






并发
任务数多于CPU核数,通过操作系统的各种任务调度算法,实现多个任务一起执行(由于切换速度很快,看起来像是一起执行,实际上总有一些任务不在执行而是处于挂起状态)
并行
任务数小于等于CPU核数,即任务是真正的一起执行
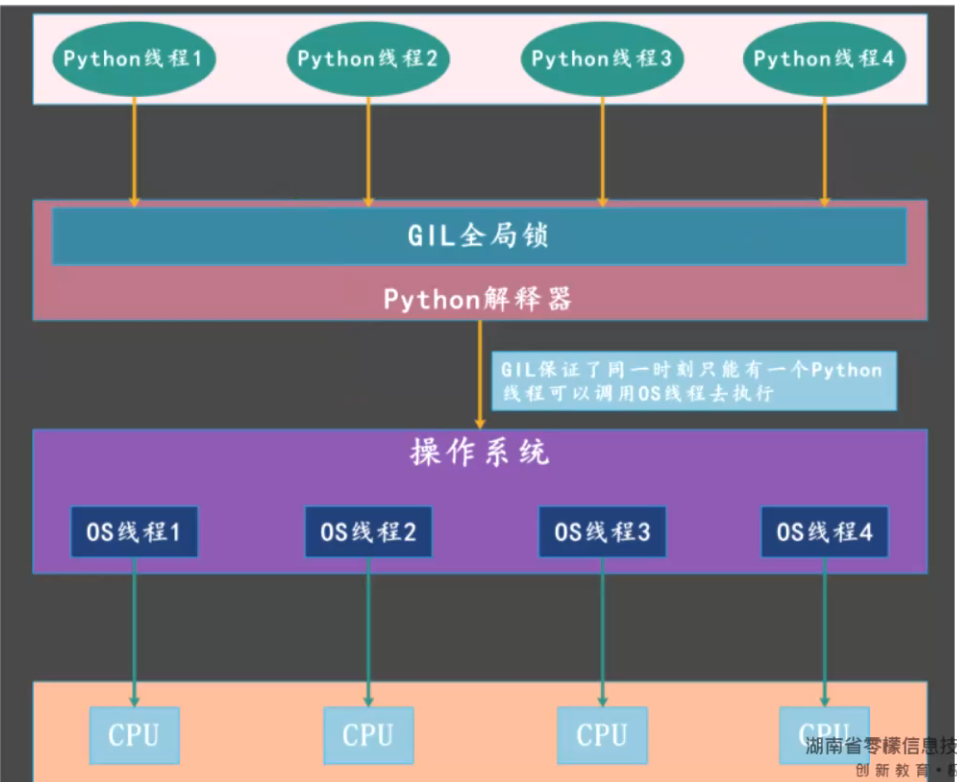
python并发的实现
# 同步和异步
# 同步,协同步调,线程在访问某一资源时,获得了资源的返回结果之后才会执行其他操作(先做某件事,完成后再做另外一件事)
# 异步,步调各异,线程在访问某一资源时,无论是否取得返回结果,都进行下一步操作;当有了资源返回结果时,系统自会通知线程
# (如页面加载下一页数据时,可以操作点击登录等其他功能)
# 多线程实现并发
# 线程(英语:thread)是操作系统能够进行运算调度的最小单位。
# 它被包含在进程之中,是进程中的实际运作单位。
# 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
import time
from threading import Thread
def work1(name):
for i in range(5):
time.sleep(1)
print(f'work1-----------{name}')
def work2(name):
for i in range(3):
time.sleep(1)
print(f'work2-----------{name}')
# 适用于不同线程执行不同的任务
def main():
# 1、创建线程,把要执行的任务函数传给target,任务函数传参方式args位置参数,传元组类型;kwargs关键字参数,传字典类型
t1 = Thread(target=work1, args=('ran',))
t2 = Thread(target=work2, kwargs={'name': 'could'})
# 2、启动线程
t1.start()
t2.start()
print('这里子线程去执行对应的任务,同时主线程会继续往下走')
# 3、等待线程执行,默认等待执行完毕,可以传参设置等待时长;如果不写join()主线程不会等待子线程完毕,main()函数执行完毕直接往下继续走
t1.join()
t2.join()
print('写了join()后主线程会等待子线程执行完毕,才会执行到这里')
main()
# 适用于开启多个线程,执行同样的任务
# 通过继承线程类,重写run方法把要执行的任务写到run方法里面,来开启多线程
class RequestApi(Thread):
def __init__(self, url):
self.url = url
super().__init__()
def run(self) -> None:
# 定义线程对象要执行的任务
time.sleep(1)
print(self.url)
for url in range(100):
t = RequestApi(url) # 会瞬间开启100个线程去执行run方法
t.start()
协程
# 协程,可以理解为程序内部微小的线程,由程序本身去调度
# 协程是线程中的一个特殊函数,这个函数执行的时候可以在某个地方暂停,并且可以在暂停处继续运行
# 协程在进行切换的时候只需要保存当前协程函数中一些临时变量信息等,然后切换到另一个函数中去执行,并且切换次数及切回时机都可以自定义
# 协程切换的时候,既不涉及资源切换,也不涉及操作系统调度,而是在同一个程序中切换不同的函数执行,所以占用资源很少,切换较快
# Python3.4以前版本如果要实现协程,需要通过生成器去实现
# Python3.4新增一个模块asyncio,可以通过asyncio去实现协程
# Python3.5新增async、await两个关键字来实现协程
# 协程函数,通过async、await语法定义的函数叫协程函数
# 协程对象,调用协程函数,返回的对象叫协程对象
# 时间循环机制,不断的去循环里面已经注册的任务是不是处于一个可执行的状态,如果是就会执行,遇到IO耗时等待就会循环其他任务,直到遇到可执行任务
# 它管理一个任务列表(协同程序)并尝试在循环的每次迭代中按顺序推进每个任务,以及执行其他任务,如执行回调和处理 I/O。
# import asyncio
# 1、 创建事件循环
# loop = asyncio.get_event_loop()
# 2、 启动时间循环
# loop.run_until_complete(asyncio.wait('任务函数'))
# Python3.7之后直接使用async.run()来代替上面的两行代码
# await关键字后面只能写可等待对象(任务、协程、future)等
# 协程任务函数在进行到await的时候会释放执行权限,可以切换到其他的协程函数
import asyncio
async def work1():
for i in range(3):
print(f'--work1------{i}-----------')
await asyncio.sleep(1) # 会转化成等待1秒钟的任务;如果直接使用tiem.sleep(1)不会切换任务
async def work2():
for i in range(5):
print(f'--work2------{i}-----------')
await asyncio.sleep(1)
