






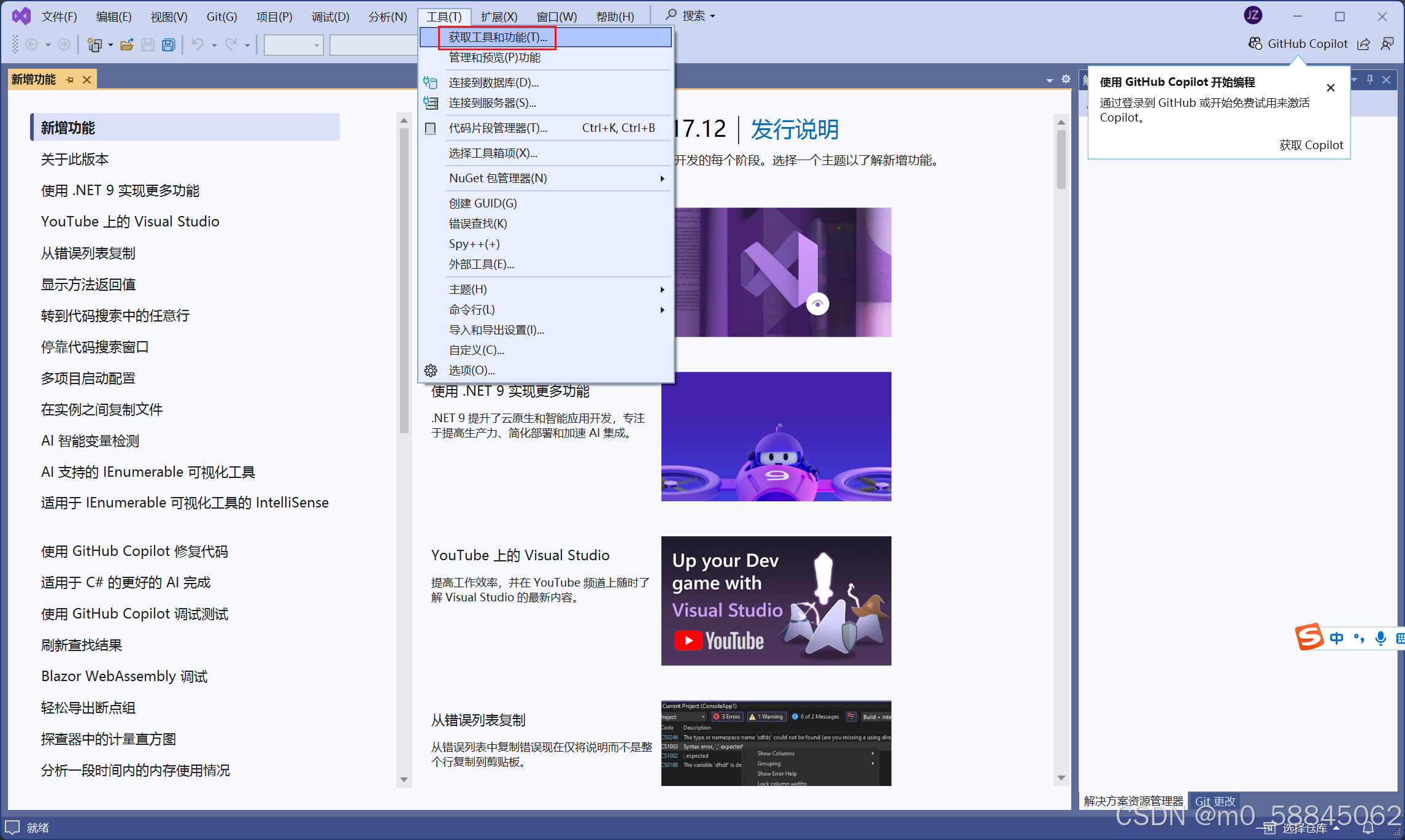
前期工作:下载pycharm、anaconda、visual studio,下载faster-RCNN代码(我用的是B站霹雳吧啦Wz大佬的代码,地址如下(直接点击没有找到项目的话,新开个网页复制这个网址进入,需要挂梯子):GitHub - WZMIAOMIAO/deep-learning-for-image-processing: deep