






赛题介绍:
RNA (核糖核酸) 在细胞生命活动中扮演着至关重要的角色,从基因表达调控到催化生化反应,都离不开 RNA 的参与。RNA 的功能很大程度上取决于其三维 (3D) 结构。理解 RNA 的结构与功能之间的关系,是生物学和生物技术领域的核心挑战之一。RNA 折叠 是指 RNA 序列自发形成特定三维结构的过程。而 RNA 逆折叠 则是一个更具挑战性的问题,即基于给定的RNA 三维骨架结构设计出能够折叠成这种结构的 RNA 序列。本次赛题的核心是 RNA 逆折叠问题,具体来说,是基于给定的 RNA 三维骨架结构,生成一个或多个 RNA 序列,使得这些序列能够折叠并尽可能接近给定的目标三维骨架结构。评估标准是序列的恢复率 (recovery rate),即算法生成的 RNA 序列,在多大程度上与真实能够折叠成目标结构的 RNA 序列相似。恢复率越高,表明算法性能越好。
实现的技术路径:
AI 驱动的生成模型:如上海元码智药近期获批的 “双曲离散扩散模型”,通过双曲等变图神经网络(Hyperbolic Isometric Graph Neural Network)将 RNA 结构嵌入几何空间,结合扩散过程逐步去噪,实现高效序列生成。
物理模型与数据融合:结合第一性原理(如自由能计算)与大规模实验数据(如 siRNA 药物研发数据集),提升模型的泛化能力
相关专业概念:
1.RNA干扰(RNAi)
通过小干扰RNA(siRNA)等沉默特定基因的表达。siRNA结合靶mRNA诱导RISC切割mRNA实现沉默靶基因,在疾病基因疗法中发挥作用。
可在siRNA分子中引入化学修饰,以增强其稳定性、靶向性和有效性,形成化学修饰siRNA,
2. 深度学习与RNN
深度学习:一种擅长处理复杂非线性关系和高维数据的机器学习方法。
递归神经网络(RNN):一类适用处理序列数据的深度学习模型。
3. 词汇表与序列编码
输入深度学习模型时,需将基因序列数据转换为数值表示形式,词汇表即映射方
训练模型代码:
导入模块
主要用的是pytorch框架
#import 相关库
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch_geometric.data import Data, Batch
from torch_geometric.nn import GCNConv, global_mean_pool
import torch_geometric
from Bio import SeqIO数据探索
数据探索性分析,是通过了解数据集,了解变量间的相互关系以及变量与预测值之间的关系,对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法,从而帮助我们后期更好地进行特征工程和建立模型,是机器学习中十分重要的一步。
# 数据探索性分析模块
# 查看coords seqs文件有多个个
seqs=glob.glob("./RNAdesignv1/train/seqs/*.fasta")
coords=glob.glob("./RNAdesignv1/train/coords/*.npy")
print(f"RNA序列文件有 {len(seqs)}个, 坐标文件有 {len(coords)}个")
#RNA序列文件有 2317个, 坐标文件有 2317个
#查看npy的数据类型
import numpy as np
file_path= "./RNAdesignv1/train/coords/1A9N_1_Q.npy"
data = np.load(file_path)
print(data.shape)
#(24, 7, 3)对RNA序列的长度信息进行统计
import os
from Bio import SeqIO
import matplotlib.pyplot as plt
def calculate_sequence_lengths(folder_path):
sequence_lengths = []
for filename in os.listdir(folder_path):
if filename.endswith('.fasta'):
file_path = os.path.join(folder_path, filename)
try:
for record in SeqIO.parse(file_path, 'fasta'):
sequence_lengths.append(len(record.seq))
except Exception as e:
print(f"Error reading {file_path}: {e}")
return sequence_lengths
def plot_histogram(sequence_lengths):
plt.figure(figsize=(10, 6))
plt.hist(sequence_lengths, bins=50, edgecolor='black')
plt.title('Distribution of RNA Sequence Lengths')
plt.xlabel('Sequence Length')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
if __name__ == "__main__":
folder_path = './RNAdesignv1/train/seqs/' # 请将此路径替换为你的文件夹路径
lengths = calculate_sequence_lengths(folder_path)
print(lengths)
plot_histogram(lengths)
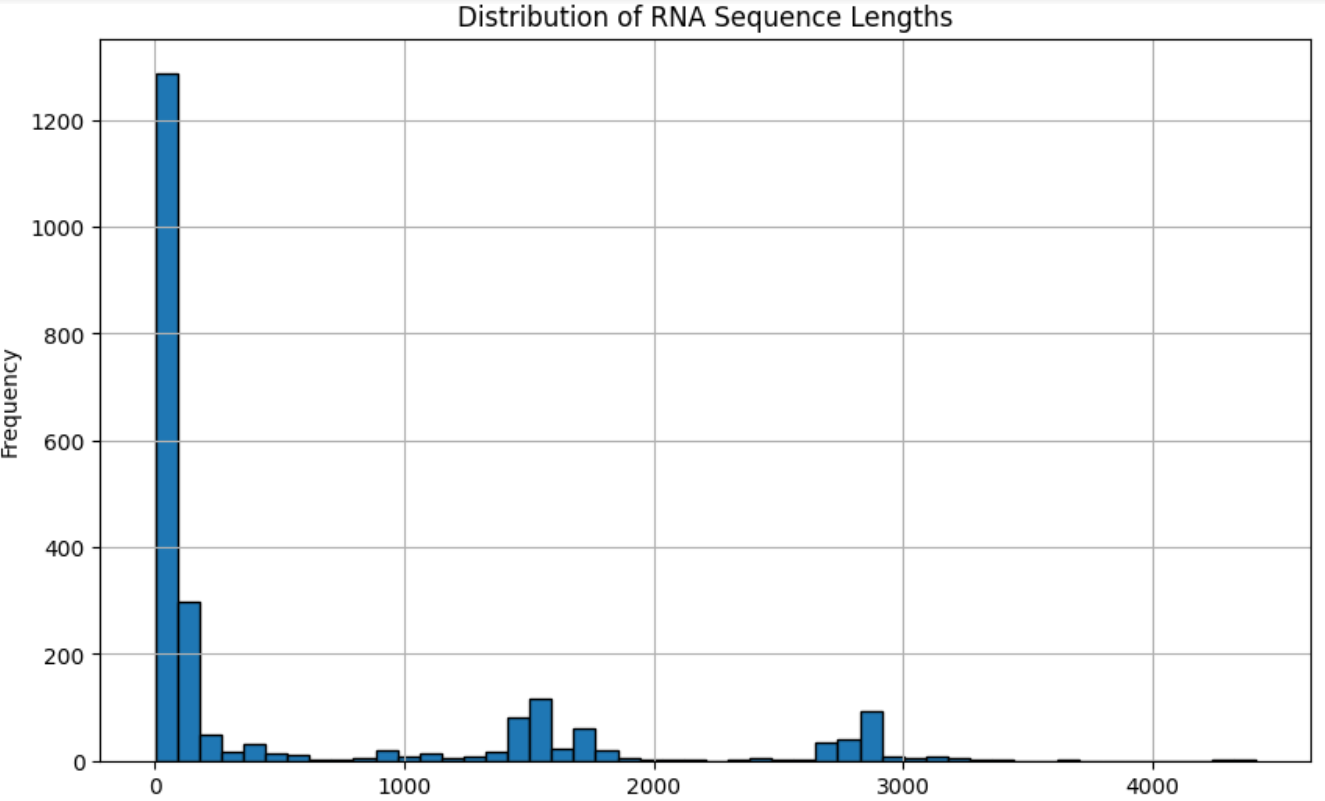
从图中我们可以看到RNA序列长度之间有较大的差异,这样不同的RNA序列需要做好填充后才能 放到模型运行
特征构建
# 图结构数据生成器
class RNAGraphBuilder:
@staticmethod
def build_graph(coord, seq):
"""将坐标和序列转换为图结构"""
num_nodes = coord.shape[0]
# 节点特征:展平每个节点的7个骨架点坐标
x = torch.tensor(coord.reshape(num_nodes, -1), dtype=torch.float32) # [N, 7*3]
# 边构建:基于序列顺序的k近邻连接
edge_index = []
