






———————————————————————————————————————————
简述Redis Cluster的原理及数据分布方式
———————————————————————————————————————————
Redis Cluster就是redis集群,他和一主多重的作用是不一样的。
一主多重主要是为了提高可用性:
当主节点出现故障,哨兵模式下从节点可以快速成为新的主节点进行请求的处理,不至于让整个redis不可用了。
redis集群的目的是分摊压力提高性能:
一主多重的情况下当数据量非常大的时候,内存可能会不够用,主从之间的复制也会更加消耗性能,什么RDB文件的生成、传输、载入啊很消耗内存、网络传送。redis集群就可以缓解这个问题,redis集群中是可以有多个主服务器进行写操作的,用户的数据会根据某种计算方式存储到不同的主服务器中,平摊只有一个主服务器的压力。集群只能使用0号数据库,其他模式情况下所有数据库都可以使用
原理:
1:成为集群
首先启动的3个redis都是独立的redis,启动的配置文件中cluster-enabled的值改为yes,因为启动的时候会根据这个值判断是否为集群模式。这时他们都处于一个只包含自己的集群当中,可以通过在某个redis客户端执行命令
CLUSTER MEET <ip> <端口号>
127.0.0.1:7000> CLUSTER MEET 127.0.0.1 7001
这个命令的意思是将节点7001添加到7000所在的集群,这样7000和7001就在一个集群里面了
127.0.0.1:7000> CLUSTER MEET 127.0.0.1 7002
这样3个redis 就在同一个集群中了。

2:启动集群
这个时候仅仅是集群中有3个redis,集群还没有上线,我们知道redis集群的功能是分摊压力,把数据的存储可以分开来,那么如何才能知道一个key应该被存储到哪一个redis当中呢?
给集群中的redis进行槽指派:集群中一共有16384个槽,别问为什么,多了不好少了也不好,这个数值够用就好了,现在需要做的是把16384个槽分配一下,redis1负责几到几,redis2负责几到几之类的。
命令:CLUSTER ADDSLOTS <slot> [slot ...]
例如:
127.0.0.1:7000> CLUSTER ADDSLOTS 0 1 2 3 4 ...5000 给节点7000分配槽0--5000
127.0.0.1:7001> CLUSTER ADDSLOTS 0 1 2 3 4 ...5000 给节点7001分配槽5001--10000
127.0.0.1:7002> CLUSTER ADDSLOTS 0 1 2 3 4 ...5000 给节点7002分配槽10000--16383
这样就分完了,但凡有一个槽没有被分配集群都不算是上线。因为插入的key到底是属于哪一个槽的算法是: CRC16(key) & 16383,有槽没有被分配redis就意味着有可能某个key找不到处理的redis,这肯定不行,当所有槽都被分配了集群才算是上线了,且一个槽有且仅会被指派为一个redis处理。
具体说哪个redis分的多哪个分的少,看redis配置啊,内存多的多分点,内存少的少分点,但是如果分布的过于不均,出现极大极小的情况,其效果和一主多从没什么大区别的。尽量均匀些。
3:集群中数据的处理
集群中每个redis都知道自己处理哪些槽,并且知道其他几个redis处理哪些槽。用的是指针数组的结构进行存储的,只需要O(1)时间复杂度就可以知道一个key属于哪个redis处理。
因此当我们在redis1上set了一个key时,当redis1发现这个key不应该属于自己处理的时候,通过计算会转向处理这个槽的redis,并且把命令传输过去。
中间还有些七七八八的,感觉这个题也就回这些就够了,大家自己精简一下哈。
———————————————————————————————————————————
Redis Cluster如何处理节点间的hash slot迁移与客户端重定向?
