








前言
locust测试本质上只是一个 Python 程序,向您要测试的系统发出请求。这使得它非常灵活,特别擅长实现复杂的用户流。但它也可以做简单的测试,所以让我们从它开始:
from locust import HttpUser, task
class HelloWorldUser(HttpUser):
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
此用户将一次又一次地向 发出 HTTP 请求。有关完整的说明和更实际的示例,请参阅编写 locustfile。/hello/world
更改并更改为要测试的网站/服务上的一些实际路径,将代码放在当前目录中命名的文件中,然后运行:/hello/worldlocustfile.pylocust
$ locust
[2021-07-24 09:58:46,215] .../INFO/locust.main: Starting web interface at http://*:8089
[2021-07-24 09:58:46,285] .../INFO/locust.main: Starting Locust 2.20.1
locust的 Web 界面
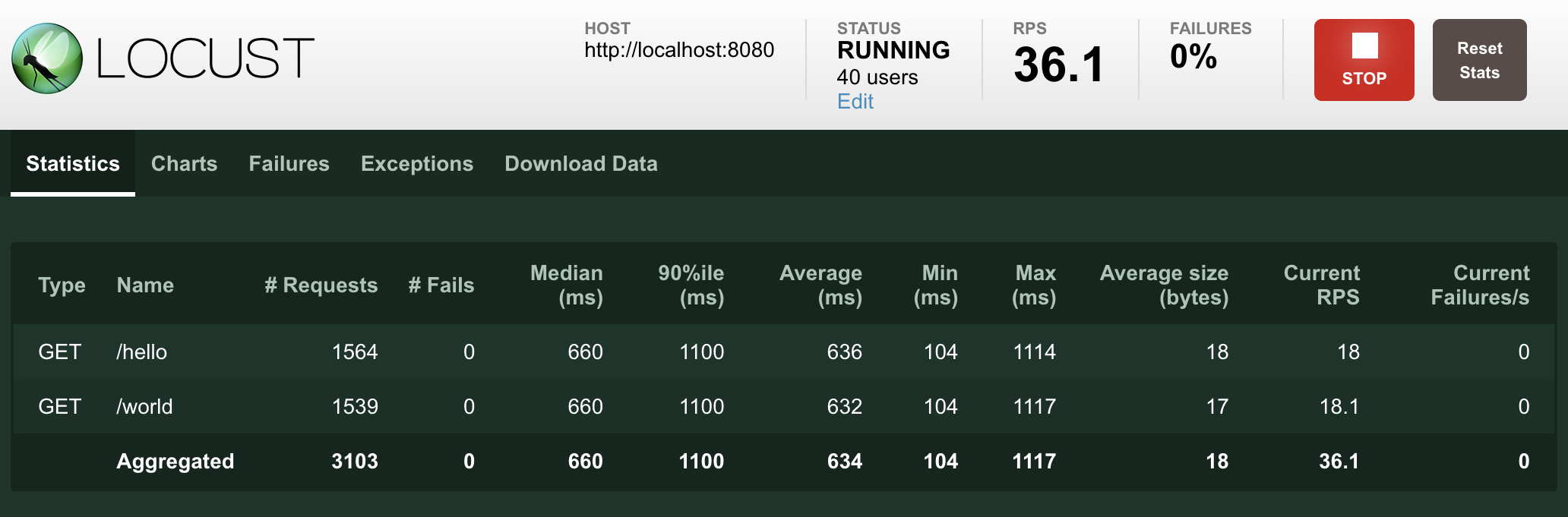
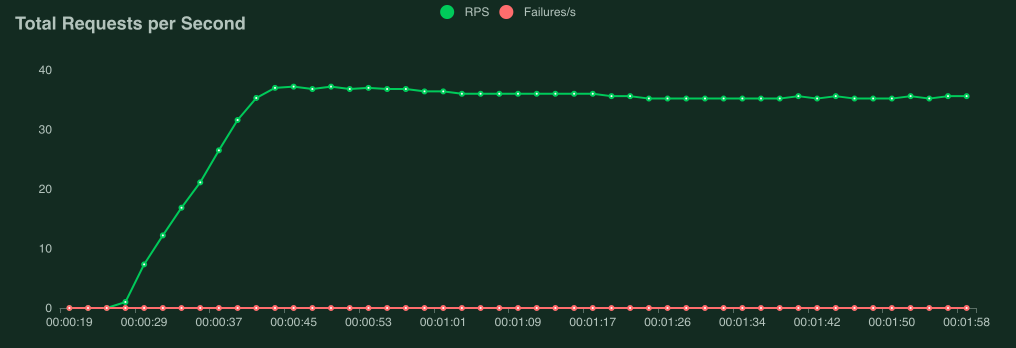
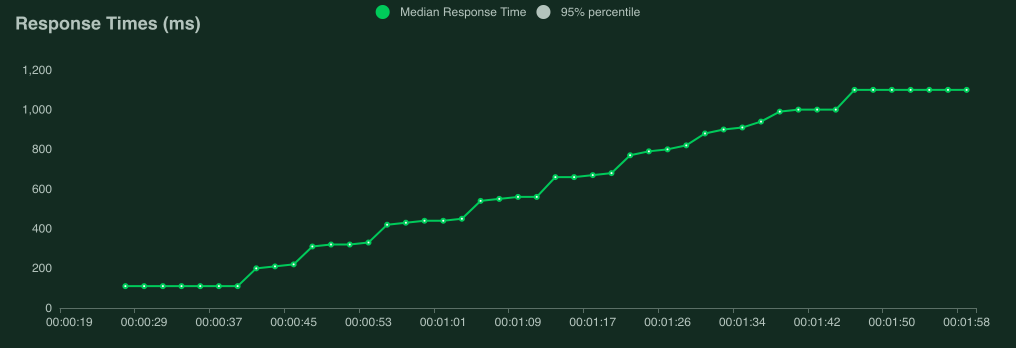
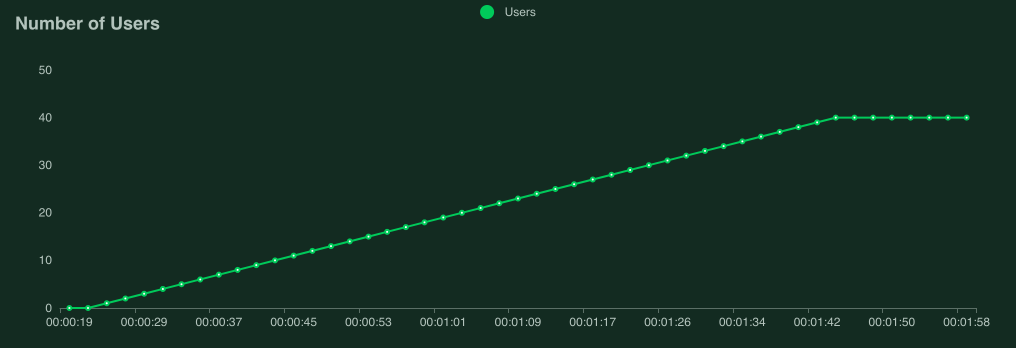
以下屏幕截图显示了使用 40 个并发用户(上升速率为 0.5 个用户/秒)针对性能稍差的服务器运行此测试时可能是什么样子。
注意
解释性能测试结果非常复杂(而且大多超出了本手册的范围),但是如果您的图形开始看起来像这样,则目标服务/系统无法处理负载,并且您发现了瓶颈。
当我们达到大约 9 个用户时,响应时间开始快速增加,即使 Locust 仍在产生更多用户,每秒的请求数量也不再增加。目标服务处于“过载”或“饱和”状态。
如果响应时间没有增加,则添加更多用户,直到找到服务的中断点,或者庆祝服务的性能已经足以满足预期的负载。
如果你在挖掘服务器端问题时需要一些帮助,或者你在生成足够的负载来使你的系统饱和时遇到困难,请查看 Locust FAQ。
现在有一个现代版本的 Web UI 可用!通过设置标志来尝试一下。--modern-ui
注意
此功能是实验性的,您可能会遇到重大更改。
直接命令行使用/无头
使用 Locust Web UI 是完全可选的。您可以在命令行上提供加载参数,并以文本形式获取有关结果的报告:
$ locust --headless --users 10 --spawn-rate 1 -H http://your-server.com
[2021-07-24 10:41:10,947] .../INFO/locust.main: No run time limit set, use CTRL+C to interrupt.
[2021-07-24 10:41:10,947] .../INFO/locust.main: Starting Locust 2.20.1
