







文献基本信息
- 标题:ActionCLIP: A New Paradigm for Video Action Recognition
- 作者:Mengmeng Wang、Jiazheng Xing、Yong Liu
- 单位:浙江大学
- 会议/期刊:CVPR
- 发表时间:2021年9月17日
- 代码:https://github.com/sallymmx/ActionCLIP.git
背景与意义
- 视频动作识别是视频理解的第一步,是近年来视频研究的热点,主要经历了两个阶段:
- 特征工程(feature engineering)。
- 结构工程(architecture engineering)。
- 由于在Kinetics等大型数据集诞生之前,没有足够的数据来学习高质量的模型,早期的方法侧重于特征工程,利用他们的知识设计特定的手工表达。
- 然后,随着深度神经网络和大型基准测试的出现,现在进入了第二阶段,即结构工程,通过合理吸收时间维度,出现了许多设计良好的网络,如双流网络、三维卷积神经网络(CNN)、计算高效的网络和基于Transformer的网络。
- 尽管特征和网络结构在过去几年中得到了很好的研究,它们经过训练,可以在单模态框架内预测一组固定的预定义类别,如下图(a)所示,但是这种预先确定的方式限制了其通用性和可用性,因为需要额外的带标签的训练数据才能迁移到任何其他新的概念。
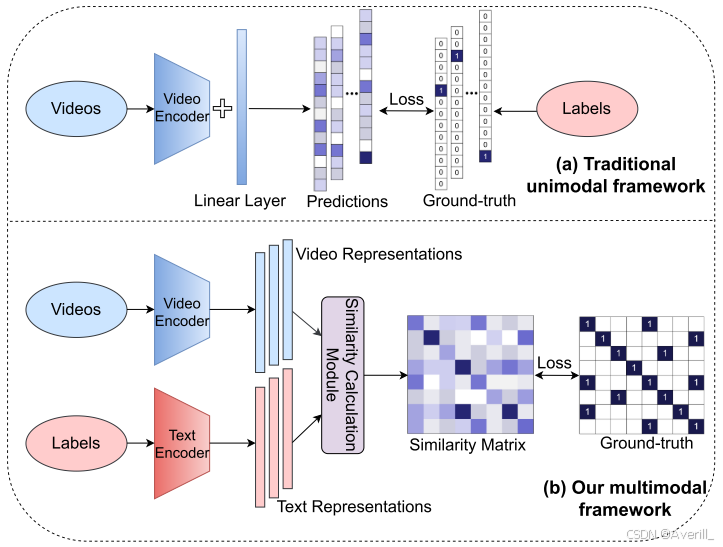
- 与以前那样直接将标签映射到数字相比,直接从文本中学习是更加有效的,可以成为更广泛的监督来源,并提供更全面的代表性,人类可以通过将视觉外观的语义信息与自然语言源(而不是数字)相关联来识别已知和未知的视频。
- 本文在多模态框架中探索自然语言监督,如上图(b)所示,目标有两个:
- 通过更多语义语言监督加强传统动作识别的表示。
- 使模型能够实现zero-shot迁移,而无需任何进一步的标记数据或参数要求。
研究方法与创新点
多模态学习框架
