







My SQL数据库新手基础笔记(下)
前言
-
如果真的要说程序员用得最多的语言,那应该是 SQL 吧。
-
不仅是前端,或是后端或多或少都要懂得写一些 SQL。甚至接触过很多业务人员,例如产品经理、运营、财务人员,也懂得写 SQL。
-
SQL 作为与数据直接打交道的语言,是与各种前端、后端语言进行交互的“中台”语言。不论是前端工程师,还是后端算法工程师,都一定会和数据打交道,都需要了解如何又快又准确地提取自己想要的数据。
-
MySQL 由于免费,而且性能强劲,是目前使用最广泛的数据库产品,同时也是入门门槛最低的数据库产品之一,更重要的是,我们可以以 MySQL 为学习原型,以后去适应和掌握其他数据库产品,思想和原理都是互通的,也不会有太大障碍。`
八、MySQL多表查询
多表关系
一对多/多对一关系
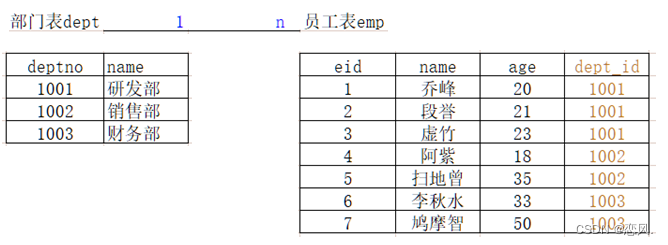
部门和员工
- 分析:一个部门有多个员工,一个员工只能对应一个部门
- 实现原则:在多的一方建立外键,指向一的一方的主键
一对一关系
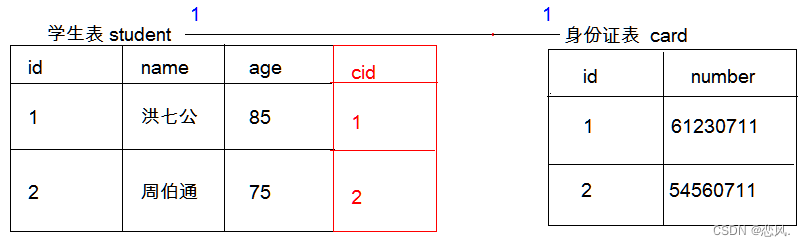
- 一个学生只有一张身份证;一张身份证只能对应一学生。
- 在任一表中添加唯一外键,指向另一方主键,确保一对一关系。
- 一般一对一关系很少见,遇到一对一关系的表最好是合并表。
多对多关系
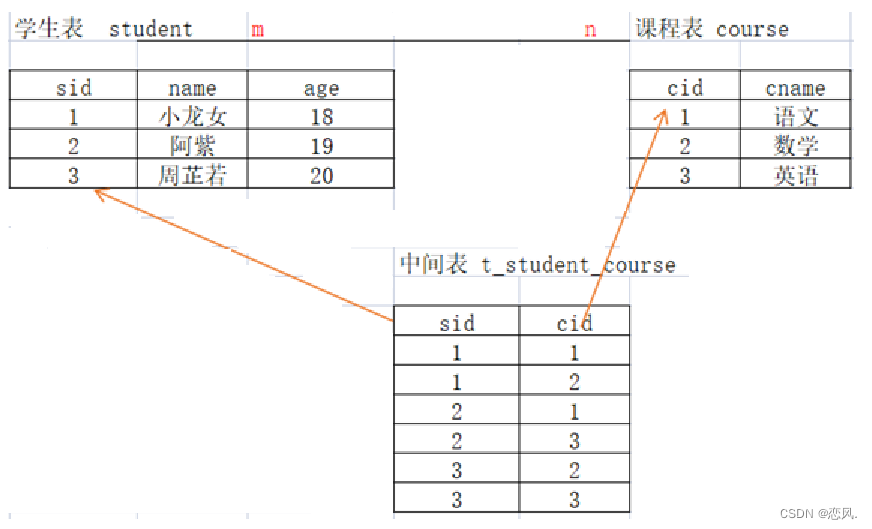
学生和课程
- 分析:一个学生可以选择很多门课程,一个课程也可以被很多学生选择
- 原则:多对多关系实现需要借助第三张中间表。中间表至少包含两个字段,将多对多的关系,拆成一对多的关系,中间表至少要有两个外键,这两个外键分别指向原来的那两张表的主键
多表查询
- 多表查询就是同时查询两个或两个以上的表
交叉连接查询
- 交叉连接查询返回被连接的两个表所有数据行的笛卡尔积
笛卡尔积可以理解为一张表的每一行去和另外一张表的任意一行进行匹配
假如A表有m行数据,B表有n行数据,则返回m*n行数据
笛卡尔积会产生很多冗余的数据,后期的其他查询可以在该集合的基础上进行条件筛选
#格式:
select * from 表1,表2,表3….;
#实现:
select * from dept3,emp3;
外连接查询
介绍:
- 外连接分为左外连接(left outer join)、右外连接(right outer join),满外连接(full outer join)。
- 注意:oracle里面有full join,可是在mysql对full join支持的不好。我们可以使用union来达到目的。
格式:
#左外连接:left outer join
select * from A left outer join B on 条件;
#右外连接:right outer join
select * from A right outer join B on 条件;
#满外连接: full outer join
select * from A full outer join B on 条件;
内连接查询
- 内连接查询求多张表的交集
隐式内连接(SQL92标准):select * from A,B where 条件;