learning for image processing including classification and object-detection etc.)
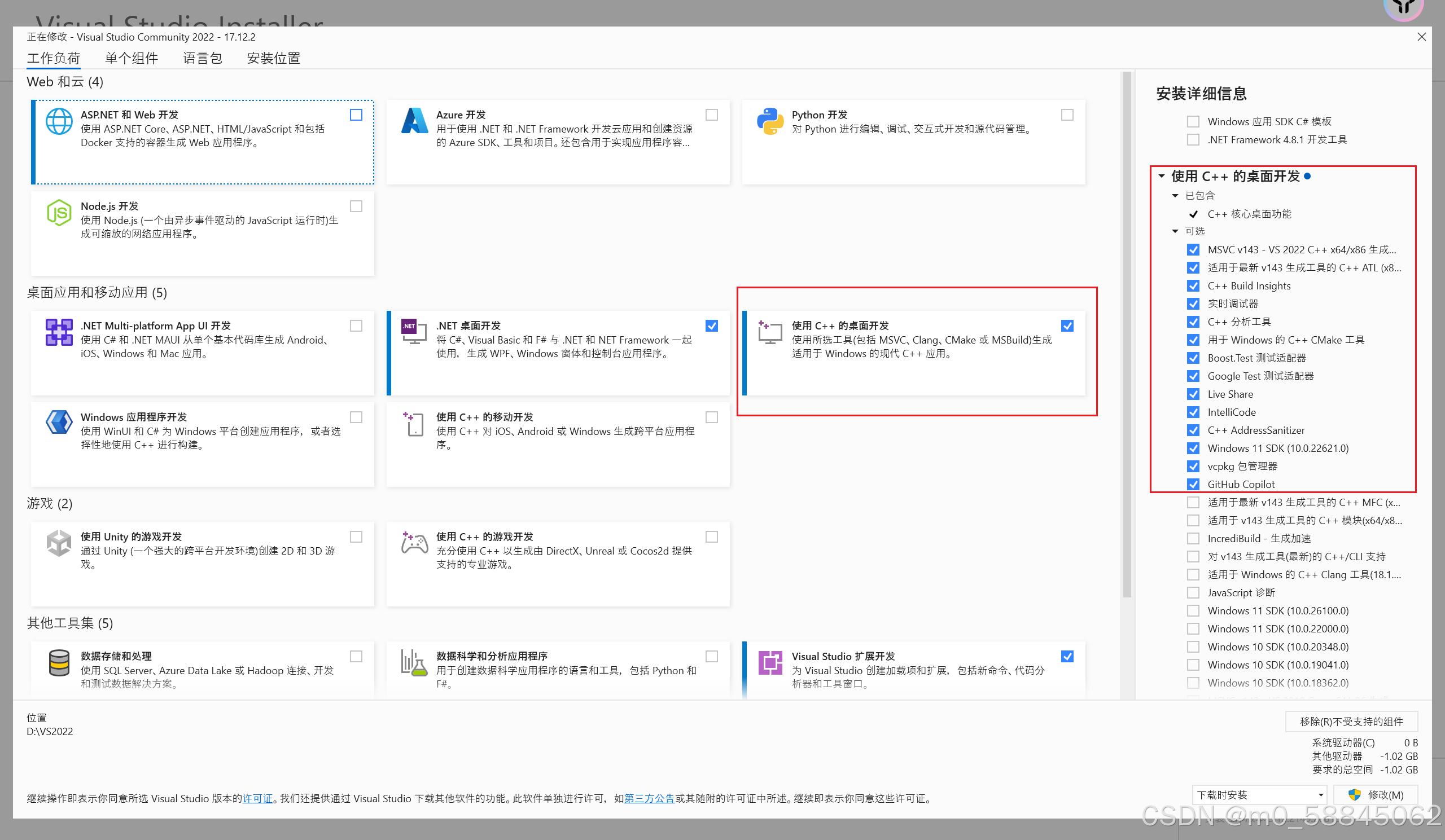
1.visual studio下载完要安装【使用C++的桌面开发】
如图3所示,按红框里的选。如果一开始没装,打开Visual Studio,按图1-图3红框依次点击,最后点图3右下角“修改”即可。

