






参考借鉴
最好的C++学习教程(下篇)——The Cherno CppSeries - 知乎 (zhihu.com)
C++ 教程 - 油管大佬The Cherno C++ 教程_哔哩哔哩_bilibili
Cherno C++系列笔记1——P5~P7 C++工作原理、编译和链接器原理_the cherno cppseries学习笔记-CSDN博客
很大部分摘抄:相当于整合给自己看
最好的C++学习教程(上篇)——The Cherno CppSeries - 知乎 (zhihu.com)
C++是如何工作的
1.1.预处理
在#符号之后的都是预处理语句,编译器收到源文件后会预先处理。之所以叫预处理语句,是因为在实际编译发生之前就被处理了。
include的含义是需要找个一个文件,在这里指的是需要找到叫iostream的文件,然后将该文件的所有内容复制粘贴到现在的文件内,这些所包含的文件通常被成为“头文件”
1.2.编译和链接
项目中的每一个cpp文件都会被编译,但是头文件不会被编译,头文件的内容在预处理时包含到了cpp中。每一个cpp文件都被编译为object file(目标文件),如果使用VS生成的文件后缀为.obj。我们需要将这些文件合并成一个执行文件,链接(Link)会将所有的obj文件黏合在一起,合并成一个.exe文件。
如果是多文件工程,那么如果当前文件调用外部文件中定义的函数,那么需要有外部函数的声明,这样编译器就会信任我们知道有这样一个外部函数,编译就可以正常进行。这个函数到底在哪里,就是链接器负责的了。
C++编译器是如何工作的(vs ctrl+F7编译)
每一个CPP文件将产生一个目标文件,这些CPP文件被称为翻译单元。本质上必须意识到C++不关心文件,文件不是存在于C++中的东西。在C++中,文件只是提供给编译器源代码的一种方式,你负责告诉编译器你输入的是什么类型的文件,以及编译器应该如何处理它。比如说把a.cpp改为b.bubu,只要告诉编译器器这是一个C++文件也可以,所以文件是没有意义的。
一个CPP文件不一定就是一个translation unit,但如果每个CPP文件都是独立的,互不include的文件,则一个CPP文件都是一个translation unit,并且都会产生一个obj文件。
#include 预处理语句
编译器预先处理我们引用的include文件,将它全部复制到我们include的位置
下面的代码是等价的
}int multi(int a, int b) {
return a * b;
#include "test.h"int multi(int a, int b) {
return a * b;
}再VS中可以通过以下的方式去查看我们预处理生成的文件.i
现实再项目的属性页,的C++下面的预处理器的预处理到文件中,选择Yes,这样就能生成预处理文件.i
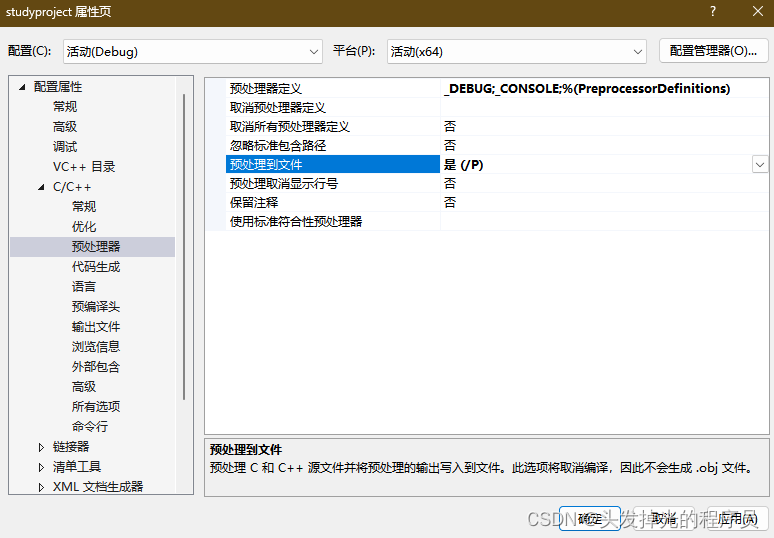
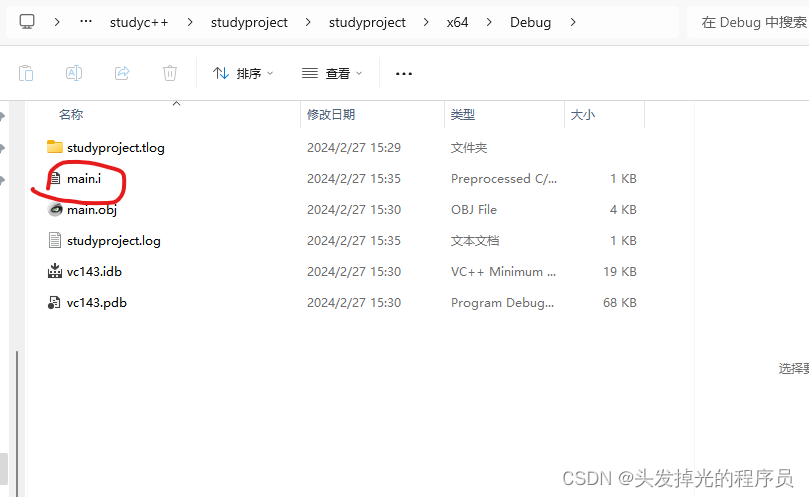
得到下面的生成结果
#line 1 "F:\\studyc++\\studyproject\\studyproject\\main.cpp"
int multi(int a, int b) {
return a * b;
#line 1 "F:\\studyc++\\studyproject\\studyproject\\test.h"
}
#line 4 "F:\\studyc++\\studyproject\\studyproject\\main.cpp"#define 预处理语句
#define A B
同时define中的内容,也会再预处理,C++会把下面内容的所有A替换为B
#define INTEGER jack
INTEGER multi(int a, int b) {
return a * b;
}#line 1 "F:\\studyc++\\studyproject\\studyproject\\main.cpp"
jack multi(int a, int b) {
return a * b;
}
#if 预处理语句
#if预处理可以让我们依据特定的条件包含或者剔除代码
模块1,2等价
模块3,4等价
#if 1
int multi(int a, int b) {
return a * b;
}
#endif
========================================================================================
#line 1 "F:\\studyc++\\studyproject\\studyproject\\main.cpp"
int multi(int a, int b) {
return a * b;
}
#line 7 "F:\\studyc++\\studyproject\\studyproject\\main.cpp"
========================================================================================
#if 0
int multi(int a, int b) {
return a * b;
}
#endif
=======================================================================================
#line 1 "F:\\studyc++\\studyproject\\studyproject\\main.cpp"
#line 7 "F:\\studyc++\\studyproject\\studyproject\\main.cpp"
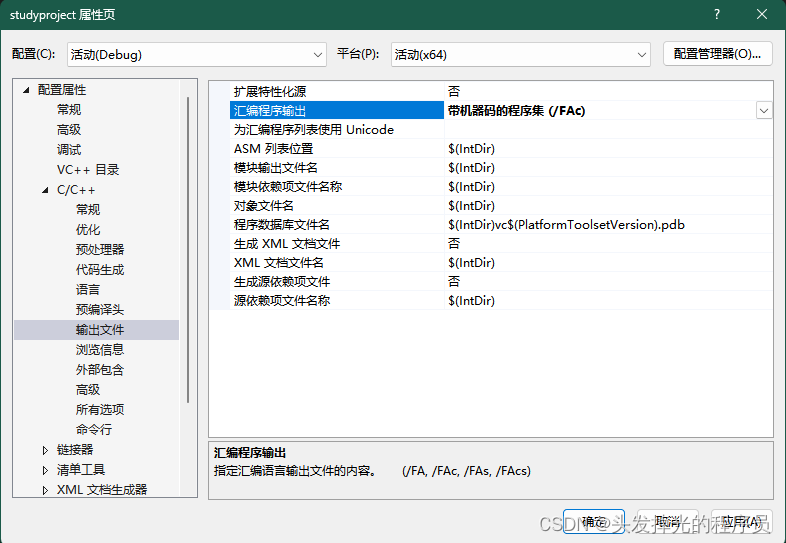
obj文件
生成得到的obj文件是一堆的机器码
可以在汇编输出中更改输出的形式
; Listing generated by Microsoft (R) Optimizing Compiler Version 19.38.33134.0
include listing.inc
INCLUDELIB MSVCRTD
INCLUDELIB OLDNAMES
msvcjmc SEGMENT
__7164527C_main@cpp DB 01H
msvcjmc ENDS
PUBLIC ?multi@@YAHHH@Z ; multi
PUBLIC __JustMyCode_Default
EXTRN _RTC_InitBase:PROC
EXTRN _RTC_Shutdown:PROC
EXTRN __CheckForDebuggerJustMyCode:PROC
; COMDAT pdata
pdata SEGMENT
$pdata$?multi@@YAHHH@Z DD imagerel $LN3
DD imagerel $LN3+57
DD imagerel $unwind$?multi@@YAHHH@Z
pdata ENDS
; COMDAT rtc$TMZ
rtc$TMZ SEGMENT
_RTC_Shutdown.rtc$TMZ DQ FLAT:_RTC_Shutdown
rtc$TMZ ENDS
; COMDAT rtc$IMZ
rtc$IMZ SEGMENT
_RTC_InitBase.rtc$IMZ DQ FLAT:_RTC_InitBase
rtc$IMZ ENDS
; COMDAT xdata
xdata SEGMENT
$unwind$?multi@@YAHHH@Z DD 025051601H
DD 01112316H
DD 0700a001dH
DD 05009H
xdata ENDS
; Function compile flags: /Odt
; COMDAT __JustMyCode_Default
_TEXT SEGMENT
__JustMyCode_Default PROC ; COMDAT
ret 0
__JustMyCode_Default ENDP
_TEXT ENDS
; Function compile flags: /Odtp /RTCsu /ZI
; File F:\studyc++\studyproject\studyproject\main.cpp
; COMDAT ?multi@@YAHHH@Z
_TEXT SEGMENT
a$ = 224
b$ = 232
?multi@@YAHHH@Z PROC ; multi, COMDAT
; 2 : int multi(int a, int b) {
$LN3:
mov DWORD PTR [rsp+16], edx
mov DWORD PTR [rsp+8], ecx
push rbp
push rdi
sub rsp, 232 ; 000000e8H
lea rbp, QWORD PTR [rsp+32]
lea rcx, OFFSET FLAT:__7164527C_main@cpp
call __CheckForDebuggerJustMyCode
; 3 : return a * b;
mov eax, DWORD PTR a$[rbp]
imul eax, DWORD PTR b$[rbp]
; 4 : }
lea rsp, QWORD PTR [rbp+200]
pop rdi
pop rbp
ret 0
?multi@@YAHHH@Z ENDP ; multi
_TEXT ENDS
END
所有这些看起来像是很多的代码,这是因为我们再debug环境下编译的,debug不会做任何优化,而且会有许多额外的东西,以确保我们的代码尽可能冗长以及更方便去debug
当使用o2的时候
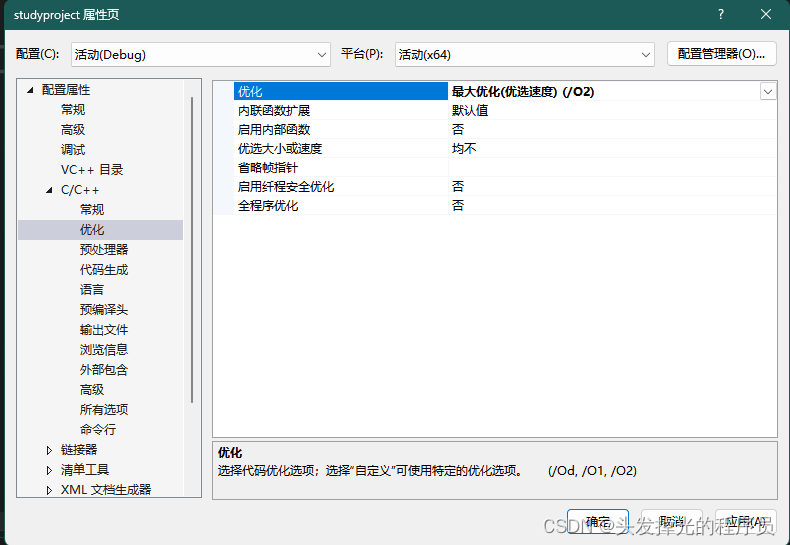 会报错不兼容
会报错不兼容
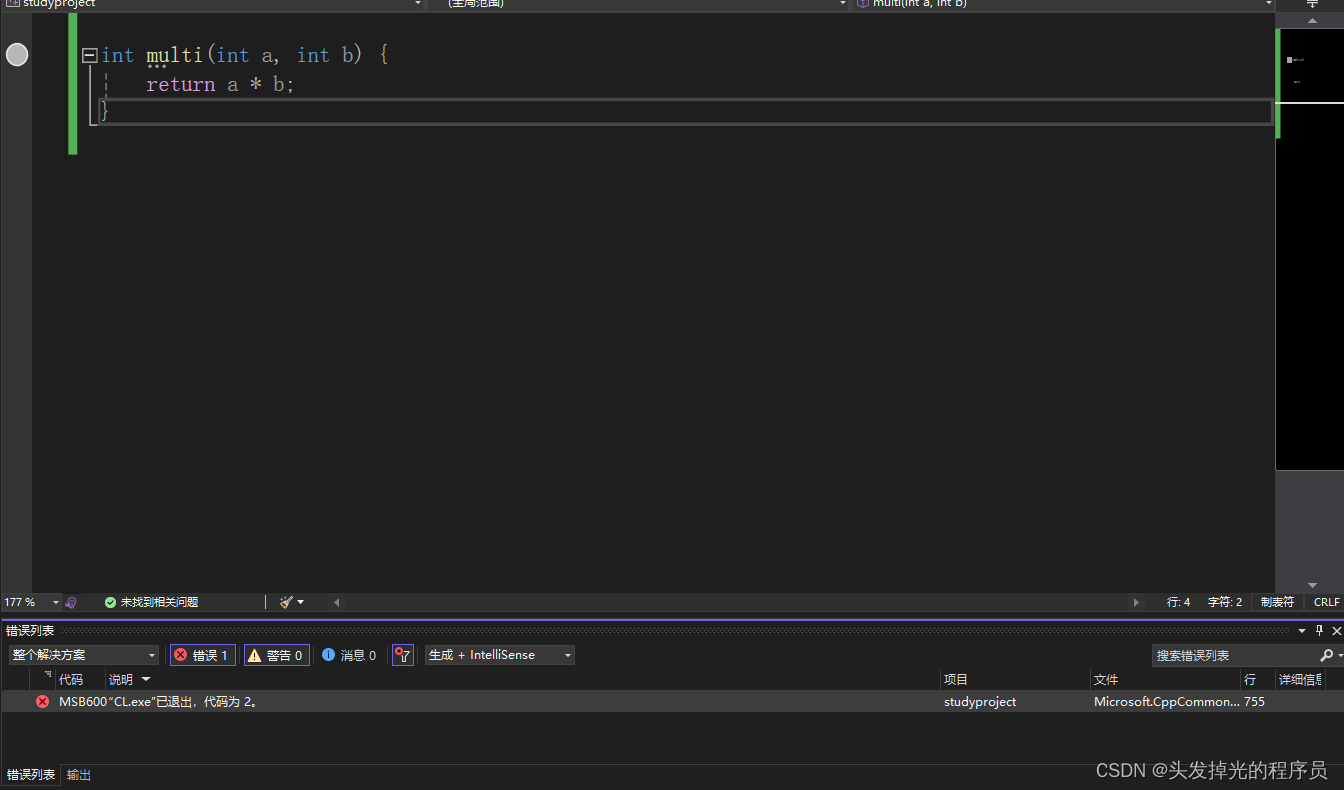 需要把运行时检查改成默认
需要把运行时检查改成默认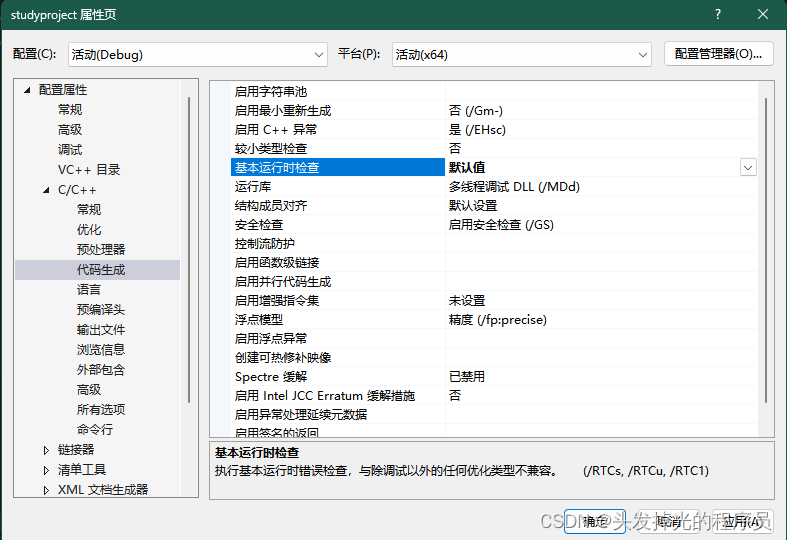
此时生成的汇编结果,会比之前的短,比较精简
链接器
链接器的工作
一旦我们编译好源文件,我们需要通过一个叫做链接的过程。链接的主要作用是找到每个符号和函数所在的地方,并把它们链接起来。多个翻译单元之间并不互通,我们需要一种方法把这些文件连接起来成一个项目。即使只有一个翻译单元,也需要将main函数连接起来。
在vs中,当我们按下ctrl+F7的时候只有编译会执行,链接不会执行,只有F5运行的时候,编译和链接才会都执行。
编译阶段检查语法错误(C开头)
Link阶段(Link开头)
Link阶段会检查工程的入口代码,如果没有入口的代码,会报错。
自定义entry point(一个exe 一定会有一个entry point)
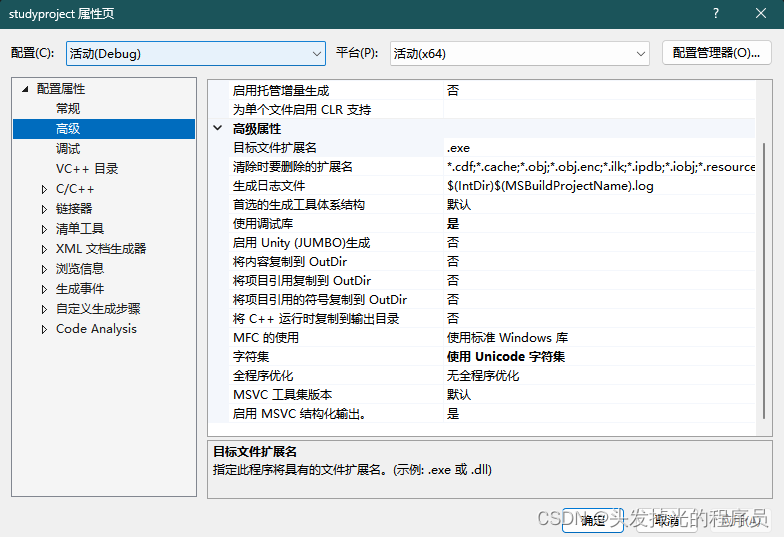
可以设定程序的入口点
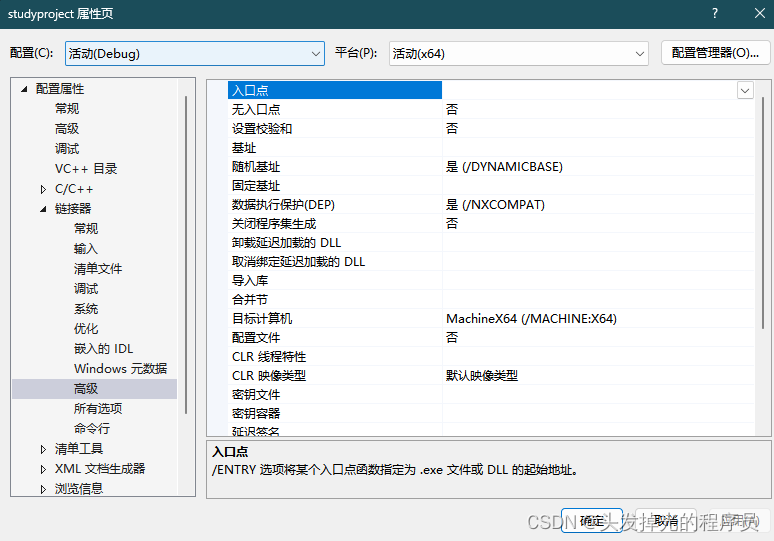
生成的时候,链接器会自动去链接程序所需要。但是如果找不到就会报错。
#include<iostream>
void Log(const char* str);
int Mul(int a, int b) {
Log("jack");
return a * b;
}
int main() {
std::cout << Mul(2,3) << std::endl;
std::cin.get();
return 0;
}#include<iostream>
void Log(const char* str) {
std::cout << str << std::endl;
}静态函数static避免找不到定义问题
如果我们不调用Multiply函数,重新build仍然会报错如下图。因为虽然在Math.cpp我们不用Multiply函数,但是从技术上讲,我们有可能在另一个文件中用到这个函数,所以链接器需要链接到它。
#include<iostream>
void Log(const char* str);
int Mul(int a, int b) {
Log("jack");
return a * b;
}
int main() {
//std::cout << Mul(2,3) << std::endl;
std::cin.get();
return 0;
}
#include<iostream>
void Logr(const char* str) {
std::cout << str << std::endl;
}
如果我们告诉编译器Multiply函数只会在这个文件中使用,就可以去掉链接的必要性。我们可以在Multiply函数前写个“static”静态这个词,意味这Multiply函数只被声明在这个翻译单元(Math.cpp)中,再次build会发现没有任何链接错误。
#include<iostream>
void Log(const char* str);
static int Mul(int a, int b) {
Log("jack");
return a * b;
}
int main() {
//std::cout << Mul(2,3) << std::endl;
std::cin.get();
return 0;
}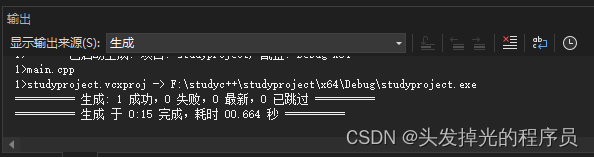
多重定义问题
在C++中定义同一个函数多次
#include<iostream>
void Log(const char* str);
void Log(const char* str) {
std::cout << str << std::endl;
}
static int Mul(int a, int b) {
Log("jack");
return a * b;
}
int main() {
//std::cout << Mul(2,3) << std::endl;
std::cin.get();
return 0;
}#include<iostream>
void Log(const char* str) {
std::cout << str << std::endl;
}此时编译是可以通过的,但是链接以后。
会产生错误,这是由于链接的时候发现出现了多个重复定义的Log函数

常见的一种错误为 ,下面三个文件
main.cpp
#include<iostream>
#include "test.h"
static int Mul(int a, int b) {
Log("jack");
return a * b;
}
int main() {
//std::cout << Mul(2,3) << std::endl;
std::cin.get();
return 0;
}test.cpp
#include<iostream>
#include "test.h"
void initlog() {
Log("jack");
}test.h
#include<iostream>
void Log(const char* str) {
std::cout << str << std::endl;
}此时会告诉你,你多重定义的链接问题

因为链接cpp文件的时候,出现了两个Log函数
解决方式
- 方法1——static静态函数限制在本文件中链接
我们可以将Log函数标记为静态的,这意味在链接Log函数时,Log函数只能是内部函数。这样在Log.cpp,Main.cpp中的Log函数只能是文件的内部函数,Log.cpp和Main.cpp文件都有自己版本的Log函数,对任何其它的obj文件不可见。重新build就不会报错。
#include<iostream>
static void Log(const char* str) {
std::cout << str << std::endl;
}-
方法2——内联函数化函数调用为本地语句
在函数名前面加上inline关键字限定,这样在调用这个函数的地方将会直接替换为这个函数的实体(类似include的感觉),而不会执行函数的调用(就不需链接到这个函数定义的地方)
就是直接拿函数体来使用,不包括上面的函数名那些
#include<iostream>
inline void Log(const char* str) {
std::cout << str << std::endl;
}这样下面的代码1,等价于,代码2
代码1
#include<iostream>
#include "test.h"
void initlog() {
Log("jack");
}代码2
#include<iostream>
#include "test.h"
void initlog() {
std::cout << "jack" << std::endl;
}还有一种方式
现在的Log函数相当于是在被包含在两个翻译单元,main.cpp,test.cpp
test.h
//只对函数进行了声明
#include<iostream>
void Log(const char* str);test.cpp
只在test.cpp翻译单元中进行声明
#include<iostream>
#include "test.h"
void initlog() {
std::cout << "jack" << std::endl;
}
void Log(static char* str) {
std::cout << str << std::endl;
}main.cpp
//在main中使用test.h
//这样在链接的时候就可以链接到test.cpp上进行使用Log的定义
#include<iostream>
#include "test.h"
static int Mul(int a, int b) {
Log("jack");
return a * b;
}
int main() {
//std::cout << Mul(2,3) << std::endl;
std::cin.get();
return 0;
}
这里引入一个概念,就是我们一般将需要跨cpp使用的函数定义放在.h文件中,方便每个cpp,可以对它进行include,但是对于函数体的声明只有一个cpp有。
main.cpp
#include<iostream>
#include "log.h"
void Log(const char* str) {
std::cout << str << std::endl;
}
int main() {
Log("jack");
initlog("god");
return 0;
}
initlog.cpp
#include "log.h"
void initlog(const char* str) {
Log(str);
}
log.h
#pragma once
void initlog(const char* str);
void Log(const char* str);pragma once的作用。pragma其实是一个被输入到编译器或者说预处理器的指令
pragma once的作用是说在一个翻译器(.cpp)中只被include一次,防止重复定义
include头文件时的<>和""
< >是包含编译器设置的头文件路径中的头文件,比如CMakeLists.txt中可以设置头文件包含目录。或者简单点说<>包含的都是系统中的头文件
" "是包含当前源文件所在的路径下的文件,或者相对当前文件所在路径的其他路径下的文件。比如想包含当前文件所在的文件夹的上一层目录下的common.h头文件,那么可以这么写:#include "../common.h"。
实际上,对于<>包含的头文件,也可以使用 " " 来包含,也就是 " " 是万能的。但是通常不会这么做,区分使用<>和""可以让程序可读性更好。
C++类和结构体外的静态(static)
static关键字两种用法
- 在类或结构体外部使用static关键字
这意味着你定义的函数和变量只对它的声明所在的cpp文件(编译单元)是“可见”的。换句话说此时static修饰的符号,(在link的时候)它只对定义它的翻译单元(.obj)可见(internal linkage)。
- 在类或结构体内部使用static关键字
此时表示这部分内存(static变量)是这个类的所有实例共享的。即:该静态变量在类中创建的所有实例中,静态变量只有一个实例。一个改变就改变所有。
类中的静态方法也一样,静态方法中没有该实例的指针(this)。在类中没有实例会传递给该方法。
如果不用static定义全局变量,在别的翻译单元可以用extern int a这样的形式,这被称为 external linkage或external linking。
重点是,要让函数和变量标记为静态的,除非你真的需要它们跨翻译单元链接。
全局变量
当全局变量不使用static且定义多个时
main.cpp
#include<iostream>
int a = 10;
int main() {
return 0;
}
init.cpp
int a = 10;报错:
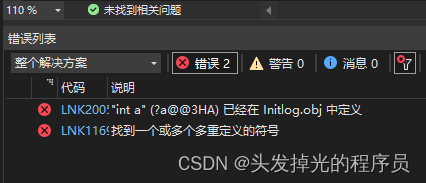
解决方法,如果你实在需要使用全局变量,那么在全局变量前面加上static,就可以只在本cpp使用,如果你需要跨cpp,在外部引用加上extern
注意在加上extern后,不能赋值
//方式1
#include<iostream>
static int a = 10;
int main() {
return 0;
}
int a = 10;
//方式2
#include<iostream>
#include<iostream>
int a = 10;
int main() {
return 0;
}
#include<iostream>
extern int a;
void kk() {
std::cout << a << std::endl;
}C++类和结构体中的静态(static)
- 静态方法不能访问非静态变量
- 静态方法没有类实例
- 本质上你在类里写的每个非静态方法都会获得当前的类实例作为参数(this指针)
- 静态成员变量在编译时存储在静态存储区,即定义过程应该在编译时完成,因此一定要在类外进行定义,但可以不初始化。 静态成员变量是所有实例共享的,但是其只是在类中进行了声明,并未定义或初始化(分配内存),类或者类实例就无法访问静态成员变量,这显然是不对的,所以必须先在类外部定义,也就是分配内存。
在几乎所有面向对象的语言里,static在一个类中意味着特定的东西。如果是static变量,这意味着在类的所有实例中,这个变量只有一个实例。比如一个entity类,有很多个entity实例,若其中一个实例更改了这个static变量,它会在所有实例中反映这个变化。这是因为即使创建了很多实例,static的变量仍然只有一个。正因如此,通过类实例来引用静态变量是没有意义的。因为这就像类的全局实例。
静态方法也是一样,无法访问类的实例。静态方法可以被调用,不需要通过类的实例。而在静态方法内部,你不能写引用到类实例的代码,因为你不能引用到类的实例。
如果这样写代码,直接在结构体内部赋值静态变量,编译错误。
static int b = 10;
struct Ep{
static int a = 10;
void print() {
std::cout << std::endl;
}
};
int main() {
return 0;
}
