







##KMP 算法
基本思想
-
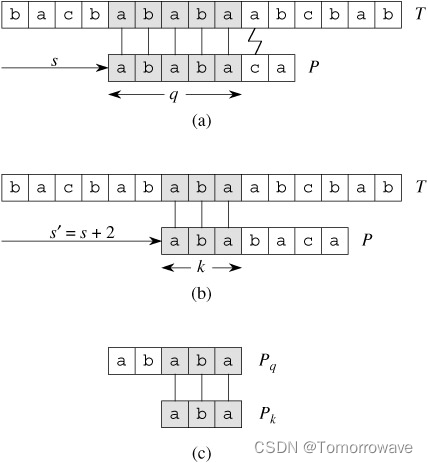
我们来观察一下朴素的字符串匹配算法的操作过程。如下图(a)中所描述,在模式 P = ababaca 和文本 T 的匹配过程中,模板的一个特定位移 s,q = 5 个字符已经匹配成功,但模式 P 的第 6 个字符不能与相应的文本字符匹配。
-
此时,q 个字符已经匹配成功的信息确定了相应的文本字符,而知道这 q 个文本字符,就使我们能够立即确定某些位移是非法的。例如上图(a)中,我们可以判断位移 s+1 是非法的,因为模式 P 的第一个字符 a 将与模式的第二个字符 b 匹配的文本字符进行匹配,显然是不匹配的。而图(b)中则显示了位移 s’ = s+2 处,使模式 P 的前三个字符和相应的三个文本字符对齐后必定会匹配。KMP 算法的基本思路就是设法利用这些已知信息,不要把 “搜索位置” 移回已经比较过的位置,而是继续把它向后面移,这样就提高了匹配效率。
算法原理
-
已知模式 P[1…q] 与文本 T[s+1…s+q] 匹配,那么满足 P[1…k] = T[s’+1…s’+k] 其中 s’+k = s+q 的最小位移 s’ > s 是多少?这样的位移 s’ 是大于 s 的但未必非法的第一个位移,因为已知 T[s+1…s+q] 。在最好的情况下有 s’ = s+q,因此立刻能排除掉位移 s+1, s+2 … s+q-1。在任何情况下,对于新的位移 s’,无需把 P 的前 k 个字符与 T 中相应的字符进行比较,因为它们肯定匹配。
-
可以用模式 P 与其自身进行比较,以预先计算出这些必要的信息。例如上图(c)中所示,由于 T[s’+1…s’+k] 是文本中已经知道的部分,所以它是字符串 Pq 的一个后缀。
-
此处我们引入模式的前缀函数 π(Pai),π 包含有模式与其自身的位移进行匹配的信息。这些信息可用于避免在朴素的字符串匹配算法中,对无用位移进行测试。
π [ q ] = m a x k : k < q a n d P k ⊐ P q π[q] = max {k : k < q and Pk ⊐ Pq} π[q]=maxk:k<qandPk⊐Pq -
π[q] 代表当前字符之前的字符串中,最长的共同前缀后缀的长度。(π[q] is the length of the longest prefix of P that is a proper suffix of Pq.)
下图给出了关于模式 P = ababababca 的完整前缀函数 π,可称为部分匹配表(Partial Match Table)。
计算过程:
- π[1] = 0,a 仅一个字符,前缀和后缀为空集,共有元素最大长度为 0;
- π[2] = 0,ab 的前缀 a,后缀 b,不匹配,共有元素最大长度为 0;
- π[3] = 1,aba,前缀 a ab,后缀 ba a,共有元素最大长度为 1;
- π[4] = 2,abab,前缀 a ab aba,后缀 bab ab b,共有元素最大长度为 2;
- π[5] = 3,ababa,前缀 a ab aba abab,后缀 baba aba ba a,共有元素最大长度为 3;
- π[6] = 4,ababab,前缀 a ab aba abab ababa,后缀 babab abab bab ab b,共有元素最大长度为 4;
- π[7] = 5,abababa,前缀 a ab aba abab ababa ababab,后缀 bababa ababa baba aba ba a,共有元素最大长度为 5;
- π[8] = 6,abababab,前缀 … ababab …,后缀 … ababab …,共有元素最大长度为 6;
- π[9] = 0,ababababc,前缀和后缀不匹配,共有元素最大长度为 0;
- π[10] = 1,ababababca,前缀 … a …,后缀 … a …,共有元素最大长度为 1;
算法原理
- KMP 算法 KMP-MATCHER 中通过调用 COMPUTE-PREFIX-FUNCTION 函数来计算部分匹配表。
1 KMP-MATCHER(T, P)
2 n ← length[T]
3 m ← length[P]
4 π ← COMPUTE-PREFIX-FUNCTION(P)
5 q ← 0 //Number of characters matched.
6 for i ← 1 to n //Scan the text from left to right.
7 do while q > 0 and P[q + 1] ≠ T[i]
8 do q ← π[q] //Next character does not match.
9 if P[q + 1] = T[i]
10 then q ← q + 1 //Next character matches.
11 if q = m //Is all of P matched?
12 then print "Pattern occurs with shift" i - m
13 q ← π[q] //Look for the next match.
1 COMPUTE-PREFIX-FUNCTION(P)
2 m ← length[P]
3 π[1] ← 0
4 k ← 0
5 for q ← 2 to m
6 do while k > 0 and P[k + 1] ≠ P[q]
7 do k ← π[k]
8 if P[k + 1] = P[q]
9 then k ← k + 1
10 π[q] ← k
11 return π

















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











