






“path”: “/user/hive/warehouse/bigdata30_test.db/new_students_hive”,阿里云开源离线同步工具DataX3.0
一. DataX3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

-
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
-
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX
二、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三. DataX3.0插件体系
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。详情请看:DataX数据源指南
四、DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了25个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据25个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
五、DataX 3.0六大核心优势
-
可靠的数据质量监控
-
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
-
提供作业全链路的流量、数据量运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
-
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
-
-
丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
-
精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
"speed": { "channel": 5, "byte": 1048576, "record": 10000 } -
强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
-
健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
-
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
-
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
-
-
极简的使用体验
-
易用
下载即可用,支持linux和windows,只需要短短几步骤就可以完成数据的传输。请点击:Quick Start
-
详细
DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。
-
传输过程中打印传输速度、进度等

-
传输过程中会打印进程相关的CPU、JVM等

-
在任务结束之后,打印总体运行情况

-
-



六、DataX与Sqoop对比
| 功能 | DataX | Sqoop |
|---|---|---|
| 运行模式 | 单进程多线程 | MR |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在core部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
七、DataX部署
1、下载
github上下载安装包并上传到master中
地址:https://github.com/alibaba/DataX
2、解压并配置环境变量
tar -zxvf datax.tar.gz -C ../
3、自检,执行如下命令
[root@master datax]# python ./bin/datax.py ./job/job.json
出现如下内容,则表明安装成功

八、DataX使用
模板介绍
生成模板的命令 reader、writer按需要任意更改
datax.py -r mysqlreader -w hdfswriter
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [{
"type":"string",
"value":"你好"
},
{
"type":"string",
"value":"世界"
},
{
"type":"string",
"value":"刘天保真帅"
}],
"sliceRecordCount": 10
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 2
}
}
}
}
1、使用说明
1.1 DataX任务提交命令
DataX的使用十分简单,用户只需根据自己同步数据的数据源和目的地选择相应的Reader和Writer,并将Reader和Writer的信息配置在一个json文件中,然后执行如下命令提交数据同步任务即可。
python ./bin/datax.py ./job/job.json
datax.py xxx.json
1.2 DataX配置文件格式
编写json文件的步骤:
1、根据你确定的reader和writer来使用命令生成对应的模板
2、去github上找到对应参数值的写法,主要是看参数是否是必须项,有什么影响
可以使用如下命名查看DataX配置文件模板。
举例:mysql–>hdfs中
[root@master datax]# datax.py -r mysqlreader -w hdfswriter
"where": "" :相当于sql中的where
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [],
"compress": "",
"defaultFS": "",
"fieldDelimiter": "",
"fileName": "",
"fileType": "",
"path": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
配置文件模板如下,json最外层是一个job,job包含setting和content两部分,其中setting用于对整个job进行配置,content用户配置数据源和目的地。
带同学们一起去理解配置中的信息
Reader和Writer的具体参数可参考官方文档
2、DataX基本使用
2.1 打印输入流在控制台
查看
streamreader --> streamwriter的模板:
[root@master datax]# datax.py -r streamreader -w streamwriter
根据模板编写json文件
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{"type": "string","value": "李凯迪"},
{"type": "string","value": "真帅"},
{"type": "string","value": "是的"},
{"type": "string","value": "没错"}
],
"sliceRecordCount": "2"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
{
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"column": [{ # 同步的列名 (* 表示所有)
"type": "string",
"value": "你好."
},
{
"type": "string",
"value": "世界!!"
},
],
"sliceRecordCount": "3" # 打印数量
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8", # 编码
"print": true
}
}
}],
"setting": {
"speed": {
"channel": "2" # 并发 (即 sliceRecordCount * channel = 结果)
}
}
}
}
注意,练习的时候,复制时需要把我上面的#注释内容去掉
执行同步任务
datax.py stream2stream.json

