







如图所示,表示发起一个请求时,涉及到数据库的相关操作,在前面的文章中我们说过,如果服务端要提升整体的吞吐量,就必须要减少每一次请求的处理时长,那么在当前这个场景中,数据库层面哪些因素会影响到性能呢?
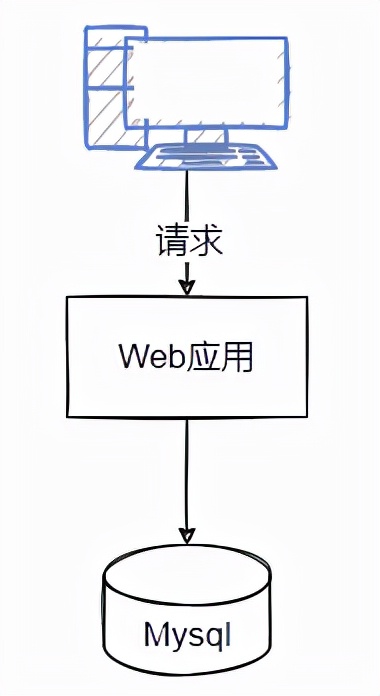
图2-1
池化技术,减少频繁创建数据库连接
遇到这样的问题,解决办法就是顺着当前整体的逻辑去思考,首先,应用要和数据库打交道,必然会设计到数据库链接的建立。然后在当前连接中完成数据库的相关操作,最后再关闭连接。
在这种场景下,客户端每次发起请求,都需要重新建立连接,如果频繁的创建连接是否会影响到性能呢?答案是一定的,我们通过下面这样一个方式来验证一下
# -i指定网卡名称
tcpdump -i eth0 -nn -tttt port 3306
当我们向数据库发起一次连接时,上述抓包命令会打印连接的相关信息如下。(通过Navicat 的链接测试工具测试)
关注前面8行数据即可。
2021-06-24 23:15:50.130812 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [S], seq 759743325, win 64240, options [mss 1448,nop,wscale 8,nop,nop,sackOK], length 0
2021-06-24 23:15:50.130901 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [S.], seq 3058334924, ack 759743326, win 29200, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
2021-06-24 23:15:50.160730 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [.], ack 1, win 260, length 0
2021-06-24 23:15:50.161037 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [P.], seq 1:79, ack 1, win 229, length 78
2021-06-24 23:15:50.190126 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [P.], seq 1:63, ack 79, win 259, length 62
2021-06-24 23:15:50.190193 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [.], ack 63, win 229, length 0
2021-06-24 23:15:50.190306 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [P.], seq 79:90, ack 63, win 229, length 11
2021-06-24 23:15:50.219256 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [P.], seq 63:82, ack 90, win 259, length 19
2021-06-24 23:15:50.219412 IP 172.17.136.216.3306 > 218.76.8.219.57423: Flags [P.], seq 90:101, ack 82, win 229, length 11
2021-06-24 23:15:50.288721 IP 218.76.8.219.57423 > 172.17.136.216.3306: Flags [.], ack 101, win 259, length 0
- 第一部分是TCP三次握手建立连接的数据包第一个数据包是客户端向服务区段发送一个SYN包第二个数据包是服务端返回给客户端的ACK包以及一个SYN包第三个数据包是客户端返回给服务端的ACK包
- 第二个部分是Mysql服务端校验客户端密码的过程
从开始建立连接的时间130812到最终完成连接288721, 总共耗时157909,接近158ms时间,这个时间看起来很小,而且在请求量较小的情况下,对系统的影响不是很大。但是请求量上来之后,这个请求耗时的影响就非常大了。
而对于这个问题的解决办法大家都已经知道,就是利用池化技术,预先建立好数据库连接,当应用需要使用连接时,直接从预先建立好的连接中来获取进行调用,如图2-2所示。
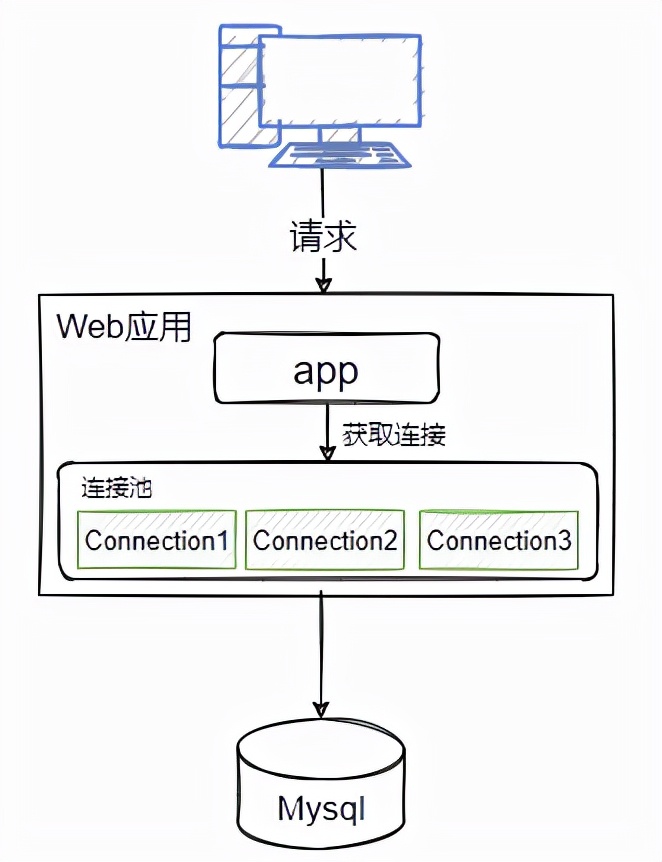
图2-2
数据库连接池的工作原理和线程池类似,数据库连接池有两个最重要的配置: 最小连接数和最大连接数, 它们控制着从连接池中获取连接的流程:
- 如果当前连接数小于最小连接数,则创建新的连接处理数据库请求;
- 如果连接池中有空闲连接则复用空闲连接;
- 如果空闲池中没有连接并且当前连接数小于最大连接数,则创建新的连接处理请求;
- 如果当前连接数已经大于等于最大连接数,则按照配置中设定的时间(maxWait)等待旧的连接可用;
- 如果等待超过了这个设定时间则向用户抛出错误。
总的来说,连接池核心思想是空间换时间,期望使用预先创建好的对象来减少频繁创建对象的性能开销,同时还可以对对象进行统一的管理,降低了对象的使用的成本。
数据库本身的性能优化
数据库本身的性能优化也很重要,常见的优化手段
- 创建并正确使用索引,尽量只通过索引访问数据
- 优化SQL执行计划,SQL执行计划是关系型数据库最核心的技术之一,它表示SQL执行时的数据访问算法,优化执行计划也就能够提升sql查询的性能
- 每次数据交互时,尽可能返回更少的数据,因为更大的数据意味着会增
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1551
1551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