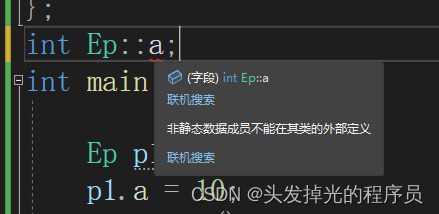
这样写编译正确,但是,链接错误。
#include<iostream>
static int b = 10;
struct Ep{
static int a;
void print() {
std::cout << std::endl;
}
};
int main() {
Ep p;
p.a = 10;
return 0;
}第二个错误

必须在外面进行初始化,也就是分配内存。而且还必须是全局范围定义。
::(静态变量)按照这种方式去初始化静态成员,这里我试了非静态,不行。
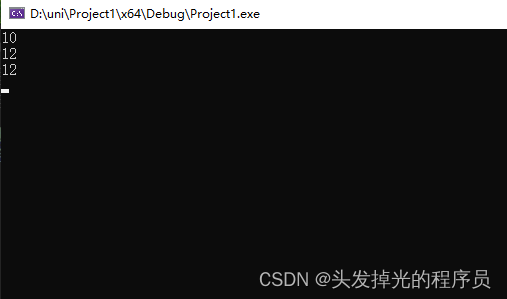
发现p2更改了static变量了以后,p1调用的值也改了,于是得出static变量,通用的结论
#include<iostream>
static int b = 10;
struct Ep{
static int a;
void print() {
std::cout <<a<< std::endl;
}
};
int Ep::a;
int main() {
Ep p1, p2;
p1.a = 10;
p1.print();
p2.a = 12;
p2.print();
p1.print();
std::cin.get();
return 0;
}
正因如此,通过类实例来引用静态变量是没有意义的,最好写为
struct Ep{
static int a;
void print() {
std::cout <<a<< std::endl;
}
};
int Ep::a;
int main() {
Ep p1, p2;
Ep::a = 10;
p1.print();
p2.print();
Ep::a = 20;
p1.print();
return 0;
}如果把print()函数改为static,仍然正常,因为它引用的x,y也是静态的变量,这里我们都用不到类的实例,因为这些全是静态的,正确代调用方式:
struct Ep{
static int a;
static void print() {
std::cout <<a<< std::endl;
}
};
int Ep::a;
int main() {
Ep::a = 10;
Ep::a = 20;
Ep::print();
return 0;
}但如果把x改为非静态的,则会报错,因为静态方法不能访问非静态变量,原因就是静态方法没有类实例,我们在编写类的时候,本质上我们在类里写的每个非静态方法都会获得当前的类实例作为参数(this指针)。
因此静态方法和在类外部编写的方法是一样的。
如果在类外面写一个print()函数,则就会报错,这就能为什么说明不能访问到x;
static int b = 10;
struct Ep{
int a;
static void print() {
std::cout <<a<< std::endl;
}
};
static void print() {
std::cout << a << std::endl;//找不到a
}
int main() {
return 0;
}但是如果这样就可以
struct Ep{
int a;
static void print(Ep b) {
std::cout <<b.a<< std::endl;
}
};
static void print(Ep b) {//给了a 的定义
std::cout << b.a << std::endl;
}
int main() {
Ep p1;
p1.a = 10;
Ep::print(p1);
return 0;
}我们刚刚写的方法,本质上就是一个类的非静态方法在编译时的真正样子
但如果我把Entity实例去掉,就是把static关键字加到类方法时所做的
C++中的局部静态(Local Static)
在局部作用域中可以使用static来声明一个变量,这和前两种有所不同。这一种情况需要考虑变量的生命周期和作用域。
生命周期:变量实际存在的时间;作用域:指可以访问变量的范围。
静态局部(local static)变量允许我们声明一个变量,它的生命周期基本相当于整个程序的生命周期,然而它的作用范围被限制在这个作用域内。
意思就是,这个函数中的局部静态变量一旦被执行初始化一次,那么它的值不会在改变,后面调用这个函数也是这个值,但是它的作用域只有这个函数内部可以使用。
void kk() {
static int a = 10;
a++;
std::cout << a << std::endl;
}
int main() {
kk();
kk();
kk();
kk();
return 0;
}下面的运行结果证明a的值只会初始化一次,然后后面再次调用就不会再次进行初始化。

它的效果相当于在外面写了一个全局变量,但是与全局变量不同的是
全局变量在任何地方都可以访问到
而静态局部变量只能在函数范围内访问
另一个例子:有一个单例的类(即:这个类只有一个实例存在)
通过static静态,将生存期延长到永远。这意味着,我们第一次调用get的时候,它实际上会构造一个单例实例,在接下来的时间它只会返回这个已经存在的实例。
class Ep {
public:
int a;
static Ep* get() {
static Ep* p1 = new Ep();
return p1;
}
};
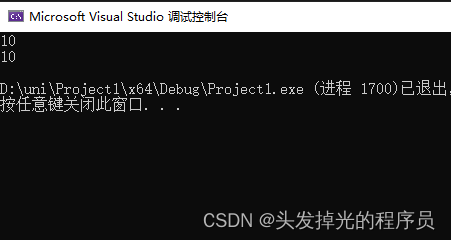
int main() {
Ep* p1 = Ep::get();
p1->a = 10;
Ep* p2 = Ep::get();
std::cout << p1->a << std::endl;
std::cout << p2->a << std::endl;
return 0;
} 
C++枚举
枚举量的声明
- ENUM是enumeration的缩写。基本上它就是一个数值集合。不管怎么说,这里面的数值只能是整数。
- 定义枚举类型的主要目的:增加程序的可读性
- 枚举变的名字一般以大写字母开头(非必需)
- 默认情况下,编译器设置第一个 枚举变量值为 0,下一个为 1,以此类推(也可以手动给每个枚举量赋值),且 未被初始化的枚举值的值默认将比其前面的枚举值大1。 )
- 枚举量的值可以相同
- 枚举类型所使用的类型默认为int类型,也可指定其他类型 ,如 unsigned char
输出3
enum En {
A=2, B, C
};
int main() {
En a = B;
std::cout <<a<< std::endl;
return 0;
}可以以:数据类型的方式,制定为unsigned char,但是在后面使用记得转回int
enum En : unsigned char {
A=34, B, C
};
int main() {
En a = B;
std::cout <<int(a)<< std::endl;
return 0;
}枚举量的定义:
可利用新的枚举类型example声明这种类型的变量 example Dd,可以在定义枚举类型时定义枚举变量:
enum En : unsigned char {
A=34, B, C
}e;与基本变量类型不同的地方是,在不进行强制转换的前提下,只能将定义的枚举量赋值给该种枚举的变量(非绝对的,可用强制类型转换将其他类型值赋给枚举变量)
enum En{
A, B, C
}e;
int main() {
En a = B;
e = 5;//error
e = En(5);//true
std::cout <<int(a)<< std::endl;
return 0;
}
得到5枚举量可赋给非枚举变量
int main() {
En a = B;
e = En(5);//true
int c = e;
std::cout <<c<< std::endl;
return 0;
}枚举的取值范围:
枚举的上限:大于【最大枚举量】的【最小的2的幂】,减去1;
枚举的下限:
- 枚举量的最小值不小于0,则枚举下限取0;
- 枚举量的最小值小于0,则枚举下限是: 小于【最小枚举量】的【最大的2的幂】,加上1。
例如定义enumType枚举类型:
enum enumType { First=-5,Second=14,Third=10 };则枚举的上限是16-1=15(16大于最大枚举量 14,且为2的幂); 枚举的下限是-8+1=-7(-8小于最小枚举量-5,且为2的幂);
在类中可以直接使用枚举。
class Ep {
public:
enum En {
A, B, C
};
int a;
static Ep* get() {
static Ep* p1 = new Ep();
return p1;
}
};
int main() {
std::cout <<Ep::A<< std::endl;
return 0;
}C++构造函数
- 当创建对象的时候,构造函数被调用
- 构造函数最重要的作用就是初始化类
class Ep {
private:
int x, y;
public:
Ep() {
}
Ep(int a, int b) {
x = a, y = b;
}
void print() {
std::cout << x<<" "<<y << std::endl;
}
};
int main() {
Ep p(2, 3);
p.print();
return 0;
}
- 构造函数没有返回类型
- 构造函数的命名必须和类名一样
- 如果你不指定构造函数,你仍然有一个构造函数,这叫做默认构造函数(default constructor),是默认就有的。但是,我们仍然可以删除该默认构造函数:
两种删除方式:
第一种,直接让默认构造为私有。
private:
int x, y;
Ep();
public:
Ep(int a, int b) {
x = a, y = b;
}
void print() {
std::cout << x<<" "<<y << std::endl;
}
};
int main() {
Ep p();
p.print();
return 0;
}第二种方式,让它 =delete
class Ep {
private:
int x, y;
public:
Ep() = delete;
Ep(int a, int b) {
x = a, y = b;
}
void print() {
std::cout << x<<" "<<y << std::endl;
}
};
int main() {
Ep p();
p.print();
return 0;
}
- 构造函数不会在你没有实例化对象的时候运行,所以如果你只是使用类的静态方法,构造函数是不会执行的。
- 当你用new关键字创建对象实例的时候也会调用构造函数。
C++析构函数
- 析构函数是在你销毁一个对象的时候运行。
- 析构函数同时适用于栈和堆分配的内存
因此如果你用new关键字创建一个对象(存在于堆上),然后你调用delete,析构函数就会被调用。
如果你只有基于栈的对象,当跳出作用域的时候这个对象会被删除,所以这时侯析构函数也会被调用。
- 构造函数和析构函数在声明和定义的唯一区别就是放在析构函数前面的波形符(~)
- 因为这是栈分配的,我们会看到当main函数执行完的时候析构函数就会被调用
- 析构函数没有参数,不能被重载,因此一个类只能有一个析构函数。
- 不显式的定义析构函数系统会调用默认析构函数
这里写一个预先的知识,因为在那个知乎大佬的博客上看到的,惊讶我的下巴。
类中的函数可以在外部进行定义,原理和static一样。
使用 类名::方法定义类中的方法、构造等函数。
class Ep {
private:
int x, y;
public:
Ep() = delete;
Ep(int a, int b) {
x = a, y = b;
}
void print();
};
void Ep::print() {
std::cout << x << " " << y << std::endl;
}
int main() {
Ep p(1,2);
p.print();
return 0;
}在private中也可以
class Ep {
private:
int x, y;
void print();
public:
Ep() = delete;
Ep(int a, int b) {
x = a, y = b;
print();
}
};
void Ep::print() {
std::cout << x << " " << y << std::endl;
}
int main() {
Ep p(1,2);
return 0;
}于是我们就可以在.h中写入我们共同需要的类的定义,就像之前一样。
//log.h
#pragma once
#include<iostream>
class Student {
int num;
std::string name;
public:
Student(int num, std::string name);
~Student();
void print();
};
//log.cpp
#include<iostream>
#include "log.h"
Student::Student(int num, std::string name) : num(num), name(name){}
Student::~Student() {
std::cout << "bye" << std::endl;
}
void Student::print() {
std::cout << num << " " << name << std::endl;
}
//main.cpp
#include<iostream>
#include "log.h"
void test() {
Student s(1, "jack");
s.print();
}
int main() {
test();
return 0;
}当对象的生命周期结束,调用析构函数
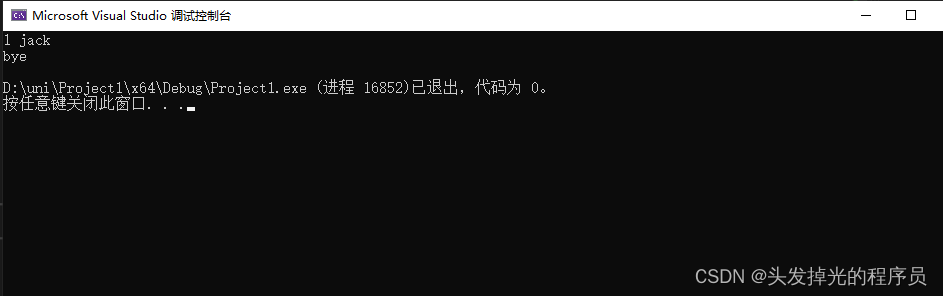
C++继承
- 当你创建了一个子类,它会包含父类的一切。
- 继承给我们提供了这样的一种方式:把一系列类的所有通用的代码(功能)放到基类
- 在定义一个新的类 B 时,如果该类与某个已有的类 A 相似(指的是 B 拥有 A 的全部特点),那么就可以把 A 作为一个基类,而把B作为基类的一个派生类(也称子类)。
- 派生类是通过对基类进行修改和扩充得到的,在派生类中,可以扩充新的成员变量和成员函数。
- 派生类拥有基类的全部成员函数和成员变量,不论是private、protected、public。需要注意的是:在派生类的各个成员函数中,不能访问基类的private成员。
继承的格式
class 派生类名:public 基类名
{
};例子如下,分析:
- 这个Player类不再仅仅只是Player类型,它也是Entity类型,就是说它同时是这两种类型。意思是我们可以在任何想要用Entity的地方使用Player
- Player总是Entity的一个超集,它拥有Entity的所有内容。
- 因为对于Player来说,在Entity中任何不是私有的(private)成员,Player都可以访问到
这个代码中,访问不了id
class En {
private:
int id;
public :
float x, y;
void print() {
std::cout << x << " " << y << std::endl;
}
};
class Player :public En{
public:
std::string name;
void printname() {
std::cout << name << std::endl;
}
};
int main() {
Player p;
p.x = 2;
p.y = 3;
p.print();
p.name = "jack";
p.printname();
return 0;
}C++虚函数
- 虚函数可以让我们在子类中重写方法。
- 格式
claee 父类名{
//virtual + 函数
virtual void GetName(){
.....
}
}
class 子类:public 父类{
void GetName(){}
}如果不使用virtual
class En {
private:
int id;
public :
float x, y;
void print() {
std::cout << x << " " << y << std::endl;
}
};
class Player :public En{
public:
std::string name;
void print() {
std::cout << name << std::endl;
}
};
void printname(En* e) {
e->print();
}
int main() {
Player p;
p.x = 2;
p.y = 3;
p.print();
p.name = "jack";
printname(&p);
return 0;
}输出 2 3
原因在于如果我们在类中正常声明函数或方法,当调用这个方法的时候,它总是会去调用属于这个类型的方法 ,而
void printname(En* e);参数类型是En*,意味着它会调用En内部的print函数,它只会在En的内部寻找和调用print.但是我们希望C++能意识到,在这里我们传入的其实是一个Player,所以请调用Player的print。此时就需要使用虚函数了。
- 虚函数引入了一种要动态分配的东西,一般通过虚表(vtable)来实现编译。虚表就是一个包含类中所有虚函数映射的列表,通过虚表我们就可以在运行时找到正确的被重写的函数。
- 简单来说,你需要知道的就是如果你想重写一个函数,你么你必须要把基类中的原函数设置为虚函数
class En {
private:
int id;
public :
float x,y;
virtual void print() {
std::cout << x << " " << y << std::endl;
}
};
class Player :public En{
public:
std::string name;
void print() {
std::cout << name << std::endl;
}
};
void printname(En* e) {
e->print();
}
int main() {
Player p;
p.x = 2;
p.y = 3;
p.print();
p.name = "jack";
printname(&p);
return 0;
}输出jack
视频中的例子,感觉写的很规范:
注意作为参数传递的时候,记得传递地址,因为单纯传递一个对象,只是对值进行了拷贝。
override,代表重载
class Entity {
public:
virtual std::string GetName() {
return "jack";
}
};
class Player : public Entity {
public:
std::string Name;
Player(const std::string& name) :Name(name){}
std::string GetName() override{
return Name;
}
};
void PrintName(Entity* e) {
std::cout << e->GetName() << std::endl;
}
int main() {
Player* p = new Player("god");
PrintName(p);
Entity* tr = p;
std::cout << tr->GetName() << std::endl;
return 0;
}输出
god
god
C++接口(纯虚函数)
纯虚函数优点
防止派生类忘记实现虚函数,纯虚函数使得派生类必须实现基类的虚函数。
在某些场景下,创建基类对象是不合理的,含有纯虚拟函数的类称为抽象类,它不能直接生成对象。声明方法: 在基类中纯虚函数的方法的后面加 =0
virtual void funtion()=0;
virtual std::string GetName() = 0;- C++中的纯虚函数本质上与其他语言(bi如Java或C#)中的抽象方法或接口相同。
- 纯虚函数与虚函数的区别在于,纯虚函数的基类中的
virtual函数,只定义了,但不实现。实现交给派生类来做。 - 只能实例化一个实现了所有纯虚函数的类。纯虚函数必须被实现,然后我们才能创建这个类的实例。
- 纯虚函数允许我们在基类中定义一个没有实现的函数,然后强制子类去实现该函数。
- 实际上,其他语言有interface关键字而不是叫class,但C++没有。接口只是C++的类而已。
- 在面向对象程序设计中,创建一个只包含未实现方法然后交由子类去实际实现功能的类是非常普遍的,这通常被称为接口。接口就是一个只包含未实现的方法并作为一个模板的类。并且由于此接口类实际上不包含方法实现,所以我们无法实例化这个类。
必须是一模一样,加别的参数就是新的方法了
class Entity {
public:
virtual void print() {
std::cout << "jack" << std::endl;
}
virtual std::string GetName() = 0;
};
class Player : public Entity {
public:
std::string Name;
Player(const std::string& name) :Name(name){}
std::string GetName() {
return Name;
}
};
void PrintName(Entity* e) {
std::cout << e->GetName() << std::endl;
}
int main() {
Player* p = new Player("god");
PrintName(p);
return 0;
}这里Player2继承了Player,可以不实现方法。
class Entity {
public:
virtual void print() {
std::cout << "jack" << std::endl;
}
virtual std::string GetName() = 0;
};
class Player : public Entity {
public:
std::string Name;
Player(){}
Player(const std::string& name) :Name(name){}
virtual std::string GetName() override {
return "22222";
}
};
class Player2 :public Player {
};
void PrintName(Entity* e) {
std::cout << e->GetName() << std::endl;
e->print();
}
int main() {
Player2* p = new Player2();
PrintName(p);
return 0;
}如果不是继承就要添加接口
类似:
class Player2 : public OtherClass,Entity //加逗号,添加接口Entity
{
....
