







前言:基础知识
1:程序设计语言的发展历程

由于结构化语言有缺陷,因此又出现了面向对象语言,面向对象语言最复杂的是C++,C++完全兼容C语言。在高级语言中C语言的速度最快,C++次之,JAVA、C#又次之。
三大操作系统:Windows,Unix,Linux内核都是用C语言写的。
1.1:C语言的诞生
1972年,贝尔实验室的丹尼斯-里奇(Dennis Ritch)与肯-汤普逊(Ken Thompson)在开发Unix操作系统时设计了C语言,C语言是在B语言(汤普逊发明)的基础上进行设计的。
1.2:C语言的优缺点
C语言是一种高效、灵活、可移植性强的语言,程序员利用C可以访问硬件,操控内存中的位。同时由于其灵活性,程序员也会犯一些莫名其妙的错误,特别是C语言中的指针。享受C语言自由编程的乐趣的同时也必须承担其自由带来的后果。
2:C语言与其他高级语言的关系
2.1:C语言与JAVA
- 学习C语言就是在学习Java, C语言中大多数的语法都被Java继承了。
- C语言是面向过程的代表,学好C语言有助于学习Java中面向对象的思想。
- C语言中的指针是理解Java中引用的基础。
2.2:C语言与C++
20世纪90年代,许多软件公司开始使用C++来开发大型编程项目,C++在C语言的基础上嫁接了面向对象编程工具,因此C++几乎就是C的超集,意味着学习C语言的同时也学习了C++的许多知识。(面向对象编程是一门哲学,它通过对语言建模来适应问题,而不是对问题建模以适应语言。)
3:电脑如何播放一部电影?
一部下载好的电影是存储在硬盘上的,双击打开,这个操作是由操作系统规定的。这时硬盘上的电影会加载到内存上,再由CPU(主流的有intel,Apple,AMD)进行处理(CPU只能处理内存上的数据),声音的部分交给声卡,图像的部分交给显卡,最后声音在喇叭中播放,图像在显示器上显示。而电脑的主板就相当于身体的躯干,提供一个平台。
4:八进制常量在C语言中的表示
八进制常量在C语言中表示前面加的是数字0而不是字母o。十六进制前面加0x或0X。
5:什么是字节?
- 字节就是存储数据的单位,并且是硬件所能访问的最小单位。
- 1 Byte = 8 Bit
1 K = 1024 Byte
1 M = 1024 K
1 G = 1024 M
6:什么是变量?
变量的本质就是内存中的一段存储空间。
6.1:再论什么变量
- 从硬件方面来看,被存储的每个值都占用一定的物理内存,C语言把这样的一块内存称为对象(object),对象可以存储一个或多个值,一个对象可能并未存储实际的值,但是它在存储适当的值时一定具有相应的大小(面向对象编程中的对象指的是类对象,其定义包括数据和允许对数据进行的操作,C不是面向对象编程语言);
- 从软件方面看,程序需要一种方法访问对象(内存),这可以通过声明变量来完成,
int i = 3;该声明创建了一个名为i的标识符(identifier)。标识符是一个名称,可以用来指定(designate)特定对象的内容。
7:什么是ASCII码?
- ASCII码不是一个值,而是一种规定。它规定了不同的字符是使用哪个整数值去表示。例如‘A’–65。
- 标准ASCII码范围是0-127,只需7位二进制数即可表示,C语言把1字节定义为char类型占用的位数,即8位,因此容纳标准的ASCII码绰绰有余。许多其他的系统(如IMB PC与苹果macOS)还提供拓展ASCII码,但也在8位的表示范围之内。
8:C语言对真假的处理
非零是真;
零是假;
真用1表示 ;
9:C语言中的术语
9.1:副作用
副作用是对数据对象或文件的修改。
9.2:序列点
序列点是程序执行的点,在该点上,所有副作用都在进入下一步之前发生。
- C语言中,语句中的分号(;)标记了一个序列点。
- 逗号也是一个序列点,所以逗号左侧项的所有副作用都在程序执行逗号右侧项之前发生。(&&和||都是序列点。)
- 任何一个完整表达式的结束也是一个序列点。(完整表达式指的是该表达式不是另一个更大表达式的子表达式。)
10:进制
10.1:什么叫n进制?
进制就是逢几进一,n进制就是逢n进1。
10.2:不同进制数的表示
在汇编中,二进制后面加字母B,八进制后面加字母O,十进制后面加字母D,十六进制后面加字母H。
10.3:n进制转10进制
举个例子8进制的123,转换为10进制,即3+2乘8的一次+1乘8的二次。
10.4:10进制转n进制
10进制转n进制,就是除n,取余数,直至商为0,余数倒序排列。
10.5:16进制、8进制、2进制之间的关系
每个16进制数对应4个二进制位;12个十六进制数,对应48个二进制位。
每个8进制数,对应3个二进制位。
不存在十六进制和八进制的直接相互转化,都是以二进制为中间进制来进行转化的。
10.6:进制转换的基础知识
小数除以大数,商为0,余数是小数本身
11:回显输入与无回显输入
- 回显输入:意味着用户输入的字符直接显示在屏幕上。
- 无回显输入:意味着击键后对应的字符不显示。
12:什么是栈和堆?
- 栈(Stack)是一种基于后进先出(Last In, First Out,LIFO)原则的数据结构。这意味着最后进入栈的元素会最先被取出。栈有两个主要操作:压栈(Push)将元素添加到栈的顶部。出栈(Pop)从栈的顶部移除元素。栈的实现可以使用数组或链表。
- 在栈中,只能在栈顶进行操作,而不允许在中间或底部插入或删除元素。这使得栈特别适用于需要按照后进先出顺序进行操作的场景,如函数调用的管理、表达式求值、括号匹配等。栈还有一个重要的特性是栈帧的使用。每当函数被调用,系统都会为该函数创建一个栈帧,栈帧包含了函数的局部变量、参数、返回地址等信息。当函数执行完毕时,栈帧被弹出,控制权返回到调用函数。
- 堆(Heap): 堆是一种数据结构,通常指的是二叉堆。二叉堆是一个完全二叉树,可以分为最大堆和最小堆。在最大堆中,每个节点的值都大于或等于其子节点的值;在最小堆中,每个节点的值都小于或等于其子节点的值。堆在优先队列、堆排序等算法中有广泛的应用。
13:重点概念
13.1:什么叫分配内存,什么叫释放内存?
- 分配内存:操作系统把某一块内存空间的操作权限分配给该程序。
- 释放内存:操作系统把分配给该程序内存空间的操作权限收回,使得该程序不能再对这一块内存空间进行操作。释放内存不是把该内存的内容清零。
13.2:变量为什么必须要初始化?
- 不初始化,则变量存储的可能就是垃圾值。
13.3:系统是如何执行:int i = 5这条语句的?
- IDE软件请求操作系统为i分配存储空间。
- 操作系统会在内存中寻找一块空闲的区域,把该区域当做i来使用。
- IDE软件会把i和这块空闲区域关联起来,今后对字母i的操作就是对这块空闲区域的操作。
- 把5存储到字母i所关联的内存区域中。
- 附注:所谓内存区域也就是内存中的一块存储单元。
13.4:函数的优点
- 避免重复性操作
- 有利于程序的模块化
13.5:什么是指针、地址、指针变量?
地址是内存单元的编号,指针就是地址,指针和地址是同一个概念,指针变量是存放内存单元编号的变量,指针变量和指针是两个完全不同的概念,只不过人们通常把指针变量简称指针。
13.6:静态变量和动态变量的异同?
- 相同点:都需要分配内存。
- 不同点:静态变量是有系统自动分配,自动释放,程序员无法在程序运行的过程中手动分配和手动释放静态变量是在栈中分配的,函数终止之后,静态变量的存储空间才会被系统释放。
- 动态变量是由程序员手动分配,手动释放,程序员可以在程序运行的过程中手动分配或释放,动态
变量是在堆中分配的。
一:C语言的编程机制
1.1:预处理器
- C预处理器在程序执行之前查看程序,故称之为预处理器。
- 在预处理之前,编译器必须对该程序进行一些翻译处理,首先,编译器把源代码中出现的字符映射到源字符集。第二,编译器定位每个反斜杠后面跟着换行符的实例,并删除它们。第三,编译器把文本划分为预处理记号序列,空白序列和注释序列(记号是由空格,制表符、换行符分隔的项)。
1.2:明示常量:#define
当一个程序中有一个多处使用的常量,而且有时需要更改常量的值时,定义一个符号常量会方便很多。
#define PI 3.1415926 //定义一个符号常量
- 编译程序时,程序中的PI都会被替换为3.1415926,这一过程被称为编译时替换。
- 明示变量末尾不用加分号,因为这是一种由预处理器处理的替换机制。
- 用大写字母表示符号常量是C语言一贯的传统。
1.2.1:const限定符
C90标准新增const关键字,用于限定一个变量为只读。
const int MONTHS = 12;
1.2.2:明示常量
- 使用
#define指令来定义明示常量(也叫符号常量)。 - 每行#define都由3个部分组成:
#define PI 3.141.#define指令本身,2.宏。3.替换体。 #号作为一个预处理运算符,可以把记号转换成字符串。(宏的替换体看作记号型字符串,而不是字符型字符串)
C头文件limits.h和folat.h分别提供了与整数类型和浮点类型大小限制相关的详细信息。每个头文件都定义了一系列供使用的明示常量。例如limit.h头文件中包含类似代码:
#define INT_MAX +32767
#define INT_MIN -32768
1.3:命令行参数

- 在图形界面普及之前都使用命令行参数,DOS和UNIX就是例子,Linux终端提供类UNIX命令行环境,命令行(command line)是在命令行环境中,用户为运行程序输入命令的行;
- C编译器运行main()没有参数或者有两个参数(一些实现允许main()有更多参数,属于对标准的扩展)。main有两个参数时,第1个参数是命令行中字符串的数量。过去,这个int类型的参数被称为argc(表示参数计数argument count),系统用空格表示一个字符串的结束和下一个字符串的开始;
- 该程序把命令行字符串存储在内存中,并把每个字符串的地址存储在指针数组中,而该数组的地址则被存储在main()的第2个参数中,按照惯例这个指向指针的指针被称为argv(表示参数值argument value);
1.4:文件包含:#include
当预处理器发现#include指令时,会查看后面的文件名并把文件的内容包含到当前文件中。
二:转义序列、指定数据类型
2.1:常用转义序列
| 转义序列 | 含义 |
|---|---|
| \a | 警报 |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \\ | 反斜杠(\) |
| \’ | 单引号 |
| \" | 双引号 |
| \? | 问号 |
转义序列举例如下:

代码:
/* Functions:转义序列的使用举例
* 注:%.2f中的.2用于精确控制输出,指定输出的浮点数只能显示小数点后两位。
*/
#include <stdio.h>
int main(void)
{
float Salary;
printf("\a输入你每个月的薪水:"); // \a表示警报
printf("$____\b\b\b\b"); // \b表示退格
scanf_s("%f", &Salary); //&表示把输入的字符赋给变量Salary
printf("\n\t $%.2f一个月的话,一年就是$%.2f", Salary, Salary * 12); // \n换行
printf("\r哇!\n"); // \r表示回车,使得光标回到当前行的起始处。
}
- 了解了转义序列的含义之后便可以理解用AT指令给单片机发送命令时,为什么双引号(”)之前要加一个斜杠(\)。
2.2:sizeof()运算符
- sizeof是C语言的内置运算符,以字节为单位(一个字节Byte有8位)输出指定类型的大小,运算对象可以是具体的数据对象(如,变量名)或类型。
- C99和C11标准专门为sizeof运算符的返回类型添加了%zd转换说明。对于strlen()同样适用。
- stddef.h头文件(包含在stdio.h头文件中)把size_t定义成系统使用sizeof返回的类型,这被称为底层类型。其次,printf()使用z修饰符表示打印相应的类型。
- sizeof()则将字符串末尾不可见的空字符也计算在内,strlen()函数给出字符串中字符的长度(包括空格和标点符号,末尾的空字符不计算在内)。
2.2.1:size_t类型
C语言规定,sizeof返回size_t类型的值,C头文件使用typedef声明 size_t 为 unsigned int类型别名。
2.3:指定类型int、float、char、double的大小
如何知道当前系统的指定类型大小,比如int、float、char、double等等数据类型的大小是多少。这里贴出C语言程序运行截图及代码。
运行程序截图:
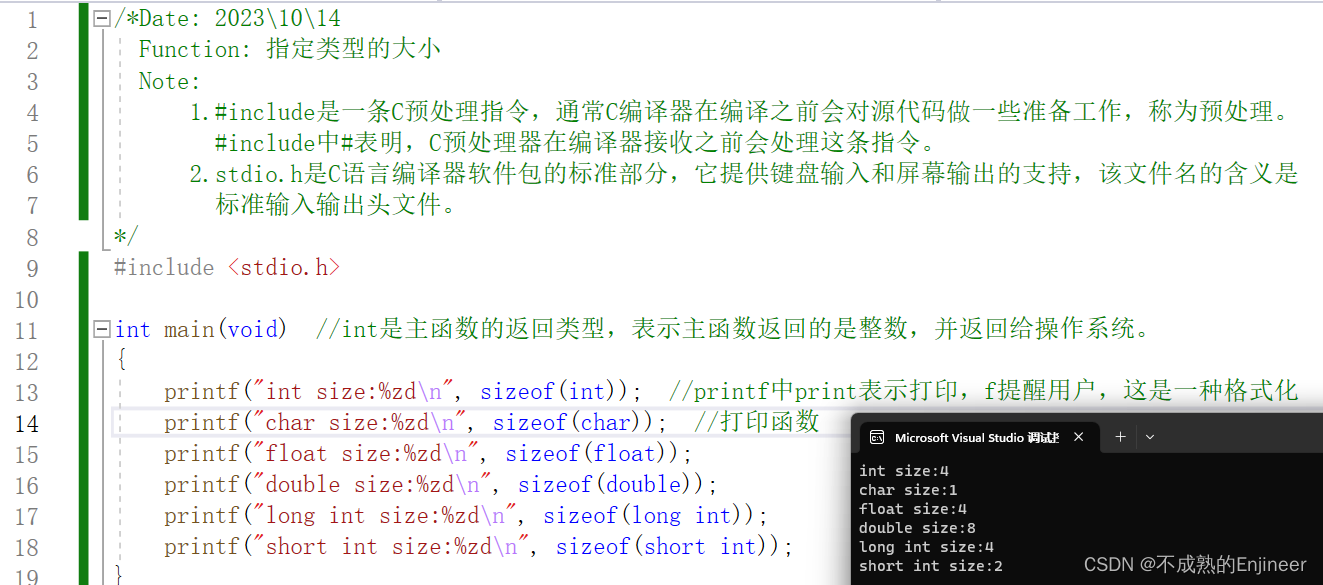
代码部分:
/*Date: 2023\10\14
Function: 指定类型的大小
Note:
1.#include是一条C预处理指令,通常C编译器在编译之前会对源代码做一些准备工作,称为预处理。
#include中#表明,C预处理器在编译器接收之前会处理这条指令。
2.stdio.h是C语言编译器软件包的标准部分,它提供键盘输入和屏幕输出的支持,该文件名的含义是
标准输入输出头文件。
*/
#include <stdio.h>
int main(void) //int是主函数的返回类型,表示主函数返回的是整数,并返回给操作系统。
{
printf("int size:%zd\n", sizeof(int)); //printf中print表示打印,f提醒用户,这是一种格式化
printf("char size:%zd\n", sizeof(char)); //打印函数
printf("float size:%zd\n", sizeof(float));
printf("double size:%zd\n", sizeof(double));
printf("long int size:%zd\n", sizeof(long int));
printf("short int size:%zd\n", sizeof(short int));
return 0;
}
- 类似于%zd、%d、%f的符号称为转换说明,它指定了printf()应使用什么格式来显示一个值。
- C99与C11标准提供了%zd转换说明以匹配sizeof的返回类型(即 size_t 类型),一些不支持C99、C11标准的编译器可以采用%lu或%u来代替%zd。
2.4:_Bool类型
_Bool类型的变量只能存储1(真)或0(假)。如果把其它非零数值赋给_Bool类型的变量,该变量就会被设置为1。
2.4.1:使用布尔类型时的注意点
- 使用布尔类型,可以在程序中添加stdbool.h头文件,为bool、true、false提供定义。
- 使用布尔类型变量,通常习惯把变量自身作为测试条件。
bool inward = true;
if (inward) //代替if(inward == true)
{
printf("it's OK.\n");
}
三:转换说明
3.1:常用的转换说明及其作用
举个例子:%d称为转换说明,作用有二:
- 相当于一个占位符,指明要输出变量的具体位置。
- 指定了printf应使用什么格式来显示一个变量,%(输出控制符)则提醒程序,我要在此处打印一个变量,d(转换字符)表明要程序把变量作为十进制整数打印。(注意在转换说明中转换字符只能是小写)
- 举个例子int a = 10; 此时a中存储的是10的二进制代码,这时想要以十进制的方式显示数字10,就必须要用%d,表明程序要把存储在计算机中的10的二进制代码转换为10进制输出。
- 转换说明是把以二进制格式存储在计算机中的值转换成一系列字符(字符串)显示。转换说明实际上是翻译说明,%d的意思是把给定的值翻译成十进制整数文本并打印出来。
常用的转换说明:
| 转换说明 | 输出 |
|---|---|
| %d | 有符号十进制整数 |
| %f | 浮点数,十进制计数法 |
| %lf | double类型 |
| %e | 浮点数,e计数法 |
| %c | 单个字符 |
| %s | 字符串 |
| %% | 打印一个百分号 |
| %a | 以指数形式输出浮点数,十六进制计数法 |
| %g | 小数点右侧尾数0不被显示 |
| %x | 以十六进制输出 |
| %#x | 以十六进制输出,前面带0x,也可以是%#X |
| %o | 以八进制输出 |
| %i | 有符号十进制整数(与%d相同) |
| %u | 无符号十进制整数 |
| %p | 指针(输出地址的转换说明) |
| %o | 以八进制输出 |
| %zd | 匹配sizeof的返回类型(即 size_t 类型) |
| %td | 打印地址的差值(差值的单位与数组类型的单位相同) |
例:输入一个ASCLL码值,输出其对应的字符

代码:
/* Functions: 输入一个ASCLL码值,输出其对应的字符
* 注:标准ASCLL码的范围是0-127。 整数66代表大写字母B。
*/
#include <stdio.h>
int main(void)
{
int ch = 0;
printf("请输入ASCLL码值:");
scanf_s("%d", &ch);
printf("%d对应的ASCLL码为%c", ch, ch); //
return 0;
}
3.2:转换不匹配
3.2.1:一些不匹配的整形转换
/*Date: 2023\10\12
Function: 转换说明不匹配
*/
#include <stdio.h>
#define PAGES 336
#define WORDS 65618
int main(void)
{
short num = PAGES;
short mnum = -PAGES;
printf("num as an short and unsigned short: %hd %hu\n", num, num);
printf("-num as an short and unsigned short: %hd %hu\n", mnum, mnum);
printf("num as int and char: %d %c\n", num, num);
printf("WORDS as an int,short,and char: %d %hd %c\n", WORDS, WORDS, WORDS);
return 0;
}
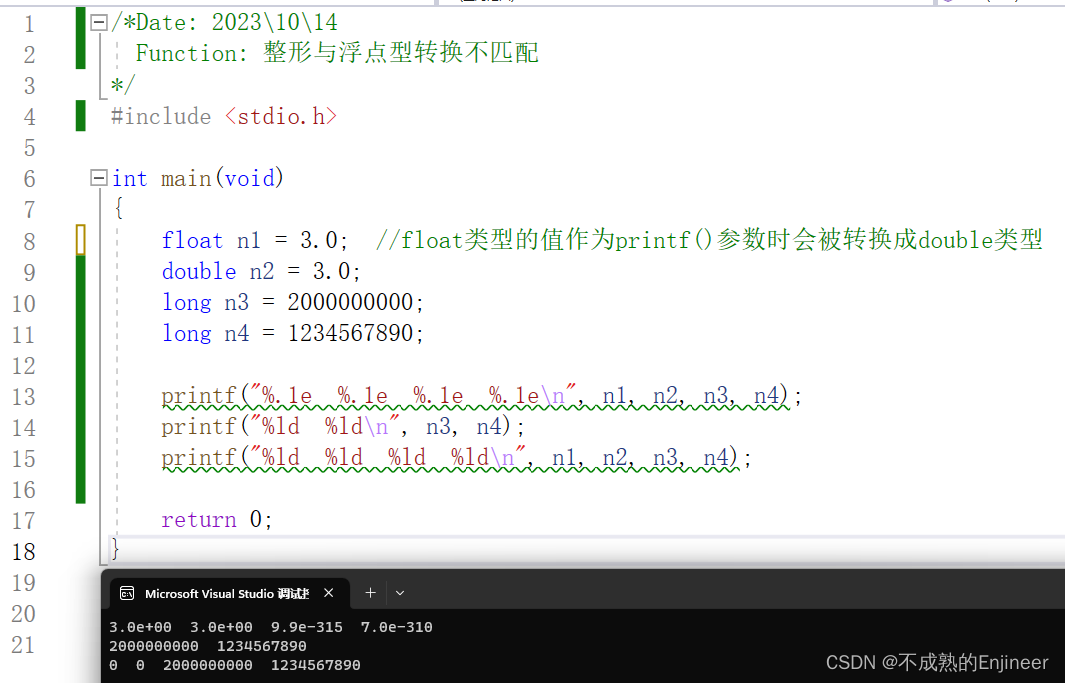
3.2.2:整形与浮点型转换不匹配
/*Date: 2023\10\14
Function: 整形与浮点型转换不匹配
*/
#include <stdio.h>
int main(void)
{
float n1 = 3.0; //float类型的值作为printf()参数时会被转换成double类型
double n2 = 3.0;
long n3 = 2000000000;
long n4 = 1234567890;
printf("%.1e %.1e %.1e %.1e\n", n1, n2, n3, n4);
printf("%ld %ld\n", n3, n4);
printf("%ld %ld %ld %ld\n", n1, n2, n3, n4);
return 0;
}
程序运行结果:
3.2.3:参数传递
参数传递机制因编译器实现而异。
printf("%.1e %.1e %.1e %.1e\n", n1, n2, n3, n4);
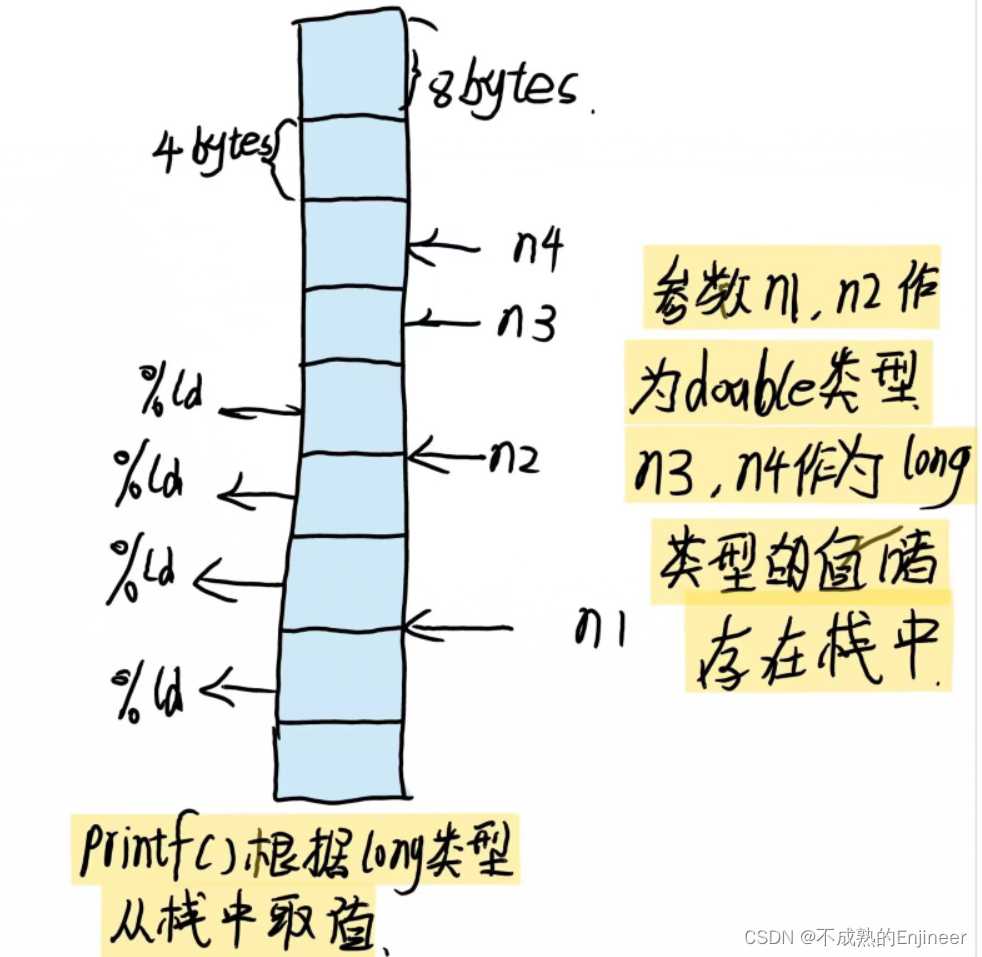
上述函数告诉计算机将变量n1,n2,n3,n4的值传递给程序,这是一种常见的参数传递方式,程序把传入的值放入栈(stack)的内存区域。计算机根据变量类型(不是根据转换说明)把这些值放入栈中。n1被放入栈中,占8个字节,n2也占8个字节,n3,n4分别占4个字节,然后,控制转到printf()函数,该函数根据转换说明(不是变量类型)从栈中读取数值。%ld转换说明表示printf()函数应该读取4个字节,所以printf()读取栈中前4个字节,这是n1的前半部分,将被解释成一个long类型的整数,根据下一个%ld转换类型,printf()在读取4个字节,这是n1的后半部分,将被解释成第2个long类型整数。类似的根据第3个,第4个%d,printf()函数读取n2的前后部分,并解释成两个long类型整数。(根据程序运行结果可以看出,只有n1,n2的输出有问题,n3,n4的结果正确,应当是参数传递机制不同导致的。)
四:float浮点类型
4.1:浮点数的传统与科学计数法
- 传统计数法: float x = 3.2;
- 科学计数法: float x = 3.2e3; //x的值为3200.
float x = 123.45e-2;//x的值为1.2345.
4.2:形如%m.nf的转换说明修饰符
形如%m.nf的转换说明,其中m表示输出数据的宽度(如果宽度不够就补空格,小数点也算一个宽度,如果数据实际宽度超过m就用实际宽度),n表示输出的实数保留n位小数。
4.3:浮点型与整形的存储
浮点数与整数的存储方案不同,计算机把浮点数分为小数部分和指数部分来表示,而且分开存储这两部分。因此7.00与7虽然在数值上相同,但他们的存储方式不同。十进制下,可以把7.0写成0.7E1。其中0.7是小数部分,1是指数部分。
图3.2演示了使用二进制编码存储整数7:

图3.3演示了以浮点格式(十进制)存储Π的值:

- 浮点数通常只是实际值的近似值,例如,7.0可能被存储为浮点值6.99999。
- 过去浮点运算比整数运算慢,不过现在许多CPU都包含浮点处理器,缩小了速度上的差距。
- 整数是以补码的形式转化为二进制代码存储在计算机中的。
- 实数(浮点型)是以IEEE754标准转化为二进制代码存储在计算机中的。
- 字符的本质实际与整数的存储方式相同。(参见六:关于char类型的一些注释)
- float和double类型都不能保证可以精确的存储一个小数。
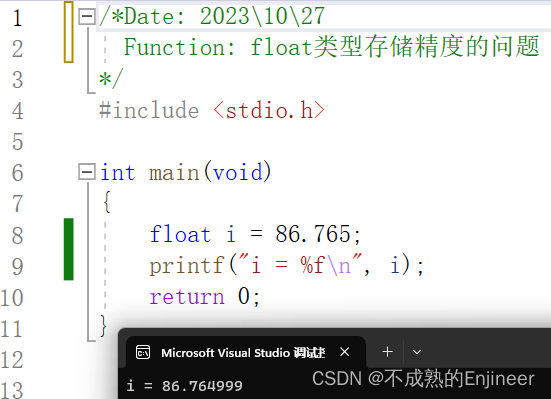
/*Date: 2023\10\27
Function: float类型存储精度的问题
*/
#include <stdio.h>
int main(void)
{
float i = 86.765;
printf("i = %f\n", i);
return 0;
}
4.4:浮点数的打印
printf函数使用%f转换说明打印十进制记数法的float和double类型浮点数,用%e打印指数记数法的浮点数。
4.5:浮点数的舍入错误
假设一个数b加上1后,再减去b,结果是多少? 正常情况下一定是1,但下面的例子却给出了不同答案:

代码:
/* Functions:演示float类型的舍入错误*/
#include <stdio.h>
int main(void)
{
float a, b;
b = 2.0e20 + 1;
a = b - 2.0e20;
printf("%f \n", a);
return 0;
}
由于计算器缺少足够的小数位来完成正确的计算,2.0e20是2后面有20个零,如果把该数+1,那么发生变化的就是第21位,要正确运算,程序至少需要存储21位数字,而float类型的数字通常只能存储按指数比例缩小或放大的6或7位有效数字,这种情况下,计算结果一定是错误的。另一方面,如果将2.0e20改成2.0e4,那么发生变化的就是第5位上的数字,float类型的精度足够进行这样的计算。
如图所示:


4.6:浮点值的上溢与下溢、整数的上溢
假设系统的最大float类型值是3.4E38,那么其乘以100会得到什么?如图所示:

当计算导致数字过大,超出当前类型能表达的范围时,就会发生上溢(overflow),C语言规定,这种情况下会给toobig赋一个表示无穷大的特定值,而且printf函数显示该值为inf或infinity(无限)。顺便提一嘴,英飞凌半导体公司(infineon)是不是就有取infinite的意思呢?言归正传,以十进制为例,4位有效数字0.1234E-10除以10,得到的结果是0.123E-10。在计算过程中损失了原末尾有效位上的数字,这种情况叫做下溢(underflow)。
那么系统又会如何处理整数上溢的问题呢?请看下图,程序显示整数最大值为2147483647,加1后为-2147483648,由第一部分,我们得知此系统下int类型是4个字节,32位,2的32次方为4294967296,除以2即为2147483648正数部分为0-2147483647,负数部分为-2147483648- -1,所以2,147,483,647+1就变成了-2,147,483,648。

代码:
/* Functions: 通过程序观察系统如何处理整数上溢,浮点数上溢,浮点数下溢的问题
**注:该程序使用了博主MZZDX专栏C Primer Plus编程练习答案汇总中的程序,并自主添加注释。
*/
#include <stdio.h>
#include <limits.h>
#include <float.h>
int main(void)
{
int max_int = INT_MAX; //INT_MAX与INT_MIN分别表示最大、最小整数,定义在头文件limits.h中
float max_float = FLT_MAX; //同理FLT_MAX的定义包含在头文件float.h中
float small_float = 0.001234 / 10;
printf("max_int = %d,整数上溢后其值为%d\n", max_int, max_int + 1);
printf("max_float = %f,浮点数上溢后其值为%f\n", max_float, max_float * 10);
printf("浮点数下溢后其值为%f\n", small_float);
return 0;
}
4.7:float与double类型为什么不能精确表示实数?
由2.3知float与double类型的大小分别4字节(32位)与8字节(64位)。此图参考此博主的文章

符号位决定了数字的正负,指数位决定了其范围,尾数位决定了其精度。
一个小数转换成二进制:每次取小数部分与2相乘,取结果的整数部分,直到积为0,最后将取得的数正序排列。举例来说:
0.9 * 2 = 1.8 取1
0.8 * 2 = 1.6 取1
0.6 * 2 = 1.2 取1
0.2 * 2 = 0.4 取0
0.4 * 2 = 0.8 取0
0.8 * 2 = 1.6 取1
0.6 * 2 = 1.2 取1
… …
所以0.9的二进制表达式为111001100 … 无限循环,而float和double的尾数位是有限的,float类型只能保存小数点后的23位,23位之后的数据就会被丢弃,所以也就导致了其不能精确表示实数。
五:Char字符与String字符串
5.1:什么是字符串?
- 字符串(character string)是一个或者多个字符的序列。“hello,world!” 中双引号不是字符串的一部分,双引号仅仅告知编译器它括起来的是字符串,正如单引号用于标识单个字符一样;
- C语言中没有专门用于存储字符串的变量类型,字符串都被存储在char类型的数组中,数组由连续的存储单元组成,字符串中的字符被存储在相邻的存储单元中,每个单元存储一个字符;(如下图)
- 字符串是以空字符(\0)结尾的char类型数组;
- 如果要在字符串内部使用双引号,必须在双引号前面加上一个反斜杠
\;

