





 在Python编程中,通过requests模块向网页发送请求时遇到状态码错误。为了解决这个问题,我们采用了设置headers,特别是模拟user-agent的方式,成功伪装浏览器进行爬取,从而获取到了所需文本内容。
在Python编程中,通过requests模块向网页发送请求时遇到状态码错误。为了解决这个问题,我们采用了设置headers,特别是模拟user-agent的方式,成功伪装浏览器进行爬取,从而获取到了所需文本内容。
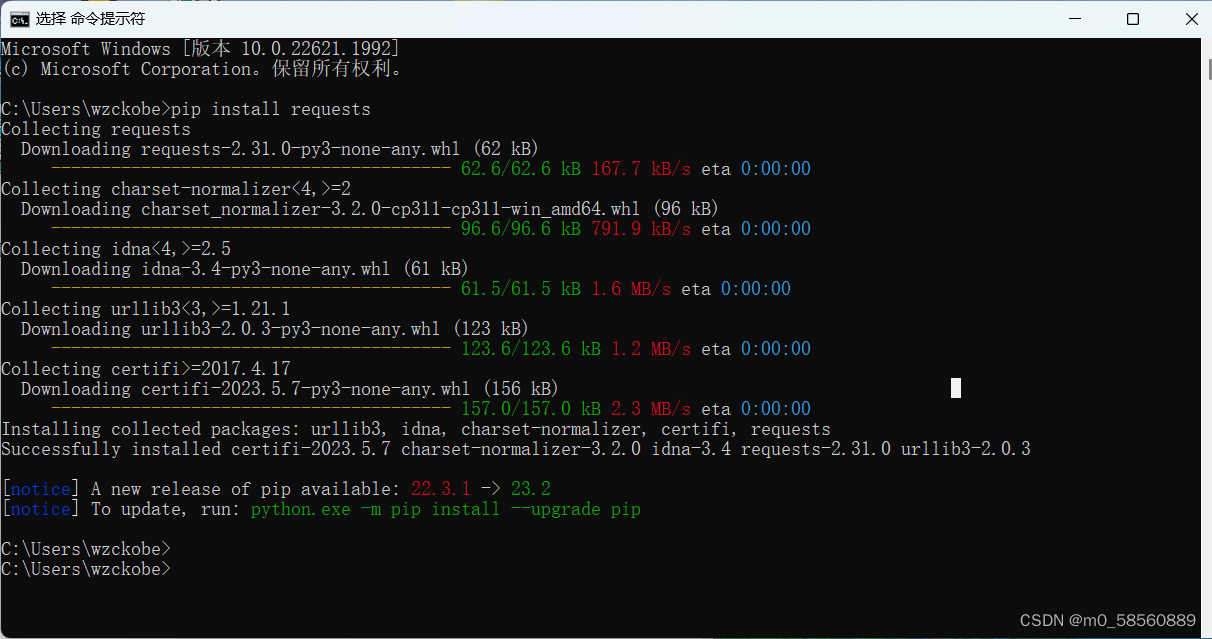
先安装requests模块,用来向网页发送请求
