







摘 要
随着大数据技术的快速发展和普及,电影推荐系统在互联网应用中扮演着越来越重要的角色。传统的基于协同过滤的推荐系统在处理大规模数据时存在效率低下的问题,而基于Spark大数据平台、Python编程语言和MySQL数据库的电影推荐系统能够有效处理海量数据,提高推荐的准确性和效率。因此,本研究基于这些技术,旨在设计并实现一套高效的电影推荐系统,为用户提供个性化的推荐服务,提升用户体验和满意度。
本研究基于Spark大数据平台、Python编程语言和MySQL数据库,设计并实现了一套电影推荐系统,旨在为用户提供个性化的电影推荐服务。该系统包括登录、系统用户管理、电影信息管理、热门电影管理、系统管理、公告信息管理、资源管理和后台首页等功能模块。通过对用户的历史行为数据和电影内容信息进行分析和处理,系统能够实现精准的电影推荐,提升用户体验和满意度。本研究将深入探讨Spark大数据平台、Python编程语言和MySQL数据库在电影推荐系统中的应用,评估系统的性能和效果,为电影推荐系统的研究和实践提供有益参考。
关键词:Python语言;spark框架;电影推荐系统研究与应用;大数据
Abstract
With the rapid development and popularization of big data technology, movie recommendation systems are playing an increasingly important role in Internet applications. Traditional collaborative filtering based recommendation systems have the problem of low efficiency in processing large-scale data, while movie recommendation systems based on Spark big data platform, Python programming language, and MySQL database can effectively process massive data, improve the accuracy and efficiency of recommendations. Therefore, based on these technologies, this study aims to design and implement an efficient movie recommendation system to provide personalized recommendation services for users, improve user experience and satisfaction.
This study designs and implements a movie recommendation system based on the Spark big data platform, Python programming language, and MySQL database, aiming to provide users with personalized movie recommendation services. The system includes functional modules such as login, system user management, movie information management, popular movie management, system management, announcement information management, resource management, and backend homepage. By analyzing and processing user historical behavior data and movie content