






人工智能课程设计之基于今日头条数据集的模型分类训练
课程设计要求
1.给定今日头条数据集,共32000条,分布于15个类别。每行为一条数据,以
_!_分割的个字段。从前往后分别是新闻ID,分类code,类别,新闻字符串(仅含标题),新闻关键词。
2.去除数据集中的冗余信息,仅保留新闻长度大于5的标题及类别。
3.根据语料库构建单词词典,并生成对应的word2vec向量。
4.从TextCNN、LSTM、BILSTM、FastText、DPCNN中任选一种用于实验,可在模型的基础上自行增加模块。
5.调整学习率的变化,比如:0.1、0.01、0.05、0.001等,分析不同学习率对实验结果的影响,分析原因。
6.使用不同的优化器,比如Adam、AdamW、SGD等,观察实验的结果。
7.使用matplotlib工具绘制模型损失Loss下降曲线。
8.数据集按照8:1:1划分训练集、验证集、测试集,且实验准确率要求达到70%以上。
9.撰写实验报告
数据集
32000条今日头条数据集
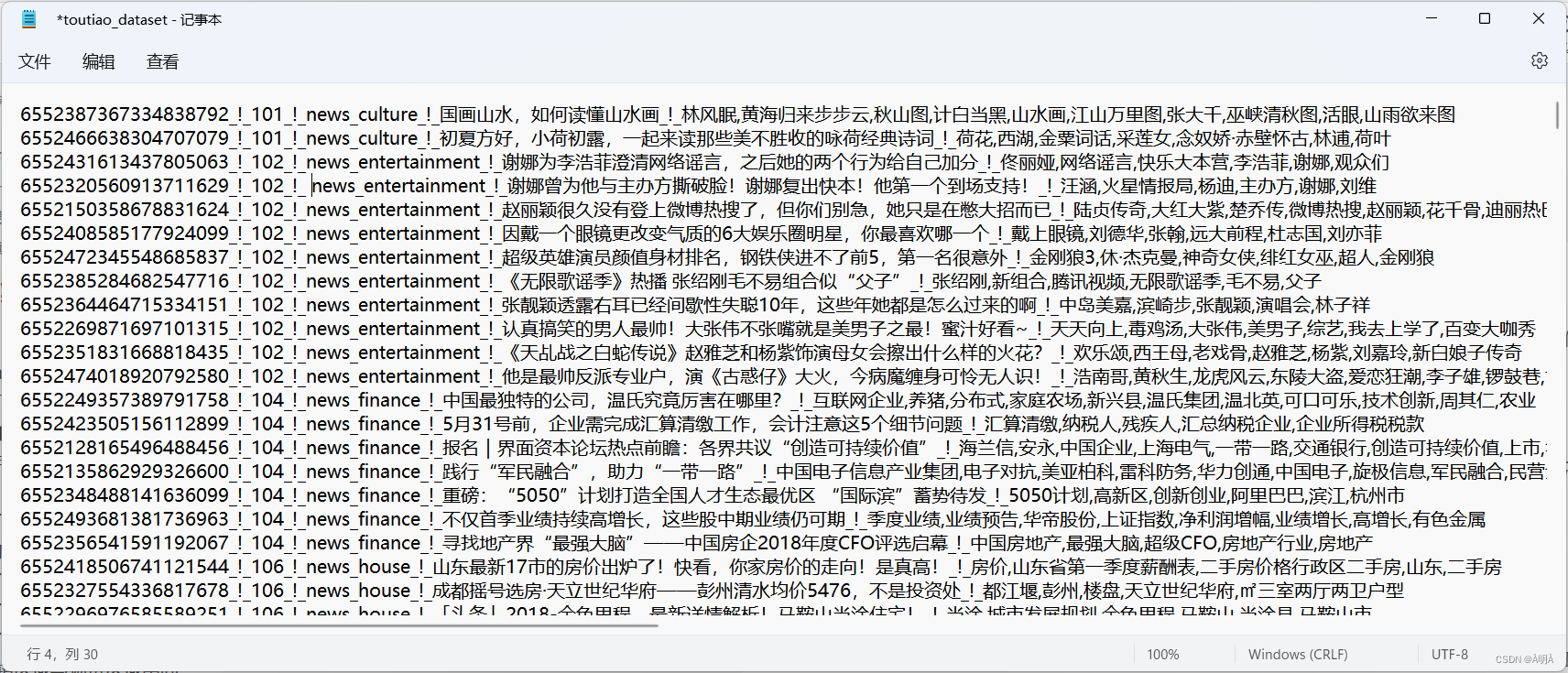
15个类别数据集
文章处理-数据获取
今日头条数据集处理
在数据集的TXT文档中的格式是以_!_来进行画划分的,根据题目条件,若要进行数据集的冗余信息的去除和保留新闻内容(关键词),就要先对_!_进行识别并划分
实现原理:python中的split()函数:
语法:str.split(sep=“”,maxsplit=n)
参数说明:
sep: 表示为分隔符,默认为空格,但是不能为空值。若字符串中没有分隔符,则把整个字符串作为>列表的一个元素。
maxsplit:表示分割次数
以下为函数实现:
def data_get():
#文件地址
filname = "D:/Course-data/toutiao_dataset.txt"
#文件格式
encoding = "utf-8"
#读入文件
with open(filname,encoding=encoding) as file:
#函数去除读入时的/n符号:strip()函数
data_list = [i.strip() for i in file.readlines()]
#建立保存txt文件的数据列表
data_id=[]
data_code=[]
data_size=[]
data_title=[]
data_key=[]
for k in data_list:
#通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list):split()函数
#sep指定分隔的字符,maxsplit限制分隔的次数为5次,即5列
#5列分别为新闻ID,分类code,类别,新闻字符串(仅含标题),新闻关键词。
#用append()函数将数据进行保存
t = k.split(sep="_!_",maxsplit=5)
data_id.append(t[0])
data_code.append(t[1])
data_size.append(t[2])
data_title.append(t[3])
data_key.append(t[4])
#将列表格式转化为dataframe格式
DATA_Title=pd.DataFrame(data_title,columns=["标题"])
DATA_Size=pd.DataFrame(data_size,columns=["类别"])
#通过agg函数对数据进行整合
DATA = pd.DataFrame()
DATA["标题"]=DATA_Title[["标题"]].agg(''.join,axis=1)
DATA["类别"]=DATA_Size[["类别"]].agg(''.join,axis=1)
return DATA
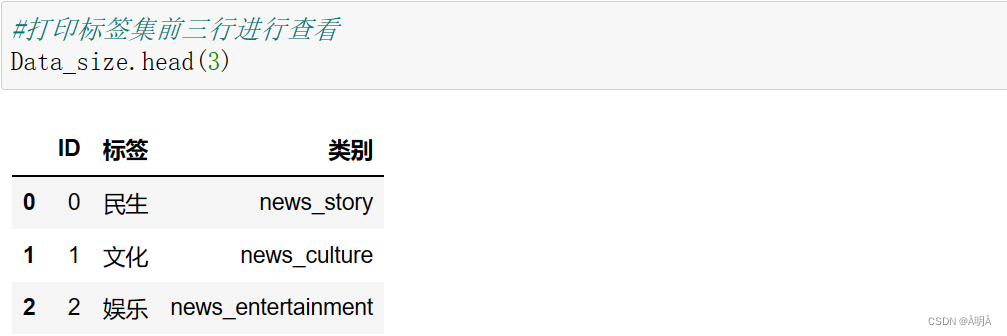
将数据集都入后,对标签文件进行读入:
"""
读入标签文件,建立对应的列表
"""
def Target():
#文件地址
filname = "D:/Course-data/toutiao_sizeset.txt"
