







活动地址:CSDN21天学习挑战赛
作者简介:大家好我是狂暴于涛侠本侠
🦸个人主页:狂暴于涛侠
目录
🪐MySQL的优化
概念:
在应用的的开发过程中,由于初期数据量小,开发人员写 SQL 语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多 SQL 语句开始逐渐显露出性能问题,对生产的影响也越来越大,此时这些有问题的 SQL 语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化.
MySQL的优化方式有很多,大致我们可以从以下几点来优化MySQL:
- 从设计上优化
- 从查询上优化
- 从索引上优化
- 从存储上优化
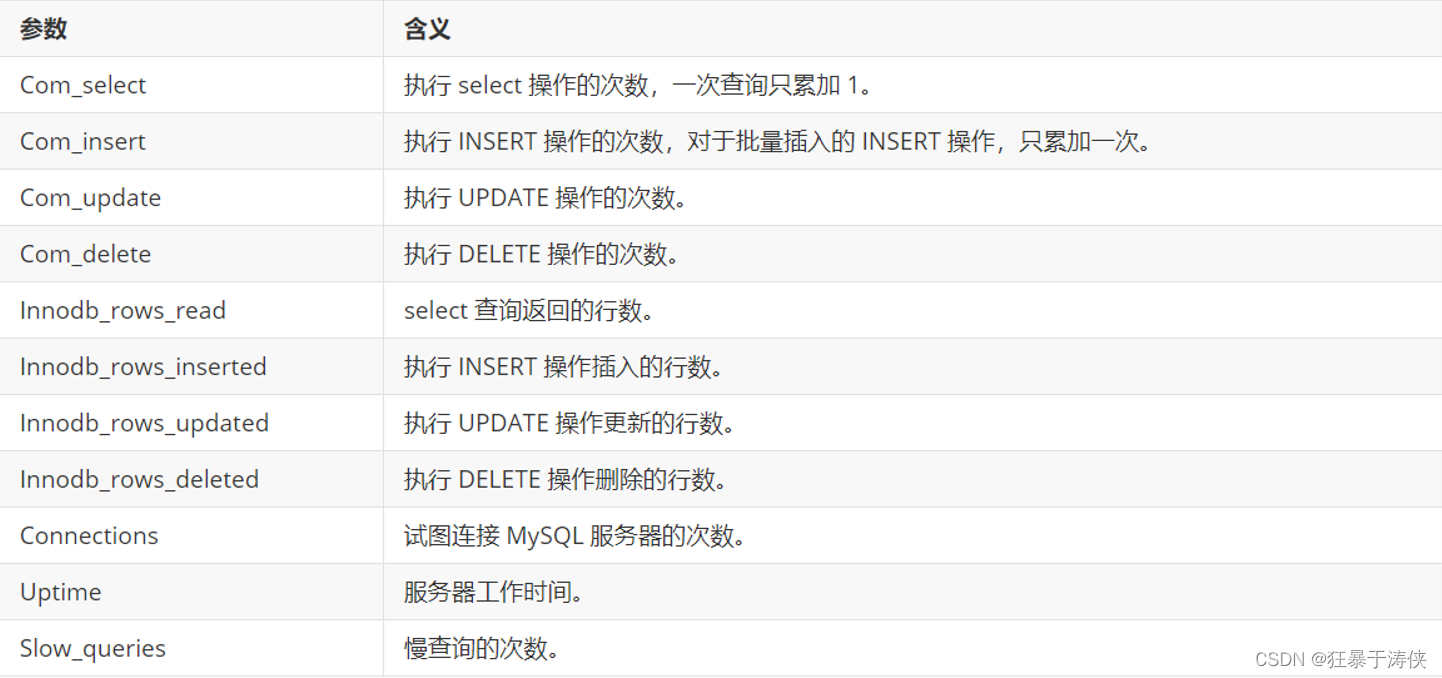
🌠 查看SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以查看服务器状态信息。通过查看状态信息可以查看对当前数据库的主要操作类型。
操作:
-- 下面的命令显示了当前 session 中所有统计参数的值
-- 查看当前会话统计结果
show session status like 'Com_______';
-- 查看自数据库上次启动至今统计结果
show global status like 'Com_______';
-- 查看针对Innodb引擎的统计结果
show status like 'Innodb_rows_%';
🌠定位低效率执行SQL
可以通过以下两种方式定位执行效率较低的 SQL 语句:
慢查询日志 : 通过慢查询日志定位那些执行效率较低的 SQL 语句。
show processlist:该命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。
🌠定位低效率执行SQL-慢查询日志
操作:
-- 查看慢日志配置信息
show variables like '%slow_query_log%';
-- 开启慢日志查询
set global slow_query_log=1;
-- 查看慢日志记录SQL的最低阈值时间,默认如果SQL的执行时间>=10秒,则算慢查询,则会将该操作记录到慢日志中去
show variables like 'long_query_time%';
select sleep(12);-- 休息12秒,会被记录到慢日志中去
-- 修改慢日志记录SQL的最低阈值时间
set global long_query_time=4;
-- 如果SQL的执行时间>=4秒则算慢查询,则会将该操作记录到慢日志中去
🌠定位低效率执行SQL-show processlist
show processlist;