information, the system can achieve accurate movie recommendations, improve user experience and satisfaction. This study will delve into the application of Spark big data platform, Python programming language, and MySQL database in movie recommendation systems, evaluate the performance and effectiveness of the system, and provide useful references for the research and practice of movie recommendation systems.
Keywords: Python language; Spark framework; Research and application of movie recommendation systems; Big data
目 录
随着互联网的快速发展和普及,人们对个性化推荐系统的需求日益增加。电影推荐系统作为个性化推荐系统的一个重要应用领域,对于提升用户体验、增加用户粘性具有重要意义。传统的电影推荐系统在处理大规模数据时存在效率低下和准确性不高的问题,而基于大数据技术和机器学习算法的电影推荐系统能够更好地解决这些问题,提高推荐的准确性和效率。因此,本研究选取基于Spark大数据平台、Python编程语言和MySQL数据库的电影推荐系统作为研究对象,旨在探讨如何利用这些先进技术和工具,设计并实现一套高效的电影推荐系统,为用户提供个性化、精准的推荐服务,提升用户体验和满意度。通过对电影推荐系统的研究与应用,旨在推动个性化推荐技术的发展,促进电影产业的数字化转型,为用户提供更优质的服务体验。
随着信息技术的迅速发展和互联网的普及,大数据技术作为一种强大的数据处理和分析工具,正逐渐渗透到各个行业和领域,包括娱乐产业。在电影产业中,大数据技术的应用已经成为提升用户体验、优化资源配置和推动产业发展的重要手段。
电影推荐系统作为大数据技术在娱乐产业中的重要应用领域,具有巨大的潜力和价值。通过大数据技术,电影推荐系统能够收集、存储和分析海量用户数据,包括用户的观影历史、评分偏好、点击行为等,从而深入了解用户的喜好和需求。基于这些数据,系统可以实现个性化推荐,为用户提供符合其口味的电影推荐,提升用户体验和满意度。
此外,大数据技术还可以帮助电影产业更好地了解市场需求和用户趋势,优化资源配置和制作决策。通过分析用户行为和偏好数据,电影公司可以更准确地把握观众喜好,制作更受欢迎的影视作品,提高票房收入和市场竞争力。同时,大数据技术还可以帮助电影公司进行市场营销和推广策略的优化,提高宣传效果和用户参与度。
基于Spark大数据平台、Python编程语言和MySQL数据库的电影推荐系统的研究与应用,将进一步探索大数据技术在电影推荐领域的应用潜力。通过深入研究和实践,我们可以更好地利用大数据技术,推动电影产业的数字化转型,提升用户体验,优化资源配置,促进产业发展,为用户提供更丰富、个性化的电影观影体验。大数据技术在电影推荐系统中的应用,将为电影产业带来新的发展机遇和挑战,推动产业向着更加智能化、个性化的方向发展。
-
- 国内外研究现状
国内研究现状:
在国内,电影推荐系统的研究和实践也取得了显著进展。知名的电影推荐系统网站包括豆瓣电影、腾讯视频、爱奇艺等。豆瓣电影作为国内颇具影响力的电影评分和推荐平台,通过用户评分、评论和标签等信息,为用户提供个性化的电影推荐服务。腾讯视频和爱奇艺等视频平台也拥有强大的推荐系统,通过用户观看历史和行为数据,为用户推荐符合其喜好的影视内容,提升用户体验和观影满意度。
国外研究现状:
在国外,许多知名的电影推荐系统网站应用了先进的推荐技术,为用户提供个性化的推荐服务。其中,Netflix和IMDb等电影网站是国际上备受关注的电影推荐平台。Netflix通过分析用户的观影历史和评分数据,采用先进的推荐算法,为用户推荐个性化的电影和电视剧。IMDb作为全球最大的电影数据库和评分平台,为用户提供了丰富的电影信息和推荐服务,帮助用户发现符合其口味的影视作品。
这些国内外知名的电影推荐系统网站,通过大数据技术和机器学习算法,实现了个性化推荐服务,提升了用户体验和满意度。它们的成功经验和先进技术为电影推荐系统的研究和应用提供了宝贵的参考和借鉴,促进了电影产业的数字化转型和用户体验的提升。通过借鉴和学习这些成功案例,可以进一步推动电影推荐系统的发展,提高推荐的准确性和个性化程度,满足用户对个性化推荐的需求。
早在上个世纪90年代,Python就由詹姆斯·高斯林进行开发,自诞生之日起,Python就一直深深的受到了程序开发者的广泛喜爱,它作为计算机主要的编程语言,一直到今。Python语言是真的是一种纯面向对象的计算机语言,在Python的世界中,所有的方法、数据类型、符号等都是以类的方式存在的,最顶层的就是Object,所有的类都是对object的继承。继承是Python中的核心思想,与C语言不同的是,子类只有一个父类,这样的好处就是操作更加的简便,让人更容易理解,在代码的书写上也会容易较多。Python另外一个特性就是多态性,调用父类接口的方法可以实现子类的实现,这样的好处就是很好的对实现方法进行了隐藏(封装),而且又能够把API进行公开,一举两得。接口思想很好的诠释了想象对象的思想,让面向对象编程渐渐转向面向接口编程。如今,随着编程思想的继续发展,Python也加入了一些函数式编程的思想,这样的好处就是让编程代码更加的简洁与方便。本管理系统采用Python编程语言进行后台的开发,一是鉴于标准化制定以后,Python语言常用于大型商业应用程序后台系统中,生态稳定;二是也希望通过本系统的开发提高自己编写Python代码的能力。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
-
- 大数据技术
大数据技术是指用于处理和分析大规模数据集的技术和工具。在电影推荐系统中,大数据技术发挥着重要作用,帮助系统处理海量用户数据和电影信息,实现个性化推荐和优化用户体验。以下是大数据技术在电影推荐系统中的应用:
数据采集和存储:大数据技术可以帮助电影推荐系统高效地采集、存储和管理海量的用户数据和电影信息。通过分布式存储系统Spark和分布式数据库MySQL,系统能够处理大规模数据并实现快速访问。
数据清洗和预处理:大数据技术可以对原始数据进行清洗、去重和预处理,提高数据质量和准确性。通过数据清洗和预处理,可以消除数据中的噪声和错误,为后续的分析和建模提供高质量的数据基础。
数据分析和挖掘:大数据技术包括数据分析和挖掘工具,如Spark和Hive,能够帮助系统分析用户行为、偏好和电影内容信息,发现隐藏在数据背后的规律和模式,为推荐算法提供支持。
推荐算法:实现个性化推荐。通过协同过滤推荐算法,系统可以根据用户的历史行为和偏好,为用户推荐符合其口味的电影和影视作品。
为了迎合当今社会的现况,便于在市场中打开局面、占有一席之地;在大数据时代下,所有的信息化资源全部都是共享资源、为了长远性考虑,对此需要考虑如何推动整体的系统开发实现标准化。保证系统成功,所以就必须从效益、技术等上面做可行性报告研究。
基于大数据平台的电影推荐系统研究与应用的注册与登陆页面设计简洁容易应用,可以通过最常见的页面窗口来登录页面,并利用过计算机实现登录功能,因此使用者只要平时利用过计算机都可以实现登录应用。此操作系统的研发工作环境运用了Python技术,并运用了B/S结构,这些研发工作环境都使得此系统功能更为完整,使整个设计更为个性化,使用者功能也更为简洁方便。本基于大数据平台的电影推荐系统研究与应用具备了易于运行、容易管理、交互性较好的优点,在实际操作上也是非常简单的。因此,本基于大数据平台的电影推荐系统研究与应用也可进行商业设计。
采用Spark大数据平台、MySQL数据库和可视化大屏技术在电影推荐系统中具有较高的技术可行性。Spark提供高性能的数据处理能力,结合MySQL数据库实现数据存储和管理。可视化大屏技术能直观展示数据分析结果和推荐信息,提高用户体验。这些技术的结合将为系统提供强大的数据处理和存储能力,支持个性化推荐和用户交互,促进电影产业的数字化转型和发展。
