






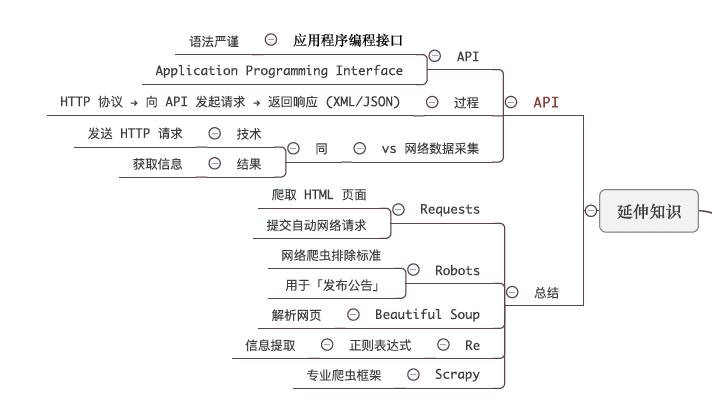
Python是编写爬虫的不二语言:
除了Python语言本身的诸多优点之外,更重要的是爬虫具备脚本语言特征,特别适合将数据清洗,存储到数据库中。
Python在爬虫方面形成了深度的社区文化。破解各种反爬虫机制,解析各种数据的具体方法,数据清洗和数据库管理的各种方案都已经成熟。这是其他语言所无法追上的。