5.1.1:什么是数组?
数组是同类型数据元素的有序序列。
5.1.2:每一个字节存储一个字符值
/*Date: 2023\10\10
Function: 演示与用户进行交互
*/
#include <stdio.h>
#include <string.h> //提供strlen()函数的原型
#define DENSITY 62.4 //人体密度
int main()
{
float weight, volume;
int size, letters;
char name[40]; //name是一个可容纳40字符的数组
printf("hi,what is your first name?\n");
scanf_s("%s", name, 40); //scanf()函数不会检查输入边界,可能造成数据溢出,涉及到数组时,scanf_s会
//进行边界检查,调用时要提供一个数字以表明最多读取多少位字符。
printf("%s, what is your weight in pounds?\n", name);
scanf_s("%f", &weight);
size = sizeof(name);
letters = strlen(name);
volume = weight / DENSITY;
printf("well! %s, your voulme is %2.2f cubic feet.\n", name, volume);
printf("also, your first name has %d letters,\n", letters);
printf("and we have %d bytes to store it.\n", size);
return 0;
}
- 用数组存储字符串,在上述程序中,用户输入的名字被存储在数组中,该数组占用内存中40个连续的字节,每个字节存储一个字符。
- 使用%s处理字符串的输入输出,程序中&weight与name都是地址。
5.1.3:字符串字面量(字符串常量)
- 用双引号括起来的内容称为字符串字面量(string literal),也叫字符串常量(string constant)。双引号中的字符和编译器自动加入末尾的
\0字符,都作为字符串存储在内存中。 - 字符串常量属于静态存储类别(static storage class),这说明如果在函数中使用字符串常量,该字符串只会被存储一次。
- 用双引号
" "括起来的内容被视为指向该字符串存储位置的指针,类似于把数组名作为指向该数组位置的指针。
5.1.4:把字符串看作指针
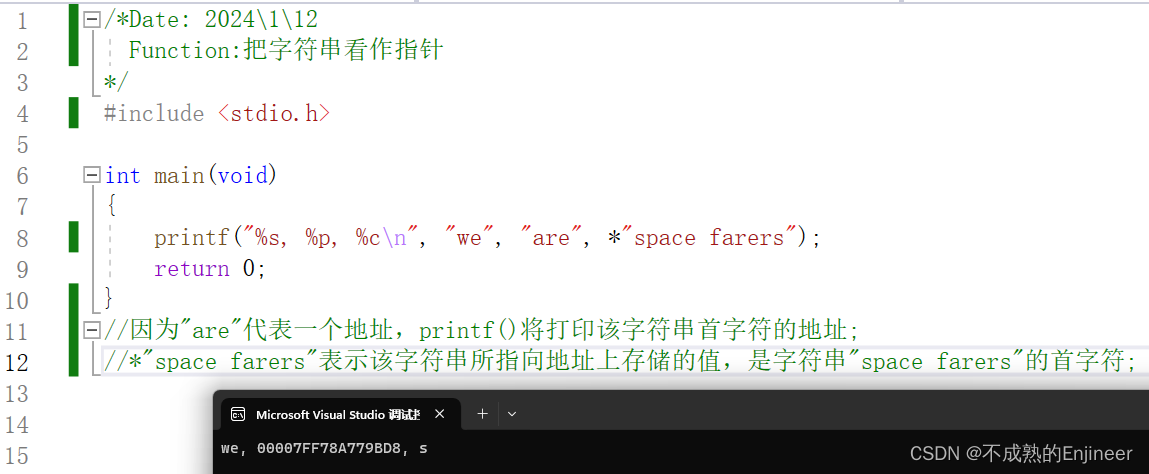
5.1.5:字符串组名是该字符串首元素的地址

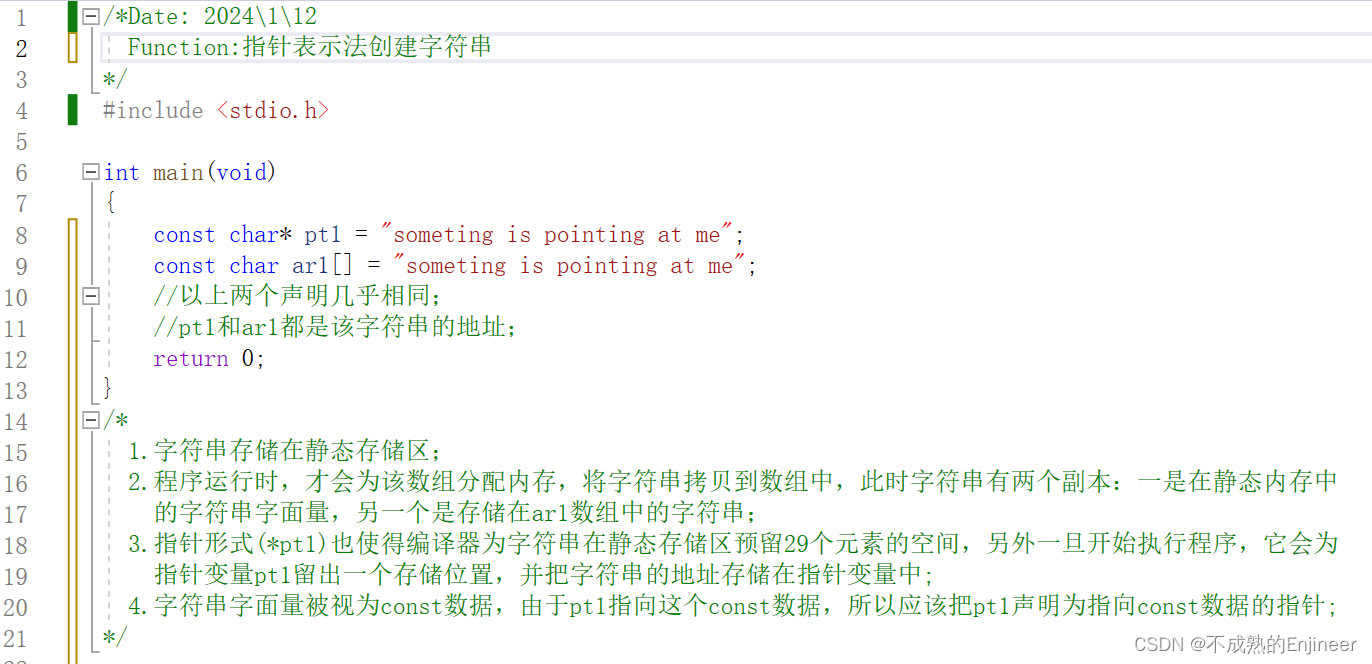
5.1.6:指针表示法创建字符串
/*Date: 2024\1\12
Function:指针表示法创建字符串
*/
#include <stdio.h>
int main(void)
{
const char* pt1 = "someting is pointing at me";
const char ar1[] = "someting is pointing at me";
//以上两个声明几乎相同;
//pt1和ar1都是该字符串的地址;
return 0;
}
/*
1.字符串存储在静态存储区;
2.程序运行时,才会为该数组分配内存,将字符串拷贝到数组中,此时字符串有两个副本:一是在静态内存中
的字符串字面量,另一个是存储在ar1数组中的字符串;
3.指针形式(*pt1)也使得编译器为字符串在静态存储区预留29个元素的空间,另外一旦开始执行程序,它会为
指针变量pt1留出一个存储位置,并把字符串的地址存储在指针变量中;
4.字符串字面量被视为const数据,由于pt1指向这个const数据,所以应该把pt1声明为指向const数据的指针;
*/
5.1.7:数组获得的是原始字符串的副本
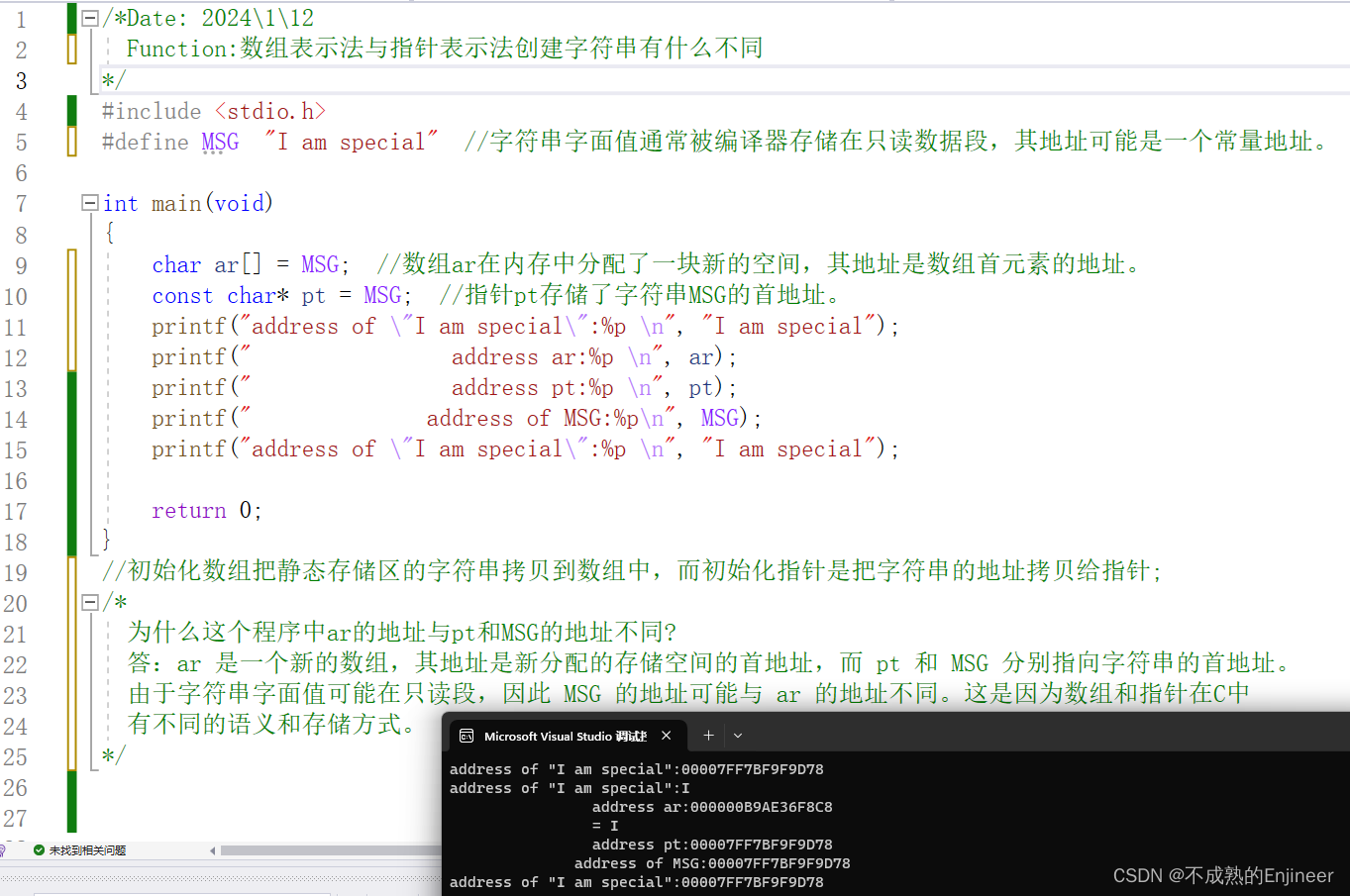
/*Date: 2024\1\12
Function:数组表示法与指针表示法创建字符串有什么不同
*/
#include <stdio.h>
#define MSG "I am special" //字符串字面值通常被编译器存储在只读数据段,其地址可能是一个常量地址。
int main(void)
{
char ar[] = MSG; //数组ar在内存中分配了一块新的空间,其地址是数组首元素的地址。
const char* pt = MSG; //指针pt存储了字符串MSG的首地址。
printf("address of \"I am special\":%p \n", "I am special");
printf(" address ar:%p \n", ar);
printf(" address pt:%p \n", pt);
printf(" address of MSG:%p\n", MSG);
printf("address of \"I am special\":%p \n", "I am special");
return 0;
}
//初始化数组把静态存储区的字符串拷贝到数组中,而初始化指针是把字符串的地址拷贝给指针;
/*
为什么这个程序中ar的地址与pt和MSG的地址不同?
答:ar 是一个新的数组,其地址是新分配的存储空间的首地址,而 pt 和 MSG 分别指向字符串的首地址。
由于字符串字面值可能在只读段,因此 MSG 的地址可能与 ar 的地址不同。这是因为数组和指针在C中
有不同的语义和存储方式。
*/
5.1.8:初始化字符数组和初始化指针指向字符串的区别
- 初始化指针指向字符串的意思是指向字符串的首字符;
- 把指针初始化为字符串字面量时要使用const限定符,
const char *p = "hello";数组初始化为字符串字面量时却不用加const,因为数组获得的是原始字符串的副本;
5.2:null字符(空字符)
- 上图中数组末尾位置的字符\0,成为空字符,C语言中用它标记字符串的结束。空字符不是数字0,它是非打印字符,其Ascall码值是(或等价于)0。
- C语言中字符串必须以空字符结束,如此数组的容量要至少要比待储存字符串中的字符数多1。
5.2.1:空字符与空指针
- 空字符
'\0'是用于标记C字符串末尾的字符,其对应字符编码是0,由于其他字符的编码不可能是0,所以空字符不可能是字符串中的数据; - 空指针(NULL)有一个值,该值不会与任何数据的有效地址对应。通常,函数使用它返回一个有效地址表示某些特殊情况的发生,例如遇到文件结尾或未能按预期执行;
- 空字符是整数类型,空指针是指针类型,它们都可以用数值0来表示,但从概念上看,两者是不同类型的0,另外空字符是一个字符,占1字节,而空指针是一个地址,指针变量在32位计算机上占4个字节,在64we
5.3:字符串与字符
单个字符用单引号括起来,字符串用双引号括起来,“A”表示也正确,因为“A”代表‘A’ 、‘\0’的组合。只要是字符串结尾默认添加‘\0’。在C语言中,用单引号括起来的单个字符被称为字符常量,举个例子:编译器一发现’A’,就会将其转换成相应的代码值65。
字符串常量“x”与字符常量‘x’的不同之处有二,其一:‘x’是基本类型(char),而“x”是派生类型(char 数组);其二:”x“实际上是由两个字符组成‘x’和空字符\0;
5.4:char类型的存储
char类型用于存储字符,如字母或标点符号。但是从技术层面看,char是整数类型,因为char类型实际上存储的是整数而不是字符。计算机使用数字编码来处理字符,即用特定的整数表示特定的字符,美国最常用的是ASCII编码,在ASCII编码中整数65代表的是大写字母A。因此存储字母A实际上存储的是整数65。此外,不同的国家可能使用不同的编码。如:商业的统一码(Unicode)创建了一个能表示世界范围内多种字符集的系统,目前包含的字符已超过110000个。
5.5:字符串数组
创建字符串数组的方法:1.指向字符串的指针数组;2.char类型数组的数组;
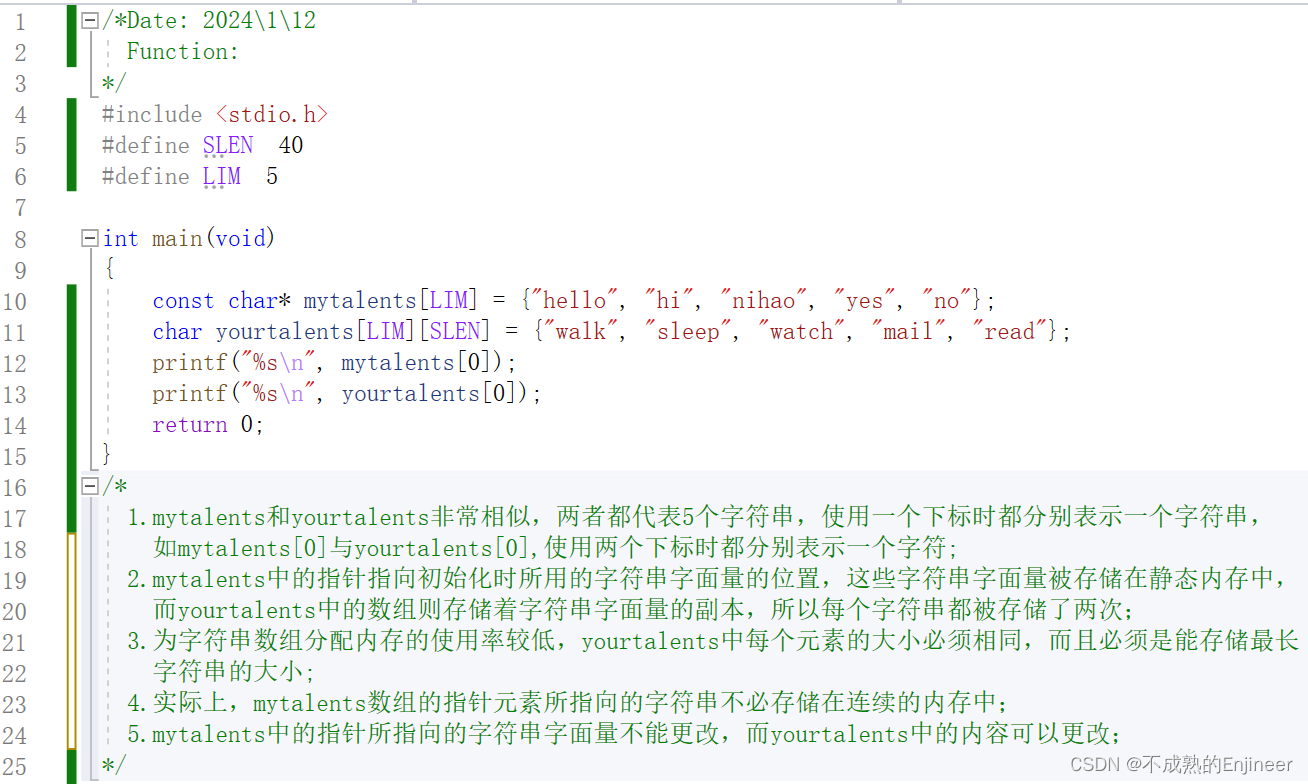
/*Date: 2024\1\12
Function:
*/
#include <stdio.h>
#define SLEN 40
#define LIM 5
int main(void)
{
const char* mytalents[LIM] = {"hello", "hi", "nihao", "yes", "no"};
char yourtalents[LIM][SLEN] = {"walk", "sleep", "watch", "mail", "read"};
printf("%s\n", mytalents[0]);
printf("%s\n", yourtalents[0]);
return 0;
}
/*
1.mytalents和yourtalents非常相似,两者都代表5个字符串,使用一个下标时都分别表示一个字符串,
如mytalents[0]与yourtalents[0],使用两个下标时都分别表示一个字符;
2.mytalents中的指针指向初始化时所用的字符串字面量的位置,这些字符串字面量被存储在静态内存中,
而yourtalents中的数组则存储着字符串字面量的副本,所以每个字符串都被存储了两次;
3.为字符串数组分配内存的使用率较低,yourtalents中每个元素的大小必须相同,而且必须是能存储最长
字符串的大小;
4.实际上,mytalents数组的指针元素所指向的字符串不必存储在连续的内存中;
5.mytalents中的指针所指向的字符串字面量不能更改,而yourtalents中的内容可以更改;
*/
5.6:字符串函数
5.6.1:strlen()函数
strlen()函数给出字符串中字符的长度(包括空格和标点符号,末尾的空字符不计算在内)。
5.6.2: strlen()与sizeof()的辨析
sizeof()函数以字节为单位给出对象的大小,strlen()函数给出字符串中字符长度,因为1字节存储一个字符,读者可能会认为两种方法用于字符串得到的结果相同,其实不然。
- strlen()函数给出字符串中字符的长度(包括空格和标点符号,末尾的空字符不计算在内)。
- sizeof()则将字符串末尾不可见的空字符也计算在内。
/*Date: 2023\10\10
Function: sizeof()与strlen()的辨析
*/
#include <stdio.h>
#include <string.h>
#define PRAISE "You are an extraordinary being."
int main()
{
char name[40];
printf("what is your name? ");
scanf_s("%s", name, 40);
printf("hello, %s, %s", name, PRAISE);
printf("your name of %zd letters occupies %zd memory cells.\n",
strlen(name), sizeof(name));
printf("the Phrase of praise has %zd letters",
strlen(PRAISE));
printf("and occupies %zd memory cells.\n", sizeof(PRAISE));
return 0;
}
5.6.3:strcat()函数
- strcat()用于拼接字符串,函数接收两个字符串作为参数。该函数把第2个字符串的备份附加在第1个字符串末尾,并把拼接后形成的新字符串作为第1个字符串,第2个字符串不变。并返回拼接第2个字符串后的第1个字符串的地址;
strcat(a, b); - strcat()函数的类型是char *(即指向char的指针);
- strcat()函数无法确保第1个数组能否容纳第2个字符串,如果分配给第1个数组的空间不够大,多出来的字符溢出到相邻存储单元时就会出问题;
5.6.4:strncat()函数
- strncat()函数的第3个参数制定了最大添加字符数,例如:
strncat(a, b, 13);将b字符串的内容附加给a,在加到第13个字符或遇到空字符时停止;
5.6.5:strcmp()函数
- strcmp()函数用于字符串比较,该函数通过比较运算符来比较字符串,如果两个字符串参数相同则返回0,如果不同则返回非0值;
- strcmp()函数只会比较数组中第1个空字符前面的内容,因此此函数可以比较存储在不同大小数组中的字符串;
- 如果在字母表中第1个字符串位于第2个字符串前面,strcmp()返回负数,反之返回正数。如果两个字符串开始的几个字符都一样,那么strcmp()会依次比较每个字符,直到发现第1对不同的字符为止,然后返回相应的值;
- 空字符在ASCII码中排第1;
5.6.6:strncmp()函数
- strncmp()函数在比较两个字符串时,可以比较到字符不同的地方,也可以只比较第3个参数指定的字符数。例如:要查找以“astro”开头的字符串,可以限定函数只查找这5个字符。
strncmp(list[i], "astro", 5) == 0;
5.6.7:strcpy()函数
- strcpy()接受两个字符串指针作为参数(第1个参数是目标字符串,第2个参数是源字符串),第2个参数指向的字符串被拷贝至第1个参数指向的数组中,拷贝出来的字符串被称为目标字符串,最初的字符串被称为源字符串;
- 可以把指向源字符串的第2个指针声明为指针、数组名或字符串常量;而指向源字符串副本的第1个指针应指向一个数据对象(如数组),且该对象有足够的空间存储源字符串的副本;
- 声明数组将分配存储数据的空间,声明指针只分配存储一个地址的空间;
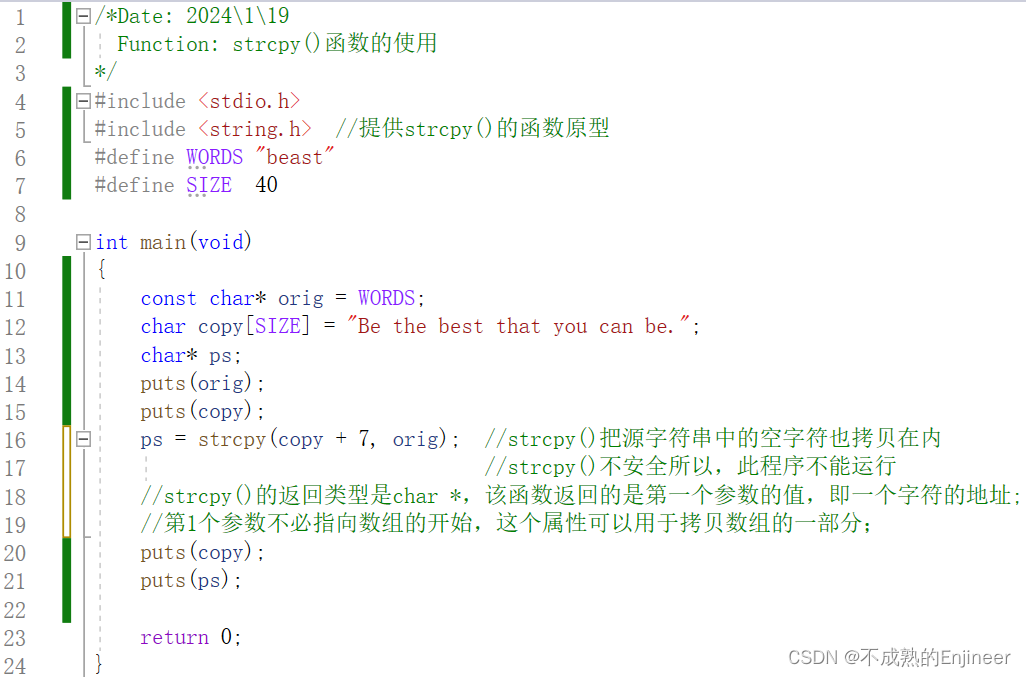
- strcpy()的返回类型是
char *,该函数返回的是第一个参数的值,即一个字符的地址; - 第1个参数不必指向数组的开始,这个属性可以用于拷贝数组的一部分;
- strcpy()把源字符串中的空字符也拷贝在内;
- strcpy()和strcat()都有同样的问题,它们都不能检查目标空间是否能容纳源字符串的副本;
/*Date: 2024\1\19
Function: strcpy()函数的使用
*/
#include <stdio.h>
#include <string.h> //提供strcpy()的函数原型
#define WORDS "beast"
#define SIZE 40
int main(void)
{
const char* orig = WORDS;
char copy[SIZE] = "Be the best that you can be.";
char* ps;
puts(orig);
puts(copy);
ps = strcpy(copy + 7, orig); //strcpy()把源字符串中的空字符也拷贝在内
//strcpy()不安全所以,此程序不能运行
//strcpy()的返回类型是char *,该函数返回的是第一个参数的值,即一个字符的地址;
//第1个参数不必指向数组的开始,这个属性可以用于拷贝数组的一部分;
puts(copy);
puts(ps);
return 0;
}
5.6.8:strncpy()函数
strncpy(target,source,n)把source中的n个字符或空字符之前的字符(先满足哪个条件就拷贝到何处)拷贝到target中,因此source中的字符数小于n,则拷贝整个字符串,包括空字符。但是,strncpy()拷贝字符串的长度不会超过n,如果拷贝到第n个字符时还未拷贝完整个源字符串,就不会拷贝空字符。所以拷贝的副本中不一定有空字符;
鉴于此,该程序把n设置未比目标数组大小少1,然后把数组最后一个元素设置为空字符。这样确保存储的是一个字符串,如果目标空间能容纳源字符串的副本,那么从源字符串拷贝的空字符便是该副本的结尾,如果目标空间装不下副本,则把副本最后一个元素设置为空字符;
5.6.9:sprintf()函数
- sprintf()函数声明在stdio.h中,它是把数据写入字符串,而不是打印在显示器上,sprintf()的第1个参数是目标字符串的地址;
sprintf(formal,“%s”,string);sprintf()函数获取输入,并将其格式化为标准形式,然后把格式化后的字符串存储在formal中;
5.7:字符串输入
5.7.1:不安全的gets()函数
在读取字符串时,scanf()和转换说明%s只能读取一个单词,可在程序中经常需要一整行输入而不是一个单词。许多年前,gets()函数就用于处理这种情况,它读取整行输入,直到遇到换行符,然后丢弃换行符,存储其它字符,并在这些字符末尾添加一个空字符使其成为一个C字符串。
但是gets()函数无法检测用来存储数据的数组是否装的下输入行,gets()函数只能通过数组名知道该数组的首元素地址,而不知道该数组究竟有多少元素,如果输入的字符串过长,会导致缓冲区溢出(buffer overflow),即多余的字符超出了指定的目标空间。如果这些多余的字符只是占用了尚未使用的内存,就不会立即出现问题,但如果它们擦掉程序中的其他数据,会导致程序异常终止,因此有些人通过系统编程,利用gets()函数插入和运行一些破坏系统安全的代码。

5.7.2:fgets()函数(gets的替代品)
fgets()函数通过第2个参数限制读入的字符数来解决溢出的问题,该函数专门设计用于处理文件输入,所以一般情况下可能不太好用。
- fgets()函数的第2个参数指明了读入字符的最大数量。如果该参数是n,那么fgets()将读入n-1个字符,或者读到遇到第一个换行符为止;
- 如果fgets()读到一个换行符,会把它存储在字符串中,这点与gets()不同,gets()会丢弃换行符;
- fgets()函数的第3个参数指明要读入的文件,如果读入从键盘输入的数据,则以stdin(标准输入)作为参数,该标识符定义在stdio.h中;
- 与puts()函数不同,fputs()函数不在字符串末尾添加换行符;
- fgets()函数返回指向char的指针,如果一切顺利,该函数返回的地址与传入的第1个参数相同,但是,如果函数读到文件结尾,它将返回一个特殊的指针:空指针(null pointer)。该指针不会指向有效的数据,所以可用于标识这种特殊情况。在代码中可以用数字0来代替,不过在C语言中用宏NULL来代替更为常见(如果在读入数据时出现某些错误,该函数也返回NULL)。
- 系统使用缓冲的I/O,这意味着用户按下return键之前,输入都被存储在临时存储区(缓冲区)中,按下return键就在输入中增加了一个换行符,并把整行输入发送给fgets()。对于输出,fputs()把字符发送给另一个缓冲区,当发送换行符时,缓冲区中的内容被发送到屏幕上;
/*Date: 2024\1\14
Function:fgets()函数示例
*/
#include <stdio.h>
#define STLEN 10
int main(void)
{
char words[STLEN];
int i;
puts("enter strings(empty line to quit):");
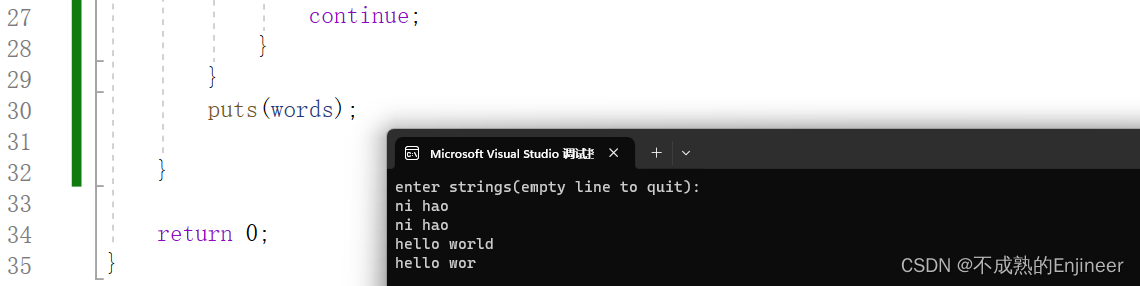
while ((fgets(words, STLEN, stdin) != NULL) && (words[0] != '\n'))
{ //当fgets函数没有读到文件末尾并且输入的第一个字符不是换行符时
i = 0;
while ((words[i] != '\n') && (words[i] != '\0')) //遍历字符串直到遇到换行符或空字符
{
i++;
}
if (words[i] == '\n') //如果遇到换行符,将其替换成空字符
{
words[i] = '\0';
}
else //如果遇到空字符,else部分丢弃输入行的剩余字符
{
while (getchar() != '\n')
{
continue;
}
}
puts(words);
}
return 0;
}
5.7.3:gets_s()函数
- C11新增的gets_s()函数和fgets()类似,用一个参数限制读入的字符数;
gets_s(words, STLEN); - gets_s()只从标准输入中读取数据,所以不需要第3个参数;
- gets_s()读到换行符,会丢弃它而不是存储它;
- 如果gets_s()读到最大字符数都没有读到换行符,会执行以下几步,首先把目标数值中的首字符设置为空字符,读取并丢弃随后的输入直至读到换行符或文件结尾,然后返回空指针。接着调用依赖实现的"处理函数"(或者你选择的其他函数),可能会终止或退出程序;
5.7.4:s_gets()函数
char* s_gets(char *st, int n)
{
char* ret_val;
int i = 0;
ret_val = fgets(st, n, stdin); //如果fgets()返回NULL,说明读到文件结尾或出现读取错误
if (ret_val) //即ret_val != NULL
{
while (st[i] != '\n' && st[i] != '\0')
i++;
if (st[i] == '\n') //如果字符串出现换行符,就用空字符替换它
st[i] = '\0';
else
while (getchar() != '\n') //如果字符串出现空字符,就丢弃输入行的其余字符,然后
continue; //返回与fgets()相同的值。
}
return ret_val;
}
5.7.5:为什么要丢弃过长输入行中的余下字符?
为什么要丢弃过长输入行中的余下字符?因为:初入行中多出来的字符会被留在缓冲区,成为下一次读取语句的输入。丢弃输入行余下的字符是为了保证读取语句与键盘输入同步。
5.8:字符串输出
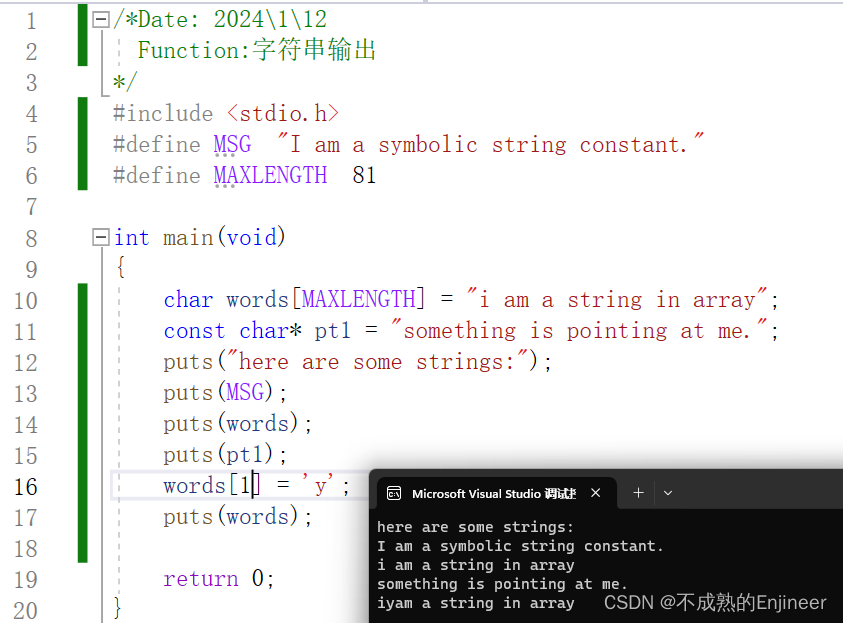
5.8.1:puts()函数
- puts()函数很容易使用,只需把字符串的地址作为参数传递给它即可;
- puts()函数只显示字符串,而且自动在显示的字符串末尾加上换行符;
- 与puts()函数不同,fputs()函数不在字符串末尾添加换行符;
- 该函数在遇到空字符时就停止输出,所以必须确保有空字符;
- 用双引号括起来的内容是字符串常量,且被视为该字符串的地址,存储字符串的数组名也被看作是地址;
/*Date: 2024\1\12
Function:字符串输出
*/
#include <stdio.h>
#define MSG "I am a symbolic string constant."
#define MAXLENGTH 81
int main(void)
{
char words[MAXLENGTH] = "i am a string in array";
const char* pt1 = "something is pointing at me.";
puts("here are some strings:");
puts(MSG);
puts(words);
puts(pt1);
words[1] = 'y';
puts(words);
return 0;
}
5.8.2:fputs()函数
- fputs()函数是puts()针对文件定制的版本;
- fputs()函数的第2个参数指明要写入数据的文件,如果要打印在显示器上,可以用定义在stdio.h中的stdout作为该参数;
- 与puts()不同,fputs()不会在输出的末尾添加换行符;
5.9:把字符串转化为数字
- C要求用数值形式进行数值运算,但在屏幕上显示数字则要求以字符串形式,因为屏幕显示的是字符,printf()和sprintf()函数,通过%d和其他转换说明,把数字从数值形式转换为字符串形式,scanf()可以把输入字符串转换为数值形式;
- atoi()、atol、atof()函数把字符串形式的数字分别转换成int、long、double类型的数字
- strtol()、strtoul()、strtod()函数把字符串形式的数字分别转换成long、unsigned long、double类型的数字;
六:printf()与scanf()函数
6.1:printf函数输出百分号(%)
由于printf()函数使用%符号来标识转换说明,因此当需要输出%的时候就需要用两个%%。
如果直接printf函数打印%会发现输出的是空白,如图所示:

其实要输出%很简单,就是加两个%%,如图所示:

6.2:printf()的转换说明修饰符与标记
在%和转换字符之间插入修饰符可修饰基本的转换说明。更多转换说明修饰符参考C Primer Plus第71页。
| 修饰符 | 含义 |
|---|---|
| 标记 | -、+、空格、#、0;示例“%-10d” |
| 数字 | 最小字段宽度,如果该字段不能容纳待打印的数字或字符串,系统会使用更宽的字段;例“%4d” |
| 点+数字 | 精度。对于%e、%E、%f:表示小数点右边数字的位数;对于%G、%g转换:表示有效数字的最大位数;对于%s转换:表示待打印字符的最大数量;对于整形转换:表示待打印数字的最小位数;例如"%5.2f"打印一个浮点数,字段宽度为5字符,其中小数点后面有两位数字 |
| h | 和整型转换说明一起使用,表示short int或unsigned short int类型的值;例:”%hu“、”%hx“、”%6.4hd“ |
| z | 和整型转换说明一起使用,表示size_t类型的值。size_t是sizeof返回的类型;例:”%zd“、”%12zd“ |
标记
| 标记 | 含义 |
|---|---|
| - | 待打印项左对齐。例:“%-20d” |
| + | 有符号值若为正,则值前面显示加号;若为负,则在值前面显示减号。例:“%+6.2f” |
| 空格 | 有符号值为正,值前面不显示任何符号;若为负,则在值前面显示减号标记并覆盖空格; 例:“% 6.2f” |
| # | 把结果转换为另一种形式。如果是%0格式,则以0开始;如果是%x或%X格式,则以0x或0X开始;对于所有的浮点格式,#保证了即使后面没有任何数字,也打印一个小数点字符。对于%g和%G格式,#防止结果后面的0被删除 |
| 0 | 对于数值格式,用前导0代替空格填充字段宽度。对于整数格式,如出现-标记或指定精度,则忽略该标记。 例:“%010d”、“%08.3f” |
6.3:printf()的返回值
printf()函数也有返回值,它返回打印字符的个数(将空格,换行符包含在内。),如果有错误则返回一个负值。
如图:
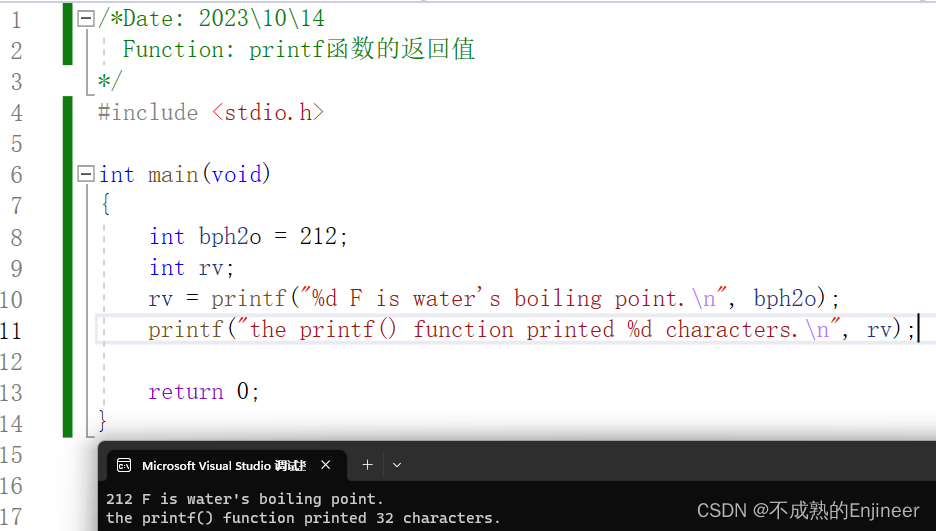
程序:
/*Date: 2023\10\14
Function: printf函数的返回值
*/
#include <stdio.h>
int main(void)
{
int bph2o = 212;
int rv;
rv = printf("%d F is water's boiling point.\n", bph2o);
printf("the printf() function printed %d characters.\n", rv);
return 0;
}
6.4:scanf()函数的三种用法
scanf()函数的三种用法:
- scanf(“输入控制符”,输入参数);
将从键盘输入的字符(操作系统规定从键盘输入的都是字符,例如键盘输入21,不是数字21,而是字符21)转化为输入控制符所规定格式的数据,然后存入以输入参数的值为地址的变量中。
#include <stdio.h>
int main()
{
int i;
scanf("%d",&i); //&i表示i的地址,&是一个取地址符。
return 0;
}
- scanf(“非输入控制符+输入控制符”,输入参数),非输入控制符必须原样输入。
#include <stdio.h>
int main()
{
int i;
scanf_s("key%d", &i); //key123正确的输入,123非法的输入
printf("i = %d\n", i);
return 0;
}//scanf()中加一个非输入控制符,则必需先输入非输入控制符key
- scanf()多个输入控制符。
#include <stdio.h>
int main()
{
int i, j, k;
scanf_s("%d,%d,%d", &i, &j, &k); //输入时i,j,k数字时必须加逗号
printf("i = %d, j = %d, k = %d\n", i, j, k);
return 0;
}
6.5:scanf()对用户非法输入的处理
/*Date: 2023\11\1
Function: scanf()对用户非法输入的处理
*/
#include <stdio.h>
int main()
{
int i, j;
char ch;
scanf_s("%d", &i);
printf("i = %d\n", i);
while ((ch = getchar()) != '\n') //当用户输入非法字符时,getchar()获取之,如果不是“换行符”,
continue; //则执行continue语句,while()中继续判断用户的输入是否为合法数据,
//直至用户输入合法的字符,跳出while循环。
//要注意的是“回车键”也是换行符'\n'。
scanf_s("%d", &j);
printf("j = %d\n", j);
return 0;
}
如图:

6.6:scanf()的读取规则
除了%c模式,scanf()在读取输入时会则跳过非空白字符串前的所有空白字符,然后一直读取字符,直到遇到空白字符(制表符、空格、换行符)或与正在读取字符不匹配的字符。
假设scanf()根据一个%d转换说明读取一个整数,scanf()函数每次读取一个字符,跳过所有空白字符,直至遇到第一个非空白字符才开始读取。因为要读取整数,所以scanf()函数希望发现一个数字字符或者一个符号(+或-),如果找到一个数字或符号,它便保存该字符,并读取下一字符,scanf()不断地读取和保存字符,直至遇到非数字字符,它便认为读到了整数的末尾,然后,scanf()把非数字字符放回输入。 这意味着程序在下一次读取输入时,首先读到的是上一次读取丢弃的非数字字符。最后,scanf()计算已读取数字(可能还有符号)相应的数值,并将计算后的值放入指定的变量中。
代码:
/*Date: 2023\10\10
Function: scanf函数读取时注意的点
*/
#include <stdio.h>
#define PRAISE "You are an extraordinary being."
int main()
{
char name[40];
printf("what is your name?\n");
scanf_s("%s", name, 40);
printf("hello, %s, %s", name, PRAISE);
return 0;
}
//你不用把空字符放在字符串的结尾,scanf_s()在读取输入时就已完成这项工作
//也不用在字符串常量PRAISE末尾添加空字符,PRAISE后面双引号括起来的文本是一个字符串,编译器
//会在末尾加上空字符。
运行结果:
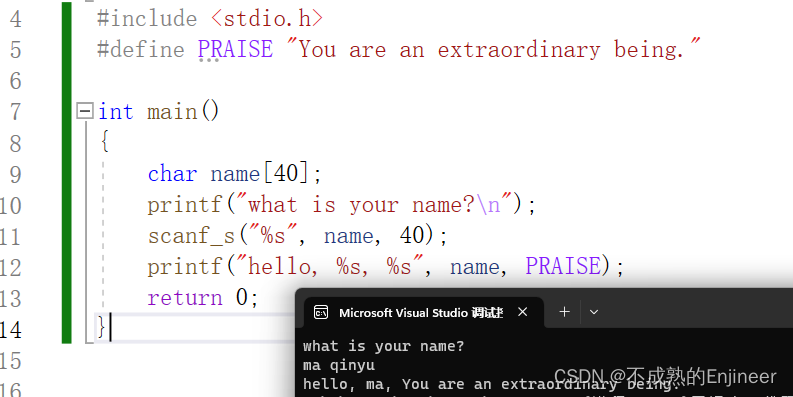
- 你不用把空字符放在字符串的结尾,scanf_s()在读取输入时就已完成这项工作,也不用在字符串常量PRAISE末尾添加空字符,PRAISE后面双引号括起来的文本是一个字符串,编译器会在末尾加上空字符。
- 当你输入自己的姓名时,如zhang san; scanf()函数只读取了zhang san中的zhang,它在遇到第1个空白(空格、制表符或换行符)时就不在读取输入。
- C语言中还有其他的输入函数,如fgets();用于读取一般字符串。
- scanf()运行时,我们输入完字符串后按下的回车键也会被存储在缓冲区。
- 因为输入是缓冲的,只有当用户输入Enter键后数字才会被发给程序。
6.6.1:scanf()读取字符串
scanf()函数有两种方法确定输入结束,无论哪种方法,都从第1个非空白字符作为字符串的开始,如果使用%s转换说明,以下一个空白字符(空行,空格,制表符或换行符)作为字符串的结束。(字符串不包含空白字符)
在%s转换说明中使用字段宽度可防止溢出。例:scanf("%5s", name)
6.7:scanf()中%c输入控制符
除了%c,其他转换说明都会自动跳过待输入值前面所有的空白。因此,scanf(“%d%d”,&n, &m)与scanf(“%d %d”,&n, &m)的行为相同。
scanf(“ %c",&n),scanf()会跳过空格,从输入的第1个非空白字符开始读取。而scanf(“%c",&n)时,从输入的第一个字符读取。
根据%c转换说明,scanf()函数一次只能从输入中读取一个字符,而且当用户按下Enter键时,scanf()函数会生成一个换行字符(\n)。
6.8:scanf()的返回值
- scanf()函数返回成功读取的项数。如果没有读取任何项,且需要读取一个数字而用户却输入一个非数值字符串,scanf()便返回0。
- scanf()返回成功读取项的数量,如果scanf()成功读取一个整数,就会返回1,如果成功读取两个整数,则返回2。
- 当scanf()监测到文件结尾或遇到硬件问题时,返回EOF。(EOF是stdio.h中定义的特殊值,通常用#define指令把其定义为-1。)
- scanf()返回类型是int。
6.8.1:利用scanf()的返回值求和
/*Date: 2023\11\2
Function: scanf的返回值
*/
#include <stdio.h>
int main(void)
{
long num;
long sum = 0L; //Long类型的0
int status;
printf("请输入加数(按q键结束):");
status = scanf_s("%ld", &num);
while (1 == status) //当用户的输入非数字时,scanf会返回0。
{
sum = sum + num;
printf("请输入加数(按q键结束):");
status = scanf_s("%ld", &num);
}
printf("和为:%ld\n", sum);
return 0;
}
6.9:printf()的*修饰符
若不想预先指定字段宽度,希望通过程序来指定,那么可以使用*修饰符来替代字段宽度,但是需要用一个参数来告诉函数,字段宽度应该是多少。即:如果转换说明是%(星号)d,那么参数列表中应该包含(星号)和d对应的值。
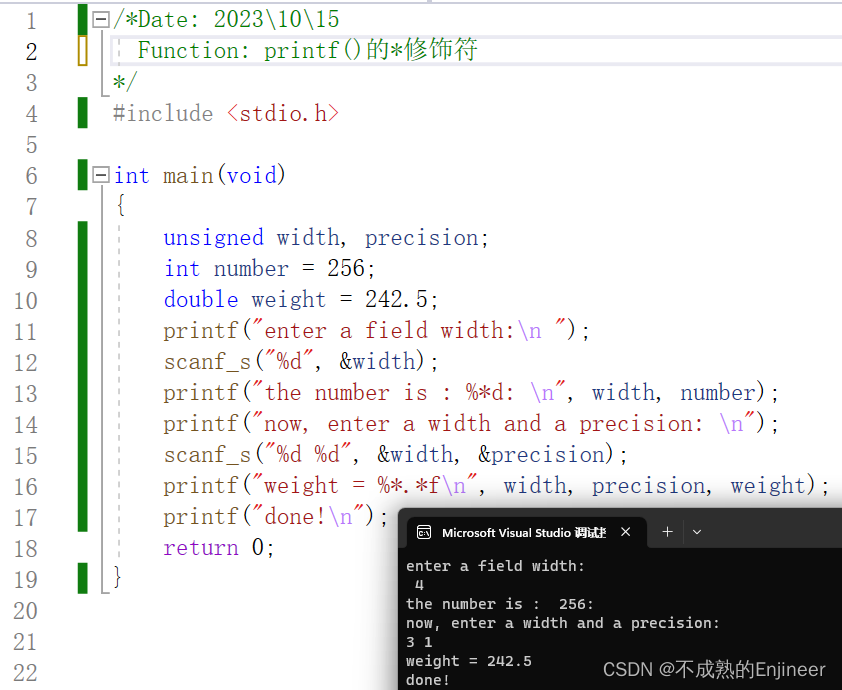
/*Date: 2023\10\15
Function: printf()的*修饰符
*/
#include <stdio.h>
int main(void)
{
unsigned width, precision;
int number = 256;
double weight = 242.5;
printf("enter a field width:\n ");
scanf_s("%d", &width);
printf("the number is : %*d: \n", width, number);
printf("now, enter a width and a precision: \n");
scanf_s("%d %d", &width, &precision);
printf("weight = %*.*f\n", width, precision, weight);
printf("done!\n");
return 0;
}
6.10:scanf()的*修饰符
scanf()中的*修饰符用法与printf()不同,把星号修饰符放在%与转换字符之间时,会使scanf()跳过相应的输入项。在程序需要读取文件中的特定列时,这项跳过功能很有用。如%*d是为跳过输入的整数型数据;%*s为跳至下一个空白字符。

/*Date: 2023\10\15
Function: scanf()的*修饰符
*/
#include <stdio.h>
int main(void)
{
int n;
printf("please enter threee integers:\n");
scanf_s("%*d %*d %d", &n);
printf("the last integer was %d\n", n);
return 0;
}
6.11:Visual Studio中使用scanf_s读取字符串
在Visual Studio中使用scanf_s读取字符串时要指定最大读入的字符数,即缓冲区边界,以避免缓冲区溢出的问题。字符串长度可以直接设置一个大于字符串真实长度的数字(至少比真实长度大一位,用来存放’\0’;也可以使用sizeof(字符串名))
char str[20];
scanf_s("%s", s.name); //字符串读取失败
scanf_s("%s", s.name, sizeof(s.name)); //字符串读取成功
scanf_s("%s", s.name, MaxSize); //字符串读取成功
七:运算符
7.1:运算符的分类
该表涵盖了所有的数值关系。(数字之间的关系再复杂也没有人与人之间的关系复杂。)
| 算术运算符 | +(加);-(减);*(乘);/(除);%(取余) |
|---|---|
| 关系运算符 | >(大于);>=(大于等于);<(小于);<=(小于等于); !=(不等于);==(等于) |
| 逻辑运算符 | !(非);&&(与); ||(或) |
| 赋值运算符 | =; +=;*=;/=;-= |
7.2:运算符的优先级别
算术 > 关系 > 逻辑 > 赋值
7.3:除法与取余运算符的注意点
-
除法运算中:两个数都是整数,则商为整数(C语言中,整数除法结果的小数部分被丢弃,这个过程被称为截断。);若被除数与除数中有一个或两个为浮点数,则商为浮点数。
例: 16/5= =3;
16/5.0= =3.20000; -
取余%的运算对象必须是整数,结果是整除后的余数,余数的符号与被除数相同。
例:13%3= =1;
13%(-3)== 1;
-13%3 = = (-1)
/*Date: 2023\10\17
Function: 使用取余运算符把秒数换成分和秒
*/
#include <stdio.h>
#define SEC_PER_MIN 60 //一分钟60秒
int main(void)
{
int sec, min, left;
printf("convert seconds to minutes and seconds!\n");
printf("enter the number of seconds:\n");
scanf_s("%d", &sec);
while (sec > 0)
{
min = sec / SEC_PER_MIN; //截断分钟数
left = sec % SEC_PER_MIN; //剩下的秒数
printf("%d seconds is %d minutes, %d seconds.\n", sec, min, left);
printf("enter next value:\n");
scanf_s("%d", &sec);
}
printf("done");
return 0;
}
7.4:&&与运算的注意点
&&与运算的左表达式若为假,则右边的表达式便不会执行。同理||运算的左边表达式为真时,右边的表达式便不会执行。
#include <stdio.h>
int main()
{
int i = 10;
int k = 20;
int m;
m = (1 > 2) && (k = 4); //&&运算如果左边的表达式为假,右边的表达
printf("m = %d, k = %d\n",m, k); //式便不会执行
return 0;
}
7.4.1:&&用于测试范围时的注意事项
现实中的关系有时不能直接用于程序中,例如要对学生成绩进行等级判断,现实中判断一般为90 =< score =< 100;然而这种方式是不能用于程序中的,因为编译器会将该测试表达式解释为:
(90 =< score) =< 100
如此,子表达式90 =< score的值要么是1,要么是0。这两个值都小于100。所以不管score的值是多少,整个表达式都恒为真。因此,在测试范围中要使用&&。如下例:
/*2023\10\7*/
#include <stdio.h>
int main()
{
float score; //学生分数
printf("请输入您的分数:");
scanf_s("%f", &score);
if (score > 100)
printf("做梦!\n");
else if ((score >= 60) && (score <= 100)) //不能写成60<= score <=100
printf("及格!\n");
else if ((score >= 0) && (score < 60))
printf("不及格!\n");
return 0;
}
/*if语句默认只能控制一个语句的执行或不执行*/
7.4.2:&&用于确定要一个字符是否为小写字母
许多代码都用范围测试来确定一个字符是否是小写字母。
char ch;
if ((ch >= 'a') && (ch <= 'z'))
{
printf("that's a lowercase character.\n");
}
但该方法只对ASCII这样的字符编码有效,这些编码中相邻字母与相邻数字一 一对应。但是对于EBCDIC这样的代码就没用了。相应的可移植方法是,用ctype.h系列中的islower()函数。无论哪种特定的字符编码,islower()函数都能正常运行。
if (islower(ch))
{
printf("that's a lowercase character.\n");
}
7.5:指数运算
C的标准数学库中提供了pow()函数用于指数运算。pow(3.5, 2.2)返回的是3.5的2.2次幂。
/*Date: 2023\10\17
Function: 指数运算
*/
#include <stdio.h>
#include <math.h>
int main(void)
{
int a = 4;
int b;
b = pow(a, 3);
printf("%d\n", b);
return 0;
}
7.6:赋值运算符(=)的注意点
- 在C语言中,=并不意味着相等,而是一个赋值运算符。
- 赋值运算符把一个值赋给它的左侧变量。如 number = 31;表示把值31赋给number。
- 赋值行为从右往左进行。赋值运算符左侧必须引用一个存储位置。
7.6.1:数据对象、左值、右值
数据对象:赋值表达式的语句目的是把值存储到内存位置上。用于存储值的数据储存区域统称为数据对象。使用变量名是标识变量的一种方法。
左值:用于标识或定位存储位置的标签。
右值:指能赋值给可修改左值的量,且本身不是左值。
7.6.2:关系相等运算符(==)的小技巧
为了避免赋值运算符与关系相等运算符的混淆错误,有经验的程序员在建构比较是否相等的表达式时,习惯于把常量放在左侧。例如:5==number。这样做的原因是因为C语言不允许给常量赋值,编译器会把赋值运算符的这种用法作为语法错误标记出来。
7.7:递增运算符(++)与递减运算符(- -)
7.7.1:递增、递减运算符的优点
- 使程序更精炼。
- 因为递增递减运算符和实际的机器语言指令很相似,所以其生成的机器语言代码效率更高。(但随着C编译器的智能化,这一优势可能会消失。)
- 递增运算符和递减运算符都有很高的结合优先级,只有小括号的优先级比它们高。
7.7.2:递增、递减运算符的注意点
- 如果一个变量出现在一个函数的多个参数中,不要对该变量使用递增或递减运算符。
- 如果一个变量多次出现在一个表达式中,不要对该变量使用递增或递减运算符。
- 编程时应该尽量屏蔽掉前自增和后自增的差别。
- 递增、递减运算符最好单独一个语句出现,不要把它作为一个完整符合语句的一部分来使用。
7.7.3:前缀递增运算符与后缀递增运算符的区别(++i与i++)
++i是先递增,然后再使用i的值; i++是先使用i的值,然后再递增i;
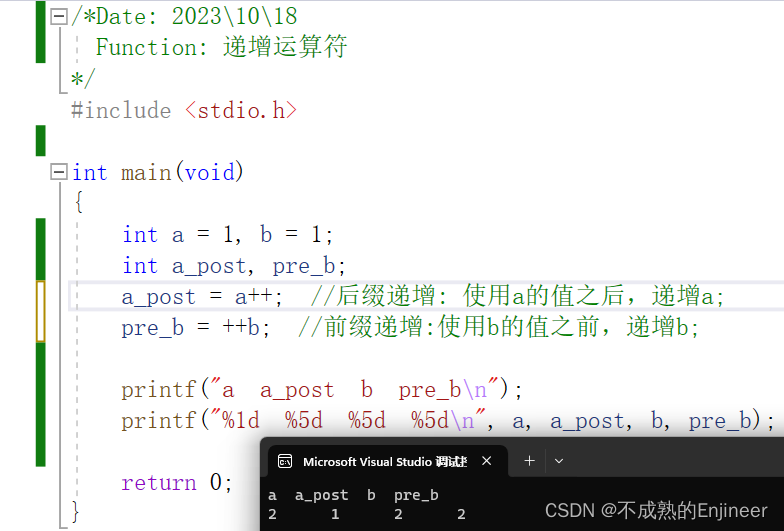
/*Date: 2023\10\18
Function: 递增运算符
*/
#include <stdio.h>
int main(void)
{
int a = 1, b = 1;
int a_post, pre_b;
a_post = a++; //后缀递增: 使用a的值之后,递增a;
pre_b = ++b; //前缀递增:使用b的值之前,递增b;
printf("a a_post b pre_b\n");
printf("%1d %5d %5d %5d\n", a, a_post, b, pre_b);
return 0;
}
7.7.4:前缀递减运算符与后缀递减运算符的区别(–i与i–)
--i是使用i的值之前,递减i;i–是使用i的值之后,递减i;
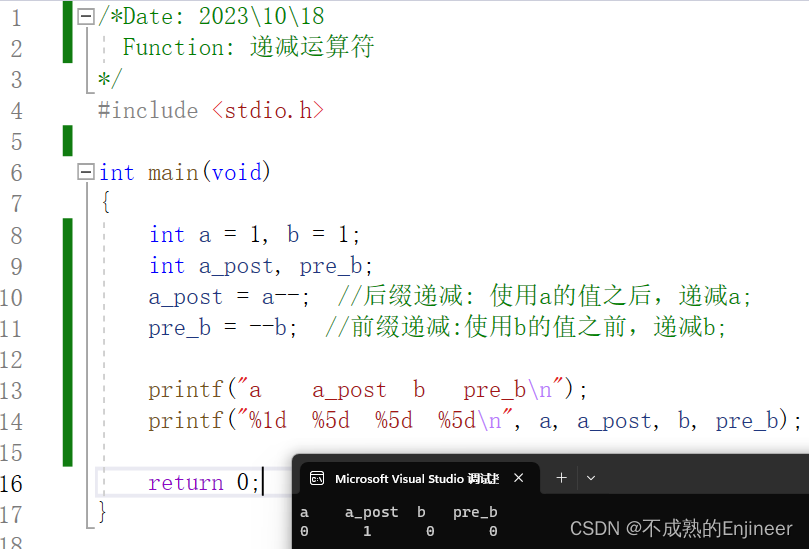
/*Date: 2023\10\18
Function: 递减运算符
*/
#include <stdio.h>
int main(void)
{
int a = 1, b = 1;
int a_post, pre_b;
a_post = a--; //后缀递减: 使用a的值之后,递减a;
pre_b = --b; //前缀递减:使用b的值之前,递减b;
printf("a a_post b pre_b\n");
printf("%1d %5d %5d %5d\n", a, a_post, b, pre_b);
return 0;
}
7.8:三目运算符(条件运算符)
- 带3个运算对象的运算符称为三元运算符,条件运算符是C语言中唯一的三元运算符。
- 条件运算符的第2个和第3个运算对象可以是字符串。
格式:A?B:C
等价于:
if (A)
{
B;
}
else
{
C;
}
7.8.1:三目运算符(条件运算符)示例
/*Date: 2023\11\27
Function: 条件运算符示例
*/
#include <stdio.h>
#define COVERAGE 350 //每罐油漆可以刷的面积
int main(void)
{
int sq_feet; //房间的面积
int cans; //需要油漆的罐数
printf("Enter number of square feet to be painted: \n");
while(scanf_s("%d", &sq_feet) == 1)
{
cans = sq_feet / COVERAGE;
cans += (sq_feet % COVERAGE == 0) ? 0 : 1;
printf("You need %d %s of paint.\n", cans, (cans == 1) ? "can" : "cans");
printf("enter next value (q to quit): \n");
}
return 0;
}
7.9:逗号表达式
格式:(A,B,C,D);
功能:从左到右执行,最终表达式的值是最后一项的值。
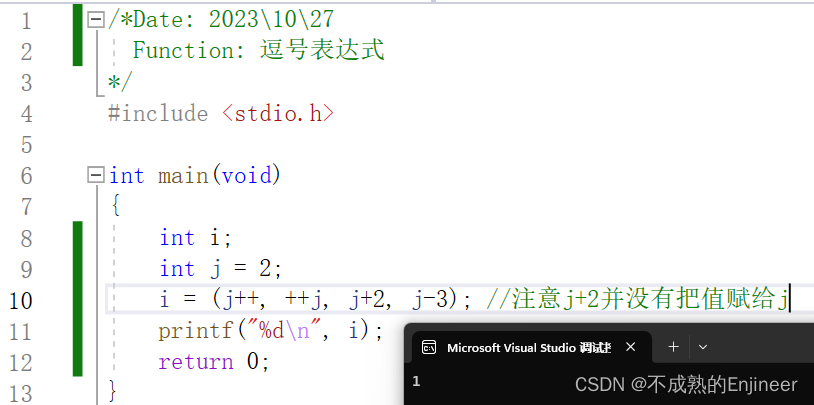
/*Date: 2023\10\27
Function: 逗号表达式
*/
#include <stdio.h>
int main(void)
{
int i;
int j = 2;
i = (j++, ++j, j+2, j-3); //注意j+2并没有把值赋给j
printf("%d\n", i);
return 0;
}
7.9.1:逗号运算符结合for语句
逗号运算符把两个表达式连接成一个表达式,并保证最左边的表达式最先求值。逗号运算符通常在for循环头的表达式中用于包含更多信息,整个逗号表达式的值是逗号右侧表达式的值。
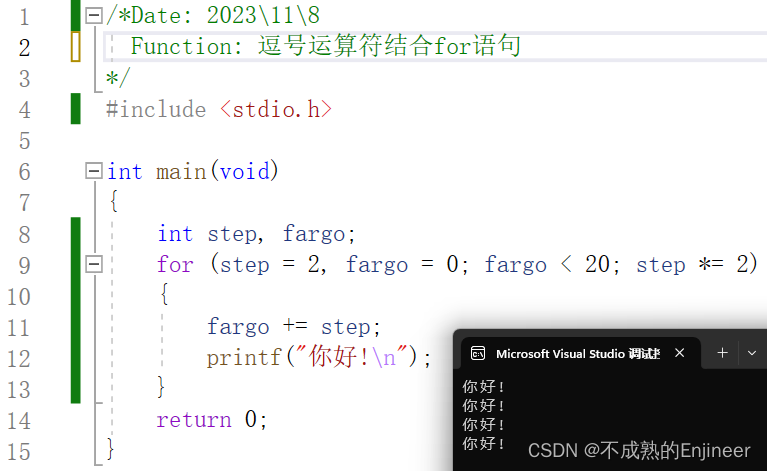
/*Date: 2023\11\8
Function: 逗号运算符结合for语句
*/
#include <stdio.h>
int main(void)
{
int step, fargo;
for (step = 2, fargo = 0; fargo < 20; step *= 2)
{
fargo += step;
printf("你好!\n");
}
return 0;
}
7.9.2:给变量赋值时,不小心输入了逗号
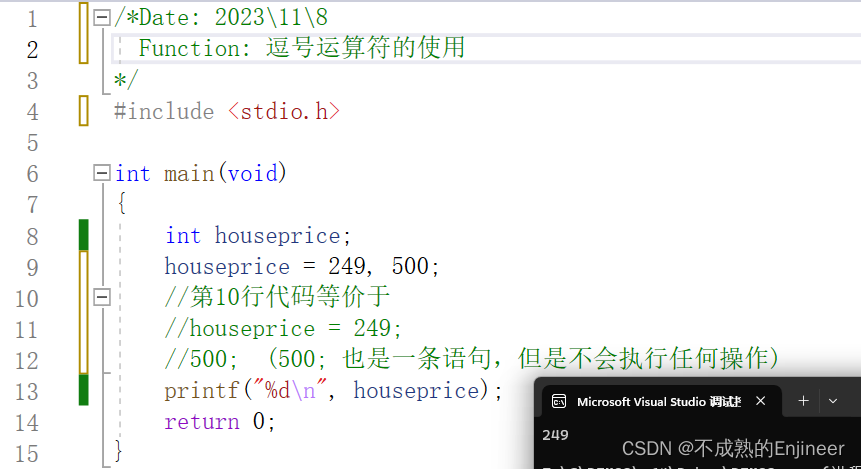
7.10:逻辑运算符的备选拼写:iso646.h头文件
C语言是在美国用标准美式键盘开发的语言,但在世界各地并非所有键盘都有和美式键盘一样的符号。因此,C99标准新增了可以代替逻辑运算符的拼写,它们被定义在iso646.h头文件中。
| 传统写法 | iso646.h |
|---|---|
| && | and |
| || | or |
| ! | not |
八:流程控制
8.1:什么是流程控制?
流程控制是程序代码执行的顺序。
8.2:流程控制的分类
顺序、选择、分类。一个无论多么复杂的程序都可以用这三种分类解决。
8.3:if语句
8.3.1:if语句的控制范围
if语句默认只能控制一个语句的执行或不执行,如果想控制多个语句的执行与不执行就必须把这些语句用花括号括起来。while语句与for语句也是如此,默认只能控制一个语句的执行或不执行。
8.3.2:if…else、if…else if语句
if…else是一个语句,执行if里的代码,就不执行else里的代码。同理if…else if语句也是如此,执行if语句便不会执行else if里的语句。
else在没有括号的情况下就近原则。
#include <stdio.h>
int main()
{
if (3 > 2)
{
printf("您好");
}
else if (3 > 1)
{
printf("hello");
}
return 0;
}
8.4:循环
8.4.1:循环的定义
某些代码会被重复执行。
8.4.2:循环的分类
- for
- while
- do…while
8.4.3:for语句
for (语句1; 语句2; 语句3)
{
语句4;
}
/*for循环先执行语句1,然后对语句2进行判断,若为真,则执行语句4,最后再执行语句3,
执行完语句3后,再对语句2进行判断。若为假,则直接结束for循环。 */
- for语句的更新部分,即语句1中的更新的变量不能定义为浮点类型。因为float类型不能很精确的存储小数。
- for语句循环的次数为语句2中的量减去语句1中的量。
8.4.4:for语句与多重for语句的循环次数

