






C++:
1,C和C++区别
(1)C语言是面向过程的程序设计,主要核心为数据结构和算法。C++是面向对象的程序设计
(2)C++包含C语言所有库
(3)C++比C语言变量检测增强
2,C++三大特性
(1)封装:封装隐藏了类的实现细节和成员数据,属性私有化,行为公有化。
(2)继承:子类可以复用父类的方法和成员,实现了代码的复用,提高编码效率
(3)多态:一个接口,多种方法。
3,多态
多态分为静态多态和动态多态 静态多态由函数重载和模板实现 动态多态由虚函数实现。
一个类中如果有虚函数的话,其类中也有一张虚函数表(虚函数表类似一个指针数组,其中存放着虚函数的地址 虚函数表中有一个虚函数表指针 如果其中虚函数被调用的话 这个虚函数表指针就会指向被调用的虚函数,以此来实现动态的调用)。ps:虚函数表是属于类的,一个类中的所用对象共用一张虚函数表。
如果一个子类继承了父类,并且父类中有虚函数的话,那么子类也可调用这些虚函数。如果子类重写父类的虚函数(子类也会有一张属于自己的虚函数表),就将虚函数表中相应的函数指针设置为子类的函数地址,否则指向基类的函数地址。
4,指针与引用的区别
指针可以不用初始化,引用一定要先初始化
指针可以赋值为NULL,引用必须与合法的存储的单元相关联
指针可以有多级,引用只有一级
指针是间接访问,引用是直接访问(存储的内容为一个地址,给一个已有对象起的别名)
5,将引用作为参数传递有哪些特点?(引用传递与值传递区别)
传递引用和函数与传递指针的效果是一样的。使用引用传递函数的参数,在内存中并没有产生实参的副本,是直接对实参操作。而使用一般变量传递函数的参数,当产生函数调用时,需要给形参分配存储单元,形参变量是实参变量的副本。如果传递的数据较大时,用引用比用一般变量传递参数的效率更好,如果不想改变主调函数中实参可以在传递引用参数时前面加const来限制参数只读。
6,this指针
this指针是存在于类成员函数中(静态成员函数没有this指针),指向类对象的指针,this是一个常量指针。
成员函数调用时,传递了一个隐含的参数,指向了函数所在类对象的地址。
7,常量指针和指针常量
指针常量-指针类型的常量 本质上一个常量,指针用来说明常量的类型,表示该常量是一个指针类型的常量。在指针常量中,指针自身的值是一个常量,不可改变,始终指向同一个地址。
常量指针-指向常量的指针 本质上是一个指针,常量表示指针指向的内容,说明该指针指向一个常量。在常量指针中,指针指向的内容是不可改变的。
(看到了一个写的比较易懂的解释:中文翻译太搞了,我是想不明白为什么起两个这么容易混淆的名字。我总结一下,区别就是 const pointer,指针本身是一个常量,指向的地址不能改变,里面的内容可以修改。(门牌号11,不管里面住谁,我指向的都是这条街11号) pointer to const,指向的内容是一个常量,可以改变指向的地址,只要新地址里面也是常量就好。(原来是幽灵街11号,现在改为12号也可以,因为都是幽灵,都是不变的常量) 当然如果单纯为了区别两个中文,那么const=常量,*=指针,看谁在谁前面就叫对应的名字。)
8,局部变量能否和全局变量重名?
能,局部会覆盖全局
9,联合与结构体的区别
结构体和联合都是由多个不同的数据类型成员组成的,但在同一时刻,联合中只存放一个被选中的成员(所有成员共用一块地址空间),而结构体中的所有成员都存在(不同成员的存放地址不同)。联合中对不同成员赋值会对其他成员重写,而结构体中不同成员赋值互不影响。
10,#include< >和 #include" "的区别
<>是从标准库路径中寻找文件," "是从当前工作路径搜索文件
11,struct和class的区别
struct的默认属性共有,class的默认属性私有 其余地方无不同
12,如何防止头文件被重复包含
#ifndef #define #endif C++还提供了#pragma once
13,C++源文件从文本到可执行文件经历的过程
预处理-编译-汇编-链接
预处理:删除注释,替换宏 处理条件编译
编译:将预处理后的文件进行词法、语法分析 生成汇编文件
汇编:将汇编文件转成机器能执行的代码
链接:地址和空间分配,符号决议
14,堆栈溢出的原因
没有回收垃圾资源
层次太深的递归调用
15,C++内存管理
C++中内存分为五个区:堆区,栈区,全局/静态区,常量区,代码区
栈区:一般局部变量在栈上创建,等脱离了作用域会被编译器自动释放,栈是系统提供的数据结构,有着先进后出的特性,计算机在底层对栈提供支持 所以栈的效率比较高 但是栈区的内存较小在windows下大概默认是1M?可以手动修改
堆区:由编写者控制的一块区域,空间较大 但效率没有栈高 而且频繁的创建和销毁会产生内存碎片, C++中用new分配,delete释放。C中用malloc分配,free释放。
全局/静态区,在程序整个运行阶段一直存在,全局变量和静态变量
常量区:存放的是常量字符串不允许修改
代码区:存放程序的二进制代码
16,堆和栈的区别
堆区的空间是手动分配申请/释放,栈区空间由编译器自动申请/释放,栈区空间有限,堆区是一个很大的内存空间。 栈区效率比堆区高。 堆的生长空间向上,栈的生长空间向下。
17,内存泄漏
动态申请(new/malloc申请)的内存空间没有被正常释放,但也不能继续使用的情况。
18,野指针
指向被释放的内存或访问受限的指针
野指针原因:
指针未被初始化
被释放的指针没有被置为NULL
指针越界操作
19,既然有了malloc/free为什么什么还要new/delete?