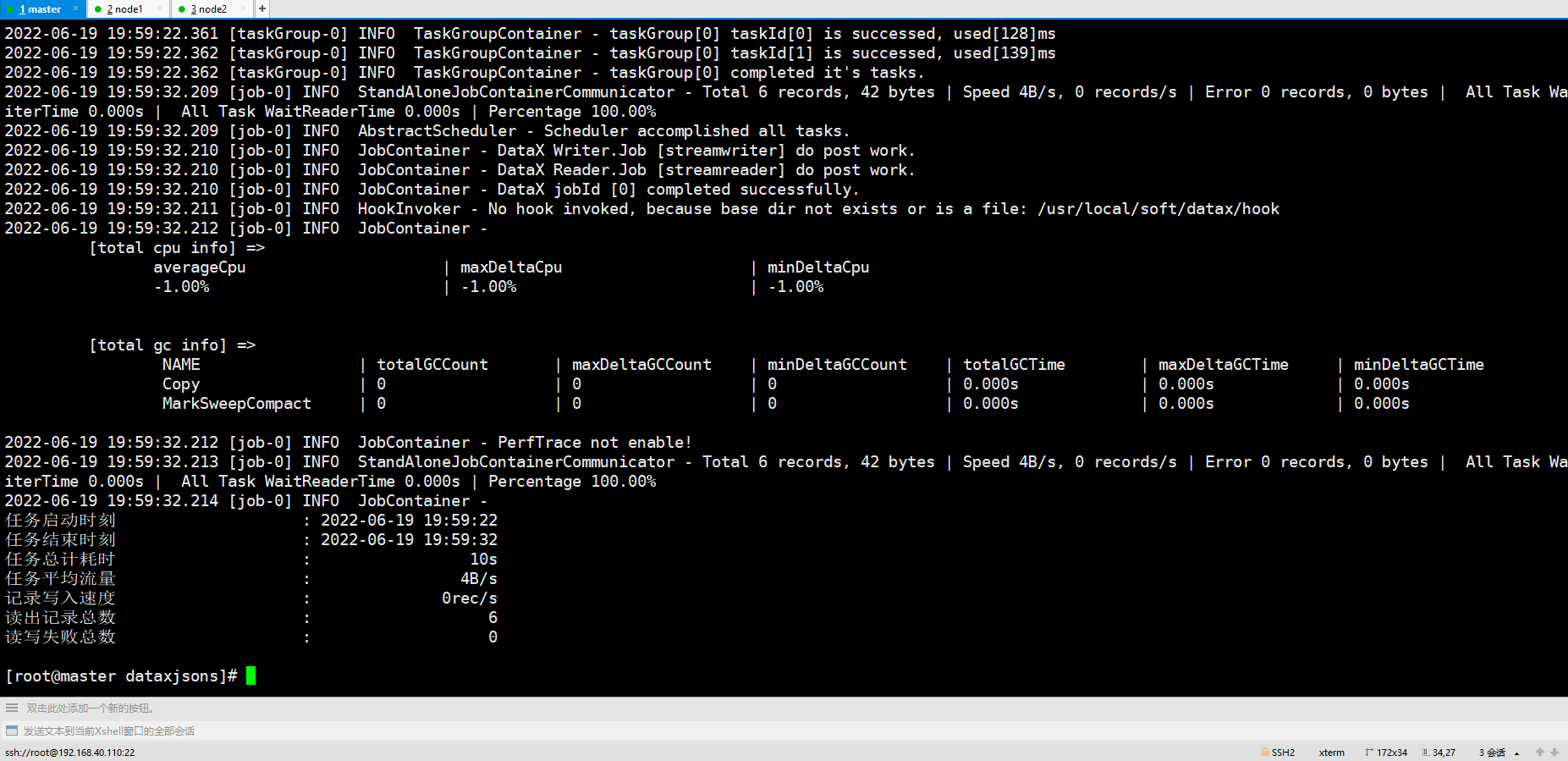
2.2 mysql2mysql(数据迁移)
生成 MySQL 到 MySQL 同步的模板:(用于新旧数据库的数据同步)
datax.py -r mysqlreader -w mysqlwriter
模板:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://master:3306/bigdata25?useUnicode=true&characterEncoding=utf-8"],
"table": ["jd_goods"]
}
],
"password": "123456",
"username": "root",
"where": "goods_shop='华为京东自营官方旗舰店'"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id","goods_name","goods_price","goods_shop","goods_comments"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://master:3306/shujia?useUnicode=true&characterEncoding=utf-8",
"table": ["jd_goods"]
}
],
"password": "123456",
"username": "root",
"preSql": [
"delete from jd_goods"
],
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
需要新建student2数据库,并创建student表
DROP TABLE IF EXISTS `dataxtostudent`;
CREATE TABLE `dataxtostudent` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` char(5) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`gender` char(2) DEFAULT NULL,
`clazz` char(4) DEFAULT NULL,
`last_mod` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=1500101002 DEFAULT CHARSET=utf8;
编写配置文件mysql2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"gender",
"clazz",
"last_mod"
],
"splitPk": "age",
"connection": [
{
"table": [
"dataxtostudent"
],
"jdbcUrl": [
"jdbc:mysql://master:3306/bigdata_30"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"age",
"gender",
"clazz",
"last_mod"
],
"preSql": [
"truncate students"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://master:3306/bigdata_30?useUnicode=true&characterEncoding=utf8",
"table": [
"students"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
执行同步任务
datax.py mysql2mysql.json
2.3 mysql2hdfs
查看模板
python /usr/local/soft/datax/bin/datax.py -r mysqlreader -w hdfswriter
模板:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://master:3306/bigdata25?useUnicode=true&characterEncoding=utf-8"],
"table": ["jd_goods"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "string"
},
{
"name": "goods_name",
"type": "string"
},
{
"name": "goods_price",
"type": "string"
},
{
"name": "goods_shop",
"type": "string"
},
{
"name": "goods_comments",
"type": "string"
}
],
"defaultFS": "hdfs://master:9000",
"fieldDelimiter": ",",
"fileName": "jd_goods",
"fileType": "text",
"path": "/bigdata25/dataxinfo/output1",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
mysql 建表
CREATE TABLE `t_user` (
`id` bigint(10) NOT NULL,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
/*Data for the table `t_user` */
insert into `t_user`(`id`,`name`) values (1,'flink'),(2,'slave'),(3,'hive'),(4,'flink04'),(5,'hbase');
编写配置文件mysql2hdfs.json
"column": 传入该列名的数据
"fieldDelimiter": " " : 用于指定数据文件中字段之间的分隔符
"path": "/bigdata30/datax" : 脚本不会自动在hdfs端生成该文件夹,需要自己手动创建该文件夹 ???
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.128.100:3306/bigdata_30"
],
"table": [
"t_user"
]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://192.168.128.100:9000",
"fieldDelimiter": " ",
"fileName": "t_user.txt",
"fileType": "text",
"path": "/bigdata30/datax/test",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
执行同步任务
datax.py mysql2hdfs.json
datax.py mysql2hdfstest.json