8.4.5:for语句表达式的省略(分号不能省略)
for语句可以省略一个或多个表达式。(但是不能省略分号)
例:
int i = 0;
for (i = 0; i < 10;)
{
i++;
}
又如:
int main(void)
{
int i = 0;
for (; i < 10; i++) //由此可以看出,第1个表达式可以执行其它语句,例如执行printf()语句
{
printf("1\n");
}
return 0;
}
再如:
int main(void)
{
for (; ; ) //省略第2个表达式被视为真,循环会一直运行。
{
printf("1\n");
}
return 0;
}
8.4.6:while语句
while语句是一种迭代语句,有时被称为结构化语句。因为它的结构比简单的赋值表达式语句复杂。
8.4.7:代码块
花括号({})以及被花括号括起来的部分被称为块(block)。
8.4.8:带有空语句的while语句
- 在C语言中,单独的分号表示空语句。

/*Date: 2023\11\2
Function: 带有空语句的while
*/
#include <stdio.h>
int main(void)
{
int num;
while (scanf_s("%d", &num) == 1) //只有当用户输入非空白和非数字时,循环才会跳出。
; //在C语言中,单独的分号表示空语句。
return 0;
}
8.4.9:只读每行的首字符
- 以下代码所做的只是读取并丢弃字符,由于最后丢弃的字符是换行符,所以下一个被读取的字符是下一行的首字母。
while (getchar() != '\n') //此行代码所做的只是读取并丢弃字符
{
continue;
}
8.4.10:do…while语句
do…while语句先执行,再判断。
do //do...while语句先执行,再判断
{
语句;
} while (表达式);
8.4.11:用do…while语句做一元二次方程
/*Date: 2023\10\31
Function: 用do...while做一元二次方程(注意scanf()函数的读取规则)
*/
#include <stdio.h>
#include <math.h>
int main(void)
{
double a, b, c;
double delta;
double x1, x2;
char ch;
do
{
printf("请输入一元二次方程的三个系数:\n");
printf("a = ");
scanf_s("%lf", &a);
printf("b = ");
scanf_s("%lf", &b);
printf("c = ");
scanf_s("%lf", &c);
delta = (b * b) - (4 * a * c);
if (delta > 0)
{
x1 = (-b + sqrt(delta)) / (2 * a);
x2 = (-b - sqrt(delta)) / (2 * a);
printf("有两个解,x1 = %lf, x2 = %lf.\n", x1, x2);
}
else if (0 == delta)
{
x1 = x2 = (-b) / (2 * a);
printf("有唯一解, x1 = x2 = %lf", x1);
}
else
{
printf("无解!\n");
}
printf("是否要继续?(Y/N)\n");
scanf_s(" %c", &ch);
//scanf(“ %c",&n),scanf()会跳过空格,从输入的第1个非空白字符开始读取。
//而scanf(“%c",&n)时,从输入的第一个字符读取。
//详情请参考6.6:scanf()的读取规则。
} while (('y' == ch) || ('Y' == ch));
return 0;
}
8.4.12:入口条件循环和出口条件循环
入口条件循环:while循环和for循环都是入口条件循环,即在循环的每次迭代之前检查测试条件,所有有可能根本不执行循环体中的内容。
出口条件循环:即在循环的每次迭代之后检查测试条件,这保证了至少执行一次循环体中的内容。
8.4.13:switch语句

- 所有case后面的常量表达式为姑且称为标签,这些标签只能是(1)枚举常量(枚举元素)、(2)数值常量、(3)字符常量、(4)常变量、(5)宏名的一种。注意普通变量,枚举变量是不能作为标签使用的。
- switch后面括号里的“表达式”应该是一个整数值(包括char类型),case标签必须是整数类型(包括char类型)。
- 执行完一个case语句后,流程控制就转移到下一个case语句继续执行。case常量表达式只是起语句标号的作用,并不是在该处进行条件判断。在执行switch语句时,根据switch()中表达式的值找到与之匹配的case子句,就从此case子句开始执行下去,不再进行判断。
- switch语句是选择不是循环,如果在switch中出现了break语句。该语句的功能只是退出switch语句转而去执行它下面的语句。在switch语句中出现continue语句是错误的,除非switch本身就属于for或while循环的一部分。
/*Date: 2023\10\31
Function: switch语句
*/
#include <stdio.h>
#include <math.h>
int main(void)
{
int floor = 0; //定义楼层
printf("请输入您要到达的楼层:");
scanf_s("%d", &floor);
switch (floor)
{
case 1:
printf("一楼到了!\n");
break;
case 2:
printf("二楼到了!\n");
break;
default:
printf("还没盖到这层!\n");
}
return 0;
}
8.4.14:具有多重标签的switch语句
char ch;
switch (ch)
{
case 'a':
case 'A': printf("AAAA!\n"); break;
case 'b':
case 'B': printf("BBBB!\n"); break;
default: break;
}
8.4.15:break
- break如果是用于循环,则起终止循环的作用,在多层循环中,break只能终止距离它最近的且包裹着它的循环。
- break如果用于switch语句,则是用于终止switch语句。
- break不能直接用于if,除非if属于循环内部的一个子句。
- 在多层switch嵌套中,break只能终止距离它最近的switch语句。
8.4.16:break不能直接用于if中
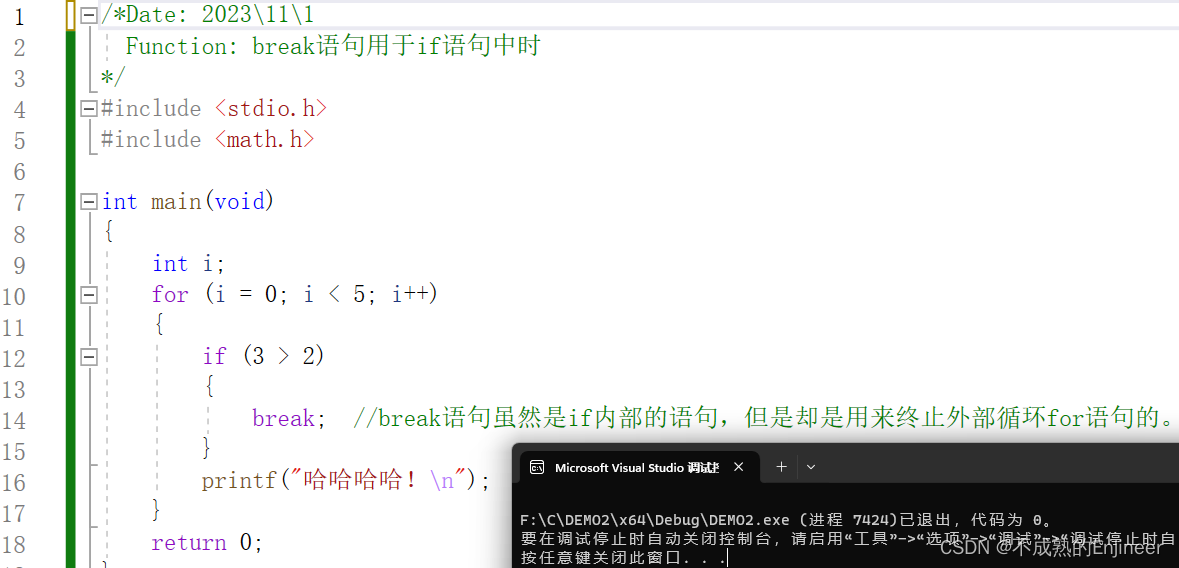
/*Date: 2023\11\1
Function: break语句用于if语句中时
*/
#include <stdio.h>
#include <math.h>
int main(void)
{
int i;
for (i = 0; i < 5; i++)
{
if (3 > 2)
{
break; //break语句虽然是if内部的语句,但是却是用来终止外部循环for语句的。
}
printf("哈哈哈哈!\n");
}
return 0;
}
8.4.17:在多层循环中,break只能终止距离它最近的循环
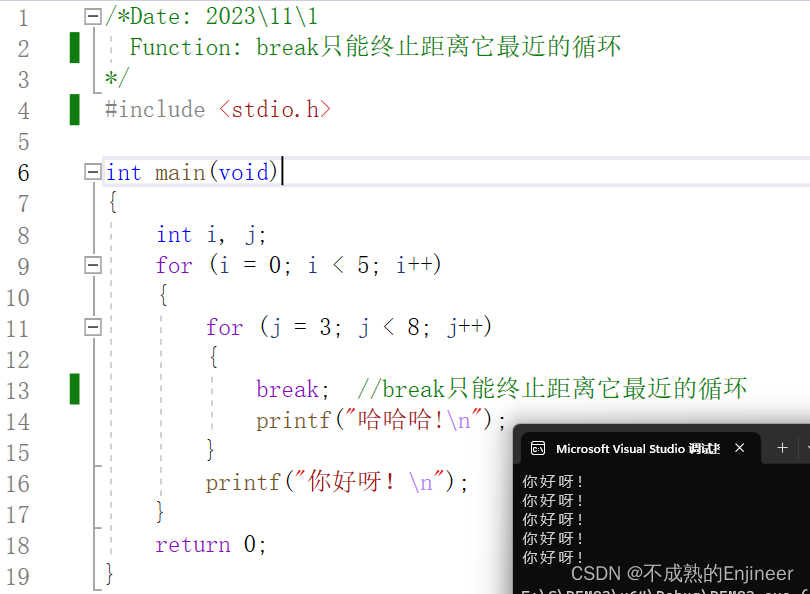
/*Date: 2023\11\1
Function: break只能终止距离它最近的循环
*/
#include <stdio.h>
int main(void)
{
int i, j;
for (i = 0; i < 5; i++)
{
for (j = 3; j < 8; j++)
{
break; //break只能终止距离它最近的循环
printf("哈哈哈!\n");
}
printf("你好呀!\n");
}
return 0;
}
8.4.18:continue
- 用于跳过本次循环余下的语句,转去判断是否需要执行下次循环。
- continue针对的是循环。
8.4.19:for与while语句中的continue

8.4.20:if语句中的continue

8.4.21:break语句与continue语句辨析
- break语句:所有的循环和switch语句都可以使用break语句。它使程序跳出当前循环或switch语句的剩余部分,并继续执行跟在循环或switch后面的语句。
- continue语句:所有循环都可以使用continue语句,但是switch语句不行。continue语句使程序控制跳出循环的剩余部分。对于while和for语句,程序执行到continue语句后会开始进入下一轮迭代。对于do…while循环,对出口条件求值后,如有必要会进入下一轮迭代。
8.4.22:goto语句
- goto语句使程序控制跳转至相应的标签语句。冒号用于分隔标签和标签语句。标签语句可以出现在goto的前面或后面。
- 原则上在C语言中要避免使用goto语句,因为其很容易导致代码逻辑混乱,但讽刺的是C语言中的goto语句比其它语言的goto语句好用,因为C允许在标签中使用描述性单词而不是数字。
- 如果程序正常执行到打标签的程序段时也是会执行标签里的语句的。
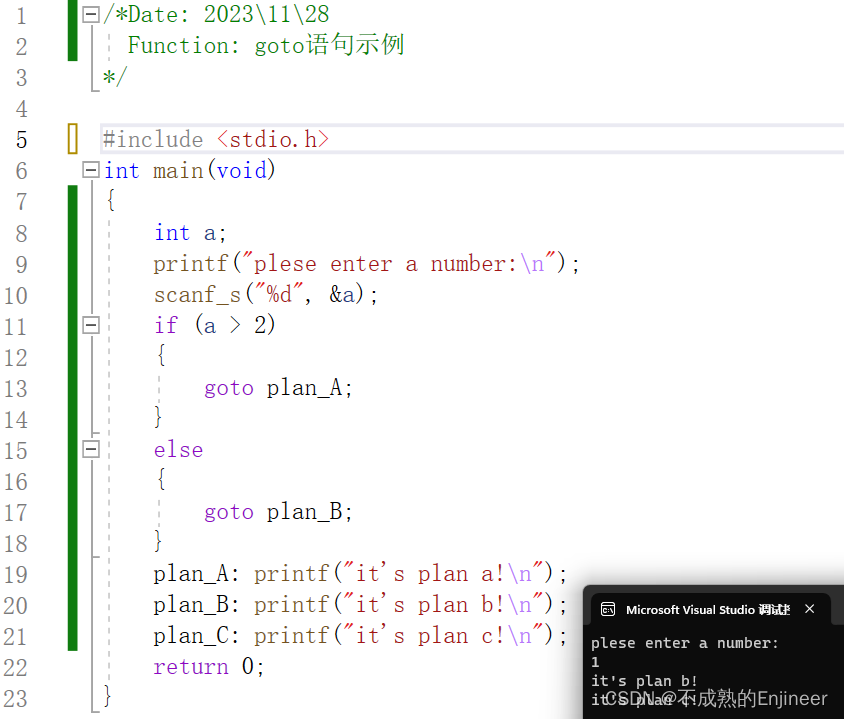
/*Date: 2023\11\28
Function: goto语句示例
*/
#include <stdio.h>
int main(void)
{
int a;
printf("plese enter a number:\n");
scanf_s("%d", &a);
if (a > 2)
{
goto plan_A;
}
else
{
goto plan_B;
}
plan_A: printf("it's plan a!\n");
plan_B: printf("it's plan b!\n");
plan_C: printf("it's plan c!\n");
return 0;
}
九:类型转换
9.1:类型的级别
类型级别从高到低依次是:long double、double、float、unsigned long long、long long、unsigned long、int。(当long和int的大小相同,unsigned int 比long级别高。)
注意 :
1:当作为函数参数传递时,char和short被转换成int;float被转换成double。
2:类型升级通常不会有什么问题,但类型降级可能会导致麻烦,因为较低类型可能放不下整个数字。
9.2:自动类型转换
在C语言中,许多类型转换都是自动进行的。char和short类型出现在表达式或作为函数参数时会被升级为int类型、float类型在函数参数中会被升级为double类型。
- 程序第17行演示了类型降级的示例,把ch设置为一个超出其类型范围的值,确切的说ch的值是1107%256,即83,ASCII码为S。
- 程序第18行将ch设置为一个浮点数,发生截断后,ch的值是字符p的ASCII码。
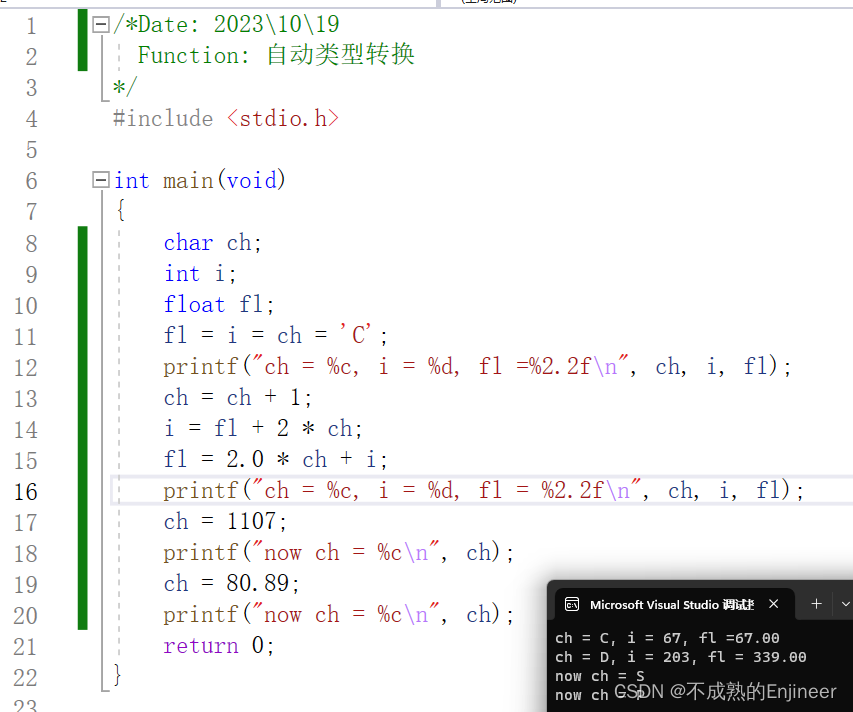
/*Date: 2023\10\19
Function: 自动类型转换
*/
#include <stdio.h>
int main(void)
{
char ch;
int i;
float fl;
fl = i = ch = 'C';
printf("ch = %c, i = %d, fl =%2.2f\n", ch, i, fl);
ch = ch + 1;
i = fl + 2 * ch;
fl = 2.0 * ch + i;
printf("ch = %c, i = %d, fl = %2.2f\n", ch, i, fl);
ch = 1107;
printf("now ch = %c\n", ch);
ch = 80.89;
printf("now ch = %c\n", ch);
return 0;
}
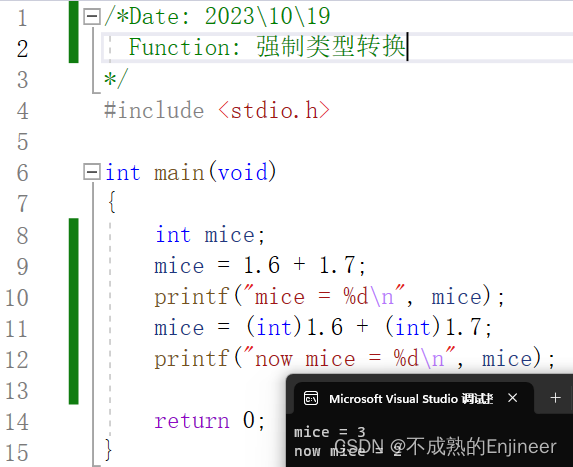
9.3:强制类型转换
格式:(数据类型)(表达式)
功能:把表达式的值强制转换为前面所指定的数据类型。使用强制类型转换可以明确表达转换类型的意图,保护程序免受不同版本编译器的影响。
/*Date: 2023\10\19
Function: 强制类型转换
*/
#include <stdio.h>
int main(void)
{
int mice;
mice = 1.6 + 1.7;
printf("mice = %d\n", mice);
mice = (int)1.6 + (int)1.7;
printf("now mice = %d\n", mice);
return 0;
}
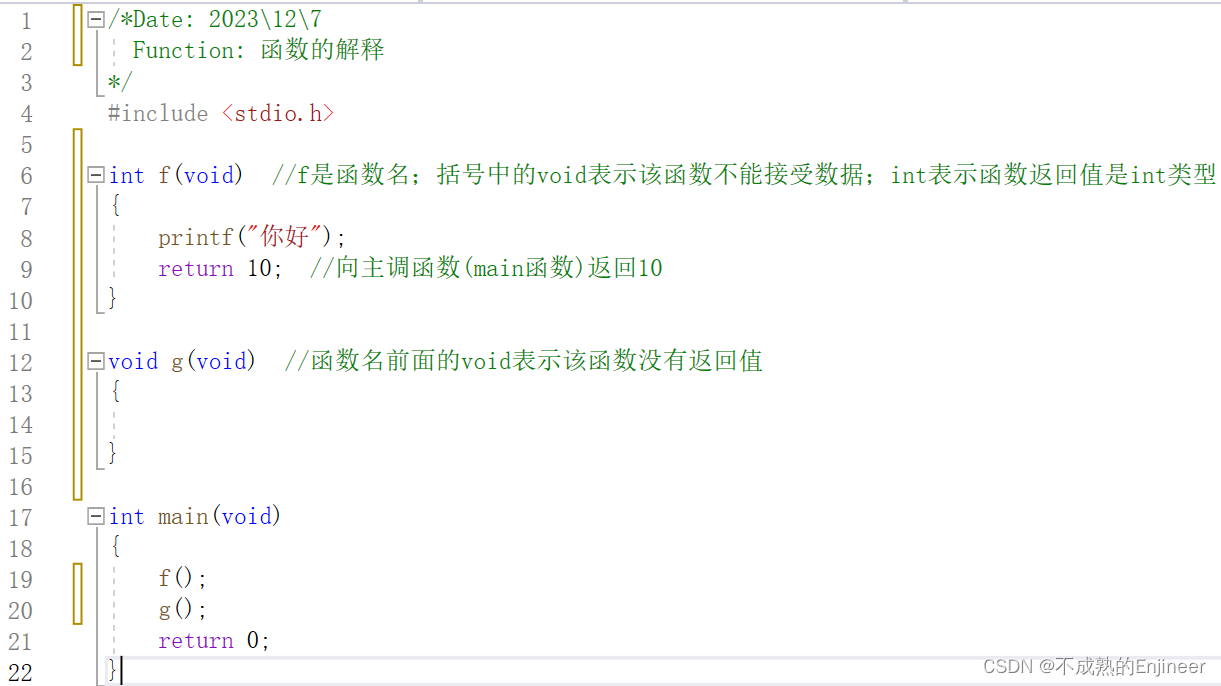
十:函数
10.1:为什么需要函数?
- 避免了重复性操作。
- 有利于程序的模块化。
10.2:什么是函数?
- 逻辑上:能够完成特定功能的独立的代码块。
- 物理上:能够接收或者不接受数据;能够对接收的数据进行处理;能够将数据处理的结果返回或者不返回。
- 总结:函数是个工具,它是为了解决大量类似问题而设计的。
- 函数是C语言的基本单位,类是JAVA、C#、C++的基本单位。
10.3:如何定义函数?
函数的返回值 函数的名字(函数的形参列表)
{
函数的执行体;
}
10.3.1:函数定义的本质
函数定义的本质是详细描述函数之所以能实现某个特定功能的具体方法。
10.3.2:函数的类型
函数的类型指的是函数返回值的类型,而不是函数参数的类型。因为如果函数名前的返回值类型和函数执行体中的return表达式中的类型不同的话,则最终的函数返回值类型以函数名前的返回值类型为准。
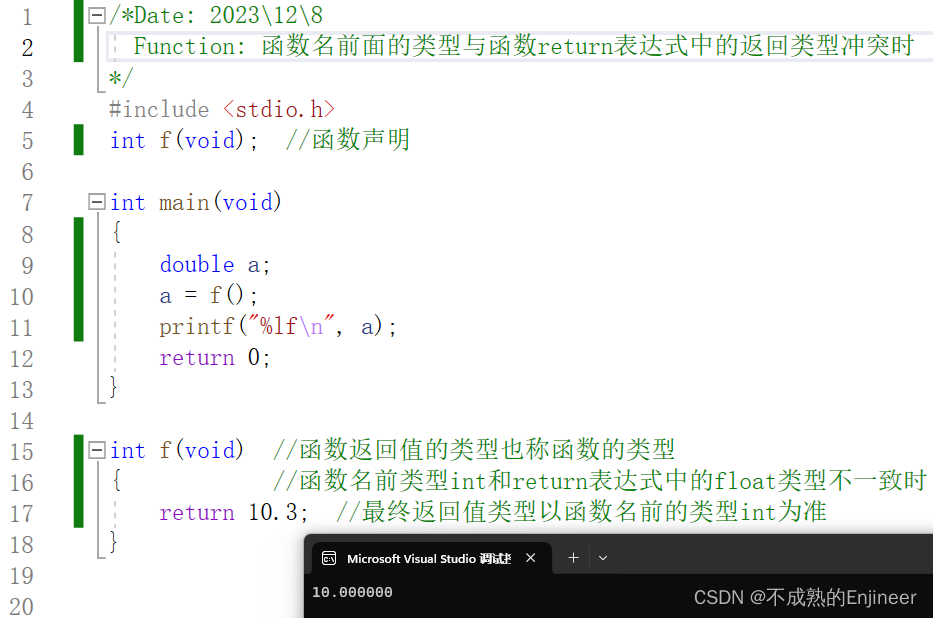
10.3.3:函数的分类
有参函数 和 无参函数;
有返回值函数 和 无返回值函数;
库函数 和 用户自定义函数;
普通函数 和 主函数(main函数)
10.3.4:函数签名
函数的返回类型和形参列表构成了函数签名。因此,函数签名指定了传入函数的值的类型和函数返回值的类型。
10.4:return
- 如果return的表达式为空,则只终止函数,不向被调函数返回任何值。
- break是用来终止循环和switch的,return是用来终止函数的。
10.4.1:return与exit()
如果main()在一个递归程序中,exit()仍然会终止程序,但是return只会把控制权交给上一级递归,直至最初的一级,然后return结束程序;return和exit()的另一个区别是:在其它函数中调用exit()也能结束整个程序。
10.5:如何理解主函数?
- 一个函数必须有且只能有一个主函数;
- 主函数可以调用普通函数,普通函数不能调用主函数;
- 普通函数可以相互调用;
- 主函数是程序的入口也是程序的出口;
- 主调函数把它的参数存储在被称为栈(Stack)的临时存储区,被调函数从栈中读取这些参数。
10.6:函数的声明
- 如果函数调用写在了函数定义的前面,则必须加函数前置声明。
- 函数前置声明的作用:1)告诉编译器即将出现的若干个字母代表的是一个函数。
2)告诉编译器即将出现的若干个字母所代表的函数的形参和返回值的具体情况。
3)函数声明是一个语句,所以末尾必须加分号。
4)对库函数的声明是通过#include<库函数所在的文件的名字>来实现的。
5)告诉编译器在别处查找该函数的定义。

10.7:形参与实参
- 声明函数就创建了形式参数,简称形参。
- 函数调用传递的值为实际参数,简称实参。
- 形参和实参个数相同,位置一一对应,数据类型必须相互兼容。
- 形式参数是被调函数中的变量,实际参数是主调函数赋给被调函数的具体值。
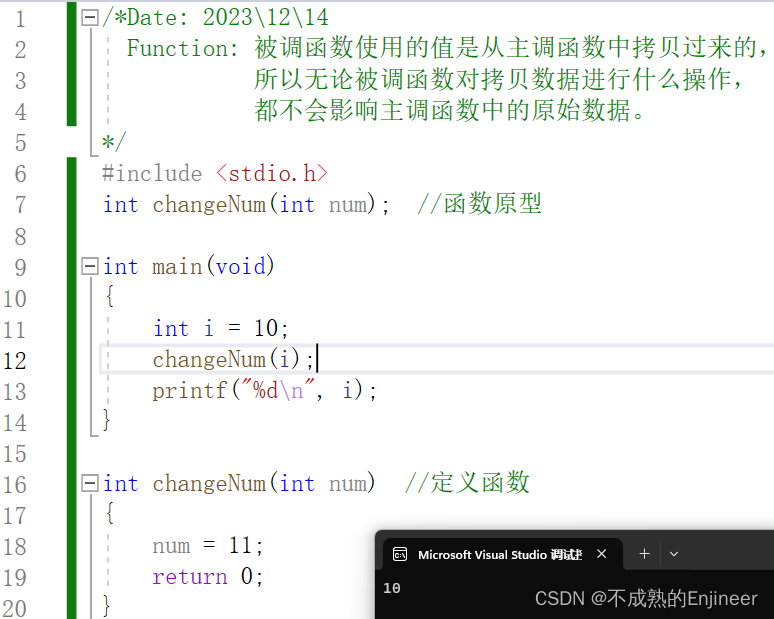
10.7.1:对被调函数的操作不会影响主调函数中的原始数据
被调函数使用的值是从主调函数中拷贝过来的,所以无论被调函数对拷贝数据进行什么操作,都不会影响主调函数中的原始数据。
/*Date: 2023\12\14
Function: 被调函数使用的值是从主调函数中拷贝过来的,
所以无论被调函数对拷贝数据进行什么操作,
都不会影响主调函数中的原始数据。
*/
#include <stdio.h>
int changeNum(int num); //函数原型
int main(void)
{
int i = 10;
changeNum(i);
printf("%d\n", i);
}
int changeNum(int num) //定义函数
{
num = 11;
return 0;
}
10.8:函数的返回值
10.8.1:函数各部分的解释
10.8.2:使用函数返回值的循环示例
- 函数原型是为了方便编译器查看程序中使用的函数是否正确,函数定义描述了函数如何工作。
- 现代编程习惯是把程序要素分为接口部分和实现部分,接口部分描述了如何使用一个特性,也就是函数原型所做的;实现部分描述了具体行为,也就是函数定义所做的。


/*Date: 2023\11\15
Function: 使用函数返回值的循环示例
*/
#include <stdio.h>
double power(double n, int p); //ANSI函数原型
//编译器要知道power()函数返回值的类型,才能知道有多少字节数据,以及如何解释它们,这就是为什么必须
//声明函数的原因
//编译器首次遇到power(),需要知道power()的返回类型,因此必须通过前置声明预先说明函数的返回类型。
//前置声明告诉编译器,power的定义在别处,其返回类型为doubel,如果把power()函数的定义置于main()的
//顶部,就可以省略前置声明。因为编译器在执行到main()之前已经知道power()的所有信息。
int main(void)
{
double x, xpow;
int esp;
printf("enter a number and the positive integer power ");
printf("to which\nthe number will be raised. Enter q to quit\n");
while (scanf_s("%lf%d", &x, &esp) == 2)
{
xpow = power(x, esp); //函数调用
printf("%.3g to the power %d is %.5g\n", x, esp, xpow);
printf("enter the pair of numbers or q to quit.\n");
}
return 0;
}
double power(double n, int p) //函数定义 n为底数,p为指数
{
double pow = 1;
int i;
for (i = 1; i <= p; i++)
{
pow *= n;
}
return pow; //返回pow的值(返回值可以是一个变量的值,也可以是表达式的值)
}
10.9:如何合理的设计函数来解决实际问题?
- 一个函数的功能尽量独立、单一。
- 多学习,多模仿业内人士的代码。
10.10:常用的函数
10.10.1:fabs()函数(求绝对值)
fabs()函数是一个求绝对值的函数,该函数返回一个浮点类型的绝对值。(声明在math.h头文件中。)
/*Date: 2023\11\7
Function: 使用fabs()函数进行比较
*/
#include <stdio.h>
#include <math.h>
int main(void)
{
const double ANSWER = 3.1415926;
double response;
printf("Π的值是多少?\n");
scanf_s("%lf", &response);
while (fabs(response - ANSWER) > 0.0001)
{
printf("请再次输入!\n");
scanf_s("%lf", &response);
}
printf("输入正确!\n");
return 0;
}
10.10.2:pow()函数(幂函数)
double pow(double x, double y)是C、C++的数学函数,计算x的y次幂,返回幂指数的结果。