而且Python拥有request和Scrapy两个成熟的爬虫框架。
requests:库应该是现在做爬虫最火最实用的库了,非常的人性化。Request灵活自由,适合应对各种反爬机制。
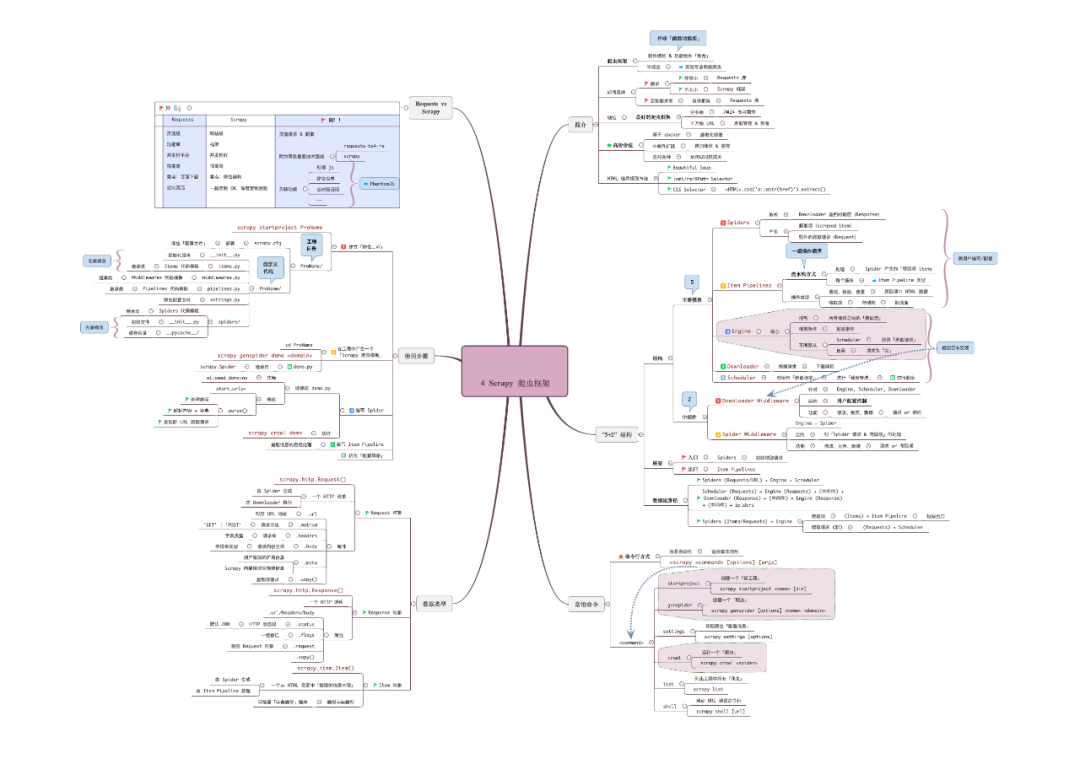
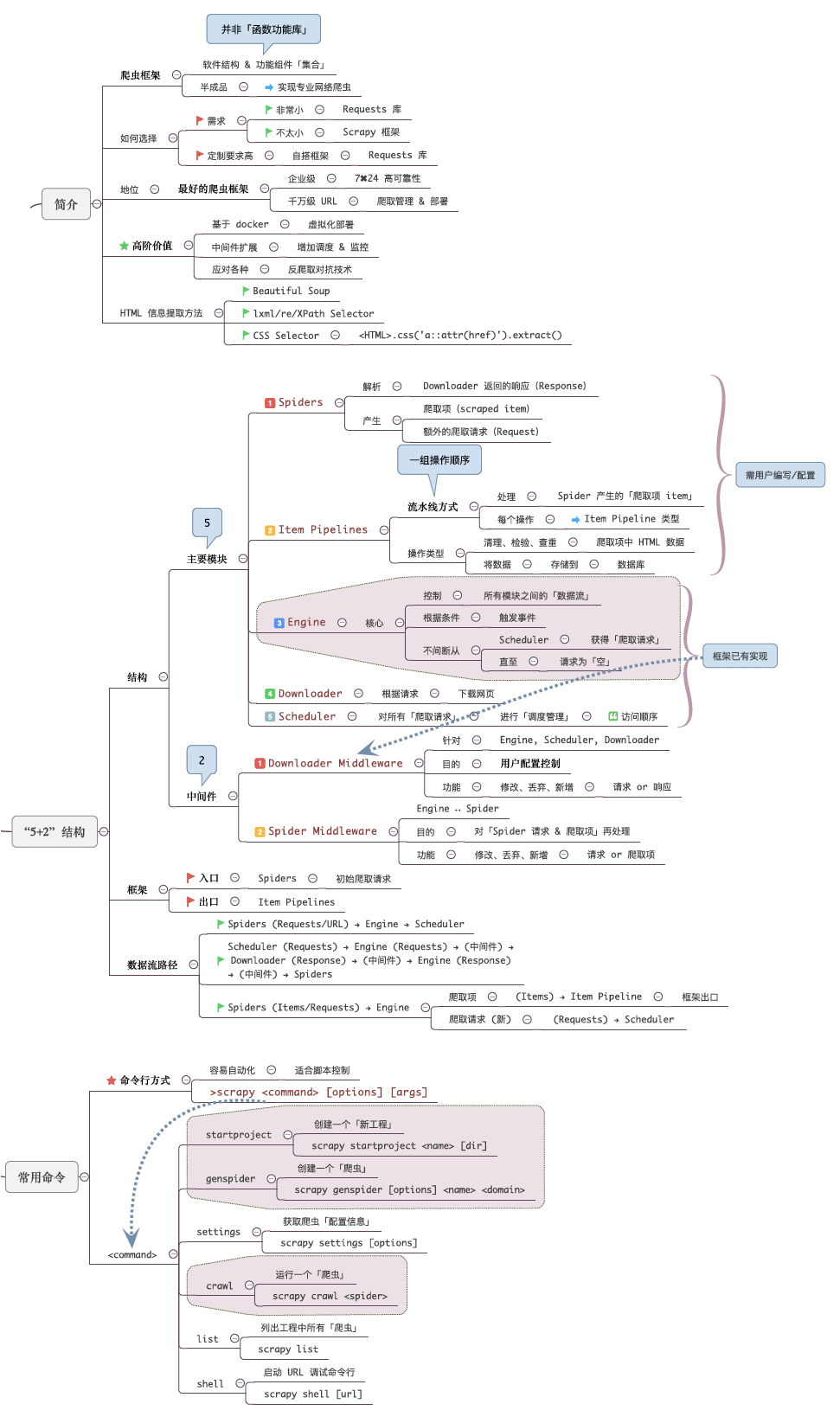
Scrapy :很强大的爬虫框架,Scrapy成熟稳定,对海量爬取任务有奇效。
