






引入xml文件约束的两种方式:
1.使用dtd约束
DTD:约束xml,可以有哪些标签,标签数量,标签关系,标签顺序,以及属性
!DOCTYPE 声明文档的类型固定的
<!DOCTYPE 标签名 SYSTEM "dtd文件名.dtd">
!ELEMENT:声明元素(声明标签)
students:标签名
(student):子标签
(student):必须有1个student子标签并且只能有一个;
(student?):0个或者1个;
(student+):至少1个;
(student*):0~多个
students(student):students标签中有student子标签;
student (name*,age,sex):student标签中有name,age,sex 子标签
注:使用标签时顺序必须和指定的顺序一致;
#PCDATA:字符串类型的值;
name(#PCDATA):name标签中字符串值;
!ATTLIST:声明属性
student:为哪个标签指定属性;
id:自定义属性名
CDATA:属性控制,固定
#REQUIRED:必须有;
#IMPLIED:可选;
#FIXED:固定值“值”;
#FIXED "128":固定值为128;
2.使用xsd约束
<根标签名 xmlns:自定义="http://www.w3.org/2001/XMLSchemainstance" 自定义:noNamespaceSchemaLocation="xsd文件.xsd">
xs:schema = xs(自定义名称):schema(固定)
xmlns:xs:xmlns(固定):xs(自定义名称)=“
http://www.w3.org/2001/XMLSchema
”(固定的)
xs:element 定义标签 name = 标签名(自定义)
xs:complexType 定义复杂类型,子标签(指定了子标签的使用顺序),属性
xs:sequence 指定子标签的顺序
maxOccurs=该标签出现的次数,(自定义数字) ref=引用指定标签
子标签顺序,type 指定标签中的内容类型 例:xs:string
xs:attribute:设置标签属性
name="id" 该属性可选
default:属性默认值
use:required 必要的,optional 可选的,prohibited 禁止的
fixed=“自定义” 固定值
使用DOM解析xml文件过程以及步骤和创建
解析
//使用DOM解析xml文件
public static void DOMParse(String path) throws Exception{
//获取文档构建工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//根据文档构建工厂获取文档构建器(解析xml文件的构建器)
//(文档构建器的作用为1.将xml解析成document(文档) 2.构建文档)
DocumentBuilder builder = factory.newDocumentBuilder();
//使用文档构建起解析xml,将xml解析出的内容存储在document对象中;
//注传递进来的参数为xml文件的引用,(也就是xml文件的位置)
Document parse = builder.parse(path);
//获取根节点对象(parse.getFirstChild()获取文件中的第一个节点对象,也就是根节点,
Node firstChild = parse.getFirstChild();
//获取根节点名字(getNodeName()获取节点名字)
String nodeName = parse.getFirstChild().getNodeName();
//输出根节点名字
System.out.println("根节点为:"+nodeName);
//获取根节点中的所有子节点
NodeList childNodes = firstChild.getChildNodes();
//获取根节点中的子节点对象(使用遍历的方式将集合中的对象获取)
for (int i = 0; i < childNodes.getLength(); i++) {
//表示拿到的根节点下面第一个节点对象
Node item = childNodes.item(i);
//判断每次拿到的节点对象是否是节点对象(因为在解析的时候空文本也是一个节点对象)
if(item.getNodeType() == Node.ELEMENT_NODE){
//获取最后的子节点对象
NodeList lastChild = item.getChildNodes();
//输出第二层节点的节点名
System.out.println("第二层节点为:"+item.getNodeName());
//循环遍历拿出最后的字节点
for (int j = 0; j < lastChild.getLength(); j++) {
