






汇编语言格式:AT&T
灵感来源于 MIT 6.828 关于中断实现的 challenge 部分
c语言文件和汇编文件在编译运行流程中都会转化为 .o 后缀的目标文件,通过链接器将他们链接为一个可执行文件。在这个过程中,汇编文件和c语言文件可以共享一些全局变量,并且汇编文件可以通过.data和.text灵活切换当前代码是作用于数据段还是代码段。我们可以巧妙使用这些 feature,配合宏定义,简化重复代码编写。配合x86中断机制中的中断处理函数注册过程,来给出一个具体例子。其中重点在于实现的简洁化,省略中断机制中不必要的细节。
中断机制
中断是一种机制,允许外部设备(如键盘、鼠标、网络接口)或软件(如系统调用)通知CPU有事件需要立即处理。中断可以是同步的如:由执行的指令序列显式触发如系统调用,或在程序执行过程中遇到了错误如除以0(也被称为异常);或异步的,一般由外部事件触发。通过中断机制,我们能提升程序响应速度,并且实现内核态与用户态的保护与隔离机制。
中断描述符表(IDT)
中断描述符表,用来确保中断和异常只能使内核通过一些特定的、由内核自己决定的、定义良好的入口点进入,而不是由发生中断或异常时正在运行的代码决定。
在中断发生时,处理器会识别发生的中断对应的中断号,在IDT中索引对应的中断表项,并将控制流从被中断代码位置跳转到对应中断处理函数开头。
x86架构允许最多256个不同的中断或异常进入内核的入口点,每个入口点都有一个不同的中断向量。向量是一个0到255之间的数字。中断的向量由中断的来源决定:不同的设备、错误条件和对内核的应用程序请求生成带有不同向量的中断。
中断处理函数注册
编写完成具体的中断处理函数后,程序员需要将其注册进入IDT中,才能够让处理器在中断处理的固定流程中调用该中断处理函数。中断处理函数的注册即在IDT中设置对应中断号的IDT 表项,包括中断门和陷阱门,以便当该中断发生时能调用正确的处理函数。具体数据结构如下:
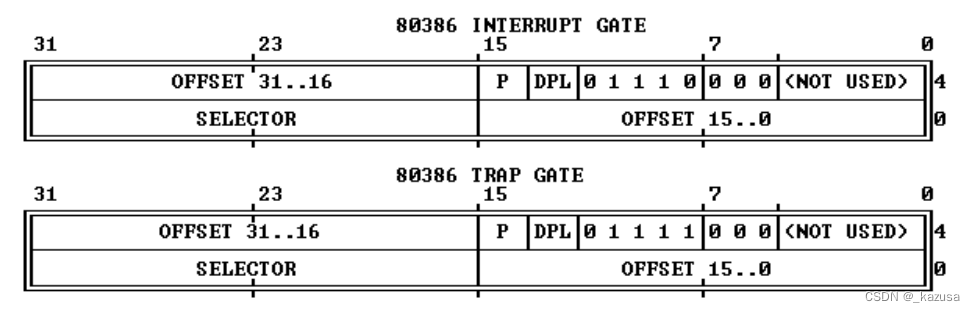
这两个门最主要的区别:中断门置位 IF 标志使得中断过程不被打断,而陷阱门不改变 IF 标志的值。
实现注册过程(直觉)
直觉上,对于所有中断处理函数,我们需要两个方面的准备工作:
- 设置IDT表项
- 设置表项对应的处理函数入口,做一些预处理操作再转入
对于必须的预处理操作,举例:在中断处理过程前,我们需要保存原有程序运行的信息以及寄存器现场,这个数据结构被称为 trap frame。那么必须的预处理操作即:中断发生后,每一个入口根据对应情况构造相同形式的 trap frame ,再转入统一的中断处理。
可以想到,每一个中断处理函数都需要编写对应的入口代码以及将函数注册入IDT中,这使得代码非常冗杂,先给出比较直接的编写方式,不优化代码的简洁程度。
根据这个思路,可写两部分代码:
trap.c:设置IDT表项
在IDT中构造中断门和陷阱门,注册对应中断处理函数:
// 必须要先声明外部定义的函数,这里是汇编代码中定义的中断处理入口
// 这部分函数在汇编文件中定义
void divide_handler();
void debug_handler();
void nmi_handler();
void brkpt_handler();
void oflow_handler();
void bound_handler();
void illop_handler();
void device_handler();
// 设置IDT表项
SETGATE(idt[T_DIVIDE], 1, GD_KT, divide_handler, 0);
SETGATE(idt[T_DEBUG], 1, GD_KT, debug_handler, 0);
SETGATE(idt[T_NMI], 1, GD_KT, nmi_handler, 0);
SETGATE(idt[T_BRKPT], 1, GD_KT, brkpt_handler, 0);
SETGATE(idt[T_OFLOW], 1, GD_KT, oflow_handler, 0);
SETGATE(idt[T_BOUND], 1, GD_KT, bound_handler, 0);
SETGATE(idt[T_ILLOP], 1, GD_KT, illop_handler, 0);
SETGATE(idt[T_DEVICE], 1, GD_KT, device_handler, 0);
// 宏定义如下,创建IDT表项,注册IDT:
// Set up a normal interrupt/trap gate descriptor.
// - istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate.