#文件格式
encoding = "utf-8"
#读入文件
with open(filname,encoding=encoding) as file:
#函数去除读入时的/n符号:strip()函数
size_list = [i.strip() for i in file.readlines()]
#建立保存txt文件的数据列表
size_id=[]
size_code=[]
size_size=[]
size_target=[]
for k in size_list:
#通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list):split()函数
#sep指定分隔的字符,maxsplit限制分隔的次数为5次,即5列
#5列分别为新闻ID,分类code,类别,新闻字符串(仅含标题),新闻关键词。
#用append()函数将数据进行保存
t = k.split(sep=" ",maxsplit=4)
size_id.append(t[0])
size_code.append(t[1])
size_target.append(t[2])
size_size.append(t[3])
#将列表格式转化为dataframe格式
SIZE_ID = pd.DataFrame(size_id,columns=["ID"])
SIZE_TARGET = pd.DataFrame(size_target,columns=["标签"])
SIZE_SIZE = pd.DataFrame(size_size,columns=["类别"])
#通过agg函数对数据进行整合
SIZE = pd.DataFrame()
SIZE["ID"]=SIZE_ID[["ID"]].agg(''.join,axis=1)
SIZE["标签"]=SIZE_TARGET[["标签"]].agg(''.join,axis=1)
SIZE["类别"]=SIZE_SIZE[["类别"]].agg(''.join,axis=1)
return SIZE
训练集数据划分
将训练集数据按照8:1:1的比列进行划分:
但是由于数据是规则排列的,直接划分势必会导致数据集的不平衡。需要先进行随机的排列生成一个新的数据,在对该数据进行划分。
实现原理:对于获得的数据的索引index进行随机排列,在对索引进行重新建立,根据索引对于数据进行划分
"""
建立训练集,验证集,测试集
"""
def set_data(Data=data_get()):
Data_train = pd.DataFrame()
Data_val = pd.DataFrame()
Data_test = pd.DataFrame()
#将获取到的数据随机打乱
# 随机打乱索引
indexs = np.arange(Data.shape[0])
np.random.seed(2019) # 固定种子
np.random.shuffle(indexs)
#以8:1:1划分训练集,测试集,验证集
#通过生成的随机数充当索引
Data=Data.iloc[indexs]
#重新建立一遍索引
Data=Data.reset_index(drop=True)
Data_train = Data[0:int(8/10*len(Data))]
Data_val = Data[int(8/10*len(Data)):int(9/10*len(Data))]
Data_test = Data[int(9/10*len(Data)):int(len(Data))]
#对于已经分好的数据建立索引
Data_train=Data_train.reset_index(drop=True)
Data_val=Data_val.reset_index(drop=True)
Data_test=Data_test.reset_index(drop=True)
print("训练集",len(Data_train))
print("验证集",len(Data_val))
print("测试集",len(Data_test))