正因为本系统是在服务器的基础上开发的,系统开发成功以后,用户无需导航指导便可自己上手进行操作。系统一经开发测试后,在计算机移动客户端能上网的情况下,只需在浏览器里完成所有可用操作,也无需配置复杂的使用环境,只需一个网址便可进入系统。
用户用例图如下所示。
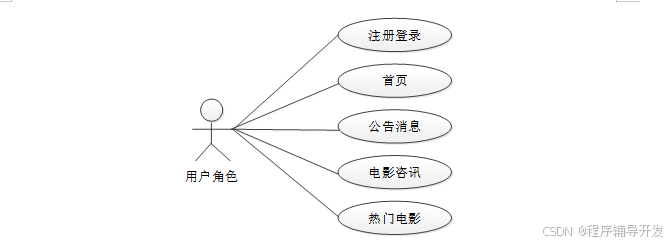
图4-1 用户用例图
管理员用例图如下所示。
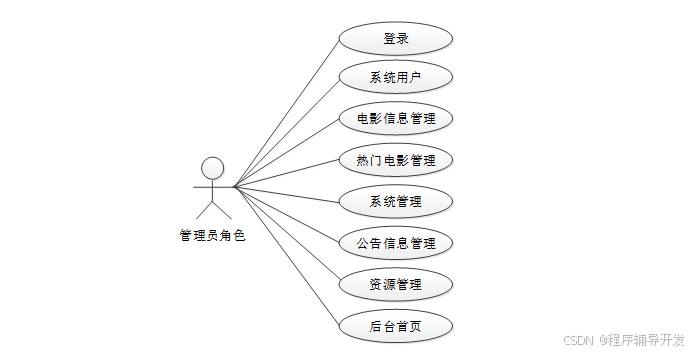
图4-2 管理员用例图
表4-3 公告浏览用例描述
| 描述项 |
说明 |
| 用例名称 |
公告查询 |
| 用例描述 |
用户可以查看公告的详情 |
| 参与者 |
用户 |
| 前置条件 |
使用者是普通用户类型并成功进入该系统 |
| 后置条件 |
浏览成功 |
| 主事件流 |
(1)用户可以浏览公告的模块、公告的内容 (2)用户点击公告可以对公告进行详情阅读 |
| 异常事件流 |
e1.报500错误 e2.数据库连接异常 |
表4-4 个人信息管理用例描述
| 用例名称 |
管理和修改个人信息 |
| 参与者 |
用户 |
| 描述 |
用户查看、修改个人信息 |
| 前置条件 |
用户已登录到系统中 |
| 后置条件 |
无 |
| 事件流 |
(1)用户查看个人信息 (2)用户修改个人信息 |
| 补充说明 |
(a)用户可修改密码 (b)用户可修改个人资料,例如姓名,头像等 |
表4-5 用户管理用例描述
| 描述项 |
说明 |
| 用例名称 |
用户操作 |
| 用例描述 |
管理员正确登录后台管理的条件下,对用户进行管理 |
| 参与者 |
管理员 |
| 前置条件 |
管理员登录成功并跳转到后台主界面 |
| 后置条件 |
操作成功 |
| 主事件流 |
管理员跳转用户管理页面,查询用户详情的信息 管理员可以删除用户信息 |
| 异常事件流 |
e1.报500错误 e2.数据库连接异常 |
表4-6数据信息管理用例描述
| 描述项 |
说明 |
| 用例名称 |
数据信息操作 |
| 用例描述 |
管理员正确登录后台管理的条件下,对数据信息模块进行管理 |
| 参与者 |
管理员 |
| 前置条件 |
管理员成功登录 |
| 后置条件 |
操作成功 |
| 主事件流 |
(1)管理员进入数据信息管理页面,查询数据信息的信息 (2)管理员可以对数据信息进行增删除和编辑数据信息操作 (3)管理员新增数据信息,添加成功跳转到查询页面 |
| 异常事件流 |
e1.报500错误 e2.数据库连接异常 |
管理员权限下的工作流程主要为:管理员通过系统界面提供登录按钮并点击,转入管理员登录界面,并在界面上填入相应的管理员账户和管理员密码,进入管理员权限下的后台系统,并且在系统左侧导航条设置了相应的操作功能。
用户权限下的工作流程主要为:用户通过系统提供的注册功能,进行身份验证并注册,而后在登录界面进行个人身份验证,并且进入用户的个人后台界面,并进行相应的操作。
基于大数据平台的电影推荐系统研究与应用的业务流程如下图所示。
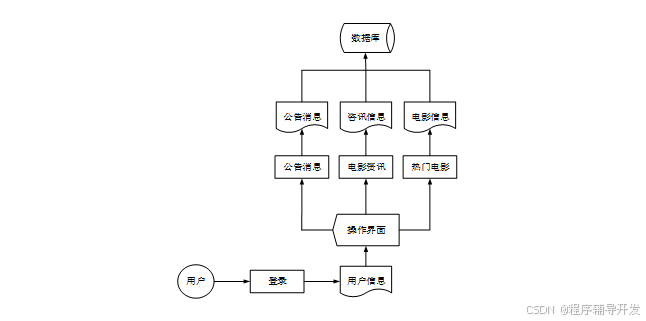
图4-7 系统业务流程图
层次框图是一系列由多层矩形框架组成的树,其顶部为矩形框架,表示整个数据结构,下方的长方形立方体表示独立的数据,下方的长方形表示该数据的实际数据(不能进行分割)。由于这个架构的精炼,层级方块图描述的资料结构也愈加详尽,这个模型很好地满足了需求分析的要求。首先对最上层的信息进行分类,然后在图表中的每个路径上重复地进行优化,直至完整的数据结构被确定。
这个系统由两个模块组成,一是管理员,二是普通用户,这两个部分看起来是独立的,实际上却是连接着数据库,每个模块都有自己的权限,唯一不同的,就是访问的方式不同。在调研资料的基础上,完成了各个模块的功能。在对上述功能进行分析的基础上,本系统提出了两个主要的模块,每个单元可划分为若干小单元。
系统的功能结构图如下图所示。