std::string GetName() override {return m_Name;}
};C++数组补充
栈数组和堆数组
- 不能把栈上分配的数组(字符串)作为返回值,除非你传入的参数是一个内存地址。
- 如果你想返回的是在函数内新创建的数组,那你就要用new关键字来创建。
- 栈数组
int example[5];堆数组int* another = new int[5]
原因是堆数组直到程序结束才会清除内存,another存的是数组的地址,所以访问的时候需要跳两级。
ptr的形式和c的赋值形式是一样的,其最终的结果,存储的是数组的地址,只不过指针自己有一个地址,所以需要跳两次。
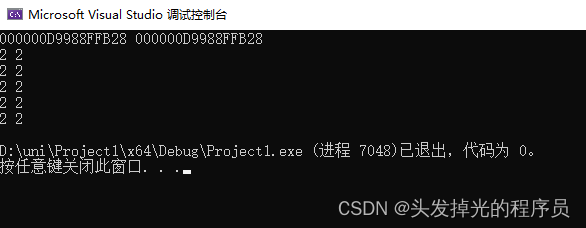
int main() {
int b[5];
int* c = b;
std::cout << c << " " << &b << std::endl;
int* ptr = new int[5];
for (int i = 0; i < 5; i++) {
ptr[i] = 2;
c[i] = 2;
}
for (int i = 0; i < 5; i++) {
std::cout << ptr[i] << " " << c[i] << std::endl;
}
return 0;
}
在程序中,如果需要释放内存,需要手动删除new创造的数组
int main() {
int b[5];
int* c = b;
std::cout << c << " " << &b << std::endl;
int* ptr = new int[5];
for (int i = 0; i < 5; i++) {
ptr[i] = 2;
c[i] = 2;
}
for (int i = 0; i < 5; i++) {
std::cout << ptr[i] << " " << c[i] << std::endl;
}
delete[] ptr;
return 0;
}C++11中的std:array
这是一个内置数据结构,定义在C++11的标准库中。很多人喜欢用它来代替这里的原生数组,因为他有很多优点,它有边界检查,有记录数组的大小
实际上我们没有办法计算原生数组的大小,但可以通过一些办法知道大小(例如因为当你删除这个数组时,编译器要知道实际上需要释放多少内存)
计算原生数组的方式
通过sizeof可以知道传递的变量或者类型的字节大小,此时相除就可以知道大小
int main() {
int b[5];
std::cout << sizeof b / sizeof(int) << std::endl;
return 0;
}堆上的可不行。
会得到1(32位系统)
int main() {
int* ptr = new int[5];
std::cout << sizeof(ptr) / sizeof(int) << std::endl;
return 0;
}所以只能在栈分配的数组上用这个技巧,但是你真的不能相信这个方法!当你把它放在函数或者它变成了指针,那你完蛋了(因为“栈上的地址加上偏移量”)。所以你要做的就是自己维护数组的大小。
使用 std::array
#include<array>//记得加上array
int main() {
std::array<int, 5> a;
for (int i = 0; i < a.size(); i++) {
a[i] = 2;
}
return 0;
}C++字符串补充
C++以下形式是const char*,不可以修改
int main() {
std::string a = "jack";
std::string b = "jack" + "god";//Error const char*不可以修改
std::string c = a + "god";//可以这样加
return 0;
}虽然是字符数组,但是传递到函数中,更改值,不会改变其本身。
void chan(std::string p) {
p[0] = 'a';
}
int main() {
std::string a = "jack";
std::string c = a + "god";//可以这样加
chan(c);
std::cout << c << std::endl;
return 0;
}
//输出jackgod相当于是copy这个字符串,这样会影响效率,如果你传递的值不会改变,最好使用
const std::string &p
C++字符串字面量
- 字符串字面量就是双引号中的内容。
- 字符串字面量是存储在内存的只读部分的,不可对只读内存进行写操作。
- C++11以后,默认为
const char*,否则会报错。
int main() {
char* ptr = "jack";//error报错,字符串字面量是存储在内存的只读部分的
const char* p = "god";//true
char name[] = "pop";
name[1] = 'a';
std::cout << name << std::endl;
return 0;
}别的一些字符串
基本上,char是一个字节的字符,char16_t是两个字节的16个比特的字符(utf16),char32_t是32比特4字节的字符(utf32),const char就是utf8. 那么wchar_t也是两个字节,和char16_t的区别是什么呢?事实上宽字符的大小,实际上是由编译器决定的,可能是一个字节也可能是两个字节也可能是4个字节,实际应用中通常不是2个就是4个(Windows是2个字节,Linux是4个字节),所以这是一个变动的值。如果要两个字节就用char16_t,它总是16个比特的。
int main() {
const char* str = "jack";
const char16_t* s1 = u"god";
const char32_t* s2 = U"po";
const wchar_t* s3 = L"kk";
return 0;
}string_literals
string_literals中定义了很多方便的东西,这里字符串字面量末尾加s,可以看到实际上是一个操作符函数,它返回标准字符串对象(std::string)
然后我们就还能方便地这样写等等:
int main() {
using namespace std::string_literals;
std::wstring a = L"jack"s + L"god"s;
return 0;
}string_literals也可以忽略转义字符
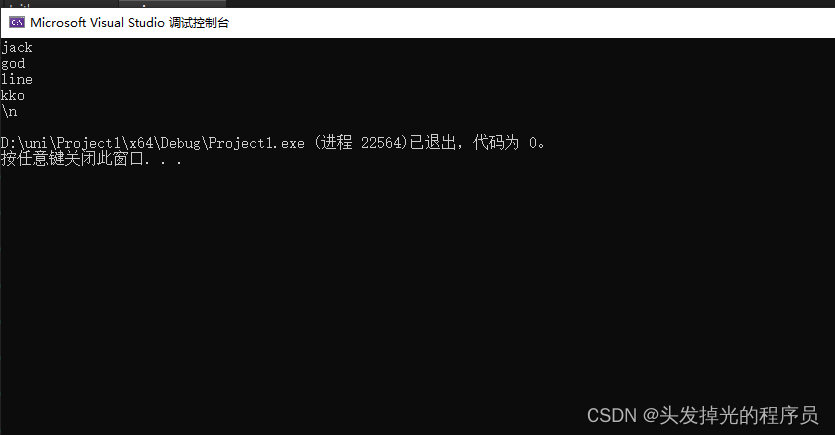
int main() {
using namespace std::string_literals;
std::wstring a = L"jack"s + L"god"s;
std::string b = R"(jack
god
line
kko
\n)";
std::cout << b << std::endl;
return 0;
}
C++中const
- const首先作用于左边的东西;如果左边没东西,就做用于右边的东西
- const被cherno称为伪关键字,因为它在改变生成代码方面做不了什么。
- const是一个承诺,承诺一些东西是不变的,你是否遵守诺言取决于你自己。我们要保持const是因为这个承诺实际上可以简化很多代码。
- 绕开const的方法:(但不建议这么做)
这样会报错 :
这里b还是一个可变量,而a已经是常量了,如果这样赋值,就有可能会改变a,就会冲突了
int main() { const int a = 10; int* b = new int; *b = 34; b = &a; return 0; }
上面的解决方法一:
将指针指向的值也定义为常量,就是不能够修改指针指向的地址,比如a的值
int main() { const int a = 10; const int* b = new int; b = &a; return 0; }
上面的解决方法二:
强制转换,这样虽然能够拿到和a一样的地址,但是你改变值,a是不会变的,a已经在只读的内存中了
int main() { const int a = 10; const int* b = new int; b = (int*)&a; return 0; }int main() { const int a = 10; int* b = new int; b = (int*)&a; *b = 43; std::cout <<a<< std::endl; return 0; }输出10
const的位置,对指针的作用
int main() {
const int a = 10;
const int* b = new int;
int* const c = new int;
b = (int*)&a;
c = a;//error const修饰指针,指针指向的地址不可以改变,只能修改值
*b = 43;//error const修饰指针指向的地址,该地址内的值不可以修改,可以指向其他地址
std::cout <<a<< std::endl;
return 0;
}在类和方法中的const
const的第三种用法,他和变量没有关系,而是用在方法名的后面( 只有类才有这样的写法 )
这意味这这个方法不会修改任何实际的类,因此这里你可以看到我们不能修改类的成员变量
class Entity {
private:
int x, y;
public:
int get() const {
y = 4;//error不能修改
return x;
}
void set(int xx) {
x = xx;
}
};
int main() {
return 0;
}这样做的好处
传入函数的时候,为了不复制一般用其本身地址,这时不需要改变值。
class Entity {
private:
int x, y;
public:
int get(){
y = 3;
return x;
}
void set(int xx) {
x = xx;
}
};
void printx(const Entity&e) {
std::cout << e.get() << std::endl;//报错,因为e修饰为const,但是get方法会改变e内的成员变量
}
int main() {
return 0;
}然后有时我们就会写两个Getx版本,一个有const一个没有,然后上面面这个传const Enity&的方法就会调用const的GetX版本。
所以,我们把成员方法标记为const是因为如果我们真的有一些const Entity对象,我们可以调用const方法。如果没有const方法,那const Entity&对象就掉用不了该方法。
- 如果实际上没有修改类或者它们不应该修改类,总是标记你的方法为const,否则在有常量引用或类似的情况下就用不了你的方法。
- 在const函数中, 如果要修改别的变量,可以用关键字mutable:
把类成员标记为mutable,意味着类中的const方法可以修改这个成员。
class Entity {
private:
int x;
mutable int y;
public:
int get() const{
y = 3;
return x;
}
void set(int xx) {
x = xx;
}
};
void printx(const Entity&e) {
std::cout << e.get() << std::endl;
}
int main() {
return 0;
}C++的成员初始化列表
注意:在成员初始化列表里需要按成员变量定义的顺序写。这很重要,因为不管你怎么写初始化列表,它都会按照定义类的顺序进行初始化。
按照顺序进行初始化:
class P1 {
public:
P1() {
std::cout << "p1" << std::endl;
}
};
class P2 {
public:
P2() {
std::cout << "p2" << std::endl;
}
};
class Entity {
private:
char m_c;
int m_x, m_y;
P2 p2;
P1 p1;
public:
Entity(int x,int y):m_y(x),m_x(y){}
void print() {
std::cout << m_x << " " << m_y << std::endl;
}
};
int main() {
Entity p(1, 2);
p.print();
return 0;
}上面的代码会先输出p2,然后输出p1,告诉我们两个信息,
首先,这样定义类的对象作为成员变量的时候,它会自己进行一次初始化,那如果后面通过构造的方式再次赋值,它还会在定义,初始化一次,影响性能。
其次就是上面说的按顺序。
class P2 {
public:
P2() {
std::cout << "p2" << std::endl;
}
};
class Entity {
private:
char m_c;
int m_x, m_y;
P2 p2;
P1 p1;
public:
Entity() {
P2 p2;
std::cout << &p2 << std::endl;
}
void print() {
std::cout << &p2<< std::endl;
}
};
int main() {
Entity p;
return 0;
}P2初始化了两次
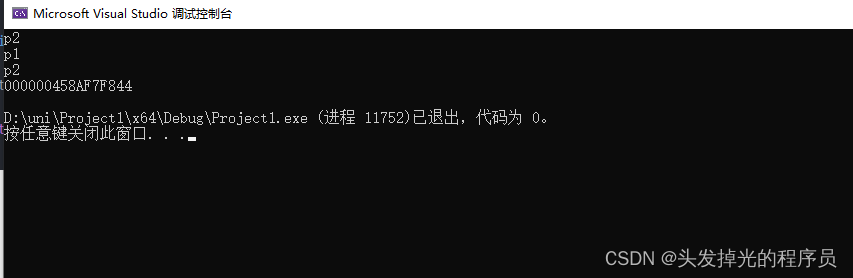
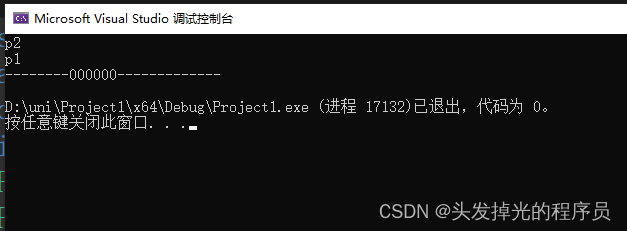
但是我们只需要P2初始化一次,并且在我们的构造函数中,此时成员初始化列表就很有作用了,同时它还可以美化代码。
class Entity {
private:
char m_c;
int m_x, m_y;
P2 m_p2;
P1 m_p1;
public:
Entity(P2 p2,P1 p1):m_p2(p2),m_p1(p1){}
void print() {
std::cout << &m_p2<< std::endl;
}
};
int main() {
P2 p2;
P1 p1;
std::cout << "--------000000-------------" << std::endl;
Entity p(p2,p1);
return 0;
} 
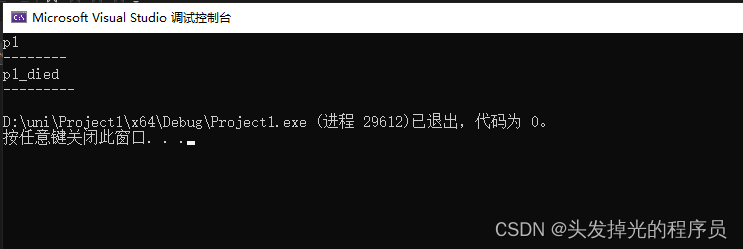
创建并初始化C++对象
- 基本上,当我们编写了一个类并且到了我们实际开始使用该类的时候,就需要实例化它(除非它是完全静态的类)
- 实例化类有两种选择,这两种选择的区别是内存来自哪里,我们的对象实际上会创建在哪里。
- 应用程序会把内存分为两个主要部分:堆和栈。还有其他部分,比如源代码部分,此时它是机器码。
栈分配
格式:
class P1 {
public:
P1() {
std::cout << "p1" << std::endl;
}
~P1() {
std::cout << "p1_died" << std::endl;
}
};
int main() {
{
P1 p1;
}
return 0;
}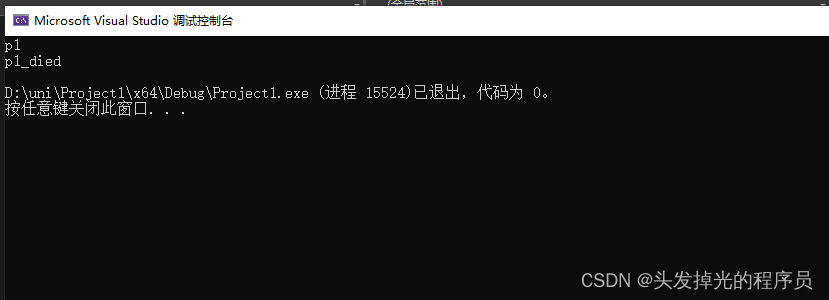
当作用域结束的时候,会调用P1的析构函数。
- 什么时候栈分配?几乎任何时候,因为在C++中这是初始化对象最快的方式和最受管控的方式。
- 什么时候不栈分配? 如果创建的对象太大,或是需要显示地控制对象的生存期,那就需要堆上创建 。
堆分配
格式:
P1* pp1 = new P1();
delete pp1;//删除pp1
P1* pp2 = new P1[5];
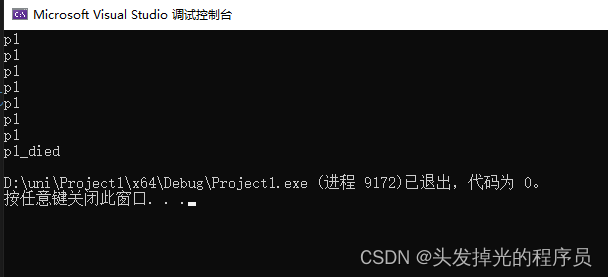
delete[] pp2;//删除pp2数组堆分配的内存,不会随着作用域结束而回收。
int main() {
{
P1 p1;
P1* pp1 = new P1();
P1* pp2 = new P1[5];
}
return 0;
}
C++ new关键字
- new的主要目的是分配内存,具体来说就是在堆上分配内存。
- 如果你用new和[]来分配数组,那么也用delete[]。
- new主要就是找到一个满足我们需求的足够大的内存块,然后返回一个指向那个内存地址的指针。
- 在new类时,该关键字做了两件事
分配内存 调用构造函数
- new 是一个操作符,就像加、减、等于一样。它是一个操作符,这意味着你可以重载这个操作符,并改变它的行为。
- 通常调用new会调用隐藏在里面的C函数malloc,但是malloc仅仅只是分配内存然后给我们一个指向那个内存的指针,而new不但分配内存,还会调用构造函数。同样,delete则会调用destructor析构函数。
int main() {
{
P1* p1 = new P1();
std::cout << "--------" << std::endl;
P1* p2 = (P1*)malloc(sizeof P1);
delete p1;
std::cout << "---------" << std::endl;
free(p2);
}
return 0;
}结果表明new-delete组合会调用构造函数和析构函数,而malloc-free函数则不会调用这两个函数
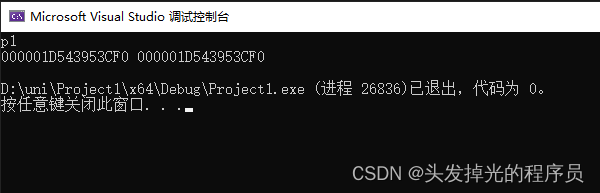
new支持一种叫placement new的用法,这决定了他的内存来自哪里, 所以你并没有真正的分配内存。在这种情况下,你只需要调用构造函数,并在一个特定的内存地址中初始化你的Entity,可以通过些new()然后指定内存地址,例如:
int main() {
int* b = new int[50];
P1* p1 = new(b) P1();
std::cout << p1 <<" "<<b << std::endl;
return 0;
}这样可以输出得到,p1指向的地址和b指向的地址是一个地址
C++隐式转换与explicit关键字
隐式转换:
class P1 {
public:
P1(const std::string& str) {
std::cout << str << std::endl;
}
P1(const int &a) {
std::cout << a << std::endl;
}
};
int main() {
P1 a = 2;
P1 b = (std::string)"jack";
return 0;
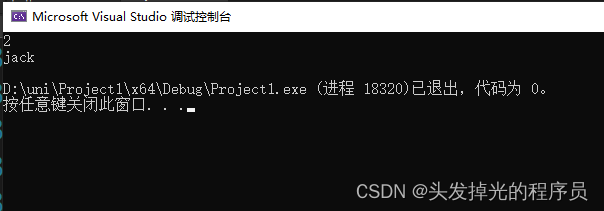
}如上,在main中,int型的2就被隐式转换为一个P1对象,这是因为P1类中有一个P1(const int &a)构造函数,因此可以调用这个构造函数,然后把2作为他的唯一参数,就可以创建一个Entity对象。 字符串同理,从const char *转成string。
应尽量避免隐式转换。因为P1
a(2);更清晰。
explicit 关键字
- explicit是用来当你想要显示地调用构造函数,而不是让C++编译器隐式地把任何整形转换成Entity
- 我有时会在数学运算库的地方用到explicit,因为我不想把数字和向量来比较。一般explicit很少用到。
- 如果你在构造函数前面加上explicit,这意味着这个构造函数不会进行隐式转换
- 如果你想用一个整数构造一个Entity对象,那你就必须显示的调用这个构造函数,explicit会禁用隐式转换,explicit关键字放在构造函数前面
主要就是explicit会禁用隐式转换
class P1 {
public:
explicit P1(const std::string& str) {
std::cout << str << std::endl;
}
P1(const int &a) {
std::cout << a << std::endl;
}
};
int main() {
P1 a = 2;
P1 c = 3;
P1 b = (std::string)"jack";//error
return 0;
}但是可以这样:
int main() {
P1 a = 2;
P1 c = 3;
P1 b = (P1)(std::string)"jack";//error
return 0;
}C++运算符(操作符)及其重载
- 操作符就是函数。
- 运算符是给我们使用的一种符号,通常代替一个函数来执行一些事情。比如加减乘除、dereference运算符、箭头运算符、+=运算符、&运算符、左移运算符、new和delete、逗号、圆括号、方括号等等 。
- 运算符重载允许你在程序中定义或者更改一个操作符的行为。
- 应该相当少地使用操作符重载,只在他非常有意义的时候使用。
“+”和“*”操作符重载
无重载时:
struct Vector2 {
int m_x, m_y;
Vector2(int x, int y) :m_x(x), m_y(y){}
Vector2 Add(const Vector2& other)const {
return Vector2(m_x + other.m_x, m_y + other.m_y);
}
};
int main() {
Vector2 p1(1, 2);
Vector2 p2(3, 4);
Vector2 p3 = p1.Add(p2);
std::cout << p3.m_x << " " << p3.m_y << std::endl;
return 0;
}使用重载
需要要【定义操作符】比如上述代码中的“+”
struct Vector2 {
int m_x, m_y;
Vector2(int x, int y) :m_x(x), m_y(y){}
Vector2 Add(const Vector2& other)const {
return Vector2(m_x + other.m_x, m_y + other.m_y);
}
Vector2 operator+ (const Vector2& other) const {
std::cout << m_x << " " << m_y << std::endl;
return Add(other);
}
};
int main() {
Vector2 p1(1, 2);
Vector2 p2(3, 4);
Vector2 p3 = p1 + p2;
std::cout << p3.m_x << " " << p3.m_y << std::endl;
return 0;
}可以看到,当使用+号的时候,默认前面的执行,也就是p1.+(p2)

*乘法是一样的就不赘述了,这里试试看它会不会具有优先级。
int main() {
Vector2 p1(1, 2);
Vector2 p2(3, 4);
Vector2 p3 = p1 + p2;
Vector2 p4 = p1 + p2 * p2;
std::cout << p4.m_x << " " << p4.m_y << std::endl;
return 0;
}具备正常的四则运算法则

左移操作符的重载
如上,现在我们有了这个Vector2,然后我们想要把它打印到控制台,但是我想这样打印
Vector2 p4 = p1 + p2 * p2;
std::cout << p4 << std::endl;肯定是报错的
报错的原因在于"<<"操作符还没有被重载,他接受两个参数,一个是输出流,也就是cout,然后另一个就是Vector2 (操作数类型为: std::ostream << Vector2 )
我们可以在Vector2类外面对它进行重载,因为她其实和Vector2其实没什么关系(这就意味着整个程序的<<改变)
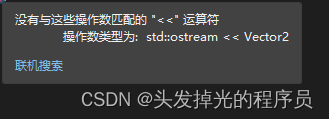
你在类里面重定义<<会报错,具体参考:(C++)类内运算符重载时:此运算符函数的参数太多/少-CSDN博客
std::ostream& operator<<(std::ostream& stream, const Vector2& other){
stream << other.m_x << " " << other.m_y << std::endl;
return stream;
}
int main() {
Vector2 p1(1, 2);
Vector2 p2(3, 4);
Vector2 p3 = p1 + p2;
Vector2 p4 = p1 + p2 * p2;
std::cout << p4 << std::endl;
return 0;
}注意需要返回值,相当于你把东西放入输出流stream中,如果你不返回,它就会报错。并且不需要再自带std::endl;因为它已经在输出流中。不会影响正常使用
int main() {
Vector2 p1(1, 2);
Vector2 p2(3, 4);
Vector2 p3 = p1 + p2;
Vector2 p4 = p1 + p2 * p2;
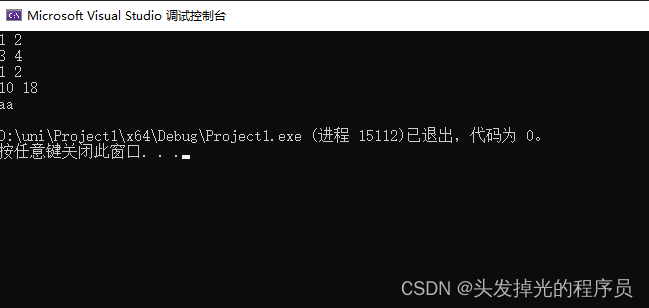
std::cout << p4;
std::cout << "aa" << std::endl;
return 0;
} 
针对bool类型的判断,其效果是一样的,比如你重载小于号,进行排序。此时,就可以根据你的的定义进行排序。
#include<algorithm>
struct Vector2 {
int m_x, m_y;
bool operator<(const Vector2& other) const {
return m_x > other.m_x;
}
};
std::ostream& operator<<(std::ostream& stream, const Vector2& other){
stream << other.m_x << " " << other.m_y << std::endl;
return stream;
}
int main() {
Vector2* ptr = new Vector2[2];
ptr[0].m_x = 1;
ptr[0].m_y = 2;
ptr[1].m_x = 3;
ptr[1].m_y = 1;
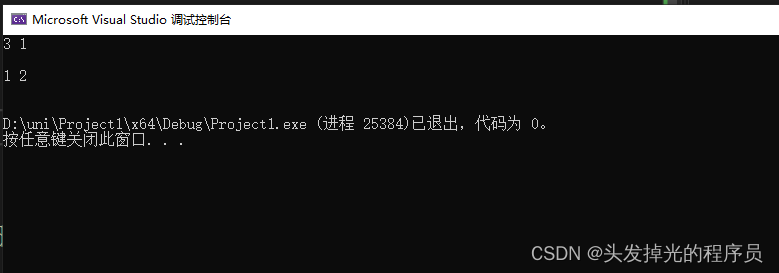
std::sort(ptr, ptr + 2);
for (int i = 0; i < 2; i++) {
std::cout << ptr[i] << std::endl;
}
return 0;
}
C++this关键字
- C++中有this关键字,通过他我们可以访问成员函数,成员函数就是属于某个类的函数或方法。
- this在一个const函数中,this是一个
const Entity* const- 或者是
const Entity*,在一个非const函数中,那么它就是一个Entity*类型的- 在函数内部,我们可以引用this,this是指向这个函数所属的当前对象实例的指针
以下面这种方式去调用,因为变量一样,会赋值失败。
class Entity {
int x, y;
public:
Entity(int x, int y) {
x = x;
y = y;
}
void print()const {
std::cout << x << " " << y << std::endl;
}
};
int main() {
Entity* e = new Entity(1,2);
e->print();
return 0;
} 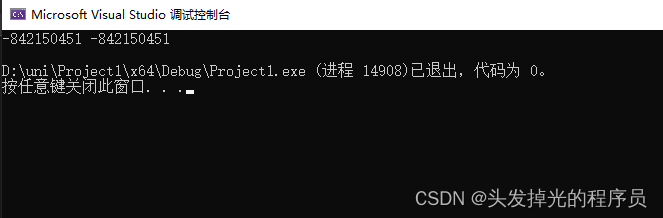
这其实只是在用它自己给这个x参数进行赋值操作,这相当于啥都没干。
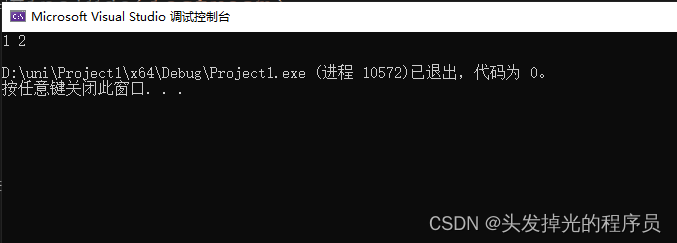
我其实真正要做的是引用属于这个类的x和y,这个类的成员。而this关键字可以让我们做到这点,因为this是指向当前对象的指针。
class Entity {
int x, y;
public:
Entity(int x, int y) {
this->x = x;
this->y = y;
}