return Data_train,Data_val,Data_test
建立的数据如下所示:

训练数据冗余信息剔除
按照题目要求,需要仅保留新闻长度大于五的标题和类别
实现原理:对于所获得的训练集,验证集,测试集的标题进行遍历,对于其中的元素进行数量统计
保留数量大于五的类别:
"""
去除数据集中的冗余信息,仅保留新闻长度大于5的标题及类别
"""
def clean_more(Data):
print("长度处理前",len(Data))
Data_after=Data[Data["标题"].apply(lambda x: len(x)>5)]
#重新建立一遍索引
Data_after=Data_after.reset_index(drop=True)
print("长度处理后",len(Data_after))
return Data_after
随后的到处理结果:

可以看到训练集的部分信息被剔除
训练集+标签集数据获取结果
训练集
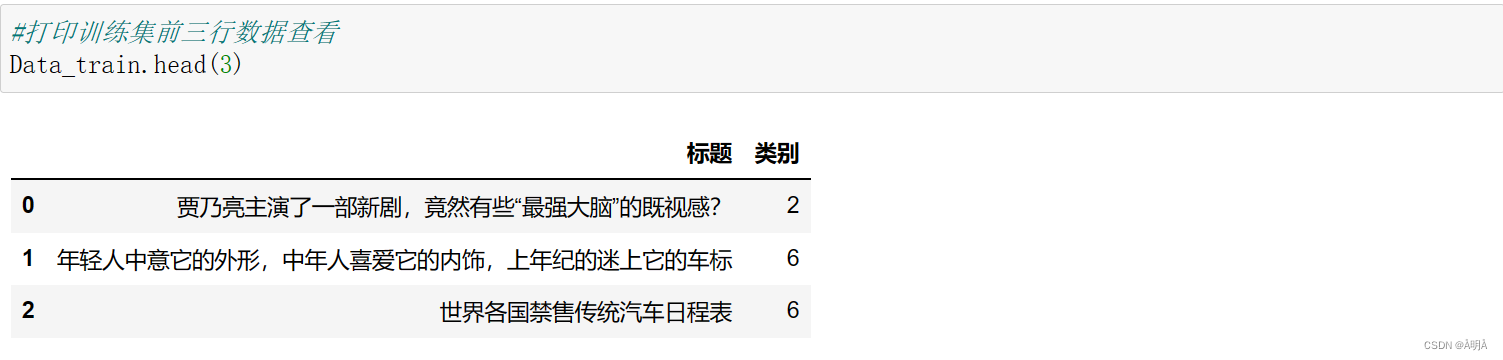
标签集
文章处理-数据清洗
为什么要进行数据清洗
数据清洗,也被称作数据处理,是在文本分类过程中的重要一步。通过数据清洗,可以将表中不正确,不相关,不完整的数据进行剔除,得到可以用于建立词典和词向量的数据集。
数据清洗过程-文本规范化
将文章中出现的符号、半角字符、全角字符和数字进行剔除,只保留我们需要的文本
实现原理:引入Unicode汉字编码的概念:
Unicode是一个很大的集合。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字”严”。
具体汉字对应编码可以参照Unicode中文字符查看
对于中文字符的Unicode,其范围在\u4E00—\u9FA5之间
After = []
for ago in Before:
if(ago >= u'\u4e00' and ago <= u'\u9fa5'):
After.append(ago)
基于以上原理,就可以将文本字符进行遍历,保留处于中文编码范围的字符
数据清洗过程-中文分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程
中文分词就是将连续的一段中文序列进行切分使其成为一个个单独的词
实现原理:中文分词库:jieba
jieba分词是国内使用人数最多的中文分词工具,在使用之前需要先对于jieba库进行引入操作:
pip install jieba
jieba工具分词时具有三种模式:精确模式,全模式,
精确模式:试图将句子最精确地切开,适合文本分析
全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
After = jieba.cut(Before,cut_all = False)
数据清洗过程-重复数据剔除
实现原理:通过建立列表对于每个分词后的词进行数量统计。统计后返回的值的key是只出现一次的值。那么将这些词进行保存就可以得到只出现一次的序列
After=[]
counts={}
for ago in Before:
counts[ago] = counts.get(ago,0)+1
items = list(counts.items())
for i in range(len(items)):
word, count = items[i]
After.append(word)
数据清洗过程-绘制云图进行分析
目的:通过云图直观的判断出部分相关度低的词,方便下一步的自定义停用词的建立
通过wordcloud库绘制词云图,其是对文本中出现频率较高的“关键词”予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主要关键词
原理:部分关键词虽然占据了较大的权重,但在文本分类过程中,这些词并不携带有有效信息,需要过滤
def wordcloud(Data):
reward_str = "".join(Data)
Data_wordcloud = WordCloud( background_color = "white",