- 以前的视频动作识别方法将此任务视为标准的1-of-N投票问题,将标签映射为数字,这个pipeline完全忽略了标签文本中包含的语义信息。
- 与纯视频建模相比,本文将此任务建模为视频文本多模态学习问题,在自然语言的监督下学习不仅可以提高表达能力,而且可以实现灵活的zero-shot迁移。
- 形式上,给定一个输入视频
和一个来自预定义标签集的标签
。
- 之前的工作通常训练一个模型来预测条件概率
,并将${\bf{y}}$转换为一个数字或一个one-hot向量。在推理阶段,预测得分最高的下标被视为对应的类别。
- 本文试图打破这一pipeline,并将问题建模为
,其中
是一个相似函数,那么测试就是一个匹配过程,相似度得分最高的标签词就是分类结果:
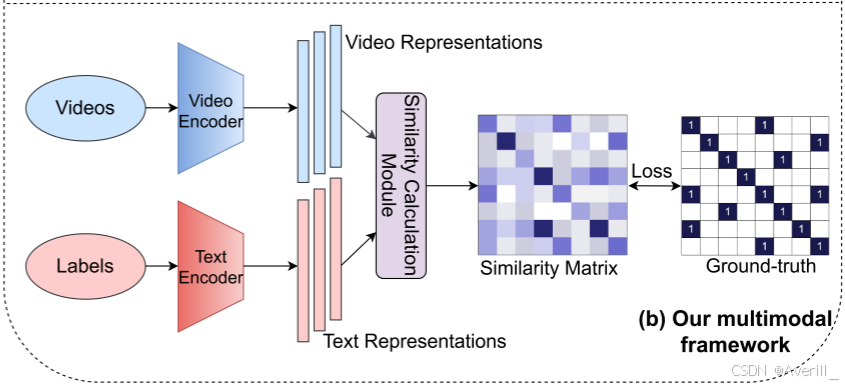
- 如上图所示,本文在双流框架内学习视频和标签词的单独单模态编码器,视频编码器提取视觉形态的时空特征,语言编码器用于提取输入标签文本的特征,可以是多种语言模型。然后,为了使成对视频和标签表示彼此接近,本文在相似性计算模块中定义两种模态之间的对称相似性,即余弦距离:
- 其中,
和
分别是
- 式中,
是可学习的温度参数,
是训练对的数量。
- 设
、
表示ground-truth相似性得分,其中负对的概率为0,正对的概率为1。由于视频的数量远大于固定标签,因此在一个batch的视频中不可避免地会出现属于一个标签的多个视频。因此,在
- 其中,
表示整个训练集。
- 由于模型学习到了语义信息,因此也可以进行zero-shot迁移。
新范式
- 在考虑上述多模态学习框架时,需要考虑标签词的不足,最直观的方法是利用大量的web图像文本或视频文本数据。
- 为了迎合这一点,本文提出了一种新的“预训练、提示和微调(pre-train, prompt and fine-tune)” 动作识别范式。
预训练
- 正如先前的工作所表明的,预训练对视觉语言多模态学习有很大的影响,由于训练数据是直接从网络上收集的,因此其中一个热门方向是设计适当的目标,以便在此过程中处理这些噪声数据。
