






我在启动Hadoop集群的时候发现没有DataNode节点,于是我去查看了一下日志(日志在自己的hadoop目录下):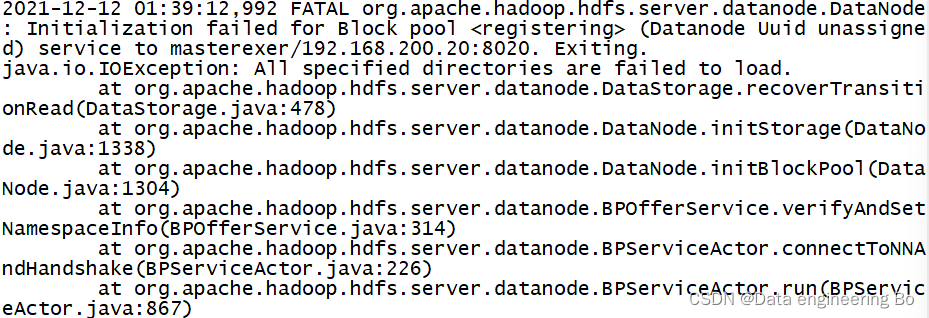
发现是java.io.IOException:All specified directories are failed to load
原因可能是我之前格式化了几次导致namenode和DataNodeID不匹配造成的
解决方法:
首先关闭集群
①可以找到自己的/tmp/dfs这个路径下的一个VERSION文件,在子节点里面修改成和主节点一样的。
②把这个/tmp/dfs的文件和日志删掉,然后重新格式化一下namenode:hdfs namenode -format然后就没问题了
重新启动集群
各个子节点的DataNode就出来了

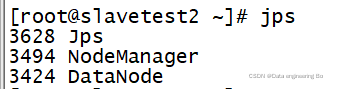
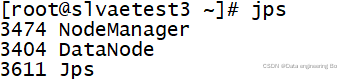
个人更倾向于第二种方法,简单易做还能一下解决问题。

















 6528
6528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