———————————————————————————————————————————
这一题我感觉应该是对上一题中的集群中数据的处理做详细的回答
前置知识
1:每个redis加入集群之后,这个redis都会和集群中的其他redis进行通信,是双向哪种A->B B->A,方便沟通,同步信息,为后面的重定向做准备,他们都知道对方的ip、端口号、runid之类的。
2:每个redis被指派槽之后都会告诉其他redis我负责哪些槽,其他收到这个信息的redis会把这信息记录在本地,方便到时候查找哪个槽属于哪个redis
1:计算键属于哪一个槽,通过CRC16(key) & 16383这个算法计算出该key应该属于0-16383之间的哪个槽
2:判断槽是否由当前节点处理,是则节点直接执行,不是则找出这个槽负责的节点信息,返回客户端MODE错误,指引客户端转向该槽的处理节点。

3:key值冲突:链地址法。当key1和key2计算出的槽点属于同一个时,会使用链地址法解决。

4:想要在某个节点中存储同类型数据 例如user数据
key1:{userInfo:1001}:name set {user_info}:name 张三
key2:{userInfo:1001}:age set {user_info}:age 28
key3:{userInfo:1001}:email set {user_info}:email xxx@gmail.com
就可以拥有如图效果

———————————————————————————————————————————
Redis的过期键删除策略是怎样的?
———————————————————————————————————————————
1:定时删除:通过使用定时器,当一个键到了过期时间立马进行删除
优点:对内存友好,已经过期的键不会再存在了,节省了内存
缺点:
- 对cpu不友好,在过期键比较多的情况下,删除过期键这一行为可能会占用相当一部分 CPU 时间,在内存不紧张但是 CPU 时间非常紧张的情况下,将 CPU 时间用在删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。
- 创建一个定时器需要用到 Redis 服务器中的时间事件,而当前时间事件的实现方式一无序链表,查找一个事件的时间复杂度为 O(M并不能高效地处理大量时间事件。让服务器创建大量的定时器,从而实现定时删除策略并不现实
2:惰性删除:当一个过期键被访问的时候才会被删除
优点:对cpu友好,程序只有取出键时才对键进行过期检查,并且仅删除这一个缉拿,不会花时间再其他不想关的键上
缺点:如果一个键过期很长时间了,又没有被访问,他可能永远也不会被删除,他的内存也不会被释放,这种情况甚至可以看成是一种内存泄露
3:定期删除:每隔一段时间进行一次过期键的删除,算是定时和惰性删除的折中
优点:
- 每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
- 通过定期删除过期键,定期删除策略有效地减少了因为过期键而带来的内存浪费。
缺点:
- 如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时
删除策略,以至于将 CPU 时间过多地消耗在删除过期键上面。- 如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除策
略一样,出现浪费内存的情况。如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行的时长和频率
———————————————————————————————————————————
如何避免Redis内存碎片?了解Redis的内存管理机制吗?
———————————————————————————————————————————
为何产生?
- 删除操作:当从Redis中删除键值对后,可能会留下未被充分利用的小内存块,这些小内存块就是所谓的内存碎片。由于这些小内存块大小不一,新的存储需求可能无法得到满足,从而导致内存使用效率降低。
- 数据动态调整:字符串、哈希表等数据结构在增长时,如果超出了初始分配的空间,Redis会重新分配一块更大的内存,并把旧数据复制到新的空间,然后释放旧空间。频繁的这类操作会导致不断有大的内存块被分配,而留下的小碎片难以被有效利用。
- 过期键清理与主动淘汰:当键因过期被清除时,其占用的内存并不会直接返回给操作系统,而是由Redis的内存管理器处理。虽然这提高了内存利用率,但也可能导致未被利用的内存累积,形成内存碎片。
- 内存不足的淘汰策略:在内存不足的情况下,Redis会根据设置的淘汰策略(如LRU、LFU)移除部分数据。如果这些参数设置不当,可能会导致内存碎片问题加剧。
如何避免?
嘻嘻避免不了呢~,多少肯定是会有的,只能减少碎片以及清理碎片
- 配置优化与策略选择:调整
maxmemory_policy,合理置maxmemory_samples- 碎片整理(Defragmentation):重启 Redis 实例、使用
MEMORY PURGE命令- 数据结构与编码优化:选择紧凑的数据结构,如set,list。避免过度使用
incr、decr等可能导致字符串动态增长的操作- 升级到 Redis 6.0 及以上版本:Redis 6.0 引入了jemalloc 5作为新的内存分配器,默认启用 tcache 功能,能够更高效地处理小对象分配,从而降低内存碎片。同时,jemalloc 5还提供了实验性的内存压缩功能,有助于进一步减少内存碎片。
Redis的LRU(Least Recently Used) 算法是如何实现的?