1) id列,用户登录mysql时,系统分配的"connection_id",可以使用函数connection_id()查看
2) user列,显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句
3) host列,显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户
4) db列,显示这个进程目前连接的是哪个数据库
5) command列,显示当前连接的执行的命令,一般取值为休眠(sleep),查询(query),连接(connect)等
6) time列,显示这个状态持续的时间,单位是秒
7) state列,显示使用当前连接的sql语句的状态,很重要的列。state描述的是语句执行中的某一个状态。一个sql语句,以查询为例,可能需要经过copying to tmp table、sorting result、sending data等状态才可以完成
8) info列,显示这个sql语句,是判断问题语句的一个重要依据
🌠explain分析执行计划
操作:
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN命令获取 MySQL如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
explain select * from user where uid = 1;
explain select * from user where uname = '张飞';
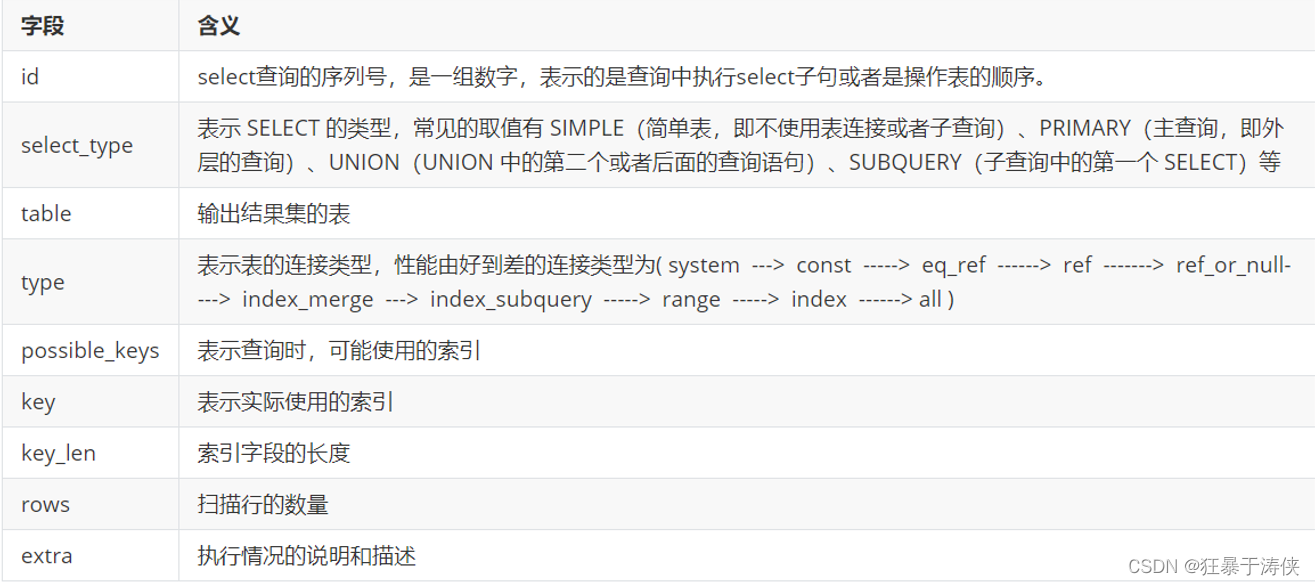
🌠Explain分析执行计划-Explain 之 id
id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id 情况有三种:
1、id 相同表示加载表的顺序是从上到下。
explain select * from user u, user_role ur, role r where u.uid = ur.uid and ur.rid = r.rid ;

2、 id 不同,id值越大优先级越高,越先被执行。
explain select * from role where rid = (select rid from user_role where uid = (select uid from user where uname = '张飞'))

