







String a = “”;
for (int i = 0; i < length; i++) {
a += i;
}
blackhole.consume(a);
}
@Benchmark
public void testStringBuilderAdd(Blackhole blackhole) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < length; i++) {
sb.append(i);
}
blackhole.consume(sb.toString());
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(StringConnectTest.class.getSimpleName())
.result(“result.json”)
.resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
}
其中需要测试的方法用 @Benchmark 注解标识,这些注解的具体含义将在下面介绍。最新面试题整理好了,点击Java面试库小程序在线刷题。
在 main() 函数中,首先对测试用例进行配置,使用 Builder 模式配置测试,将配置参数存入 Options 对象,并使用 Options 对象构造 Runner 启动测试。
另外大家可以看下官方提供的 jmh 示例 demo:http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/
执行基准测试
准备工作做好了,接下来,运行代码,等待片刻,测试结果就出来了,下面对结果做下简单说明:
JMH version: 1.23
VM version: JDK 1.8.0_201, Java HotSpot™ 64-Bit Server VM, 25.201-b09
VM invoker: D:\Software\Java\jdk1.8.0_201\jre\bin\java.exe
VM options: -javaagent:D:\Software\JetBrains\IntelliJ IDEA 2019.1.3\lib\idea_rt.jar=61018:D:\Software\JetBrains\IntelliJ IDEA 2019.1.3\bin -Dfile.encoding=UTF-8
Warmup: 3 iterations, 1 s each
Measurement: 5 iterations, 5 s each
Timeout: 10 min per iteration
Threads: 4 threads, will synchronize iterations
Benchmark mode: Average time, time/op
Benchmark: com.wupx.jmh.StringConnectTest.testStringBuilderAdd
Parameters: (length = 100)
该部分为测试的基本信息,比如使用的 Java 路径,预热代码的迭代次数,测量代码的迭代次数,使用的线程数量,测试的统计单位等。
Warmup Iteration 1: 1083.569 ±(99.9%) 393.884 ns/op
Warmup Iteration 2: 864.685 ±(99.9%) 174.120 ns/op
Warmup Iteration 3: 798.310 ±(99.9%) 121.161 ns/op
该部分为每一次热身中的性能指标,预热测试不会作为最终的统计结果。预热的目的是让 JVM 对被测代码进行足够多的优化,比如,在预热后,被测代码应该得到了充分的 JIT 编译和优化。
Iteration 1: 810.667 ±(99.9%) 51.505 ns/op
Iteration 2: 807.861 ±(99.9%) 13.163 ns/op
Iteration 3: 851.421 ±(99.9%) 33.564 ns/op
Iteration 4: 805.675 ±(99.9%) 33.038 ns/op
Iteration 5: 821.020 ±(99.9%) 66.943 ns/op
Result “com.wupx.jmh.StringConnectTest.testStringBuilderAdd”:
819.329 ±(99.9%) 72.698 ns/op [Average]
(min, avg, max) = (805.675, 819.329, 851.421), stdev = 18.879
CI (99.9%): [746.631, 892.027] (assumes normal distribution)
Benchmark (length) Mode Cnt Score Error Units
StringConnectTest.testStringBuilderAdd 100 avgt 5 819.329 ± 72.698 ns/op
该部分显示测量迭代的情况,每一次迭代都显示了当前的执行速率,即一个操作所花费的时间。在进行 5 次迭代后,进行统计,在本例中,length 为 100 的情况下 testStringBuilderAdd 方法的平均执行花费时间为 819.329 ns,误差为 72.698 ns。
最后的测试结果如下所示:
Benchmark (length) Mode Cnt Score Error Units
StringConnectTest.testStringAdd 10 avgt 5 161.496 ± 17.097 ns/op
StringConnectTest.testStringAdd 50 avgt 5 1854.657 ± 227.902 ns/op
StringConnectTest.testStringAdd 100 avgt 5 6490.062 ± 327.626 ns/op
StringConnectTest.testStringBuilderAdd 10 avgt 5 68.769 ± 4.460 ns/op
StringConnectTest.testStringBuilderAdd 50 avgt 5 413.021 ± 30.950 ns/op
StringConnectTest.testStringBuilderAdd 100 avgt 5 819.329 ± 72.698 ns/op
结果表明,在拼接字符次数越多的情况下,StringBuilder.append() 的性能就更好。
生成 jar 包执行
对于一些小测试,直接用上面的方式写一个 main 函数手动执行就好了。
对于大型的测试,需要测试的时间比较久、线程数比较多,加上测试的服务器需要,一般要放在 Linux 服务器里去执行。
JMH 官方提供了生成 jar 包的方式来执行,我们需要在 maven 里增加一个 plugin,具体配置如下:
org.apache.maven.plugins
maven-shade-plugin
2.4.1
package
shade
jmh-demo
<transformer
implementation=“org.apache.maven.plugins.shade.resource.ManifestResourceTransformer”>
org.openjdk.jmh.Main
接着执行 maven 的命令生成可执行 jar 包并执行:
mvn clean install
java -jar target/jmh-demo.jar StringConnectTest
JMH 基础
为了能够更好地使用 JMH 的各项功能,下面对 JMH 的基本概念进行讲解:
@BenchmarkMode
用来配置 Mode 选项,可用于类或者方法上,这个注解的 value 是一个数组,可以把几种 Mode 集合在一起执行,如:@BenchmarkMode({Mode.SampleTime, Mode.AverageTime}),还可以设置为 Mode.All,即全部执行一遍。
-
Throughput:整体吞吐量,每秒执行了多少次调用,单位为
ops/time -
AverageTime:用的平均时间,每次操作的平均时间,单位为
time/op -
SampleTime:随机取样,最后输出取样结果的分布
-
SingleShotTime:只运行一次,往往同时把 Warmup 次数设为 0,用于测试冷启动时的性能
-
All:上面的所有模式都执行一次
点击关注公众号,Java干货****及时送达
@State
通过 State 可以指定一个对象的作用范围,JMH 根据 scope 来进行实例化和共享操作。@State 可以被继承使用,如果父类定义了该注解,子类则无需定义。由于 JMH 允许多线程同时执行测试,不同的选项含义如下:
-
Scope.Benchmark:所有测试线程共享一个实例,测试有状态实例在多线程共享下的性能
-
Scope.Group:同一个线程在同一个 group 里共享实例
-
Scope.Thread:默认的 State,每个测试线程分配一个实例
@OutputTimeUnit
为统计结果的时间单位,可用于类或者方法注解
@Warmup
预热所需要配置的一些基本测试参数,可用于类或者方法上。一般前几次进行程序测试的时候都会比较慢,所以要让程序进行几轮预热,保证测试的准确性。参数如下所示:
-
iterations:预热的次数
-
time:每次预热的时间
-
timeUnit:时间的单位,默认秒
-
batchSize:批处理大小,每次操作调用几次方法
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