for i in range(num_nodes):
# 连接前k和后k个节点
neighbors = list(range(max(0, i-Config.k_neighbors), i)) + \
list(range(i+1, min(num_nodes, i+1+Config.k_neighbors)))
for j in neighbors:
edge_index.append([i, j])
edge_index.append([j, i]) # 双向连接
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
# 节点标签
y = torch.tensor([Config.seq_vocab.index(c) for c in seq], dtype=torch.long)
return Data(x=x, edge_index=edge_index, y=y, num_nodes=num_nodes)模型训练与验证
将RNA序列构建为图数据后,即可以开始训练
# 模型训练与验证
class RNADataset(torch.utils.data.Dataset):
def __init__(self, coords_dir, seqs_dir):
self.samples = []
# 读取所有数据并转换为图
for fname in os.listdir(coords_dir):
# 加载坐标数据
coord = np.load(os.path.join(coords_dir, fname)) # [L, 7, 3]
coord = np.nan_to_num(coord, nan=0.0) # 新增行:将NaN替换为0
# 加载对应序列
seq_id = os.path.splitext(fname)[0]
seq = next(SeqIO.parse(os.path.join(seqs_dir, f"{seq_id}.fasta"), "fasta")).seq
# 转换为图结构
graph = RNAGraphBuilder.build_graph(coord, str(seq))
self.samples.append(graph)
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
# 简单GNN模型
class GNNModel(nn.Module):
def __init__(self):
super().__init__()
# 特征编码
self.encoder = nn.Sequential(
nn.Linear(7*3, Config.hidden_dim),
nn.ReLU()
)
# GNN层
self.conv1 = GCNConv(Config.hidden_dim, Config.hidden_dim)
self.conv2 = GCNConv(Config.hidden_dim, Config.hidden_dim)
# 分类头
self.cls_head = nn.Sequential(
nn.Linear(Config.hidden_dim, len(Config.seq_vocab))
)
def forward(self, data):
# 节点特征编码
x = self.encoder(data.x) # [N, hidden]
# 图卷积
x = self.conv1(x, data.edge_index)
x = torch.relu(x)
x = self.conv2(x, data.edge_index)
x = torch.relu(x)
# 节点分类
logits = self.cls_head(x) # [N, 4]
return logits
# 训练函数
def train(model, loader, optimizer, criterion):
model.train()
total_loss = 0
for batch in loader:
batch = batch.to(Config.device)
optimizer.zero_grad()
# 前向传播
logits = model(batch)
# 计算损失
loss = criterion(logits, batch.y)
# 反向传播
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
# 评估函数
def evaluate(model, loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch in loader:
batch = batch.to(Config.device)
logits = model(batch)
preds = logits.argmax(dim=1)
correct += (preds == batch.y).sum().item()
total += batch.y.size(0)
return correct / total
# 主流程
if __name__ == "__main__":
# 设置随机种子
torch.manual_seed(Config.seed)
# 加载数据集
full_dataset = RNADataset("./RNAdesignv1/train/coords", "./RNAdesignv1/train/seqs")
# 划分数据集
train_size = int(0.8 * len(full_dataset))
val_size = (len(full_dataset) - train_size) // 2
test_size = len(full_dataset) - train_size - val_size
train_set, val_set, test_set = torch.utils.data.random_split(
full_dataset, [train_size, val_size, test_size])
# 创建DataLoader
train_loader = torch_geometric.loader.DataLoader(
train_set, batch_size=Config.batch_size, shuffle=True)
val_loader = torch_geometric.loader.DataLoader(val_set, batch_size=Config.batch_size)