3) id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大优先级越高,越先执行。
explain select * from role r , (select * from user_role ur where ur.uid = (select uid from user where uname = '张飞')) t where r.rid = t.rid ;

🌠Explain分析执行计划-Explain 之 select_type
表示 SELECT 的类型,常见的取值,如下表所示:

操作:
-- Explain的select_type;
-- SIMPLE:没有子查询和union
explain select * from user;
explain select * from user u,user_role ur where u.uid = ur.uid;
-- PRIMARY :主查询,也就是子查询中的最外层查询
explain select *from role where rid = (select rid from user_role where uid = (select uid from user where uname = '张飞'));
-- SUBQUERY:在Select和WHERE中包含子查询
explain select * from role where rid = (select rid from user_role where uid = (select uid from user where uname = '张飞'));
-- DERIVED:在from中包含子查询,被标记为衍生表
explain select * from (select * from user limit 2)t;
-- UNION
-- UNION RESULT
explain select * from user where uid = 1 union select * from user where uid = 3;
🌠Explain分析执行计划-Explain 之type
type 显示的是访问类型,是较为重要的一个指标,可取值为:
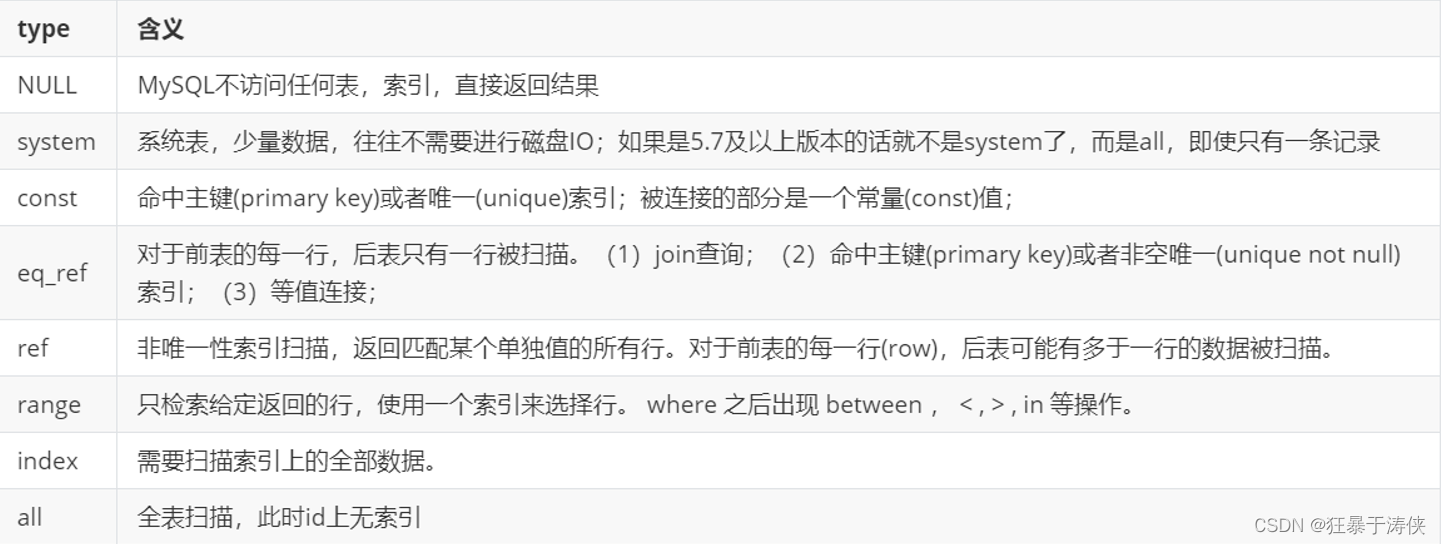
-- Explain分析执行计划-Explain 之 type
-- NULL不访问任何表,任何索引,直接返回结果
explain select now();
explain select rand();
-- system查询系统表,表示直接从内存读取数据,不会从磁盘读取,但是5.7及以上版本不再显示system ,直接显示ALL
explain select * from mysql.tables_priv;
-- const
-- 只有唯一索引才会是const(主键是特殊的唯一索引)
explain select *from user where uid = 2;-- 这里面uid是主键是const
explain select * from user where uname ='张飞';-- ALL
create unique index index_uname on user(uname);-- 添加唯一索引
explain select * from user where uname ='张飞';-- const
drop index index_uname on user;-- 删除上一个唯一索引
create index index_uname on user(uname); -- 添加普通索引
explain select * from user where uname ='张飞';-- ref
-- eq_ref 左表有主键,而且左表的每一行和右表的每一行刚好匹配
create table user2(
id int,
name varchar(20)
);
insert into user2 values(1,'张三'),(2,'李四'),(3,'王五');
create table user2_ex(
id int,
age int
);
insert into user2_ex values(1,20),(2,21),(3,22);
-- 测试
explain select * from user2 a, user2_ex b where a.id = b.id;-- ALL
-- 给user2表添加主键索引
alter table user2 add primary key(id);
explain select * from user2 a, user2_ex b where a.id = b.id; -- ALL,eq_ref--在user_ex表添加一个重复的行数据
-- 现在再次添加一个数据让两个表不在1对1对应
insert into user2_ex values(1,40);
explain select * from user2 a, user2_ex b where a.id = b.id; -- ALL
-- ref左表有普通索引,和右表配置时可能会匹配多行
-- 删除user2表的主键索引
alter table user2 drop primary key;
-- 给user2表添加普通索引
create index index_id on user2(id); -- 添加普通索引
explain select * from user2 a, user2_ex b where a.id = b.id; -- ALL,ref
-- range:范围查询
explain select * from user2 where id >2;
-- index :把索引列的全部数据都扫描
explain select id from user2; -- index
explain select * from user2;-- ALL
结果值从最好到最坏以此是:system > const > eq_ref > ref > range > index > ALL
🌠Explain分析执行计划-其他指标字段
Explain 之 table
显示这一步所访问数据库中表名称有时不是真实的表名字,可能是简称,
explain 之 rows
扫描行的数量。
Explain 之 key
possible_keys : 显示可能应用在这张表的索引, 一个或多个。
key : 实际使用的索引, 如果为NULL, 则没有使用索引。
key_len : 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。
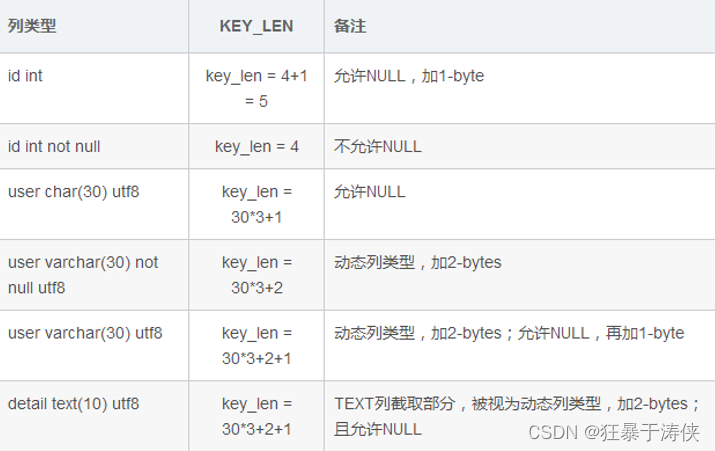
Explain之 extra
其他的额外的执行计划信息,在该列展示 。

