







 本文详细介绍了SQL中的OLAP(在线分析处理)查询,包括聚集查询、联表查询和子查询。聚集查询讲解了聚合函数、GROUP BY和HAVING关键字的使用;联表查询探讨了笛卡尔积、内联、外联和自联合的操作;子查询则阐述了其在过滤条件中的应用,如IN和EXISTS关键字。通过实例展示了如何在实际数据库操作中进行这些高级查询。
本文详细介绍了SQL中的OLAP(在线分析处理)查询,包括聚集查询、联表查询和子查询。聚集查询讲解了聚合函数、GROUP BY和HAVING关键字的使用;联表查询探讨了笛卡尔积、内联、外联和自联合的操作;子查询则阐述了其在过滤条件中的应用,如IN和EXISTS关键字。通过实例展示了如何在实际数据库操作中进行这些高级查询。
目录
在进行聚合查询时,能出现在select后边的,只能是1)聚合函数;2)分组的字段
1.把一个select结果视为一张表,继续from这张表去查询
数据库的主要使用场景:
1)OLTP:事务处理(发表文章、写作业、批改作业...CURD都有)
2)OLAP:事务分析(某班共写了多少作业、完成率、CSDN用户增长数...一次涉及众多数据,一般仅查询,很少修改)
OLAP:聚集查询;联表查询;子查询
一、聚集/聚合查询

这些问题都是对已有数据做聚合(aggeegation),是按照班级来做聚合的。不但可以对单一字段,也可以对多字段聚合。
1.聚合函数
count(*)、max(...)、min(...)、sum(...)、avg(...)
-- 学生表
CREATE TABLE student (
id INT,
sn INT comment '学号',
name VARCHAR(20) comment '姓名',
qq_mail VARCHAR(20) comment 'QQ邮箱'
);INSERT INTO student VALUES (100, 10000, '开心超人', NULL);
INSERT INTO student VALUES (101, 10001, '小心超人', '11111');INSERT INTO student (id, sn, name) VALUES
(102, 20001, '甜心超人'),
(103, 20002, '粗心超人');
-- 成绩表
CREATE TABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);-- 给成绩表插入测试数据
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'开心超人', 67, 98, 56),
(2,'甜心超人', 87.5, 78, 77),
(3,'小心超人', 88, 98, 90),
(4,'粗心超人', 82, 84, 67),
(5,'大大怪', 55.5, 85, 45),
(6,'小小怪', 70, 73, 78.5),
(7,'花心超人', 75, 65, 30);
-- COUNT
SELECT COUNT(*) FROM student; -- 结果 COUNT(*) 4
SELECT COUNT(*) FROM exam_result; -- 结果 8
SELECT count(1) from student; -- 4
select count(name) from student; -- 4
select count(qq_mail) from student; -- 如果是 null,不算入count(qq_email只有一个人有,所以只统计了一个人的)-- sum/avg/max/min只能用于数字类型的字段
-- 聚合的意思是竖着计算的
select sum(math) from exam_result;
-- 而要计算某个人的语文+数学+英语,作为对比,这种不叫聚合
select chinese+math+english total from exam_result where id=7; -- 不是聚合
select avg(math) from exam_result;
select max(math) from exam_result;
select min(math) from exam_result;
2.聚合字段(group by)
-- group : 分组进行聚合;
-- by 以哪个字段作为依据进行分组
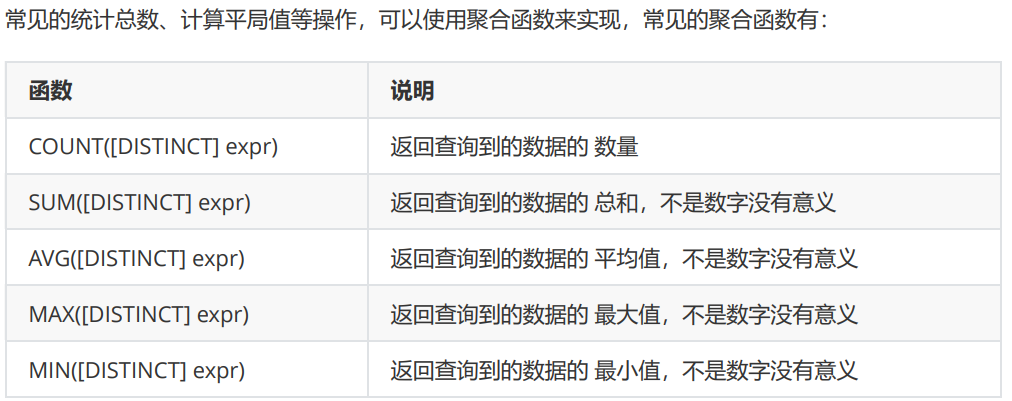
select role, count(*) from emp group by role; -- 以角色为依据进行聚合,每种角色都是一个独立的聚合单位
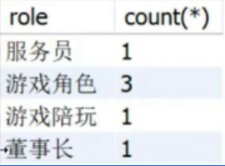
-- 永远不要这么用,这里演示的目的只是告诉大家 mysql 不讲武德
-- 因为 mysql 没有遵循规范,name 的值没有道理
select name, role, count(*) from emp group by role;
(有些DBMS没有遵循规范,比如MySQL是可以出现其他字段的,但最终结果中出现什么都是未定义行为) 如此处name既不是聚合函数,也不是分组字段,是没有任何道理的。
在进行聚合查询时,能出现在select后边的,只能是1)聚合函数;2)分组的字段
-- 可以先通过 where 条件筛选过数据之后再进行聚合
select role, count(*) from emp where salary > 1000 group by role;create table emp2(
id int primary key auto_increment,
name varchar(20) not null,
company varchar(20) not null,
depart varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);insert into emp2(name, company, depart, role, salary) values
('小a', '小小公司', '服务部', '服务员', 1000.20),
('小b', '小小公司', '服务部', '服务员', 1000.20),
('小c', '小小公司', '服务部', '服务员', 1000.20),
('小d', '小小公司', '服务部', '服务员', 1000.20),
('小e', '小小公司', '服务部', '服务员', 1000
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