test_loader = torch_geometric.loader.DataLoader(test_set, batch_size=Config.batch_size)
# 初始化模型
model = GNNModel().to(Config.device)
optimizer = optim.Adam(model.parameters(), lr=Config.lr)
criterion = nn.CrossEntropyLoss()
# 训练循环
best_acc = 0
for epoch in range(Config.epochs):
train_loss = train(model, train_loader, optimizer, criterion)
val_acc = evaluate(model, val_loader)
print(f"Epoch {epoch+1}/{Config.epochs}")
print(f"Train Loss: {train_loss:.4f} | Val Acc: {val_acc:.4f}")
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), "best_gnn_model.pth")
# 最终测试
model.load_state_dict(torch.load("best_gnn_model.pth",weights_only=True))
test_acc = evaluate(model, test_loader)
print(f"\nTest Accuracy: {test_acc:.4f}")训练完成后可以获得模型的最佳权重
进阶优化代码(来自某位大佬的教程):
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch_geometric
from torch_geometric.data import Data
from torch_geometric.nn import TransformerConv, LayerNorm
from torch_geometric.nn import radius_graph
from Bio import SeqIO
import math
# 配置参数
class Config:
seed = 42
device = "cuda" if torch.cuda.is_available() else "cpu"
batch_size = 16 if torch.cuda.is_available() else 8 # 根据显存调整
lr = 0.001
epochs = 50
seq_vocab = "AUCG"
coord_dims = 7
hidden_dim = 256
num_layers = 4 # 减少层数防止显存溢出
k_neighbors = 20
dropout = 0.1
rbf_dim = 16
num_heads = 4
amp_enabled = True # 混合精度训练
# 几何特征生成器
class GeometricFeatures:
@staticmethod
def rbf(D, D_min=0., D_max=20., D_count=16):
device = D.device
D_mu = torch.linspace(D_min, D_max, D_count, device=device)
D_mu = D_mu.view(*[1]*len(D.shape), -1)
D_sigma = (D_max - D_min) / D_count
D_expand = D.unsqueeze(-1)
return torch.exp(-((D_expand - D_mu)/D_sigma) ** 2)
@staticmethod
def dihedrals(X, eps=1e-7):
X = X.to(torch.float32)
L = X.shape[0]
dX = X[1:] - X[:-1]
U = F.normalize(dX, dim=-1)
# 计算连续三个向量
u_prev = U[:-2]
u_curr = U[1:-1]
u_next = U[2:]
# 计算法向量
n_prev = F.normalize(torch.cross(u_prev, u_curr, dim=-1), dim=-1)
n_curr = F.normalize(torch.cross(u_curr, u_next, dim=-1), dim=-1)
# 计算二面角
cosD = (n_prev * n_curr).sum(-1)
cosD = torch.clamp(cosD, -1+eps, 1-eps)
D = torch.sign((u_prev * n_curr).sum(-1)) * torch.acos(cosD)
# 填充处理
if D.shape[0] < L:
D = F.pad(D, (0,0,0,L-D.shape[0]), "constant", 0)
return torch.stack([torch.cos(D[:,:5]), torch.sin(D[:,:5])], -1).view(L,-1)
@staticmethod
def direction_feature(X):
dX = X[1:] - X[:-1]
return F.pad(F.normalize(dX, dim=-1), (0,0,0,1))
# 图构建器
class RNAGraphBuilder:
@staticmethod
def build_graph(coord, seq):
assert coord.shape[1:] == (7,3), f"坐标维度错误: {coord.shape}"
coord = torch.tensor(coord, dtype=torch.float32)
# 节点特征
node_feats = [
coord.view(-1, 7 * 3), # [L,21]
GeometricFeatures.dihedrals(coord[:,:6,:]), # [L,10]
GeometricFeatures.direction_feature(coord[:,4,:]) # [L,3]
]
x = torch.cat(node_feats, dim=-1) # [L,34]