学习爬虫,还要掌握的一些第三方库。
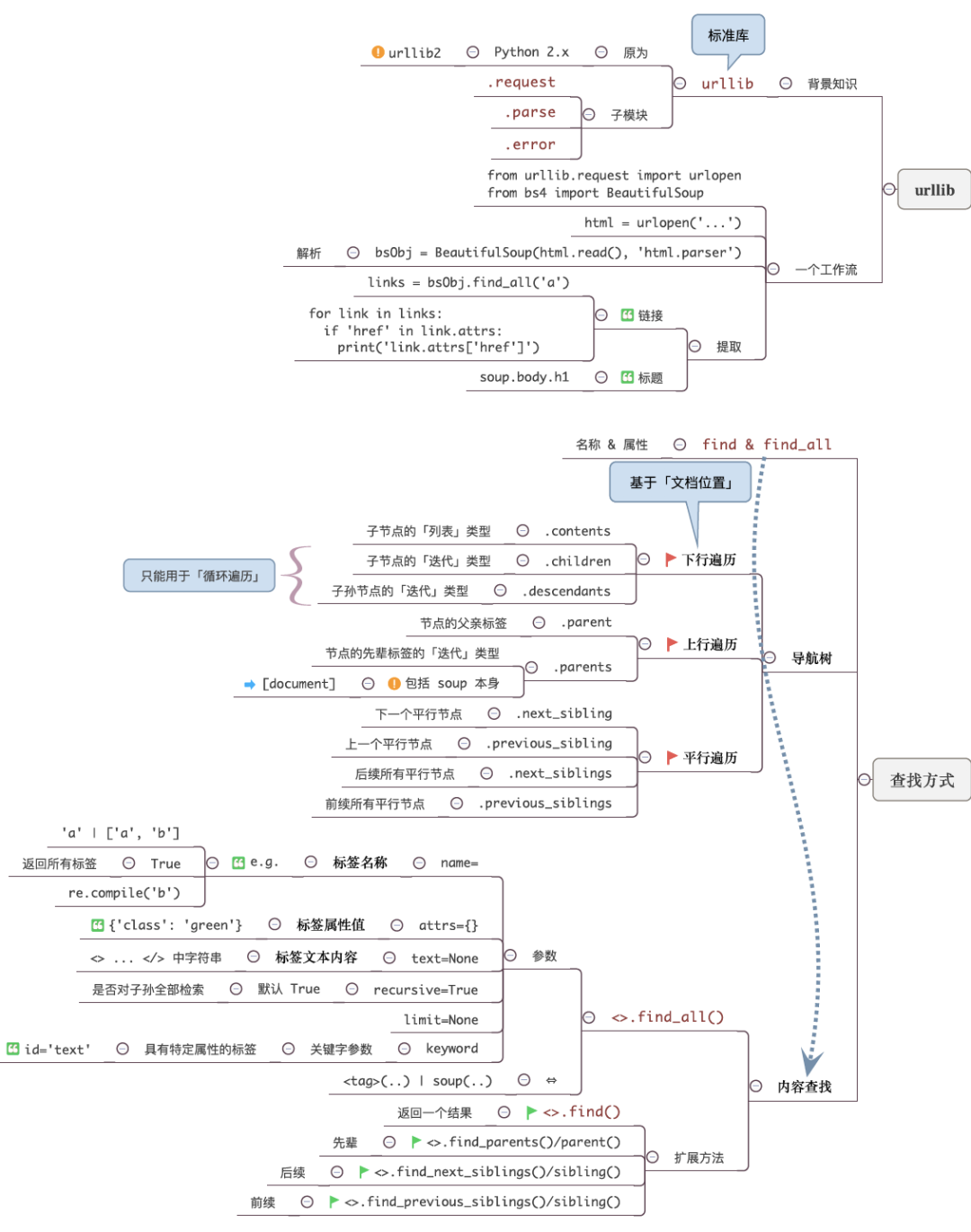
urllib3:是一个非常强大的http请求库,提供一系列的操作URL的功能。
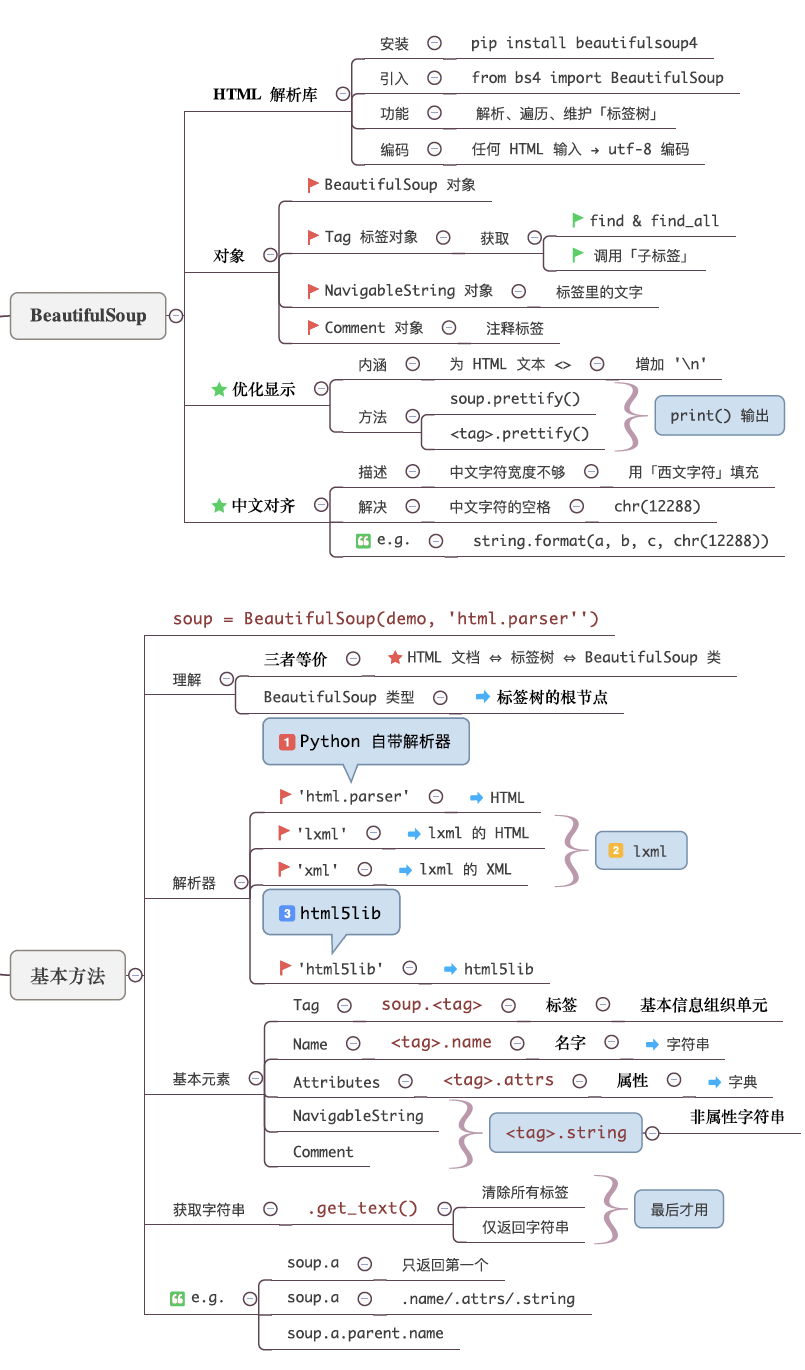
beautifulsoup:对于html的解析是非常的好用。对于写爬虫的人来说这也是必须掌握的库。