# async def main():
# task1 = asyncio.create_task(work1()) # create_task创建任务
# task2 = asyncio.create_task(work2())
# await task1
# await task2
# asyncio.run(main()) # 等同于下面两行代码
task = [work1(), work2()]
asyncio.run(asyncio.wait(task)) # 原理同上面main()代码
# 异步请求,瞬间实现高并发;异步编程库较少,所以应用较少
import asyncio
from aiohttp import ClientSession # 异步请求
async def work():
url = 'www.test.com'
async with ClientSession() as cs:
async with cs.get(url) as response:
res = await response.read()
print(res)
await asyncio.sleep(1)
gs = [work() for i in range(5)]
asyncio.run(asyncio.wait(gs))
协程gevent
import time
import gevent
from gevent import monkey # gevent补丁,补丁只在单线程内有效
monkey.patch_all(ssl=False) # 遇到等待,异步执行,同步改为异步
def work1(name):
for i in range(3):
print(f'--work1------{i}------{name}-----')
time.sleep(1)
# gevent.sleep(1)
def work2(name):
for i in range(5):
print(f'--work2------{i}-------{name}----')
time.sleep(1)
g1 = gevent.spawn(work1, 'sss') # 任务函数传参方法
g2 = gevent.spawn(work2, 'lll')
g1.join()
g2.join()
多线程共享全局变量
# Python多线程是并发执行的,不是并行;因为CPython解释器中存在全局解释器锁(GIL),真正同时只有一个任务在执行,所以是伪多线程
# 多线程是可以共享全局变量的
# 多线程共享全局变量会面临的问题是 资源竞争
# 由于全局解释器锁(GIL)的存在,会出现代码执行一半的时候钥匙被Python解释器释放出来被其他线程拿去,等再次拿回钥匙的时候全局数据会丢失一部分
# 优化一,可以通过加锁的方式去解决
# 必须要使用同一把锁,会降低代码的执行效率
# 避免出现死锁,在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁
# 比如,创建两把锁,线程A获取a锁,在等待b锁;线程B获取b锁,在等待a锁
from threading import Thread, Lock
a = 0
lock_a = Lock()
def work1():
global a
for i in range(5000000):
lock_a.acquire() # 加锁
a += 1 # 如果不加锁,执行到这的时候GIL可能会被释放,代码执行到一半,等再次拿回GIL时会使用原有的变量值运行,造成数据丢失
lock_a.release() # 释放锁
print('work1 ', a)
def work2():
global a
for i in range(5000000):
lock_a.acquire()
a += 1
lock_a.release()
print('work2 ', a)
def main():
t1 = Thread(target=work1)
t2 = Thread(target=work2)
t1.start()
t2.start()
t1.join()
t2.join()
print(a)
main()
多进程
# 进程(Process)是系统进行资源分配的基本单位,是操作系统结构的基础。
# 多进程使用方法同多线程
# Windows需要注意的一点是,进程的创建不能直接定义在模块中,否则启动后会陷入无限递归中
# 如果要定义在模块里,请写在 if __name__ == '__main__': 里
# 或者将进程创建的代码封装到方法里
# linux或者Mac没有这个问题
# 创建一个进程并准备资源数据等所需要占用的时间要大于创建一个线程
import time
from multiprocessing import Process
def work1(name):
for i in range(5):
time.sleep(1)
print(f'work1-----------{name}')
def work2(name):
for i in range(3):
time.sleep(1)
print(f'work2-----------{name}')
def main():
p1 = Process(target=work1, args=('sss',))
p2 = Process(target=work2, args=('lll',))
p1.start()
p2.start()
p1.join() # 主进程等待子进程执行完毕
p2.join() # 主进程等待子进程执行完毕
print(time.time()) # 主进程等待子进程执行完毕后才会执行到这里,如果没有join(),主进程直接执行到这里,不会等待子进程