hdfs查看结果

t_user.txt__c5a41041_6919_4514_821a_6e571ce5d115 HdfsWriter 实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名
2.4 mysql2hive
(1)、目前HdfsWriter仅支持textfile和orcfile两种格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表;
(2)、由于HDFS是文件系统,不存在schema的概念,因此不支持对部分列写入;
(3)、目前仅支持与以下Hive数据类型: 数值型:TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE 字符串类型:STRING,VARCHAR,CHAR 布尔类型:BOOLEAN 时间类型:DATE,TIMESTAMP 目前不支持:decimal、binary、arrays、maps、structs、union类型;
(4)、对于Hive分区表目前仅支持一次写入单个分区;
(5)、对于textfile需用户保证写入hdfs文件的分隔符与在Hive上创建表时的分隔符一致,从而实现写入hdfs数据与Hive表字段关联;
(6)、HdfsWriter实现过程是:/首先根据用户指定的path,创建一个hdfs文件系统上不存在的临时目录?/,创建规则:path_随机;然后将读取的文件写入这个临时目录;全部写入后再将这个临时目录下的文件移动到用户指定目录(在创建文件时保证文件名不重复); 最后删除临时目录。如果在中间过程发生网络中断等情况造成无法与hdfs建立连接,需要用户手动删除已经写入的文件和临时目录。
(7)、目前插件中Hive版本为1.1.1,Hadoop版本为2.7.1(Apache[为适配JDK1.7],在Hadoop 2.5.0, Hadoop 2.6.0 和Hive 1.2.0测试环境中写入正常;其它版本需后期进一步测试;(之前的)
(8)、目前HdfsWriter支持Kerberos认证(注意:如果用户需要进行kerberos认证,那么用户使用的Hadoop集群版本需要和hdfsreader的Hadoop版本保持一致,如果高于hdfsreader的Hadoop版本,不保证kerberos认证有效)
查看模板
datax.py -r mysqlreader -w hdfswriter
创建hive数据库
create database dataxinfo;
创建表
use database; 选择数据库,并在其中建表(与MySQL相同)
或在datagrip中,点击该数据库创建queryconsole端口,在其中编写建表语句
CREATE TABLE IF NOT EXISTS new_students(
id STRING,
name STRING,
sum_score bigint,
clazz STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
location '/bigdata30/datax/new_students';
mysql建表
CREATE TABLE IF NOT EXISTS new_students(
id varchar(5),
name varchar(10),
sum_score int,
clazz varchar(10)
)
编写配置文件mysql2hdfs2.json.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://master:3306/bigdata_30?useUnicode=true&characterEncoding=utf-8"],
"table": ["new_students"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "string"
},
{
"name": "name",
"type": "string"
},
{
"name": "sum_score",
"type": "int"
},
{
"name": "clazz",
"type": "string"
}
],
"defaultFS": "hdfs://master:9000",
"fieldDelimiter": ",",
"fileName": "new_students",
"fileType": "text",
"path": "/bigdata30/datax/new_students",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
执行同步任务
只是将数据上传到了hdfs上,hive中并没有数据???(开始时hive中建表没有指定MySQL数据导入的文件夹)
MySQLtoHive操作步骤:(与MySQLtoHDFS相比,多了在hive中建表指定location这一步)-- 这是由于 "path": "/bigdata30/datax/new_students"指定的并非是hive中创建的表的路径,所以hive中创建表的时候要指定location,正确实现见本文的最后一个案例
1.在hive中建表,并指定数据之间的分隔符(与"fieldDelimiter": ","保持一致),指定location为MySQL传入数据的文件夹(location '/bigdata30/datax/new_students')
2.在MySQL中建表,导入数据(若MySQL下没有表)
3.编写json脚本,在填入模板中填入本机中数据对应信息
4.datax.py mysql2hdfs2.json(启动脚本)