显示内连接(SQL99标准):select * from A inner join B on 条件;
子查询
介绍:
- 子查询就是指的在一个完整的查询语句之中,嵌套若干个不同功能的小查询,从而一起完成复杂查询的一种编写形式,通俗一点就是包含select嵌套的查询。
子查询可以返回的数据类型一共分为四种:
- 单行单列:返回的是一个具体列的内容,可以理解为一个单值数据;
- 单行多列:返回一行数据中多个列的内容;
- 多行单列:返回多行记录之中同一列的内容,相当于给出了一个操作范围;
- 多行多列:查询返回的结果是一张临时表
-- 查询年龄最大的员工信息,显示信息包含员工号、员工名字,员工年龄
select eid,ename,age from emp3 where age = (select max(age) from emp3);
-- 查询年研发部和销售部的员工信息,包含员工号、员工名字
select eid,ename,t.name from emp3 where dept_id in (select deptno,name from dept3 where name = '研发部' or name = '销售部') ;
-- 查询研发部20岁以下的员工信息,包括员工号、员工名字,部门名字
select eid,age,ename,name from (select * from dept where name = '研发部 ')t1,(select * from emp3 where age <20)t2
select * from emp,dept where emp.eid_did = dept.did and eid_did in(select did from dept where dname='研发部') and eage < 30
子查询关键字
- 在子查询中,有一些常用的逻辑关键字,这些关键字可以给我们提供更丰富的查询功能,主要关键字如下:
1.ALL关键字
特点
- ALL: 与子查询返回的所有值比较为true 则返回true
- ALL可以与=、>、>=、<、<=、<>结合是来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的其中的所有数据。
- ALL表示指定列中的值必须要大于子查询集的每一个值,即必须要大于子查询集的最大值;如果是小于号即小于子查询集的最小值。同理可以推出其它的比较运算符的情况。
select …from …where c > all(查询语句)
--等价于:
select ...from ... where c > result1 and c > result2 and c > result3
2.ANY和SOME关键字
特点
- ANY:与子查询返回的任何值比较为true 则返回true
- ANY可以与=、>、>=、<、<=、<>结合是来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的其中的任何一个数据。
- 表示制定列中的值要大于子查询中的任意一个值,即必须要大于子查询集中的最小值。同理可以推出其它的比较运算符的情况。