if __name__ == '__main__':
main()
# 也可以通过创建类并继承Process,并重写run方法来开启多进程,类似多线程
class P1(Process):
def run(self) -> None:
pass
多进程间的数据通讯
# 进程之间数据是独立的,无法共享全局变量
# 下方案例中,主进程只是创建了2个子进程,变量a没有任何改变,所以主进程的a=0,2个子进程中的a都是5000000
# from multiprocessing import Process
#
# a = 0
#
# def work1():
# global a
# for i in range(5000000):
# a += 1
# print('work1 ', a)
#
#
# def work2():
# global a
# for i in range(5000000):
# a += 1
# print('work2 ', a)
#
#
# def main():
# p1 = Process(target=work1)
# p2 = Process(target=work2)
# p1.start()
# p2.start()
# p1.join()
# p2.join()
# print(a)
#
# if __name__ == '__main__':
# main()
# from queue import Queue 进程内可使用的队列,无法跨进程使用
# from multiprocessing import Queue 进程模块中的队列可以跨进程使用,来实现进程间的数据通讯
# 进程间的队列使用注意点,需要把队列通过传参的形式,传到各个进程中
from multiprocessing import Process, Queue
def work1(q):
a = q.get()
for i in range(5000000):
a += 1
q.put(a)
print('work1 ', a)
def work2(q):
a = q.get()
for i in range(5000000):
a += 1
q.put(a)
print('work2 ', a)
def main():
q = Queue() # 定义队列
q.put(0) # 往队列添加一个值
p1 = Process(target=work1, args=(q,)) # 把队列传到进程里
p2 = Process(target=work2, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
print(q.get())
if __name__ == '__main__':
main()
进程池
# 使用进程池可以避免频繁的去创建进程和销毁进程
import time
from multiprocessing import Pool
# def work1(name):
# for i in range(5):
# time.sleep(1)
# print(f'work1-----------{name}')
#
#
# def work2(name):
# for i in range(3):
# time.sleep(1)
# print(f'work2-----------{name}')
# if __name__ == '__main__':
# pp = Pool(2) # 创建进程池,设置数量3
# pp.apply_async(func=work1, args=('sss',)) # 异步执行,提交任务函数,函数参数等
# pp.apply_async(func=work2, args=('lll',)) # 使用异步执行,里面有错误信息不会报出来,可以改为同步执行方法apply查看
# pp.apply_async(func=work1, args=('sss2',)) # 如果进程池已满,会等待其他进程任务执行完成后有空余进程执行剩下的任务
# pp.close() # 要先关闭进程池,关闭后不可往进程池里继续提交任务
# pp.join() # 关闭进程池后,才可以使用主进程阻塞,等待子进程执行完成
# 进程池之间的数据通讯,需要用到进程池之间专用的队列 Manager().Queue()
from multiprocessing import Pool, Manager
def work1(q):
a = q.get()
for i in range(5000000):
a += 1
q.put(a)
print('work1 ', a)
def work2(q):
a = q.get()
for i in range(5000000):
a += 1
q.put(a)
print('work2 ', a)
def main():
q = Manager().Queue() # 创建队列
q.put(0) # 往队列添加一个值
pp = Pool(2)
pp.apply_async(func=work1, args=(q,)) # 把队列传到进程里
pp.apply_async(func=work2, args=(q,))
pp.close()
pp.close()
pp.join()
pp.join()
print(q.get())
if __name__ == '__main__':
main()
进程池和线程池