查询hive表

hdfs2mysql == hive2mysql
案例:将hive中dataxinfo数据库下的new_students表中的数据,同步到MySQL中的studentdb数据库下的new_students表中
编写脚本
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": [
{
"type": "Long",
"index": 0
},
{
"type": "String",
"index": 1
},
{
"type": "Long",
"index": 2
},
{
"type": "String",
"index": 3
}
],
"defaultFS": "hdfs://master:9000",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileType": "text",
"path": "/bigdata30/datax/new_students/*"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name",
"sum_score",
"clazz"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://master:3306/studentdb?useUnicode=true&characterEncoding=utf-8",
"table": ["new_students"]
}
],
"password": "123456",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
数据库建表:
create table studentdb.new_students(
id int,
name varchar(10),
sum_score int,
clazz varchar(10)
)
执行脚本
datax.py hive2mysql.json
运行结果:


2.5 mysql2hbase
脚本模板:
datax.py -r mysqlreader -w hbase20xsqlwriter
python /usr/local/soft/datax/bin/datax.py -r mysqlreader -w hbase11xwriter
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://master:3306/shujia?useUnicode=true&characterEncoding=utf-8"],
"table": ["new_students"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"hbaseConfig": {
"hbase.zookeeper.quorum": "master:2181,node1:2181,node2:2181"
},
"table": "newstudents",
"mode": "normal",
"rowkeyColumn": [
{
"index":0,
"type":"string"
},
{
"index":-1,
"type":"string",
"value":"_"
}
],
"column": [
{
"index":1,
"name": "cf1:name",
"type": "string"
},
{
"index":2,
"name": "cf1:email",
"type": "string"
},
{
"index":3,
"name": "cf1:age",
"type": "string"
}
],
"encoding": "UTF-8"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
案例将MySQL中studentdb数据库下的student表中的数据同步到hbase中的dataxstudent表中
编写脚本:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"age",
"gender",
"clazz",
"last_mod"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://master:3306/studentdb?useUnicode=true&characterEncoding=utf8"],
"table": ["student"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"column": [
{"index":1,"name": "cf1:id","type": "string"},
{"index":2,"name": "cf1:name","type": "string"},
{"index":3,"name": "cf1:age","type": "string"},
{"index":4,"name": "cf1:gender","type": "string"},
{"index":5,"name": "cf1:clazz","type": "string"},
{"index":6,"name": "cf1:last_mod","type": "string"}
],
"encoding": "UTF-8",
"hbaseConfig": {
"hbase.zookeeper.quorum": "master:2181,node1:2181,node2:2181"
},
"mode": "normal",
"rowkeyColumn": [
{"index":0,"type": "string"},
{"index":-1,"type": "string","value":"_"},
{"index":4,"type": "string"}
],
"table": "dataxstudent2"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
hbase中创建表:
create 'dataxstudent2','cf1'
执行脚本
datax.py mysql2hbase.json
执行结果:

mysql中的score表需将cource_id改为course_id,并将student_id、course_id设为主键,并将所有字段的类型改为int
hbase需先创建score表:create ‘score2’,‘cf1’
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"sum_score",
"clazz"
],
"connection": [
{
"table": [
"new_students"
],
"jdbcUrl": [
"jdbc:mysql://master:3306/bigdata_30"
]
}
]
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"hbaseConfig": {
"hbase.zookeeper.quorum": "master:2181,node1:2181,node2:2181"
},
"table": "new_students_hb",
"mode": "normal",
"rowkeyColumn": [
{
"index":0,
"type":"string"
},
{
"index":-1,
"type":"string",
"value":"_"
},
{
"index":1,
"type":"string"
}
],
"column": [
{
"index":2,
"name": "cf1:score",
"type": "int"
}
],
"encoding": "utf-8"
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"sum_score",
"clazz"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://master:3306/bigdata_30?useUnicode=true&characterEncoding=utf8"],
"table": ["new_students"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"column": [
{"index":1,"name": "cf1:name","type": "string"},
{"index":2,"name": "cf1:sum_score","type": "string"},
{"index":3,"name": "cf1:clazz","type": "string"},
],
"encoding": "UTF-8",
"hbaseConfig": {
"hbase.zookeeper.quorum": "master:2181,node1:2181,node2:2181"
},
"mode": "normal",
"rowkeyColumn": [
{"index":0,"type": "string"},
{"index":-1,"type": "string","value":"_"},
],
"table": "dataxstudent3"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
datax.py mysql2hbase2.json
2.6 hbase2mysql
datax.py -r hbase11xreader -w mysqlwriter
官方模板:
{
"job": {
"content": [
{
"reader": {
"name": "hbase11xreader",
"parameter": {
"column": [],
"encoding": "",
"hbaseConfig": {},
"mode": "",
"range": {
"endRowkey": "",
"isBinaryRowkey": true,
"startRowkey": ""
},
"table": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
案例:将hbase中dataxstudent3中的表数据同步到MySQL的bigdata_30数据库中的new_students_hb表中
操作步骤:
编写脚本:
"column":[] : hbase cloumn 中的字段类型可以都设置为string
{
"job": {
"content": [
{
"reader": {
"name": "hbase11xreader",
"parameter": {
"hbaseConfig": {
"hbase.zookeeper.quorum": "master:2181,node1:2181,node2:2181"
},
"table": "dataxstudent3",
"encoding": "utf-8",
"mode": "normal",
"column": [
{
"name": "rowkey",
"type": "string"
},
{
"name": "cf1:name",
"type": "string"
},
{
"name": "cf1:sum_score",
"type": "string"
},
{
"name": "cf1:clazz",
"type": "string"
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id","name","sum_score","clazz"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://master:3306/bigdata_30?useUnicode=true&characterEncoding=utf-8",
"table": ["new_students_hb"]
}
],
"password": "123456",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
preSql
描述:写入数据到目的表前,会先执行这里的标准语句,非必选。
"preSql": ["delete from new_students" ],
preSql
描述:写入数据到目的表前,会先执行这里的标准语句,非必选。
"preSql": [ "truncate student" ]
执行脚本:
datax.py hbaseTomysql1.json

2.7 mysql增量同步到hive
需要注意的部分就是:
where(条件筛选,筛选出一部分的内容同步到hive中)
案例取出bigdata_30中new_students表的符合条件的数据同步到hive中
编写脚本
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"name",
"sum_score",
"clazz"
],
"splitPk": "id",
"where": "sum_score < 100",
"connection": [
{
"table": [
"new_students"
],
"jdbcUrl": [
"jdbc:mysql://master:3306/bigdata_30"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://master:9000",
"fileType": "text",
"path": "/user/hive/warehouse/bigdata30_test.db/new_students_hive",
"fileName": "new_students_hive",
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "sum_score",
"type": "INT"
},
{
"name": "clazz",
"type": "string"
}
],
"writeMode": "append",
"fieldDelimiter": ","
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
执行脚本
datax.py mysqlToHive.json

MySQLtoHive注意:
指定hdfs上的路径,该路径对应于Hive中创建的表
“path”: “/user/hive/warehouse/bigdata30_test.db/new_students_hive”
一个表对应于下面的一个文件夹,选择该文件夹为path。将来传入的数据会存放到该文件夹下,那么数据就会自动同步到hvie中的那个对应的表中
















 2858
2858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