max_words = 2000,
font_path ="D:\Course-data\simfang.ttf",
max_font_size = 50,
color_func=None,
random_state = 40,
).generate(reward_str)
plt.imshow(Data_wordcloud)
plt.axis('off')
#调用云图绘制函数
wordcloud(data_reward)
得到结果:比如图中的个就是冗余信息

数据清洗过程-停用词处理
停用词处理实际上就是把相关度高的词语进行保留,去除相关度低的词语的过程
停用词表的导入:在网络上搜索停用词表,便可以得到一个停用词库,下载后为TXT格式
自定义停用词:本篇采取了直接将自定义停用词手动添加到网络停用词表中
实现原理:对于目标数据集进行遍历,判断元素是否在停用词表中,True则去除
def stopwords_Customization(Before,stopwords):
After = []
for ago in Before:
if ago not in stopwords:
After.append(ago)
return After
def get_stopwords():
#保存停用词
stopwords = []
#文件地址
filname = "D:/Course-data/stopwords.txt"
#文件格式
encoding = "utf-8"
with open(filname,encoding=encoding) as file:
for stopword in file.readlines():
stopwords.append(stopword.strip())
return stopwords
#从文件获取停用词
stopwords = get_stopwords()
数据清洗过程-结果展示
通过上述的清洗过程的类调用,可以得到处理后的结果

文章处理-词典和词向量获取
词典获取
Gensim简介:
开源第三方Python工具包,主要用于从原始的非结构化文本抽取语义主题。
支持语料处理TF-IDF、word2vec等主题模型
核心:语料、稀疏向量和模型
原理:通过调用Gensim库的corpora中Dictionary()函数得到词典
corpora是gensim中的一个基本概念,是文档集的表现形式,也是后续进一步处理的基础。corpora其实是一种格式或者说约定,实际上二维矩阵。
使用dictionary = corpora.Dictionary(texts)生成词典。并可以使用save函数将词典持久化。
注意所传入的text文档是一个列表形式
"""
词典获取
"""
def save_dict(corpus):
#词典
dictionary = corpora.Dictionary(corpus)
#保存dictionary
savePath = r"D:/Course-data/mycorpus.dict"
dictionary.save(savePath) # 把字典保存起来,方便以后使用
#词典构建
save_dict(corpus)
词向量获取
题目要求需要获取Word2vec词向量
Word2Vec诞生于2013年,由Google开源问世,其是一款计算词向量的工具
Word2Vec工具其实是基于CBoW模型和Skip-gram模型的计算词向量的工具。
在python中Gensim工具箱,里面包含了Word2Vec
如果要安装Word2vec工具,需要先安装gcc
原理:
这里有大佬finley介绍了word2vec原理
在本篇中,我采取直接调用Word2vec库,进行词向量获取
Word2vec训练中的参数:
(1)sentences: 要分析的语料,可以是一个列表,或者从文件中遍历读出
(2)size=260: 词向量的维度。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
(3)window=5:即词向量上下文最大距离。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。推荐在[5,10]之间;