//表示拿到的第二层节点中的第一个节点
Node lastItem = lastChild.item(j);
//判断每次拿到的节点对象是否是节点对象(因为在解析的时候空文本也是一个节点对象)
if(lastItem.getNodeType() == Node.ELEMENT_NODE) {
//如果是的话就进行输出(getNodeName():获取名字 getTextContent():获取标签名对象中的文本内容 )
System.out.println("第三层节点:"+lastItem.getNodeName() + ",节点中的内容:" + lastItem.getTextContent());
//注:如果还有节点对象就再次获取子节点循环再判断
}
}
}
}
}
xml文件图
结果图

使用DOM进行创建xml文件
//使用DOM创建xml文件
public static void DOMCreate(String path) throws Exception{
//创建文档构建工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//根据文档构建工厂获取文档构建器
//(文档构建器的作用为1.将xml解析成document(文档) 2.构建文档)
DocumentBuilder builder = factory.newDocumentBuilder();
//获取将document转换为xml文件的转换器工厂
TransformerFactory transformerFactory = TransformerFactory.newInstance();
//使用文档构建器,创建document(文档)对象
Document document = builder.newDocument();
//创建标签
Element students = document.createElement("students");
Element student = document.createElement("student");
Element name = document.createElement("name");
//可在标签中设置文本内容(其它标签也是如此)
name.setTextContent("....");
Element age = document.createElement("age");
Element sex = document.createElement("sex");
//为标签指定关系,(例根标签子标签啥的)
//appendChild(student)表示students的子标签为student(其它亦是如此)
students.appendChild(student);
student.appendChild(name);
student.appendChild(age);
student.appendChild(sex);
//将根元素添加到文档中
document.appendChild(students);
//设置为独立的xml
document.setXmlStandalone(true);
//将document转换为xml,将xml输出到指定的位置
//根据将document转换为xml的转换器工厂获取转换器
Transformer transformer = transformerFactory.newTransformer();
//输出后的xml进行标签格式化(输出并设置属性)
transformer.setOutputProperty(OutputKeys.INDENT,"yes");
transformer.setOutputProperty("{https://xml.apache.org/xslt}indent-amount","2");
//将document转换为xml,将xml输出到指定的位置
transformer.transform(new DOMSource(document),new StreamResult(new FileOutputStream(path)));
}
创建后结果图
使用SAX进行解析和创建
解析
//使用SAX解析xml文件
public static void SAXParse(String path) throws Exception{
//获取SAX解析器工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//根据解析器工厂获取解析器
SAXParser saxParser = factory.newSAXParser();
//开始解析xml,(由于sax将解析xml的过程进行了封装,所以解析对应节点时,自动调用相关方法即可)
saxParser.parse(new FileInputStream(path),new MyHandler());