// see section 9.6.1.3 of the i386 reference: "The difference between
// an interrupt gate and a trap gate is in the effect on IF (the
// interrupt-enable flag). An interrupt that vectors through an
// interrupt gate resets IF, thereby preventing other interrupts from
// interfering with the current interrupt handler. A subsequent IRET
// instruction restores IF to the value in the EFLAGS image on the
// stack. An interrupt through a trap gate does not change IF."
// - sel: Code segment selector for interrupt/trap handler
// - off: Offset in code segment for interrupt/trap handler
// - dpl: Descriptor Privilege Level -
// the privilege level required for software to invoke
// this interrupt/trap gate explicitly using an int instruction.
#define SETGATE(gate, istrap, sel, off, dpl) \
trap_entry.S:设置表项对应的处理函数入口
描述处理函数入口,利用汇编宏定义简化:
define TRAPHANDLER(name, num) \
.globl name; /* define global symbol for 'name' */ \
.type name, @function; /* symbol type is function */ \
.align 2; /* align function definition */ \
name: /* function starts here */ \
pushl $(num); /* interrupt number */
# 上面的pushl指令以及后续指令都是在构造trapframe,不具体展开
# 定义C文件中引用的函数名
TRAPHANDLER(divide_handler, T_DIVIDE)
TRAPHANDLER(debug_handler, T_DEBUG)
TRAPHANDLER(nmi_handler, T_NMI)
TRAPHANDLER(brkpt_handler, T_BRKPT)
TRAPHANDLER(oflow_handler, T_OFLOW)
TRAPHANDLER(bound_handler, T_BOUND)
TRAPHANDLER(illop_handler, T_ILLOP)
TRAPHANDLER(device_handler, T_DEVICE)
实现注册过程(简化)
对于上面的实现过程,确实存在了大量的重复代码,比如一个中断处理函数名在这两个文件中会出现三次,一次定义,一次声明,一次SETGATE。可以简化这些重复出现的函数名吗?重新审视整个注册过程,我们实际上将汇编中定义的函数名通过c代码注册进入了IDT表,是否可以通过一些方式在c文件中直接访问这些函数的地址,省略在c文件中显式声明和使用这些函数名呢?
trap_entry.S
# 在.data段定义函数指针,指向将要创建的处理函数地址
.data
.p2align 2
.globl funs
funs:
# 与原宏定义的区别是多了.data段的.long name
#define TRAPHANDLER(name, num)\
.data;\
.long name;\
.text;\
.globl name;\
.type name, @function;\
.align 2;\
name:\
pushl $(num);\
TRAPHANDLER(divide_handler, T_DIVIDE)
TRAPHANDLER(debug_handler, T_DEBUG)
TRAPHANDLER(nmi_handler, T_NMI)
TRAPHANDLER(brkpt_handler, T_BRKPT)
TRAPHANDLER(oflow_handler, T_OFLOW)
TRAPHANDLER(bound_handler, T_BOUND)
TRAPHANDLER(illop_handler, T_ILLOP)
TRAPHANDLER(device_handler, T_DEVICE)
首先,在汇编文件的数据段设置一个全局可见的函数指针 func。在原来宏定义的基础上,向数据段中添加 name 变量的地址,即为中断处理函数的地址。汇编代码中,段定义有这样的特点:在一个文件中,源代码文件的.data段内或者.text段内的内容在最终的地址空间中是连续的,我们在编写的时候可以分别定义每个段的部分,最终汇编器会将相同段的内容连接起来。
以上面的代码为例来解释,每次宏的使用都会在数据段中func的位置下写入处理函数的地址,当该汇编文件创建完代码段处理函数入口的同时,整体上也在数据段创建了一个函数地址数组,由于func是全局可见的,我们在c文件中可以通过引用该指针来访问这些处理函数的地址,在注册过程中使用。
trap.c
extern void (*funs[])();
for (int i = 0; i <= 16; ++i)
if (i!=9) {
SETGATE(idt[i], 0, GD_KT, funs[i], 0);
}
以上c代码非常简洁地引用了汇编中通过宏定义的函数地址数组,通过循环将中断处理函数注册进IDT。
对于i != 9,再详细解释下具体实现:
再x86处理器的中断机制中,有一些中断号是保留不用的,如9号中断。那么为了保证汇编数据段func指向的函数地址在数组中的位置与中断号对齐,就需要一些padding。
trap_entry.S
# 在.data段定义函数指针,指向将要创建的处理函数地址
.data
.p2align 2
.globl funs
funs:
# 与原宏定义的区别是多了.data段的.long name
#define TRAPHANDLER(name, num)\
.data;\
.long name;\
.text;\
.globl name;\
.type name, @function;\
.align 2;\
name:\
pushl $(num);
#define PADDING\
.data;\
.long 0
TRAPHANDLER(divide_handler, T_DIVIDE)
TRAPHANDLER(debug_handler, T_DEBUG)
TRAPHANDLER(nmi_handler, T_NMI)
TRAPHANDLER(brkpt_handler, T_BRKPT)
TRAPHANDLER(oflow_handler, T_OFLOW)
TRAPHANDLER(bound_handler, T_BOUND)
TRAPHANDLER(illop_handler, T_ILLOP)
TRAPHANDLER(device_handler, T_DEVICE)
PADDING
由此完成了更简洁的中断处理函数注册实现,通过仔细分析需求与目的,我们可以在汇编代码中创建函数地址数组直接访问函数地址,避免全局符号访问机制中冗杂的声明和使用。















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