[2021-07-24 10:41:10,949] .../INFO/locust.runners: Ramping to 10 users using a 1.00 spawn rate
Name # reqs # fails | Avg Min Max Median | req/s failures/s
----------------------------------------------------------------------------------------------
GET /hello 1 0(0.00%) | 115 115 115 115 | 0.00 0.00
GET /world 1 0(0.00%) | 119 119 119 119 | 0.00 0.00
----------------------------------------------------------------------------------------------
Aggregated 2 0(0.00%) | 117 115 119 117 | 0.00 0.00
(...)
[2021-07-24 10:44:42,484] .../INFO/locust.runners: All users spawned: {"HelloWorldUser": 10} (10 total users)
(...)
有关更多详细信息,请参阅不使用 Web UI 运行。
更多选项
要运行分布在多个 Python 进程或机器上的 Locust,请启动单个 Locust 主进程 使用命令行参数,然后使用命令行参数对任意数量的 Locust 工作进程进行操作。有关详细信息,请参阅分布式负载生成。--master--worker
要查看所有可用选项,请键入: 或选中配置。`locust --help
写入locust文件
现在,让我们看一个更完整/更现实的测试示例:
import time
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@task(3)
def view_items(self):
for item_id in range(10):
self.client.get(f"/item?id={
item_id}", name="/item")
time.sleep(1)
def on_start(self):
self.client.post("/login", json={
"username":"foo", "password":"bar"})
让我们来分解一下
import time
from locust import HttpUser, task, between
locust文件只是一个普通的 Python 模块,它可以从其他文件或包中导入代码。
class QuickstartUser(HttpUser):
在这里,我们为将要模拟的用户定义一个类。它继承给每个用户一个属性, 这是 的实例,即 可用于向我们想要加载测试的目标系统发出 HTTP 请求。当测试开始时, Locust 将为它模拟的每个用户创建一个此类的实例,并且每个用户 用户将开始在他们自己的绿色 gevent 线程中运行。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