02
QIKUXUEYUAN
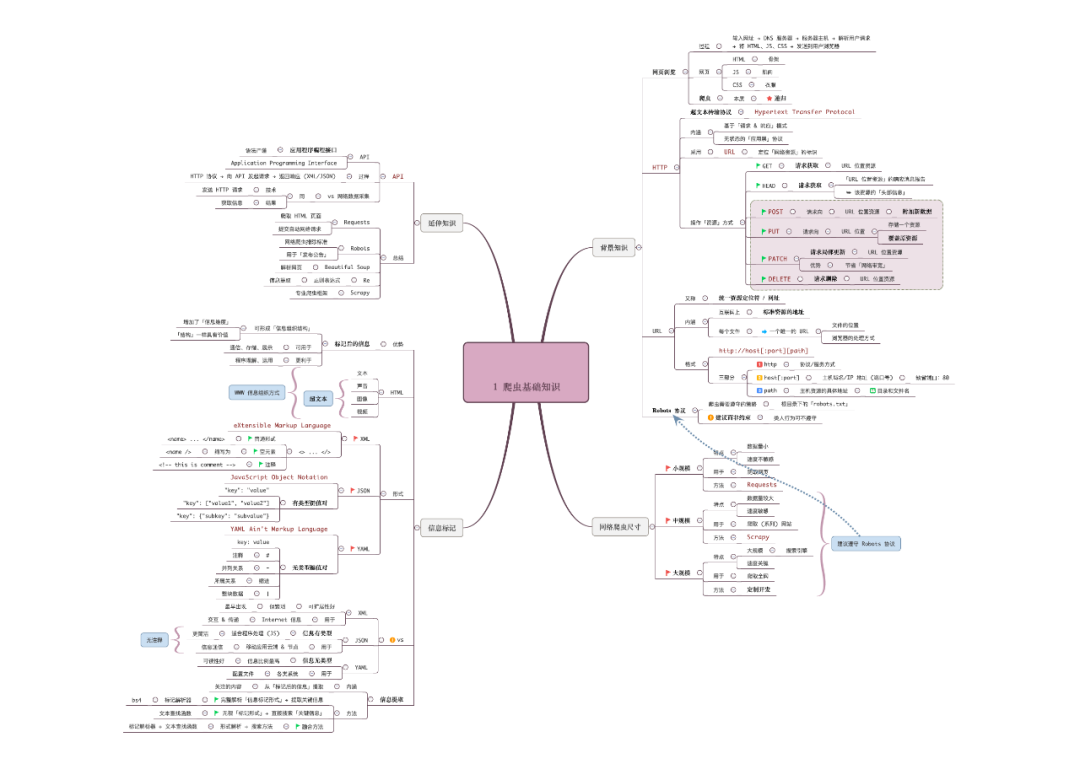
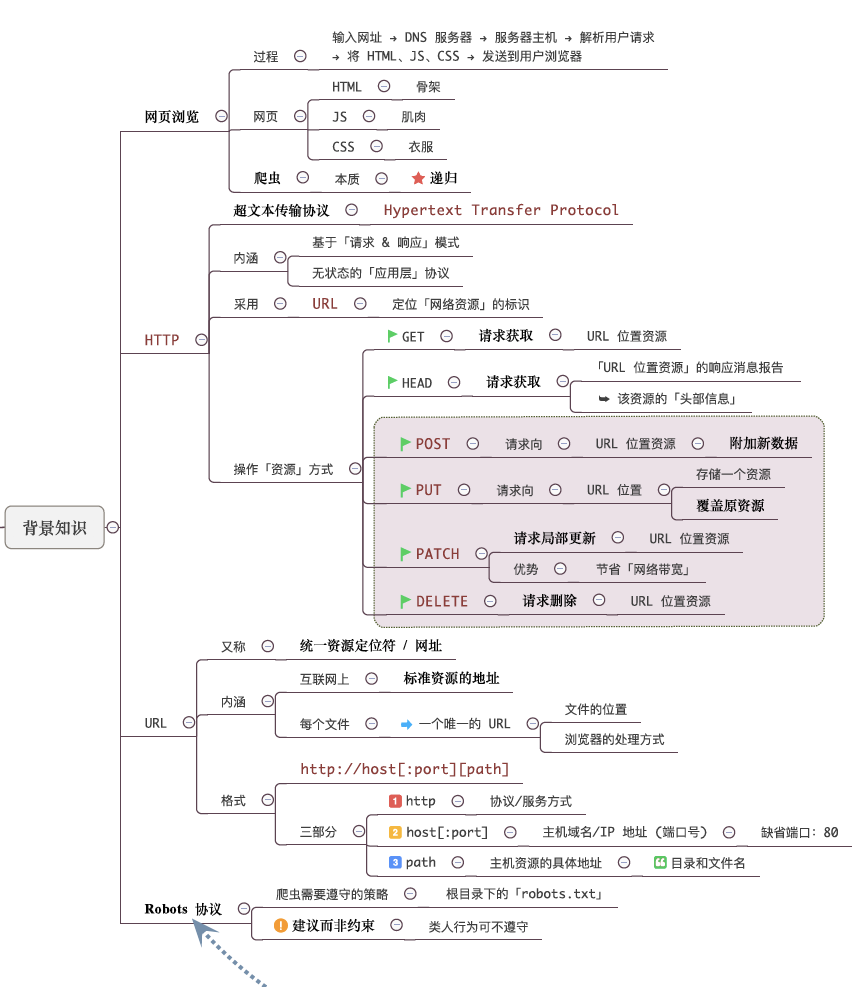
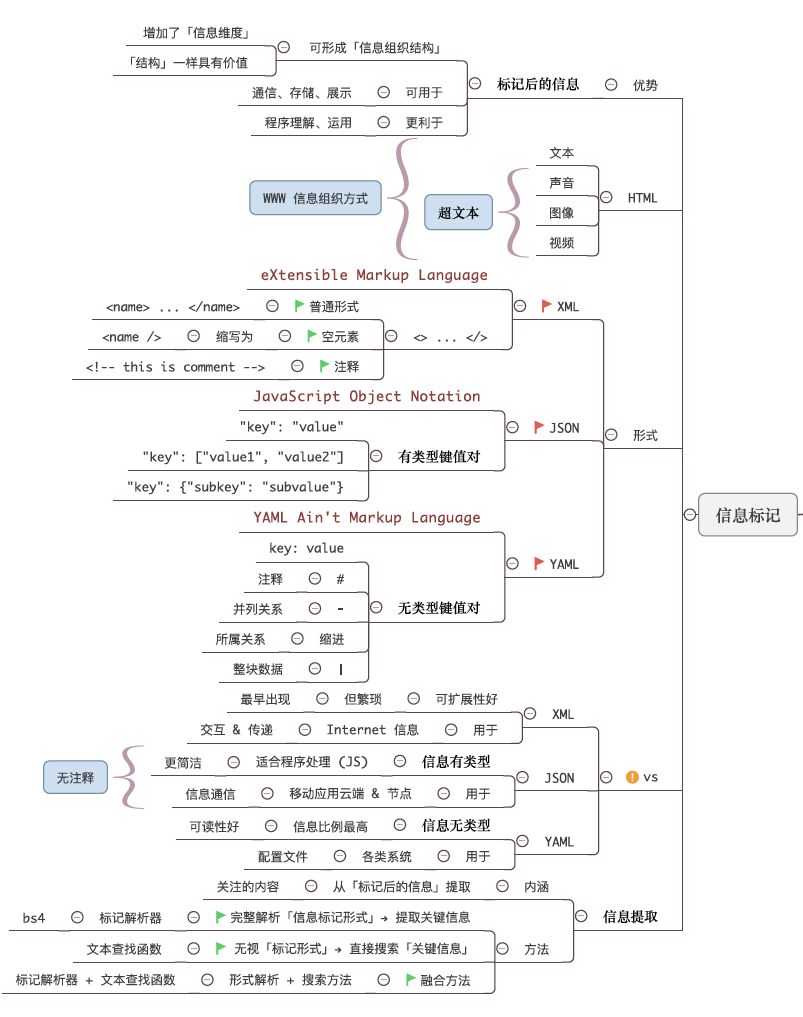
爬虫基础知识
爬虫基础知识→
03
QIKUXUEYUAN