- 在预训练过程中主要有三个上游预训练代理任务:
- 多模态匹配(Multimodal Matching, MM)。
- 多模态对比学习(Multimodal Contrastive Learning, MCL)。
- 掩蔽语言建模(Masked Language Modeling, MLM)。
- MM预测一对模态是否匹配,MCL的目的是绘制彼此接近的成对单模态表示,MLM利用这两种模态的特征来预测掩蔽的词。
- 然而,由于计算量巨大的限制,本文没有关注这一步骤,直接选择应用预训练的模型,并在其他两个步骤上进行研究。
prompt
- NLP中的提示(prompt)意味着使用模板将原始输入修改为文本字符串提示,该提示有一些未填充的slot,以填充预期结果。值得注意的是,传统的做法是通过在预训练的特征提取器上附加一个新的线性层,使预训练的模型适应下游的分类任务,这与本文的做法相反。
- 本文做了两种提示:文本提示(textual prompt)和视觉提示(visual prompt)。
- 文本提示:
- 对于标签文本扩展具有重要意义。
- 给定一个标签
,然后通过填充函数
获得提示的文本输入
,其中
。
- 有三种类型的
:前缀提示(prefix prompt)、中间提示(cloze prompt)和后缀提示(suffix prompt),它们是根据填充位置进行分类的。
- 视觉提示:
- 设计主要取决于预训练模型。如果模型在视频文本数据上进行了预训练,则几乎不需要对视觉部分进行额外的重新格式化,因为模型已经训练为输出视频表示;而如果模型是用图像-文本数据预训练的,那么应该让模型学习视频的重要时间关系。
- 形式上,给定一个视频
,其中
是预训练模型的视觉编码网络。
- 类似地,
根据其工作位置分为三种变体:网络前提示(pre-network prompt)、网络内提示(in-network prompt)和网络后提示(post-network prompt)。
