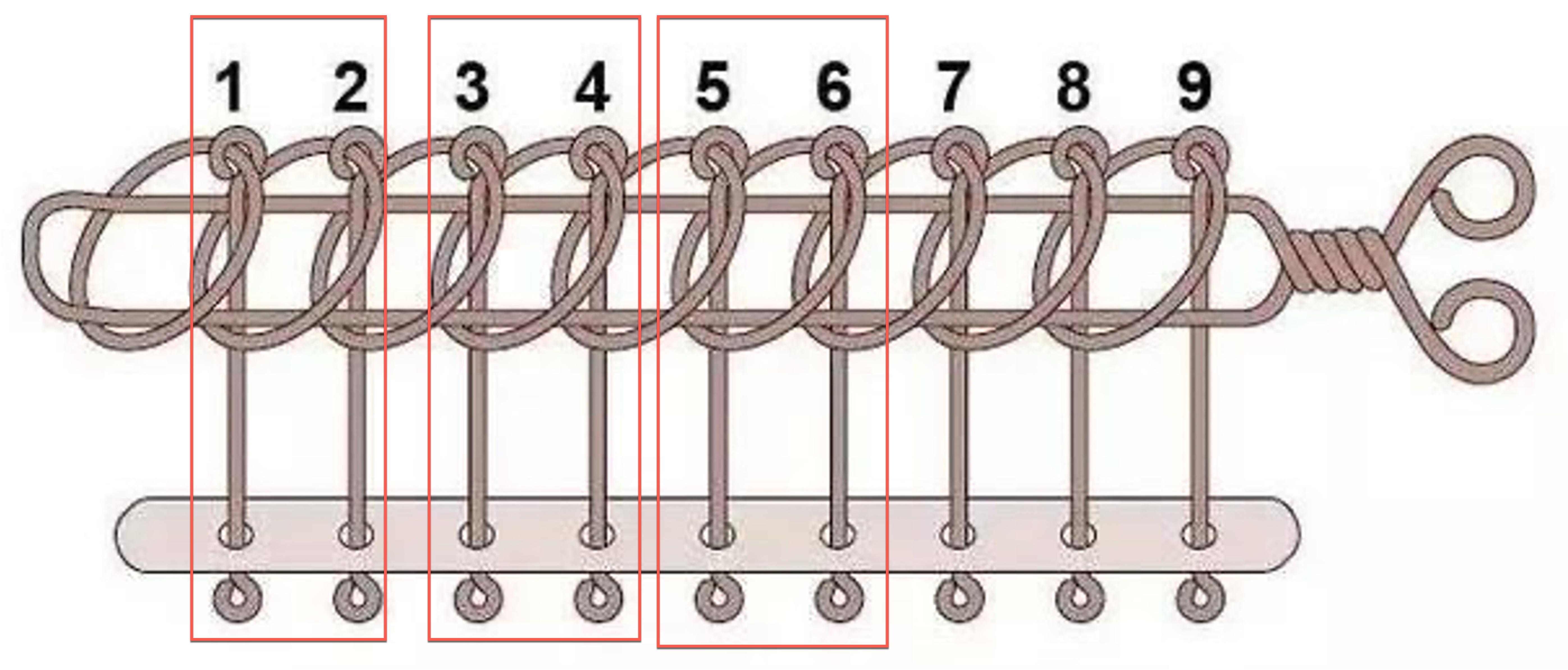
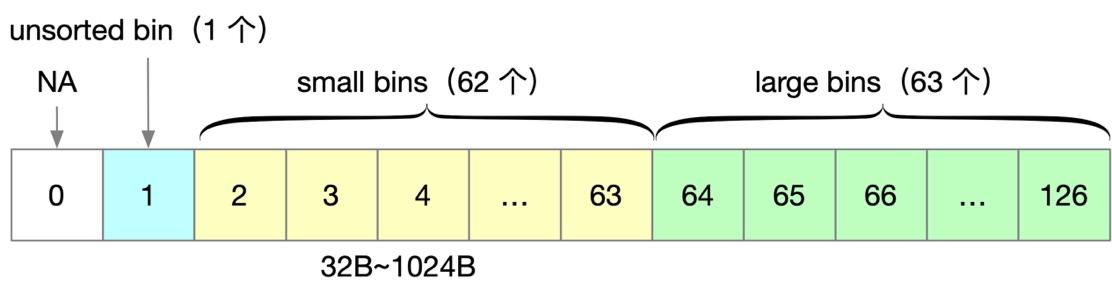
所以普通 bin 的总个数是 254/2 = 127 个。其中 unsorted bin 只有 1 个,small 有 62 个,large bin 有 63 个,还有一个暂未使用,如下图所示。
smallbin
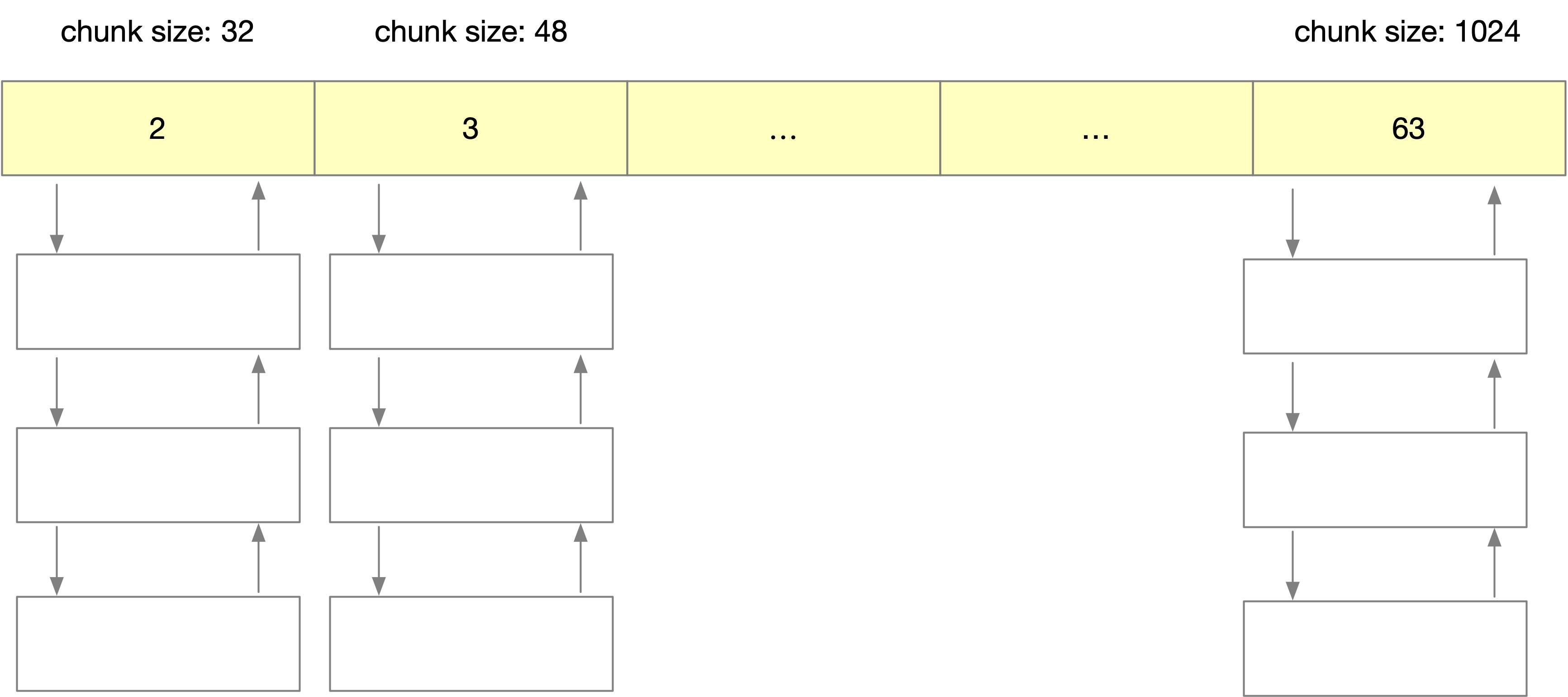
其中 smallbin 用于维护 <= 1024B 的 chunk 内存块。同一条 small bin 链中的 chunk 具有相同的大小,都为 index * 16,结构如下图所示。