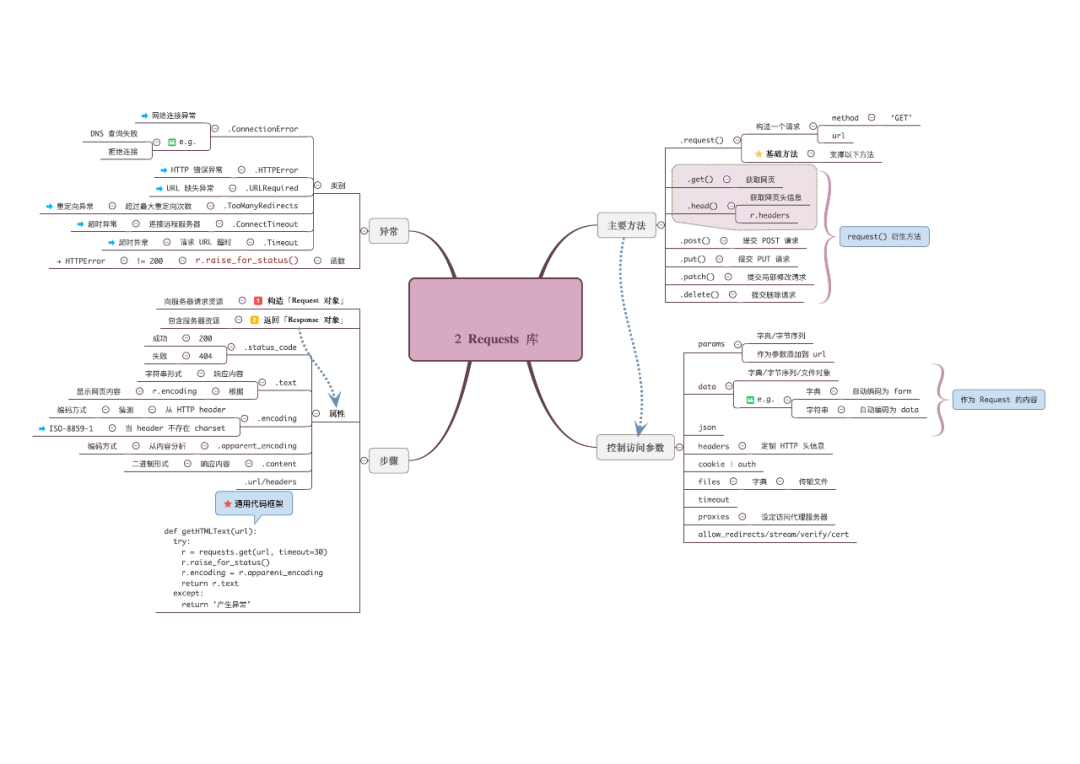
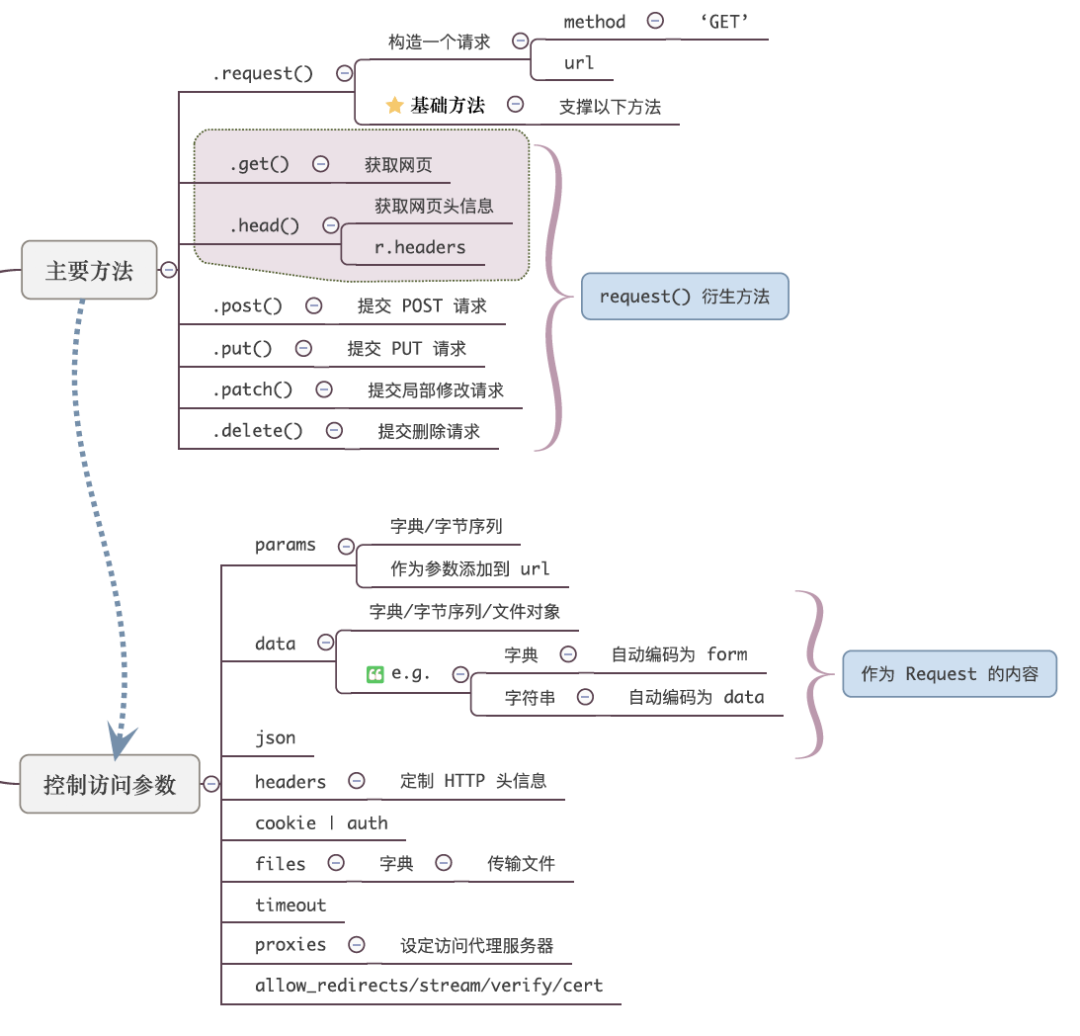
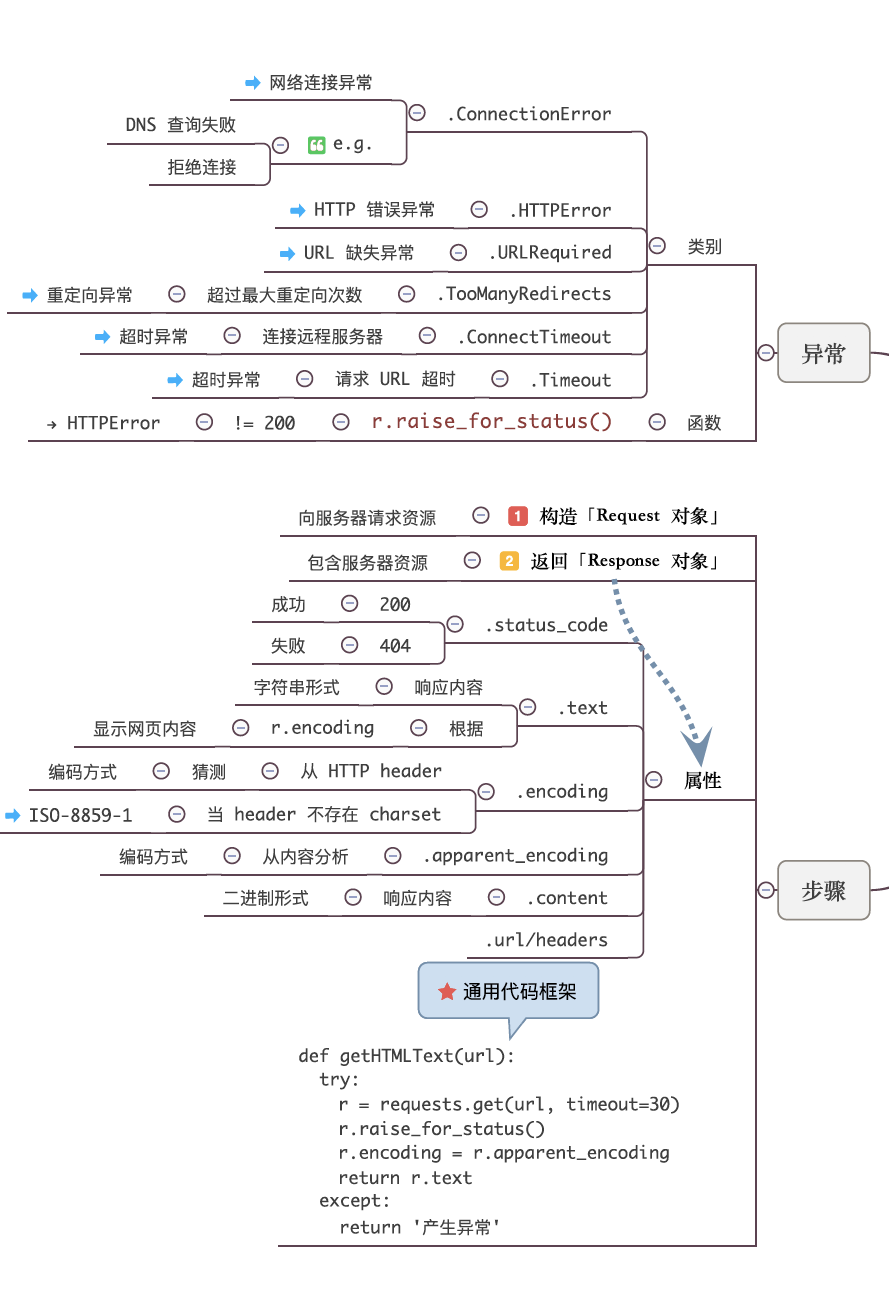
Requests库
requests:库应该是现在做爬虫最火最实用的库了,非常的人性化→
04
QIKUXUEYUAN
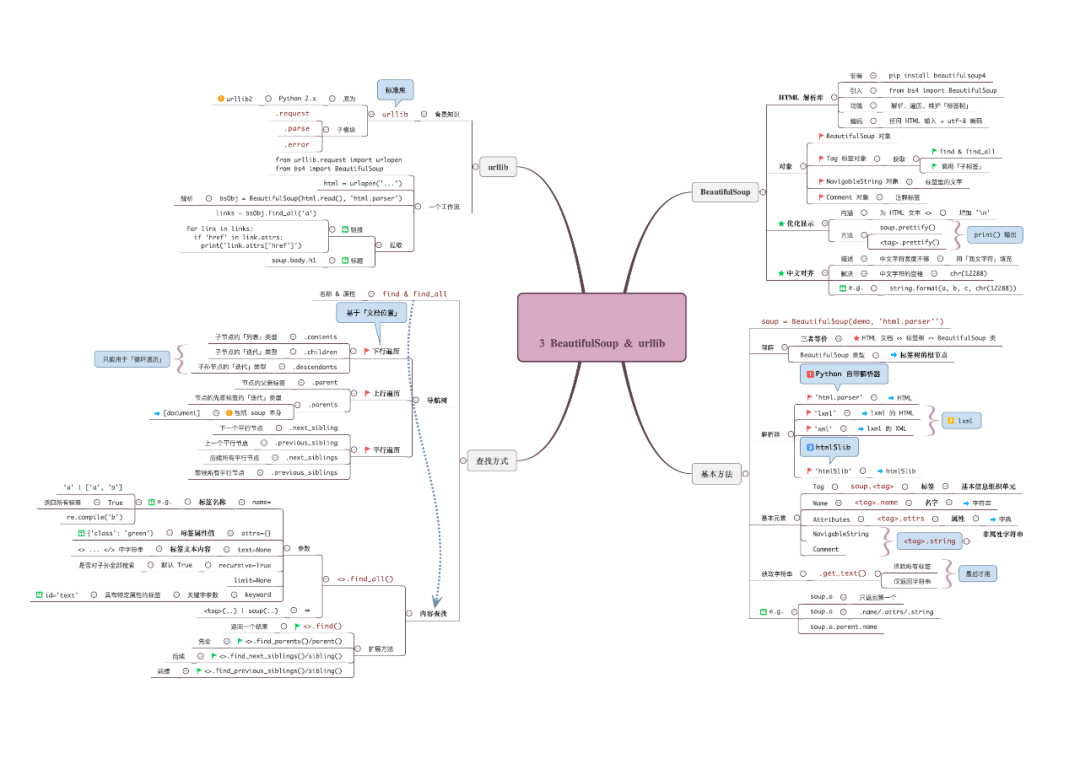