🌠show profile分析SQL
Mysql从5.0.37版本开始增加了对 show profiles 和 show profile 语句的支持。show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。。
通过 have_profiling 参数,能够看到当前MySQL是否支持profile:
-- MySQL是否支持profile
select @@have_profiling;
set profiling=1; -- 开启profiling 开关;
执行show profiles 指令, 来查看SQL语句执行的耗时:
show profiles;
通过show profile for query query_id 语句可以查看到该SQL执行过程中每个线程的状态和消耗的时间:
show profile for query 8;
在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、block io 、context switch、page faults等明细类型类查看MySQL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间 :
show profile cpu for query 133;
在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、block io 、context switch、page faults等明细类型类查看MySQL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间 :

🌠trace分析优化器执行计划
MySQL5.6提供了对SQL的跟踪trace, 通过trace文件能够进一步了解为什么优化器选择A计划, 而不是选择B计划
打开trace , 设置格式为 JSON,并设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整展示。
操作:
SET optimizer_trace="enabled=on",end_markers_in_json=on;
set optimizer_trace_max_mem_size=1000000;
执行SQL语句 :
select * from user where uid < 2;
最后, 检查information_schema.optimizer_trace就可以知道MySQL是如何执行SQL的 :
select * from information_schema.optimizer_trace\G;
🌠使用索引优化
索引是数据库优化最常用也是最重要的手段之一, 通过索引通常可以帮助用户解决大多数的MySQL的性能优化问题。
数据准备:
create table `tb_seller` (
`sellerid` varchar (100),
`name` varchar (100),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