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def work1(name):
for i in range(5):
time.sleep(1)
print(f'work1-----------{name}')
def work2(name):
for i in range(3):
time.sleep(1)
print(f'work2-----------{name}')
# if __name__ == '__main__':
# tp = ThreadPoolExecutor(2) # 设置线程池中线程的数量
# tp.submit(work1, 'sss') # 往线程池提交任务函数,如果任务函数有参数,直接往后面写即可
# tp.submit(work2, name='lll') # 提交的任务函数如有参数,传参也可以关键字传参
# tp.shutdown() # 等待线程池中的子线程执行结束
# print('---------end-----------')
# 由于线程池实现了上下文管理器协议,所以可以使用with方法去操作,在执行完with语句所有代码后会自动等待线程池中的所有子线程代码执行完成
with ThreadPoolExecutor(2) as tp:
tp.submit(work1, 'sss')
tp.submit(work1, 'lll')
print('---------end-----------') # 执行完with语句所有代码后会自动等待线程池中的所有子线程代码执行完成
# 进程池使用方法同线程池
# if __name__ == '__main__':
# with ProcessPoolExecutor(2) as tp:
# tp.submit(work1, 'sss')
# tp.submit(work1, 'lll')
# print('---------end-----------')
队列
from queue import Queue, LifoQueue, PriorityQueue # 官方库
# from queue import Queue 进程内可使用的队列,无法跨进程使用
# from multiprocessing import Queue 进程模块中的队列可以跨进程使用
# Queue 先入先出队列
# LifoQueue 后入先出队列
# PriorityQueue 优先级队列
# 三种队列使用方法一致,PriorityQueue优先级队列会多出一个优先级的参数
# PriorityQueue队列以元组形式传参,(优先级,数值),优先级越小,越先执行
# 尽量优先级不要设置一样,如果一样会比较后面数值的大小,如果数据类型不一致会抛出异常
# q = PriorityQueue()
# q.put((3, 'a'))
# q.put((2, 'b'))
# print(q.get()) # (2, 'b')
# get和put使用一样,如果列表为空,get会一直等待,同样可以使用block和timeout参数以及get_nowait()
# get_nowait()、get(block=False)、get(timeout=2) 如果队列为空会抛出_queue.Empty异常
q = Queue(maxsize=4) # maxsize自定义队列长度,默认长度无限制
q.put(1) # 往队列中添加数据
q.put(2)
q.put(3)
q.put(4) # 如果队列已满,会阻塞到这里进行等待,队列有位置后再添加进去
# q.put(5, block=False) # 设置添加队列不等待,如果已满直接抛出队列已满queue.Full异常
# q.put_nowait(5) # 等同于q.put(5, block=False)
# q.put(6, timeout=2) # timeout设置添加队列等待2秒
size = q.qsize() # 获取队列长度
print(size) # 4
print(q.empty()) # 判断队列是否为空,为空返回True,不为空返回False
print(q.full()) # 判断队列是否已满,已满返回True,未满返回False
vaule = q.get() # 获取队列的值
print(vaule) # 1
# 队列中可以添加任何数据类型,包括函数等,可以把队列中的每个值看做一个任务
# 每个任务get后使用task_done()方法向队列发送该任务已执行完毕的信息
# 等队列中所有任务都执行完毕后,join()方法才会执行
q1 = Queue()
for i in range(5):
q1.put(i)
for i in range(5):
print(q1.get())
# q1.task_done() # 向队列发送该次get获取的任务已经执行完毕
q1.join() # 等待队列中所有任务执行完毕,才会执行join()
socket通讯
# socket(简称 套接字)是进程间通讯的一种方式
from socket import socket, AF_INET, SOCK_STREAM, SOCK_DGRAM
# TCP通讯-------------------------------------
# 创建一个TCP套接字
conn = socket(AF_INET, SOCK_STREAM)
# 连接服务器,域名和端口以元组形式传参
conn.connect(('www.baidu.com', 80))
# 编排数据并发送,HTTP协议的需要严格按照HTTP协议报文格式编排
data = 'GET / HTTP/1.1\r\n'