2.conda环境配置
打开这个: (在电脑搜索栏搜“Anaconda Promp”就行),
(在电脑搜索栏搜“Anaconda Promp”就行),
依次输入以下代码,注意此处的“fasterRCNN”是你给环境起的名字,可以自行更改。
conda create -n fasterRCNN python=3.8
activate fasterRCNNconda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch输入下面代码,成功最好,如果出错了 ,就不管了,你先跳过,后面出错了看本文第六章【6.各种错误如何解决】
pip install -r requirements.txt3.pycharm环境配置
进到项目中,点右下角红框处(我这里是已经配置好了,你显示的肯定不跟我一样),

点红框

这里按图片顺序点,注意第4个红框选的那个python.exe文件,是你创建的环境中的文件

4.训练数据集制作
我这里从图像打标开始,如果你已经有图像以及对应的xml文件,可以直接看4.3划分数据集
4.1安装labelimg
进入Anaconda Promp,依次输入以下代码:
activate fasterRCNN【下面这个代码2就安装的时候输就行了,安装完了之后每次启动labelimg只用输代码1和代码3】
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simplelabelimg就进入到labelimg里了
4.2打标
点A,选择要打标的图片所在的文件夹;点B,选择标签保存的文件夹。(可以选择同一个文件夹)

按“W”,你鼠标上出来一条十字线,然后框上你需要标的目标,输入标签名就行了。按“A”和“D”是切换上一张图、下一张图,切换图片后自动保存上一张标签。
全部打完看看标签格式是不是xml(就是右键点击文件——属性),如果是txt,要改成xml格式(写个脚本就能实现,之后我会把脚本放上来,如果我忘放了,留言或者私信一下)
【打标特别注意事项:
1.如果你发现一张图上没有需要标的目标,可以跳过,但是一定记得打完标把这张图删掉!
2.如果你在一张图上打了个标签,并且标签已经保存了,但又不想要这个标签了,把这个标签删掉后,删掉后本图片上没有其他目标了,那么你文件夹中会有一个对应的 空的 xml文件,一定记得把这个xml文件和对应的图片删掉!】
4.3划分数据集
在faster_rcnn文件夹下建立红框中的文件夹,最好名字一模一样,不然后面还要改代码,几个名字放在这里,空格别复制啊:VOCdevkit VOC2012 Annotations ImageSets JPEGImages Main

把你所有的图片放在上述JPEGImages文件夹中;xml文件放在Annotations文件夹中。
打开代码【split_data.py】(红框),看下路径(黄框)没问题,直接运行。
这个代码是将数据划分为训练集和验证集,原代码写的验证集比例是0.5(橘框),我这里改成0.2了,可以随便改。

在根目录(最外层目录)下会生成两个txt文件【train.txt】和【val.txt】,剪切两个文件,粘贴到你前面创建的ImageSets的Main文件夹下

打开文件【pascal_voc_classes.json】,改成你的标签,最后一个标签记得给后面的逗号删掉,把多余的空行也删掉。

5.开始训练!!!!!!!!!!!!
我用的gpu训练,打开【train_multi_GPU.py】(红框)这个文件,可以改下黄框里的内容,调整训练参数;204行的目标类别数也要改成你数据集的类别数;如果你路径和我的不一样,记得把图片中200行的路径也改了。运行!!!!

6.各种错误如何解决:
① The package for pytorch located at XXXXX appears to be corrupted
环境没安好,重新安一下
解决:进入Anaconda Prompt,依次输入:
activate fasterRCNNconda clean --packages问你Y/N就输Y,回车,下同
conda clean --allconda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch②RuntimeError: CUDA out of memory
解决:把batchsize调小
③ModuleNotFoundError: No module named XXX
解决:按红框顺序点,然后在下面输入pip install XXX
前面requirements.txt那没装好,就会出现好几个这个问题,出一个这个问题你就pip一个,直到不出这个错

④json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 colu
标签错啦
解决:打开根目录下的文件【pascal_voc_classes.json】,看看标签哪里有问题,打错字了、有多余空行、最后一个标签后面还有逗号......改就完了。
⑤AttributeError: 'Namespace' object has no attribute 'rank'
解决:train_multi_GPU.py文件最后一堆parser.add_argument最后加上以下代码
parser.add_argument('--rank', type=int, default=-1, help='The rank of the current process in distributed training')如图:
⑥训练出现一个警告:UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argume
解决:找到报错的地方,在括号里的最后加上:indexing = 'ij'
 即:torch.meshgrid(shifts_y, shifts_x,indexing = 'ij')
即:torch.meshgrid(shifts_y, shifts_x,indexing = 'ij')
⑦Loss is nan,stopping training
解决:可以先试试把batchsize调大,如果没用或者出现RuntimeError: CUDA out of memory问题,用以下方法:
打开【train_eval_utils.py】,把with torch.cuda.amp.autocast这行黄框代码注释了,记得把下面两行的缩进删除