void print()const {
std::cout << x << " " << y << std::endl;
}
};
int main() {
Entity* e = new Entity(1,2);
e->print();
return 0;
} 
在const的方法中,this为const Entity* 或者也可以写成const Entity* const
class Entity {
int x, y;
public:
Entity(int x, int y) {
this->x = x;
this->y = y;
}
void print()const {
std::cout << x << " " << y << std::endl;
}
int Get()const {
const Entity* const e = this;
}
};
int main() {
Entity* e = new Entity(1,2);
e->print();
return 0;
}另一个用到的场景就是,如果我们想要调用这个Entity类外面的函数,他不是Entity的方法,但是我们想在这个类内部调用一个外部的函数,然后这个函数接受一个Entity类型作为参数,这时候就可以使用this
class Entity;//类声明
void print(const Entity* e);//方法声明
class Entity {
int x, y;
public:
Entity(int x, int y) {
this->x = x;
this->y = y;
print(this);
}
int Get_x()const {
return this->x;
}
int Get_y() const {
return this->y;
}
};
std::ostream& operator<<(std::ostream& stream, const Entity* e){
stream << e->Get_x() << " " << e->Get_y() << std::endl;
return stream;
}
void print(const Entity* ptr) {
std::cout << ptr;
}
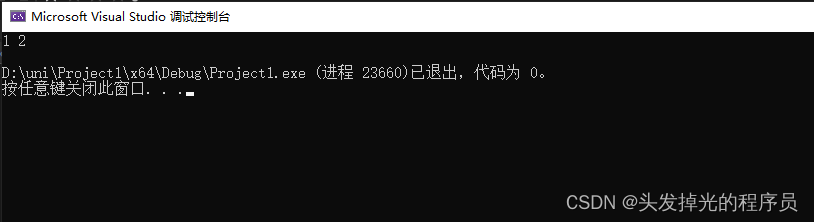
int main() {
Entity e(1, 2);
return 0;
}
或者使用引用
class Entity;//类声明
void print(const Entity& e);//方法声明
class Entity {
int x, y;
public:
Entity(int x, int y) {
this->x = x;
this->y = y;
print(*this);
}
int Get_x()const {
return this->x;
}
int Get_y() const {
return this->y;
}
};
std::ostream& operator<<(std::ostream& stream, const Entity e){
stream << e.Get_x() << " " << e.Get_y() << std::endl;
return stream;
}
void print(const Entity& ptr) {
std::cout << ptr;
}
int main() {
Entity e(1, 2);
return 0;
}C++的对象生存期(栈作用域生存期)
1.基于栈的变量生存周期是什么意思
这些分为两部分:一个是你必须要明白对象是如何生存在栈上的,这样你才会写出能正常工作不会崩溃的代码2.作用域可以是任何东西,比如说函数作用域,还有像if语句作用域,或者for和while循环作用域,或者空作用域、类作用域。
3.每当我们在C++中进入一个作用域,我们是在push栈帧。它不一定就是一个栈帧。
当我在push数据时,你可以想象成把一本书放到书堆上,在这个作用域声明的变量一就是你再这本书里写的内容,一旦这个作用域结束,你就把这本书从书堆上拿出来,他就结束了,每个基于栈的变量,就是你再那本书里创建的对象就都结束了4.基于栈的变量在我们离开作用域的时候就会被摧毁,内存被释放。在堆上创建的,当程序结束后才会被系统摧毁。
局部作用域创建数组的经典错误
例如:返回一个在作用域内创建的数组
如下代码,因为我们没有使用new关键字,所以他不是在堆上分配的,我们只是在栈上分配了这个数组,当我们返回一个指向他的指针时(return array),也就是返回了一个指向栈内存的指针,旦离开这个作用域(CreateArray函数的作用域),这个栈内存就会被回收
struct En {
En() {
std::cout << "create" << std::endl;
}
~En() {
std::cout << "died" << std::endl;
}
};
En* CreateArray() {
En e[5];
return e;
}
int main() {
En* ptr = CreateArray();
std::cout << "jack" << std::endl;
return 0;
}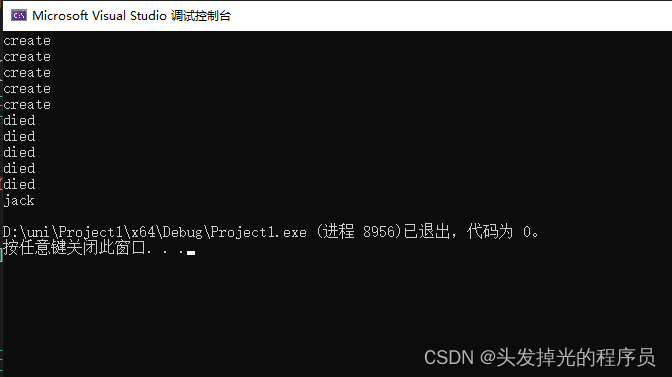
理论上来说,它不会died,但是它调用了析构函数 ,证明对象被回收。要么转成堆,但是栈有栈的好处。
基于栈的变量的好处
1.可以帮助我们自动化代码。 比如类的作用域,比如像智能指针smart_ptr,或是unique_ptr,这是一个作用域指针,或者像作用域锁(scoped_lock)。
2.最简单的例子可能是作用域指针,它基本上是一个类,它是一个指针的包装器,在构造时用堆分配指针,然后在析构时删除指针,所以我们可以自动化这个new和delete。
创建Entity对象时,我还是想在堆上分配它,但是我想要在跳出作用域时自动删除它,这样能做到吗?我们可以使用标准库中的作用域指针unique_ptr实现。
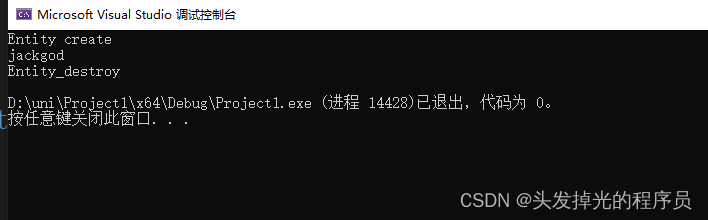
如下,CreateEntity就是我们写的一个最基本的作用域指针,由于其是在栈上分配的,然后作用域结束的时候,CreateEntity这个类就被析构,析构中我们又调用delete把堆上的指针删除内存。
class Entity {
public:
Entity() {
std::cout << "Entity create" << std::endl;
}
void print() {
std::cout << "jackgod" << std::endl;
}
~Entity() {
std::cout << "Entity_destroy" << std::endl;
}
};
class CreateEntity {
public:
class Entity* e;
CreateEntity(Entity* pr):e(pr){}
~CreateEntity() {
delete e;
}
};
int main() {
{
CreateEntity c(new Entity());
c.e->print();
}
return 0;
}
C++的智能指针
- 智能指针本质上是原始指针的包装。当你创建一个智能指针,它会调用new并为你分配内存,然后基于你使用的智能指针,这些内存会在某一时刻自动释放。
- 优先使用unique_ptr,其次考虑shared_ptr。
尽量使用unique_ptr因为它有一个较低的开销,但如果你需要在对象之间共享,不能使用unique_ptr的时候,就使用shared_ptr
作用域指针unique_ptr的使用
- 要访问所有这些智能指针,你首先要做的是包含memory头文件
- unique_ptr是作用域指针,意味着超出作用域时,它会被销毁然后调用delete。
- unique_ptr是唯一的,不可复制,不可分享。
如果复制一个unique_ptr,会有两个指针,两个unique_ptr指向同一个内存块,如果其中一个死了,它会释放那段内存,也就是说,指向同一块内存的第二个unique_ptr指向了已经被释放的内存。
- unique_ptr构造函数实际上是explicit的,没有构造函数的隐式转换,需要显式调用构造函数。
- 最好使用
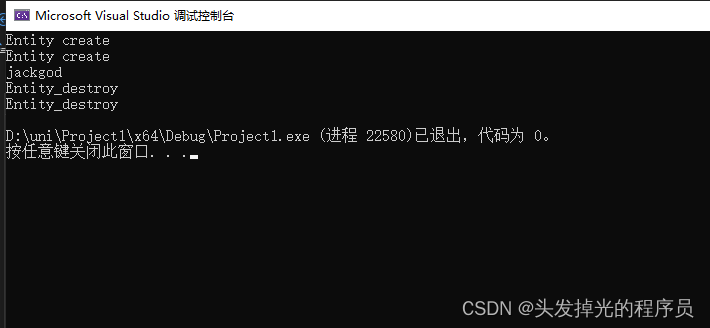
std::unique_ptr<Entity> entity = std::make_unique<Entity>();因为如果构造函数碰巧抛出异常,不会得到一个没有引用的悬空指针从而造成内存泄漏,它会稍微安全一些。std::make_unique<>()是在C++14引入的,C++11不支持。
#include<memory>
class Entity {
public:
Entity() {
std::cout << "Entity create" << std::endl;
}
void print() {
std::cout << "jackgod" << std::endl;
}
~Entity() {
std::cout << "Entity_destroy" << std::endl;
}
};
int main() {
{
std::unique_ptr<Entity> entity(new Entity());//ok,可以但不建议
std::unique_ptr<Entity> en = std::make_unique<Entity>();
en->print();
}
return 0;
}
共享指针shared_ptr 的使用
1.shared_ptr的工作方式是通过引用计数。
引用计数基本上是一种方法,可以跟踪你的指针有多少个引用,一旦引用计数达到零,他就被删除了。
例如:我创建了一个共享指针shared_ptr,我又创建了另一个shared_ptr来复制它,我的引用计数是2,第一个和第二个,共2个。当第一个死的时候,我的引用计数器现在减少1,然后当最后一个shared_ptr死了,我的引用计数回到零,内存就被释放。2.shared_ptr需要分配另一块内存,叫做控制块,用来存储引用计数,如果您首先创建一个new Entity,然后将其传递给shared_ptr构造函数,它必须分配,做2次内存分配。先做一次new Entity的分配,然后是shared_ptr的控制内存块的分配。然而如果你用make_shared你能把它们组合起来,这样更有效率。
#include<memory>
int cnt = 0;
class Entity {
public:
Entity() {
cnt++;
std::cout << "Entity create" << std::endl;
}
void print() {
std::cout << cnt << std::endl;
}
~Entity() {
std::cout << "Entity_destroy" << std::endl;
}
};
int main() {
{
std::shared_ptr<Entity> e0;
{
//std::shared_ptr<Entity> e1(new Entity());//也可以,但是不推荐
std::shared_ptr<Entity> e1 = std::make_shared<Entity>();
e0 = e1;
e1->print();
}
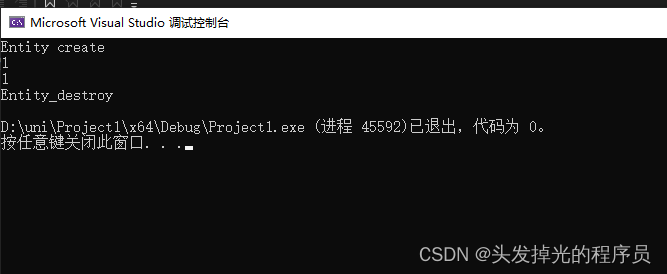
e0->print();
}
return 0;
} 
弱指针weak_ptr
1.可以和共享指针shared_ptr一起使用。
2.weak_ptr可以被复制,但是同时不会增加额外的控制块来控制计数,仅仅声明这个指针还活着。
当你将一个shared_ptr赋值给另外一个shared_ptr,引用计数++,而若是 把一个shared_ptr赋值给一个weak_ptr时,它不会增加引用计数。这很好,如果你不想要Entity的所有权,就像你可能在排序一个Entity列表,你不关心它们是否有效,你只需要存储它们的一个引用就可以了。
弱指针,无法调用赋值的类的成员和函数
#include<memory>
int cnt = 0;
class Entity {
public:
Entity() {
cnt++;
std::cout << "Entity create" << std::endl;
}
void print() {
std::cout << cnt << std::endl;
}
~Entity() {
std::cout << "Entity_destroy" << std::endl;
}
};
int main() {
{
std::weak_ptr<Entity> e0;
{
std::shared_ptr<Entity> e1 = std::make_shared<Entity>();
e0 = e1;
e1->print();
e0->print();//报错
}
}
return 0;
}C++的拷贝与拷贝构造函数
浅拷贝
浅拷贝只拷贝基本数据类型,意味着,如果是拷贝指针,因为指针是变量,指针内的值是地址,所以浅拷贝是拷贝地址,这样会导致一个很严重的问题,如下:
class String {
public:
char* str;
int m_size;
String(const char * p_str) {
m_size = strlen(p_str);
str = new char[m_size + 1];
memcpy(str, p_str, m_size);
str[m_size] = 0;
}
~String() {
delete str;
}
};
std::ostream& operator<<(std::ostream& stream, const String& s) {
stream << s.str;
return stream;
}
int main() {
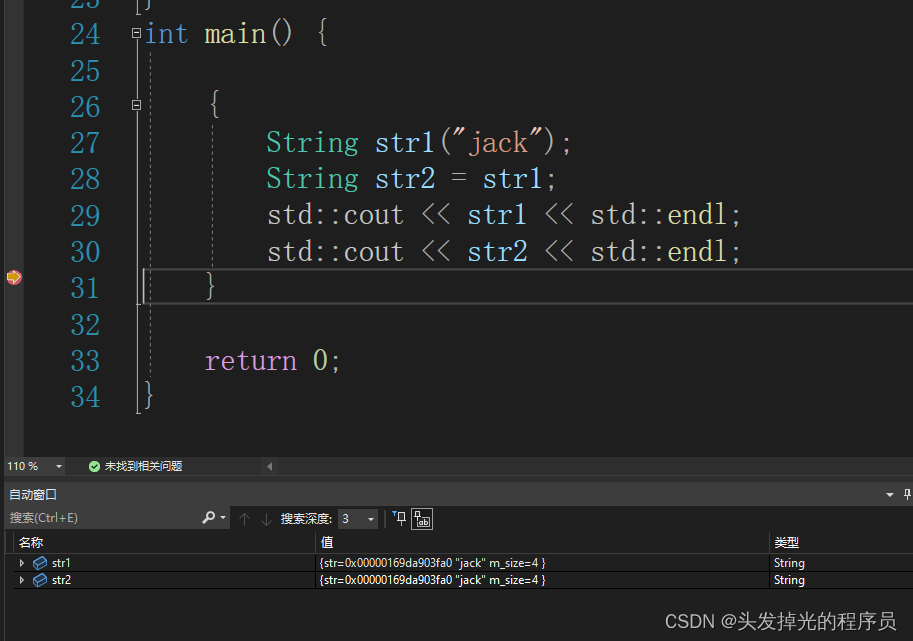
{
String str1("jack");
String str2 = str1;
std::cout << str1 << std::endl;
std::cout << str2 << std::endl;
}
return 0;
}这样拷贝相当于拷贝指针的地址,这样当析构的时候,相当于删两次同样的地址。下面可以看到,指针指向的地址相同,这样程序析构的时候,会崩溃。
解决这个问题的方式就是拷贝构造函数,拷贝构造函数是一个构造函数。
拷贝构造函数的格式:
String(const String& other):m_size(other.m_size){
}
T(const& T t){}friend声明可以,在外部访问私有变内容。这里还改变了[]运算符,使得返回了该字符的引用,于是可以直接改。
class String {
char* str;
int m_size;
public:
String(const char * p_str) {
m_size = strlen(p_str);
str = new char[m_size + 1];
memcpy(str, p_str, m_size);
str[m_size] = 0;
}
~String() {
delete[] str;
}
String(const String& other):m_size(other.m_size){
str = new char[m_size+1];
memcpy(str, other.str, m_size);
str[m_size] = 0;
}
char& operator[](const int index)const {
return str[index];
}
friend std::ostream& operator<<(std::ostream& stream, const String& s);
};
std::ostream& operator<<(std::ostream& stream, const String& s) {
stream << s.str;
return stream;
}
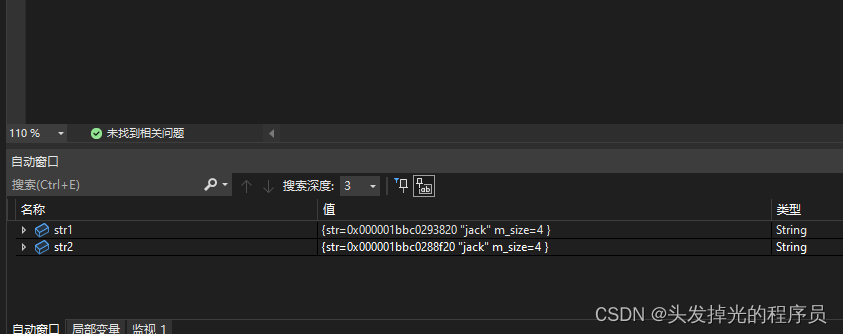
int main() {
{
String str1("jack");
String str2 = str1;
str2[2] = 'p';
std::cout << str1 << std::endl;
std::cout << str2 << std::endl;
}
return 0;
}可以看到,指针指向的地址不一样了。
C++的箭头操作符
C++重载 箭头运算符_c++ 箭头运算符重载-CSDN博客
他写的真的很牛
1.特点:
箭头操作符(->)的内置用法是,使用一个类对象的指针来调用所指对象的成员。左操作数为对象指针,右操作数为该对象的成员。
重载箭头操作符,首先重载箭头操作符必须定义为类成员函数。
箭头操作符与众不同。它其实是一元操作符,却表现得像二元操作符一样:接受一个对象和一个成员名。对对象解引用以获取成员。不管外表如何,箭头操作符不接受显式形参。
对于形如point->member的表达式来说,point必须是二者之一:指向类对象的指针、一个重载了operator->() 的类对象。
//第一种形式,ptr->member
class Entity {
public:
Entity() {
std::cout << "Entity" << std::endl;
}
void print() {
std::cout << "Entity_class_call" << std::endl;
}
};
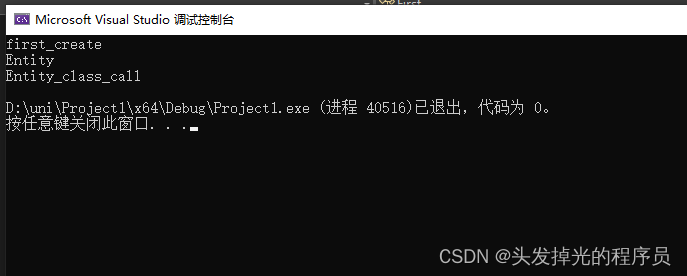
int main() {
Entity* e = new Entity();
e->print();
return 0;
}第二种方式一个重载了operator->() 的类对象。这里返回也必须是指针
class First {
public:
First() {
std::cout << "first_create" << std::endl;
}
void print() {
std::cout << "first_class_call" << std::endl;
}
};
class Entity {
private:
First* first;
public:
Entity(First* f):first(f) {
std::cout << "Entity" << std::endl;
}
void print() {
std::cout << "Entity_class_call" << std::endl;
}
First* operator->() {
std::cout << "Entity->()call" << std::endl;
return first;
}
};
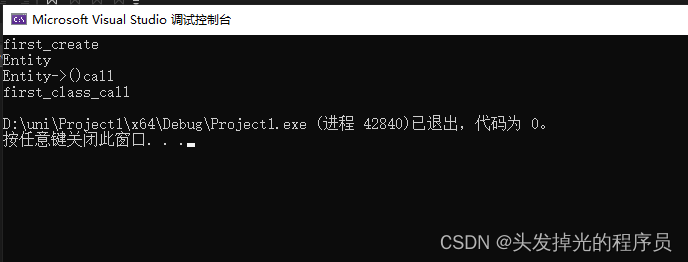
int main() {
//Entity* e = new Entity();
Entity e(new First());
e->print();
return 0;
}
这里一个有趣的现象,让我认为,只要遇到了指向类对象的指针,那么就会终止。
这里我使用Entity的指针。
class First {
public:
First() {
std::cout << "first_create" << std::endl;
}
void print() {
std::cout << "first_class_call" << std::endl;
}
};
class Entity {
private:
First* first;
public:
Entity(First* f):first(f) {
std::cout << "Entity" << std::endl;
}
void print() {
std::cout << "Entity_class_call" << std::endl;
}
First* operator->() {
std::cout << "Entity->()call" << std::endl;
return first;
}
};
int main() {
//Entity* e = new Entity();
Entity* e = new Entity(new First());
e->print();
return 0;
}这里可以看到,First不会被调用了
根据point类型的不同,有如下两条作用规则:
1.如果point是指针,则按照内置的箭头运算符去处理。表达式等价于(*point).member。首先解引用该指针,然后从所得的对象中获取指定的成员。如果point所指的类没有名为member的成员,则编译器报错。
2.如果point是一个定义了operator->() 的类对象,则point->member等价于point.operator->() ->member。其中,如果operator->()的返回结果是一个指针,则转第1步;如果返回结果仍然是一个对象,且该对象本身也重载了operator->(),则重复调用第2步,否则编译器报错。最终,过程要么结束在第一步,要么无限递归,要么报错。
class First {
public:
First() {
}
void print() {
std::cout << "first_class_call" << std::endl;
}
First* operator->() {
std::cout << "First->()call" << std::endl;
return this;
}
};
class Entity {
private:
First first;
public:
Entity(First f):first(f) {
}
void print() {
std::cout << "Entity_class_call" << std::endl;
}
First operator->() {
std::cout << "Entity->()call" << std::endl;
return first;
}
};
int main() {
First f;
Entity e(f);
e->print();
return 0;
}结果可以得到,遇到了this指针,就会结束,并且调用。

它的作用有两个
一个是用在之前所讲的栈生成堆
可以直接使用->
class Entity {
private:
int m_x, m_y;
public:
Entity(int x,int y):m_x(x),m_y(y) {
std::cout << "Entity()_create" << std::endl;
}
friend std::ostream& operator<(std::ostream& stream, const Entity* ptr);
void print() {
std::cout << "hello" << std::endl;
}
};
std::ostream& operator<(std::ostream& stream, const Entity* ptr) {
stream << ptr->m_x << " " << ptr->m_y << std::endl;
return stream;
}
class Unique_ptr {
Entity* entity;
public:
Unique_ptr(Entity* e) :entity(e) {
std::cout << "Unique_ptr_create" << std::endl;
}
Entity* operator->() {
return entity;
}
};
int main() {
{
Unique_ptr ptr(new Entity(1,2));
ptr->print();
}
return 0;
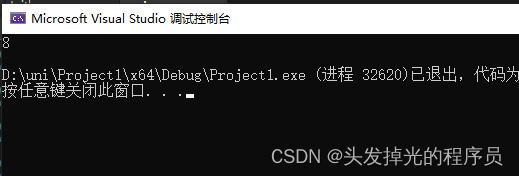
}可用于计算成员变量的offset
引自B站评论:
因为"指针->属性"访问属性的方法实际上是通过把指针的值和属性的偏移量相加,得到属性的内存地址进而实现访问。 而把指针设为nullptr(0),然后->属性就等于0+属性偏移量。编译器能知道你指定属性的偏移量是因为你把nullptr转换为类指针,而这个类的结构你已经写出来了(float x,y,z),float4字节,所以它在编译的时候就知道偏移量(0,4,8),所以无关对象是否创建
class Position {
public:
double x;
float y;
};
int main() {
//nullptr
int offset = (int) & (((Position*)0)->y);
std::cout << offset << std::endl;
return 0;
} 
C++的动态数组(std::vector) 及其优化
问题1:当向vector数组中添加新元素时,为了扩充容量,当前的vector的内容会从内存中的旧位置复制到内存中的新位置(产生一次复制),然后删除旧位置的内存。 简单说,push_back时,容量不够,会自动调整大小,重新分配内存。这就是将代码拖慢的原因之一。 解决办法: vertices.reserve(n) ,直接指定容量大小,避免重复分配产生的复制浪费。
在非vector内存中创建对象进行初始化时,即push_back() 向容器尾部添加元素时,首先会创建一个临时容器对象(不在已经分配好内存的vector中)并对其追加元素,然后再将这个对象拷贝或者移动到【我们真正想添加元素的容器】中 。这其中,就造成了一次复制浪费。 解决办法: emplace_back,直接在容器尾部创建元素,即直接在已经分配好内存的那个容器中直接添加元素,不创建临时对象。
简单的说:
reserve提前申请内存,避免动态申请开销 emplace_back直接在容器尾部创建元素,省略拷贝或移动过程
#include<iostream>
#include<cstring>
#include<vector>
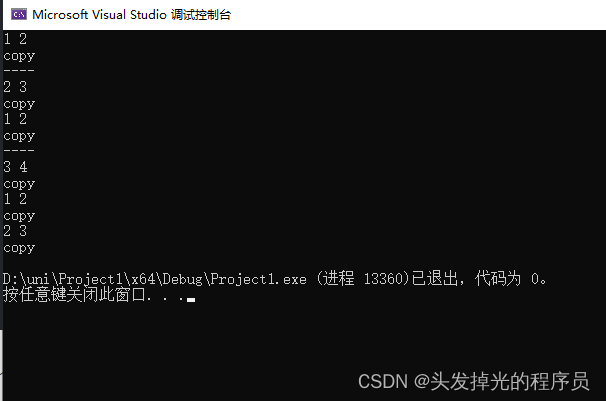
class Entity {
public:
int m_x, m_y;
Entity(int x,int y):m_x(x),m_y(y){}
Entity(const Entity& e) {
std::cout << e.m_x << " " << e.m_y << std::endl;
std::cout << "copy" << std::endl;
this->m_x = e.m_x;
this->m_y = e.m_y;
}
};
std::ostream& operator<<(std::ostream& stream, Entity& e) {
stream << e.m_x << " " << e.m_y;
return stream;
}
int main() {
std::vector<Entity> v;
v.push_back(Entity(1,2));
std::cout << "----" << std::endl;
v.push_back(Entity( 2,3 ));
std::cout << "----" << std::endl;
v.push_back(Entity(3,4 ));
return 0;
}结果可以看到,首先进行了一次拷贝,这是因为,首先将(1,2)追加进了一个容器中,然后再将这个对象拷贝或者移动到【我们真正想添加元素的容器】中。然后追加(2,3)的时候,先拷贝追加的到指定位置,然后再拷贝其它的。
所以在下面这种情况循环,最好使用引用。
int main() {
std::vector<Entity> v;
v.push_back(Entity(1,2));
std::cout << "----" << std::endl;
v.push_back(Entity( 2,3 ));
std::cout << "----" << std::endl;