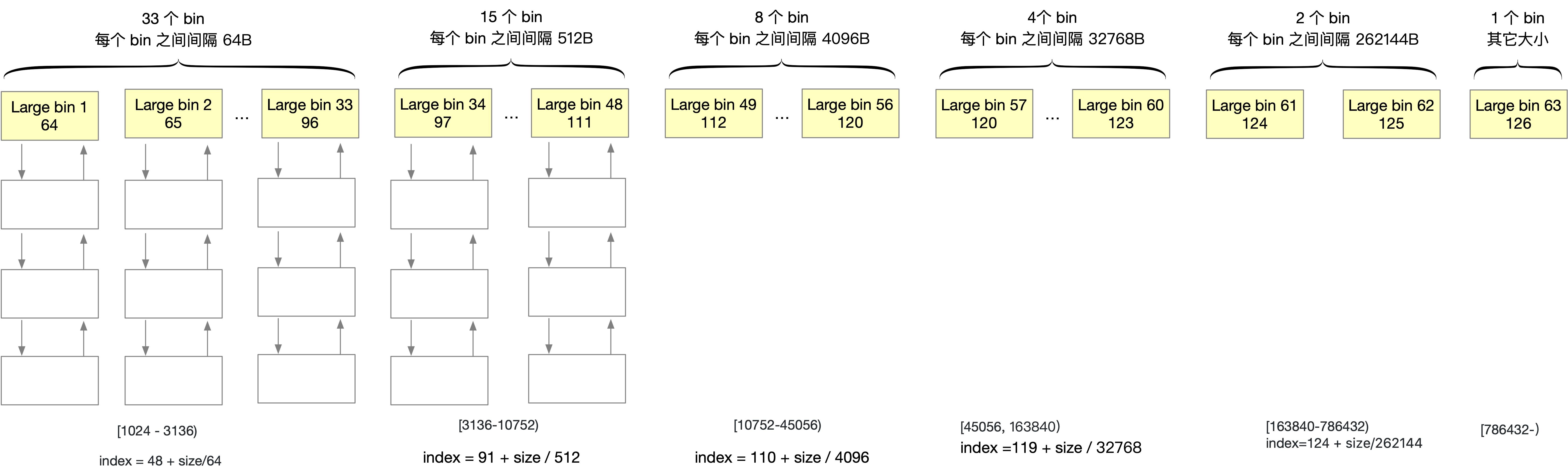
largebin
largebin 中同一条链中的 chunk 具有「不同」的大小
-
分为 6 组
-
每组的 bin 数量依次为 33、15、8、4、2、1,每条链表中的最大 chunk 大小公差依次为 64B、 512B、4096B、32768B、262144B 等
结构如下图所示。
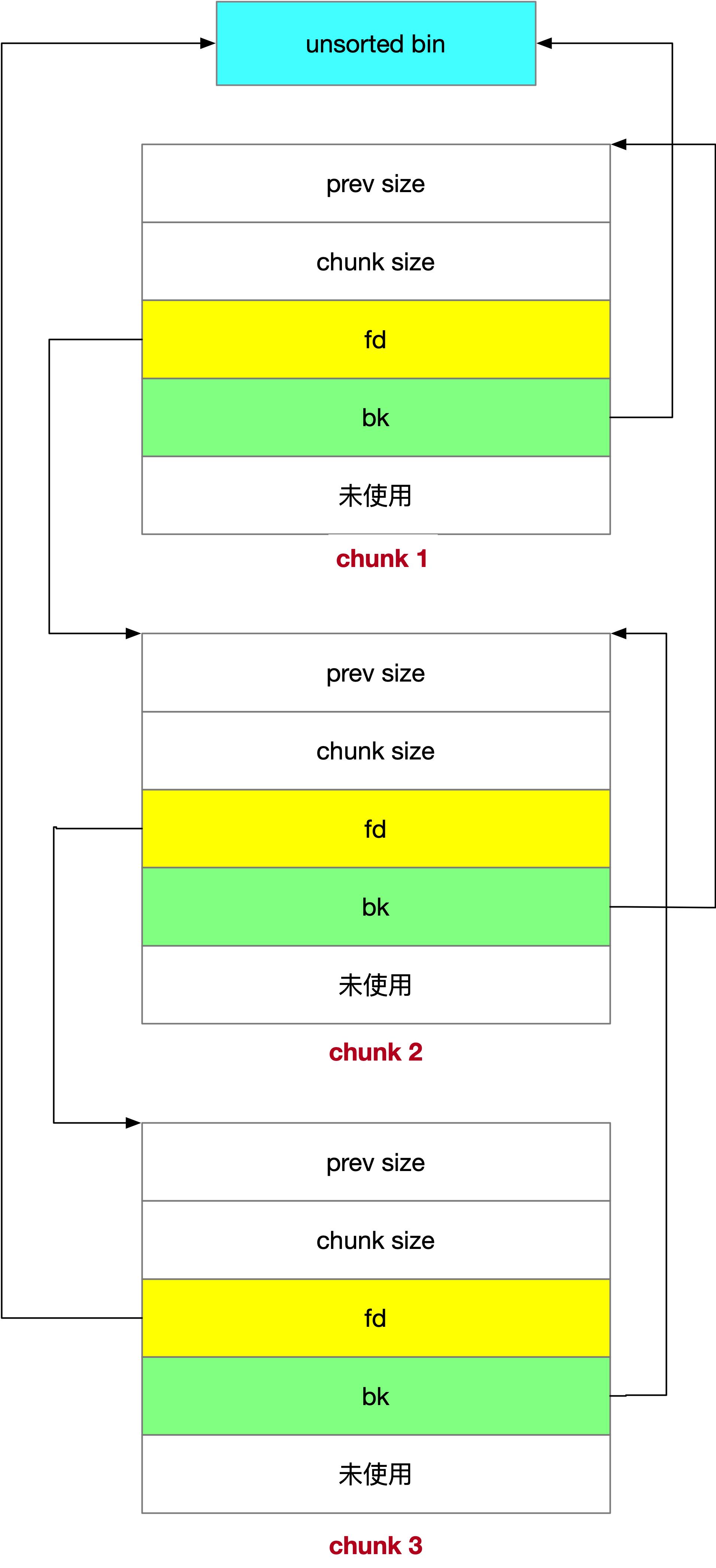
unsorted bin
unsorted bin 只有一条双向链表,它的特点如下。