- 通过精心设计提示,甚至可以通过保持预训练模型的学习能力来避免上述无法达到的计算“预训练”步骤。
- 注意,由于新范式的灾难性遗忘,不能对预训练模型进行大量修改。
微调
- 当有足够的下游训练数据集时,对特定数据集进行微调无疑会显著提高性能。
- 如果提示(prompt)引入了额外的参数,则有必要对这些参数进行训练,并对整个框架进行端到端的学习。
新范式实例化细节
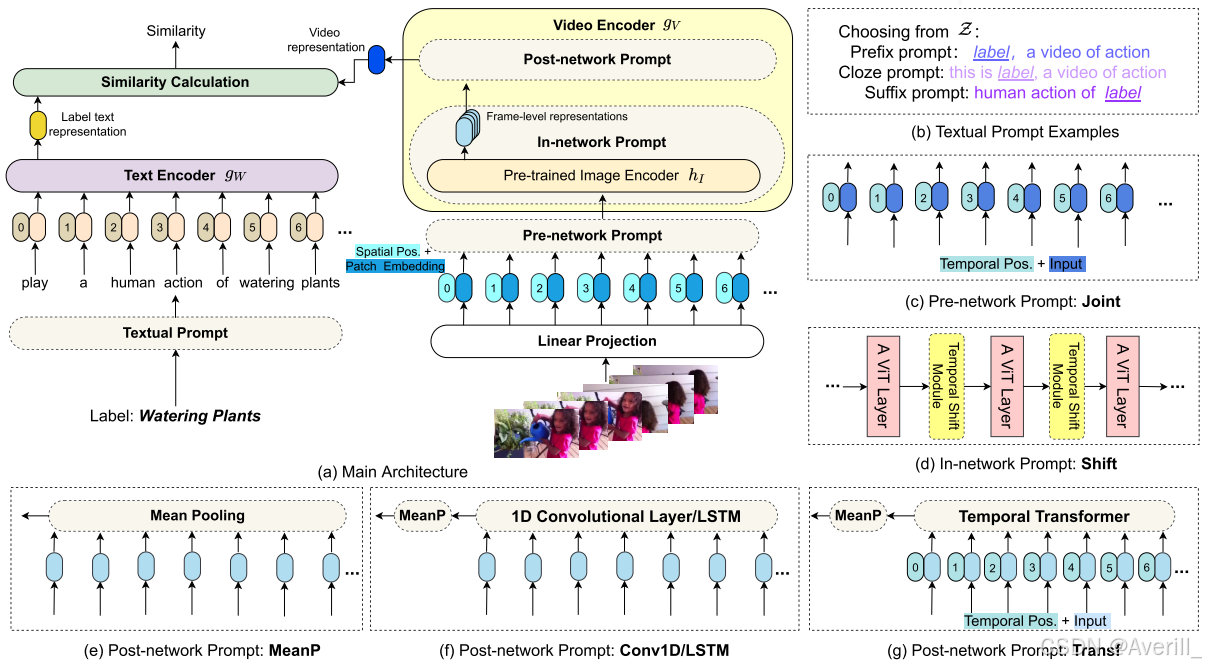
- 新范式的每个组成部分都有多种选择,上图是一个实例化示例,并使用该实例化进行了所有实验。
- 采用了预训练的模型CLIP,以避免在第一个预训练步骤中产生巨大的计算量,因此,此实例化模型称为ActionCLIP,如上图(a)所示。CLIP是一种通过MCL任务训练的高效图像文本表示,类似于本文的多模态学习框架。
- 上图(b)显示了实例化中使用的文本提示的具体示例。为了简单起见,将
个离散的人工定义的句子。然后,提示输入
被输入到语言编码器
中,这与预训练的语言模型
相同。
- 对于视觉模型,基于CLIP的预训练图像编码器
,采用了三种类型的视觉提示。
网络前提示
- 如上图(c)所示,该类型在送入编码器之前对输入进行操作。
- 给定一个视频
- 除了空间位置嵌入外,token嵌入将添加额外的可学习时间位置嵌入,以指示帧索引。
可以使用原始预训练图像编码
网络内提示
- 如上图(d)所示,这是一种无参数提示,简称为Shift。
- 引入了时间移位模块,该模块沿时间维度移动部分特征通道,并促进相邻输入帧之间的信息交换,在每两个相邻的
网络后提示
- 给定一个具有提取帧的视频
- 首先是空间编码器
,只负责对从同一时间索引中提取的token之间的交互进行建模,可以使用
- 提取的帧级表示为
,然后将其concat成
,然后送到时间编码器
,以模拟来自不同时间索引的token之间的交互。
- MeanP:时间维度上的平均池化。
- Conv1D:应用于时间维度上的1D卷积层。
- LSTM:递归神经网络。
- Transf:时间视觉Transformer编码器。