v.push_back(Entity(3,4 ));
std::cout << "----" << std::endl;
for (Entity& e : v) {
std::cout << e << std::endl;
}
std::cout << "*************************" << std::endl;
for (Entity e : v) {
std::cout << e << std::endl;
}
return 0;
} 
emplace_back一定要如下的方式使用,否则没用。
int main() {
std::vector<Entity> v;
v.emplace_back(1,2);
std::cout << "----" << std::endl;
v.emplace_back(2,3);
std::cout << "----" << std::endl;
v.emplace_back(3,4);
return 0;
}
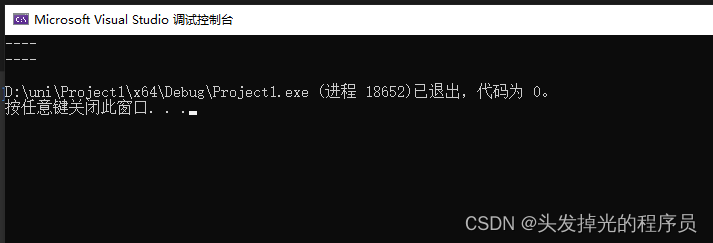
reserve(n)
int main() {
std::vector<Entity> v;
v.reserve(3);
v.emplace_back(1,2);
std::cout << "----" << std::endl;
v.emplace_back(2,3);
std::cout << "----" << std::endl;
v.emplace_back(3,4);
return 0;
}
C++中使用库(静态链接) 创建与使用库(VisualStudio多项目)
因为不想找外部库,所以两个一起。
首先是创建静态库
这里我创建了project2
然后,我生成出了两个文件,我把他们分别存放
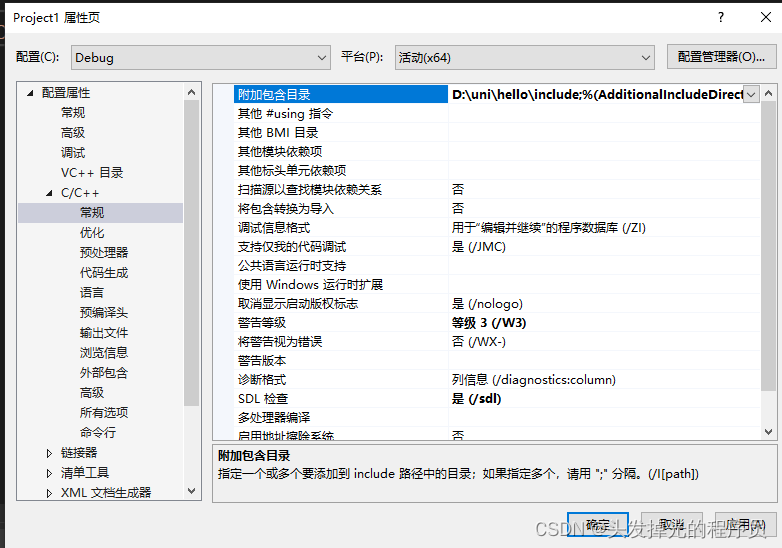
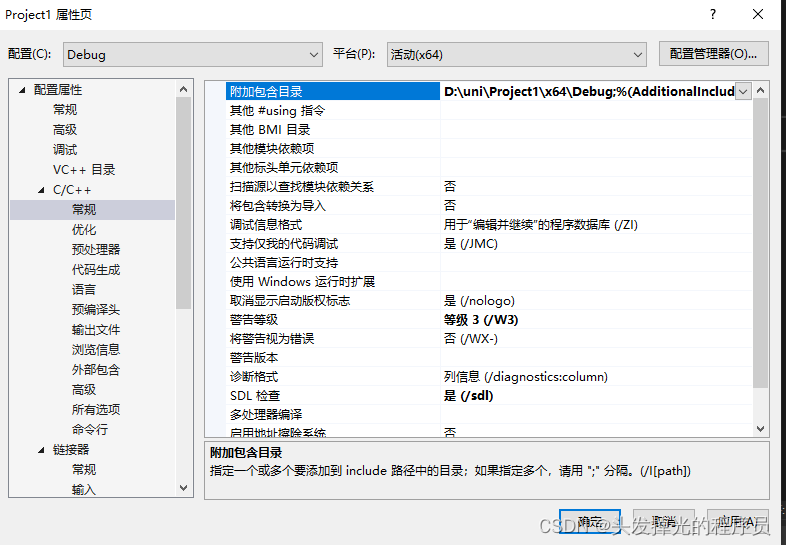
project1 配置 ,包含目录需要包含所有的库目录
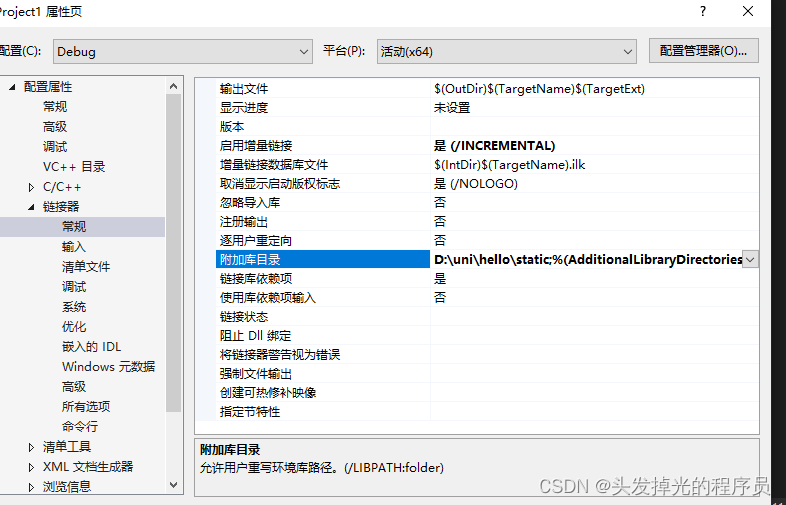
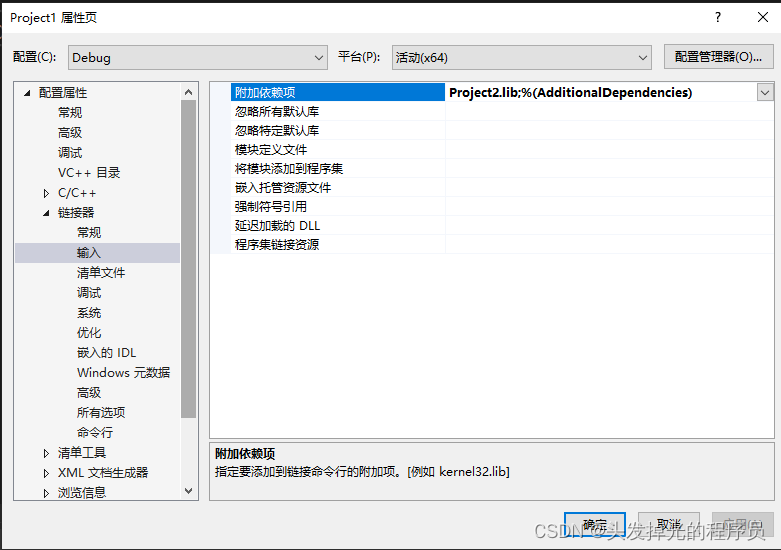
#include<iostream>
#include<Hello.h>
int main() {
SayHello();
return 0;
}
但是其实如果同时vs创建的解决方案有一个更好的方式
只需要编辑如下:
在project1中添加引用
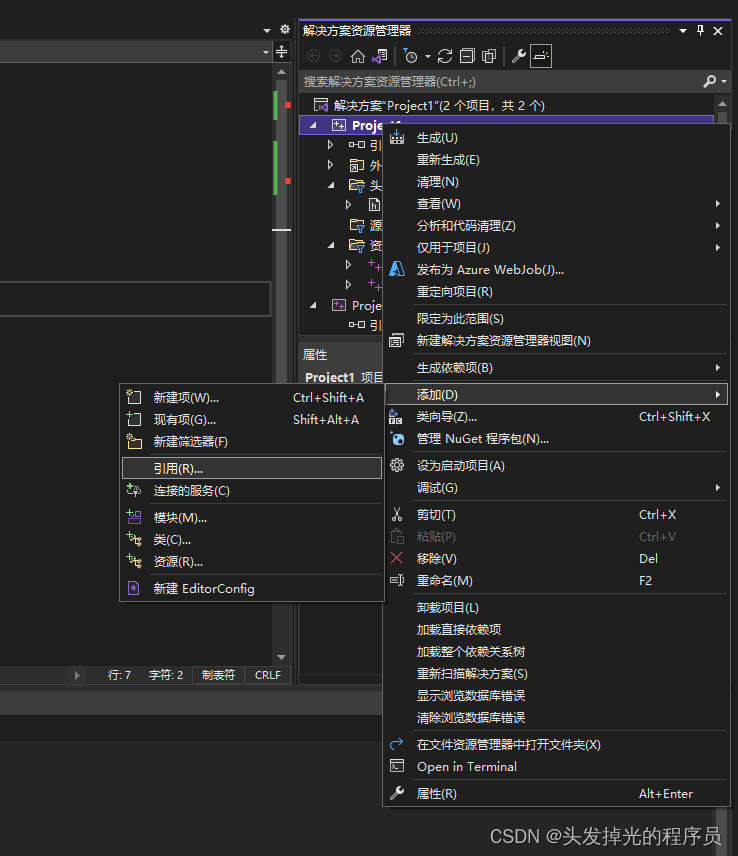
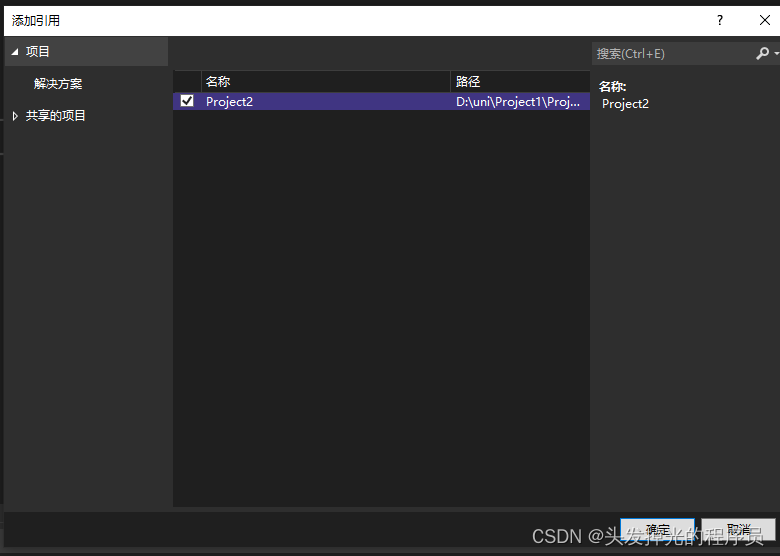
这样做的好处是,当project2改变名字的时候,不需要再去手动改变名字。
动态库
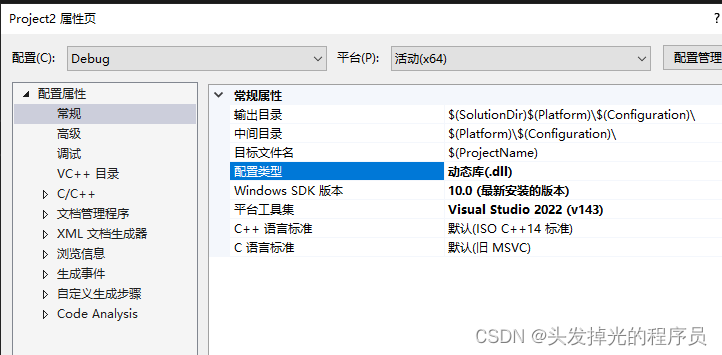
动态库,失败了,好像缺点东西,它对于dll的lib我没找到。
C++中如何处理多返回值
记录下博主说的一般的处理方法。
方法一:通过函数参数传引用或指针的方式
把函数定义成
void,然后通过参数引用传递的形式“返回”两个字符串,这个实际上是修改了目标值,而不是返回值,但某种意义上它确实是返回了两个字符串,而且没有复制操作,技术上可以说是很好的。但这样做会使得函数的形参太多了,可读性降低,有利有弊 。同时指针一般比引用好用,因为指针可以使用nullptr来判断是否需要返回参数。
#include<iostream>
#include<string>
void GetName(std::string* res1, std::string* res2) {
*res1 = "jack";
*res2 = "god";
}
int main() {
std::string str1;
std::string str2;
GetName(&str1, &str2);
std::cout << str1 << " " << str2 << std::endl;
return 0;
}
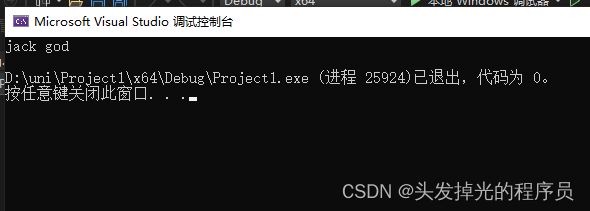
#include<iostream>
#include<string>
void GetName(std::string& res1, std::string& res2) {
res1 = "jack";
res2 = "god";
}
int main() {
std::string str1;
std::string str2;
GetName(str1, str2);
std::cout << str1 << " " << str2 << std::endl;
return 0;
} 
方法二: 通过函数的返回值是一个array(数组)或vector
不同点是Array是在栈上创建,而vector会把它的底层储存在堆上,所以从技术上说,返回Array会更快
但以上方法都只适用于相同类型的多种数据的返回
#include<iostream>
#include<string>
#include<array>
#include<vector>
//std::array<std::string,2> GetName() {
// std::array<std::string, 2> res;
// res[0] = "jack";
// res[1] = "god";
// return res;
//}
std::vector<std::string> GetName() {
std::vector<std::string> res;
res.reserve(2);
res.emplace_back("jack");
res.emplace_back("god");
return res;
}
int main() {
std::string str1;
std::string str2;
/*std::array<std::string, 2> res=GetName();*/
std::vector<std::string> res = GetName();
str1 = res[0];
str2 = res[1];
std::cout << str1 << " " << str2 << std::endl;
return 0;
}方法三:使用std::pair返回两个返回值
可以返回两个不同类型的数据返。
使用std::pair这种抽象数据结构,该数据结构可以绑定两个异构成员。这种方式的弊端是只能返回两个值。我挺喜欢用的,可以嵌套。
#include<iostream>
std::pair<std::string,std::pair<std::string,std::string>> GetName() {
std::pair<std::string, std::pair<std::string, std::string>> res;
res=std::make_pair("jack", std::make_pair("god", "ko"));
return res;
}
int main() {
std::string str1;
std::string str2;
/*std::array<std::string, 2> res=GetName();*/
std::pair<std::string, std::pair<std::string, std::string>> res = GetName();
str1 = res.first;
str2 = res.second.first;
std::cout << str1 << " " << str2 << std::endl;
return 0;
}方法四:使用std::tuple返回三个或者三个以上返回值(很不推荐)
std::tuple这种抽象数据结构可以将三个或者三个以上的异构成员绑定在一起,返回std::tuple作为函数返回值理论上可以返回三个或者三个以上的返回值。
tuple相当于一个类,它可以包含x个变量,但他不关心类型,用tuple需要包含头文件
#include<iostream>
#include<tuple>
#include<utility>
std::tuple<int,std::string,bool> GetName() {
std::tuple<int, std::string, bool> res;
res = std::make_tuple(22, "jack", true);
return res;
}
int main() {
int a;
std::string str;
bool b;
/*std::array<std::string, 2> res=GetName();*/
std::tuple<int, std::string, bool> res = GetName();
a = std::get<0>(res);
str = std::get<1>(res);
b = std::get<2>(res);
std::cout << a << " " << str << std::endl;
return 0;
}还可以使用tie,来指定不同的变量分配
#include<iostream>
#include<string>
#include<tuple>
#include<utility>
std::tuple<int,std::string,bool> GetName() {
std::tuple<int, std::string, bool> res;
res = std::make_tuple(22, "jack", true);
return res;
}
int main() {
int a;
std::string str;
bool b;
/*std::array<std::string, 2> res=GetName();*/
std::tuple<int, std::string, bool> res = GetName();
std::tie(a, str, b) = res;
std::cout << a << " " << str << std::endl;
return 0;
}方法五:返回一个结构体(推荐)(别引用,栈变量在离开作用域会寄)
结构体是在栈上建立的,所以在技术上速度也是可以接受的
而且不像用pair的时候使用只能temp.first, temp.second,这样不清楚前后值是什么,可读性不佳。而如果换成temp.str, temp.val后可读性极佳,永远不会弄混!
#include<iostream>
#include<string>
#include<tuple>
#include<utility>
struct Point {
int number;
std::string str;
bool is;
};
Point GetName() {
Point res={ 1,"jackgod",true };
return res;
}
int main() {
int a;
std::string str;
bool b;
/*std::array<std::string, 2> res=GetName();*/
Point res = GetName();
a = res.number;
str = res.str;
b = res.is;
std::cout << a << " " << str << std::endl;
return 0;
}C++的模板
模板:模板允许你定义一个可以根据你的用途进行编译的模板(有意义下)。故所谓模板,就是让编译器基于DIY的规则去为你写代码 。
不使用模板
功能相同,只是传入参数不同,就会很很冗余。
#include<iostream>
#include<string>
void print(std::string str) {
std::cout << str << std::endl;
}
void print(int num) {
std::cout << num << std::endl;
}
void print(float num) {
std::cout << num << std::endl;
}
int main() {
print("jack");
print(120);
print(1.2f);
return 0;
}模板格式:
格式:
template<typename T>
#include<iostream>
#include<string>
template <typename T> void print(T str) {
std::cout << str << std::endl;
}
int main() {
print("jack");
print(120);
print(1.2f);
return 0;
}通过
template定义,则说明定义的是一个模板,它会在编译期被评估,所以template后面的函数其实不是一个实际的代码,只有当我们实际调用时,模板函数才会基于传递的参数来真的创建 。 只有当真正调用函数的时候才会被实际创建 。
比如下面的例子就会出问题
没有错误提示,只有当调用的时候,模板函数才会创建。
#include<iostream>
#include<string>
template <typename T> void print(T str) {
std::cout << str2 << std::endl;
}
int main() {
/*print("jack");
print(120);
print(1.2f);*/
return 0;
}类的模板
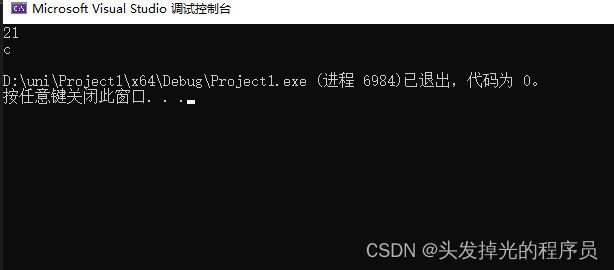
传递数字给模板,来指定要生成的类
#include<iostream>
#include<string>
template<int N,char id> class Entity {
int li[N];
public:
void Print() {
std::cout << N << std::endl;
std::cout << id << std::endl;
}
};
int main() {
Entity<21, 'c'> e;
e.Print();
return 0;
} 
提醒:不要滥用模板!
C++的堆和栈内存的比较
1.当我们的程序开始的时候,程序被分成了一堆不同的内存区域,除了堆和栈以外,还有很多东西,但我们最关心这两个 。
2.栈通常是一个预定义大小的内存区域,通常约为2兆字节左右。堆也是一个预定义了默认值的区域,但是它可以随着应用程序的进行而改变。
3.栈和堆内存区域的实际位置(物理位置)在ram中完全一样(并不是一个存在CPU缓存而另一个存在其他地方)
在程序中,内存是用来实际储存数据的。我们需要一个地方来储存允许程序所需要的数据(比如局部变量or从文件中读取的东西)。而栈和堆,它们就是可以储存数据的地方,但 栈和堆的工作原理非常非常不同,但本质上它们做的事情是一样的
栈和堆的区别
区别一:定义格式不同
int main() {
int z = 1;//栈
int* d = new int;//堆
*d = 1;
return 0;
}区别二:内存分配方式不同
对栈来说:
在栈上,分配的内存都是 连续的。添加一个int,则 栈指针(栈顶部的指针)就移动4个字节,所以连续分配的数据在内存上都是 连续的。栈分配数据是直接把数据堆在一起(所做的就是移动栈指针),所以栈分配数据会很快 。
如果离开作用域,在栈中分配的所有内存都会弹出,内存被释放。
对堆来说
在堆上,分配的内存都是 不连续的,new实际上做的是在内存块的 空闲列表中找到空闲的内存块,然后把它用一个指针圈起来,然后返回这个指针。(但如果 空闲列表找不到合适的内存块,则会询问 操作系统索要更多内存,而这种操作是很麻烦的,潜在成本是巨大的)
离开作用域后,堆中的内存仍然存在
建议: 能在栈上分配就在栈上分配,不能够在栈上分配时或者有特殊需求时(比如需要生存周期比函数作用域更长,或者需要分配一些大的数据),才在堆上分配
C++的宏
1.预处理阶段 :当编译C++代码时,首先预处理器会过一遍C++所有的以#符号开头(这是预编译指令符号)的语句,当预编译器将这些代码评估完后给到编译器去进行实际的编译。
2.宏和模板的区别:发生时间不同,宏是在预处理阶段就被评估了,而模板会被评估的更晚一点。
3.用宏的目的:写一些宏将代码中的文本替换为其他东西(纯文本替换)(不一定是简单的替换,是可以自定义调用宏的方式的)
#include<iostream>
#include<string>
#define log(x) std::cout<<x<<std::endl
int main() {
log("jack");
//等价于 std::cout<<x<<std::endl;
return 0;
}宏可以辅助调试
在Debug模式下会有很多日志的输出,但是在Release模式下就不需要日志的输出了。正常的方法可能会删掉好多的输出日志的语句或者函数,但是用宏可以直接取消掉这些语句
这里我们定义一个预处理参数。
下面两种定义方式都是对的(在Debug的条件下)
方式1:
#include<iostream>
#include<string>
#define PRE_DEBUG 1
#if PRE_DEBUG==1
#define log() std::cout<<"hello"<<std::endl;
#else
#define log()
#endif
int main() {
log("jack");
return 0;
}方式2:
配置Debug的预处理参数
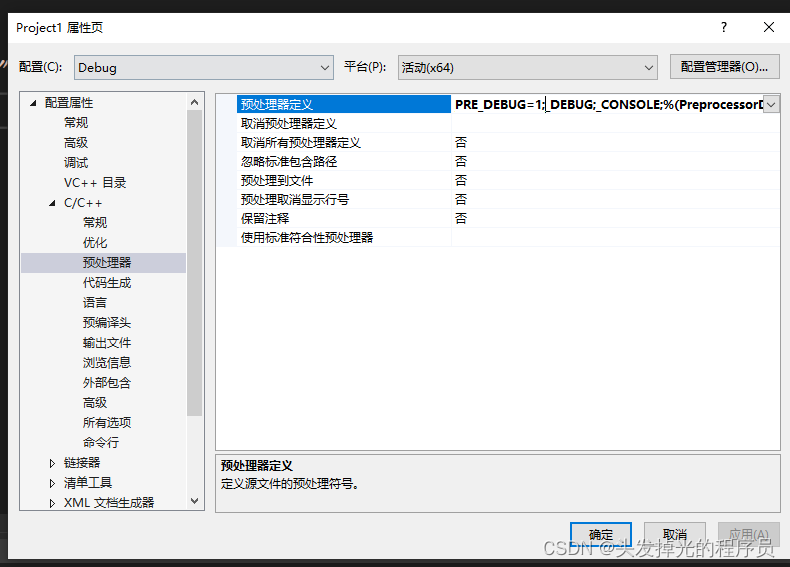
#include<iostream>
#include<string>
#if PRE_DEBUG==1
#define log() std::cout<<"hello"<<std::endl;
#else
#define log()
#endif
int main() {
log("jack");
return 0;
}输出hello
同时可以在Release的配置下设置为0,这样就能区分调用
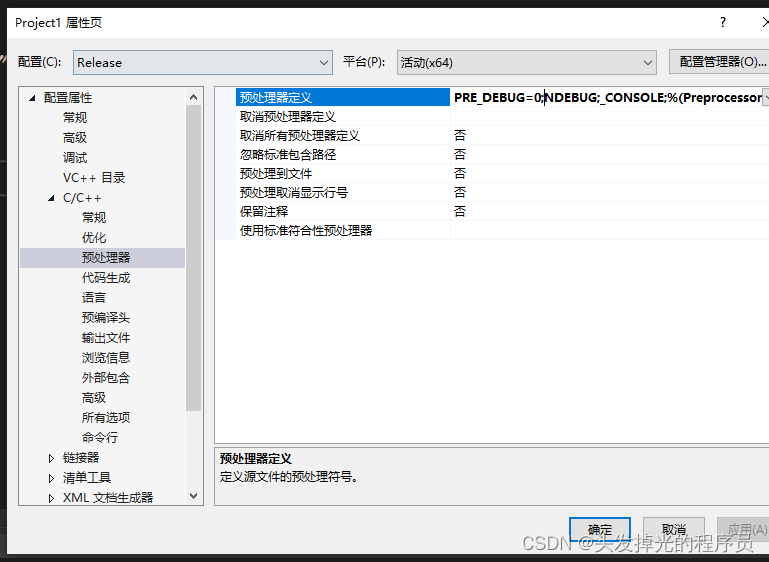
C++的auto关键字
auto的使用场景:
在使用iterator 的时候
#include<iostream>
#include<string>
#include<vector>
int main() {
std::vector<int> v{ 1,2,3,4,5 };
for (std::vector<int>::iterator it = v.begin(); it != v.end(); it++) {
std::cout << *it << std::endl;
}
for (auto it = v.begin(); it != v.end(); it++) {
std::cout << *it << std::endl;
}
}当类型名过长的时候可以使用auto
#include<unordered_map>
class Device {
};
class ManageDevice {
public:
std::unordered_map<std::string, std::vector<Device*>> mp;
std::unordered_map<std::string, std::vector<Device*>>& GetDevice(std::string name) {
return mp;
}
};
int main() {
ManageDevice manager;
//std::unordered_map<std::string, std::vector<Device*>>& mp = manager.GetDevice("jack");
auto& mp= manager.GetDevice("jack");
}除此之外类型名过长的时候也可以使用using或typedef方法:
#include<vector>
#include<unordered_map>
class Device {
};
class ManageDevice {
public:
std::unordered_map<std::string, std::vector<Device*>> mp;
std::unordered_map<std::string, std::vector<Device*>>& GetDevice(std::string name) {
return mp;
}
};
int main() {
ManageDevice manager;
typedef std::unordered_map<std::string, std::vector<Device*>>& M;
using MM = std::unordered_map<std::string, std::vector<Device*>>&;
//std::unordered_map<std::string, std::vector<Device*>>& mp = manager.GetDevice("jack");
M mp= manager.GetDevice("jack");
MM mp= manager.GetDevice("jack");
}auto使用建议:如果不是上面两种应用场景,请尽量不要使用auto!能不用,就不用!会伤害代码的可阅读性。
C++的静态数组(std::array)
1.std::array是一个实际的标准数组类,是C++标准模板库的一部分。
2.静态的是指不增长的数组,当创建array时就要初始化其大小,不可再改变。
3.使用格式
#include<iostream>
#include<array>
int main() {
std::array<int, 5> li;
li[0] = 1;
std::cout << li[0] << std::endl;
return 0;
}4.array和原生数组都是创建在栈上的(vector是在堆上创建底层数据储存的)
5.原生数组越界的时候不会报错,而array会有越界检查,会报错提醒。
6.使用std::array的好处是可以访问它的大小(通过size()函数),它是一个类。
#include<iostream>
#include<array>
void print(const std::array<int, 5>& li) {
for (auto i : li) {
std::cout << i << std::endl;
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5 };
print(li);
return 0;
}但是这样不具备可变性,首先我并不知道类型是什么,其次,我并不知道大小为多少。
使用模板
#include<iostream>
#include<array>
template<typename T, int N> void print(const std::array<T, N>& li) {
for (auto i : li) {
std::cout << i << std::endl;
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5 };
print(li);
return 0;
}C语言风格的函数指针
定义方式:
这里我main用模板,会给我报错。
#include<iostream>
#include<array>
template<typename T, int N>
int print(const std::array<T, N>& li) {
for (auto i : li) {
std::cout << i << std::endl;
}
return 1;
}
void F() {
std::cout << "Hello" << std::endl;
}
int main() {
void(*Funtion2)() = F;
Funtion2();
int (*function)(const std::array<int,5>&) = print;
std::array<int, 5> li{ 1,2,3,4,5};
int res=function(li);
return 0;
}为什么要首先使用函数指针
如果需要将一个函数作为另一个函数的形参,那么就要需要函数指针 .(这里给出auto的用法)
#include<iostream>
#include<array>
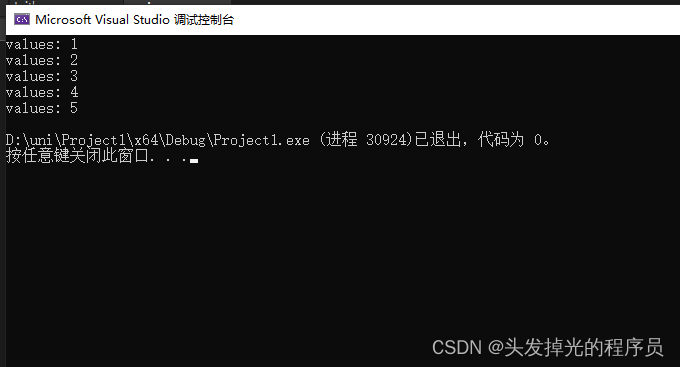
void PrintNumber(int number) {
std::cout << "values: " << number << std::endl;
}
template<typename T, int N> void print(const std::array<T, N>& ar, void(*func)(int)) {
for (auto t : ar) {
func(t);
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5};
auto Function = PrintNumber;
print(li, Function);
return 0;
} 
优化:lambda
lambda本质上是一个普通的函数,只是它不像普通函数这样声明,它是我们的代码在过程中生成的,用完即弃的函数,不算一个真正的函数,是匿名函数 。
格式:[] ({形参表}) {函数内容}
template<typename T, int N> void print(const std::array<T, N>& ar, void(*func)(int)) {
for (auto t : ar) {
func(t);
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5};
print(li, [](int value) {std::cout << "values: " << value << std::endl; });
return 0;
}C++的lambda
参考网站:https://en.cppreference.com/w/cpp/language/lambda
lambda本质上是一个匿名函数。 用这种方式创建函数不需要实际创建一个函数 ,它就像一个快速的一次性函数 。 lambda更像是一种变量,在实际编译的代码中作为一个符号存在,而不是像正式的函数那样
使用场景
在我们会设置函数指针指向函数的任何地方,我们都可以将它设置为lambda
lambda表达式的写法(使用格式):
[]( {参数表} ){ 函数体 }
中括号表示的是捕获,作用是如何传递变量 lambda使用外部(相对)的变量时,就要使用捕获。
//If the capture-default is `&`, subsequent simple captures must not begin with `&`.
struct S2 { void f(int i); };
void S2::f(int i)
{
[&]{}; // OK: by-reference capture default
[&, i]{}; // OK: by-reference capture, except i is captured by copy
[&, &i] {}; // Error: by-reference capture when by-reference is the default
[&, this] {}; // OK, equivalent to [&]
[&, this, i]{}; // OK, equivalent to [&, i]
}
//If the capture-default is `=`, subsequent simple captures must begin with `&` or be `*this` (since C++17) or `this` (since C++20).
