一、什么是ElasticSearch
1.1简介
ElasticSearch(以下简称ES)是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。也可以使用Java开发并使用Lucene作为其核心实现所有的索引和CRUD功能,可以通过简单的RestFul API来降低Lucene的复杂性,让全文检索变得更加简单。ES主要解决的问题是1)检索相关数据;2)返回统计结果;3)速度要快。
1.2ES核心概念
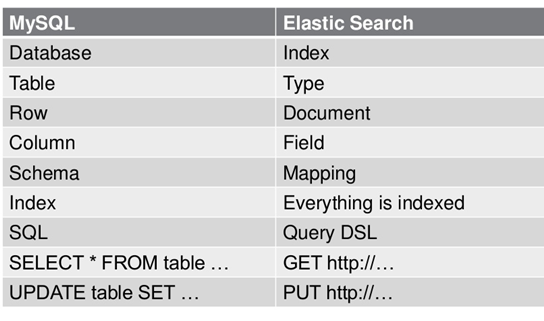
①index(索引):我们使用ES的根本目的是想把大量的数据存进去,然后再通过条件查询高效的取出我们所需要的数据然后满足业务需求。ES的功能就很像一个关系型的数据库比如mysql,而ES的index和数据库中的index不同,它相当于database。
②type(类型):type是用来定义数据结构的,在每一个index下面,可以有一个或者多个type,好比数据库里面的table,相当于表结构的描述,描述每个字段的类型。
③document(文档):document就是最终的数据,一个document就是一条记录。
④field(字段):一个document有一个或者多个field组成,field相当于一个字段
⑤shard(分页):一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
⑥replica(副本):一个分布式的集群,在实际运行的时候,难免会有一台或者多台服务器宕机,如果没有replica的概念,就会造成shard发成故障,无法提供正常的服务。在ES集群中,我们一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)。
⑦Node(节点):就是集群中的一台服务器
⑧cluster(集群):ES是一个分布式的系统,在ES里面默认有一个配置,clustername 默认值就是ElasticSearch,如果这个值是一样的就属于同一个集群,不一样的值就是不一样的集群。
下图是ES与Mysql数据库的对照,方便理解ES的基本概念。
二、ElasticSearch的安装
1.docker镜像下载
docker pull elasticsearch
:
5.6.8
2.安装es容器
docker run -id --name
= qyl
_es -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e"discovery.type=single-node"
-p 9200
:
9200 -p 9300
:
9300 elasticsearch
:
5.6.8
(这里不加-e的环境变量可能会让docker容器内存不足而导致)
参数说明:
--name表示镜像启动后的容器名称
-d: 后台运行容器,并返回容器ID;
-e: 指定容器内的环境变量
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
启动成功后截图:

安装完成之后,es并不能正常使用,ES从5版本以后默认不开启远程连接,我们需要修改es的配置开启远程连接。
登录容器
docker exec -it qyl_es /bin/bash
查看目录结构
root@07f22eb41bb5
:
/usr/share/elasticsearch# ls
显示的目录
NOTICE.txt README.textile bin config data lib logs modules plugins
进入config目录
cd config
修改
elasticsearch.yml
⽂件
root@07f22eb41bb5
:
/usr/share/elasticsearch/config# vi elasticsearch.yml
bash
:
vi
:
command not found
vi
命令⽆法识别,因为
docker
容器⾥⾯没有该命令,我们可以安装该编辑器。
安装vim编辑器
apt-get update
apt-get install vim
安装完了之后
修改
elasticsearch.yml
配置
vi elasticsearch.yml
将transport.host :0.0.0.0之前的#去掉,放开端口
同时添加一行代码:
cluster.name
:
my-elasticsearch
重启docker
docker restart qyl_es
参数配置
修改vi/etc/sysctl.conf,追加内容
vm.max_map_count
=
655360
执行下面内容 修改内核参数马上生效
sysctl -p
重启虚拟机
reboot
跨域配置
修改
elasticsearch/config
下的配置⽂件:
elasticsearch.yml
,增加以下三句命令,并重启
:
http.cors.enabled
:
true
http.cors.allow-origin
:
"*"
network.host
:
192.168.220.100
重启
docker restart qyl_es
三、ElasticSearch的客户端操作
实际开发中,主要有三种⽅式可以作为
elasticsearch
服务的客户端:
第⼀种,elasticsearch-head
插件
第⼆种,使⽤elasticsearch
提供的
Restful
直接访问
第三种,使⽤elasticsearch
提供的
API
进⾏访问
四、IK分词器安装
IKAnalyzer
是⼀个开源的,基于
java
语⾔开发的轻量级的中⽂分词⼯具包。从
2006
年
12
⽉推出
1.0
版开 始,IKAnalyzer
已经推出 了
3
个⼤版本。最初,它是以开源项⽬
Lucene
为应⽤主体的,结合词典分词和 ⽂法分析算法的中⽂分词组件。新版本的IKAnalyzer3.0
则发展为 ⾯向
Java
的公⽤分词组件,独⽴于 Lucene项⽬,同时提供了对
Lucene
的默认优化实现。
IK
分词器
3.0
的特性如下:
{
"query"
: {
"term"
: {
"title"
:
"
搜索
"
}
}
}
1
)采⽤了特有的
“
正向迭代最细粒度切分算法
“
,具有
60
万字
/
秒的⾼速处理能⼒。
2
)采⽤了多⼦处理器分析模式,⽀持:英⽂字母(
IP
地址、
Email
、
URL
)、数字(⽇期,常⽤中⽂数量词,罗马数字,科学计数法),中⽂词汇(姓名、地名处理)等分词处理。
3
)对中英联合⽀持不是很好
,
在这⽅⾯的处理⽐较⿇烦
.
需再做⼀次查询
,
同时是⽀持个⼈词条的优化的词典存储,更⼩的内存占⽤。
4
)⽀持⽤户词典扩展定义。
5
)针对
Lucene
全⽂检索优化的查询分析器
IKQueryParser
;采⽤歧义分析算法优化查询关键字的搜索排列组合,能极⼤的提⾼Lucene
检索的命中率。
注意:分词器的版本必须和ES的版本一致,我是5.6.8版本的ES就装5.6.8版本的分词器
IK分词器下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
将下载完的ik分词器上传到服务器上,然后解压,并改名字为ik方便后续操作
unzip elasticsearch-analysis-ik-5.6.8.zip
mv elasticsearch ik
将
ik
⽬录拷贝到
docker
容器的
plugins
⽬录下
docker cp ./ik qyl_es
:
/usr/share/elasticsearch/plugins
重启
docker restart qyl_es






















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