/*Date: 2023\11\14
Function: 幂函数pow的使用
*/
#include <stdio.h>
#include <math.h>
int main()
{
float i = 1.1;
float j;
j = pow(i, 2); //pow(double x, double y)中x表示底数,y表示指数。
printf("%f", j);
return 0;
}
10.10.3:getchar()和putchar()函数
getchar()函数不带任何参数,它从输入队列中返回下一个字符。(键盘输入通常是行缓冲输入,即出现换行符时刷新缓冲区,进行打印。)
char ch;
ch = getchar();
//与下面语句相同
scanf_s("%c", &ch);
putchar()函数打印它的参数。(由于getchar()和putchar()函数只处理字符,所以它们比scanf()和printf()函数更快,更简洁。)
putchar(ch);
//效果相同于
printf("%c", ch);
getchar()和putchar()都不是真正的函数,它们被定义为供预处理器使用的宏。
10.10.4:应用举例
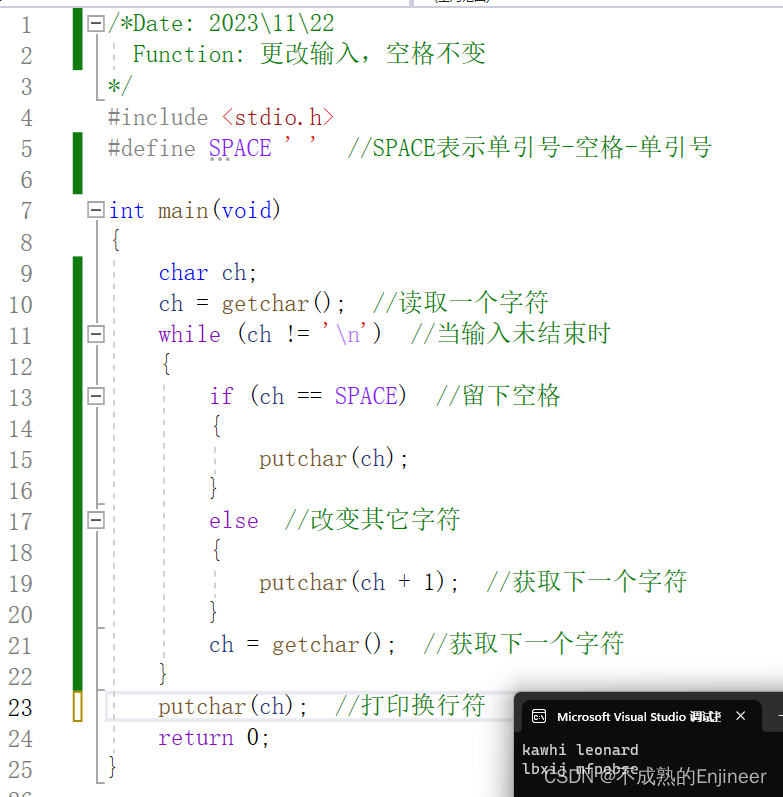
/*Date: 2023\11\22
Function: 更改输入,空格不变
*/
#include <stdio.h>
#define SPACE ' ' //SPACE表示单引号-空格-单引号
int main(void)
{
char ch;
ch = getchar(); //读取一个字符
while (ch != '\n') //当输入未结束时
{
if (ch == SPACE) //留下空格
{
putchar(ch);
}
else //改变其它字符
{
putchar(ch + 1); //获取下一个字符
}
ch = getchar(); //获取下一个字符
}
putchar(ch); //打印换行符
return 0;
}
10.10.5:getchar()与scanf()辨析
getchar()读取每个字符,包括空格、制表符和换行符;而scanf() 在读取数字时会跳过空格、制表符和换行符。
10.10.6:ctype.h系列的字符函数
C有一系列专门处理字符的函数,ctype.h头文件包含了这些函数的原型。这些函数接收一个字符作为参数,如果该字符属于某特殊的类别,就返回一个非零值(真),否则,返回0(假)。
10.10.7:ctype.h头文件中的字符测试函数
| 函数名 | 如果是下列参数时,返回值为真 |
|---|---|
| isalnum() | 字母数字(字母或数字) |
| isalpha() | 字母 |
| isblank() | 标准的空白字符(空格,水平制表符或换行符)或任何其他本地化指定为空白的字符 |
| iscntrl() | 控制字符,如Ctrl+B |
| isdigit() | 数字 |
| isgraph() | 除空格之外任意可打印字符 |
| islower() | 小写字母 |
| isprint() | 可打印字符 |
| ispunct() | 标点符号(除空格或字母数字字符以外的任何可打印字符) |
| isspace() | 空白字符(空格、换行符、换页符、回车符、垂直制表符、水平制表符或其他本地化定义的字符) |
| issupper() | 大写字母 |
| isxdigit() | 十六进制数字符 |
10.10.8:ctype.h头文件中的字符映射函数
| 函数名 | 行为 |
|---|---|
| tolower() | 如果参数是大写字符,该函数返回小写字符;否则,返回原始参数 |
| toupper() | 如果参数是小写字符,该函数返回大写字符;否则,返回原始参数 |
10.11:变量的作用域和存储方式
- 按作用域分:1)全局变量:在所有函数外部定义的变量称为全局变量。全局变量的使用范围是从定义位置开始到整个程序结束。
2)局部变量:在一个函数内部定义的变量或者函数的形参都统称为局部变量。局部变量的使用范围是只能在本函数内部使用。 - 按变量的存储方式:1)静态变量;
2)自动变量;
3)寄存器变量;
10.11.1:局部变量名与全局变量名冲突时
在一个函数内部如果局部变量的名字和全局变量的名字相同时,局部变量会屏蔽掉全局变量。(换言之:如果内层块中声明的变量与外层块中声明的变量同名时,内层块会隐藏外层块的定义。)
10.12:递归
10.12.1:什么是递归?
- C允许函数调用它自己,这种调用过程称为递归(recursion)。
- 每次递归都会创建一组变量,所以递归使用的内存会增加,每次递归调用都会把创建的一组新变量放在栈中。递归调用的数量受限于内存空间。
10.12.2:递归程序的演示
/*Date: 2023\12\14
Function: 递归
*/
#include <stdio.h>
void up_and_down(int n); //函数声明
int main(void)
{
up_and_down(1);
return 0;
}
void up_and_down(int n)
{
printf("第%d层:n 的地址为 %p\n", n, &n);
if (n < 4) //递归必须包含能让递归调用停止的语句
up_and_down(n + 1);
printf("在第%d层:n 的地址为 %p\n", n, &n);
}
10.12.3:用递归将十进制数转二进制数
/*Date: 2023\12\16
Function: 递归和倒序计算
*/
#include <stdio.h>
int main(void)
{
unsigned long number;
printf("enter an integer(q to quit):\n ");
while (scanf_s("%lu", &number) == 1)
{
printf("binary equivalent: ");
to_binary(number);
putchar('\n');
printf("enter an integer(q to quit):\n ");
}
printf("done.\n");
return 0;
}
void to_binary(unsigned long n) //递归函数
{
int r;
r = n % 2;
if (n >= 2)
to_binary(n / 2);
putchar(r == 0 ? '0' : '1');
return;
}
10.12.4:尾递归
最简单的递归形式是把递归调用置于函数的末尾,即正好在return语句之前。这种形式的递归被称为尾递归。尾递归相当于循环。
/*Date: 2023\12\14
Function: 尾递归
*/
#include <stdio.h>
long rfact(int n);
int main(void)
{
int num;
printf("此程序用于计算数的阶乘。输入的数字0-12:\n");
while (scanf_s("%d", &num) == 1)
{
if (num < 0)
printf("负数没有阶乘。\n");
else if (num > 12)
printf("keep input under 13.\n");
else
{
printf("loop: %d factorial = %ld\n", num, rfact(num));
}
printf("enter a value in the range 0-12(q to quit):\n");
}
printf("bye.\n");
return 0;
}
long rfact(int n) //使用递归的函数
{
long ans;
if (n > 0)
ans = n * rfact(n - 1);
else
ans = 1;
return ans;
}
10.13:函数调用的底层实现方式
主流的编程语言中,函数调用的底层实现方式可以分为两种主要模型:栈帧模型(压栈方式)和寄存器模型。
- 栈帧模型(压栈方式):大多数常见的编程语言(如C、C++、Java)使用栈帧模型。在这种模型中,每次函数调用时,系统都会在栈上创建一个新的栈帧,用于存储函数的局部变量、参数、返回地址等信息。函数的参数和局部变量通常存储在栈上。当函数调用完成时,栈帧会被弹出,恢复到调用函数的上一个栈帧。
- 寄存器模型:一些编程语言或体系结构采用寄存器模型,其中函数调用的信息存储在寄存器中而不是栈帧中。这种模型可能会更高效,但对于高级语言而言,通常会在底层使用栈帧模型。寄存器模型可能更常见于一些嵌入式系统或特定硬件体系结构。
十一:数组与指针
11.1:为什么需要数组?
为了解决大量同类型数据的存储和使用问题,同时也是为了模拟现实世界。
11.1.1:const关键字
使编译器保护那些不希望被修改的参数,意味着只读,防止无意识的修改。
11.1.2:对形式参数使用const
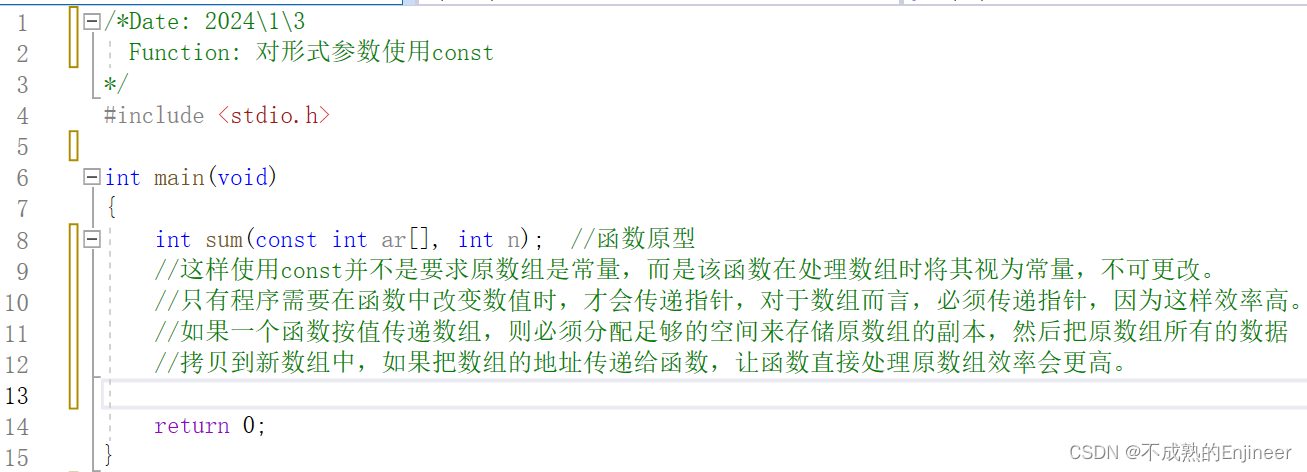
11.1.3:在指针和形参声明中使用const

const char *pc = "hello";const只能保证pc指向的字符串内容不能被修改,但无法保证pc不指向别的字符串(即创建的pc指向不能被修改的值,而pc本身的值可以改变,例如可以设置该指针指向其它const值。与char const *pc = "hello"相同)。char * const pc = "hello";创建的指针pc本身的值不能更改,pc必须指向同一个地址,但是它所指向的值可以改变。- const放在
*左侧任意位置,限定了指针指向的数据不能改变,const放在*右侧,限定了指针本身不能改变。 - 在函数原型和函数头,形参声明
const int array[]与const int * array相同,所以该声明表明不能更改array指向的数据。
11.2:数组的特点
- 数组(array)是按顺序存储一系列类型相同的值,整个数组有一个数组名,通过整数下标访问数组中单独的项或元素。
- 用于识别数组元素的数字被称为下标、索引或偏移量,下标必须是整数,且必须从0开始计数;
- 考虑到执行的速度,C编译器不会检查数组的下标是否正确,所以要注意数组下标越界。
- 数组的元素被依次存储在内存中相邻的位置。
- 传统的C数组,必须用常量表达式指明数组的大小,所以数组的大小在编译时就已经确定。C99/C11新增了变长数组,可以用变量表示数组大小,这意味着变长数组的大小延迟到程序运行时才确定。
- C把数组名解释为该数组首元素的地址。即数组名与指向该数组首元素的指针等价,如果ar是一个数组,那么ar[i]等价于*(ar + i);
- 在指定数组大小时,要确保数组元素个数至少比字符串长度多1(为了容纳空字符);
11.3:数组的分类
11.3.1:一维数组
为n个变量连续分配存储空间,其中所有的变量数据类型相同且所占字节大小相同。只有在定义数组的同时才可以整体赋值,其它情况下整体赋值都是错误的。(一维数组名代表数组第一个元素的地址。)
11.3.2:一维数组的初始化
- 完全初始化:int a[5] = {1,2,3,4,5};
- 不完全初始化,未被初始化的元素自动为零:int a[5] = {1,2,3};
- 不初始化,所有元素为垃圾值:int a[5];
- 清零: int a[5] = {0};
- C不允许把数组作为一个单元赋给另一个数组,除初始化以外也不允许使用花括号列表的形式赋值。
11.3.3:一维数组名
- 一维数组名是个指针常量;
- 它存放的是一维数组第一个元素的地址;
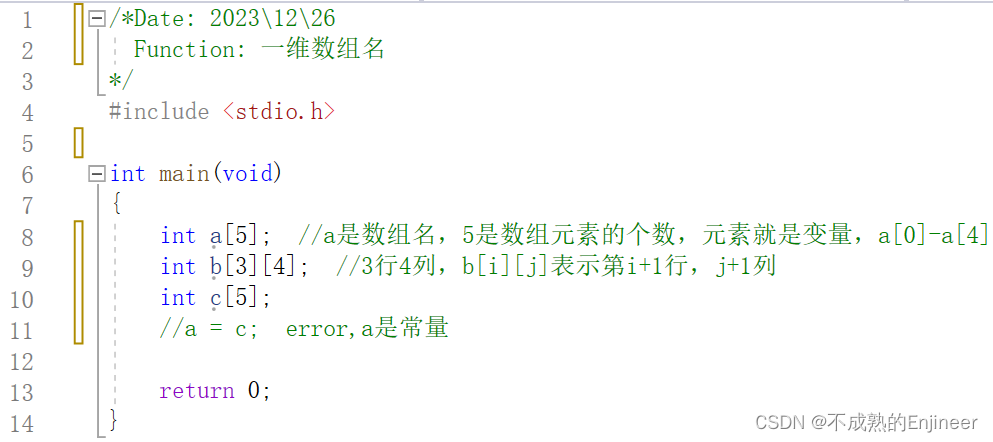
11.3.4:确定一个一维数组需要两个参数
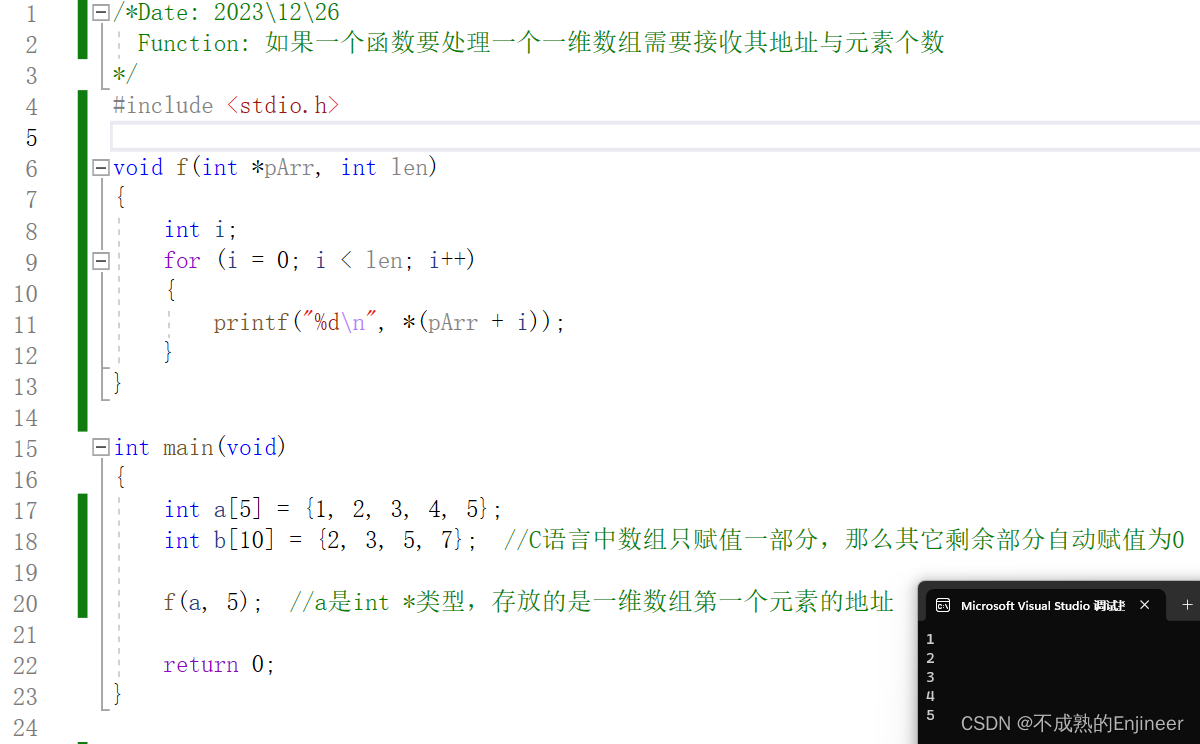
/*Date: 2023\12\26
Function: 如果一个函数要处理一个一维数组需要接收其地址与元素个数
*/
#include <stdio.h>
void f(int *pArr, int len)
{
int i;
for (i = 0; i < len; i++)
{
printf("%d\n", *(pArr + i));
}
}
int main(void)
{
int a[5] = {1, 2, 3, 4, 5};
int b[10] = {2, 3, 5, 7}; //C语言中数组只赋值一部分,那么其它剩余部分自动赋值为0
f(a, 5); //a是int *类型,存放的是一维数组第一个元素的地址
return 0;
}
11.3.5:指定初始化器(C99)
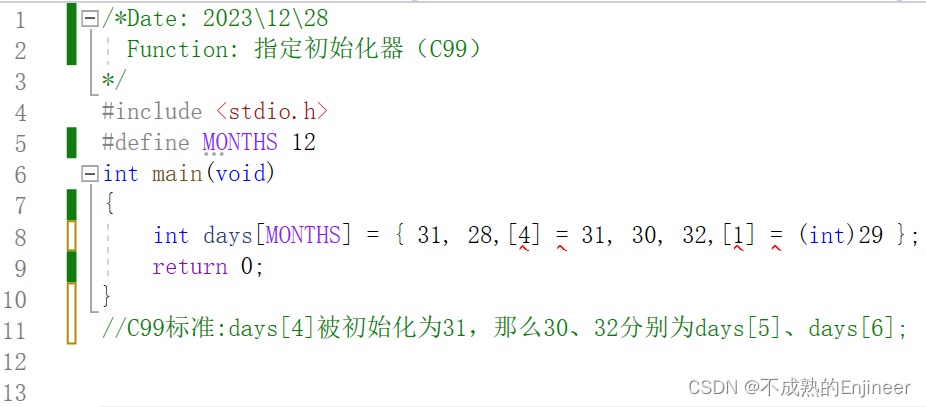
11.3.6:二维数组
int a[3][4];总共是12个元素,3行4列;依次是a[0][0],a[0][1],a[0][2],a[0][3]…。
int a[3][4]可以这样理解:a是一个内含3个元素的数组,a的每个元素都是包含4个int类型值的数组。
a[i][j]表示第i+1行第j+1列的元素。
11.3.7:二维数组的初始化

11.3.8:二维数组的输出
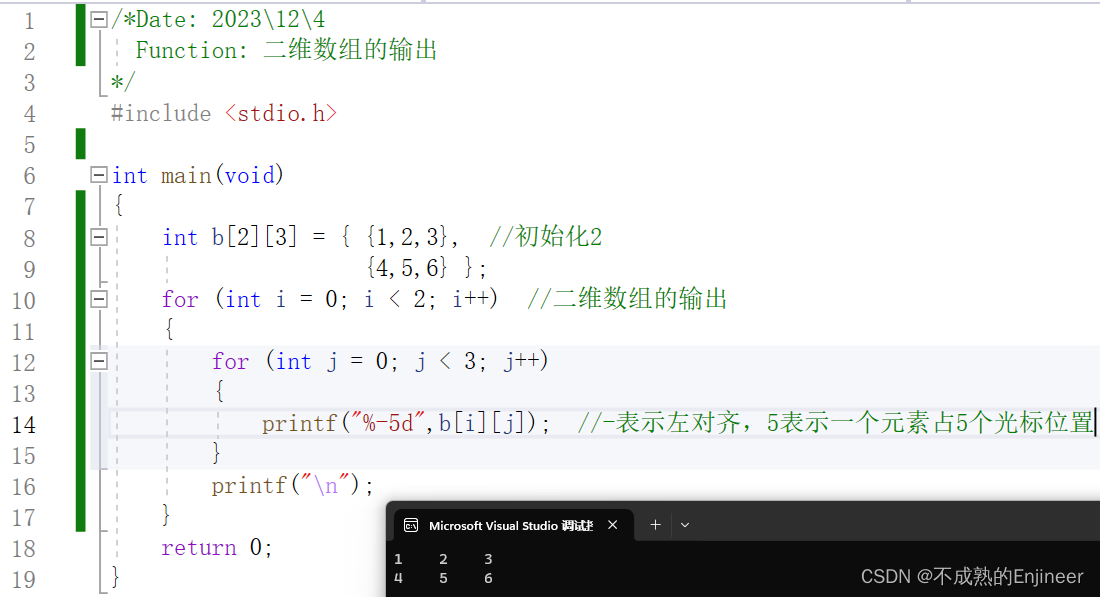
11.3.9:如何理解二维数组?

11.3.10:三维数组
可以把一维数组想象成一行数据,二维数组则是数据表,三维数组是一叠数据表。int box[10][20][30];box内含10个元素,每个元素是内含20元素的数组,这个20个元素中每个元素是内含30个元素的数组。通常处理三维数组要使用3重嵌套循环,处理四维数组要使用4重嵌套循环,对于其它多维数组,以此类推。
11.3.11:是否存在多维数组(从存储角度)?
不存在多维数组,因为内存是线性一维的。n维数组可以当做每个元素是n-1维数组的一维数组。
11.4:&运算符
- 指针(pointer)是C语言中最重要也是最复杂的概念之一,指针用于存储变量的地址。
- 一元&运算符给出变量的存储地址,如果pooh是变量名,那么&pooh是变量的地址。可以把地址看作是变量在内存中位置。
11.5:指针
11.5.1:什么是指针?
- 指针是C语言的灵魂。
- 指针变量是一个值为内存地址的变量(或数据对象)。
- 指针能表示一些复杂的数据结构(链表,树,图);
- 指针能快速的传递数据,能够方便的处理字符串,能够使函数返回一个以上的值;
- 指针能够直接访问硬件,是理解面向对象语言中引用的基础;
- 指针就是地址,地址就是指针。
- 指针变量就是存放内存单元编号的变量,或者说指针变量就是存放地址的变量。
- 指针的本质就是一个操作受限(不能相加、乘、除)的非负整数。
11.5.2:什么是地址?
- 地址是内存单元的编号。
- 地址是从零开始的非负整数。
- 一个字节一个地址,即8位一个地址。
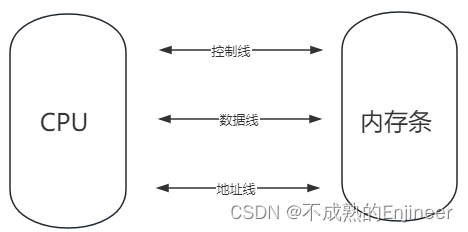
11.5.3:CPU与内存条的关系
一根地址线可以控制两位(Bit),10根地址线可以控制1024Bit(1KB),20根地址线可以控制1MB,30根可以控制1GB,31根地址线可以控制2GB内存。
11.5.4:指针和地址
- 计算机中地址一般是16进制的,因此dd比dc大1,a1比a0大1。地址按字节编址,short类型占两个字节,double类型占八个字节。
- 在C语言中,指针加1指的是增加一个存储单元,对数组而言加1后的地址是下一个元素的地址,而不是下一个字节的地址。这就是为什么必须声明指针所指向对象类型的原因,只知道地址不够,因为计算机要知道存储对象需要多少字节(即使指针指向的是标量变量,也要知道变量的类型,否则*pt就无法正确地取回地址上的值)。
- 一个较大对象的地址通常是该对象第一个字节的地址。
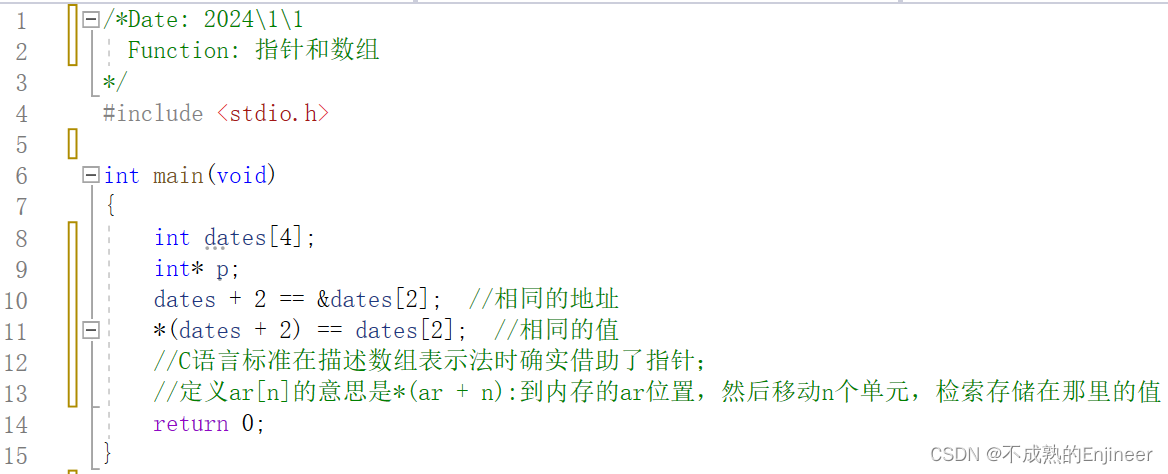
11.5.5:int array[ ]代替int *array

11.5.6:间接运算符 *(解引用运算符)
后面跟一个指针名或地址时,* 给出存储在指针指向地址上的值。
该运算符放在已经定义好的指针变量前面,如果p是一个已经定义好的指针变量,则*p表示以p的内容为地址的变量。
11.5.7:声明指针、如何理解指针?
- 声明指针变量时必须指定指针所指向变量的类型,因为不同的变量类型占用不同的存储空间,一些指针操作要求知道操作对象的大小。
- 程序必须知道存储在指定地址上的数据类型,long和float可能占用相同的存储空间,但它们存储的数据却不同。

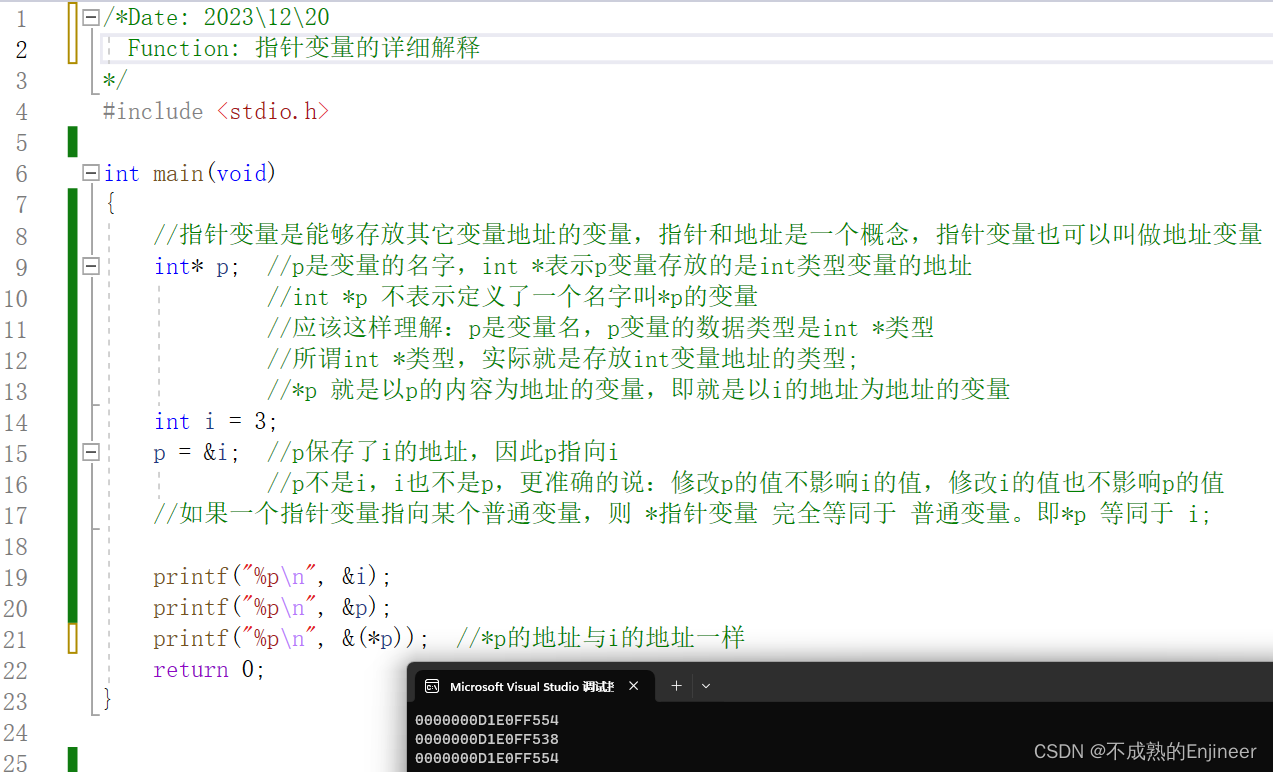
/*Date: 2023\12\20
Function: 指针变量的详细解释
*/
#include <stdio.h>
int main(void)
{
//指针变量是能够存放其它变量地址的变量,指针和地址是一个概念,指针变量也可以叫做地址变量
int* p; //p是变量的名字,int *表示p变量存放的是int类型变量的地址
//int *p 不表示定义了一个名字叫*p的变量
//应该这样理解:p是变量名,p变量的数据类型是int *类型
//所谓int *类型,实际就是存放int变量地址的类型;
//*p 就是以p的内容为地址的变量,即就是以i的地址为地址的变量
int i = 3;
p = &i; //p保存了i的地址,因此p指向i
//p不是i,i也不是p,更准确的说:修改p的值不影响i的值,修改i的值也不影响p的值
//如果一个指针变量指向某个普通变量,则 *指针变量 完全等同于 普通变量。即*p 等同于 i;
printf("%p\n", &i);
printf("%p\n", &p);
printf("%p\n", &(*p)); //*p的地址与i的地址一样
return 0;
}
11.5.8:如何在被调函数中更改主调函数中的变量?