struct S2 { void f(int i); };
void S2::f(int i)
{
[=]{}; // OK: by-copy capture default
[=, &i]{}; // OK: by-copy capture, except i is captured by reference
[=, *this]{}; // until C++17: Error: invalid syntax
// since C++17: OK: captures the enclosing S2 by copy
[=, this] {}; // until C++20: Error: this when = is the default
// since C++20: OK, same as [=]
}
详情参考:https://en.cppreference.com/w/cpp/language/lambda当我需要捕获外面的变量的时候,用以前的方式会报错。
#include<iostream>
#include<array>
void PrintNumber(int number) {
std::cout << "values: " << number << std::endl;
}
template<typename T, int N> void print(const std::array<T, N>& ar, void(*func)(int)) {
for (auto t : ar) {
func(t);
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5};
std::string test1 = "jack";
int test2 = 20;
print(li, [test1](int value) {std::cout << "values: " << value << std::endl; std::cout << test1 << std::endl; });//error
return 0;
}于是需要加上std::function<void(int)>&(可以选择引用) func 它在functional的头文件中
#include<iostream>
#include<array>
#include<functional>
void PrintNumber(int number) {
std::cout << "values: " << number << std::endl;
}
template<typename T, int N> void print(const std::array<T, N>& ar, std::function<void(int)> func) {
for (auto t : ar) {
func(t);
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5};
std::string test1 = "jack";
int test2 = 20;
print(li, [test1](int value) {std::cout << "values: " << value << std::endl; std::cout << test1 << std::endl; });//铺货test1
return 0;
}捕获所有
#include<iostream>
#include<array>
#include<functional>
void PrintNumber(int number) {
std::cout << "values: " << number << std::endl;
}
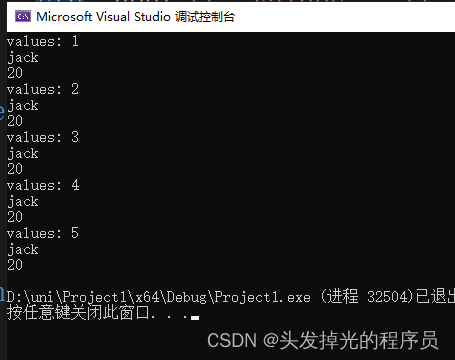
template<typename T, int N> void print(const std::array<T, N>& ar, std::function<void(int)> func) {
for (auto t : ar) {
func(t);
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5};
std::string test1 = "jack";
int test2 = 20;
print(li, [=](int value) {std::cout << "values: " << value << std::endl; std::cout << test1 << std::endl; std::cout << test2 << std::endl; });//error
return 0;
} 
我们有一个可选的修饰符mutable,它允许lambda函数体修改通过拷贝传递捕获的参数。若我们在lambda中给a赋值会报错,需要写上mutable 。
#include<iostream>
#include<array>
#include<functional>
void PrintNumber(int number) {
std::cout << "values: " << number << std::endl;
}
template<typename T, int N> void print(const std::array<T, N>& ar, std::function<void(int)> func) {
for (auto t : ar) {
func(t);
}
}
int main() {
std::array<int, 5> li{ 1,2,3,4,5};
std::string test1 = "jack";
int test2 = 20;
print(li, [=](int value) mutable {test1 = "god"; std::cout << "values: " << value << std::endl; std::cout << test1 << std::endl; std::cout << test2 << std::endl; });
return 0;
} 另一个使用lambda的场景find_if
我们还可以写一个lambda接受vector的整数元素,遍历这个vector找到比3大的整数,然后返回它的迭代器,也就是满足条件的第一个元素。
find_if是一个搜索类的函数,区别于find的是:它可以接受一个函数指针来定义搜索的规则,返回满足这个规则的第一个元素的迭代器。这个情况就很适合lambda表达式的出场了
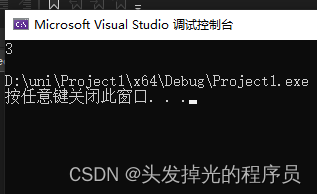
#include<iostream>
#include<vector>
int main() {
std::vector<int> v{ 1,2,3,4,4,5,6,7 };
auto ptr = std::find_if(v.begin(), v.end(), [](int value) {return value > 3; });
std::cout << ptr-v.begin() << std::endl;
return 0;
} 
为什么不使用using namespace std
当使用函数命名冲突的时候,使用多个命名空间using会冲突。
#include<iostream>
#include<vector>
namespace apple {
void print(int a) {
std::cout << "apple: " << a << std::endl;
}
}
namespace pear {
void print(int a) {
std::cout << "pear: " << a << std::endl;
}
}
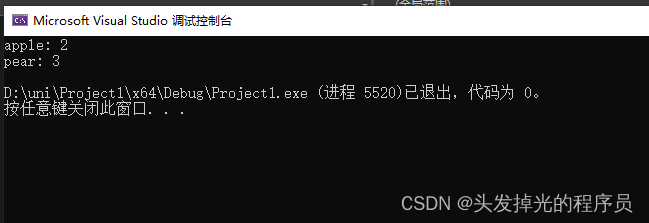
int main() {
using namespace apple;
using namespace pear;
print(2);//error冲突
return 0;
}C++的命名空间
1.命名空间是C++独有,C是没有的,故写C时会有命名冲突的风险。
2.类本身就是名称空间 。
类外使用一个类内的成员需要加::3.命名空间(名称空间)的主要目的是避免命名冲突,便于管理各类命名函数。使用名称空间的原因,是因为我们希望能够在不同的上下文中调用相同的符号。
#include<iostream>
#include<vector>
namespace apple {
void print(int a) {
std::cout << "apple: " << a << std::endl;
}
}
namespace pear {
void print(int a) {
std::cout << "pear: " << a << std::endl;
}
}
int main() {
apple::print(2);
pear::print(3);
return 0;
} 
大型程序往往会使用多个独立开发的库,这些库会定义大量的全局名字,如类、函数和模板等,不可避免会出现某些名字相互冲突的情况。命名空间
namespace分割了全局命名空间,其中每个命名空间是一个作用域。
全局命名空间
全局作用域中定义的名字(即在所有类、函数以及命名空间之外定义的名字)也就是定义在全局命名空间
global namespace中。全局作用域是隐式的,所以它并没有名字,下面的形式表示全局命名空间中一个成员:
int aa = 10;
int main() {
apple::print(2);
pear::print(::aa);
return 0;
}嵌套的命名空间
#include<iostream>
#include<vector>
namespace apple {
namespace pear {
void print(int a) {
std::cout << "pear: " << a << std::endl;
}
}
}
int main() {
apple::pear::print(3);
return 0;
}未命名的命名空间
关键字
namespace后紧跟花括号括起来的一系列声明语句是未命名的命名空间unnamed namespace。未命名的命名空间中定义的变量具有静态生命周期:它们在第一次使用前被创建,直到程序结束时才销毁。
Tips:每个文件定义自己的未命名的命名空间,如果两个文件都含有未命名的命名空间,则这两个空间互相无关。在这两个未命名的命名空间里面可以定义相同的名字,并且这些定义表示的是不同实体。如果一个头文件定义了未命名的命名空间,则该命名空间中定义的名字将在每个包含了该头文件的文件中对应不同实体。和其他命名空间不同,未命名的命名空间仅在特定的文件内部有效,其作用范围不会横跨多个不同的文件。未命名的命名空间中定义的名字的作用域与该命名空间所在的作用域相同,如果未命名的命名空间定义在文件的最外层作用域中,则该命名空间一定要与全局作用域中的名字有所区别:
int i;
namespace {
int i;
}
int main() {
apple::pear::print(3);
i = 1;//error i不明确
return 0;
}未命名的命名空间取代文件中的静态声明:
在标准C++引入命名空间的概念之前,程序需要将名字声明成static的以使其对于整个文件有效。在文件中进行静态声明的做法是从C语言继承而来的。在C语言中,声明为static的全局实体在其所在的文件外不可见。 在文件中进行静态声明的做法已经被C++标准取消了,现在的做法是使用未命名的命名空间。
C++的线程
1.使用多线程,首先要添加头文件
#include <thread>。2.在Linux平台下编译时需要加上"-lpthread"链接库
3.创建一个线程对象:
std::thread objName (一个函数指针以及其他可选的任何参数)4.等待一个线程完成它的工作的方法 :
worker.join()这里的线程名字是worker,换其他的也可以,自己决定的) 调用join的目的是: 在主线程上等待 工作线程 完成所有的执行之后,再继续执行主线程
#include<iostream>
#include<thread>
static bool st = true;
void Dowork(int a,int b) {
while (st) {
std::cout << a << " " << b << std::endl;
}
std::cout << "Over" << std::endl;
}
int main() {
std::thread worker(Dowork,1,2);
std::cin.get();//此时工作线程在疯狂循环打印,而主线程此时被cin.get()阻塞
st = false; // 让worker线程终止的条件,如果按下回车,则会修改该值,间接影响到另一个线程的工作。
worker.join();//join:等待工作线程结束后,才会执行接下来的操作
return 0;
} 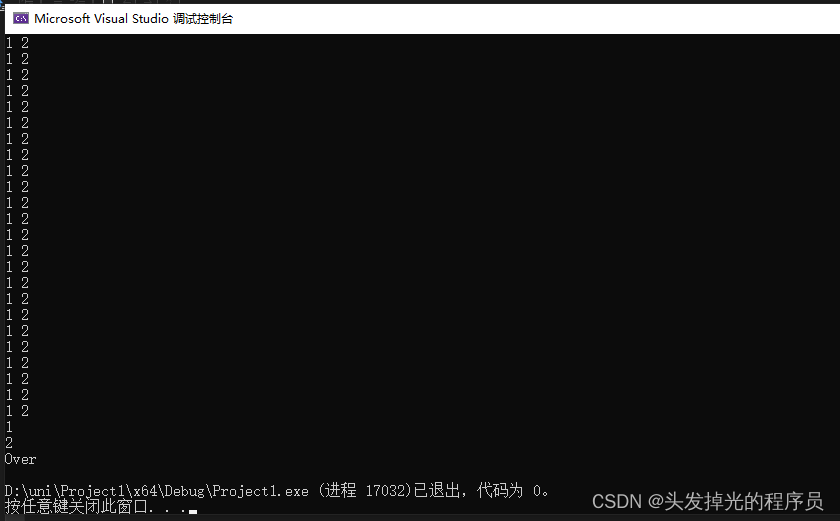
如果是正常情况,
DoWork应该会一直循环下去,但因为这里是多线程,所以可以在另一个线程中修改工作线程的变量,来停止该线程的循环。 多线程对于加速程序是十分有用的,线程的主要目的就是优化。
C++的计时
作用:
计时的使用很重要。在逐渐开始集成更多复杂的特性时,如果编写性能良好的代码时,需要用到计时来看到差异。
利用chrono类计时:
1.包含头文件
#include2.获取当前时间:
std::chrono::time_point<std::chrono::steady_clock> start = std::chrono::high_resolution_clock::now();
auto end_time = std::chrono::high_resolution_clock::now();std::literals::chrono_literals命名空间
using namespace std::literals::chrono_literals;//有了这个,才能用下面1s中的's'
auto start = std::chrono::high_resolution_clock::now(); //记录当前时间
std::this_thread::sleep_for(1s);//休眠1s,实际会比1s大。函数本身有开销。
auto end = std::chrono::high_resolution_clock::now(); //记录当前时间
std::chrono::duration<float> dur = end - start;//也可以写成 auto dur = end - start;
std::cout << dur.count() << std::endl;#include<iostream>
#include<thread>
#include<chrono>
struct Timer {
std::chrono::time_point<std::chrono::steady_clock> start;
Timer() {
start = std::chrono::steady_clock::now();
}
~Timer() {
auto end_time = std::chrono::steady_clock::now();
auto dur = end_time - start;
std::cout << dur.count() << std::endl;
}
};
int main() {
{
Timer ti;
}
return 0;
}C++内置的排序函数(为真的时候,a在b前面)
1.sort( vec.begin(), vec.end(), 谓语)
谓语可以设置排序的规则,谓语可以是内置函数,也可以是lambda表达式。
2.默认是从小到大排序
3.使用内置函数,添加头文件functional,使用std::greater函数,则会按照从大到小顺序排列。
4.使用 lambda 进行灵活排序
#include<iostream>
#include<algorithm>
#include<vector>
std::ostream& operator<<(std::ostream& stream, const std::vector<int>& v) {
for (int i:v) {
stream << i<<" ";
}
return stream;
}
int main() {
std::vector<int> v{ 2,4,10,2 };
sort(v.begin(), v.end());//从小到大排序
std::cout << v << std::endl;
//sort(v.begin(), v.end(), [](int a, int b) {return a > b; });//从大到小排序
//std::cout << v << std::endl;
sort(v.begin(), v.end(), std::greater<int>());
std::cout << v << std::endl;
return 0;
}如果把1排到最后
如果a==1,则把它移到后面去,即返回false,不希望它在b前。 如果b==1,我们希望a在前面,要返回true。
int main() {
std::vector<int> v{1,2,4,10,2 };
sort(v.begin(), v.end());//从小到大排序
std::cout << v << std::endl;
sort(v.begin(), v.end(), [](int a, int b) {
if (a == 1) return false;
if (b == 1) return true;
return a < b;
});
std::cout << v << std::endl;
return 0;
} 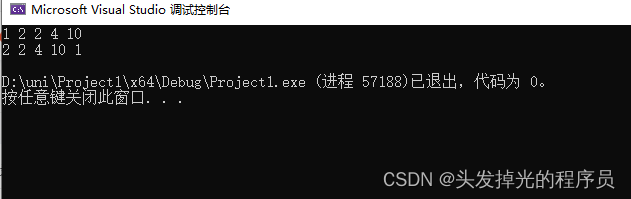
C++的类型双关(type punning)
1.将同一块内存的东西通过不同type的指针给取出来
把一个int型的内存,换成double去解释,当然 这样做很糟糕,因为添加了四字节不属于原本自己的内存,只是作为演示。 原始方法: (取地址,换成对应类型的指针,再解引用)
#include<iostream>
int main() {
int a = 10;
int* c = &a;
double b = *(double*)&a;
double* d = &b;
std::cout << b << std::endl;
return 0;
}这是a的地址,可以看到只有四个字节的时候,0a为10。然后如果你转成一个指向double的指针,然后在解引用,这时候就是8个字节。
这个时候,高位就是全c这样值就错误了
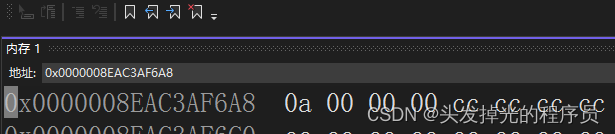

int main() {
int a = 10;
int* c = &a;
//可以用引用,这样就可以避免拷贝成一个新的变量:(只是演示,这样做很糟糕)
double& b = *(double*)&a;
double* d = &b;
std::cout << b << std::endl;
return 0;
}把一个结构体转换成数组进行操作
#include<iostream>
struct Point {
int x;
int y;
};
int main() {
Point p{ 1,2 };
int* ptr = (int*)&p;
std::cout << ptr[0] << std::endl;
std::cout << ptr[1] << std::endl;
return 0;
}
C++的联合体( union )
1.
union { };,注意结尾有分号。2.通常union是匿名使用的,但是匿名union不能含有成员函数
3.在可以使用类型双关的时候,使用union时,可读性更强 。
4.union的特点是共用内存 。可以像使用结构体或者类一样使用它们,也可以给它添加静态函数或者普通函数、方法等待。然而不能使用虚方法,还有其他一些限制。
int main() {
union {
int a;
float b;
};
a = 4;
std::cout << "a:" << a << "\tb:" << b << "\n";
return 0;
}a和b共用一块内存。当b用整形来类型双关浮点数的时候其表达如下
struct Point {
int x;
int y;
};
struct Points
{
union {
struct {
int a, b, c, d;
};
struct {
struct Point k1, k2;
};
};
};
int main() {
Points points;
std::cout << &(points.a) << std::endl;
std::cout << &(points.k1.x) << std::endl;
return 0;
}这里看到内存地址共用
一个比较有用的例子,可以拆分使用,但是集合管理 ,此时就可以通过集合管理设置内容,但是可以分别调用
#include<iostream>
struct Point {
int x;
int y;
};
struct Points
{
union {
struct {
int a, b, c, d;
};
struct {
struct Point k1, k2;
};
};
};
void print(const Point& p) {
std::cout << p.x << " " << p.y << std::endl;
}
int main() {
Points point{ 1,2,3,4 };
print(point.k1);
print(point.k2);
point.c = 10;
print(point.k2);
return 0;
}
引自评论: union里的成员会共享内存,分配的大小是按最大成员的sizeof, 视频里有两个成员,也就是那两个结构体,改变其中一个另外一个里面对应的也会改变. 如果是这两个成员是结构体struct{ int a,b} 和 int k , 如果k=2 ; 对应 a也=2 ,b不变; union我觉得在这种情况下很好用,就是用不同的结构表示同样的数据 ,那么你可以按照获取和修改他们的方式来定义你的 union结构 很方便
C++的虚析构函数
1.如果用基类指针来引用派生类对象,那么基类的析构函数必须是 virtual 的,否则 C++ 只会调用基类的析构函数,不会调用派生类的析构函数。
2.继承时,要养成的一个好习惯就是,基类析构函数中,加上virtual。
为什么要调用派生类析构函数?
若派生类有一个成员int数组在堆上分配东西,在 构造函数中分配,在析构函数中删除。运行当前代码发现没有调用那个派生析构函数,但是它调用了派生类的构造函数。我们在构造函数中分配了一些内存,但是永远不会调用派生析构函数delete释放内存,因为析构函数没有被调用,永远不会删除堆分配数组,这就是所谓的内存泄漏。
class Person {
public:
Person() { std::cout << "Person create\n"; }
~Person() { std::cout << "Person delete\n"; }
};
class Student :public Person{
private:
int* a;
public:
Student() {
a = new int[10];
std::cout << "Student create\n";
}
~Student() {
std::cout << "Student delete\n";
delete[10] a;
}
};
int main() {
{
Person* s = new Student();
delete s;
}
return 0;
}会发现继承了Person后,在只调用了Person的析构函数,这样就会导致内存泄漏
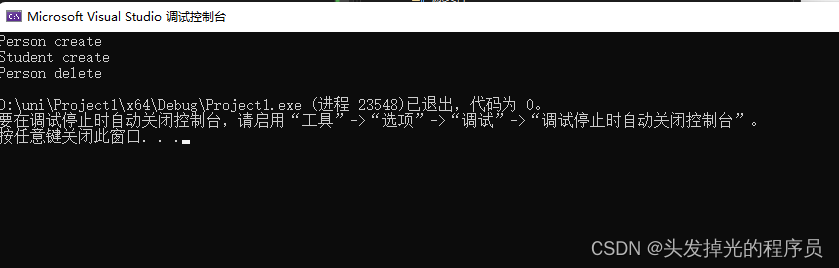
class Person {
public:
Person() { std::cout << "Person create\n"; }
virtual ~Person() { std::cout << "Person delete\n"; }
};
class Student :public Person{
private:
int* a;
public:
Student() {
a = new int[10];
std::cout << "Student create\n";
}
~Student() {
std::cout << "Student delete\n";
delete[10] a;
}
};然后你就可以发现子类的析构函数也调用了
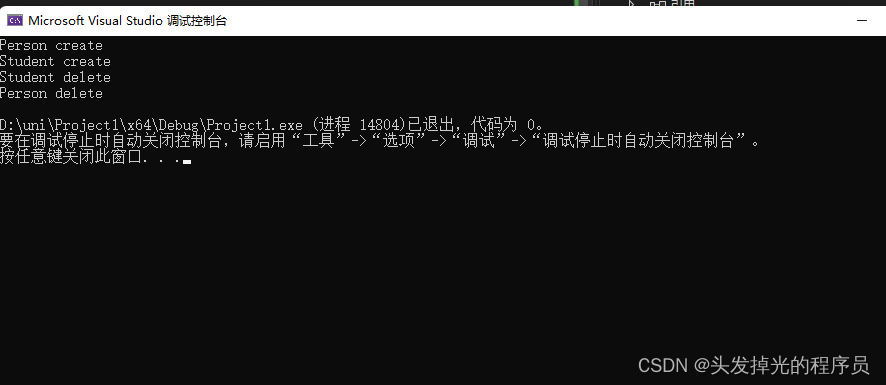
C++的类型转换
cast 分为
static_castdynamic_castreinterpret_castconst_cast
static_cast
static_cast用于进行比较“自然”和低风险的转换,如整型和浮点型、字符型之间的互相转换,不能用于指针类型的强制转换
任何具有明确定义的类型转换,只要不包含底层const,都可以使用static_cast。
int main() {
double a = 10.4;
int b = static_cast<int> (a);
double q = 1.1;
void* q_ptr = &q;
double* d_q_ptr = static_cast<double*>(q_ptr);
std::cout << *d_q_ptr << std::endl;
return 0;
}reinterpret_cast
reinterpret_cast 用于进行各种不同类型的指针之间强制转换。
通常为运算对象的位模式提供较低层次上的重新解释。危险,不推荐。
int main() {
int a = 97;
int* ip = &a;
char* pi = reinterpret_cast<char*>(ip);
std::cout << *pi << std::endl;//a
return 0;
}const_cast
const_cast 添加或者移除const性质
用于改变运算对象的 底层const。常用于有函数重载的上下文中。
顶层const:表示 对象是常量。举例int *const p1 = &i; //指针p1本身是一个常量,不能改变p1的值,p1是顶层const。
底层const:与指针和引用等复合类型部分有关。举例:const int *p2 = &ci; //指针所指的对象是一个常量,允许改变p2的值,但不允许通过p2改变ci的值,p2是底层const
一个比较实用的例子,我可以重载一个const函数得到一个非const的结果
const std::string& addString(const std::string& a, const std::string& b) {
return a.size() > b.size() ? a : b;
}
//上面函数返回的是常量string引用,当需要返回一个非常量string引用时,可以增加下面这个函数
std::string& addString(std::string& a, std::string& b) {
auto& r = addString(const_cast<const std::string&>(a), const_cast<const std::string&>(b));
return const_cast<std::string&>(r);
}
int main() {
std::string a = "jack";
std::string b = "god";
std::string c = addString(a, b);
c = c + "oooo";
std::cout << c << std::endl;//jackoooo
return 0;
}dynamic_cast
dynamic_cast 不检查转换安全性,仅运行时检查,如果不能转换,返回NULL。
支持运行时类型识别(run-time type identification,RTTI)。
适用于以下情况:我们想使用基类对象的指针或引用执行某个派生类操作并且该操作不是虚函数。一般来说,只要有可能我们应该尽量使用虚函数,使用RTTI运算符有潜在风险,程序员必须清楚知道转换的目标类型并且必须检查类型转换是否被成功执行。
class Base {
public:
Base() {
std::cout << "create Base\n";
}
virtual ~Base() {
std::cout << "delete Base\n";
}
};
class Son :public Base {
Son() { std::cout << "create Son\n"; }
~Son() {
std::cout << "delete Son\n";
}
};
int main() {
Base* b = new Base();
Son* s = dynamic_cast<Son*>(b);
if (s) {
std::cout << "work\n";
}
else {
std::cout << "it cannot work\n";//this
}
return 0;
}int main() {
Son* b = new Son();
Base* s = dynamic_cast<Base*>(b);
if (s) {
std::cout << "work\n";//this
}
else {
std::cout << "it cannot work\n";
}
return 0;
}C++预编译头文件
1.作用:
为了解决一个项目中同一个头文件被反复编译的问题。使得写代码时不需要一遍又一遍的去#include那些常用的头文件,而且能 大大提高编译速度2.使用限制:预编译头文件中的内容最好都是不需要反复更新修改的东西。
每修改一次,预编译头文件都要重新编译一次,会导致变异速度降低。但像 C++标准库,window的api这种不会大改的文件可以放到预编译头文件中,可以节省编译时间3.缺点:
预编译头文件的使用会隐藏掉这个cpp文件的依赖。比如用了#include <vector>,就清楚的知道这个cpp文件中需要vector的依赖,而如果放到预编译头文件中,就会将该信息隐藏。4..使用流程:
在Visual Studio中:https://www.bilibili.com/video/BV1eu411f736?share_source=copy_web&vd_source=48739a103c73f618758b902392cb372e
视频讲解更为详细。在g++中:
首先确保main.cpp(主程序文件)、pch.cpp(包含预编译头文件的cpp文件)、pch.h(预编译头文件)在同一源文件目录下注:pch.h文件的名字是自己命名的,改成其他名称也没问题。
g++ -std=c++11 pch.h //先编译pch头文件
//time的作用是在控制台显示编译所需要的时间。
time g++ -std=c++11 main.cpp //然后编译主程序文件即可,编译速度大大提升。C++的dynamic_cast
1.dynamic_cast是专门用于沿继承层次结构进行的强制类型转换。并且dynamic_cast只用于多态类类型。
2.如果转换失败会返回NULL,使用时需要保证是多态,即基类里面含有虚函数。
3.dynamic_cast运算符,用于将基类的指针或引用安全地转换成派生类的指针或引用。
支持运行时类型识别(run-time type identification,RTTI)。
适用于以下情况:我们想使用基类对象的指针或引用执行某个派生类操作并且该操作不是虚函数。一般来说,只要有可能我们应该尽量使用虚函数,使用RTTI运算符有潜在风险,程序员必须清楚知道转换的目标类型并且必须检查类型转换是否被成功执行。
4.使用形式
其中,type必须是一个类类型,并且通常情况下该类型应该含有虚函数。
dynamic cast<type*> (e) //e必须是一个有效的指针
dynamic cast<type&> (e) //e必须是一个左值
dynamic cast<type&&> (e) //e不能是左值在上面的所有形式中,e的类型必须符合以下三个条件中的任意一个:
1)e的类型是目标type的 公有派生类 2)e的类型是目标type的 公有基类 3)e的类型就是 目标type的类型。如果符合,则类型转换可以成功。否则,转换失败。
如果一条dynamic_cast语句的转换目标是指针类型并且失败了,则结果为0
class Base {
public:
Base() {
std::cout << "create Base\n";
}
virtual ~Base() {
std::cout << "delete Base\n";
}
};
class Son :public Base {
public:
Son() { std::cout << "create Son\n"; }
~Son() {
std::cout << "delete Son\n";
}
};
int main() {
Son* b = new Son();
if (Base* s = dynamic_cast<Base*>(b)) {
std::cout << "work\n";//this
}
else {
std::cout << "it cannot work\n";
}
return 0;
}如果转换目标是引用类型并且失败了,则dynamic_cast运算符将抛出一个bad cast异常
引用类型的dynamic_cast与指针类型的dynamic_cast在表示错误发生的方式上略有不同。因为不存在所谓的空引用,所以对于引用类型来说无法使用与指针类型完全相同的错误报告策略。当对引用的类型转换失败时,程序抛出一个名为std::bad cast的异常,该异常定义在typeinfo标准库头文件中。
#include<typeinfo>
class Base {
public:
Base() {
std::cout << "create Base\n";
}
virtual ~Base() {
std::cout << "delete Base\n";
}
};
class Son :public Base {
public:
Son() { std::cout << "create Son\n"; }
~Son() {
std::cout << "delete Son\n";
}
};
void f(const Base& b) {
try {
const Son& s = dynamic_cast<const Son&>(b);
}
catch (std::bad_cast) {
std::cout << "wrong\n";
}
}
int main() {
Base b;
f(b);//输出wrong
return 0;
}#include<typeinfo>
class Base {
public:
Base() {
std::cout << "create Base\n";
}
virtual ~Base() {
std::cout << "delete Base\n";
}
};
class Son :public Base {
public:
Son() { std::cout << "create Son\n"; }
~Son() {
std::cout << "delete Son\n";
}
};
void f(const Base& b) {
try {
const Son& s = dynamic_cast<const Son&>(b);
}
catch (std::bad_cast) {
std::cout << "wrong\n";
}
}
int main() {
Son b;
f(b);//成功
return 0;
}cherno的代码案例:
class Base {
public:
Base() { std::cout << "create Base\n"; }
virtual ~Base() { std::cout << "delete Base\n"; }
};
class Enemy:public Base{};
class Play:public Base{};
int main() {
Play* player = new Play();
Base* base = new Base();
Enemy* en = new Enemy();
//旧式转换
//Base* pb1 = player;//从下至上安全
//Play* pb2 = base;//从上至下,危险
//Enemy* pb3 = player;//平行转换,危险
//dynamic_cast
if (Base* pb1 = dynamic_cast<Base*>(player)) {
std::cout<<"pb1 success\n";//从下至上安全
