







内容简介
在数据处理和分析领域,经常需要根据特定的属性(如供应商、客户名称等)将数据分组,并分别输出到不同的Excel工作表中。本文介绍的Python脚本利用pandas和openpyxl库实现了这一功能。该脚本读取一个包含多个供应商数据的Excel文件,根据供应商名称将数据分组,并将每个供应商的数据写入一个新的工作表中。此外,脚本还调整了列宽和行高以适应内容,并复制了原始工作表的样式。最后,所有分组后的工作表被保存到一个新的Excel文件中。这种方法不仅提高了数据处理的效率,还使得结果更加清晰和易于管理。
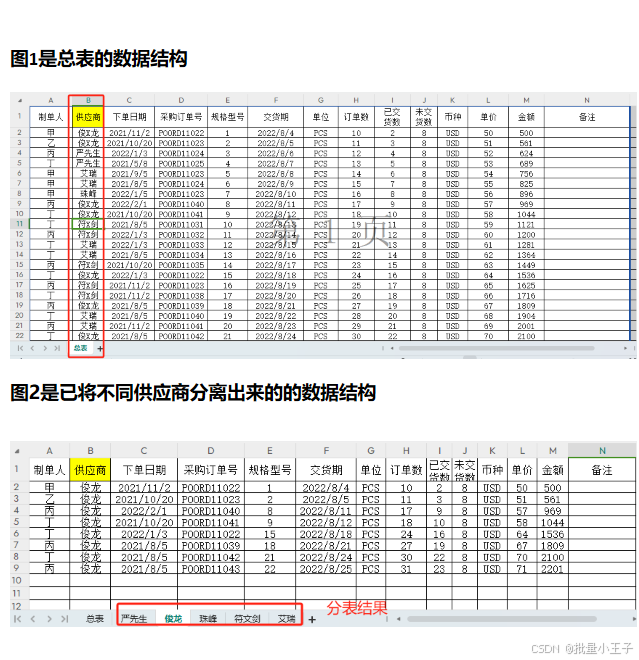
分步骤解说代码
步骤1:导入必要的库
import os
import sys
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl.utils import get_column_letter
from openpyxl.styles import Alignment, Font, Border, Side, PatternFill
from openpyxl.utils.cell import coordinate_from_string
from openpyxl.worksheet.dimensions import ColumnDimension, RowDimension
from pathlib import Path
from copy import copy
首先,我们导入了处理文件路径、数据操作和Excel文件操作所需的库。
步骤2:定义读取Excel文件的函数
def read_excel_file(file_path):
return pd.read_excel(file_path, engine='openpyxl')
定义了一个函数read_excel_file,使用pandas的read_excel函数来读取Excel文件。
步骤3:定义创建输出目录的函数
def create_output_directory(directory):
directory.mkdir(parents=True, exist_ok=True)
定义了一个函数create_output_directory,用于创建输出目录,如果目录已存在则不会抛出异常。
步骤4:定义调整列宽的函数
def adjust_column_width(ws):
for column_cells in ws.columns:
length = max(len(str(cell.value)) for cell in column_cells)
ws.column_dimensions[get_column_letter(column_cells[0].column)].width = length + 2
定义了一个函数adjust_column_width,用于遍历工作表的所有列,并根据列中内容的最大长度调整列宽。
步骤5:定义调整行高的函数
def adjust_row_height(ws):
for row in ws.iter_rows():
max_height = max(len(str(cell.value).split('\n')) * 12 for cell in row)
ws.row_dimensions[row[0].row].height = max_height
定义了一个函数adjust_row_height,用于遍历工作表的所有行,并根据行中内容的最大行数调整行高。
步骤6:定义复制单元格样式的函数
def copy_cell_styles(source_ws, target_ws):
for row in source_ws.iter_rows():
for cell in row:
target_cell = target_ws[cell.coordinate]
if cell.has_style:
target_cell.font = copy(cell.font)
target_cell.border = copy(cell.border)
target_cell.fill = copy(cell.fill)
target_cell.number_format = copy(cell.number_format)
target_cell.protection = copy(cell.protection)
target_cell.alignment = copy(cell.alignment)
定义了一个函数copy_cell_styles,用于复制原始工作表中的单元格样式到目标工作表。
步骤7:定义将分组数据写入Excel的函数
def write_groups_to_excel(groups, input_file, output_file):
try:
wb = load_workbook(input_file)
original_ws = wb.active
for sheet_name, group in groups.items():
ws = wb.create_sheet(title=sheet_name)
for r in dataframe_to_rows(group, index=False, header=True):
ws.append(r)
adjust_column_width(ws)
adjust_row_height(ws)
copy_cell_styles(original_ws, ws)
wb.save(output_file)
print(f"已保存所有数据到 {output_file}")
except Exception as e:
print(f"写入文件 {output_file} 时发生错误: {e}")
定义了一个函数write_groups_to_excel,用于将分组后的数据写入新的Excel工作表,并保存工作簿。
步骤8:从命令行参数获取文件路径
if len(sys.argv) > 1:
file_path = sys.argv[1]
else:
file_path = '总表.xlsx' # 默认路径
从命令行参数获取文件路径,如果没有提供则使用默认路径。
步骤9:确保文件路径的安全性
base_dir = os.path.dirname(os.path.abspath(__file__))
safe_file_path = os.path.join(base_dir, file_path)
确保文件路径的安全性,避免路径遍历攻击。
步骤10:检查文件是否存在
if not Path(safe_file_path).exists():
raise FileNotFoundError(f"文件不存在: {safe_file_path}")
检查文件是否存在,如果不存在则抛出异常。
步骤11:创建输出目录
output_dir = Path('output')
create_output_directory(output_dir)
创建输出目录。
步骤12:一次性读取Excel文件
df = read_excel_file(safe_file_path)
一次性读取Excel文件到pandas DataFrame。
步骤13:分组处理
data_dict = {}
