






 本文详细介绍了Python中中文编码问题的挑战,包括如何声明编码类型为utf-8,如何进行编码和解码操作,以及在实际项目中如文本处理、字符匹配和文件操作中遇到的编码问题解决方法。作者还分享了使用Jieba分词去除标点符号的例子。
本文详细介绍了Python中中文编码问题的挑战,包括如何声明编码类型为utf-8,如何进行编码和解码操作,以及在实际项目中如文本处理、字符匹配和文件操作中遇到的编码问题解决方法。作者还分享了使用Jieba分词去除标点符号的例子。
据说Python 最恶心的地方是中文编码问题,这也让很多人放弃使用Python。此刻我只想说。。放弃得好!。。
因为这确实是Python 最恶心的问题,暂时木有之一。
在经过多次挫败,多次google,多次stackoverflow 无果之后,只有硬着头皮上。。因为只会用Python 了摔!
终于我总结出的一套可以解决中文编码问题的方法。额,这只是针对文本处理的,至于解析网页那些神奇的编码表示完全无力。
原理
第一:声明程序的编码类型为utf-8
#! /usr/bin/env python2.7
#coding=utf-8
# 在所有程序开头都声明使用的Python 版本和编码
第二:编码和解码的逻辑
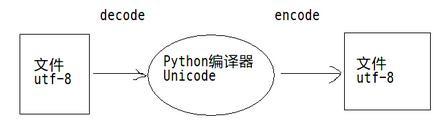
1. Python 编译器能循环处理的编码只有unicode ,其它编码都是邪魔外道,都要通通被烧死的。。。(其它编码其实也是可以处理的,但要循环遍历每一个字符的时候只能处理unicode)
2. 这样一来就简单了,只要在处理任何编码之前,把这个编码转成unicode,就可以被Python 处理了。在输出到文本中时,再从unicode 编码回去就可以了。
3. 因此解码的时候就用decode,把utf-8 编码解码成unicode;编码的时候就用encode,把unicode 编码回utf-8。具体如下:
sometext.decode("utf8") # 成为一个unicode编码
sometext.encode(“utf8”) # 重新编码成utf-8编码
str(sometext) # 用str()函数也可把unicode编码为utf-8,因为一开始已经声明了编码类型为utf-8
第三:善用type() 函数来查看字符的编码
#! /usr/bin/env python2.7
#coding=utf-8
token = “,.!?:;”
print type(token)
>> <type ‘str’> print type(token.decode(‘utf-8’))
>> <type ‘unicode’>
由于在开头声明了所有字符串类型的编码都为utf-8,所以“<type ‘str’>”的意思是该字符是字符串类型,所以编码为utf-8。而它在decode 之后可以看出它已经成为unicode 编码了。
最后:为什么要一定要是unicode 和 utf-8编码啊,其它不行吗?
因为,这是Python 的原则啊。“只给你一种选择,其它,No~”(翻译肯定有误,不过意思就是这样的。。)
而且utf-8 比什么gb2312 这样吧编码看起来舒服多了。。。
实战
1. 要循环处理字符串的时候需要解码。例子如下:
#! /usr/bin/env python2.7
#coding=utf-8
token = “,。!?:;”
for t in token:
print t
>> UnicodeDecodeError: ‘ascii’ codec can’t decode byte balabala in position balabala : ordinal not in range
for t in token.decode(‘utf-8’):
print t,
>> , 。 ! ? : ;
把字符串类型的token 解码为unicode 之后,就可以被循环遍历了。
2. 字符匹配的时候需要解码。因为当编码不一致的时候,就无法进行匹配。例子如下:
#! /usr/bin/env python2.7
#coding=utf-8
token = “,。!?:;”.decode(“utf8”)
string_list = [‘我’, ‘是’, ‘一只’, ‘大’, ‘苹果’, ‘,’, ‘又’, ‘香’, ‘又’, ‘甜’, ‘又’, ‘好吃’, ‘。’]
for t in token:
for sl in string_list:
if t == sl: #无法匹配,因为一个是unicode编码,一个是utf-8编码
print t,
>>
for t in token:
for sl in string_list:
if t == sl.decode(“utf8”) #这时两个都是unicode编码了,可以匹配了
print t,
>> , 。
由于string_list 里面都是utf-8编码的元素,因此在匹配的时候需要解码成unicode 才能和已经解码的token 匹配。
3. 结合jieba 分词来把一个字符串分词并去除标点符号(这是去停用词的其中一部分),例子如下:
① jieba 分词之后添加到一个空列表里面,得到一个分词后的结果。可以看到jieba 分词之后词语成了unicode 编码。
#! /usr/bin/env python2.7
#coding=utf-8
import jieba
string = “我是一只大苹果,又香又甜又好吃。”
string_list = []
seg = jieba.cut(string)
for word in seg:
string_list.append(word)
print string_list
>> [u’\u6211’, u’\u662f’, u’\u4e00\u53ea’, u’\u5927’, u’\u82f9\u679c’, u’\uff0c’, u’\u53c8’, u’\u9999’, u’\u53c8’, u’\u751c’, u’\u53c8’, u’\u597d\u5403’, u’\u3002’]
② 去掉标点符号
#! /usr/bin/env python2.7
#coding=utf-8
import jieba
string = “我是一只大苹果,又香又甜又好吃。”
string_list = []
seg = jieba.cut(string)
for i in seg:
string_list.append(i)
token = “,。!?:;”.decode(‘utf-8’)
filer_seg = [fil for fil in seg if fil not in token] # 用Python的列表推导来去掉标点,形成一个去掉标点后的数组
for word in filter_seg:
print word,
>> 我 是 一只 大 苹果 又 香 又 甜 又 好吃
4. 读取txt 文件和存储成txt 文件的时候需要注意的编码问题。
① txt 文件存储时记得另存为utf-8 编码,要不读取它的时候。。呵呵。。坐等抓狂
txt 文件默认编码是ascii,因此在保存txt 文件的时候需要另存为utf-8。

这样读取文件的内容就是utf-8编码的了。
② 在把列表内容存储回txt 文件,就需要把Python 里面的unicode 编码为utf-8编码,这才能在txt 文件中显示出来。
把unicode 编码成utf-8,不一定要用encode,用str() 函数也可以了。
#! /usr/bin/env python2.7
#coding=utf-8
import jieba
string = “我是一只大苹果,又香又甜又好吃。”
string_list = []
seg = jieba.cut(string)
for i in seg:
string_list.append(i)
f = open(‘D:/code/example.txt’,‘w’)
for word in string_list:
f.write(str(word)+’ ') #用str()函数把unicode字符编码为utf-8,并写入txt 文件中
f.close()
基本上文本挖掘中需要用到的编码解码内容都在里面了,如果还有其它情况,就按照原理办事,一切都好。
以上就是“Python 文本挖掘:解决Python最恶心的问题!”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