}
if (Play* pb2 = dynamic_cast<Play*>(base)) {
std::cout << "pb2 success\n";//从上至下,危险
}
if (Enemy* pb3 = dynamic_cast<Enemy*>(player)) {
std::cout << "pb3 success\n";//平行转换,危险
}
//create Base
//create Base
//create Base
//pb1 success
return 0;
}C++的基准测试
1.编写一个计时器对代码测试性能。记住要在release模式去测试,这样才更有意义 。
2.该部分内容基本同"C++计时"一节
比如说可以比较unique和shared的效率
struct Vector2 {
int x, y;
};
{
std::array<std::shared_ptr<Vector2>, 1000> shared_li;
Time time;
for (int i = 0; i < shared_li.size(); i++) {
shared_li[i] = std::shared_ptr<Vector2>(new Vector2());
}
}
{
std::array<std::shared_ptr<Vector2>, 1000> shared_li;
Time time;
for (int i = 0; i < shared_li.size(); i++) {
shared_li[i] = std::make_shared<Vector2>();
}
}
{
std::array<std::unique_ptr<Vector2>, 1000> unique_li;
Time time;
for (int i = 0; i < unique_li.size(); i++) {
unique_li[i] = std::make_unique<Vector2>();
}
}这样就可以看出知道大概的时间比较
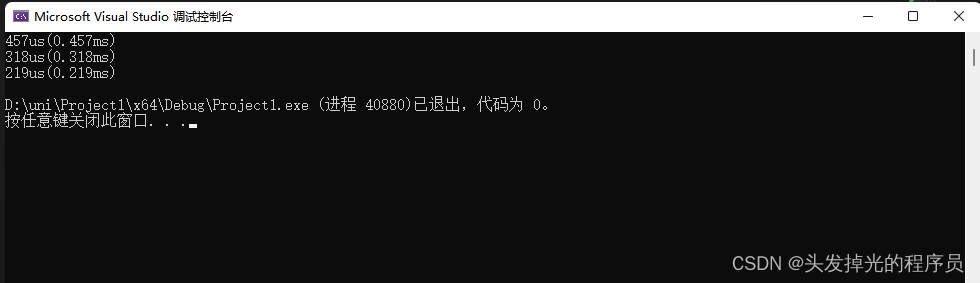
C++的结构化绑定(Structured Binding)
1.结构化绑定struct binding是C++17的新特性,能让我们更好地处理多返回值。可以在将函数返回为tuple、pair、struct等结构时且赋值给另外变量的时候,直接得到成员,而不是结构。
在视频P52谈过如何处理多返回值,当时是用结构体去处理,而这个结构化绑定就是在这个的基础上拓展的一种新方法,特别是处理元组,对组(pairs)以及返回诸如此类的东西。2.用g++编译时需要加上‘-std=c++17’ or ‘-std=gnu++17’
实例:
老方法(tuple、pair)
tie可以分别拿到对应的值
#include<tuple>
std::tuple<std::string, int,float> backData() {
return { "jack",2 ,3.3f};
}
int main() {
std::tuple<std::string, int, float> res = backData();
std::string pb1 = std::get<0>(res);
int pb2 = std::get<1>(res);
float pb3 = std::get<2>(res);
std::tie(pb1, pb2, pb3) = backData();
return 0;
}C++17新方法:结构化绑定处理多返回值
其相当于是auto自己给你定义了类型,你可以在当前作用域使用
std::tuple<std::string, int,float> backData() {
return { "jack",2 ,3.3f};
}
int main() {
auto [name, num1, num2] = backData();
std::cout << name << " " << num1 << " " << num2 << std::endl;
return 0;
}C++如何处理optional数据(std::optional)
1.C++17 在 STL 中引入了
std::optional,就像std::variant一样,std::optional是一个“和类型(sum type)”,也就是说,std::optional类型的变量要么是一个T类型的变量,要么是一个表示“什么都没有”的状态。2.基本用法:
首先要包含#include <optional>
1. opt.value() 2. (*opt) 3. value_or() //value_or()可以允许传入一个默认值, 如果optional为std::nullopt, //则直接返回传入的默认值.(如果数据确实存在于std::optional中, //它将返回给我们那个字符串。如果不存在,它会返回我们传入的任何值)
int main() {
std::string text = "jack";
std::optional<unsigned int> opt = 2;
//has_value()判断对应的optional是否处于已经设置值的状态
if (!opt.has_value()) {
std::cout << "no" << std::endl;
}
if (!opt) {//或者直接这样判断
std::cout << "no" << std::endl;
}
std::cout << opt.value() << std::endl;//通过这种方式访问数据
std::cout << *(opt) << std::endl;//或者这种
std::optional<int> op;
int k = op.value_or(10);//value_or()可以允许传入一个默认值, 如果optional为std::nullopt,
//则直接返回传入的默认值.(如果数据确实存在于std::optional中,
//它将返回给我们那个字符串。如果不存在,它会返回我们传入的任何值)
std::cout << k << std::endl;
return 0;
}
std::optional是C++17的新东西,用于检测数据是否存在or是否是我们期盼的形式,用于处理那些可能存在,也可能不存在的数据or一种我们不确定的类型 。比如在读取文件内容的时候,往往需要判断读取是否成功,常用的方法是传入一个引用变量或者判断返回的std::string是否为空,C++17引入了一个更好的方法,std::optional老方法:传入一个引用变量或者判断返回的std::string是否为空
#include<iostream>
#include<optional>
#include<fstream>
#include<string>
std::string readFile(std::string path, bool& success) {
std::ifstream stream(path);
if (stream) {
std::string str;
getline(stream, str);
stream.close();
success = true;
return str;
}
success = false;
return "";
}
int main() {
std::string path = "test.txt";
bool success = true;
std::string res = readFile(path,success);
if (!success) {
std::cout << "no read\n";
}
return 0;
}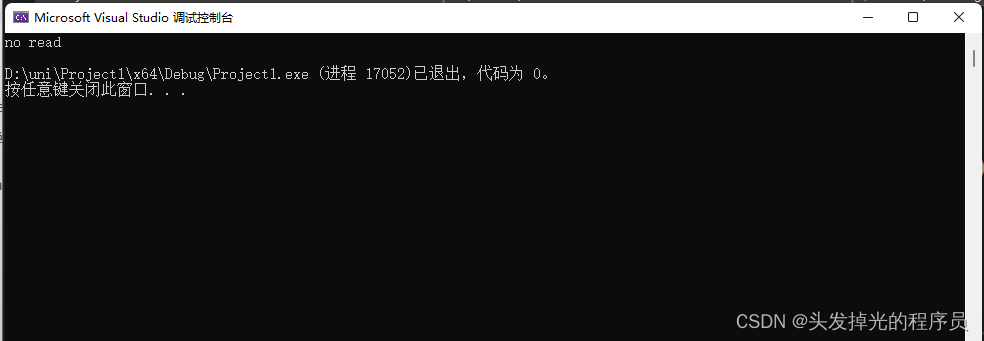
新方法:std::optional
std::optional< std::string> readFile(std::string path, bool& success) {
std::ifstream stream(path);
if (stream) {
std::string str;
getline(stream, str);
stream.close();
success = true;
return str;
}
success = false;
return {};
//如果文本存在的话,它会返回所有文本的字符串。如果不存在或者不能读取;则返回optional {}
}
int main() {
std::string path = "test.txt";
bool success = true;
std::optional<std::string> res = readFile(path,success);
res = res.value_or("jack");
std::cout << res.value() << std::endl;//输出jack
return 0;
}C++单一变量存放多种类型的数据(std::variant)
1.std::variant是C++17的新特性,可以让我们不用担心处理的确切数据类型 ,是一种 一种可以容纳多种类型变量的结构 。
它和option很像,它的作用是让我们不用担心处理确切的数据类型,只有一个变量,之后我们在考虑它的具体类型
故我们做的就是指定一个叫std::variant的东西,然后 列出它可能的数据类型2.与union的区别
1)union 中的成员内存共享。union更有效率。 2)std::variant的大小是<>里面的大小之和 。 variant更加 类型安全,不会造成未定义行为, 所以应当去使用它,除非做的是底层优化,非常需要性能。
简单的运用
#include<variant>
int main() {
std::variant<std::string, int,float> res;
res = "jack";
std::cout << std::get<std::string>(res) << std::endl;//打印出来jack
res = 4;
std::cout << std::get<int>(res) << std::endl;//print 4
std::cout << std::get<std::string>(res) << std::endl;//compile success 但是runtime会报错,显示std::bad_variant_access
return 0;
}index()索引
#include<iostream>
#include<variant>
int main() {
//std::variant的index函数
// 返回一个整数,代表res当前存储的数据的类型在<>里的序号,比如返回0代表存的是string, 返回1代表存的是int
std::variant<std::string, int,float> res;
res = "jack";
std::cout << res.index() << std::endl;//打印出来0
res = 4;
std::cout << res.index() << std::endl;//print 1
res = 3.3f;
return 0;
}get_if()
#include<iostream>
#include<variant>
int main() {
// std::get的变种函数,get_if
std::variant<std::string, int,float> res;
res = "jack";
std::cout << res.index() << std::endl;//打印出来0
res = 4;
std::cout << res.index() << std::endl;//print 1
res = 3.3f;
//p是一个指针,如果res此时存的不是float类型的数据,则p为空指针,别忘了传的是地址
if (auto p = std::get_if<float>(&res)) {// 如果res存的数据是float类型的数据
std::cout << "now is" << *p;//now is3.3
}C++如何存储任意类型的数据(std::any)
1.也是C++17引入的可以存储多种类型变量的结构,其本质是一个union,但是不像std::variant那样需要列出类型。使用时要包含头文件
#include <any>2.对于小类型(small type)来说,any将它们存储为一个严格对齐的Union, 对于大类型,会用void*,动态分配内存 。
3.评价:基本无用。 当在一个变量里储存多个数据类型,用any的类型安全版本即可:
variant
#include<iostream>
#include<any>
int main() {
std::any data;
data = 2;
std::cout << std::any_cast<int>(data) << std::endl;
data = "jack";
std::cout << std::any_cast<const char*>(data) << std::endl;
data = std::string("jackgod");
std::cout << std::any_cast<std::string&>(data) << std::endl;
return 0;
}可以看到它可以被赋值为任意类型,但是这样并不安全,因为这样你就不能显示的表示类型
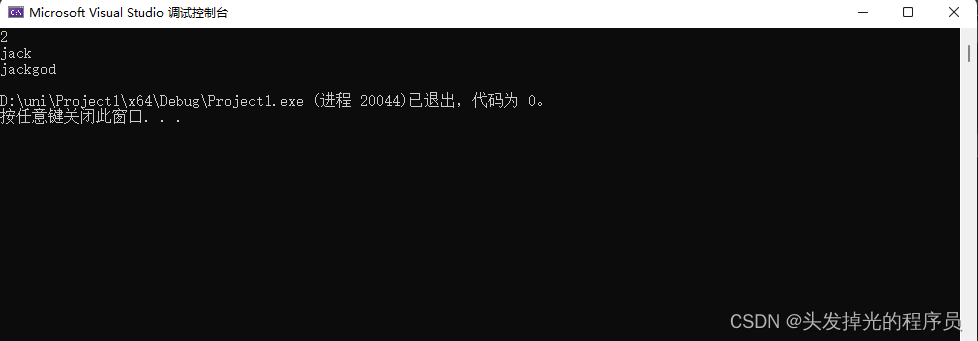
如何让C++运行得更快(std::async)
std::async是一个多线程的方式。当我们需要加载很多重复的资源的时候,如果不使用多线程就会很慢,这里模仿一个例子
这是一个单线程的方式 ,结果可想而知,就是先后打印我们的数据。
std::async的操作,其实相当于封装了std::promise、std::packaged_task加上std::thread。
返回值为future对象,第一个参数为policy,第二个为新起线程执行的函数,第三个参数为函数参数,其作用为另起一个线程,执行函数,并且返回future,实现和主线程的同步。主线程中执行future::get,完成线程同步。
void createFunction(const std::string& str) {
for (int i = 0; i < 1000; i++) {
std::cout << str << ":\t" << i;
}
}
int main() {
std::string names[] = { "jack","god","koko" };
for (int i = 0; i < 3; i++) {
createFunction(names[i]);
}
return 0;
}std::async是一种多线程的方式,但是你直接使用还是会有个问题,因为这种方式它离开作用域会自动销毁,但是如果你不保留它的内容,它还是以单线程的方式。就要用到future,std::async会返回一个future这样就能保留这个线程让它异步执行。
#include<iostream>
#include<future>
void createFunction(const std::string& str) {
for (int i = 0; i < 1000; i++) {
std::cout << str << ":\t" << i;
}
}
int main() {
std::string names[] = { "jack","god","koko" };
for (int i = 0; i < 3; i++) {
std::async(createFunction, names[i]);//会等待这个线程执行完才销毁
}
return 0;
}#include<iostream>
#include<future>
void createFunction(const std::string& str) {
for (int i = 0; i < 1000; i++) {
std::cout << str << ":\t" << i;
}
}
int main() {
std::string names[] = { "jack","god","koko" };
std::vector<std::future<void>> t_thread;
for (int i = 0; i < 3; i++) {
t_thread.push_back(std::async(createFunction, names[i]));
}
return 0;
}然后它就可以异步执行了
如果加上一个互斥资源 ,因为在线程中我们需要互斥访问资源
我们使用
std::lock_guard来获取互斥锁,并在修改共享数据之前对其加锁。这样可以确保在任何时刻只有一个线程能够访问共享数据,从而避免了数据竞争的问题。
#include<iostream>
#include<future>
#include<string>
#include<mutex>
std::vector<std::string> res;
std::mutex m_lock;
void createFunction(const std::string& str,int j) {
std::lock_guard<std::mutex> lock(m_lock);
res.push_back(std::string(str + ":\t" + std::to_string(j)));
}
void dowork(const std::string& str) {
for (int i = 0; i < 1000; i++) {
createFunction(str, i);
}
}
int main() {
std::string names[] = { "jack","god","koko" };
std::vector<std::future<void>> t_thread;
for (int i = 0; i < 3; i++) {
t_thread.push_back(std::async(dowork, names[i]));
}
return 0;
}返回类型:
future_status有三种状态:deferred:异步操作还没开始
ready:异步操作已经完成
timeout:异步操作超时
获取future结果有三种方式:get、wait、wait_for,其中get等待异步操作结束并返回结果,wait只是等待异步操作完成,没有返回值,wait_for是超时等待返回结果。注意:future::wait_for时间到后,返回的是timeout状态,当async里is_prime函数执行结束,为ready状态

如何让C++字符串更快 in C++
1.内存分配建议:能分配在栈上就别分配到堆上,因为把内存分配到堆上会降低程序的速度 。
2.std::string_view同样是C++17的新特性
3.gcc的string默认大小是32个字节,字符串小于等于15直接保存在栈上,超过之后才会使用new分配
4.string的常用优化:SSO(短字符串优化)、COW(写时复制技术优化)
首先string会在堆上面分配内存,而const char*不会 ,而且当你声明一次string的时候它也会调用一次内存,但是默认的内存大小,然后根据你的需求,当你的需求没有超过它的默认大小的时候,它不会再次分配内存,当你的需求超过它的默认大小的时候,它还会再次分配内存
#include<iostream>
static uint32_t allocation;
void* operator new(size_t size) {
allocation++;
std::cout << "allocate: " << size << "bytes\n";
return malloc(size);
}
int main() {
std::string str;
std::cout << allocation << std::endl;
}
#include<iostream>
static uint32_t allocation;
void* operator new(size_t size) {
allocation++;
std::cout << "allocate: " << size << "bytes\n";
return malloc(size);
}
int main() {
std::string str = "jackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgod";
std::cout << allocation << std::endl;
}可以看到分配了两次内存
但是当我们使用const char*以后,会发现不会有分配的问题
#include<iostream>
static uint32_t allocation;
void* operator new(size_t size) {
allocation++;
std::cout << "allocate: " << size << "bytes\n";
return malloc(size);
}
int main() {
const char* str = "jackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgod";
std::cout << allocation << std::endl;
}
为何优化字符串?
- std::string和它的很多函数都喜欢分配在堆上,这实际上并不理想 。
- 一般处理字符串时,比如使用substr切割字符串时,这个函数会自己处理完原字符串后创建出一个全新的字符串,它可以变换并有自己的内存(new,堆上创建)。
- 在数据传递中减少拷贝是提高性能的最常用办法。在C中指针是完成这一目的的标准数据结构,而在C++中引入了安全性更高的引用类型。所以在C++中若传递的数据仅仅可读,const string&成了C++天然的方式。但这并非完美,从实践上来看,它至少有以下几方面问题:
- 字符串字面值、字符数组、字符串指针的传递依然要数据拷贝 这三类低级数据类型与string类型不同,传入时编译器要做隐式转换,即需要拷贝这些数据生成string临时对象。const string&指向的实际上是这个临时对象。通常字符串字面值较小,性能损失可以忽略不计;但字符串指针和字符数组某些情况下可能会比较大(比如读取文件的内容),此时会引起频繁的内存分配和数据拷贝,影响程序性能。
- substr O(n)复杂度 substr是个常用的函数,好在std::string提供了这个函数,美中不足的时每次都要返回一个新生成的子串,很容易引起性能热点。实际上我们本意不是要改变原字符串,为什么不在原字符串基础上返回呢?
可以看到当使用引用的时候不会再次创建字符串在内存
#include<iostream>
static uint32_t allocation;
void* operator new(size_t size) {
allocation++;
std::cout << "allocate: " << size << "bytes\n";
return malloc(size);
}
void print(const std::string& str) {
std::cout << str << std::endl;
}
int main() {
std::string str = "jackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgodjackgod";
print(str);
std::cout << allocation << std::endl;
}但是当使用一些字符串的函数比如substr的时候,就会出现内存的再次创建(接下来使用不超过默认的字符串大小)
#include<iostream>
static uint32_t allocation;
void* operator new(size_t size) {
allocation++;
std::cout << "allocate: " << size << "bytes\n";
return malloc(size);
}
void print(const std::string& str) {
std::cout << str << std::endl;
}
int main() {
std::string str = "jackgod";
std::string pb1 = str.substr(0, 3);
std::string pb2 = str.substr(3);
std::cout << allocation << std::endl;
}创建了三次

使用 string_view优化字符串
std::string_view是C++ 17标准中新加入的类,正如其名,它提供一个字符串的视图,即可以通过这个类以各种方法“观测”字符串,但不允许修改字符串。由于它只读的特性,它并不真正持有这个字符串的拷贝,而是与相对应的字符串共享这一空间。即——构造时不发生字符串的复制。同时,你也可以自由的移动这个视图,移动视图并不会移动原定的字符串。
通过调用 string_view 构造器可将字符串转换为 string_view 对象。string 可隐式转换为 string_view。
- string_view 是只读的轻量对象,它对所指向的字符串没有所有权。
- string_view通常用于函数参数类型,可用来取代 const char* 和 const string&。string_view 代替 const string&,可以避免不必要的内存分配。
- string_view的成员函数即对外接口与 string 相类似,但只包含读取字符串内容的部分。
- string_view::substr()的返回值类型是string_view,不产生新的字符串,不会进行内存分配。
- string::substr()的返回值类型是string,产生新的字符串,会进行内存分配。
- string_view字面量的后缀是 sv。(string字面量的后缀是 s)
#define USE_STRING_VIEW 1
#if USE_STRING_VIEW
void PrintName(std::string_view str) {
std::cout << str << std::endl;
}
#else
void PrintName(const std::string& str) {
std::cout << str << std::endl;
}
#endif
int main() {
#if USE_STRING_VIEW
std::string str = "jackgod Luo";
std::string_view firstName(str.c_str(), 7);
std::string_view lastName(str.c_str() + 8, 3);
PrintName(firstName);
PrintName(lastName);
std::cout << allocation << std::endl;
#else
std::string str = "jackgod Luo";
std::string firstName = str.substr(0, 7);
std::string lastName = str.substr(8);
PrintName(firstName);
PrintName(lastName);
std::cout << allocation << std::endl;
#endif
}此时就只会分配一次内存,就是在初始化str的时候
使用const char* 后就会发现一次内存都没有分配了
#include<iostream>
#include<string>
static uint32_t allocation;
void* operator new(size_t size) {
allocation++;
std::cout << "allocate: " << size << "bytes\n";
return malloc(size);
}
#define USE_STRING_VIEW 1
#if USE_STRING_VIEW
void PrintName(std::string_view str) {
std::cout << str << std::endl;
}
#else
void PrintName(const std::string& str) {
std::cout << str << std::endl;
}
#endif
int main() {
#if USE_STRING_VIEW
const char* str = "jackgod Luo";
std::string_view firstName(str, 7);
std::string_view lastName(str + 8, 3);
PrintName(firstName);
PrintName(lastName);
std::cout << allocation << std::endl;
#else
std::string str = "jackgod Luo";
std::string firstName = str.substr(0, 7);
std::string lastName = str.substr(8);
PrintName(firstName);
PrintName(lastName);
std::cout << allocation << std::endl;
#endif
}
这里有篇文章解释了为什么const char* 不参与内存分配
C++的可视化基准测试
1.利用工具: chrome://tracing (chrome浏览器自带的一个工具,将该网址输入即可)
2.基本原理: cpp的计时器配合自制简易json配置写出类,将时间分析结果写入一个json文件,用chrome://tracing 这个工具进行可视化 。
3.多线程可视化实现:
视频:https://www.bilibili.com/video/BV1gZ4y1R7SG?share_source=copy_web&vd_source=48739a103c73f618758b902392cb372e 代码改进链接:https://github.com/GavinSun0921
实现代码
#include <string>
#include <chrono>
#include <algorithm>
#include <fstream>
#include <cmath>
#include <thread>
#include <iostream>
struct ProfileResult
{
std::string Name;
long long Start, End;//时间的起始和终止
uint32_t ThreadID; //线程ID
};//读入的数据需要的信息
struct InstrumentationSession
{
std::string Name;//分为不同的session来进行基准测试
};
class Instrumentor
{
private:
InstrumentationSession* m_CurrentSession;
std::ofstream m_OutputStream;
int m_ProfileCount;
public:
Instrumentor()
: m_CurrentSession(nullptr), m_ProfileCount(0)
{
}
void BeginSession(const std::string& name, const std::string& filepath = "results.json")
{
m_OutputStream.open(filepath);
WriteHeader();//写json的头部
m_CurrentSession = new InstrumentationSession{ name };
}
void EndSession()
{
WriteFooter();//写json的尾部
m_OutputStream.close();//关闭输入流
delete m_CurrentSession;//初始化,因为整个类只允许一个实例
m_CurrentSession = nullptr;
m_ProfileCount = 0;
}
void WriteProfile(const ProfileResult& result)//写json文件
{
if (m_ProfileCount++ > 0)
m_OutputStream << ",";
std::string name = result.Name;
std::replace(name.begin(), name.end(), '"', '\'');
m_OutputStream << "{";
m_OutputStream << "\"cat\":\"function\",";
m_OutputStream << "\"dur\":" << (result.End - result.Start) << ',';
m_OutputStream << "\"name\":\"" << name << "\",";
m_OutputStream << "\"ph\":\"X\",";
m_OutputStream << "\"pid\":0,";
m_OutputStream << "\"tid\":" << result.ThreadID << ","; //多线程
m_OutputStream << "\"ts\":" << result.Start;
m_OutputStream << "}";
m_OutputStream.flush();
}
void WriteHeader()
{
m_OutputStream << "{\"otherData\": {},\"traceEvents\":[";
m_OutputStream.flush();
}
void WriteFooter()
{
m_OutputStream << "]}";
m_OutputStream.flush();
}
static Instrumentor& Get()//只允许一个实例
{
static Instrumentor instance;
return instance;
}
};
class InstrumentationTimer//数据的来源
{
public:
InstrumentationTimer(const char* name)//初始化一个基准测试的类
: m_Name(name), m_Stopped(false)
{
m_StartTimepoint = std::chrono::high_resolution_clock::now();
}
~InstrumentationTimer()
{
if (!m_Stopped)
Stop();
}
void Stop()
{
auto endTimepoint = std::chrono::high_resolution_clock::now();
long long start = std::chrono::time_point_cast<std::chrono::microseconds>(m_StartTimepoint).time_since_epoch().count();
long long end = std::chrono::time_point_cast<std::chrono::microseconds>(endTimepoint).time_since_epoch().count();
uint32_t threadID = std::hash<std::thread::id>{}(std::this_thread::get_id());//在timer中的stop函数看看timer实际上是在哪个线程上运行的
Instrumentor::Get().WriteProfile({ m_Name,start,end,threadID });//写入数据
m_Stopped = true;
}
private:
const char* m_Name;
std::chrono::time_point<std::chrono::high_resolution_clock> m_StartTimepoint;
bool m_Stopped;
};
void Function1() {
InstrumentationTimer timer1("Function1");
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << std::endl;
}
}
void Function2() {
InstrumentationTimer timer2("Function2");
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << sqrt(i) << std::endl;
}
}
int main() {