# 边构建
pos = coord[:,4,:]
edge_index = radius_graph(pos, r=20.0, max_num_neighbors=Config.k_neighbors)
# 边特征
row, col = edge_index
edge_vec = pos[row] - pos[col]
edge_dist = torch.norm(edge_vec, dim=-1, keepdim=True)
edge_feat = torch.cat([
GeometricFeatures.rbf(edge_dist).squeeze(1), # [E,16]
F.normalize(edge_vec, dim=-1) # [E,3]
], dim=-1) # [E,19]
# 标签
y = torch.tensor([Config.seq_vocab.index(c) for c in seq], dtype=torch.long)
return Data(x=x, edge_index=edge_index, edge_attr=edge_feat, y=y)
# 模型架构
class RNAGNN(nn.Module):
def __init__(self):
super().__init__()
# 节点特征编码
self.feat_encoder = nn.Sequential(
nn.Linear(34, Config.hidden_dim),
nn.ReLU(),
LayerNorm(Config.hidden_dim),
nn.Dropout(Config.dropout)
)
# 边特征编码(关键修复)
self.edge_encoder = nn.Sequential(
nn.Linear(19, Config.hidden_dim),
nn.ReLU(),
LayerNorm(Config.hidden_dim),
nn.Dropout(Config.dropout)
)
# Transformer卷积层
self.convs = nn.ModuleList([
TransformerConv(
Config.hidden_dim,
Config.hidden_dim // Config.num_heads,
heads=Config.num_heads,
edge_dim=Config.hidden_dim, # 匹配编码后维度
dropout=Config.dropout
) for _ in range(Config.num_layers)
])
# 残差连接
self.mlp_skip = nn.ModuleList([
nn.Sequential(
nn.Linear(Config.hidden_dim, Config.hidden_dim),
nn.ReLU(),
LayerNorm(Config.hidden_dim)
) for _ in range(Config.num_layers)
])
# 分类头
self.cls_head = nn.Sequential(
nn.Linear(Config.hidden_dim, Config.hidden_dim),
nn.ReLU(),
LayerNorm(Config.hidden_dim),
nn.Dropout(Config.dropout),
nn.Linear(Config.hidden_dim, len(Config.seq_vocab))
)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0)
def forward(self, data):
x, edge_index, edge_attr = data.x, data.edge_index, data.edge_attr
# 边特征编码(关键步骤)
edge_attr = self.edge_encoder(edge_attr) # [E,19] -> [E,256]
# 节点编码
h = self.feat_encoder(x)
# 消息传递
for i, (conv, skip) in enumerate(zip(self.convs, self.mlp_skip)):
h_res = conv(h, edge_index, edge_attr=edge_attr)
h = h + skip(h_res)
if i < len(self.convs)-1:
h = F.relu(h)
h = F.dropout(h, p=Config.dropout, training=self.training)
return self.cls_head(h)
# 数据增强
class CoordTransform:
@staticmethod
def random_rotation(coords):
device = torch.device(Config.device)
coords_tensor = torch.from_numpy(coords).float().to(device)
angle = np.random.uniform(0, 2*math.pi)
rot_mat = torch.tensor([
[math.cos(angle), -math.sin(angle), 0],
[math.sin(angle), math.cos(angle), 0],
[0, 0, 1]
], device=device)
return (coords_tensor @ rot_mat.T).cpu().numpy()
# 数据集类
class RNADataset(torch.utils.data.Dataset):
def __init__(self, coords_dir, seqs_dir, augment=False):
self.samples = []
self.augment = augment
for fname in os.listdir(coords_dir):
# 加载坐标
coord = np.load(os.path.join(coords_dir, fname))
coord = np.nan_to_num(coord, nan=0.0)
# 数据增强
if self.augment and np.random.rand() > 0.5:
coord = CoordTransform.random_rotation(coord)
