






文章目录
⭕爬虫与第三方库requests简介
1. 爬虫流程简介
发起请求: 通过HTTP库向目标站点发起请求,等待目标站点服务器响应。
获取响应: 若服务器正常响应,会返回一个Response,该Response即为获取得页面内容,Response可以是HTML、JSON字符串、二进制数据等数据类型。
解析内容: 利用正则表达式、网页解析库对HTML进行解析;将json数据转为JSON对象进行解析;保存我们需要得二进制数据(图片、视频)。
保存数据: 可将爬取并解析后的内容保存为文本,或存至数据库等。
其中 Requests库可以实现实现发起请求,获取响应。
2. 第三方库requests简介

Python中,系统自带的urllib和urllib2都提供了功能强大的HTTP支持,但是API接口难用。Requests是一款目前非常流行的http请求库,使用python编写,能非常方便的对网页Requests进行爬取,也是爬虫最常用的发起请求第三方库。
Requests is an elegant and simple HTTP library for Python, built for human beings.
一、安装方法
- 常规安装命令
- pip install requests
- 设置超时参数,增加pip等待时间
- pip --default -timeout=100 install requests
- 指定某个镜像网站作为下载源
- pip install requests -i
官方文档:https://requests.readthedocs.io/en/latest/
二、常用方法
| 方法 | 解释 |
|---|---|
| requests. get() | 获取HTML的主要方法 |
| requests. head() | 获取HTML头部信息的主要方法 |
| requests post() | 向HTML网页提交post请求的方法 |
| requests put() | 向HTML网页提交put请求的方法 |
| requests.patch() | 向HTM提交局部修改的请求 |
| requests. delete() | 向HTM提交删除请求 |
get()方法
requests.get(url ,params ,**kwargs)请求获取指定URL位置的资源,服务器将返回一个Response对象作为对请求的响应。

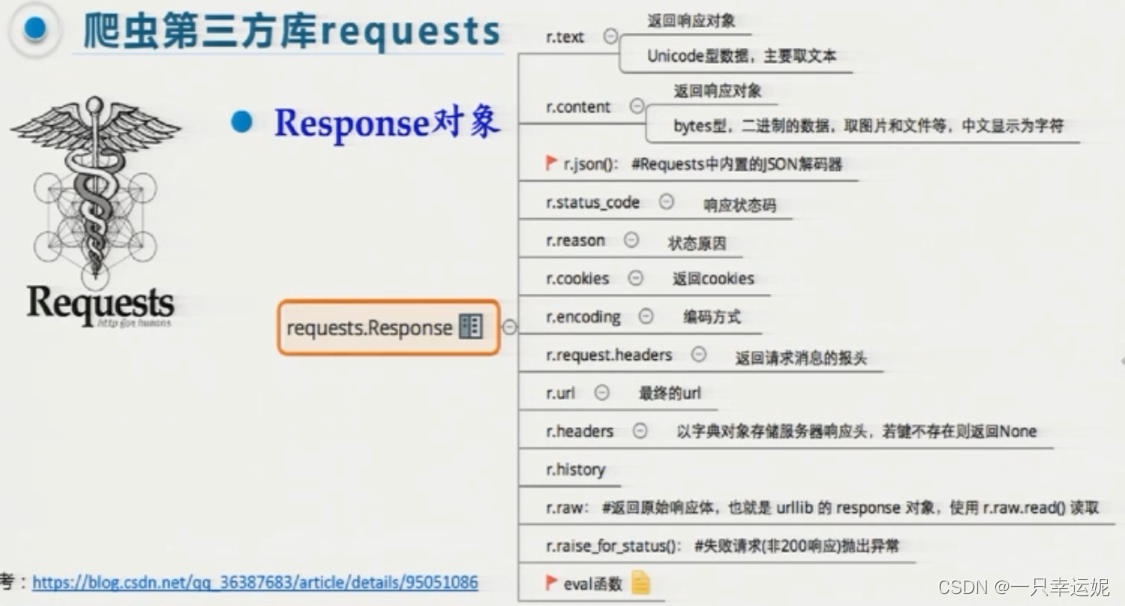
Response响应对象
| 属性 | 描述 |
|---|---|
| response.status_code | 获取HTTP请求返回的响应状态码 |
| response.text | 获取响应内容的字符串(str)形式 |
| response.content | 获取响应内容的二进制(bytes)形式 |
| response.encoding | 设置响应内容的编码方式 |
response.text()
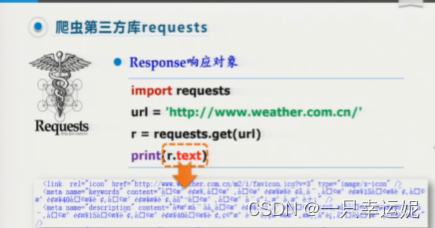
中文编码出现乱码
response.encoding
用来设置返回的response内容的编码方式,针对以上乱码设置新的编码。

response.content()
获取响应内容的二进制(bytes)形式,对二进制进行解码。中文字符的常用编码方式utf-8、gbk或者gb2312 等等

其他方法
三、说明
本笔记来源慕课视频:https://www.icourse163.org/learn/NHDX-1463126169?tid=1467058488
小白学习,如有错误,欢迎指正。















 6007
6007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