研究结论
消融实验
“多模式框架”有用吗?

- 上图展示了单模态和多模态训练框架的实验结果,可以看出,多模态框架显著提升性能。
“预训练”步骤重要吗?

- 上图展示了是否使用预训练的模型进行实验的结果。
“提示”步骤重要吗?
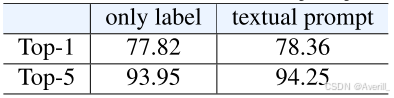
- 上图展示了是否使用提示的实验结果。
“微调”步骤重要吗?
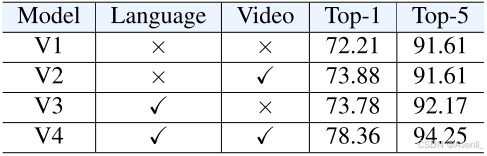
- 上图展示了不同模块是否进行微调的实验结果。
backbone和输入帧
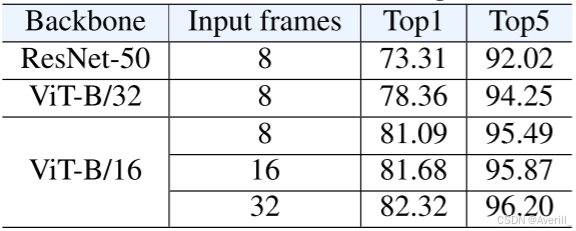
- 上图展示了不同backbone的实验结果。
运行时间分析
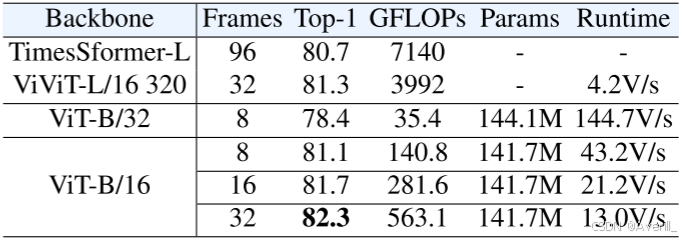
- 对于不同的backbone,上图展示了训练情况的分析。
zero-shot/few-shot识别
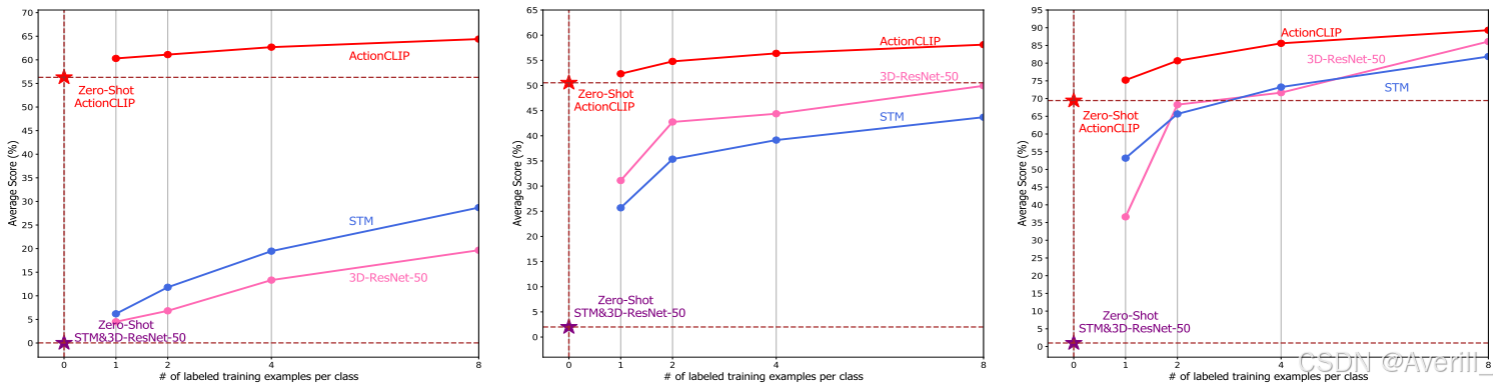
- 上图展示了不同数据集上本文方法的zero-shot结果。
与SOTA方法的比较
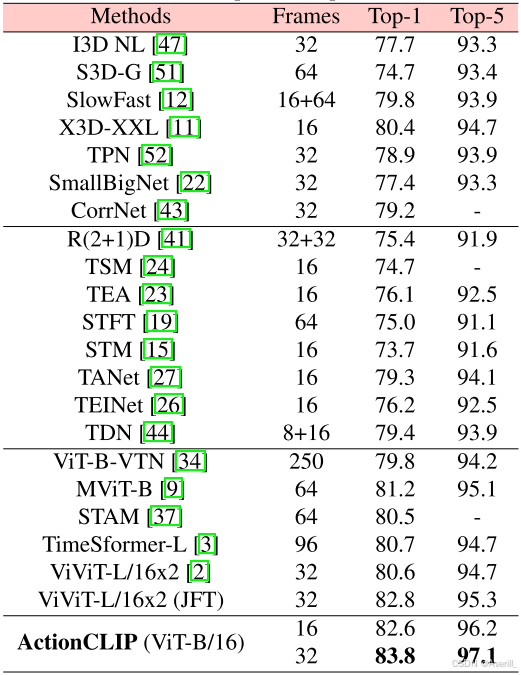
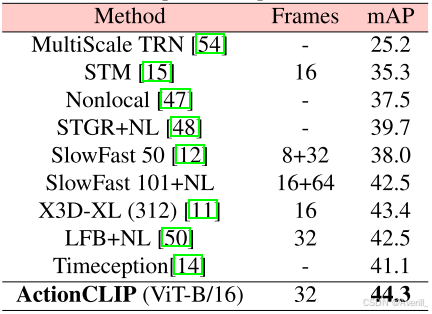
- 上图展示了不同数据集上本文方法和SOTA方法的对比结果。
存在的问题
- 表述上的问题:本文中的视觉prompt和文本prompt差异较大,视觉prompt实质上类似于adapter。
启发与思考
- 本文是对CLIP预训练模型的另一个直接应用,进一步证明了CLIP的迁移性。
- 本文详细介绍了框架设计中的几个常用技巧:预训练、提示和微调,灵活结合使用很有可能带来很好的效果。
- 写作:“消融实验”部分采用了“提问+回答”的写法,值得学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