/*Date: 2023\12\19
Function: 使用指针解决互换数字的问题
*/
#include <stdio.h>
void interchange(int* u, int* v); //此处的int* u是定义,u才是变量名,所以传入的实参必须要是地址
int main(void)
{
int x = 5, y = 10;
printf("originally x = %d and y = %d.\n", x, y);
interchange(&x, &y); //该函数传递的不是x和y的值,而是它们的地址,这意味着
//interchange()原型和定义中的形式参数u和v将把地址作为它们的值。
//把&x赋值给u。
printf("now x = %d and y = %d.\n", x, y);
return 0;
}
void interchange(int* u, int* v)
{
int temp; //冒泡法交换两个变量的值
temp = *u; //temp获得u所指向对象的值
*u = *v; //u的值是&x,所以u指向x,即*u表示x的值。
*v = temp;
/* 注意不能这样操作
int * temp;
temp = u; //因为无论是局部变量还是全局变量一旦定义了,其地址就是固定的了,不能更改
u = v; //此处只是交换指针u,v所存储的地址而已,并没有互换主函数x,y的值
v = temp;
*/
return;
}
11.5.9:指针和指针变量的区别
- 指针就是地址,地址就是指针;
- 地址是内存单元的编号;
- 指针变量是存放地址的变量(指针变量是存放指针的变量);
- 指针和指针变量是两个不同的概念;
- 值得注意的是:通常我们叙述时会把指针变量简称指针,实际它们含义并不一样。
11.5.10:指针的分类
11.5.11:基本类型指针的常见错误
/*Date: 2023\12\25
Function: 指针变量的常见错误1
*/
#include <stdio.h>
int main(void)
{
int* p;
int i = 5;
*p = i; //p没有初始化,所以其存放的地址是垃圾值,p指向不知道的位置
printf("%d\n", *p); //将5赋给*p,就是将不知道位置的变量的值改为5,
//这对于系统而言是很危险的
return 0;
}

/*Date: 2023\12\25
Function: 指针变量的常见错误2
*/
#include <stdio.h>
int main(void)
{
int i = 5;
int* p;
int* q;
p = &i;
//*q = p; error:类型不一致,*q是int类型,p是int *类型。(int *类型就是存放int变量地址的类型)
//*q = *p; error: q没有初始化所以指向随机内存单元,*q是随机内存单元储存的变量,此程序没有权限
//更改。
p = q; //q是垃圾值,q赋给p,p也变成垃圾值
printf("%d\n", *q);
/* q的控件是属于本程序的,所以本程序可以读写q的内容
但是如果q内部是垃圾值,则本程序不能读写*q的内容
因为此时*q所代表的内存单元的控制权限并没有分配给本程序
*/
return 0; //所以编译出错
}

11.5.12:指针和数组
数组下标转化为指针。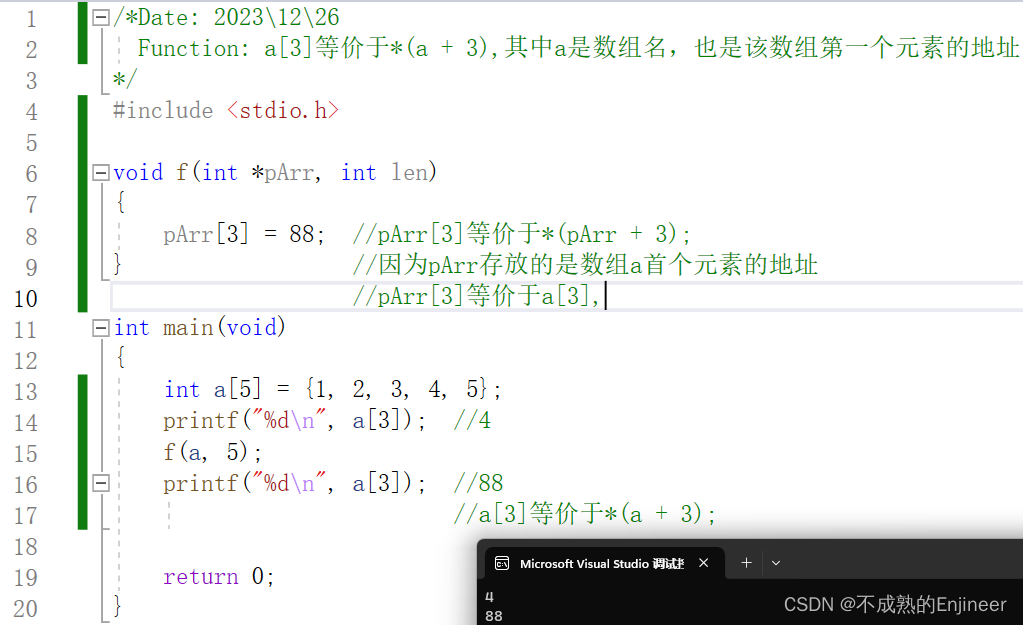
/*Date: 2023\12\26
Function: a[3]等价于*(a + 3),其中a是数组名,也是该数组第一个元素的地址
*/
#include <stdio.h>
void f(int *pArr, int len)
{
pArr[3] = 88; //pArr[3]等价于*(pArr + 3);
} //因为pArr存放的是数组a首个元素的地址
//pArr[3]等价于a[3],
int main(void)
{
int a[5] = {1, 2, 3, 4, 5};
printf("%d\n", a[3]); //4
f(a, 5);
printf("%d\n", a[3]); //88
//a[3]等价于*(a + 3);
return 0;
}
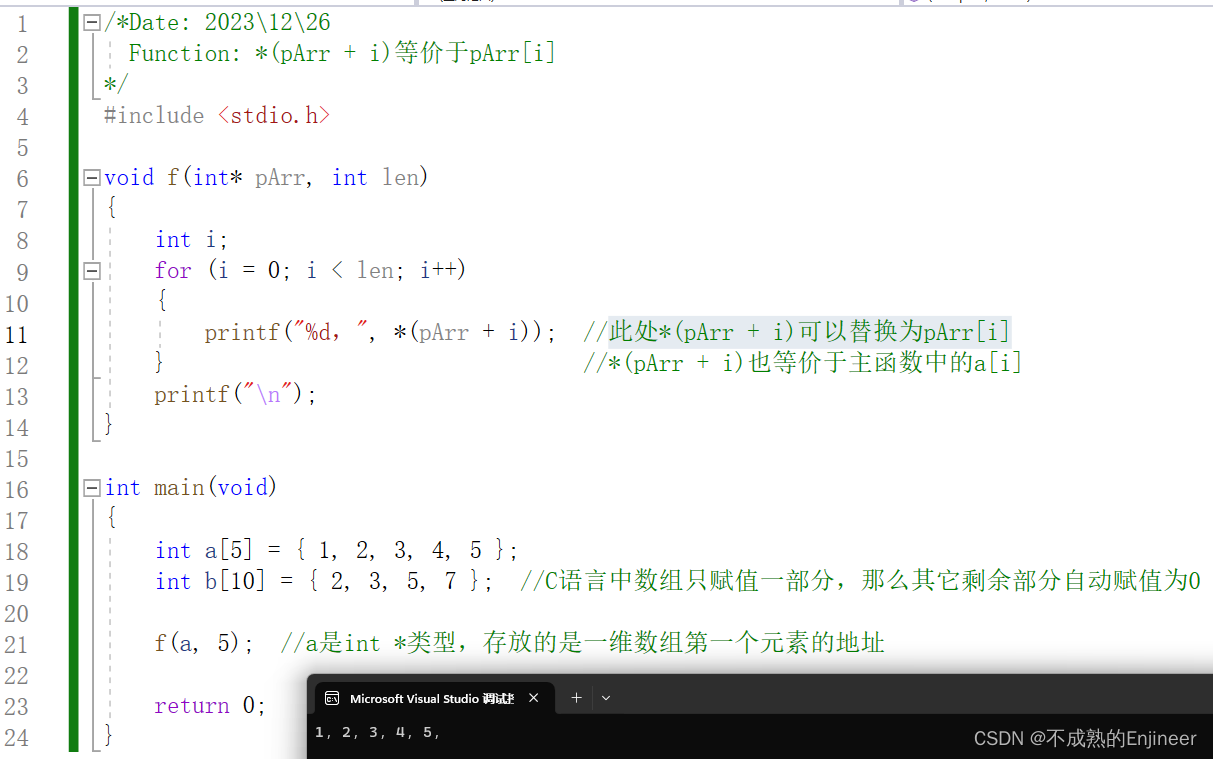
/*Date: 2023\12\26
Function: *(pArr + i)等价于pArr[i]
*/
#include <stdio.h>
void f(int* pArr, int len)
{
int i;
for (i = 0; i < len; i++)
{
printf("%d,", *(pArr + i)); //此处*(pArr + i)可以替换为pArr[i]
} //*(pArr + i)也等价于主函数中的a[i]
printf("\n");
}
int main(void)
{
int a[5] = { 1, 2, 3, 4, 5 };
int b[10] = { 2, 3, 5, 7 }; //C语言中数组只赋值一部分,那么其它剩余部分自动赋值为0
f(a, 5); //a是int *类型,存放的是一维数组第一个元素的地址
return 0;
}
11.5.13:指针和多维数组

11.5.14:指向多维数组的指针
- 一般而言,声明一个指向N维数组的指针时,只能省略最左边方括号中的值。
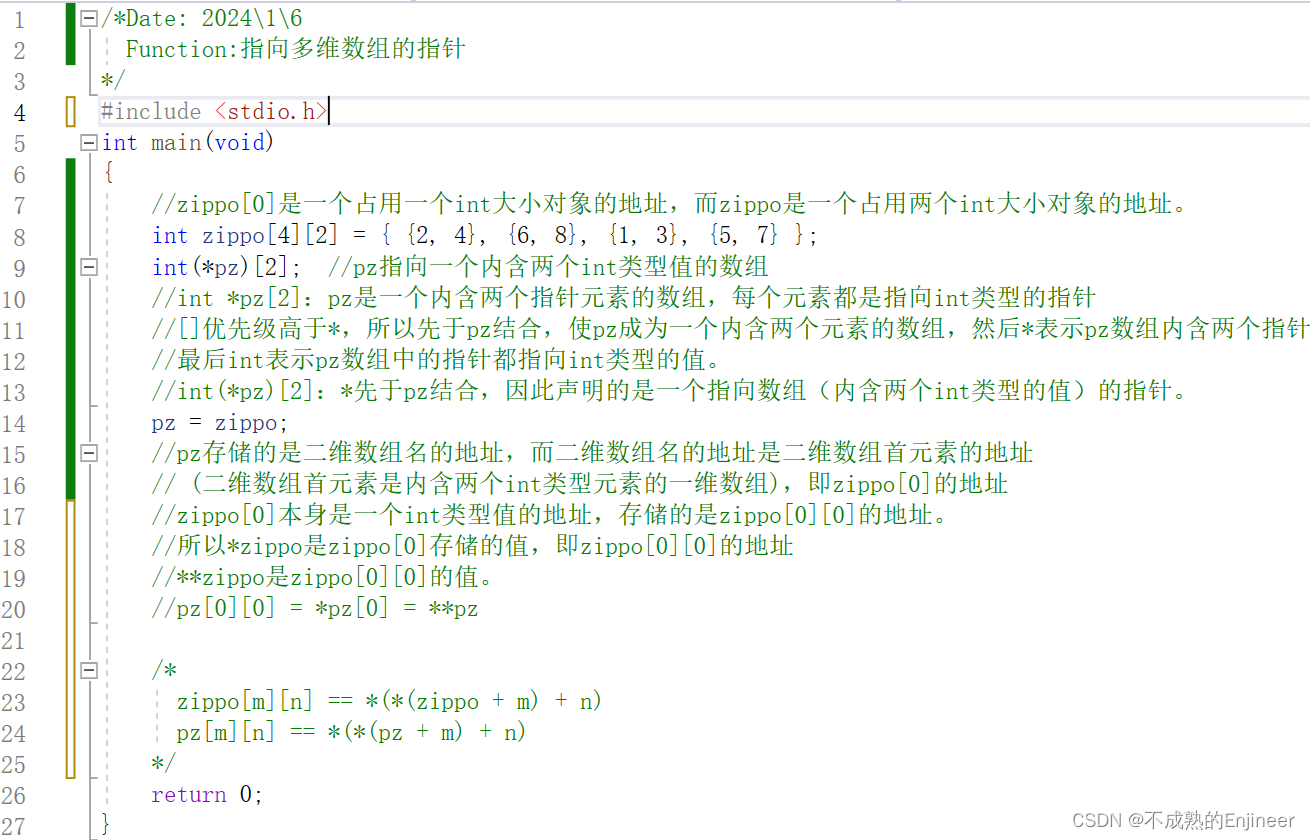
/*Date: 2024\1\6
Function:指向多维数组的指针
*/
#include <stdio.h>
int main(void)
{
//zippo[0]是一个占用一个int大小对象的地址,而zippo是一个占用两个int大小对象的地址。
int zippo[4][2] = { {2, 4}, {6, 8}, {1, 3}, {5, 7} };
int(*pz)[2]; //pz指向一个内含两个int类型值的数组
//int *pz[2]:pz是一个内含两个指针元素的数组,每个元素都是指向int类型的指针
//[]优先级高于*,所以先于pz结合,使pz成为一个内含两个元素的数组,然后*表示pz数组内含两个指针
//最后int表示pz数组中的指针都指向int类型的值。
//int(*pz)[2]:*先于pz结合,因此声明的是一个指向数组(内含两个int类型的值)的指针。
pz = zippo;
//pz存储的是二维数组名的地址,而二维数组名的地址是二维数组首元素的地址
// (二维数组首元素是内含两个int类型元素的一维数组),即zippo[0]的地址
//zippo[0]本身是一个int类型值的地址,存储的是zippo[0][0]的地址。
//所以*zippo是zippo[0]存储的值,即zippo[0][0]的地址
//**zippo是zippo[0][0]的值。
//pz[0][0] = *pz[0] = **pz
/*
zippo[m][n] == *(*(zippo + m) + n)
pz[m][n] == *(*(pz + m) + n)
*/
return 0;
}
11.5.15:指向指针的指针(多级指针)

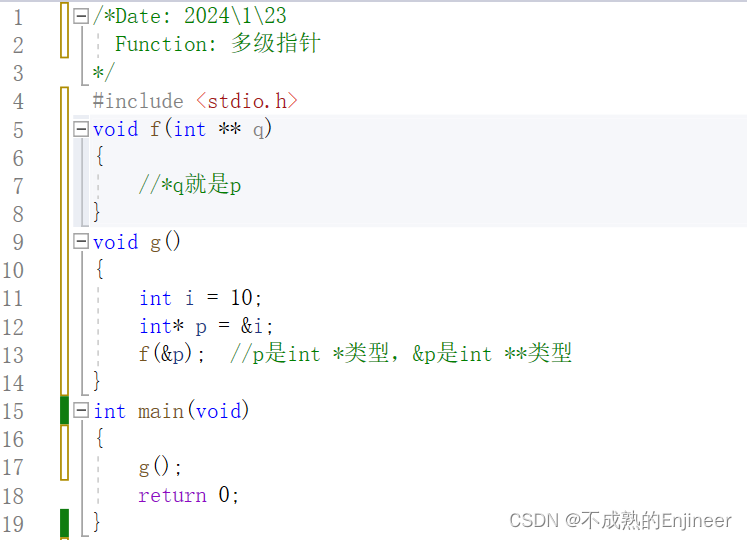
11.5.16:char **argv与char * argv[ ]

- 在一些情况下char **argv与char * argv[ ]等价,也就是说argv是一个指向指针的指针,它所指向的指针指向char类型,因为数组名在大多数情况下会退化为指针;
- char * argv[ ]声明了一个数组,其中每个元素是一个 char* 类型的指针。这表示可以使用 p[0]、p[1] 等来访问数组元素。
- char**argv 声明了一个指针,指向 char* 类型的指针。这表示argv 可以指向一个 char* 类型的指针,而不是数组。
11.5.17:指针变量的运算
- 指针变量之间不能相加,不能相乘,也不能相除。
- 如果两个指针变量指向的是同一块连续空间中的不同存储单元,则这两个指针变量才可以相减。
- 指针与整数相加:使用+运算符把指针和整数相加,整数都会和指针所指向类型的大小(以字节为单位)相乘,然后把结果与初始地址相加。指针减去一个整数原理相同。
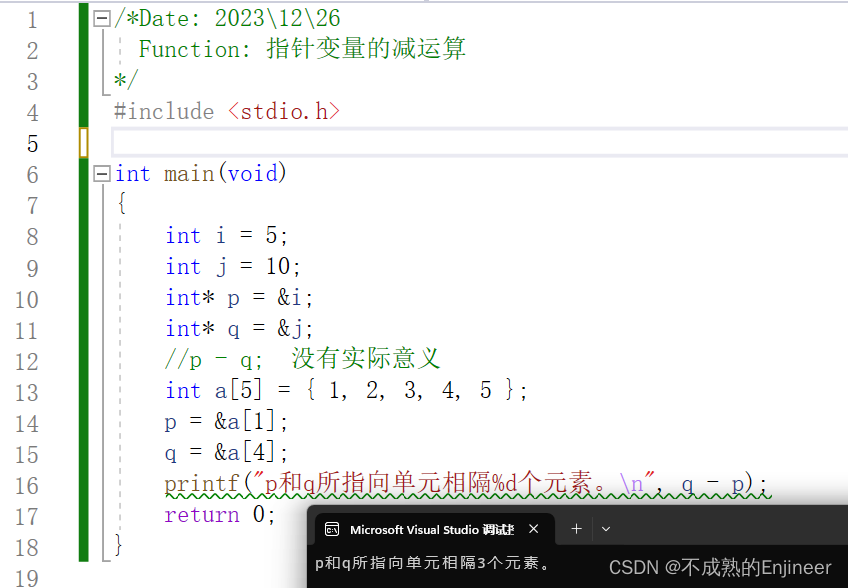
/*Date: 2023\12\26
Function: 指针变量的减运算
*/
#include <stdio.h>
int main(void)
{
int i = 5;
int j = 10;
int* p = &i;
int* q = &j;
//p - q; 没有实际意义
int a[5] = { 1, 2, 3, 4, 5 };
p = &a[1];
q = &a[4];
printf("p和q所指向单元相隔%d个元素。\n", q - p);
return 0;
}
11.5.18:一个指针变量占几个字节?
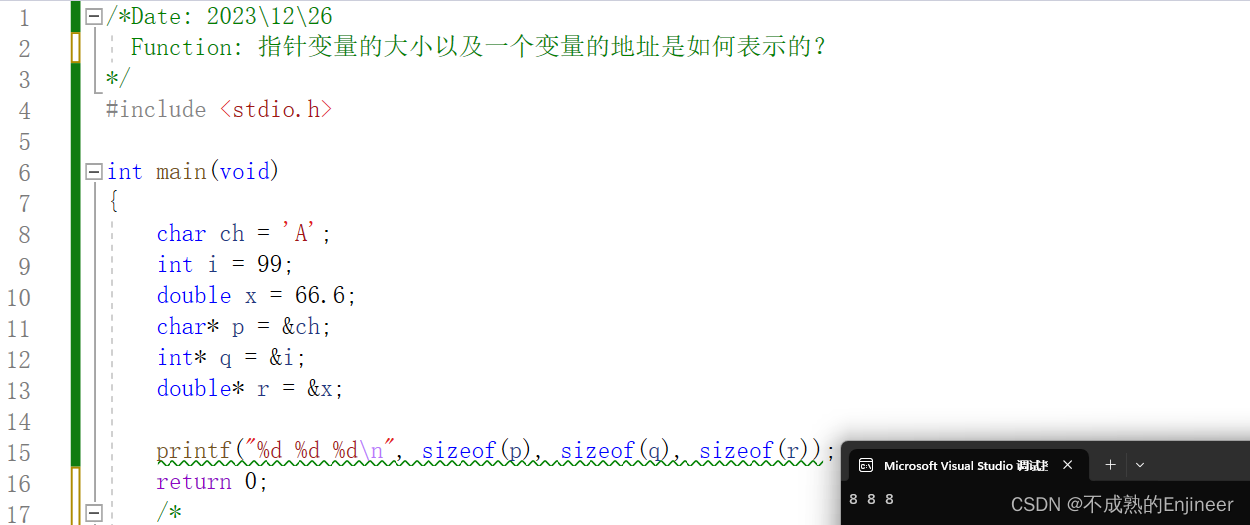

/*Date: 2023\12\26
Function: 指针变量的大小以及一个变量的地址是如何表示的?
*/
#include <stdio.h>
int main(void)
{
char ch = 'A';
int i = 99;
double x = 66.6;
char* p = &ch;
int* q = &i;
double* r = &x;
printf("%d %d %d\n", sizeof(p), sizeof(q), sizeof(r));
return 0;
/*
1:一个变量的地址是用该变量首字节的地址来表示的
2:一个指针变量,无论它指向的变量占几个字节,该指针变量在32位计算机上占4个字节,
在64位计算机上占8个字节。
3:之所以是8个字节,是因为计算机是64位的。
4:地址是内存单元的编号,一个指针变量占几个字节,就是问地址的内存单元编号有多大。CPU不能
直接与硬盘进行数据通信,只能与内存进行数据交换,CPU是通过地址总线,数据总线,控制总线
三条线与内存进行数据传输与操作的。我们平时所说的计算机是64位,32位指的是,CPU中通用寄
存器一次性处理,传输,暂时储存的信息的最大长度。即CPU在同一时间内能一次处理的二进制的
位数。
5:32位地址总线,为2的32次方Byte。CPU最大内存为4G,而64位,CPU最大内存是2的64次方约
等于17179869184GB。
*/
}
11.5.19:危险的指针
11.5.20:解引用未初始化的指针
创建一个指针时,系统只分配了存储指针本身的内存,并未分配存储数据的内存。因此在使用指针前,必须先用已分配的地址初始化它。
11.5.21:指针的优点
- 表示了一些复杂的数据结构(数据的存储和操作)。
- 快速的传递数据,减少了内存的耗用。
- 使函数返回一个以上的值。
- 能直接访问硬件。
- 能够方便的处理字符串。
- 是理解面向对象语言中引用的基础。
11.5.22:指向函数的指针
- 函数名代表函数地址,可以把函数的地址作为参数传递给其他函数,然后这些函数就可以使用被指向的函数。
- 要声明一个指向特定类型函数的指针,可以先声明一个该类型的函数,然后把函数名替换成(*pf)形式的表达式,然后,pf就成为指向该类型函数的指针。

void ToUpper(char*); //把字符串中的字符转换成大写字符
//ToUpper()是函数的类型是带char* 类型参数,返回类型是void的函数,下面的指针指向该函数
void (*pf)(char*);
//第一对()把*和pf括起来,表明pf是一个指向函数的指针,因此(*pf)是一个参数列表为(char *)
//返回类型为void的函数
void* pf(char*); //pf是一个返回字符指针的函数

void ToUpper(char*);
void ToLower(char*);
void (*pf)(char*);
char mis[] = "hello world";
pf = ToUpper; //函数名是函数的地址
(*pf)(mis); //等价于ToUpper(mis);
pf = ToLower;
pf(mis); //等价于ToLower(mis);
void show(void (*pf)(char*), char *str);
//它声明了两个形参,fp和str,fp形参是一个函数指针,str是一个数据指针,fp指向的函数接受
//char *类型的参数,其返回类型为void,str指向一个char类型的值。可以这样调用函数
show(ToUpper, mis);
11.6:复合字面量
-
C99标准新增了复合字面量(compund literal),字面量是除符号常量外的常量。
-
复合字面量类似于数组初始化列表,前面是用括号括起来的类型名。

-
初始化有数组名的数组时可以省略数组的大小,复合字面量也可以省略大小,编译器会自动计算数组当前的元素个数。

-
复合字面量是匿名的,所以不能先创建然后再使用它,必须在创建的同时使用它;
-
与有数组名的数组类似,复合字面量的类型名也代表首元素的的地址,所以可以把它赋给指针;
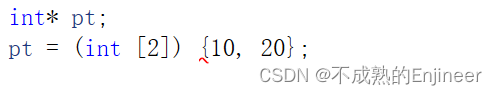
-
复合字面量是提供只临时需要的值的一种手段,复合字面量具有块作用域,一旦离开定义复合字面量的块,程序无法保证该字面量是否存在;
十二:存储类别、链接、内存管理
12.1:动态内存分配
12.1.1:传统数组的缺点
- 传统数组的长度必须事先制定,且只能是常整数,不能是变量(C99标准出现了变长数组);
- 传统形式定义的数组,该数组的内存程序员无法手动释放。在一个函数运行期间,系统为该函数中数组所分配的内存空间会一直存在,直到该函数运行完毕时,数组的空间才会被系统释放;
- 在一般情况下,对于没有被调用的函数中定义的局部数组,系统并不会为其分配内存空间。局部数组的生命周期通常仅限于函数的执行过程中,当函数执行结束时,局部数组所占用的内存空间会被释放。这是因为局部数组是在函数的栈帧上分配的,栈帧随着函数的调用和返回而动态变化。当函数被调用时,系统会在栈上为局部变量和数组分配内存,当函数执行完毕时,这些内存会被自动释放;
- A函数定义的数组,在A函数运行期间可以被其它函数使用,但A函数运行完毕之后,A函数中的数组将无法在被其它函数使用;
12.1.2:为什么需要动态内存分配?
动态数组很好的解决了传统数组的缺陷,传统数组也称静态数组。
12.1.3:动态内存和静态内存的比较
- 静态内存是由系统自动分配,由系统自动释放,静态内存是在栈上分配的。动态内存是由程序员手动分配,手动释放,动态内存是在堆分配的。
- 栈(Stack)是一种基于后进先出(Last In, First Out,LIFO)原则的数据结构。这意味着最后进入栈的元素会最先被取出。栈有两个主要操作:压栈(Push)将元素添加到栈的顶部。出栈(Pop)从栈的顶部移除元素。栈的实现可以使用数组或链表。在栈中,只能在栈顶进行操作,而不允许在中间或底部插入或删除元素。这使得栈特别适用于需要按照后进先出顺序进行操作的场景,如函数调用的管理、表达式求值、括号匹配等。栈还有一个重要的特性是栈帧的使用。每当函数被调用,系统都会为该函数创建一个栈帧,栈帧包含了函数的局部变量、参数、返回地址等信息。当函数执行完毕时,栈帧被弹出,控制权返回到调用函数。
- 堆(Heap): 堆是一种数据结构,通常指的是二叉堆。二叉堆是一个完全二叉树,可以分为最大堆和最小堆。在最大堆中,每个节点的值都大于或等于其子节点的值;在最小堆中,每个节点的值都小于或等于其子节点的值。堆在优先队列、堆排序等算法中有广泛的应用。
- 堆排序(Heap Sort): 堆排序是一种排序算法,它使用二叉堆的数据结构来实现排序。堆排序的基本思想是先将待排序的序列构建成一个堆,然后逐步取出堆顶元素(最大或最小值),再将剩余元素重新构建成堆。堆排序的时间复杂度为O(n log n),其中n是要排序的元素个数。虽然堆排序使用了堆这个数据结构,但它们是两个独立的概念。堆是一种数据结构,而堆排序是一种基于堆的排序算法。
12.1.4:malloc()函数
- malloc()函数会找到合适的空闲内存块,但不会为其赋名,并返回动态分配内存块的首字节地址。

/*Date: 2024\1\22
Function: malloc()函数
*/
#include <stdio.h>
#include <malloc.h> //malloc()函数的头文件
int main(void)
{
int i = 5; //静态分配了4个字节
int* p = (int*)malloc(4);
/*
1.malloc函数只有一个形参,并且形参是整型;
2.形参4表示请求系统为本程序分配4个字节;
3.malloc函数只能返回第一个字节的地址,但不能知道这个地址指向的变量占几个字节,所以前面加int *
强制类型转换,将malloc函数返回的地址转换为整型的地址;
4.第9行一共分配了12个字节,p占8个字节,p所指向的内存占4个字节;
5.p本身所占的内存是静态分配的,p所指向的内容是动态分配的;
*/
*p = 5; //*p代表的就是一共int变量,只不过*p的内存分配方式和i不同
free(p); //free(p)表示把p所指向的内存给释放掉
return 0;
}
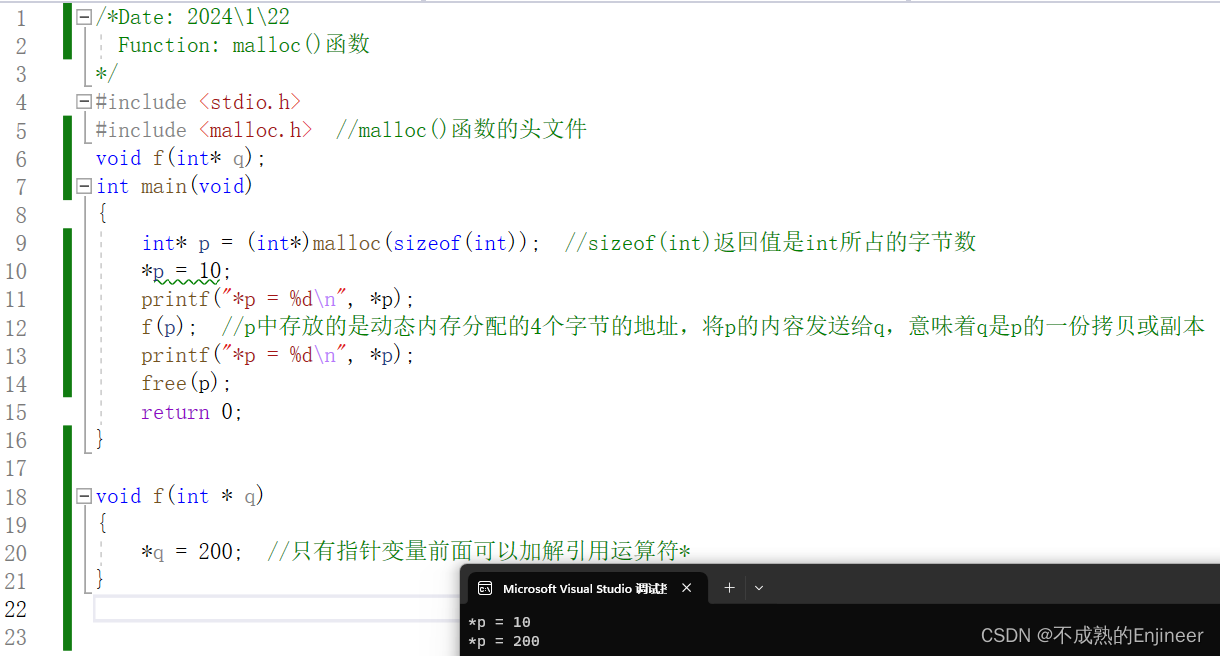
/*Date: 2024\1\22
Function: malloc()函数
*/
#include <stdio.h>
#include <malloc.h> //malloc()函数的头文件
void f(int* q);
int main(void)
{
int* p = (int*)malloc(sizeof(int)); //sizeof(int)返回值是int所占的字节数
*p = 10;
printf("*p = %d\n", *p);
f(p); //p中存放的是动态内存分配的4个字节的地址,将p的内容发送给q,意味着q是p的一份拷贝或副本
printf("*p = %d\n", *p);
free(p);
return 0;
}
void f(int * q)
{
*q = 200; //只有指针变量前面可以加解引用运算符*
}
12.1.5:动态一维数组的构造
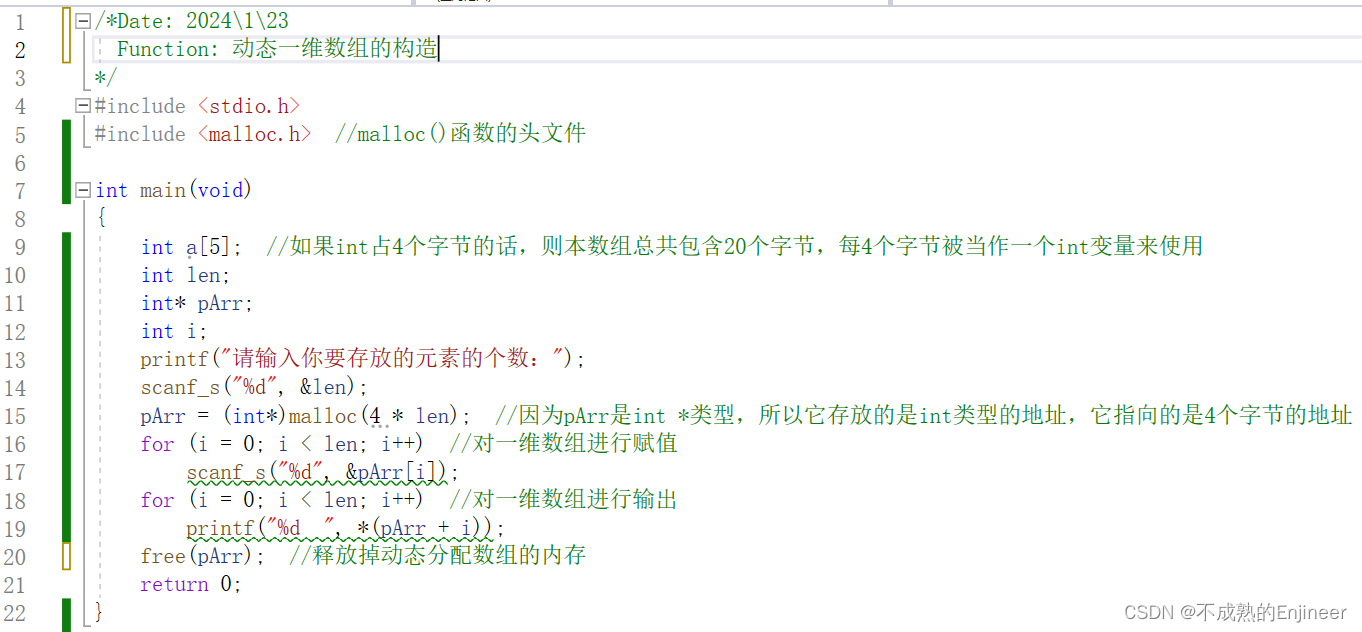
/*Date: 2024\1\23
Function: 动态一维数组的构造
*/
#include <stdio.h>
#include <malloc.h> //malloc()函数的头文件
int main(void)
{
int a[5]; //如果int占4个字节的话,则本数组总共包含20个字节,每4个字节被当作一个int变量来使用
int len;
int* pArr;
int i;
printf("请输入你要存放的元素的个数:");
scanf_s("%d", &len);
pArr = (int*)malloc(4 * len); //因为pArr是int *类型,所以它存放的是int类型的地址,它指向的是4个字节的地址
for (i = 0; i < len; i++) //对一维数组进行赋值
scanf_s("%d", &pArr[i]);
for (i = 0; i < len; i++) //对一维数组进行输出
printf("%d ", *(pArr + i));
free(pArr); //释放掉动态分配数组的内存
return 0;
}
12.1.6:静态变量不能跨函数使用