(4)iter=5: 随机梯度下降法中迭代的最大次数。对于大语料,可以增大这个值;
(5)min_count=5:需要计算词向量的最小词频。可以去掉一些生僻的低频词。如果是小语料,可以调低这个值;
(6)workers=3:多线程数;
(7)sg=0: 如果是0, 则是CBOW模型,是1则是Skip-Gram模型
(8)hs=0: 如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax
(9)negative=5:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间
(10)alpha=0.025: 在随机梯度下降法中迭代的初始步长
(11)min_alpha:最小的迭代步长值
代码实现:
def save_Word2c_model():
# 生成模型
model_CBOW = Word2Vec(sg=0,sentences = corpus, vector_size=260, window=5, min_count=5)
# 生成模型
model_Skip_Gram = Word2Vec(sg=1,sentences = corpus, vector_size=260, window=5, min_count=5)
# 字向量保存 保存路径 binary=False 以纯文本格式保存
#地址
savePath_CBOW = r"D:/Course-data/model_CBOW_word_data.vector"
#保存
model_CBOW.wv.save_word2vec_format(savePath_CBOW,binary=False)
#地址
save_path_Skip_Gram = r"D:/Course-data/model_Skip_Gram_word_data.vector"
#保存
model_Skip_Gram.wv.save_word2vec_format(save_path_Skip_Gram,binary=False)
# 模型保存
savePath_CBOW = r"D:/Course-data/model_CBOW.model"
savePath_Skip_Gram = r"D:/Course-data/model_Skip_Gram.model"
model_Skip_Gram.save(savePath_Skip_Gram)
model_CBOW.save(savePath_CBOW)
save_Word2c_model()
对于模型进行调用就可以得到词向量啦:
def recommend():
savePath_CBOW = r"D:/Course-data/model_CBOW.model"
savePath_Skip_Gram = r"D:/Course-data/model_Skip_Gram.model"
model_Skip_Gram = Word2Vec.load(savePath_Skip_Gram)
model_CBOW = Word2Vec.load(savePath_CBOW)
return model_Skip_Gram,model_CBOW
model_Skip_Gram,model_CBOW = recommend()
结果如下:

模型选择TextCnn
textcnn模型-模型介绍
将中文文本通过embedding层转换为词向量->通过不同的滑动窗口进行卷积处理->对卷积操作生成的特征矩阵使用最大池化处理->将池化后的特征矩阵进行拼接->通过全连接层进行输出
这里作者太阳花的小绿豆的博客TextCnn原理和使用对于TextCnn有着很详细的介绍
其结构是这样
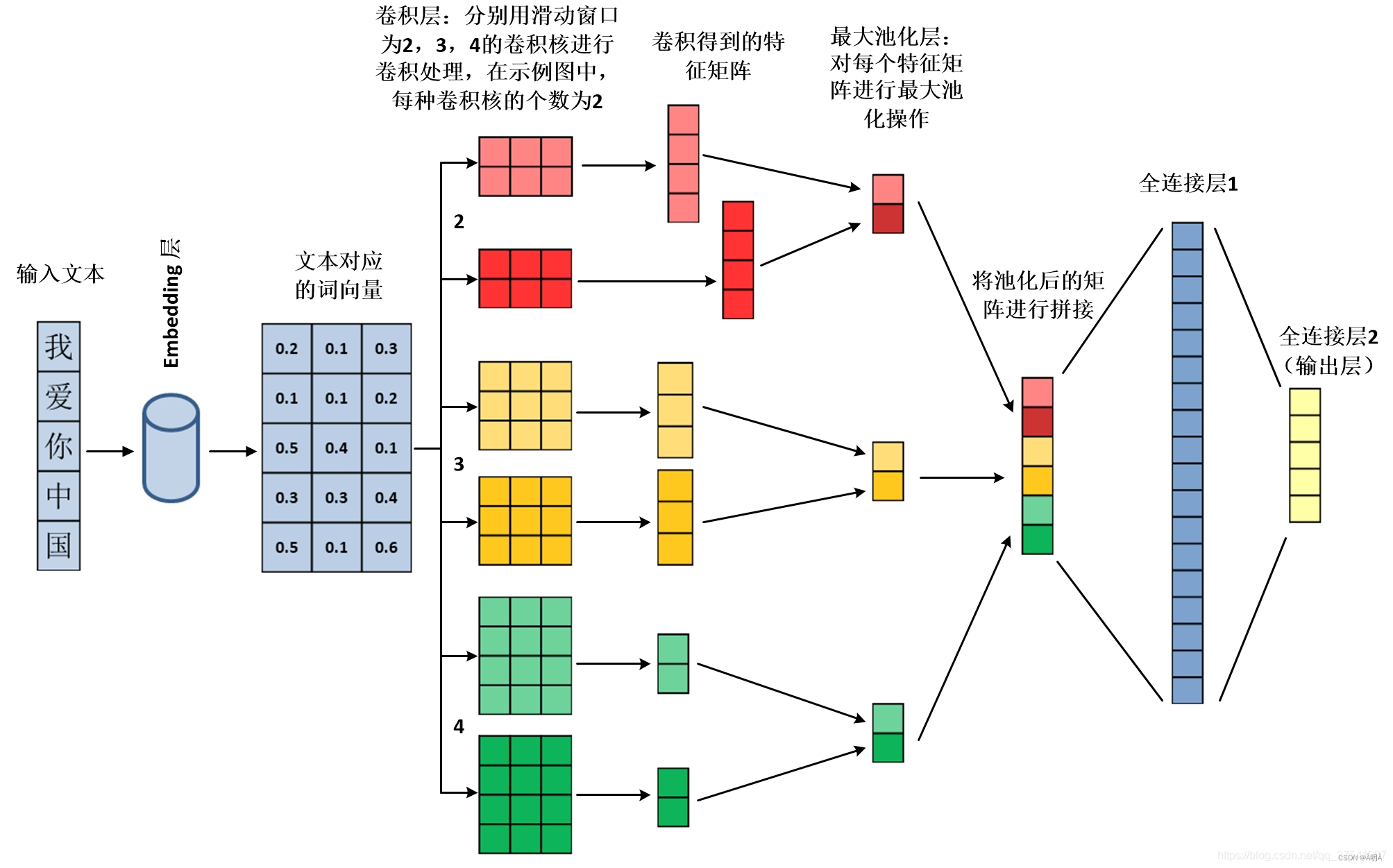
textcnn模型-词表获取:
原理:将词典中的key作为词表进行提取
def set_cocab(dictionary):
vocab_textcnn = set()