Instrumentor::Get().BeginSession("profile");//分为不同的session来进行基准测试
Function1();
Function2();
Instrumentor::Get().EndSession();
}然后你就可以看到Function1和Function2的基准测试
void RunBenchmarks() {
InstrumentationTimer timer("total");
std::cout << "run ----\n";
Function1();
Function2();
}
int main() {
Instrumentor::Get().BeginSession("profile");//分为不同的session来进行基准测试
RunBenchmarks();
Instrumentor::Get().EndSession();
}以这种方式还可以得到以下一个整合的结果
- 有两个问题,首先这个RunBenchmarks,每次都需要复制粘贴函数才能使用。
- 然后我们并不是每次都需要在程序中使用这个计时器。
首先介绍几个宏的定义
__LINE__ 它会变成所在行号(数字)
“#”的功能是将其后面的宏参数进行字符串化操作(Stringfication),简单说就是在对它所引用的宏变量,通过替换后在其左右各加上一个双引号。
“##”被称为连接符(concatenator),用来将两个Token连接为一个Token。
__FUNCTION__ 它会变成它所在的函数的名字的字符串
使用宏解决上述两个问题
有那么个宏 是所有编辑器都能自动展开的 叫 __FUNCTION__ 它会变成它所在的函数的名字的字符串
于是就有了
#define PROFILING 1
#if PROFILING
#define PROFILING_SCOPE(name) InstrumentationTimer timer(name)
#define PROFLING_FUNCTION() PROFILING_SCOPE(__FUNCTION__)//FUNCTION代表所在的函数的名字的字符串
#else
#endif
void Function1() {
PROFLING_FUNCTION();
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << std::endl;
}
}
void Function2() {
PROFLING_FUNCTION();
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << sqrt(i) << std::endl;
}
}
void RunBenchmarks() {
PROFLING_FUNCTION();
std::cout << "run ----\n";
Function1();
Function2();
}
int main() {
Instrumentor::Get().BeginSession("profile");//分为不同的session来进行基准测试
RunBenchmarks();
Instrumentor::Get().EndSession();
}
好 但还不够好
所有的计时器都是一个名称 万一不小心重名了 那事情就不好整了
又有一个宏 叫 __LINE__ 它会变成所在行号(数字)
而宏能用神奇的 #将东西黏在一起
就有了
#define PROFILING_SCOPE(name) InstrumentationTimer timer##__LINE__(name)万一我的函数是重载的 输出的是一样的函数名字 我咋知道调用的是哪个版本的函数
又有一个宏 叫 __PRETTY_FUNCTION__ MSVC是 __FUNCSIG__它能变成完整的函数签名的字符串 就像 "void core1(int)"
#define PROFILING 1
#if PROFILING
#define PROFILING_SCOPE(name) InstrumentationTimer timer##__LINE__(name)
#define PROFLING_FUNCTION() PROFILING_SCOPE(__FUNCSIG__)//FUNCTION代表所在的函数的名字的字符串
#else
#endif
void Function1() {
PROFLING_FUNCTION();
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << std::endl;
}
}
void Function2() {
PROFLING_FUNCTION();
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << sqrt(i) << std::endl;
}
}
void RunBenchmarks() {
PROFLING_FUNCTION();
std::cout << "run ----\n";
Function1();
Function2();
}
int main() {
Instrumentor::Get().BeginSession("profile");//分为不同的session来进行基准测试
RunBenchmarks();
Instrumentor::Get().EndSession();
}
#define PROFILING 1
#if PROFILING
#define PROFILING_SCOPE(name) InstrumentationTimer timer##__LINE__(name)
#define PROFLING_FUNCTION() PROFILING_SCOPE(__FUNCSIG__)//FUNCTION代表所在的函数的名字的字符串
#else
#endif
void Function1() {
PROFLING_FUNCTION();
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << std::endl;
}
}
void Function2() {
PROFLING_FUNCTION();
for (int i = 0; i < 1000; i++) {
std::cout << "Hello world #" << sqrt(i) << std::endl;
}
}
void RunBenchmarks() {
PROFLING_FUNCTION();
std::cout << "run ----\n";
std::thread a([]() {Function1(); });
std::thread b([]() {Function2(); });
a.join();
b.join();
}
int main() {
Instrumentor::Get().BeginSession("profile");//分为不同的session来进行基准测试
RunBenchmarks();
Instrumentor::Get().EndSession();
}多线程的方式,然后就可以得到多个tid的值

C++的单例模式
1.Singleton只允许被实例化一次,用于组织一系列全局的函数或者变量,与namespace很像。例子:随机数产生的类、渲染器类。
2.C++中的单例只是一种组织一堆全局变量和静态函数的方法
3.什么时候用单例模式:
当我们想要拥有应用于某种全局数据集的功能,且我们只是想要重复使用时,单例是非常有用的
有些单例的例子,比如一个随机数生成器类 我们只希望能够查询它,得到一个随机数,而不需要实例化它去遍历所有这些东西我们只想实例化它一次(单例),这样它就会生成随机数生成器的种子,建立起它所需要的任何辅助的东西了 另一个例子就是渲染器,渲染器通常是一个非常全局的东西 我们通常不会有一个渲染器的多个实例,我们有一个渲染器,我们向它提交所有这些渲染命令,然后它就会为我们渲染
4.实现单例的基本方法:
1)将构造函数设为私有,因为单例类不能有第二个实例
2)提供一个静态访问该类的方法
设一个私有的静态的实例,并且在类外将其定义! 然后用一个静态函数返回其引用or指针,便可正常使用了
3)为了安全,标记拷贝构造函数为delete(删除拷贝构造函数)
#include<iostream>
class SignalTon {
public:
static SignalTon& Get() {
static SignalTon signalTon;
return signalTon;
}
SignalTon(const SignalTon& signal) = delete;//删掉了拷贝构造函数
private:
SignalTon(){}//将构造函数私有化,外部不会创建实例
};
int main() {
auto& t = SignalTon::Get();
return 0;
}一个简单的随机数类的例子
#include<iostream>
class Random {
public:
static Random& Get() {
static Random signalTon;
return signalTon;
}
Random(const Random& signal) = delete;//删掉了拷贝构造函数
static float getNum() {
return Random::Get().IFloat();//static里面只能使用static的方法或属性
}
private:
Random(){}//将构造函数私有化,外部不会创建实例
float IFloat() {
return yourNumber;
}
float yourNumber = 0.5f;
};
int main() {
auto& t = Random::Get();
std::cout << t.getNum() << std::endl;
return 0;
}
C++的小字符串优化
VS开发工具在release模式下面 (debug模式都会在堆上分配) ,使用size小于16的string,不会分配内存,而大于等于16的string,则会分配32bytes内存以及更多,所以16个字符是一个分界线 (注:不同编译器可能会有所不同)
所以可以解释如何让C++字符串那章为什么定义string的时候都分配了内存,因为实在debug模式下。
#include<iostream>
void* operator new(size_t size) {
std::cout << "Allocated: " << size << std::endl;
return malloc(size);
}
int main() {
std::string longName = "jackgodjackgodjackgod";
std::string shortName = "jack";
}release模式下
Debug模式下
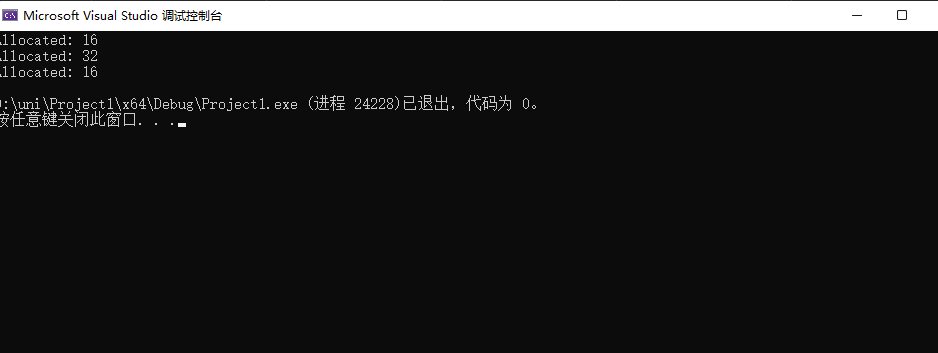
跟踪内存分配的简单方法
重写new和delete操作符函数,并在里面打印分配和释放了多少内存,也可在重载的这两个函数里面设置断点,通过查看调用栈即可知道什么地方分配或者释放了内存
我们知道一个class的new是分为三步:operator new(其内部调用malloc)返回void*、static_cast转换为这个对象指针、构造函数。而delete则分为两步:构造函数、operator delete。 new和delete都是表达式,是不能重载的;而把他们行为往下分解则是有operator new和operator delete,是有区别的。 直接用的表达式的行为是不能变的,不能重载的,即new分解成上图的三步与delete分解成上图的两步是不能重载的。这里内部的operator new和operator delete底层其实是调用的malloc,这些内部的几步则是可以重载的。 原文链接:https://blog.csdn.net/weixin_47
#include<iostream>
#include<memory>
struct AllocationMetrics {
uint32_t TotalAllocate = 0;
uint32_t TotalFree = 0;
uint32_t CurrentUsage() { return TotalAllocate - TotalFree; }
};
static AllocationMetrics s_AllocationMetrics; //创建一个全局静态实例
void* operator new(size_t size) {
s_AllocationMetrics.TotalAllocate += size;
return malloc(size);
}
void operator delete(void* memory, size_t size) {
s_AllocationMetrics.TotalFree += size;
free(memory);
}
struct Object {
int x, y, z;
};
static void printMemoryUsage() {
std::cout << "have usage: "<<s_AllocationMetrics.CurrentUsage() <<"bytes\n" << std::endl;
}
int main() {
printMemoryUsage();
{
std::unique_ptr<Object> object = std::make_unique<Object>();
printMemoryUsage();
}
printMemoryUsage();
Object* obj = new Object;
printMemoryUsage();
delete obj;
printMemoryUsage();
std::string string = "Cherno";
printMemoryUsage();
return 0;
}然后就可以根据这种方式去跟踪自己的内存分配

C++的左值与右值(lvalue and rvalue)
左值
有地址 数值 有存储空间的值,往往长期存在; 左值是由某种存储支持的变量;左值有地址和值,可以出现在赋值运算符左边或者右边。
左值引用
左值引用仅仅接受左值,除非用了const兼容( 非const的左值引用只接受左值 ) 所以C++常用常量引用。因为它们兼容临时的右值和实际存在的左值变量
右值
是临时量,无地址(或者说有地址但访问不到,它只是一个临时量) 没有存储空间的短暂存在的值
右值引用
右值引用不能绑定到左值 可以通过常引用或者右值引用(&&)延长右值的生命周期 “有名字的右值引用是左值”
右值引用的优势:优化
如果我们知道传入的是一个临时对象的话,那么我们就不需要担心它们是否活着,是否完整,是否拷贝。我们可以简单地偷它的资源,给到特定的对象,或者其他地方使用它们。因为我们知道它是暂时的,它不会存在很长时间 而如果如上使用const string& str,虽然可以兼容右值,但是却不能从这个字符串中窃取任何东西!因为这个str可能会在很多函数中使用,不可乱修改!(所以才加了const)
在给函数形参列表传参时,有四种情况
void PrintName(std::string name) {//接受左值和右值
std::cout << name << std::endl;
}
void PrintName(std::string& name) {//只接受左值
std::cout << name << std::endl;
}
void PrintName(const std::string& name) {//接受左值和右值
std::cout << name << std::endl;
}
void PrintName(std::string&& name) {//只接受右值
std::cout << name << std::endl;
}cherno的演示代码如下
int& GetValue() {
static int res = 10;
return res;
}
void PrintName(std::string& name) {//只能左值
std::cout << "[lvalue]:" << name << std::endl;
}
void PrintName(const std::string& name) {//左右值都可以
std::cout << "[value]:" << name << std::endl;
}
void PrintName(std::string&& name) {//只能右值
std::cout << "[rvalue]:" << name << std::endl;
}
int main() {
GetValue() = 5;
int i = GetValue();
std::cout << i << std::endl;//输出5引用res改了res的值
std::string name = "jack";
PrintName(name);
PrintName("god");
return 0;
}可以看到其调用的优先顺序,程序会优先使用小作用域
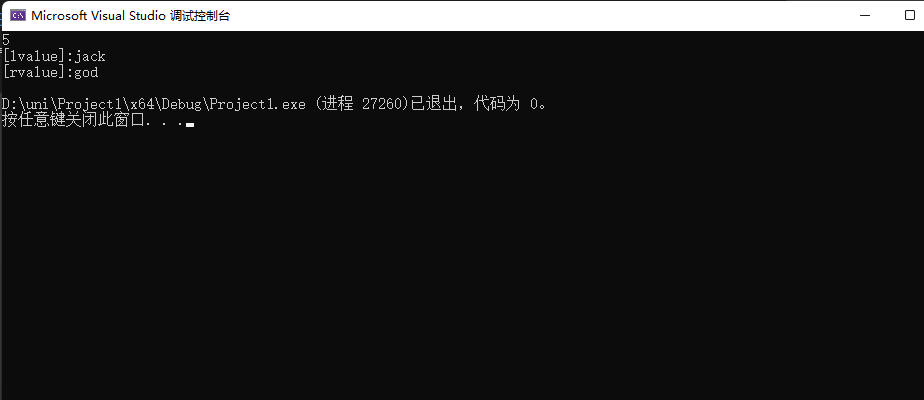
C++移动语义
在C++中,使用 =default 来显式地指示编译器生成默认构造函数、复制构造函数、移动构造函数、复制赋值运算符、移动赋值运算符,或析构函数。
- 默认构造函数:这是指没有参数或所有参数都有默认值的构造函数。如果一个类没有定义任何构造函数,编译器会自动生成一个默认构造函数。但当类中有任何其他构造函数(比如复制构造函数或带参数的构造函数),编译器不会生成默认构造函数。在这种情况下,使用
=default可以明确告诉编译器为类生成默认构造函数。 - 复制构造函数:如果你希望使用编译器默认的复制构造函数而不是自己定义一个,可以用
=default来生成。 - 移动构造函数:与复制构造函数类似,但用于移动语义。
- 赋值运算符:包括复制赋值运算符和移动赋值运算符。与上述构造函数类似,如果想使用编译器默认的赋值运算符,也可以用
=default来明确告诉编译器。 - 析构函数:使用
=default可以告诉编译器生成默认的析构函数。
使用 =default 的场景
- 简化代码:避免手动编写不必要的函数,而直接使用编译器生成的默认行为。
- 保持语义:当你希望类的行为与编译器生成的行为保持一致时。
- 辅助特性:某些情况下,明确定义
=default可以帮助编译器启用或禁用某些特性(例如,移动语义)。
示例
#include <iostream>
// 一个简单的类
class MyClass {
public:
MyClass() = default; // 使用默认构造函数
MyClass(const MyClass&) = default; // 使用默认复制构造函数
MyClass(MyClass&&) = default; // 使用默认移动构造函数
MyClass& operator=(const MyClass&) = default; // 默认复制赋值运算符
MyClass& operator=(MyClass&&) = default; // 默认移动赋值运算符
~MyClass() = default; // 默认析构函数
};
int main() {
MyClass a; // 默认构造
MyClass b = a; // 复制构造
MyClass c = std::move(a); // 移动构造
return 0;
}- 当我们知道左值和右值,左值引用和右值引用后,我们可以看看它们最大的一个用处:移动语义
- 为什么需要移动语义?
很多时候我们只是单纯创建一些右值,然后赋给某个对象用作构造函数。这时候会出现的情况是:首先需要在main函数里创建这个右值对象,然后复制给这个对象相应的成员变量。 如果我们可以直接把这个右值变量移动到这个成员变量而不需要做一个额外的复制行为,程序性能就能提高。
noexcept 指定符
含义:指定函数是否抛出异常。 举例:void f() noexcept {};// 函数 f() 不抛出异常
不用移动构造函数
在您的代码中,`String`类的拷贝构造函数需要访问另一个`String`对象(参数`other`)的私有成员变量`m_Str`和size`,以便正确复制对象的数据。这种访问是合法的,因为即使`other`是一个不同的`String`对象,它仍然是`String`类的一个实例,属于"同一个类的内部"。
这是C++中对类的访问控制的一部分,允许对象的拷贝构造、赋值操作、以及其他内部实现细节的实现,即使它们涉及访问私有成员。
总之,虽然`other`看起来是外部对象,但它和当前对象属于同一个类,因此它们可以相互访问彼此的私有成员。这样设计有助于实现诸如拷贝构造函数、重载赋值操作符等功能,同时确保外部代码无法直接访问类的内部数据,从而保持了封装性。
#include<iostream>
class String {
public:
String() = default;
String(const char* str) {
printf("creat\n");
size = strlen(str);
m_Str = new char[size];
memcpy(m_Str, str, size);
}
String(const String& other) {// 拷贝构造函数
printf("copy\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
}
~String() {
printf("delete String\n");
delete[] m_Str;
}
void print() {
for (int i = 0; i < size; i++) {
printf("%c", m_Str[i]);
}
printf("\n");
}
private:
char* m_Str;
uint32_t size;
};
class Entity {
public:
Entity(const String& str):name(str){}
void PrintName() {
name.print();
}
private:
String name;
};
int main() {
Entity entity(String("jack"));
return 0;
}可以看到,这里调用了copy函数,但是发现了没有,它再次分配了内存,但是我们只需要使用一次jack的内存,这就导出来移动的思想。
实际上这次copy发生在Entity的初始化列表里。 从String的复制构造函数可以看到,复制过程中还申请了新的内存空间!这会带来很大的消耗。
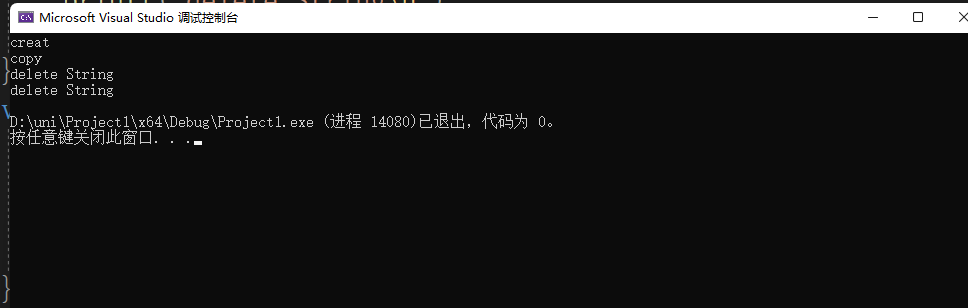
使用移动构造函数
这里如果单纯的赋值会发生什么呢
String(const String& other) {// 拷贝构造函数
printf("copy\n");
size = other.size;
m_Str = other.m_Str;
/*m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);*/
}这里看到会出现一个较大的错误。很明显,当构造函数结束,str被删掉,然后就会发生访问地址错误。
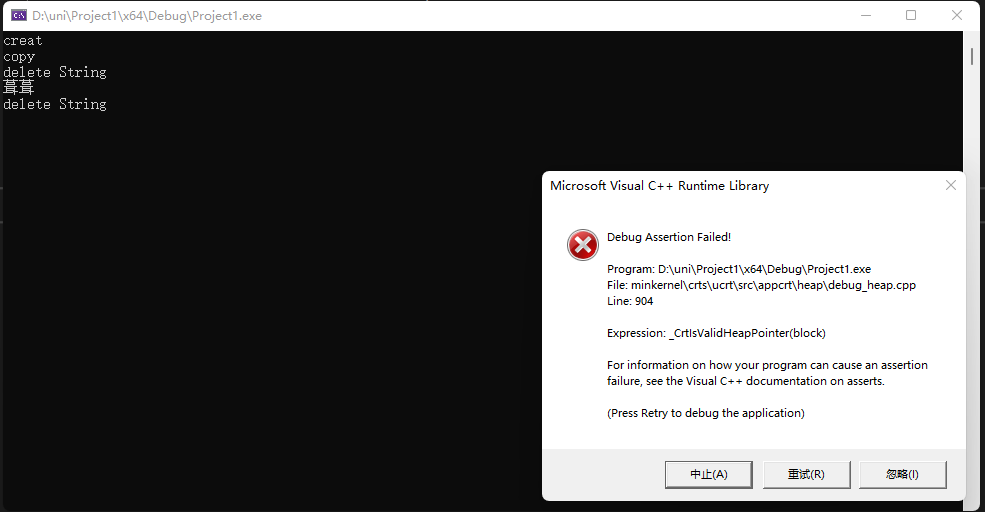
这时候就有个思路,如果我们在拷贝的时候,将other的字符串指针指向nullptr然后这样它删除了内存后,不就影响不到自己的m_Str了吗,但是发现无法修改,拷贝构造函数不允许非const,于是这条路失败
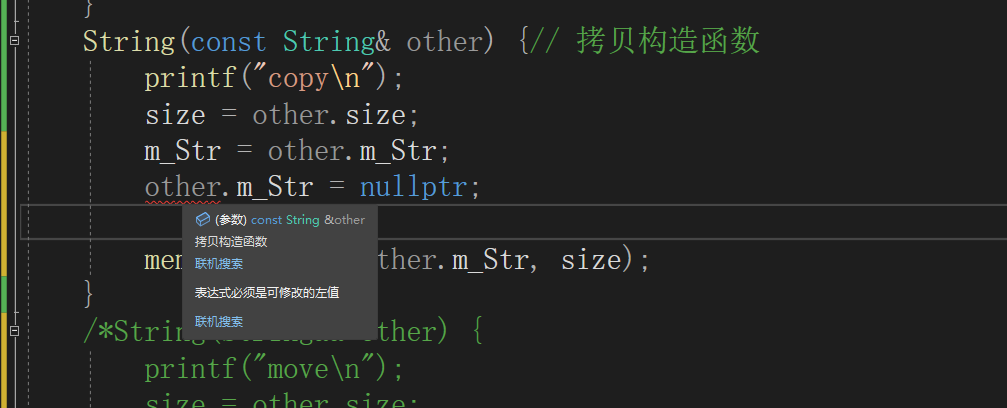
#include<iostream>
class String {
public:
String() = default;
String(const char* str) {
printf("creat\n");
size = strlen(str);
m_Str = new char[size];
memcpy(m_Str, str, size);
}
String(const String& other) {// 拷贝构造函数
printf("copy\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
}
String(String&& other) {//以右值的方式传入,然后这样就可以把这个右值的内容全部偷盗
printf("move\n");
size = other.size;
m_Str = other.m_Str;
other.m_Str = nullptr;//将other里面的字符串指向别的地方,这样就不会析构掉内存地址
other.size = 0;
}
~String() {
printf("delete String\n");
delete[] m_Str;
}
void print() {
for (int i = 0; i < size; i++) {
printf("%c", m_Str[i]);
}
printf("\n");
}
private:
char* m_Str;
uint32_t size;
};
class Entity {
public:
Entity(const String& str):name((String&&)str){}//转成右值
void PrintName() {
name.print();
}
private:
String name;
};
int main() {
Entity entity(String("jack"));
entity.PrintName();
return 0;
}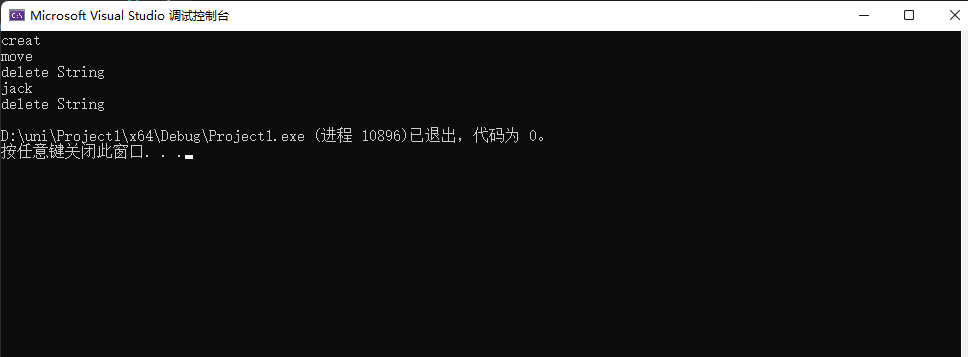
没有copy!问题完美解决。
有名字的右值引用是左值
每个表达式都有两种特征:一是类型二是值类别。
很多人迷惑的右值引用为啥是个左值,那是因为右值引用是它的类型,左值是它的值类别。
想理解右值首先要先知道类型和值类别的区别;其次是各个值类别的定义是满足了某种形式它就是那个类别,经常说的能取地址就是左值,否则就是右值,这是定义之上的不严谨经验总结,换句话说,是左值还是右值是强行规定好的,你只需要对照标准看这个表达式满足什么形式就知道它是什么值类别了。 为什么要有这个分类,是为了语义,当一个表达式出现的形式表示它是一个右值,就是告诉编译器,我以后不会再用到这个资源,放心大胆的转移销毁,这就可以做优化,比如节省拷贝之类的。 move的作用是无条件的把表达式转成右值,也就是rvalue_cast,虽然编译器可以推断出左右值,但人有时比编译器“聪明”,人知道这个表达式的值以后我不会用到,所以可以在正常情况下会推成左值的地方强行告诉编译器,我这是个右值,请你按右值的语义来做事。
std::move与移动赋值操作符
- 使用std::move,返回一个右值引用,可以将本来的copy操作变为move操作
#include<iostream>
class String {
public:
String() = default;
String(const char* str) {
printf("creat\n");
size = strlen(str);
m_Str = new char[size];
memcpy(m_Str, str, size);
}
String(const String& other) {// 拷贝构造函数
printf("copy\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
}
String(String&& other) {//以右值的方式传入,然后这样就可以把这个右值的内容全部偷盗
printf("move\n");
size = other.size;
m_Str = other.m_Str;
other.m_Str = nullptr;//将other里面的字符串指向别的地方,这样就不会析构掉内存地址
other.size = 0;
}
~String() {
printf("delete String\n");
delete[] m_Str;
}
void print() {
for (int i = 0; i < size; i++) {
printf("%c", m_Str[i]);
}
printf("\n");
}
private:
char* m_Str;
uint32_t size;
};
int main() {
String name1("jack");
String name2 = std::move(name1);
return 0;
}这样打印出来还是move
但是有一个问题,首先这个String name2 = std::move(name1);语句它是属于移动构造,所谓移动构造意思就是,还是构造这个变量(这个变量原先不存在)它也不能String name2.xxx这样使用。
如果我们想在声明完这个变量以后再初始化,会发生什么事情,可以看到编译器不通过,显示=的拷贝函数不存在。
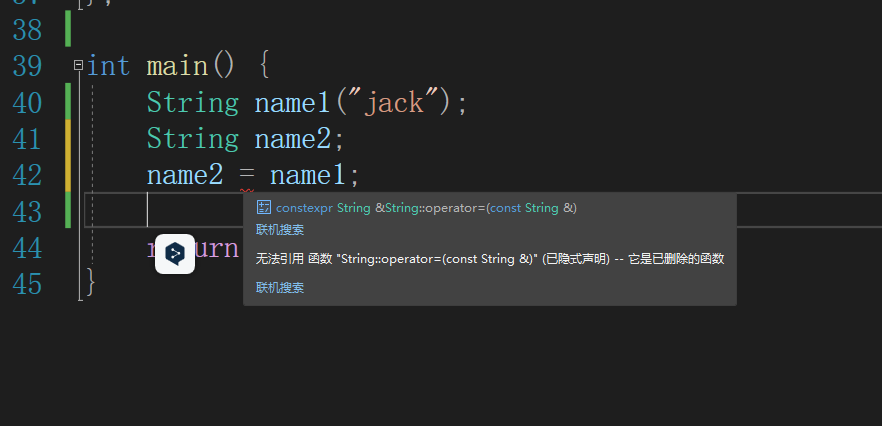
于是我们可以构造这个操作符
#include<iostream>
class String {
public:
String() = default;
String(const char* str) {
printf("creat\n");
size = strlen(str);
m_Str = new char[size];
memcpy(m_Str, str, size);
}
String(const String& other) {// 拷贝构造函数
printf("copy\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
}
String(String&& other) {//以右值的方式传入,然后这样就可以把这个右值的内容全部偷盗
printf("move\n");
size = other.size;
m_Str = other.m_Str;
other.m_Str = nullptr;//将other里面的字符串指向别的地方,这样就不会析构掉内存地址
other.size = 0;
}
String& operator =(const String& other) {//构造=的拷贝函数
printf("copy=\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
return *this;
}
~String() {
printf("delete String\n");
delete[] m_Str;
}
void print() {
for (int i = 0; i < size; i++) {
printf("%c", m_Str[i]);
}
printf("\n");
}
private:
char* m_Str;
uint32_t size;
};
int main() {
String name1("jack");
String name2;
name2 = name1;
name2.print();
return 0;
}
好,现在我需要使用右值去移动赋值,因为我不希望再分配内存,我只需要把你的东西偷过来给我用。
#include<iostream>
class String {
public:
String() = default;
String(const char* str) {
printf("creat\n");
size = strlen(str);
m_Str = new char[size];
memcpy(m_Str, str, size);
}
String(const String& other) {// 拷贝构造函数
printf("copy\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
}
String(String&& other) {//以右值的方式传入,然后这样就可以把这个右值的内容全部偷盗
printf("move\n");
size = other.size;
m_Str = other.m_Str;
other.m_Str = nullptr;//将other里面的字符串指向别的地方,这样就不会析构掉内存地址
other.size = 0;
}
String& operator =(const String& other) {//构造=的拷贝函数
printf("copy=\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
return *this;
}
String& operator =(String&& other) {//移动赋值语句
printf("move=\n");
size = other.size;
m_Str = other.m_Str;
other.m_Str = nullptr;
return *this;
}
~String() {
printf("delete String\n");
delete[] m_Str;
}
void print() {
for (int i = 0; i < size; i++) {
printf("%c", m_Str[i]);
}
printf("\n");
}
private:
char* m_Str;
uint32_t size;
};
int main() {
String name1("jack");
String name2("god");
name2 = std::move(name1);
name2.print();
return 0;
}但是可以看到,还是delete了两次,这是为什么。
是因为我们一开始创建了"god"的内存,但是我们移动了"jack"的内存,这里自动给我们删掉了"god",但是我们在使用的时候,最好还是手动释放掉这个内存。
同时移动赋值相当于把别的对象的资源都偷走,那如果移动到自己头上了就没必要自己偷自己 。 更重要的是原来自己的资源一定要释放掉,否则指向自己原来内容内存的指针就没了,这一片内存就泄露了!
#include<iostream>
class String {
public:
String() = default;
String(const char* str) {
printf("creat\n");
size = strlen(str);
m_Str = new char[size];
memcpy(m_Str, str, size);
}
String(const String& other) {// 拷贝构造函数
printf("copy\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
}
String(String&& other) {//以右值的方式传入,然后这样就可以把这个右值的内容全部偷盗
printf("move\n");
size = other.size;
m_Str = other.m_Str;
other.m_Str = nullptr;//将other里面的字符串指向别的地方,这样就不会析构掉内存地址
other.size = 0;
}
String& operator =(const String& other) {//构造=的拷贝函数
printf("copy=\n");
size = other.size;
m_Str = new char[size];
memcpy(m_Str, other.m_Str, size);
return *this;
}
String& operator =(String&& other) {//移动赋值语句
if (this != &other) {//自己移动自己就没必要了
printf("move=\n");
delete[] m_Str;//删除掉原来的内存
size = other.size;
m_Str = other.m_Str;
other.m_Str = nullptr;
}
return *this;
}
~String() {
printf("delete String\n");
delete[] m_Str;
}
void print() {
for (int i = 0; i < size; i++) {
printf("%c", m_Str[i]);
}
printf("\n");
}
private:
char* m_Str;
uint32_t size;
};
int main() {
String name1("jack");
String name2;
name2 = std::move(name1);
name2.print();
name2 = std::move(name2);
name2.print();
return 0;
}that end


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