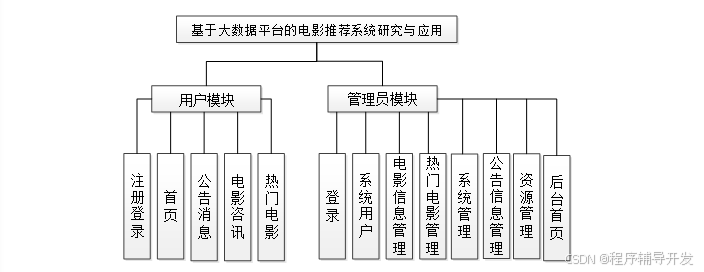
图4-8系统功能结构图
基于大数据平台的电影推荐系统研究与应用总体ER图如下图所示。
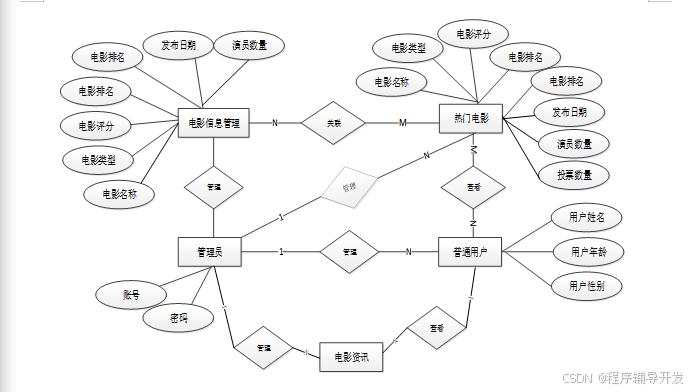
图4-9 总体ER图
所有系统的应用数据相互区分。一旦在相应的系统中实现,它们将与自己相应的网络和服务器通信。所以这个系统可以连接这些数据。当我们选择桥梁截面时,以下将简要介绍如何建立系统。在单击上一个按键的时候,就会自动在对话框中弹出数据源的名字,之后再单击下一个按键时,就在填写相对应的身份验证和登录信息。按照系统功能设计的特点与职能模块的分类,基于大数据平台的电影推荐系统研究与应用的总体设计和实施过程一共涉及到了几个资料表格。
以下就介绍了一些根据各类别主要数据库表的设计结构以及基本功能建立数据库表:
| 编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
| 1 |
token_id |
int |
10 |
0 |
N |
Y |
临时访问牌ID |
|
| 2 |
token |
varchar |
64 |
0 |
Y |
N |
临时访问牌 |
|
| 3 |
info |
text |
65535 |
0 |
Y |
N |
||
| 4 |
maxage |
int |
10 |
0 |
N |
N |
2 |
最大寿命:默认2小时 |
| 5 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
| 6 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
| 7 |
user_id |
int |
10 |
0 |
N |
N |
0 |
用户编号: |
| 编号 |
名称 |
数据类型 |
长度 |
小数位 |
允许空值 |
主键 |
默认值 |
说明 |
| 1 |
article_id |
mediumint |
8 |
0 |
N |
Y |
文章id:[0,8388607] |
|
| 2 |
title |
varchar |
125 |
0 |
N |
Y |
标题:[0,125]用于文章和html的title标签中 |
|
| 3 |
type |
varchar |
64 |
0 |
N |
N |
0 |
文章分类:[0,1000]用来搜索指定类型的文章 |
| 4 |
hits |
int |
10 |
0 |
N |
N |
0 |
点击数:[0,1000000000]访问这篇文章的人次 |
| 5 |
praise_len |
int |
10 |
0 |
N |
N |
0 |
点赞数 |
| 6 |
create_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
创建时间: |
| 7 |
update_time |
timestamp |
19 |
0 |
N |
N |
CURRENT_TIMESTAMP |
更新时间: |
| 8 |
source |
varchar |
255 |
0 |
Y |
N |
来源:[0,255]文章的出处 |
|
| 9 |
url |
varchar |
255 |
0 |
Y |
N |
来源地址:[0,255]用于跳转到发布该文章的网站 |
|
| 10 |
tag |
varchar |
255 |
0 |
Y |
N |
标签:[0,255]用于标注文章所属相关内容,多个标签用空格隔开 |
|
| 11 |
content |
longtext |
2147483647 |
0 |
Y |
N |
正文:文章的主体内容 |
|
| 12 |
img |
varchar |
255 |
0 |
Y |
N |
封面图 |
|
| 13 |
description |
text |
65535 |
0 |
Y |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