# 将词表写入本地vocab_textcnn.txt文件
pathfile = "D:/Course-data/vocab_textcnn.txt"
#将词典中的词作为词表进行保存
with open(pathfile,"w") as file:
for id,word in dictionary.items():
file.write(word)
file.write('\n')
set_cocab(dictionary)
textcnn模型-词典的构建
在实际过程中会出现没有在词表中的词,如果这时在使用该词表,就会出现错误
为了解决这种问题就需要对于词典进行调整
原理:当词不在词典中时,通常在词典中添加两个词:<pad>和<unk>
其中:pad表示文本长度不够的词,unk表示从未出现过的词
举例:比如 data = artificial intelligence 此时建立的词典是{artificial :0,intelligence=1}
此后有 data_other = artificial intelligence technology
如果上述词典被建立,则先前词典变为{artificial :0,intelligence=1,<pad>=2,<unk>=3}
那么后续数据输入时,词典是{artificial :0,intelligence=1,<unk>=3}(长度足够)
所以有代码实现:
def token_idx():
#输入文本序列长度
seq_length = 300
#词典地址
pathfile = "D:/Course-data/vocab_textcnn.txt"
#当词不在词典中时,通常在词典中添加两个词:<pad>和<unk>
#其中:pad表示文本长度不够的词,unk表示从未出现过的词
token2idx = {"[PAD]": 0, "[UNK]": 1}
with open(pathfile,"r") as words:
#enumerate()函数遍历词表
for index,line in enumerate(words):
token = line.strip()
token2idx[token] = index+2
return token2idx
textcnn模型-转化器构建
对于输入的文本当然不能是以纯文本形式进行训练,还需要对其进行转化,以变为模型所能够接受的词向量形式
原理:先进行分词,根据词典进行ID获取,以pad_sequences函数用于对序列进行填充。
代码实现:
def Preprocessor(Data,token2idx = token_idx()):
#输入文本序列长度
seq_length = 300
# 文本分词,并将词转换成相应的id, 最后不同长度的文本padding长统一长度,后面补0
idx_list = [[token2idx.get(word.strip(), token2idx["[UNK]"]) for word in jieba.cut(text)] for text in Data]
#pad_sequences函数用于对序列进行填充。参数sequences表示需要被填充的序列,参数maxlen表示填充后每一行最大的长度。
#padding = post从后面进行填充
idx_padding = pad_sequences(idx_list, seq_length, padding='post')
return idx_padding
textcnn模型-模型建立
def TextCnn(seq_length,vocab_size,embedding_dim,kernel_num,num_cla):
# 定义输入层
inputX = tf.keras.layers.Input(shape=(seq_length,))
# 嵌入层:单词表的长度;输出后向量长度;输入序列的长度
embOut = tf.keras.layers.Embedding(vocab_size, embedding_dim,input_length=seq_length,mask_zero=True)(inputX)