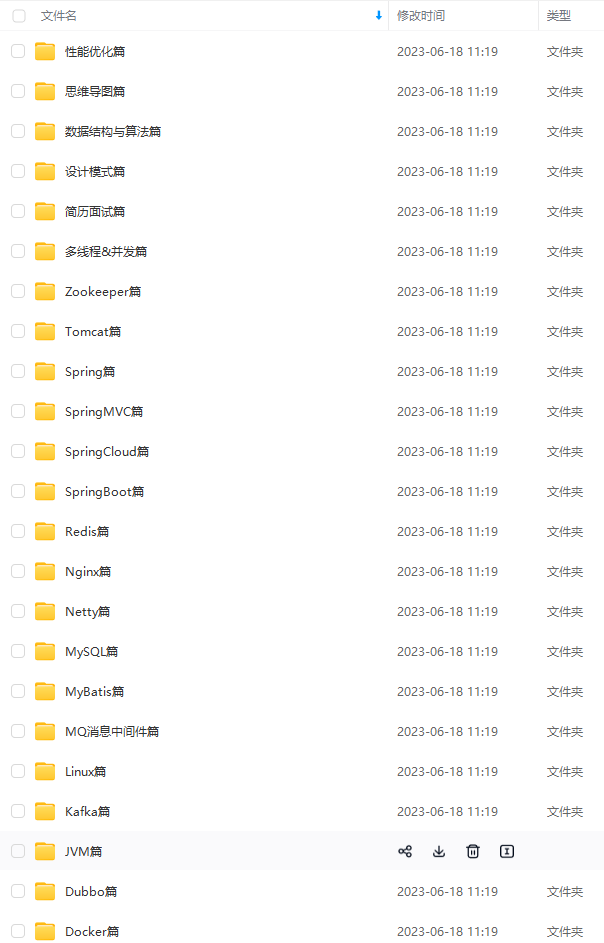
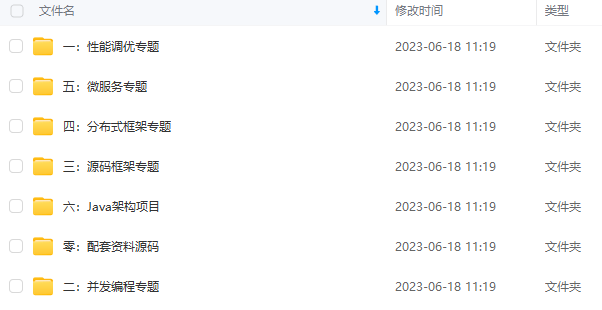