/*Date: 2024\1\23
Function: 静态变量不能跨函数使用
*/
#include <stdio.h>
void f(int ** q) //q是一个指针变量,无论q是什么类型的指针变量,都只占8个字节(与系统位数有关)
{
int i = 5;
//此时 q = &p,*q等价于p, *q是存放int类型变量的地址
*q = &i; //p = &i
}
int main(void)
{
int* p; //p是int *类型
f(&p); //&p是int **类型
printf("%d\n", *p);
/*
本语句语法没有问题,但逻辑上有问题,因为当14行语句结束后,局部变量i所分配的内存已经释放了
在函数 f 中,你将一个局部变量 i 的地址赋给了传递进来的指针 p。然而,在函数结束后,局部变量 i
的生命周期结束,其内存将被释放,而指向 i 的指针 *p 就成为悬空指针(dangling pointer),指向一
个已经被释放的内存地址。使用悬空指针是一种危险的行为,可能导致未定义的行为。
虽然存在悬空指针的问题,但在某些情况下,程序可能仍然能够访问已经释放的内存。这是由于内存释放后,
并不是立即被系统擦除,所以在一定的情况下可能仍然保留着之前的值。然而,这种情况是不可靠和不安全的,
因为它依赖于系统的实现细节,可能导致未定义的行为。在实践中,访问已释放的内存是一种危险的做法,因
为它可能导致程序的崩溃或不稳定的行为。
*/
return 0;
}
12.1.7:动态内存可以跨函数使用
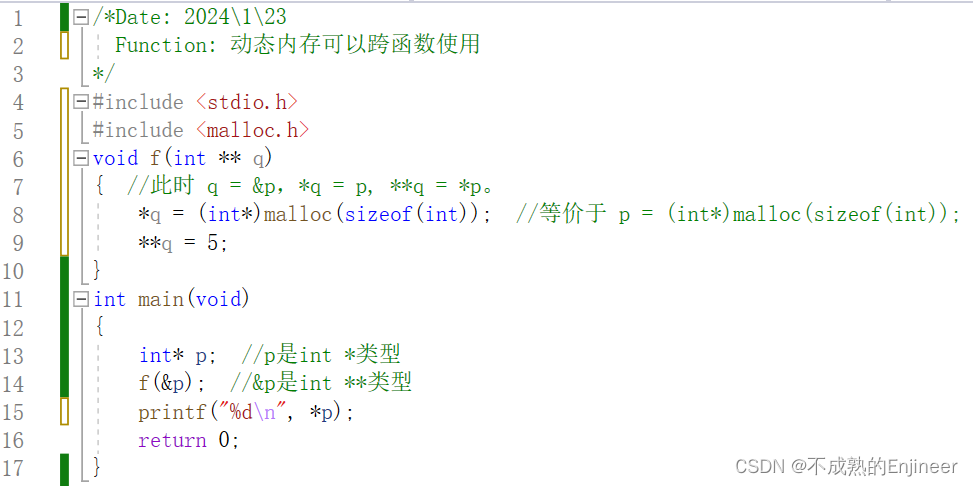
/*Date: 2024\1\23
Function: 动态内存可以跨函数使用
*/
#include <stdio.h>
#include <malloc.h>
void f(int ** q)
{ //此时 q = &p,*q = p, **q = *p。
*q = (int*)malloc(sizeof(int)); //等价于 p = (int*)malloc(sizeof(int));
**q = 5;
}
int main(void)
{
int* p; //p是int *类型
f(&p); //&p是int **类型
printf("%d\n", *p);
return 0;
}
12.1.8:free()函数
- free()函数的参数是之前malloc()返回的地址,该函数释放之前malloc()分配的内存,以避免内存泄漏。
- free()函数也可用于释放calloc()分配的内存。
- free()所用的指针变量可以与malloc()的指针变量不同,但是两个指针必须存储相同的地址,但是不能释放同一块内存两次。
12.1.9:calloc()函数
long * newman = (long *)calloc(100, sizeof(long));
calloc()函数接收两个无符号整数作为参数,第1个参数是所需的存储单元数量,第2个参数是存储单元的大小(以字节为单位)。
calloc()函数还有一个特性就是它把块中所有位都设置为0。
12.2:存储类别
12.2.1:作用域
程序中变量、函数和其他标识符的作用域(Scope)决定了其可见性和访问性。文件作用域变量也称全局变量(global variable)。
12.2.2:块
块是用一对花括号{}括起来的代码区域。
12.2.3:链接
C变量有三种链接属性:外部链接,内部链接或无链接。
具有块作用域、函数作用域、函数原型作用域的变量都是无链接变量,这意味着这些变量属于定义它们的块,函数或函数原型私有。
具有文件作用域的变量可以是外部链接或内部链接。外部链接变量可以在多文件中使用,内部链接变量只能在一个翻译单元内使用。
12.2.4:翻译单元
翻译单元:即一个源代码文件(.c扩展名)和它所包含的头文件(.h扩展名)。
12.2.5:存储区
作用域和链接描述了标识符的可见性,存储期描述了通过这些标识符访问的对象的生存期。C对象有4种存储期:静态存储期、线程存储期、自动存储期、动态分配存储期。
12.3:auto关键字
- auto说明符表面变量是自动存储期,只能用于块作用域的变量声明中。由于在块中声明的变量本身就具有自动存储期,所以使用auto主要是为了明确表达要使用与外部变量同名的局部变量的意图。
- 但在现代C语言中,它的使用已经不太常见,因为在函数内部声明的局部变量默认就是auto 的,即具有自动存储类别。
12.4:register关键字
- register说明符也只作用于块作用域的变量,它把变量归为寄存器存储类别,请求最快速度访问该变量。同时,因为寄存器变量存储在寄存器中而非内存中,所以无法获取寄存器变量的地址。
- 声明为register类别的变量与直接命令相比更像是一种请求,编译器必须根据寄存器或最快可用内存的数量衡量你的请求,或直接忽略你的请求,此时寄存器变量就会变成普通的自动变量,即便如此,仍然不能对该变量使用地址运算符。
12.5:static关键字
- 用static说明符创建的对象具有静态存储期,载入程序时创建对象,程序结束时对象消失。static用于文件作用域声明时,作用域受限于该文件;static用于块作用域声明时,作用域首先于该块。即static作用于全局变量时,只在声明它的源文件中可见,不能被其它文件访问;
- 不能在函数形参中使用static;
12.6:extern关键字
- extern说明符表面声明的变量定义在其它文件中。
- 外部变量只能初始化一次,并且只能在定义该变量时进行。
12.7:volatile关键字
volatile 是一个关键字,用于告诉编译器,某个变量的值可能会在程序的控制之外被改变,因此编译器不应该对这个变量进行优化或假设它的值是不变的。volatile 关键字通常用于以下情况:
- 内存映射的硬件寄存器:在嵌入式系统中,常常会将硬件寄存器映射到特定的内存地址。这些寄存器的值可能会被外部设备或者其他部分的程序修改,因此需要使用 volatile 来告诉编译器不要对这些寄存器的访问进行优化。
- 多线程共享变量:在多线程程序中,如果一个变量被多个线程访问并可能被其他线程修改,就应该使用 volatile 修饰这个变量,以确保每次访问都是从内存中读取最新的值,而不是依赖于缓存。
- 信号处理器中修改的变量:如果一个变量在程序的信号处理器中被修改,而主程序也在使用这个变量,就需要使用 volatile 来确保主程序能够看到信号处理器中对变量的修改。
12.8:restrict关键字
restrict关键字允许编译器优化某部分代码以更好地支持计算,它只能用于指针,表明该指针是访问数据对象的唯一且初始的方式。
这个关键字允许编译器进行更好的优化,因为它可以确保指针访问的内存区域不会与其他指针发生重叠。以下是 restrict 关键字的用途:
- 优化循环:如果在循环中使用 restrict 关键字,编译器可以更好地理解指针之间的关系,并进行更有效的优化。
- 函数参数:如果一个函数的参数使用了 restrict 关键字,编译器可以假设这些参数不会指向相同的内存区域,从而可以进行更好的优化。
- 内存复制:restrict 关键字也可以用于 memcpy() 和类似的内存复制函数中,帮助编译器生成更有效率的代码。
12.9:_Atomic关键字
在C11标准中,_Atomic 是一个关键字,用于声明原子类型。原子类型提供了一种线程安全的方式来访问内存,确保在多线程环境下对内存的读取和写入操作是原子的。
使用 _Atomic 关键字声明的变量可以确保对其进行的读取和写入操作是原子的,即这些操作要么完全执行,要么完全不执行,不会被线程调度器打断。这在多线程编程中特别重要,可以避免竞态条件和数据竞争。
十三:文件处理
13.1:无缓冲输入与缓冲输入
- 无缓冲输入:用户输入字符后立即重复打印该字符属于无缓冲(或直接)输入,即正在等待的程序可立即使用输入的字符。
- 缓冲输入:在用户按下Enter键之前不会重复打印刚输入的字符,这种输入形式属于缓冲输入。(用户输入的字符被收集并存储在一个称为缓冲区的零时存储区,按下Enter键后,程序才可使用用户输入的字符。)
13.2:缓冲区为什么存在?
- 把若干字符作为一个块进行传输比逐个发送这些字符节约时间。
- 若用户输入错误,可以通过键盘修正。
- 虽然缓冲区有很多好处,但是某些交互式程序也需要无缓冲输入,例如打游戏时的按键操作。
13.3:缓冲区的分类(完全缓冲/行缓冲)
- 完全缓冲I/O:当缓冲区被填满时才刷新缓冲区(内容被发送至目的地),通常出现在文件输入中。缓冲区大小取决于系统,常见的大小是512字节和4096字节。
- 行缓冲I/O:指出现换行符时刷新缓冲区,键盘输入通常是行缓冲输入,所以摁下Enter键后才刷新缓冲区。 按下Enter键时也传送了一个换行符,编程时要注意处理这个换行符。
13.4:文件
13.4.1:什么是文件?
- 文件(file)通常是在磁盘或固态硬盘上的一段已命名的存储区;
- 对操作系统而言,文件更为复杂,大型文件会被分开存储,或者包含一些额外的数据,方便操作系统确定文件的种类;
- C把文件看作一系列的字节,每个字节都能被单独读取;
- C提供两种文件模式:文本模式和二进制模式;
- 所有文件的内容都以二进制形式存储;
- 在二进制模式中,程序可以访问文件的每个字节;而在文本模式中,程序所见的内容和文件的实际内容不同;程序以文本模式读取文件时,把本地环境表示的行末尾或文件结尾映射为C模式;
13.4.2:底层I/O与标准高级I/O
- 底层I/O:操作系统提供的I/O服务;
- 标准高级I/O:C库的标准包和stdio.h头文件定义;
13.4.3:fopen()函数
FILE* fp;
fp = fopen("C:\\Users\\V330\\Desktop\\moment.txt", "r");
- 该函数声明在stdio.h中,它的第一个参数是带打开文件的名称,更确切的说是一个包含该文件名的字符串地址;第二个参数是一个字符串,指定待打开文件的模式;
- 如果使用任何一种"w"模式(不带x字母)打开一个现有文件,该文件的内容会被删除,以使程序在一个空白文件中开始操作;如果使用带x字母的任何一种模式,由于x模式的独占特性使得其它程序或线程无法访问正在被打开的文件;
- fopen()函数将返回一个文件指针(file pointer),其它I/O函数可以使用这个指针指定该文件;
- 文件指针(该例中是fp)的类型是指向FILE的指针,FILE是一个定义在stdio.h中的派生类型,文件指针fp并不指向实际的文件,它指向一个包含文件信息的数据对象,其中包含操作文件的I/O函数所用的缓冲区信息,因为标准库中的I/O函数使用缓冲区,所以它们不仅要知道缓冲区的位置,还要知道缓冲区被填充的程度以及操作哪一个文件;
13.4.4:文件指针
文件指针(该例中是fp)的类型是指向FILE的指针,FILE是一个定义在stdio.h中的派生类型,文件指针fp并不指向实际的文件,它指向一个包含文件信息的数据对象,其中包含操作文件的I/O函数所用的缓冲区信息,因为标准库中的I/O函数使用缓冲区,所以它们不仅要知道缓冲区的位置,还要知道缓冲区被填充的程度以及操作哪一个文件。
13.4.5:getc()和putc()函数

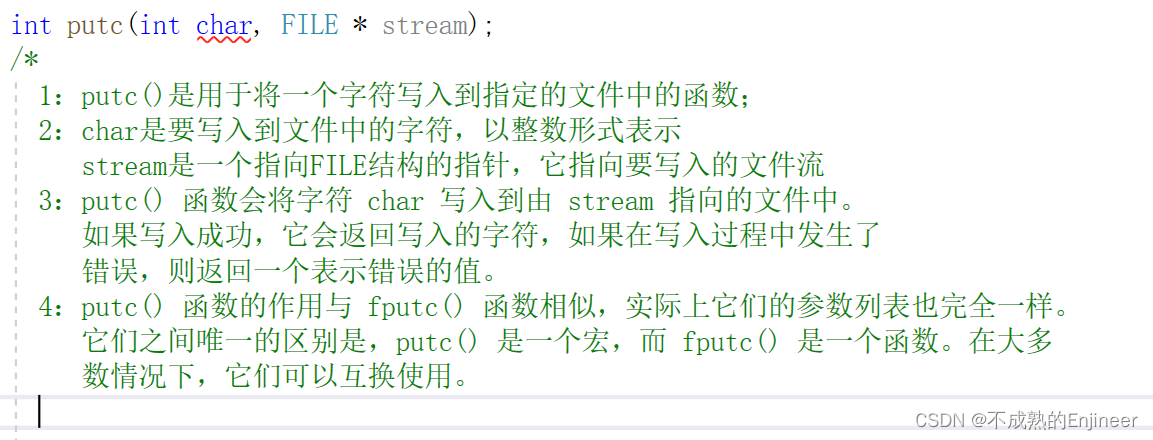
13.4.6:文件结尾
无论操作系统实际使用何种方式检测文件结尾,在C语言中,用getchar()读取文件检测到文件结尾时将返回一个特殊的值,即EOF(end of file)。scanf()函数检测到文件结尾时也返回EOF。通常EOF定义在stdio.h文件中:#define EOF (-1)
过去操作系统使用内嵌的Ctrl+Z字符来标记文件结尾,操作系统使用的另一种方法是存储文件大小的信息。
13.4.7:fclose()函数
- fclose(fp)函数关闭fp指定的文件,必要时刷新缓冲区,对于较正式的程序,应该检查是否成功关闭文件,如果关闭成功,函数返回0,关闭失败返回EOF;
- 如果磁盘已满,移动硬盘被移除或出现I/O错误,都会导致调用fclose()函数失败;
13.4.8:fprintf()、fscanf()函数

FILE* fp;
int num = 10;
fp = fopen("output.txt", "w"); // 打开文件以进行写入
fprintf(fp, "The value of num is: %d\n", num);
//fprintf() 函数被用来将整数 num 写入到文件 output.txt 中
//The value of num is: 同样也被写入文件 output.txt 中

FILE* fp;
int num1;
float num2;
fp = fopen("data.txt", "r");
fscanf(fp, "%d %f", &num1, &num2);
//fscanf(fp, "%d %f", &num1, &num2);
//语句从文件中读取一个整数和一个浮点数,并将它们分别存储到 num1 和 num2 变量中
13.4.9:fgets()、fputs()函数

fgets(buf, STLEN, fp);
/* 1.fgets()函数会从指定的文件流中读取字符,直到达到指定的字符数(包括换行符\n)
或者遇到换行符为止,然后将这一行文本存储到指定的字符串缓冲区中。
2.buf是char类型数组的名称,STLEN是字符串的大小,fp是指向FILE的指针。
3.fgets()函数在遇到EOF时将返回NULL值,可以利用这一机制检查是否到达文件结尾,
如果未遇到EOF则返回之前传给它的第一个参数地址。
*/
fputs(buf, fp);
/* 1.该函数根据传入的地址找到对应的字符串,并将其写入指定文件中。
2.与puts()函数不同,fputs()在打印字符串时不会在其末尾添加换行符。
3.buf是字符串的地址,fp用于指定目标文件。
*/
13.4.10:fseek()、ftell ()函数

fseek(fp, 0L, SEEK_SET);
/* 1.fp是FILE指针,指向待查找的文件,0L表示偏移量,表示从起始点开始要移动的距离
L后缀表示其值是long类型。SEEK_SET表示模式,该参数确定起始点。
SEEK_SET 文件开始处
SEEK_CUR 当前位置
SEEK_END 文件末尾
2.一切正常,fseek()的返回值为0,如果出现错误(如试图移动的距离超出文件的范围)
其返回值为-1。
*/
ftell(fp);
/*函数的返回类型是long,返回的参数是指向文件的当前位置距文件开始处的字节数*/
13.4.11:fgetpos()、fsetpos()函数
fseek()和ftell()潜在的问题是,他们都把文件大小限制在long类型能表示的范围内。但随着存储设备的容量迅猛增加,文件也越来越大,ANSI C新增了两个处理较大文件的新定位函数:fgetpos()和fsetpos(),这两个函数不使用long类型的值表示位置,它们使用一种新类型:fpos_t(),代表file position type文件定位类型,不是基本类型,它根据其它类型来定义。
13.4.12:文件、流
- 文件:是存储器中存储信息的区域。
- 流:是一个实际输入或输出映射的理想化数据流。这意味着不同属性和不同种类的输入,由属性更统一的流来表示。打开文件的过程就是把流和文件相关联,而且读写都通过流来完成。(从概念上看,C程序处理的是流而不是直接处理文件。)
- 要访问文件,必须创建文件指针(类型是FILE *)并把指针与特定文件名相关联,随后的代码就可以使用这个指针来处理文件。
13.4.13:标准I/O的机理
通常标准I/O的第1步是调用fopen()打开文件,fopen()函数不仅打开一个文件,还创建了一个缓冲区(在读写模式下会创建两个缓冲区)以及一个包含文件和缓冲区数据的结构。另外fopen()返回一个指向该结构的指针,以便其他函数知道如何找到该结构。假设把该指针赋给一个指针变量fp,我们说fopen()函数打开一个流,如果以文本模式打开该文件,就获得一个文本流,如果以二进制模式打开该文件,就获得一个二进制流。
这个结构通常包含一个指定流中当前位置的文件位置指示器,还包含错误和文件结尾的指示器、一个指向缓冲区开始处的指针、一个文件标识符和一个计数(统计实际拷贝进缓冲区的字节数)。
第2步就是调用一个定义在stdio.h中的输入函数,一调用这些函数,文件中的缓冲大小数据块就被拷贝到缓冲区,缓冲区的大小因实现而异,一般是512字节或是它的字节。最初调用函数,除了填充缓冲区外,好药设置fp所指向的结构中的值,尤其奥设置流中的当前位置和拷贝进缓冲区的字节数,通常,当前位置从字节0开始。
13.5:重定向输入与输出
- 重定向输入让程序使用文件而不是键盘来输入。
- 重定向输出让程序输出至文件而不是屏幕。
十四:结构和其它数据类型
14.1:结构体
14.1.1:为什么需要结构体?
为了表示一些复杂的事物,而普通的基本类型无法满足实际需要。
14.1.2:什么叫结构体?
v把一些基本数据类型组合在一起形成一个新的复合数据类型,这个叫做结构体。
14.1.3:如何定义一个结构体?
- 首先是关键字struct,它表明跟在其后的是一个结构,后面是一个可选的标记(下面例子中是Student)。
- 成员可以是任意一种C的数据类型,甚至可以是其他的结构体。
- 右花括号后面的分号是声明所必需的,表示结构布局定义结束。
- 如果把结构声明置于一个函数内部,它的标记就只限于该函数内部使用,如果结构声明置于函数的外部,那么该声明之后所有函数都能使用它的标记。


//第一种方式(推荐使用)
struct Student //定义了一个struct Student的数据类型
{
int age;
float score;
char gender;
};
//第二种方式
struct Student2
{
int age;
float score;
char gender;
}st2; //在定义结构体的同时声明一个结构体变量
//第三种方式
struct
{
int age;
float score;
char gender;
}st3;
14.1.4:如何使用结构体变量?
14.1.5:赋值和初始化
- 定义的同时可以整体赋初值,如果定义完之后,则只能单个的赋初值。
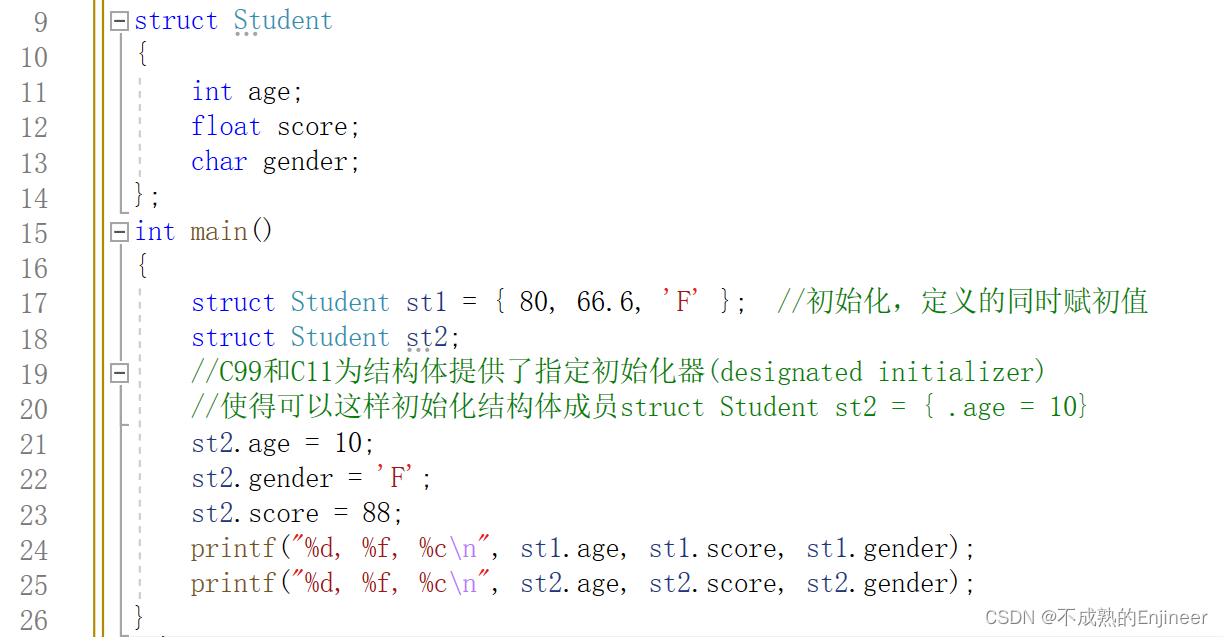
/* Time: 2024/2/22
* Functions:结构体的赋值与初始化
*
*/
#include <stdio.h>
#include <stdlib.h>
struct Student
{
int age;
float score;
char gender;
};
int main()
{
struct Student st1 = { 80, 66.6, 'F' }; //初始化,定义的同时赋初值
struct Student st2;
//C99和C11为结构体提供了指定初始化器(designated initializer)
//使得可以这样初始化结构体成员struct Student st2 = { .age = 10}
st2.age = 10;
st2.gender = 'F';
st2.score = 88;
printf("%d, %f, %c\n", st1.age, st1.score, st1.gender);
printf("%d, %f, %c\n", st2.age, st2.score, st2.gender);
}
/*
定义的同时可以整体赋初值;
如果定义完之后,则只能单个的赋初值。
*/
14.1.6:如何访问结构体变量中的成员
- 使用结构体成员运算符—.(点)访问结构体中的成员。
- 结构体变量名.(点)结构体成员名。
- 指针变量名->结构体成员名。
- 指针变量名->结构体成员名 在计算机内部会被转化成(*指针变量名).(点)结构体成员名。
- st1是一个结构体变量,但是st1.age是一个int类型的变量,可以像使用其他int类型变量那样使用它(下图的例子)。
- pst->score的含义:pst所指向的那个结构体变量中的score这个成员。

/* Time: 2024/2/22
* Functions:如何取出结构体变量中的每一个成员
*/
#include <stdio.h>
#include <stdlib.h>
struct Student
{
int age;
float score;
char gender;
};
int main()
{
struct Student st1 = {80, 66.6, 'F'}; //初始化,定义的同时赋初值
struct Student * pst = &st1; //st2是结构体指针,只能存放struct Student数据类型
//的地址
st1.age = 10; //结构体变量名.结构体成员名
pst->score = 100; //指针变量名->结构体成员名
//pst->score在计算机内部会被转化成(*pst).score
//pst->score等价于(*pst).score等价于st1.score
//pst->score的含义:pst所指向的那个结构体变量中的score这个成员
return 0;
}
14.1.7:成员运算符和间接成员运算符
- 成员运算符.(点)。
- 间接成员运算符->。
14.1.8:结构体变量的运算
- 结构体变量不能相互相加减乘除,但是可以相互赋值。
14.1.9:结构体数组
- 声明结构体数组和声明其他类型的数组类似。
- 点运算符右侧的下标作用于各个成员,点运算符左侧的下标作用于结构体数组。


/* Time: 2024/2/23
* Functions:结构体数组的声明及应用
*/
#include <stdio.h>
#include <stdlib.h>
struct Student
{
int age;
float score;
char name[5];
};
int main()
{
struct Student st[2]; //声明结构体数组
/*把st声明为一个内含2个元素的数组,数组的每个元素都是一个struct Student类型的结构体
因此st[0]是第一个struct Student类型的结构体变量,st[1]是第二个struct Student类型的
结构体变量
*/
st[0].age = 10;
st[1].name[3]; //这是st数组第2个结构体变量(st[1])中name的第4个字符(name[3])
/*点运算符右侧的下标作用于各个成员,点运算符左侧的下标作用于结构体数组
st:一个struct Student结构的数组
st[1]:一个数组元素,该元素是struct Student结构
st[1].name:一个char类型的数组(st[1]中的name成员)
st[1].name[3]; //这是st数组第2个结构体变量(st[1])中name的第4个字符(name[3])
*/
}
14.1.10:结构体的嵌套
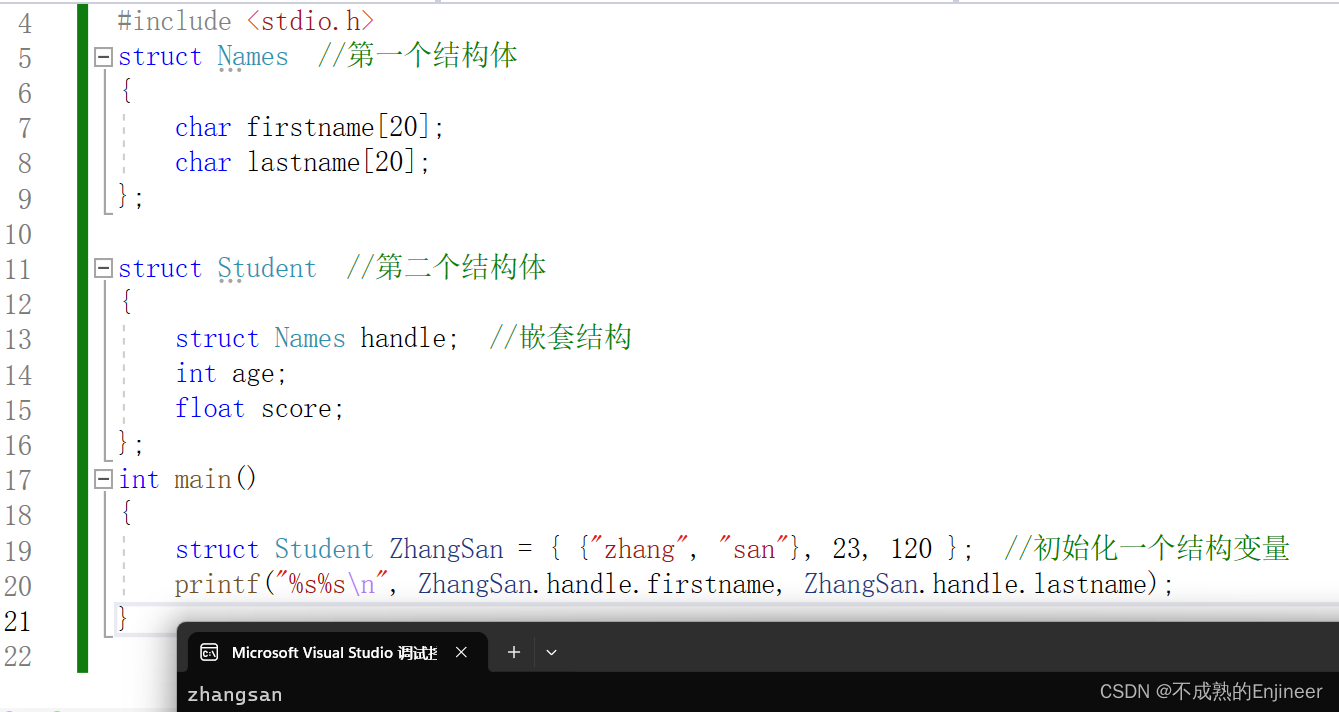
/* Time: 2024/2/23
* Functions:结构体的嵌套
*/
#include <stdio.h>
struct Names //第一个结构体
{
char firstname[20];
char lastname[20];
};
struct Student //第二个结构体
{
struct Names handle; //嵌套结构
int age;
float score;
};
int main()
{
struct Student ZhangSan = { {"zhang", "san"}, 23, 120 }; //初始化一个结构变量
printf("%s%s\n", ZhangSan.handle.firstname, ZhangSan.handle.lastname);
}
14.1.11:指向结构体的指针
14.1.12:声明和初始化结构体指针
struct Student *st1;声明结构体指针。- 和数组不同的是,结构体变量名并不是结构体变量的地址。
- 在有些系统中,一个结构体的大小可能大于它各个成员大小之和,这是因为系统对数据进行校准的过程中产生了一些"缝隙",比如有些系统必须把每个成员都放在偶数地址上,或4的倍数的地址上,因此结构体的内部就存在未使用的"缝隙"。
14.1.13:结构体变量和结构体指针变量作为函数参数传递的问题
- 推荐使用结构体指针变量作为函数参数来传递。