- SOME和ANY的作用一样,SOME可以理解为ANY的别名
select …from …where c > any(查询语句)
--等价于:
select ...from ... where c > result1 or c > result2 or c > result3
3.IN关键字
特点
- IN关键字,用于判断某个记录的值,是否在指定的集合中
在IN关键字前边加上not可以将条件反过来
select …from …where c in(查询语句)
--等价于:
select ...from ... where c = result1 or c = result2 or c = result3
4.EXISTS关键字
特点
- 该子查询如果“有数据结果”(至少返回一行数据), 则该EXISTS() 的结果为“true”,外层查询执行
该子查询如果“没有数据结果”(没有任何数据返回),则该EXISTS()的结果为“false”,外层查询不执行
EXISTS后面的子查询不返回任何实际数据,只返回真或假,当返回真时 where条件成立
注意,EXISTS关键字,比IN关键字的运算效率高,因此,在实际开发中,特别是大数据量时,推荐使用EXISTS关键字
select …from …where exists(查询语句)
九、MySQL视图
- 视图(view)也被称为虚拟表,就是一个能够长久保存的虚拟的表,其本质是一条具有SELECT的查询语句。视图中的数据其实就是该条SQL语句查询的结果集。
- 视图本身并不包含任何数据,它只包含了一条映射的sql语句查询后的结果而已,我们每一次操作时,系统都会自动的执行该视图的SELECT语句,而不用我们手动去执行,相当于结果数据永久保存。
视图中的数据会根据SELECT语句真实操作的基表的数据的改变而改变。
视图作用
1、可以对表中的敏感字段进行隐藏,提高数据的安全性
2、可以简化复杂的sql语句,把一条非常复杂的sql封装到视图中,简单使用难度需要注意:
–如果视图只关联一个基表,则通过该视图可以进行增加,删除,修改,查询功能【CRUD】
–如果视图关联多个基表,则只能通过该视图进行查询功能
操作视图
#创建视图
create view 视图名 as select 列名 表名
#删除视图
drop view 视图名
操作视图:
select .... from 视图名
insert into 视图名 values(......);
delete from 视图名 where ......
update 视图名 set 字段=新值
十、MySQL事务
-
事务就是再再项目如果有一个非常复杂的功能需要执行多个DML语句才能真正的完成此功能,那么我们就可以使用事务来管理该多个DML语句,实现多个DML语句要么全部执行完成则完成功能;要么如果有一个语句没有完成,则全部的DML语句执行失败回滚原始,功能执行失败。
-
事务其实就是数据库中用来统一管理多个DML语句的业务逻辑功能。
-
事务用来管理多个条DML语句,一旦事务管理了,则多条DML语句就是一个不可分割的整体,要么所有的DML语句执行成,要么所有的DML语句执行失败。
事务特性
- 多条SQL语句看成一个整体,要么全部执行成功,要么全部执行失败!