LRU算法指的是删除最近最少使用的对象,是内存回收的机制之一。
redis的对象结构中有一个lru属性,长度为24bit,记录的是该对象最近一次被命令程序访问的时间戳,当内存不足需要淘汰掉部分的key时候,取lru时间戳最小的值进行删除,因为该key上一次访问时间距离当前时间最长。
redis的该算法是一个近似LRU算法。因为LRU的淘汰是再全部的数据中进行比较,而redis的根据maxmemory_samples的数值大小取样本的。maxmemory_samples默认为5,因为redis存储的数据量是比较大的,如果全部进行比较的话肯定对redis的性能有很大的影响。
所以当进行redis的lru算法进行淘汰的时候,redis首先是取出maxmemory_samples大小数量的key,比较他们的lru属性,取最小的进行淘汰,如果淘汰之后内存依然不足,那么重复这个动作。直到内存足够插入新数据。因此不是完完全全准确的淘汰掉最近最不经常使用的key,但是总体的准确度也可以得到保证。
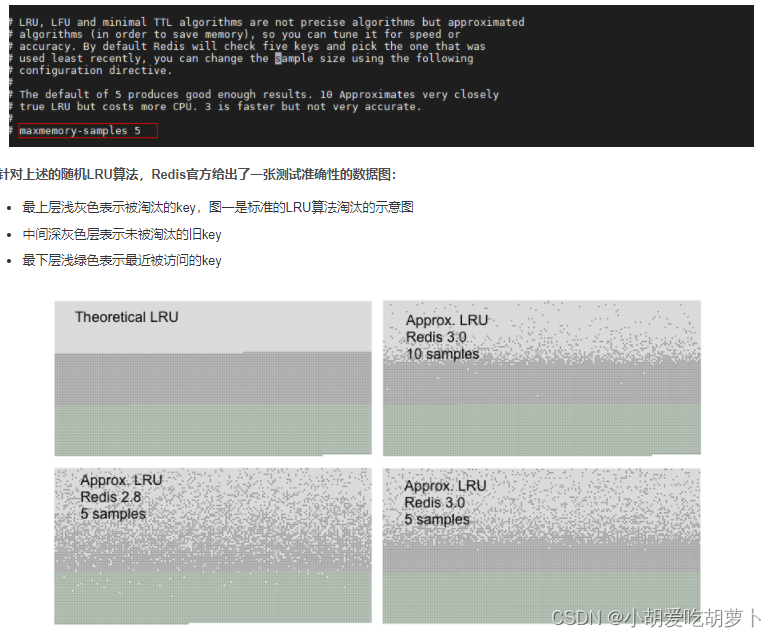
在Redis 3.0 maxmemory_samples设置为10的时候,Redis的近似LRU算法已经非常的接近真实LRU算法了,但是显然maxmemory_samples设置为10比maxmemory_samples 设置为5要更加消耗CPU计算时间,因为每次采样的样本数据增大,计算时间也会增加。
Redis3.0的LRU比Redis2.8的LRU算法更加准确,是因为Redis3.0增加了一个与maxmemory_samples相同大小的淘汰池,每次淘汰key的时候,先与淘汰池中等待被淘汰的key进行比较,最后淘汰掉最老旧的key,其实就是被选中淘汰的key放到一起再比较一下,淘汰其中最旧的。当maxmemory_samples足够大时,redis的LRU算法其实就是真正的LRU算法。
存在的问题:
LRU算法看似比较好用,但是也存在不合理的地方,比如A和B两个key,在发生淘汰时的前一个小时前同一时刻添加到Redis,A在前49分钟被访问了1000次,但是后11分钟没有被访问;B在这一个小时内仅仅第59分钟被访问了1次;此时如果使用LRU算法,如果A、B均被Redis采样选中,A将会被淘汰很显然这个是不合理的。针对这种情况Redis 4.0添加了LFU算法,(Least frequently used) 最不经常使用,这种算法比LRU更加合理,这里不介绍 ,看我之后写不写吧。
———————————————————————————————————————————
Redis如何进行内存淘汰(maxmemory-policy)
———————————————————————————————————————————
redis是基于内存的,当内存的使用达到了redis拥有的最大内存的时候,需要redis 根据某种策略进行数据的删除,这就是redis的内存淘汰策略。
redis的内存淘汰策略总共有8种:
noeviction(默认策略): 不会删除任何数据,拒绝所有写入操作并返回客户端错误消息(error)OOM command not allowed when used memory,此时 Redis 只响应删和读操作;allkeys-lru: 从所有 key 中使用 LRU 算法进行淘汰(LRU 算法:最近最少使用算法);allkeys-lfu: 从所有 key 中使用 LFU 算法进行淘汰(LFU 算法:最不常用算法,根据使用频率计算,4.0 版本新增);volatile-lru: 从设置了过期时间的 key 中使用 LRU 算法进行淘汰;volatile-lfu: 从设置了过期时间的 key 中使用 LFU 算法进行淘汰;allkeys-random: 从所有 key 中随机淘汰数据;volatile-random: 从设置了过期时间的 key 中随机淘汰数据;volatile-ttl: 在设置了过期时间的key中,淘汰过期时间剩余最短的。