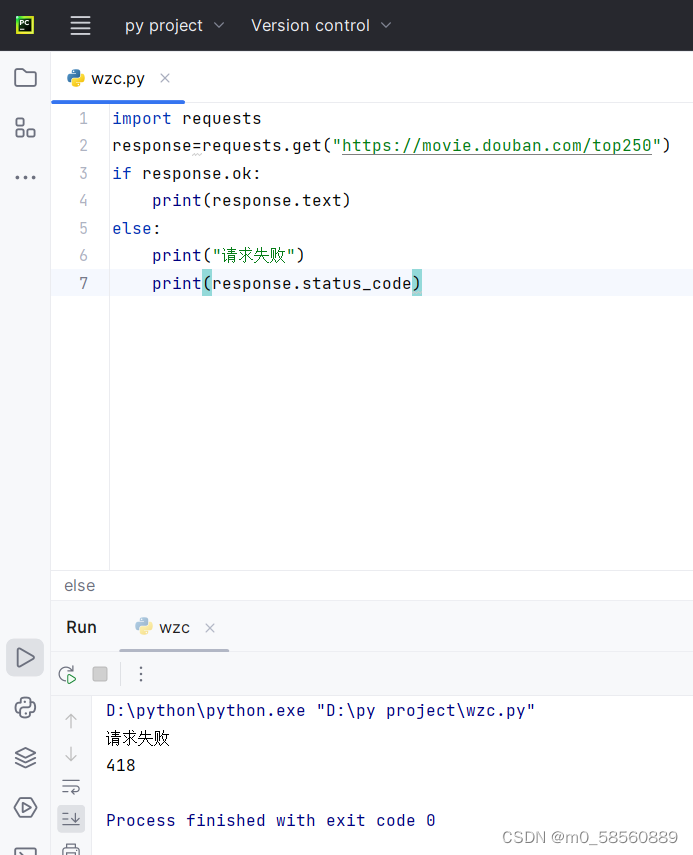
导入模块,发送请求失败,状态码错误
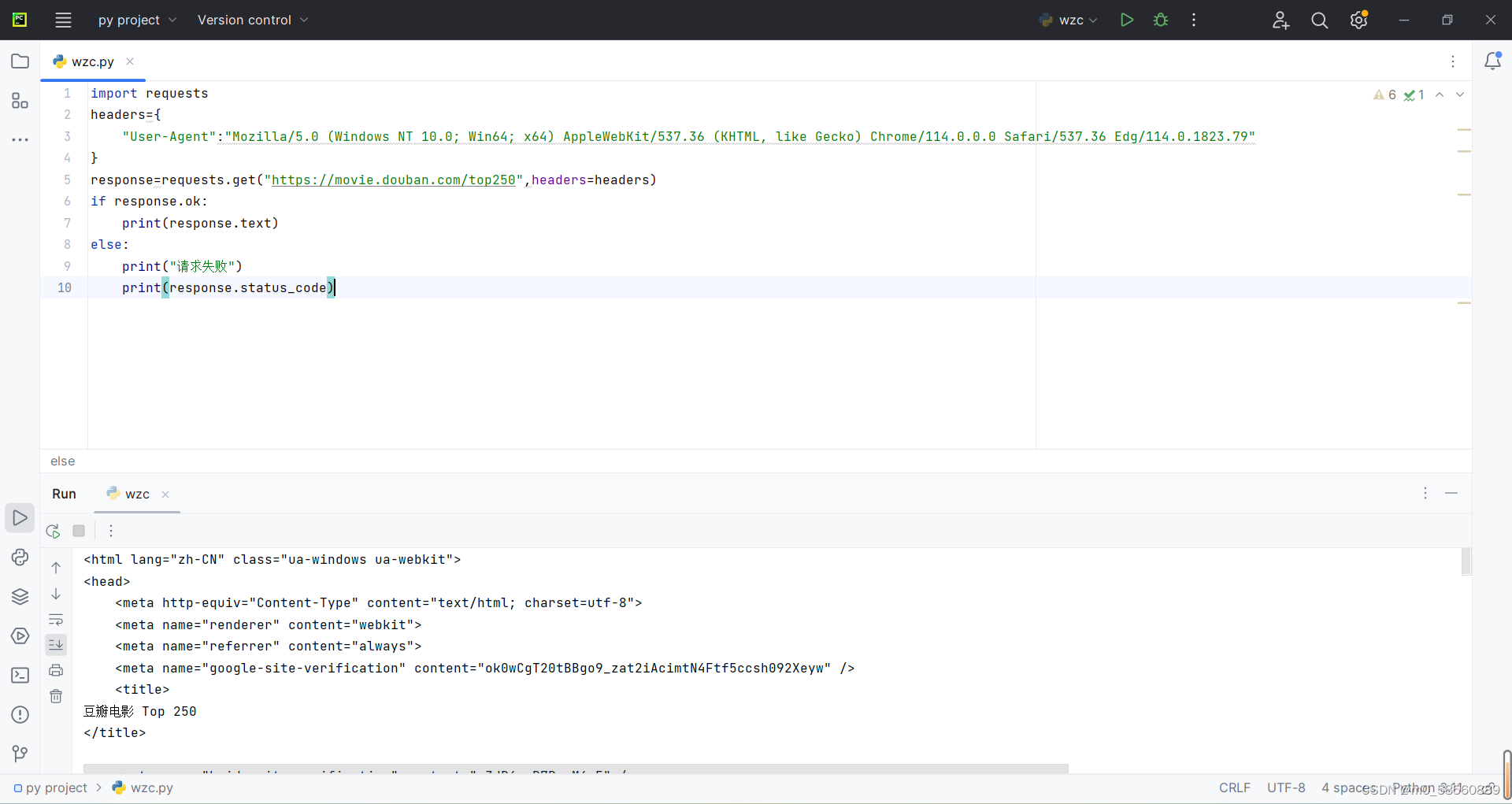
利用headers伪装user-name后爬取文本成功

先安装requests模块,用来向网页发送请求
导入模块,发送请求失败,状态码错误
利用headers伪装user-name后爬取文本成功
 1406
1683
1406
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























