






1. 本文讲讲Hadoop的mapreduce之分区Partitioner
1.1默认情况下MR输出文件个数
在默认情况下,不管map阶段有多少个并发执行task,到reduce阶段,所有的结果都将有一个reduce来处理,并且最终结果输出到一个文件中。
1.2 修改reducetask个数
在MapReduce程序的驱动类中,通过job提供的方法,可以修改reducetask的个数。
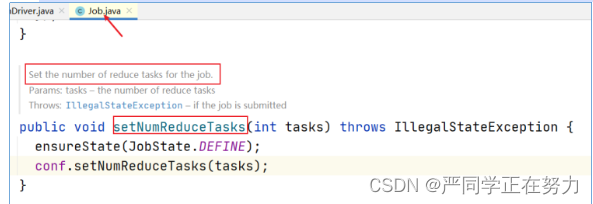
就可以得到六个分区
1.3 数据量
这个是等会用到的数据量可以下载供参考
链接:https://pan.baidu.com/s/1wByTj5jzKuQmQ9HpBWq00Q
提取码:rdcv
2. 程序代码
2.1 StatePartitioner程序
package com.niit.covid.MeiTuanstater;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
/**
* @author:严同学
* @date: 2022年08月12日 14:55
* @desc:
*/
public class StatePartitioner extends Partitioner<Text,Text> {
//模拟美国各州的数据字典,实际中可以从redis进行读取加载,如果数据量不大,也可以创建数据集合保存
public static HashMap<String,Integer> stateMap= new HashMap<String, Integer>();
static {
stateMap.put("广西壮族自治区",0);
stateMap.put("广东省",1);
stateMap.put("云南省",2);
stateMap.put("湖南省",3);
stateMap.put("贵州省",4);
}
/**
* todo 自定义分区器中分区规则的实现方法 只要getPartition返回的int一样,数据就会被分到同一个分区
* 所谓同一个分区指的是数据到同一个reducetask处理
* k:state省份 -------字符串===Text
* v:这一行内容 -------字符串整体,无需封装==Text
*/
@Override
public int getPartition(Text key, Text value, int i) {
Integer code = stateMap.get(key.toString()); //
if(code !=null ){
return code;
}else{
return 5;// 其他省份 放到 第六个分区文件
}
}
}
2.2 mapper程序
package com.niit.covid.MeiTuanstater;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author:严同学
* @date: 2022年08月12日 15:07
* @desc:
*/
public class StatePartitionMapper extends Mapper<LongWritable, Text,Text,Text> {
Text outKey = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、切割,为了拿到州
String[] lines = value.toString().split(",");
//2、以省份作为key,参与分区,通过自定义分区,同一个省份的数据到同一个分区同一个reducetask处理
String state = lines[0];
//3、赋值
outKey.set(state);
//4、写出去
context.write(outKey,value);
}
}
2.3 reduce程序
package com.niit.covid.MeiTuanstater;
/**
* @author:严同学
* @date: 2022年08月12日 15:10
* @desc:
*/
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 因为state在那一行数据里,再输出那行数据没有意义,可以使用nullWritable
*/
public class StatePartitionReducer extends Reducer<Text, Text,Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values){
context.write(value,NullWritable.get());
}
}
}
2.4 Driver程序
package com.niit.covid.MeiTuanstater;
import com.niit.covid.statePartition.StatePartitionMapper;
import com.niit.covid.statePartition.StatePartitionReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author:严同学
* @date: 2022年08月12日 15:14
* @desc:
*/
public class StatePartitionDriver {
public static void main(String[] args) throws Exception {
//创建驱动类
Configuration conf = new Configuration();
//构造job作业的实例,参数(配置对象,job名字)
Job job = Job.getInstance(conf, StatePartitionDriver.class.getSimpleName());
//设置mr程序运行的主类
job.setJarByClass(StatePartitionDriver.class);
//设置本次mr程序的mapper类型、reducer类型
job.setMapperClass(StatePartitionMapper.class);
job.setReducerClass(StatePartitionReducer.class);
//指定mapper阶段输出的key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定reducer阶段输出的key value数据类型,也是mr程序最终的输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//todo 设置程序Partition类; 注意:分区组件能够生效的前提是MapReduce程序中的reduceTask的个数 >=2
/**
* 探究: reducetask个数和分区个数之间的关系
* 正常情况下: reducetask个数 == 分区个数
* 特殊情况下: reducetask个数 > 分区个数 ====> 程序可以运行,但多有空文件产生,浪费性能
* reducetask个数 < 分区个数 ====> 程序直接报错:非法分区
*/
job.setPartitionerClass(StatePartitioner.class);
job.setNumReduceTasks(6);// 5 是已经在StatePartitioner已经分好的区 1:其他州的数据 5 + 1 = 6
//配置本次作业的输入数据路径和输出数据路径
Path inputPath = new Path("input/covid/meituan");
Path outputPath = new Path("output/covid/meituanpartitoner");
//todo 默认组件 TextInputFormat TextOutputFormat
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
//todo 判断输出路径是否已经存在,如果已经存在,先删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outputPath)){
fs.delete(outputPath,true); //递归删除
}
//最终提交本次job作业
//job.submit();
//采用waitForCompletion提交job,参数表示是否开启实时监视追踪作业的执行情况
boolean resultFlag = job.waitForCompletion(true);
//退出程序 和job结果进行绑定, 0是正常退出,1是异常退出
System.exit(resultFlag ? 0: 1);
}
}
mapreduce运行结果
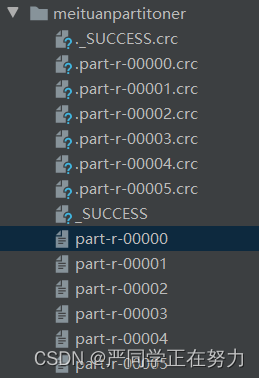
运行完成即可得出六个分区结果,程序将相同的省份分在一起,其他省份放在第六分区


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