关于内存淘汰的几个配置
maxmemory:redis的最大内存,当内存达到这个数值的时候根据策略进行内存淘汰。
maxmemory-policy:内存的淘汰策略
均可以通过命令 config get xxx进行查看 可以通过命令config set xxx value 进行临时的修改,重启后失效,要永久实现的话再redis.conf文件中进行修改
———————————————————————————————————————————
Redis如何实现分布式锁? 使用哪种数据结构?
———————————————————————————————————————————
使用命令:setnx xxx 命令,如果不存在则插入 如果存在则不插入。因为redis的命令执行是单线程的,所以不存在两个人同时返回成功。
使用的数据结构是:redis_string 简单动态字符串
关于锁的释放问题,要么服务运行之后删除锁 ,要么设置过期时间让redis过期删除去释放锁。如果锁一直没有被释放,那么就会导致死锁
- 不设置过期时间,运行完毕删除:服务A获取锁,在运行完毕之后删除锁,那么当服务A因为某些原因(服务A宕机、出错)发生了故障,导致锁一直没有被释放就会造成死锁。可以设置键过期时间,超过这个时间即给key删除掉。
- 运行完毕删除+设置过期时间:假如服务A加锁成功,锁会在10s后自动释放,但由于业务复杂,执行时间过长,10s内还没执行完,此时锁已经被redis自动释放掉了。此时服务B就重新获取到了该锁,服务B开始执行他的业务,服务A在执行到第12s的时候执行完了,那么服务A会去释放锁,则此时释放的却是服务B刚获取到的锁,虽然没有了死锁的问题,但是会有锁过期和释放其他服务锁的问题,使用redisson的watch dog机制解决。
- 一主多从情况:以上都是基于单服务器的情况,还有redis一主多从的情况下,当服务A在master加锁成功,但是这个时候master并没有把数据同步到slave中,由于网络或者其他原因导致这个时候master节点被认为宕机了,需要从slave中选择一个新的master ,这个新的master中并没有服务A的锁信息。这样其他的服务就可以继续获取锁了。解决办法是redLock,Redlock 的方案官网解释: 既然主从架构有问题, 那就部署多个主库实例.
———————————————————————————————————————————
解释Redis管道(Pipeline) 的作用及使用场景?
———————————————————————————————————————————
Redis管道(Pipeline)其实就是把多个命令一次性传送给redis,redis执行之后将这些命令的执行结果一次返回给客户端,这么做的好处是提升redis的性能。
redis客户端和redis服务端之间的连接是需要时间的,建立socket,阻塞模式等待服务的返回,服务端需要执行然后返回,如果有多个命令需要同时执行,那么客户端和服务端之间就需要进行多次的连接-返回操作。如果把多个命令打包到管道(Pipeline)中一次性发送给redis服务端,服务端一次性返回结果,这样仅需要建立一次连接即可,减少I/O网络开销、往返时间。提高redis的性能
Redis管道(Pipeline) 使用场景:你需要同时执行多个命令,且这些命令的返回值结果没有依赖关系。
例如:项目上线新功能需要初始化一批缓存、删除某些大量存在而不再使用的key。
使用Redis管道需要注意的点:
1:redis管道有大小限制,虽然命令是数量没有限制,但是输入缓冲区是有限制的,超过这个限制,命令将不会被执行,并且连接会被服务器端断开。
2:如果管道的数据过多可能会导致客户端的等待时间过长,导致网络阻塞,分批执行,不要一把梭哈,造成不必须要的事故
———————————————————————————————————————————
Redis事务的特点是什么?与传统数据库事务有何不同?