【在整个项目中找某句代码小技巧:全局搜索】
全局搜索:

箭头处输入需要搜索的代码

⑧RuntimeError: CUDA error: device-side assert triggered
解决:把类别数(红框)改成你数据集的类别数

TXT转XML文件:
# 需要注意:
# 1.图像和标签文件(txt格式)放一起
# 注意:(因为使用cv2.imread读取图像,路径中不能有中文)
# 特别注意: 路径有中文也会导致图片和xml文件匹配不上,labelimg上不显示框
# 2.图像文件名和 txt 文件名一样(后缀不要改)
# 3.最后生成的 xml 跟 txt 和图像放在同一个文件里面
# 4.如果需要使用 labelimg 查看效果,建议把 xml 单独拿出来,并把标签路径指定到 xml 的保存路径
# 5.图片和标签需要一一对应
# 修改地:1.注意图片后缀,变的话所有牵扯后缀的地方都要改。(png格式的好像有问题)2.文件地址改这个file_dir
import time
import os
from PIL import Image
import cv2
import numpy as np
'''人为构造xml文件的格式'''
out0 = '''<annotation>
<folder>%(folder)s</folder>
<filename>%(name)s</filename>
<path>%(path)s</path>
<source>
<database>None</database>
</source>
<size>
<width>%(width)d</width>
<height>%(height)d</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
'''
out1 = ''' <object>
<name>%(class)s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>%(xmin)d</xmin>
<ymin>%(ymin)d</ymin>
<xmax>%(xmax)d</xmax>
<ymax>%(ymax)d</ymax>
</bndbox>
</object>
'''
out2 = '''</annotation>
'''
'''txt转xml函数'''
def translate(fdir, lists):
source = {}
label = {}
for jpg in lists:
print(jpg)
if jpg[-4:] == '.bmp':
image = cv2.imread(jpg) # 路径不能有中文
h, w, _ = image.shape # 图片大小
# cv2.imshow('1',image)
# cv2.waitKey(1000)
# cv2.destroyAllWindows()
fxml = jpg.replace('.bmp', '.xml')
fxml = open(fxml, 'w');
imgfile = jpg.split('/')[-1]
source['name'] = imgfile
source['path'] = jpg
source['folder'] = os.path.basename(fdir)
source['width'] = w
source['height'] = h
fxml.write(out0 % source)
txt = jpg.replace('.bmp', '.txt')
lines = np.loadtxt(txt) # 读入txt存为数组
# print(type(lines))
if len(np.array(lines).shape) == 1:
lines = [lines]
for box in lines:
# print(box.shape)
if box.shape != (5,):
box = lines
'''把txt上的第一列(类别)转成xml上的类别
我这里是labelimg标1、2、3,对应txt上面的0、1、2'''
classes=['scratch','breakage','bubble','neck_crack']
# label['class'] = str(int(box[0]) + 1) # 类别索引从1开始
label['class'] = classes[int(box[0])] # 类别索引从1开始
'''把txt上的数字(归一化)转成xml上框的坐标'''
xmin = float(box[1] - 0.5 * box[3]) * w
ymin = float(box[2] - 0.5 * box[4]) * h
xmax = float(xmin + box[3] * w)
ymax = float(ymin + box[4] * h)
label['xmin'] = xmin
label['ymin'] = ymin
label['xmax'] = xmax
label['ymax'] = ymax
# if label['xmin']>=w or label['ymin']>=h or label['xmax']>=w or label['ymax']>=h:
# continue
# if label['xmin']<0 or label['ymin']<0 or label['xmax']<0 or label['ymax']<0:
# continue
fxml.write(out1 % label)
fxml.write(out2)
if __name__ == '__main__':
file_dir = 'E:\\Code\\pyqt' #改这里,文件所在位置
lists = []
for i in os.listdir(file_dir):
if i[-3:] == 'bmp':
lists.append(file_dir + '/' + i)
# print(lists)
translate(file_dir, lists)
print('---------------Done!!!--------------')

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