/* Time: 2024/2/22
* Functions:结构体变量和结构体指针变量作为函数参数传递的问题
*/
#include <stdio.h>
#include <string.h>
struct Student
{
int age;
char name[100];
char gender;
}; //分号不能省
void InputStudent_error(struct Student stu); //函数声明
void InputStudent(struct Student * stu);
void OutputStudent(const struct Student stu);
int main()
{
struct Student st = {0, "小娟", 'F'}; //st1是struct Student类型的变量
InputStudent_error(st); //对结构体变量进行输入
InputStudent(&st);
OutputStudent(&st); //对结构体变量进行输出,可以发送st的地址也可以发送st的内容
return 0; //但为了减少内存的耗费,也为了提高执行速度,推荐发送地址
}
/* 被调函数使用的值是从主调函数中拷贝过来的,所以无论被调函数
对拷贝数据进行什么操作,都不会影响主调函数中的原始数据。
所以本函数无法修改主函数st中的成员值
*/
void InputStudent_error(struct Student stu)
{
stu.age = 10;
strcpy_s(stu.name, "张三"); //不能写成stu.name = "张三",因为stu.name是数组名,
//是地址,不能赋值的
stu.gender = 'F';
}
//通过被调函数来改变主函数中变量的值必须要使用指针
void InputStudent(struct Student * pstu)
//一个变量的地址是用该变量首字节的地址来表示的
//一个指针变量,无论它指向的变量占几个字节,该指针变量在32位计算机上占4个字节,
//在64位计算机上占8个字节,所以pstu占8个字节
{
pstu->age = 10;
strcpy_s(pstu->name, "张三");
pstu->gender = 'M';
}
//如果不需要通过被调函数来更改主函数中变量的值,则被调函数可以不用指针
//可以发送st的地址也可以发送st的内容
//但从设计函数的角度,函数的功能越单一越好,带有指针的输出函数,可能会改写数据
//所以加const防止数据的误改
//const放在*左侧任意位置,限定了指针指向的数据不能改变,const放在*右侧,限定了
//指针本身不能改变。
void OutputStudent(const struct Student *stu)
{
printf("%d, %c, %s\n", stu->age, stu->gender, stu->name);
}
14.1.14:动态构造存放学生信息的结构体数组
/* Time: 2024/2/22
* Functions:动态构造存放学生信息的结构数组,动态构造一个数组,存放学生的信息
* 然后按分数排序输出
*/
#include <stdio.h>
#include <string.h>
#include <malloc.h>
struct Student
{
int age;
float score;
char name[100];
};
int main()
{
int len;
struct Student* pArr;
int i, j;
struct Student t;
printf("请输入学生的个数:\n");
printf("len = ");
scanf_s("%d", &len);
pArr = (struct Student*)malloc(len * sizeof(struct Student)); //动态的构造一维数组
for (i = 0; i < len; i++) //信息录入
{
printf("请输入第%d个学生的信息: ", i+1);
printf("age = ");
scanf_s("%d", &pArr[i].age);
printf("name = ");
scanf_s("%s", pArr[i].name, 100); //name是数组名,本身就已经是数组首元素的地址
//所以pArr[i].name不需要加取地址符
printf("score = ");
scanf_s("%f", &pArr[i].score);
}
for (i = 0; i < len - 1; i++) //按学生成绩冒泡升序排序
{
for (j = 0; j < len-1-i; j++)
{
if (pArr[j].score > pArr[j+1].score) //注意不能这样比较pArr[j]> pArr[j+1]
{ //因为结构体整体不能比较
t = pArr[j];
pArr[j] = pArr[j + 1];
pArr[j + 1] = t;
}
}
}
for (i = 0; i < len; i++) //信息输出
{
printf("第%d个学生的信息是: ", i + 1);
printf("age = %d\n", pArr[i].age);
printf("name = %s\n", pArr[i].name);
printf("score = %f\n", pArr[i].score);
}
return 0;
}
14.1.15:结构体的其他特性
- 现在的C允许把一个结构体赋值给另一个结构体,两个结构体必须是相同类型,但是数组不能这样做。
- 可以把一个结构体初始化为另一个相同类型的结构体。
struct Student st1 = {10, 100};
struct Student st2 = st1;
3.函数不仅能把结构体本身作为参数传递,还能把结构体作为返回值返回。
14.1.16:结构体中的字符数组和字符指针
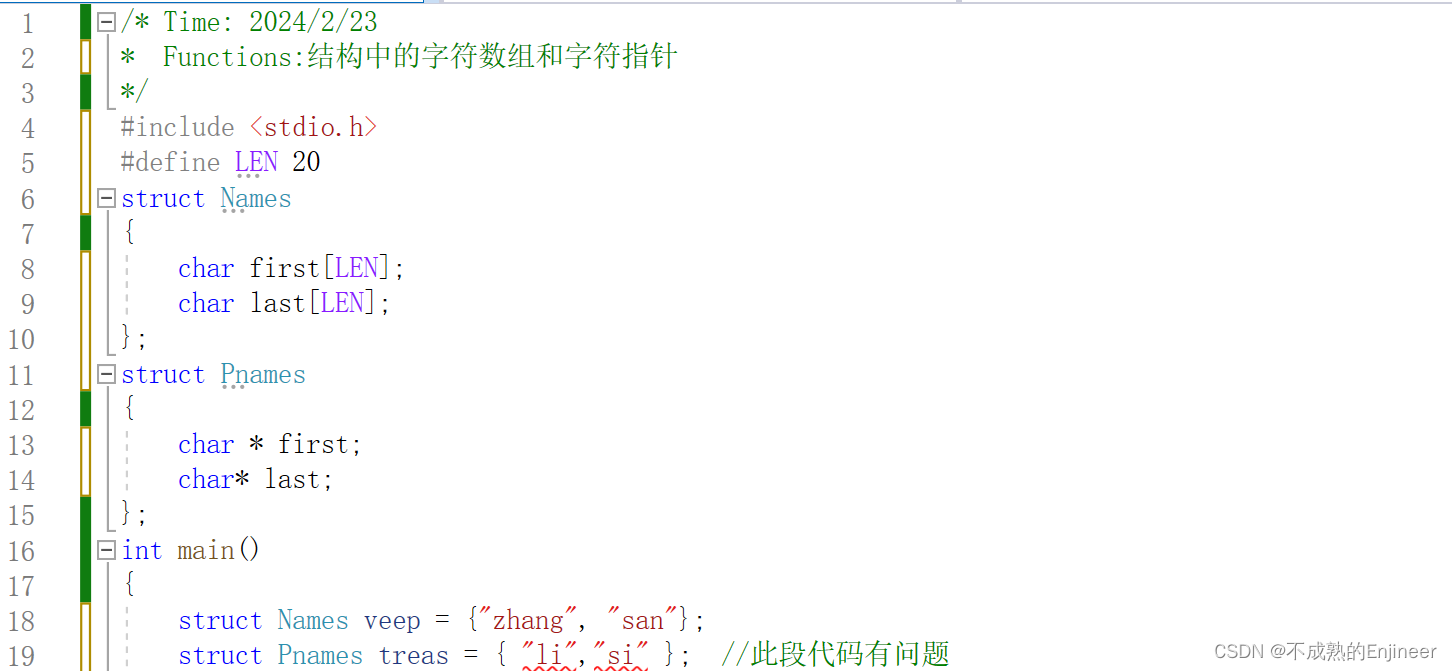

/* Time: 2024/2/23
* Functions:结构中的字符数组和字符指针
*/
#include <stdio.h>
#define LEN 20
struct Names
{
char first[LEN];
char last[LEN];
};
struct Pnames
{
char * first;
char* last;
};
int main()
{
struct Names veep = {"zhang", "san"};
struct Pnames treas = { "li","si" }; //此段代码有问题
//struct Pnames 中的 first 和 last 是指针类型,但是你没有为它们分配
//内存空间来存储字符串。你需要确保这些指针指向有效的内存,以便存储
//字符串。
/*对于struct Names类型的结构体变量veep,以上字符串都存储在结构体内部,结构体总共要分配
* 40个字节存储姓名,对于struct Pnames类型的结构体变量treas,以上字符串存储在编译器存储
* 常量的地方,结构体本身只存储了两个地址,struct Pnames结构体不用为字符串分配任何存储空
* 间,它使用的是存储在别处的字符串。简而言之,在struct Pnames结构体变量中的指针应该只用
* 来在程序中管理那些已分配和在别处分配的字符串。
*/
}
14.1.17:使用结构体指针的好处
- 就像指向数组的指针比数组本身更容易操控一样(如排序问题),指向结构体的指针通常比结构体本身更容易操控。
- 早期的C中,结构体不能作为参数传递给函数,但是可以传递指向结构体的指针。
- 即使能传递一个结构体,传递指针通常更有效率。
- 一些用于表示数据的结构体中包含指向其他结构体的指针。
14.1.18:链式结构
工程师已经开发出一些数据形式比之前提到过的数组和简单的结构体更有效的解决特定的问题这些形式包括队列、二叉树、堆、哈希表和图表,这些形式都由链式结构(linked structure)组成,通常每个结构都包含一两个数据项和一两个指向其他同类型数据的指针,这些指针把一个结构和另一个结构链接起来,并提供一种路径能遍历整个彼此链接的结构。
14.2:枚举
14.2.1:什么是枚举?
把一个事物所有可能的取值一一列举出来叫做枚举。
14.2.2:怎么样使用枚举?
- 实际上,enum常量是int类型,因此,只要能使用int类型的地方就可以使用枚举类型。枚举类型的目的是提高程序的可读性。
- 如果只给一个枚举常量赋值,没有对后面的枚举常量赋值,那么后面的常量就会备赋予后续的值。



/* Time: 2024/2/23
* Functions:枚举的使用
*/
#include <stdio.h>
void f(enum WeekDay i);
//只定义了一个数据类型,并没有定义变量,该数据类型的名字是enum WeekDay
enum WeekDay
{
Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday
};
int main()
{
enum WeekDay day = Monday;
f(day);
return 0;
}
void f(enum WeekDay i) //本函数的目的只是期望接受0-6之间的数字,将形参i定义位枚举
{
switch (i)
{
case Monday:
printf("Monday!\n");
break;
case Tuesday:
printf("Tuesday!\n");
break;
case Wednesday:
printf("Wednesday!\n");
break;
case Thursday:
printf("Thursday!\n");
break;
case Friday:
printf("Friday!\n");
break;
case Saturday:
printf("Saturday!\n");
break;
case Sunday:
printf("Sunday!\n");
break;
default:
break;
}
}
14.2.3:枚举的优缺点
- 代码更加安全。
- 书写麻烦
14.3:联合体
14.3.1:什么是联合体?
- 联合(union)是一种数据类型,它能在同一内存空间中存储不同的数据类型(不是同时存储),其典型用法是,设计一种表来存储既无规律,事先也不知道顺序的混合类型。使用联合类型的数组,其中的联合体大小都相等,每个联合体可以存储各种数据类型。
- 联合体的成员共享一个共同的存储空间,联合体同一时间内只能存储一个单项数据,不像结构体那样同时存储多种数据类型,也就是说:结构体可以同时存储一个int类型,一个double类型,一个char类型的数据,但是联合体只能保存一个int类型或者一个double类型或者一个char类型的数据。
14.3.2:怎么声明和初始化联合体?
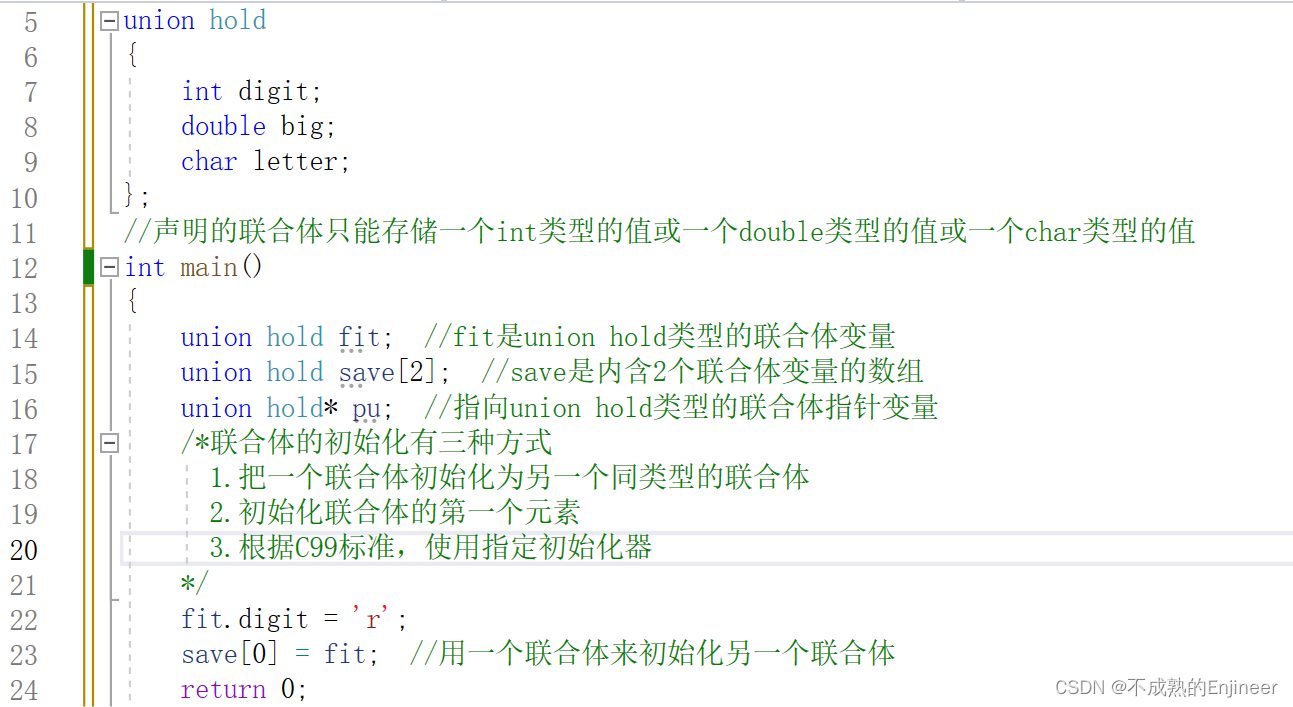
/* Time: 2024/2/23
* Functions:联合体的声明与初始化
*/
#include <stdio.h>
union hold
{
int digit;
double big;
char letter;
};
//声明的联合体只能存储一个int类型的值或一个double类型的值或一个char类型的值
int main()
{
union hold fit; //fit是union hold类型的联合体变量
union hold save[2]; //save是内含2个联合体变量的数组
union hold* pu; //指向union hold类型的联合体指针变量
/*联合体的初始化有三种方式
1.把一个联合体初始化为另一个同类型的联合体
2.初始化联合体的第一个元素
3.根据C99标准,使用指定初始化器
*/
fit.digit = 'r';
save[0] = fit; //用一个联合体来初始化另一个联合体
return 0;
}
14.3.2:联合体的使用

/* Time: 2024/2/23
1. Functions:联合体的使用
*/
#include <stdio.h>
union hold
{
int digit;
double big;
char letter;
};
//声明的联合体只能存储一个int类型的值或一个double类型的值或一个char类型的值
int main()
{
union hold fit;
fit.digit = 23; //把23存储在fit中,占4个字节
fit.big = 2.2; //清除23,存储2.2,占8个字节
fit.letter = 'h'; //清除2.2,存储h,占1个字节
//点运算符表示正在使用哪种数据类型,在联合体中一次只存储一个值,即使有足够的空间
//也不能同时存储一个char类型的值和一个int类型的值。编写代码时要注意当前存储在联合
//体中的数据类型
return 0;
}
14.4:typedef
- typedef工具是一个高级数据特性,利用typedef可以为某一类型自定义名称。
- 通常,typedef定义中用大写字母表示被定义的名称,以提醒用户这个类型名实际上是一个符号缩写。
- typedef能提高程序的可移植性。
- typedef为经常出现的类型创建一个方便、易识别的类型名。
- 用typedef来命名一个结构类型时,可以省略该结构的标签。
- typedef常用于给复杂的类型命名。
- 使用typedef要注意,typedef并没有创建任何新类型,它只是为某个已存在的类型增加了一个方便使用的标签。
14.4.1:typedef与#define的不同
- 与#define不同,typedef创建的符号名只受限于类型,不能用于值。
- typedef有编译器解释,不是预处理器。
- 在其受限范围内,typedef比#define更灵活。
14.4.2:typedef用法

/* Time: 2024/2/23
* Functions:typedef用法辨析
*/
#include <stdio.h>
#define BYTE unsigned char //使得预处理器用BYTE替换unsigned char
typedef char* STRING;
/*没有typedef关键字,编译器将把STRING识别为一个指向char类型的指针变量。有了typedef
关键字,编译器则把STRING解释成一个类型的标识符,该类型是指向char的指针。
STRING name, sign相当于: char *name, *sign;
但是如果这样假设:#define STRING char*
STRING name, sign;将被翻译为char *name, sign;这导致只有name才是指针。
*/
14.5:复杂的声明
- 数组名后面的[ ]和函数后面的( )具有相同的优先级,它们比*(解引用运算符)的优先级高,因此下面声明的risk是一个指针数组,不是指向数组的指针。
- [ ]和( )的优先级相同,由于都是从左往右结合,所以下面的声明中,在应用[ ]之前,*先与rusks结合因此rusks是一个指向数组的指针,该数组内含10个int类型的元素。
int(*rusks)[10]; - [ ]和( )都是从左往右结合,因此下面声明的goods是一个由12个内含50个int类型值的数组组成的二维数组,不是一个有50个内含12个int类型值的数组组成的二维数组。
int doods[12][50]; int oof[3][4];[3]比*优先级高,由于从左往右结合,所以[3]先于oof结合,因此oof首先是一个内含3个元素的数组然后再与[4]结合,所以oof每个元素都是内含4个元素的数组,*说明这些元素都是指针。最后int表明了这4个元素都是指向int的指针。

int board[8][8]; //声明一个内含int数组的数组
int** ptr; //声明一个指向指针的指针,被指向的指针指向int类型
int* risk[10]; //声明一个内含10个元素的数组,每个元素都是一个指向int类型的指针
int(*rusk)[10]; //声明一个指向数组的指针,该数组内含10个int类型的值
int* oof[3][4]; //声明一个3*4的二维数组,每个元素都是指向int的指针
int(*uuf)[3][4]; //声明一个指向3*4二维数组的指针,该数组内含int类型值
int(*uof[3])[4]; //声明一个内含3个指针元素的数组,其中每个指针都指向一个内含4个int类型
//元素的数组

typedef int arr5[5];
typedef arr5 * p_arr5;
typedef p_arr5 arrp10[10];
arr5 togs; //togs是一个内含5个int类型值的数组
p_arr5 p2; //p2是一个指向数组的指针,该数组内含5个int类型的值
arrp10 ap; //ap是一个内含10个指针的数组,每个指针都指向一个内含5个int类型值的数组
十五:位操作
15.1:补码
15.1.1:学完补码应该知道哪些东西?
- 一个int类型的变量所能存储的数字的范围是多少?
int类型变量能存储的最大整数用16进制表示就是:0X7FFF FFFF,因为要是整数最高位必须为0,所以后面31位为1,故为0X7FFFFFFF。
int类型变量所能存储的绝对值最大的负整数用十六进制表示:0X8000 0000 - 最小负数的二进制代码是多少?
- 最大正数的二进制代码是多少?
- 已知一个整数的二进制代码求出原始的数字。
- 数字超过最大正数会怎样?
- 不同类型数据的相互转化
15.1.2:原码、反码、移码、补码

原码:也叫符号-绝对值码,最高位0表示正,最高位1表示负,其余二进制位是该数字的绝对值的二进
制数。
原码简单易懂,但加减运算复杂,存在加减乘除四种运算,增加了CPU的复杂度。
0的表示不唯一。
反码:反码运算不便,也没有在计算机中应用。
移码:移码表示数值平移n位,n称为移码量。
移码主要用于浮点数的阶码的存储。
补码:
已知十进制求二进制
求正整数的二进制
除2取余,直至商为0,余数倒序排列。
求负整数的二进制
先求与该负数相对应的正整数的二进制代码,然后将所有位取反,末尾加1,不够位数
时,左边补1。什么叫不够位数?将(-3)存储在int类型变量中,该变量共4个字节,32位。
(-3)对应的正整数为(3),二进制为(11),取反后为(00),加1(01),然后在左边补30个1,即
为(-3)的补码。其十六进制为0XFFFFFFD。
求0的二进制
变量占几个位(一个字节8位),就有几个0。
已知二进制求十进制
如果首位是0,则表明是正整数,按普通方法来求
如果首位是1,则表明是负整数
将所有位取反,末尾加1,所得数字就是该负数的绝对值
如果全是0,则对应的十进制数字就是0

#include <stdio.h>
int main()
{
char ch = 0x80; //一个字符占一个字节8位,0x80为:1000 0000;首位为1,按照补码其为负数,是-128
printf("%d\n", ch); //-128
ch = 128; //128为整型。32位,前28为都为0,但是将整型赋给浮点型前面的三个字节丢失,只变成
//1000 0000,所以为-128
printf("%d\n", ch); //-128
ch = 129;
printf("%d\n", ch); //按照补码为-127
return 0;
}
15.1.3:掩码
按位运算符常用于掩码(MASK),所谓掩码指的是一些设置为开(1)或关(0)的位组合。
可以把掩码中的0看作不透明,1看作透明,表达式flags & MASK相当于用掩码覆盖在flags的位组合上,只有MASK为1的位才可见。
15.2:链表
15.2.1:什么是算法?

/*
*算法:
* 通俗定义:
* 解题的方法和步骤。
* 狭义定义:
* 对存储数据的操作。
* 对不同的存储结构,要完成某一个功能所执行的操作是不一样的。
* 例如对输出数组中所有的元素的操作和要输出链表中所有元素的操作是不一样的。
* 算法是依附于存储结构的,不同的存储结构,所执行的算法是不一样的。
* 广义定义:
* 广义的算法也叫泛型,即无论数据是如何存储的,对该数据的操作都是一样的。
*/
15.2.2:链表与数组的对比

/*
* 我们至少有两种方法来存储数据:
* 数组:
* 优点:存储速度快。
* 缺点:需要一个连续的很大的内存,插入和删除元素的效率很低。
* 链表:
* 优点:插入删除元素效率高。
* 缺点:查找某个位置到达元素效率低,因为内存不连续,所以不能用下标查找,只能一个一个找。
*
* 链表的专业术语:
* 首节点:
* 存放第一个有效数据的节点。
* 尾节点:
* 存放最后一个有效数据的节点。
* 头节点:
* 头节点的数据类型和首节点的数据类型是一模一样的。
* 头结点是首节点前面的那个节点。
* 头节点并不存放有效数据。
* 设置头节点的目的是为了方便对链表的操作。
* 头指针:
* 存放头节点地址的指针。
*
* 确定一个链表只需要一个参数:头指针。
* 非空链表:头节点的指针域有指向那么就是非空链表。
*/
15.2.3:创建一个链表并遍历输出它



/* Time: 2024/2/26
* Functions:链表的基础知识
*/
#include <stdio.h>
#include <malloc.h>
#include <stdlib.h>
//定义一个链表节点的数据类型
struct Node //一个链表主要分为两个部分,一个数据域,一个指针域
{
int data; //数据域,存放该节点的数据
struct Node* pNext; //指针域,存放下一个节点的地址,即下一个结构体的地址
};
//函数声明
struct Node* create_list(void); //创建链表函数
bool empty_list(struct Node* pHead);
void traverse_list(struct Node* pHead);
int main()
{
struct Node* pHead = NULL;
pHead = create_list(); //create_list()函数动态的创建一个非循环的单链表,并返回该链表头节点的地址
traverse_list(pHead); //对链表进行遍历
return 0;
}
struct Node* create_list(void)
{
int len; //用来存放有效节点的个数
int i;
int val; //用来临时存放用户输入的节点的值。
//分配了一个不存放有效数据的头结点
struct Node * pHead = (struct Node *)malloc(sizeof(struct Node));
//malloc函数返回动态分配内存块的首字节地址,但是不知道这个地址指向的变量占几个字节,所以前面
//加struct Node *强制类型转化,将malloc返回的地址转为struct Node类型的地址
//pHead为头指针,存放头节点的地址
if (NULL == pHead) //如果动态内存分配失败将返回NULL
{
printf("分配失败!程序终止!\n");
exit(-1); //终止程序
}
struct Node* pTail = pHead;
pTail->pNext = NULL;
printf("请输入您需要生成链w表节点的个数:len = ");
scanf_s("%d", &len);
for (i = 0; i < len; ++i)
{
printf("请输入第%d个节点的值:", i + 1);
scanf_s("%d", &val);
struct Node* pNew = (struct Node*)malloc(sizeof(struct Node)); //为一个新的节点分配内存空间
if (NULL == pNew)
{
printf("分配失败,程序终止!\n");
exit(-1); //终止程序
}
pNew->data = val; //将要存的数据存入新的节点中
pTail->pNext = pNew; //将上一个节点的指针域指向新的节点
pNew->pNext = NULL; //将新的节点的指针域变成NULL
pTail = pNew; //将尾节点指向新创建的节点
}
return pHead;
}
bool empty_list(struct Node* pHead) //判断链表是否为空链表
{
if (NULL == pHead->pNext) //如果头节点的指针域没有指向,则为空链表
{
return true;
}
else
{
return false;
}
}
void traverse_list(struct Node* pHead) //遍历链表
{
struct Node* p = pHead->pNext; //将头节点的指针域地址赋给p,p指向下一个节点
while (NULL != p) //如果p没有存放地址,说明该链表为空
{
printf("%d\n", p->data); //将该节点的数据域中的数据输出
p = p->pNext; //将p的指针后移
}
return;
}
15.3:位运算符


/*
位运算符
&——按位与
&&逻辑与,也叫并且(逻辑运算符的结果只能是真或假)
&&和&的含义完全不同
|——按位或
||逻辑或
~——按位取反
~i就是把i变量所有的二进制位取反
^——按位异或(相同为0,不同为1)
<<——按位左移
i<<3表示把i所有二进制位左移3位,右边补零
左移n位相当于乘以2的n次方(10进制中左移n位相当于乘10的n次方)
>>——按位右移
i>>3表示把i所有二进制位右移3位,左边一般是补零(也可能补零)
右移n位相当于除以2的n次方,前提是数据不能丢失要保证数据的精确性
位运算符的实际意义:通过位运算符我们可以对数据的操作精确到每一位。
*/
15.4:NULL(地址0)

* 二进制全部为0的含义 ——000000的含义
* 1.数值0
* 2.字符串结束标记符‘\0’
* 3.空指针NULL
* NULL的本质也是0,但是这个0不代表数字0,表示的是内存单元的编号0
* 计算机规定以0为编号的存储单元的内容不可读,不可写。
*
*/
15.5:再论一个字节为8位
C语言用字节表示存储系统字符集所需的大小,所以C字节可能是8位,9位,16位或其他值,不过,描述存储器芯片和数据传输率中所用的字节指的是8位字节。从左往右第一位是高阶位(high-order bit),最后一位是低阶位。
15.5.1:有符号整数
如何表示有符号整数取决于硬件,而不是C语言。
15.6:C语言有两个位操作工具
C有两个操控位的工具。
- 作用于位的按位运算符。
- 字段(field)数据形式,用于访问int中的位。
十六:简单的算法思想
16.1:中间变量法(互换两个数字的值)
/*Date: 2023\10\7
Function: 互换两个数的值
*/
#include <stdio.h>
int main()
{
int i = 3;
int j = 5;
int temporary; //定义一个零时变量
temporary = i;
i = j;
j = temporary;
printf("i = %d, j = %d;", i, j);
return 0;
}
16.2:冒泡排序(三个任意数字进行排序)
假设对a,b,c三个数进行排序(正序排列,最大值赋给a,最小值赋给c),冒泡法的原理就是a先与b进行比较,若a大,a里面的值不需要变动,若a小,则需要将a,b里面的值进行互换(参考中间变量法),这样a里面就是大的值了,如此,a再与c进行比较,b再与c进行比较。这样三个数就都进行了遍历,此时a中存储的便是最大值,c中存储的便是最小值。

/*Date: 2023\10\7
Function: 对任意的三个数字进行排序(正序)
*/
#include <stdio.h>
int main()
{
int a, b, c;
int temporary;
printf("请任意输入三个数字(中间以空格分割):");
scanf_s("%d %d %d", &a, &b, &c);
if (a < b) //若a > b则a,b就不需要互换值,所以就不用考虑这种情况
{
temporary = a;
a = b;
b = temporary;
}
if (a < c)
{
temporary = a;
a = c;
c = temporary;
}
if (b < c)
{
temporary = b;
b = c;
c = temporary;
}
printf("正序排列结果为:%d, %d, %d;", a, b, c);
return 0;
}
/* Time: 2024/2/22
* Functions:冒泡算法
*/
#include <stdio.h>
#include <string.h>
void sort(int* a, int len);
int main()
{
int a[6] = {2, -2, 3, 0, 23, -34};
int i = 0;
sort(a, 6);
for (i = 0; i < 6; ++i)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
void sort(int *a, int len)
{
int i, j, t;
for (i = 0; i < len - 1; i++)
{
for (j = 0; j < len-1-i; j++)
{
if (a[j] > a[j+1]) //>表示升序,<表示降序
{
t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
}
}
}
}
16.3:判断一个数是否为回文数
/*Date: 2023\10\31
Function: 判断输入的参数是否为回文数
*/
#include <stdio.h>
int main(void)
{
int val; //存放待判断的数字
int m;
int sum = 0;
printf("请输入您需要判断的数字: ");
scanf_s("%d", &val);
m = val;
while (m)
{
sum = sum * 10 + (m % 10);
m /= 10;
}
if (sum == val)
{
printf("yes!\n");
}
else
{
printf("no!\n");
}
return 0;
}
16.4:菲波拉契序列
/*Date: 2023\10\31
Function: 菲波那契序列
*/
#include <stdio.h>
int main(void)
{
int i;
int n;
int f1, f2, f3;
f1 = 1; //初始化
f2 = 2;
printf("请输入你需要求的序列:");
scanf_s("%d", &n);
if (1 == n)
{
f3 = 1;
}
else if(2 == n)
{
f3 = 2;
}
else
{
for (i = 3; i <= n; i++)
{
f3 = f1 + f2;
f1 = f2;
f2 = f3;
}
}
printf("%d\n", f3);
return 0;
}
16.5:用户输入一个单词,然后程序倒序打印之
/*Date: 2023\11\16
Function: 用户输入一个单词,然后程序倒序打印这个单词。
*/
#include <stdio.h>
#include <string.h>
#define LEN 20
int main(void)
{
char str[LEN];
printf("plese enter a word: ");
scanf_s("%19s", str, sizeof(str)); //使用scanf_s函数读取字符串,必须提供一个缓冲区大小作为第二个参数,以
//避免缓冲区溢出的问题。
printf("%s\n", str);
printf("Revering the word is: \n");
for (int i = strlen(str) - 1; i >= 0; i--) //strlen()函数给出字符串中字符的长度
//(包括空格和标点符号,末尾的空字符不计算在内)。
{
printf("%c", str[i]);
}
return 0;
}
16.6:统计字符数、单词数、行数
/*Date: 2023\11\27
Function: 统计字符数、单词数、行数
*/
#include <stdio.h>
#include <ctype.h> //为isspace()函数提供原型
#include <stdbool.h> //为bool、true、false提供定义
#define STOP '|'
int main(void)
{
char c; //读入字符
char prev; //读入的前一个字符
long n_chars = 0L; //字符数
int n_lines = 0; //行数
int n_words = 0; //单词数
int p_lines = 0; //不完整的行数
bool inward = false; //如果C在单词中inward为true
printf("enter text to be analyzed(| to terminate):\n");
prev = '\n'; //用于识别一个完整的行
while ((c = getchar()) != STOP)
{
n_chars++; //统计字符
if (c == '\n')
{
n_lines++; //统计行
}
if (!isspace(c) && !inward) //如果C不是空格且inward为假
{ //!inward的值与表达式inward == false的值相等
inward = true; //开始一个新的单词
n_words++; //统计单词
}
if (isspace(c) && inward)
{
inward = false;
}
}
prev = c; //保存字符的值
if (prev != '\n')
{
p_lines = 1;
}
printf("characters = %ld, words = %d, lines = %d, ", n_chars, n_words, n_lines);
printf("partial lines = %d\n", p_lines);
return 0;
}
16.7:判断一个数是否是素数
/*Date: 2023\12\8
Function: 判断一个数是否是素数
*/
#include <stdio.h>
bool Is_Prime(int val); //函数声明
int main(void)
{
int number;
printf("请输入一个数,程序会判断其是否为素数!\n");
scanf_s("%d", &number);
if (Is_Prime(number))
{
printf("是素数!");
}
else
{
printf("不是素数!");
}
return 0;
}
bool Is_Prime(int val) //函数的功能要尽量单一
{
int i;
for (i = 2; i < val; i++) //一个除了1和其本身之外不存在其它因数的数叫素数
{
if ((val % i) == 0)
{
break; //如果val能被i整除,说明不是素数
}
}
if (i == val)
{
return true;
}
else
{
return false;
}
}














 3513
3513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