# 加载序列
seq_id = os.path.splitext(fname)[0]
seq_path = os.path.join(seqs_dir, f"{seq_id}.fasta")
seq = str(next(SeqIO.parse(seq_path, "fasta")).seq)
# 构建图
self.samples.append(RNAGraphBuilder.build_graph(coord, seq))
def __len__(self): return len(self.samples)
def __getitem__(self, idx): return self.samples[idx]
# 训练函数
def train(model, loader, optimizer, scheduler, criterion):
model.train()
scaler = torch.cuda.amp.GradScaler(enabled=Config.amp_enabled)
total_loss = 0
for batch in loader:
batch = batch.to(Config.device)
optimizer.zero_grad()
with torch.cuda.amp.autocast(enabled=Config.amp_enabled):
logits = model(batch)
loss = criterion(logits, batch.y)
scaler.scale(loss).backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
scaler.step(optimizer)
scaler.update()
total_loss += loss.item()
scheduler.step()
return total_loss / len(loader)
# 评估函数
def evaluate(model, loader):
model.eval()
total_correct = total_nodes = 0
with torch.no_grad():
for batch in loader:
batch = batch.to(Config.device)
logits = model(batch)
preds = logits.argmax(dim=1)
total_correct += (preds == batch.y).sum().item()
total_nodes += batch.y.size(0)
return total_correct / total_nodes
if __name__ == "__main__":
# 初始化
torch.manual_seed(Config.seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(Config.seed)
torch.backends.cudnn.benchmark = True
# 数据集
train_set = RNADataset(
"./RNA_design_public/RNAdesignv1/train/coords",
"./RNA_design_public/RNAdesignv1/train/seqs",
augment=True
)
# 划分数据集
train_size = int(0.8 * len(train_set))
val_size = (len(train_set) - train_size) // 2
test_size = len(train_set) - train_size - val_size
train_set, val_set, test_set = torch.utils.data.random_split(
train_set, [train_size, val_size, test_size])
# 数据加载
train_loader = torch_geometric.loader.DataLoader(
train_set,
batch_size=Config.batch_size,
shuffle=True,
pin_memory=True,
num_workers=4
)
val_loader = torch_geometric.loader.DataLoader(val_set, batch_size=Config.batch_size)
test_loader = torch_geometric.loader.DataLoader(test_set, batch_size=Config.batch_size)
# 模型初始化
model = RNAGNN().to(Config.device)
optimizer = optim.AdamW(model.parameters(), lr=Config.lr, weight_decay=0.01)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=Config.epochs)
criterion = nn.CrossEntropyLoss()
# 训练循环
best_acc = 0
for epoch in range(Config.epochs):
train_loss = train(model, train_loader, optimizer, scheduler, criterion)
val_acc = evaluate(model, val_loader)
print(f"Epoch {epoch+1}/{Config.epochs} | Loss: {train_loss:.4f} | Val Acc: {val_acc:.4f}")
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), "best_model.pth")
# 最终测试
model.load_state_dict(torch.load("best_model.pth"))
test_acc = evaluate(model, test_loader)
print(f"\nFinal Test Accuracy: {test_acc:.4f}")

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