}
//自定义解析
static class MyHandler extends DefaultHandler{
//解析头标签
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("头标签"+qName);
}
//解析标签中的文本内容
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String s = new String(ch,start,length);
System.out.println("标签内容" +s);
}
//解析尾标签
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("尾标签"+qName);
}
}
xml文件图
运行结果图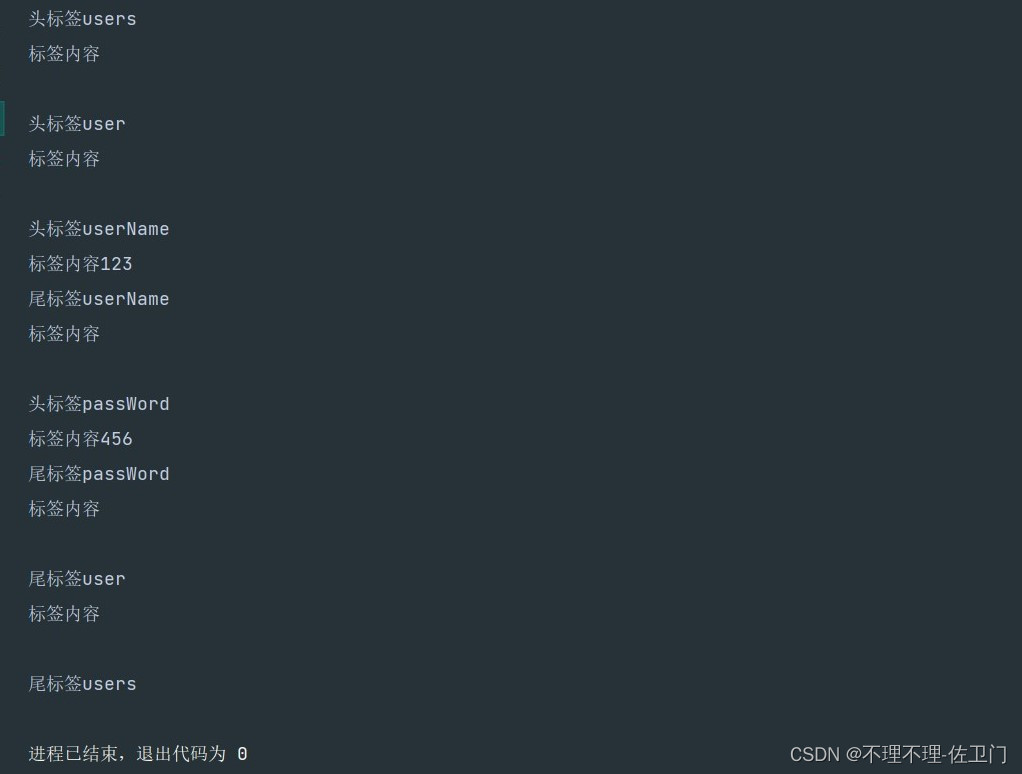
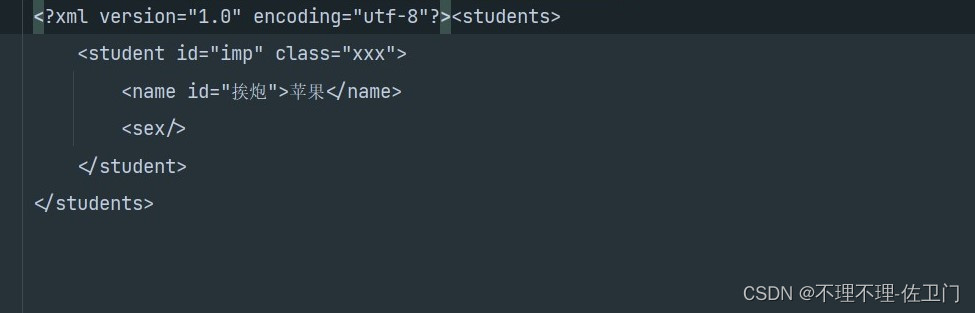
使用SAX进行创建xml文件
//使用SAX生成xml文件
public static void SAXCreate(String path) throws Exception{
//获取SAX转换器工厂,强转为子类,(因为需要用到子类中的方法)
SAXTransformerFactory factory =(SAXTransformerFactory) SAXTransformerFactory.newInstance();
//根据转换工厂获取转换器和执行器
//执行器
TransformerHandler handler = factory.newTransformerHandler();
//获取转换器
Transformer transformer = handler.getTransformer();
//进行添加标签的格式化
transformer.setOutputProperty(OutputKeys.INDENT,"yes");
transformer.setOutputProperty(OutputKeys.ENCODING,"utf-8");
transformer.setOutputProperty("{https://xml.apache.org/xslt}indent-amount", "2");
//执行xml文件(输出的地址)
handler.setResult(new StreamResult(new FileOutputStream(path)));
//编写xml文件
handler.startDocument();
//头标签(根标签)
handler.startElement(null,null,"students",null);
//设置属性
AttributesImpl attributes = new AttributesImpl();
attributes.addAttribute(null,null,"id","String","imp");
attributes.addAttribute(null,null,"class","String","xxx");
//添加第二层标签
handler.startElement(null,null,"student",attributes);
//设置三层的属性
AttributesImpl attributes1 = new AttributesImpl();
attributes1.addAttribute(null,null,"id","String","挨炮");
//添加第三层标签,也就是student中的标签
handler.startElement(null,null,"name",attributes1);
//在name标签中添加文本内容
char[] chars = "苹果".toCharArray();
handler.characters(chars,0, chars.length);
//name的尾标签
handler.endElement(null,null,"name");
//添加student中的sex标签
handler.startElement(null,null,"sex",null);
//sex的尾标签
handler.endElement(null,null,"sex");
//student的尾标签
handler.endElement(null,null,"student");
//students的尾标签
handler.endElement(null,null,"students");
//编写结束
handler.endDocument();
}
创建后结果图
谢谢你长得那么好看还点击我的内容!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