———————————————————————————————————————————
事务的四大特性:原子性、一致性、隔离性、持久性
redis通过MULTI、EXEC、WATCH等命令来实现事务功能,MULTI表示是事务的开始 ,EXEC表示事务的执行,再开始到执行过程中的命令会被维护在redis的一个事务队列当中,以一个先进先出的模式执行。而WATCH命令用于监视某个key,当在事务当中有对被watch监视的key进行更新时,该事务会被拒绝。
redis事务与传统数据库的区别是传统数据库有回滚操作,而redis事务没有回滚操作,当事务当中某个命令发生了错误,reids会继续执行后面的命令,而不会终止。而传统数据库事务是有出错即回滚机制的。
———————————————————————————————————————————
Redis的WATCH命令在事务中的作用是什么?
———————————————————————————————————————————
redis 的watch命令用于监视某个key值。
redis维护了一个监视key的字典,下图中表示有客户端c1和客户端c2监视着name这个key,客户端c1结构中有一个属性为redis_dirty_cas,当监视的key值被修改了,那么监视key值的所有客户端的redis_dirty_cas被打开,客户端执行事务时,redis会判断,该客户端的redis_dirty_cas是否被打开,如果被打开了则会拒绝执行客户端的本次事务。以此来保证事务执行前的一致性。
WATCH命令需要在MULTI命令开启事务之前使用,且一般都是这么做的,WATCH命令的效果持续到EXEC或DISCARD命令执行为止,也就是要么事务执行,要么取消WATCH效果才会失效

Redis的WATCH命令用于监视一个或多个键,确保事务执行前的一致性
———————————————————————————————————————————
如何通过Redis实现延时队列?
———————————————————————————————————————————
1:redis可以进行key的过期回调,注释掉notify-keyspace-events Ex 这个配置,然后新建一个key国过期回调处理类继承KeyExpirationEventMessageListener类实现父类方法,但是不能多部署,多部署重复操作了,其次项目重启会有概率丢失某些数据
2:利用redis的Zset命令实现
虽然可以,但是都有些问题,完全没有这么做的必要!!用mq吧。
———————————————————————————————————————————
如何使用Redis构建排行榜系统?
———————————————————————————————————————————
利用redis的Zset数据结构
场景:构建一个排行榜系统,用户根据word数量进行排序,如果word相同的,再以其today_study_time进行排序。
redis构建排行榜系统的主要难点在于你的score要如何根据你的需求进行排列,
score:word(string) + today_study_time (string) 之后在转int
例如:"259"+"124"="259124" 转int = 259124,如果有word相同 而today_study_time不同,通过这种score就能判断出其排序情况,当然再复杂一些可以规定在score中word和today_study_time占用多少位 比如word最多到10000 那么可以规定 word占用前6位,低位补0,word最多到100 那么可以规定 word占用后4位,高位补0。当word=259而today_study_time = 25则score为"259000"+"025"="259000025" 转int = 259000025。这么做当你获取该分数时,可以判断出其word值和today_study_time值。
添加:
Zadd range zhangshan 259000025
查询排行榜中zhangshan 的分数:
Zscore range zhangshan
———————————————————————————————————————————
如何使用Redis进行缓存击穿、缓存雪崩、缓存穿透的防范?