data += 'Host: www.baidu.com\r\n'
data += '\r\n\r\n'
conn.send(data.encode('utf-8'))
# 接收消息,需要传递个参数为接收消息的字节大小
resp = conn.recv(1024)
print(resp)
conn.close()
# 客户端
from socket import socket, AF_INET, SOCK_STREAM, SOCK_DGRAM
conn = socket(AF_INET, SOCK_STREAM)
conn.connect(('127.0.0.1', 8899))
data = 'hello, python'
conn.send(data.encode())
content = ''
while True: # 客户端去接收数据,防止数据过大不能接收完整
resp = conn.recv(1024)
if resp:
print(resp) # 接收的是二进制的数据
print(resp.decode()) # 转换成字符串
content += resp.decode()
else:
break
conn.close()
基于socket实现TCP服务器
from socket import socket, AF_INET, SOCK_STREAM
# 基于socket实现TCP的服务器---------------------
# 创建套接字
# server = socket(AF_INET, SOCK_STREAM)
#
# # 绑定ip和端口,ip和端口以元组形式传参
# server.bind(('127.0.0.1', 8899)) # 同一ip端口只允许同时开启一个服务,否则会报错
#
# # 监听客户端的连接,设置最大的客户端连接数
# server.listen(100)
#
# # 等待客户端连接
# # 默认阻塞在这里,等待客户端的连接以后才会继续往下执行,server.accept()返回的是客户端的套接字和客户端ip地址
# cli_sock, address = server.accept()
# # (<socket.socket fd=368, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 8899), raddr=('127.0.0.1', 57010)>,
# # ('127.0.0.1', 57010))
#
# # 设置接收客户端发送数据字节的大小
#
# info = cli_sock.recv(1024)
# print(info.decode()) # 数据解码,转换成字符串
#
#
# # 给客户端回复消息
# data = 'server okay'
# cli_sock.send(data.encode()) # 编码发出
# 如果要实现HTTP协议的服务,回复的消息需要严格按照HTTP协议格式进行编排--------
# header = 'HTTP/1.1 200 OK\r\n'
# header += 'Content-Type: text/html;charset=utf-8\r\n'
# header += '\r\n\r\n'
# body = '收到'
# data = header + body
# cli_sock.send(data.encode())
# 使用线程,优化服务
from threading import Thread
num = 1
def handle_request(cli_sock):
global num
num += 1
content = ''
while True: # 完整接收客户端发送的数据
res = cli_sock.recv(1024) # 如果接收内容为空,程序会阻塞在这里
print(res.decode())
if len(res) < 1024: # 存在个bug,由于接收内容为空时会阻塞在recv,所以这么判断的话如果刚好有1024个字节会卡在recv
content += res.decode()
break
else:
content += res.decode()
header = 'HTTP/1.1 200 OK\r\n'
header += 'Content-Type: text/html;charset=utf-8\r\n'
header += '\r\n\r\n'
body = f'收到{num}' # 每次请求会+1,浏览器请求会自动多加一个标签左侧图标的请求,所以次数是每次+2
data = header + body
cli_sock.send(data.encode())
cli_sock.close()
server = socket(AF_INET, SOCK_STREAM)
server.bind(('192.168.0.63', 8899)) # 修改下本地计算器防火墙的入站规则,同一局域网内的其他设备即可访问该服务
server.listen(100)
while True: # 服务一直运行,而不是一次请求后就关闭
cli_sock, address = server.accept()
Thread(target=handle_request, args=(cli_sock,)).start()
















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