embOut= Lambda(lambda x: x, output_shape=lambda s: s)(embOut)
# 分别使用长度为3,4,5的词窗口去执行卷积, 接着进行最大池化处理
conv1 = tf.keras.layers.Conv1D(kernel_num, 3, padding='valid', strides=1, activation='relu')(embOut)
maxp1 = tf.keras.layers.MaxPool1D(pool_size=int(conv1.shape[1]))(conv1)
conv2 = tf.keras.layers.Conv1D(kernel_num, 4, padding='valid', strides=1, activation='relu')(embOut)
maxp2 = tf.keras.layers.MaxPool1D(pool_size=int(conv2.shape[1]))(conv2)
conv3 = tf.keras.layers.Conv1D(kernel_num, 5, padding='valid', strides=1, activation='relu')(embOut)
maxp3 = tf.keras.layers.MaxPool1D(pool_size=int(conv3.shape[1]))(conv3)
# 合并三个经过卷积和池化后的输出向量
combineCnn = tf.keras.layers.Concatenate(axis=-1)([maxp1, maxp2, maxp3])
# 扁平化
flatCnn = tf.keras.layers.Flatten()(combineCnn)
# 全连接层1,节点数为64
desen1 = tf.keras.layers.Dense(64)(flatCnn)
# 在全连接层1和2之间添加dropout减少训练过程中的过拟合,随机丢弃25%的结点值
dropout = tf.keras.layers.Dropout(0.25)(desen1)
# 为全连接层添加激活函数
densen1Relu = tf.keras.layers.ReLU()(dropout)
# 全连接层2(输出层)
predictY = tf.keras.layers.Dense(num_cla, activation='softmax')(densen1Relu)
# 指定模型的输入输出层
model = tf.keras.Model(inputs=inputX , outputs=predictY)
return model
textcnn-评估模型建立
def evaluate(x_test, y_test,model):
y_pred = model.predict(x_test)
y_pred = np.argmax(y_pred, axis=-1)
result = classification_report(y_test, y_pred, target_names=size)
print(result)
textcnn-模型编译和建立
#建立TextCnn模型
model_Adam = TextCnn(seq_length=300,vocab_size=45818,embedding_dim=55,kernel_num=64,num_cla=15)
# 指定loss的计算方法,设置优化器,编译模型
model_Adam.compile(loss='sparse_categorical_crossentropy',optimizer="Adam",metrics=['accuracy'])
可以使用model_Adam.summary()函数查看建立模型的结构
训练数据获取和处理
训练集,验证集,测试集处理
对于训练集,验证集,测试集。其标签是文本形式,在上文中有获取过Target()
的相关表,对表中数据进行遍历和替换,就可以得到满足要求的标签
再者,对于数据集,需要通过上文的转化器函数,转化为模型可以接受的词向量
代码实现
def get_train_data():
#数据处理