-
空闲 chunk 不排序
-
大于 128B 的内存 chunk 回收时先放到 unsorted bin
它的结构如下图所示。
下面是所有普通 bin 的概览图。

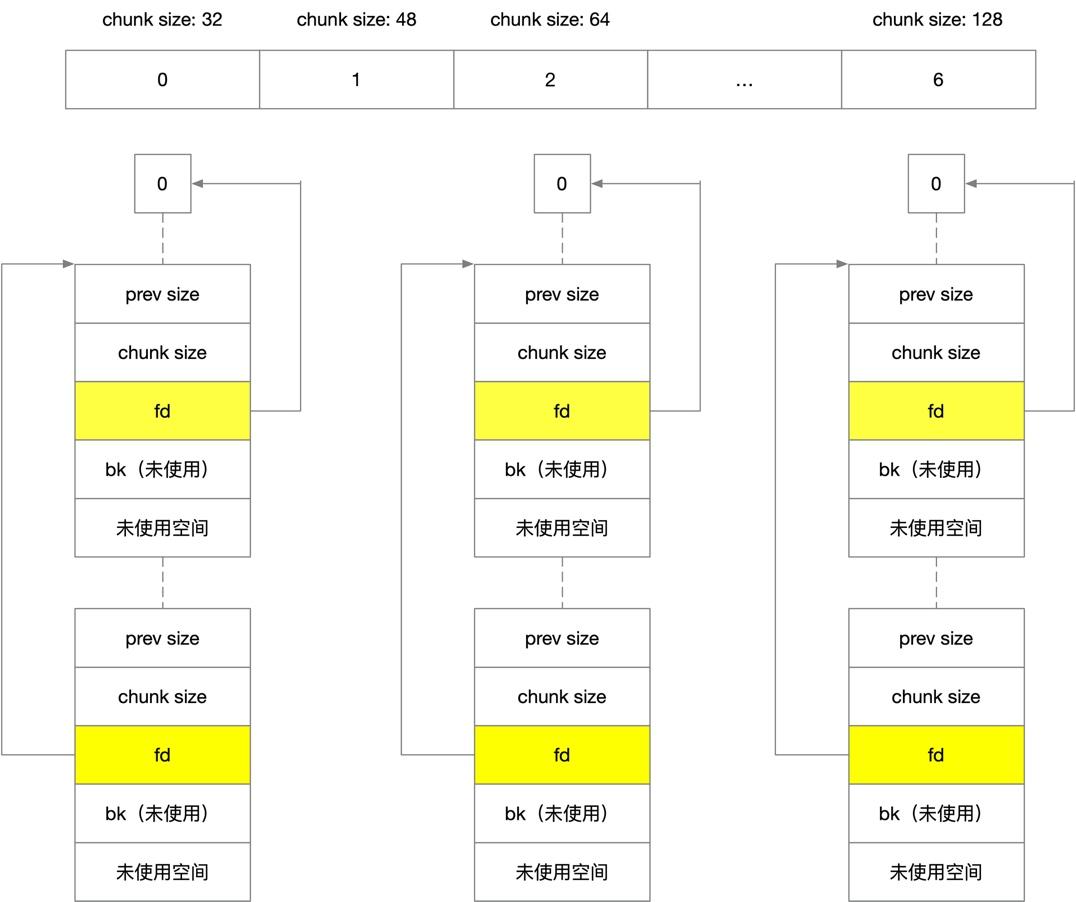
FastBin
说完了普通 bin,我们来详细看看 FastBin,FastBin 专门用来提高小内存的分配效率,它的结构如下。
它有下面这些特性。
-
小于 128B 的内存分配会先在 Fast Bin 中查找
-
单向链表,每条链表中的 chunk 大小相同,有 7 个 chunk 空闲链表,每个 bin 的 chunk 大小依次为 32B,48B,64B,80B,96B,112B,128B
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)

b8e67c8e2b.png)
它有下面这些特性。
-
小于 128B 的内存分配会先在 Fast Bin 中查找
-
单向链表,每条链表中的 chunk 大小相同,有 7 个 chunk 空闲链表,每个 bin 的 chunk 大小依次为 32B,48B,64B,80B,96B,112B,128B
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-8p3DMCk8-1710867196300)]
[外链图片转存中…(img-z3XFVOHQ-1710867196301)]
[外链图片转存中…(img-NcqhU5ok-1710867196301)]
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)
[外链图片转存中…(img-gEKuFP8f-1710867196302)]















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