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!

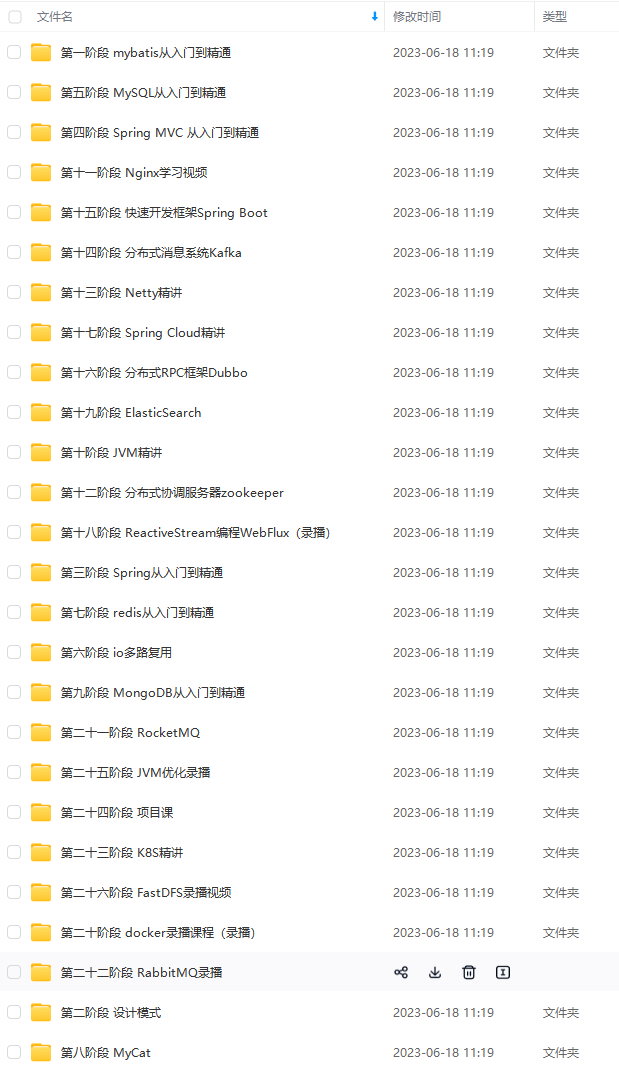
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V:vip1024b 备注Java获取(资料价值较高,非无偿)

总结:绘上一张Kakfa架构思维大纲脑图(xmind)

其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)


,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)
[外链图片转存中…(img-kOyf0oeZ-1711552324057)]
[外链图片转存中…(img-QQ6kFqxU-1711552324058)]















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