x_train = Preprocessor(X_train)
x_valid = Preprocessor(X_val)
x_test = Preprocessor(X_test)
#标签处理
y_train=Y_train.astype('int')
y_val=Y_val.astype('int')
y_test=Y_test.astype('int')
valid_data = None
valid_data = (x_valid, y_val)
return x_train,valid_data,x_test,y_train,y_test
训练模型
训练模型-基础模型训练
history_Adam=model_Adam.fit(x=x_train,y=y_train,validation_data= valid_data,
batch_size=64,epochs=5)
训练模型-训练结果

训练模型-训练评估
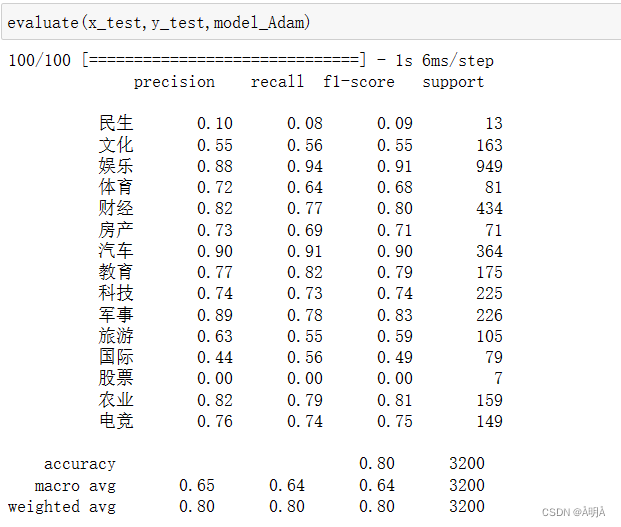
准确率达到80%满足题目要求
模型变更和Loss函数绘制
Loss函数绘制:
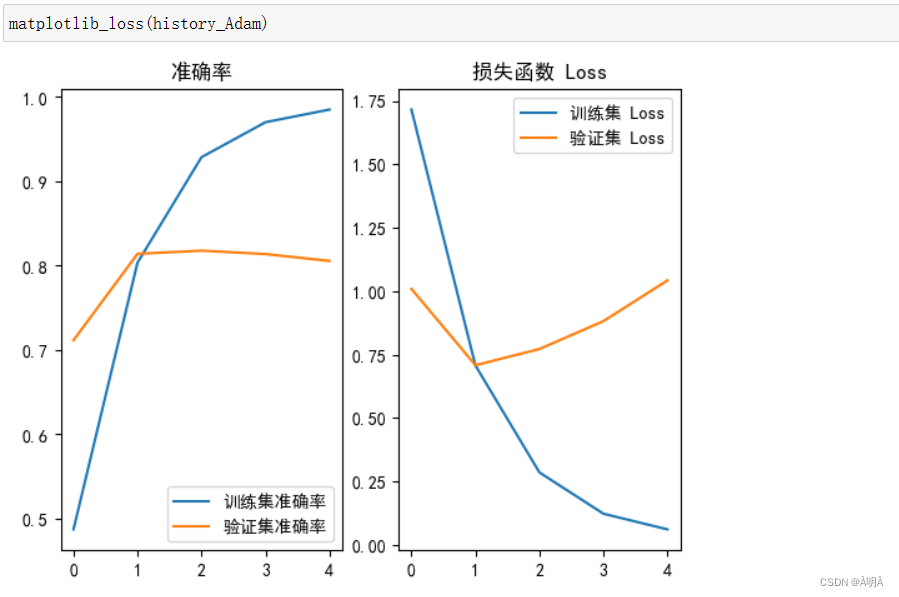
模型变更-学习率调整
原理:optimizers.Adam()的重新建立可以定义自己的学习率
Keras提供两种学习率适应方法,调整学习率需要在model.fit或者model.fit_generator中的callbacks回调函数中实现。
代码实现:
#自定义学习率更改函数
def change_rate(model,rate):
change = tf.keras.optimizers.Adam(lr=rate)
model.compile(loss='sparse_categorical_crossentropy',metrics=['accuracy'],optimizer=change)
# 定义一个学习率输出函数
def myScheduler_A(epoch):
# 获取在model.compile()中设置的学习率lr
lr = backend.get_value(model_A.optimizer.lr)
#输出
print("当前学习率",lr)
return backend.get_value(model_A.optimizer.lr)
# 定义一个学习率的回调函数
myReduce_A = LearningRateScheduler(myScheduler_A)
结果展示:
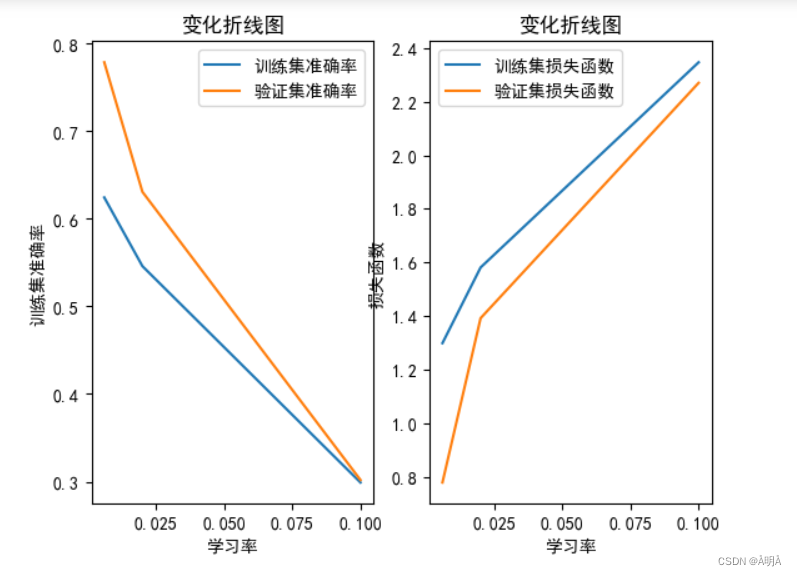
变化和原因分析略。
模型变更-优化器更改
RMSProp优化器
# 指定loss的计算方法,设置优化器,编译模型
RMSprop = tf.keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)
model_RMSprop.compile(loss='sparse_categorical_crossentropy',optimizer=RMSprop,metrics=['accuracy'])
SGD优化器
# 指定loss的计算方法,设置优化器,编译模型
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model_SGD.compile(loss='sparse_categorical_crossentropy',optimizer=sgd,metrics=['accuracy'])
模型训练
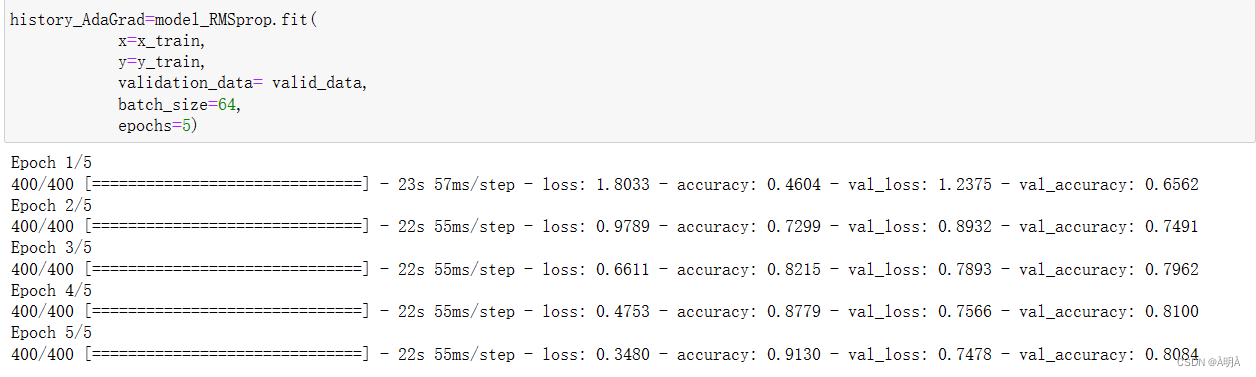
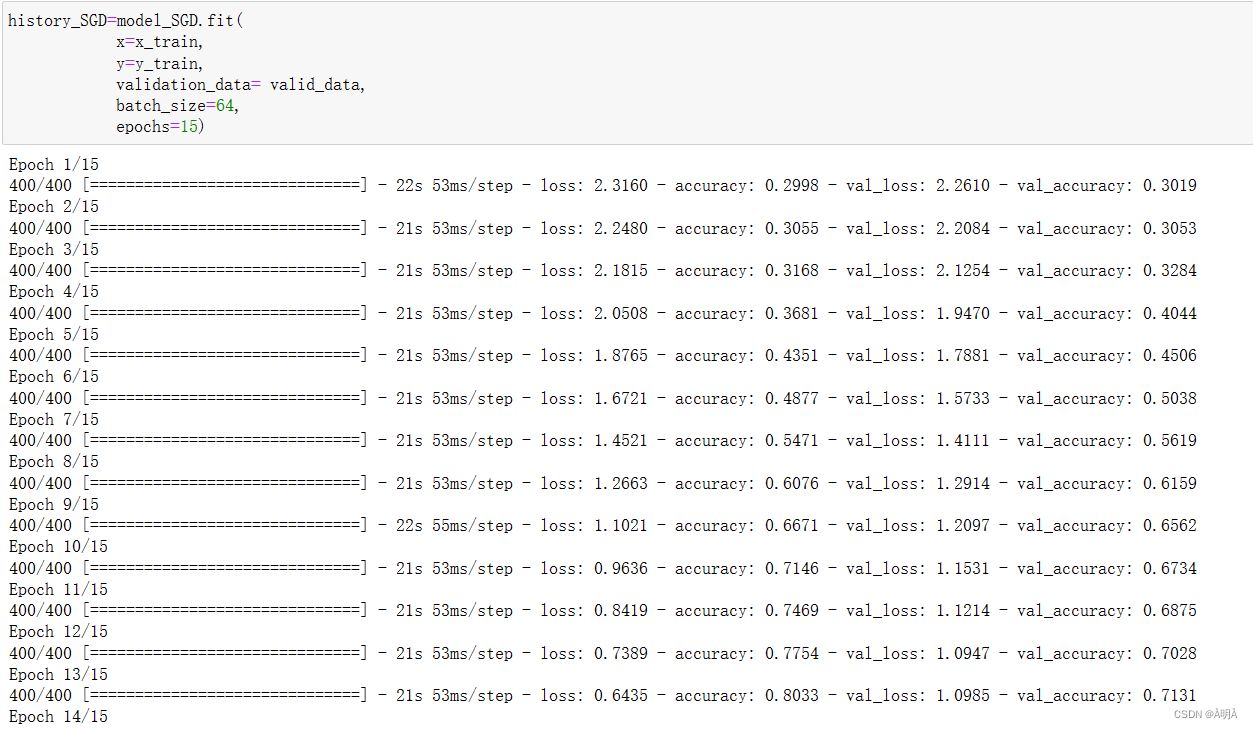
模型对比
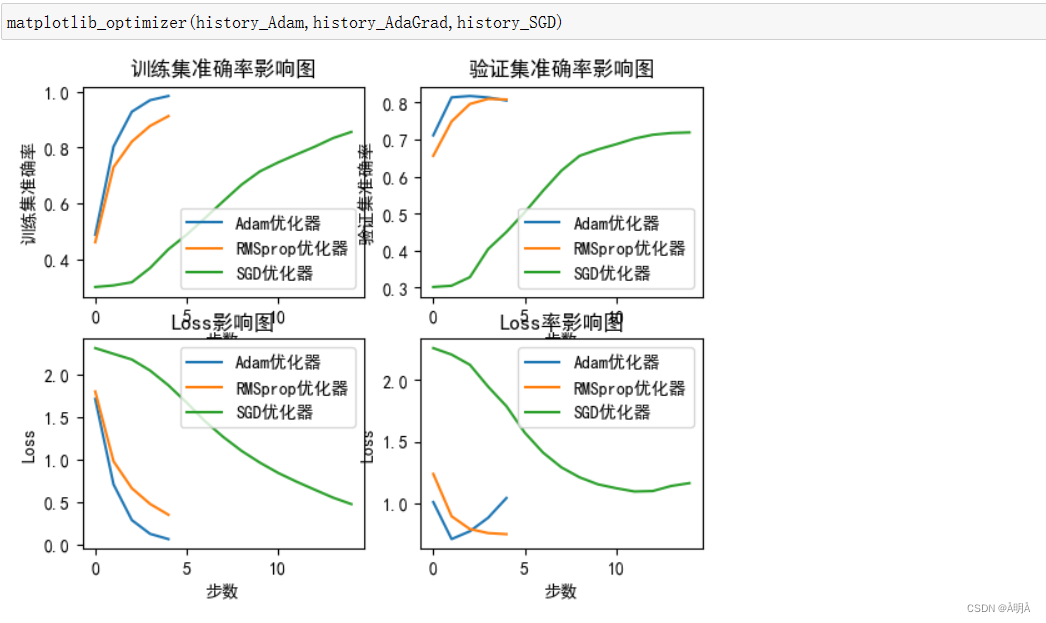
模型对比变化略
至此实验结束,课设所有条件已经满足
(新人的第一篇博客,如有错误还请包涵和指正)


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











