







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
-
HTML
-
JSON
HTML是用来描述网页的一种语言
JSON是一种轻量级的数据交换格式
爬取网页信息其实就是向网页提出请求,服务器就会将数据反馈给你
导入需要的用的模块和库:
from bs4 import BeautifulSoup
import time
import def_text_save as dts
import def_get_data as dgd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
获取网页信息需要发送请求,requests 能帮我们很好的完成这件事,但是仔细观察发现网易新闻是动态加载,requests 返回的是即时信息,网页部分稍后加载出来的数据没有返回,这种情况 selenium 能够帮助我们得到更多的数据,我们将 selenium 理解为一个自动化测试工具就好,Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
我使用的浏览器为Firefox
browser = webdriver.Firefox()#根据浏览器切换
browser.maximize_window()#最大化窗口
browser.get(‘http://news.163.com/domestic/’)
这样我们就能驱动浏览器自动登陆网易新闻页面
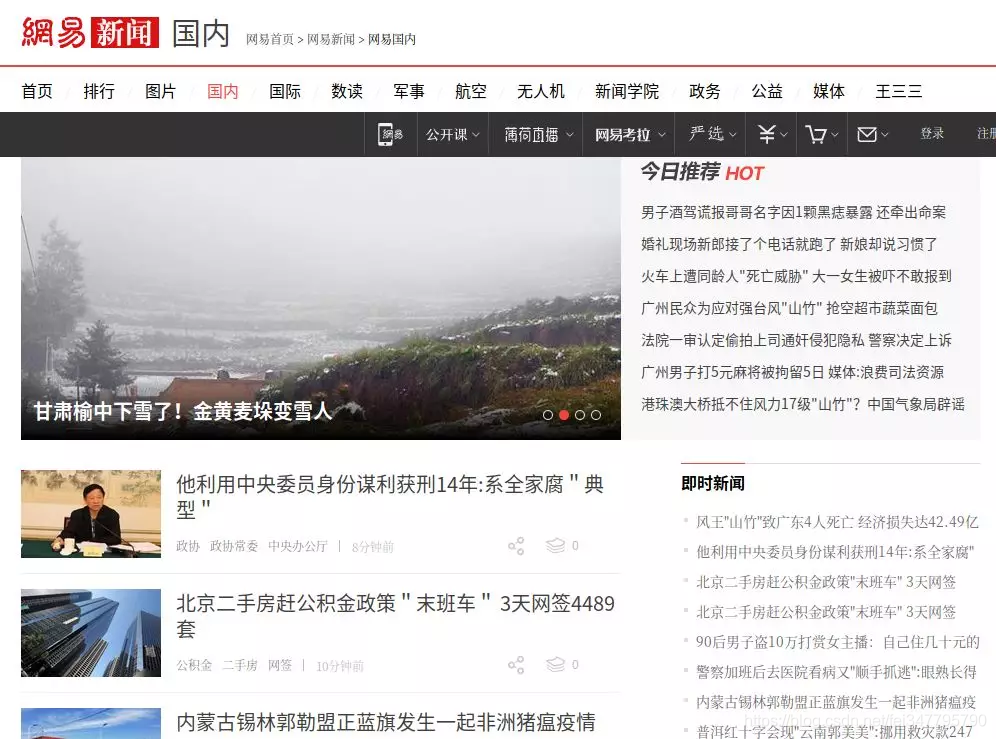
我们的目标自然是一次将国内板块爬取下来,观察网页,在网页不断向下刷时,新的新闻才会加载出来,到最下面甚至还有需要点击按钮才能刷新:
这时使用 selenium 就能展现其优势:自动化,模拟鼠标键盘操作:
diver.execute_script(“window.scrollBy(0,5000)”)
#使网页向下拉,括号内为每次下拉数值
在网页中右键点击加载更多按钮,点击查看元素,可以看到

通过这个 class 就可以定位到按钮,碰到按钮时,click 事件就能帮助我们自动点击按钮完成网页刷新
爬取板块动态加载部分源代码
info1=[]
info_links=[] #存储文章内容链接
try:
while True :
if browser.page_source.find(“load_more_btn”) != -1 :
browser.find_element_by_class_name(“load_more_btn”).click()
browser.execute_script(“window.scrollBy(0,5000)”)
time.sleep(1)
except:
url = browser.page_source#返回加载完全的网页源码
browser.close()#关闭浏览器
- 获取有用信息
简单来说,BeautifulSoup 是 python 的一个库,最主要的功能是从网页抓取数据,能减轻菜鸟的负担。
通过 BeautifulSoup 解析网页源码,在加上附带的函数,我们能轻松取出想要的信息,例如:获取文章标题,标签以及文本内容超链接

同样在文章标题区域右键点击查看元素:
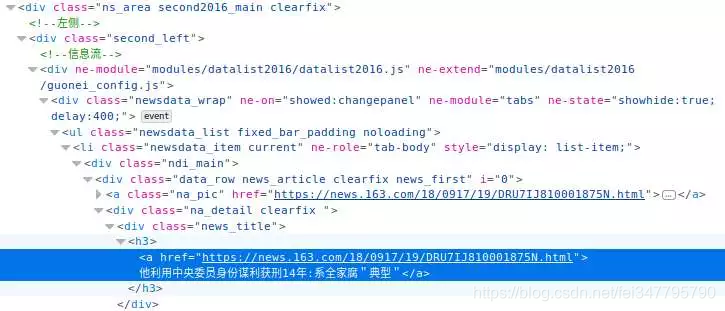
观察网页结构发现每一个div标签class=“news_title" 下都是文章的标题和超链接。soup.find_all()函数能帮我们找到我们想要的全部信息,这一级结构下的内容就能一次摘取出来。最后通过字典,把标签信息,挨个个取出来。
info_total=[]
def get_data(url):
soup=BeautifulSoup(url,“html.parser”)
titles=soup.find_all(‘div’,‘news_title’)
labels=soup.find(‘div’,‘ns_area second2016_main clearfix’).find_all(‘div’,‘keywords’)
for title, label in zip(titles,labels ):
data = {
‘文章标题’: title.get_text().split(),
‘文章标签’:label.get_text().split() ,
‘link’:title.find(“a”).get(‘href’)
}
info_total.append(data)
return info_total
4. 获取新闻内容
自此,新闻链接已经被我们取出来存到列表里了,现在需要做的就是利用链接得到新闻主题内容。新闻主题内容页面为静态加载方式,requests 能轻松处理:
def get_content(url):
info_text = []
info=[]
adata=requests.get(url)
soup=BeautifulSoup(adata.text,‘html.parser’)
try :
articles = soup.find(“div”, ‘post_header’).find(‘div’, ‘post_content_main’).find(‘div’, ‘post_text’).find_all(‘p’)
except :
articles = soup.find(“div”, ‘post_content post_area clearfix’).find(‘div’, ‘post_body’).find(‘div’, ‘post_text’).find_all(
‘p’)
for a in articles:
a=a.get_text()
a= ’ '.join(a.split())
info_text.append(a)
return (info_text)
使用 try except的原因在于,网易新闻文章在某个时间段前后,文本信息所处位置标签不一样,对不同的情况应作出不同的处理。
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
44da8af500c049bb72fbd.png#pic_center)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-yyO7oKCF-1713550410475)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1576
1576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









