







1.pandas数据处理
1.查看前五行
data.head() 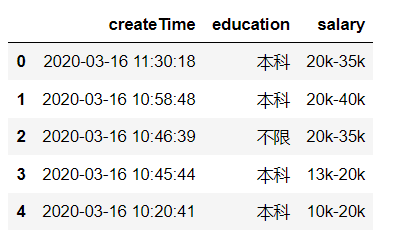
2.将salary列数据转换为最大值与最小值的平均值
# 定义函数
def func(df):
list=df["salary"].split("-")
min=int(list[0].strip("k"))
max=int(list[1].strip("k"))
df["salary"]=int((min+max)/2*1000)
return df
df=df.apply(func,axis=1)3.数据根据学历进行分组并计算平均薪资
df.groupby("education").mean()4.将createTime列时间转换为月-日
for i in range(len(df)):
df.iloc[i,0] = df.iloc[i,0].to_pydatetime().strftime("%m-%d") 5.查看数值型列的汇总统计
df.descirbe()6..新增一列根据salary将数据分为三组
df["catagories"]=pd.cut(df["salary"],
bins=[0,5000,20000,50000],
labels=["低","中","高"])7.按照salary列对数据降序排列
df.sort_values("salary",ascending=False)8.绘制薪资水平密度曲线
df.salary.plot(kind='kde',xlim=(0,80000)) # 指横坐标的范围 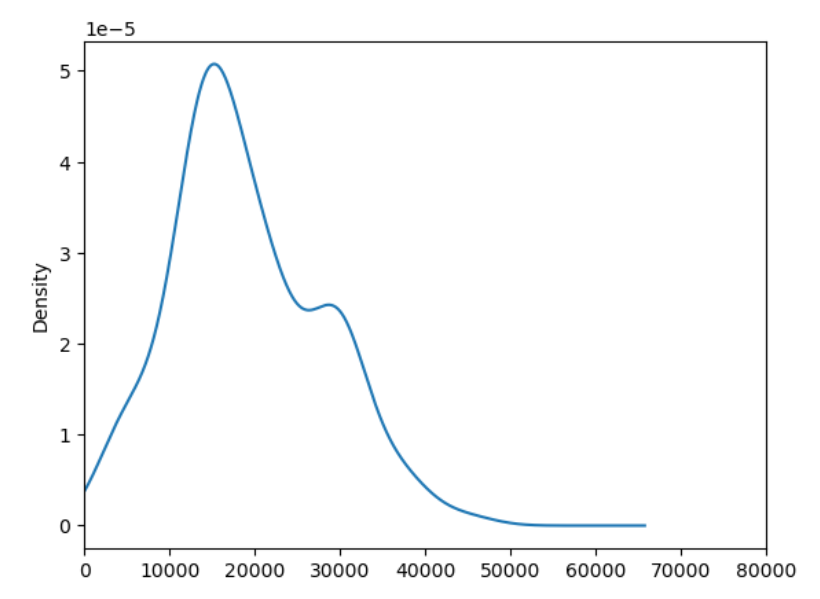
9.删除最后一列categories
del df["categories"] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