———————————————————————————————————————————
缓存穿透
缓存穿透是指查询一个不存在的数据,由于缓存中也没有,所以每次都会去数据库查询,导致数据库压力增大。
解决办法:
- 对于查询不存在的数据,可以将查询结果为null的数据也缓存起来,并设置一个较短的过期时间。
- 使用布隆过滤器
缓存击穿
缓存击穿是指某个key非常热门,访问非常频繁,当这个key在缓存中失效的瞬间,大量的请求直接打到了数据库上,造成数据库短时间内压力过大。
解决办法:
- 设置热点数据永不过期,或者设置一个较长的过期时间
- 使用互斥锁,当缓存失效时,只允许一个线程去数据库查询数据并重新缓存,其他线程等待。

缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决办法:
- 设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
- 使用互斥锁,当缓存失效时,只允许一个线程去数据库查询数据并重新缓存,其他线程等待。
- 使用双重缓存,当主缓存层发生雪崩时,可以使用备份缓存层来处理请求,防止直接打到数据库上
双重缓存
对同一数据设置两个缓存,一个是主缓存,一个是副缓存,副缓存的过期时间比主缓存要长,当主缓存失效,进程查询数据库时候,获得锁的查询数据库并且更新主缓存,没有获得锁的进程查询副缓存直接返回,就不存在进程等待获取锁了。
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存。
如果不进行预热, 那么 Redis 初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
缓存预热的操作方法
数据量不大的时候,工程启动的时候进行加载缓存动作;
数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
数据量太大的时候,优先保证热点数据进行提前加载到缓存。
缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
———————————————————————————————————————————
Redis的内存优化措施有哪些?
———————————————————————————————————————————
-
合理设置数据结构:根据存储数据的特点选择合适的数据结构,例如使用紧凑的字符串表示数字或短文本,使用集合或有序集合代替列表等。
-
避免过度碎片化:定期进行内存重分配和碎片整理,以减少内存浪费。可以通过执行
BGSAVE命令来触发这些操作。 -
控制键的数量:避免创建过多的键,因为每个键都会消耗额外的内存。可以使用命名空间和合适的键名规则来组织和管理键。
-
使用哈希槽:将数据分散到多个Redis实例中,通过分片技术将数据分布到不同的节点上,以减少单个实例的内存压力。
-
利用压缩:对于大的数据对象,如大字符串或大数据集合,可以使用压缩算法来减少内存占用。
-
限制过期时间:合理设置数据的过期时间,以自动清理不再需要的数据,释放内存空间。
-
监控和分析:定期监控Redis的内存使用情况,并使用工具如
INFO命令或第三方工具来分析和优化内存使用。 -
配置调整:根据实际需求调整Redis的配置参数,如最大内存限制、数据淘汰策略等。
-
使用内存友好的数据类型:对于特定的应用场景,选择更内存友好的数据类型,如使用位图(Bitmaps)或稀疏集合(Sparse Sets)来代替传统的字符串或列表。
———————————————————————————————————————————
如何监控Redis的性能指标?列举常用工具和指标
———————————————————————————————————————————
性能指标
| Name | Description |
| latency | Redis响应一个请求的时间 |
| instantaneous_ops_per_sec | 平均每秒处理请求总数 |
| hi rate(calculated) | 缓存命中率(计算出来的) |
内存指标
| Name | Description |
| used_memory | 已使用内存 |
| mem_fragmentation_ratio | 内存碎片率 |
| evicted_keys | 由于最大内存限制被移除的key的数量 |
| blocked_clients | 由于BLPOP,BRPOP,or BRPOPLPUSH而备阻塞的客户端 |
基本活动指标
| Name | Description |
| connected_clients | 客户端连接数 |
| conected_laves | slave数量 |
| master_last_io_seconds_ago | 最近一次主从交互之后的秒数 |
| keyspace | 数据库中的key值总数 |
持久性指标
| Name | Description |
| rdb_last_save_time | 最后一次持久化保存磁盘的时间戳 |
| db_changes_sice_last_save | 最后一次持久化以来数据库的更改数 |
错误指标
| Name | Description |
| rejected_connections | 由于达到maxclient限制而被拒绝的连接数 |
| keyspace_misses | key值查找失败(没有命中)次数 |
| master_link_down_since_seconds | 主从断开的持续时间(以秒为单位) |
监控方式
-
redis-benchmark
-
redis-stat
-
redis-faina
-
redislive
-
redis-cli
-
monitor
-
showlog















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