rllib3 & beautifulsoup
urllib3:是一个非常强大的http请求库,提供一系列的操作URL的功能。
beautifulsoup:对于html的解析是非常的好用→
05
QIKUXUEYUAN
Scrapy
Scrapy:很强大的爬虫框架,可以满足简单的页面爬取→
06
QIKUXUEYUAN
学习爬虫的十个建议
1.学习爬虫要重视验证码、ip池、js逆向、app反编译、脱壳这些技术;
2.爬虫最核心的是如何批量的获取数据,这里有两个重点,第一个是获取数据,第二个是批量;
3.有很多的加密,必须要去熟练的掌握;
4.爬虫或多或少要和数据分析以及大数据相结合,对大数据和数据分析,要有一些的了解;
5.想学习爬虫,首先要掌握一门语言,其次要掌握分布式;
6.学习爬虫不仅仅要会用框架,还要会设计分布式,要知道分布式的原理;
7.学习爬虫要会构建IP池,因为构建IP池是做大项目的一个前提,大项目都需要IP池;
8.学习爬虫要对JS的语言非常了解,因为大部分PC端的加密,以及微信小程序都是JS;
9.要会反编译这些技术;
10.爬虫不是爬来数据就不管了,时代的进步,数据是一直更新的,所以要看怎样能够更高效率的更新。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









