






本次任务是通过url下载文件到本地,可是地址里并不存在文件名,比如:http://localhost:8888/user-link?fid=18f75071bd315a88sa4b4bbd7d3
因此我需要通过其他方式获取文件名,即通过Header的Content-Disposition,样例如下:
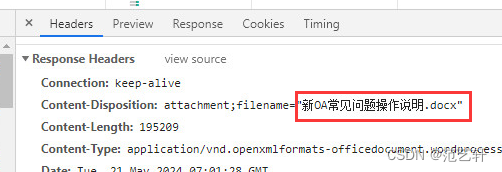
可是获取时总会有乱码,
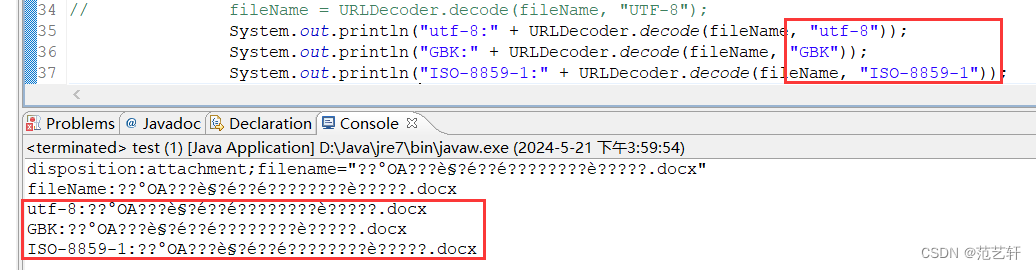
在看了别人编码的操作后,我们决定反向操作,即:对于IE的浏览器,他转UTF-8,我们就UTF-8转回来;对于其他浏览器,他先转UTF-8,后转ISO-8859-1,那我们就先转ISO-8859-1,后转UTF-8
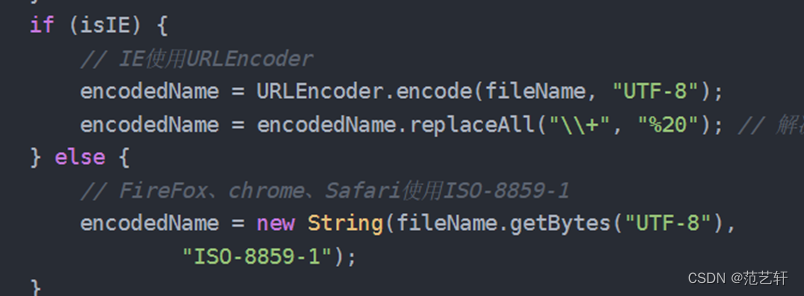

完整代码如下:
public File downloadUrlFile(String urlPath, String destDirectory) throws IOException {
File destFile = null;
String fileName = null;
FileOutputStream fos = null;
InputStream is = null;
try {
URL url = new URL(urlPath);
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
String disposition = conn.getHeaderField("Content-Disposition");
if (disposition != null) {
// 解析Content-Disposition信息
int index = disposition.indexOf("filename=");
System.out.println("disposition:" + disposition);
if (index > 0) {
// 提取文件名
fileName = disposition.substring(index + 9);
// 移除双引号
if (fileName.startsWith("\"") && fileName.endsWith("\"")) {
fileName = fileName.substring(1, fileName.length() - 1);
}
fileName = new String(fileName.getBytes("ISO-8859-1"), "UTF-8");
System.out.println("fileName:" + fileName);
}
} else {
// 如果没有Content-Disposition头部信息,则直接保存文件(文件名可能会是乱码)
fileName = "file.pdf";
}
// 下载文件并保存到本地
is = conn.getInputStream();
String destFilePath = destDirectory + File.separator + fileName;
destFile = new File(destFilePath);
fos = new FileOutputStream(destFile, false);
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
throw new IOException(e);
} finally {
if(fos != null) {
fos.close();
}
if(is != null) {
is.close();
}
}
return destFile;
}孩子们,这并不好笑















 2418
2418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