成功: 事务的提交
失败:事务的回滚- 把转出金钱和转入金钱两条修改的SQL语句作为一个整体,如果两条SQL语句都执行成功了,则该功能成功 提交;如果两条SQL语句中有一条执行失败,则该功能就自动实现事务回滚,提交失败。
事务管理
mysql中默认的是每一条sql语句都是一个事务,且该事务自动提交
开启事务: begin / start transaction
提交事务: commit
回滚事务: rollback
查看事务是否默认提交:
select @@autocommit; 1:自动提交 0:手动提交
修改事务的的提交方式:
set @@autocommit = 值;
设置保存点:
savepoint 保存点名;
回滚到保存点:
rollback to 保存点;
事务四大特性(ACID)
Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久性)
- 原子性:整个事务中的所有操作是一个不可分割的整体,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
- 隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行 相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆, 必须串行化或序列化请 求,使得在同一时间仅有一个请求用于同一数据。
- 持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
事务隔离级别

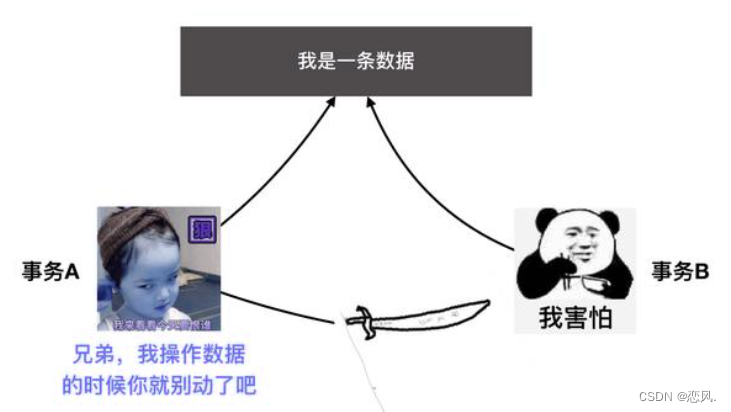
- Isolate,顾名思义就是将事务与另一个事务隔离开,为什么要隔离呢?如果一个事务正在操作的数据被另一个事务修改或删除了,最后的执行结果可能无法达到预期。如果没有隔离性还会导致其他问题。
事务隔离级别操作:
-- 查看隔离级别
show variables like '%isolation%’;
-- 设置隔离级别
/*
set session transaction isolation level 级别字符串
级别字符串:read uncommitted、read committed、repeatable read、serializable
*/
-- 设置read uncommitted
set session transaction isolation level read uncommitted;
-- 设置read committed
set session transaction isolation level read committed;
-- 设置repeatable read
set session transaction isolation level repeatable read;
-- 设置serializable
set session transaction isolation level serializable;
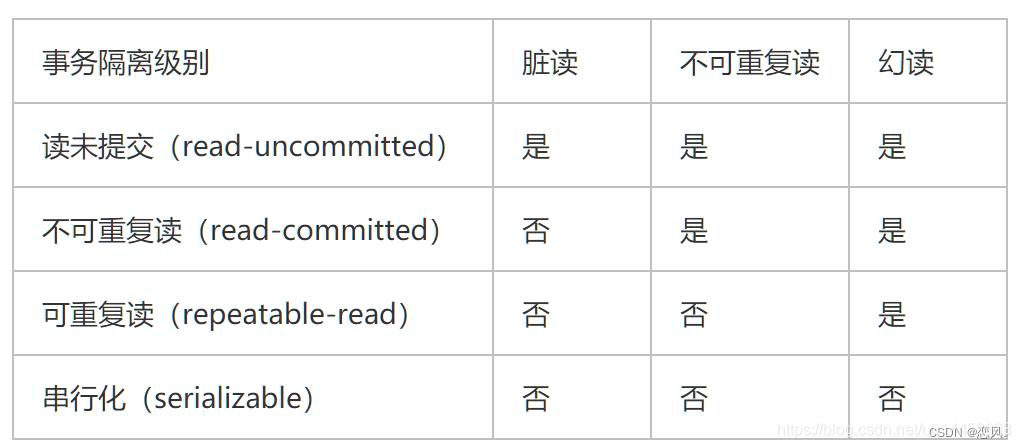
隔离级别介绍
- 读未提交(Read uncommitted)
一个事务可以读取另一个未提交事务的数据,最低级别,任何情况都无法保证,会造成脏读。- 读已提交(Read committed)
一个事务要等另一个事务提交后才能读取数据,可避免脏读的发生,会造成不可重复读。- 可重复读(Repeatable read)
就是在开始读取数据(事务开启)时,不再允许修改操作,可避免脏读、不可重复读的发生,但是会造成幻读。- 串行(Serializable)
是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离 级别效率低下,比较耗数据库性能,一般不使用。
















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