for customer_name, group in df.groupby(customer_column):
sheet_name = customer_name.replace(' ', '_')
data_dict[sheet_name] = group
根据供应商名称分组处理数据,并将每个分组存储在字典中。
步骤14:写入所有分组数据到同一个Excel文件
output_file = output_dir / '所有分表.xlsx'
write_groups_to_excel(data_dict, safe_file_path, output_file)
将所有分组数据写入同一个Excel文件。
完整代码
import os
import sys
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl.utils import get_column_letter
from openpyxl.styles import Alignment, Font, Border, Side, PatternFill
from openpyxl.utils.cell import coordinate_from_string
from openpyxl.worksheet.dimensions import ColumnDimension, RowDimension
from pathlib import Path
from copy import copy
def read_excel_file(file_path):
return pd.read_excel(file_path, engine='openpyxl')
def create_output_directory(directory):
directory.mkdir(parents=True, exist_ok=True)
def adjust_column_width(ws):
for column_cells in ws.columns:
length = max(len(str(cell.value)) for cell in column_cells)
ws.column_dimensions[get_column_letter(column_cells[0].column)].width = length + 2
def adjust_row_height(ws):
for row in ws.iter_rows():
max_height = max(len(str(cell.value).split('\n')) * 12 for cell in row)
ws.row_dimensions[row[0].row].height = max_height
def copy_cell_styles(source_ws, target_ws):
for row in source_ws.iter_rows():
for cell in row:
target_cell = target_ws[cell.coordinate]
if cell.has_style:
target_cell.font = copy(cell.font)
target_cell.border = copy(cell.border)
target_cell.fill = copy(cell.fill)
target_cell.number_format = copy(cell.number_format)
target_cell.protection = copy(cell.protection)
target_cell.alignment = copy(cell.alignment)
def write_groups_to_excel(groups, input_file, output_file):
try:
wb = load_workbook(input_file)
original_ws = wb.active
for sheet_name, group in groups.items():
ws = wb.create_sheet(title=sheet_name)
for r in dataframe_to_rows(group, index=False, header=True):
ws.append(r)
adjust_column_width(ws)
adjust_row_height(ws)
copy_cell_styles(original_ws, ws)
wb.save(output_file)
print(f"已保存所有数据到 {output_file}")
except Exception as e:
print(f"写入文件 {output_file} 时发生错误: {e}")
if len(sys.argv) > 1:
file_path = sys.argv[1]
else:
file_path = '总表.xlsx' # 默认路径
base_dir = os.path.dirname(os.path.abspath(__file__))
safe_file_path = os.path.join(base_dir, file_path)
try:
if not Path(safe_file_path).exists():
raise FileNotFoundError(f"文件不存在: {safe_file_path}")
customer_column = '供应商'
output_dir = Path('output')
create_output_directory(output_dir)
df = read_excel_file(safe_file_path)
data_dict = {}
for customer_name, group in df.groupby(customer_column):
sheet_name = customer_name.replace(' ', '_')
data_dict[sheet_name] = group
output_file = output_dir / '所有分表.xlsx'
write_groups_to_excel(data_dict, safe_file_path, output_file)
except FileNotFoundError as e:
print(f"文件不存在: {e}")
except Exception as e:
print(f"发生错误: {e}")
结尾
综上所述,Python在处理Excel方面展现出了卓越的能力,它不仅可以自动化数据处理,还可以根据实际业务流程的需要进行精准定制。通过Python,我们可以轻松地将繁琐的手动任务转变为一键执行的操作,实现批量提取、处理字体、字色、字号,甚至插入图片及二维码等功能。这不仅提高了工作效率,还为数据管理带来了前所未有的便捷性。
如果您在数据处理方面有特殊需求,或者希望进一步探索Python在自动化办公领域的应用,欢迎与我们交流和咨询。我们期待与您共同探讨如何利用技术优化工作流程,释放潜力,创造更多价值。让我们一起用Python开启自动化办公的新篇章,让工作变得更加智能和高效!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