在对非基本数据类型的对象使用的时候,对象创建的时候还需要执行构造函数,销毁的时候执行析构函数,而malloc/free是库函数,是已经编译的代码,不能把构造函数和析构函数的功能强加给malloc/free。
20,new和malloc的区别
new为关键字,malloc为库函数,需要头文件支持
使用new申请内存无需指定内存大小,编译器会自行计算,而malloc需要指定所申请内存的大小
new分配成功返回的是对象类型指针,与对象严格匹配,无需类型转换,而malloc默认返回void*如需别的类型需要自己显示转换
new分配失败抛出bad_alloc异常,malloc分配失败返回NULL
new可以重载,malloc不可以
21,前置++和后置++的区别
前置++的实现比较高效自增之后将返回this指针,而后置++是返回自增前的对象,所以需要先将对象拷贝一份 然后在自增,最后返回拷贝的对象
22,程序崩溃原因
读取为赋值的变量
堆栈溢出
数组越界访问
指针的目标对象不可用
23,如何创建一个类,使得它只能在堆上或者栈上创建?
只能在堆上生成对象:将析构函数设置为私有
原因:C++是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问属性,若析构函数不可访问则不能在栈上创建对象。
只能在栈上创建对象:将new和delete重载为私有
原因:在堆上生成对象,使用new关键词操作,其过程分为两阶段:第一阶段,使用new在堆上寻找可用内存分配给对象。第二阶段,调用构造函数生成对象,将new重载为私有 那么第一阶段无法完成 就不能在堆上创建对象。
24,成员初始化列表
成员初始化列表就是在类或者结构体的构造函数中,在参数列表后以冒号开头,逗号进行分割的一系列初始化字段。ps:(初始化顺序跟成员变量创建顺序相关,如果顺序不对有的编译器会报错) 看书的时候好像是这么说的 但是我试了一下并没有报错 不知道是我记错了还是什么原因
class A
{
int a;
string b;
double c;
A(int _a,string _b,double _c) : a(_a) , b(_b) , c(_c) {}
};25,为什么用成员初始化列表会快一些
因为使用成员初始化列表进行初始化的话,会直接使用传入参数的拷贝构造函数进行初始化,省去了一次执行传入参数的默认构造函数的过程,否则会调用一次传入参数的默认构造函数。还有几种情况是必须使用成员初始化列表进行初始化的:常量成员(因为只能初始化不能赋值),引用类型,没有默认构造函数的对象。
26,构造函数
(函数名与类名相同,无返回值,创建类对象时编译器自动调用且在对象的声明周期内只调用一次)
当类没有实现自己的构造函数时,编译器会默认提供一个构造函数(默认构造函数)
一个类可以有多个重载构造函数,但需要参数类型或个数不同
27,析构函数
析构函数不可以重载,一个类只能有一个析构函数
析构函数不能有参数
当类没有实现自己的析构函数时,编译器会默认提供一个析构函数(和构造一样)
当对象生命周期结束时,C++编译系统会自动调用析构函数
28,什么情况下调用拷贝构造函数
对象以值传递的方式传入函数参数
对象以值传递的方式从函数返回
对象需要通过另一个对象进行初始化
29,拷贝构造函数为什么传引用
参数为引用,不为值传递是为了防止拷贝构造函数无限递归 最终导致栈溢出 这也是比编译器的强制要求。
30,深拷贝和浅拷贝的区别
浅拷贝就是将对象的指针进行简单的复制,原对象和副本指向的是相同的资源
深拷贝是开辟一块新的空间 将原对象的资源复制到新的空间中,并返回该空间的地址
深拷贝可以避免重复释放,例如使用浅拷贝的对象进行释放后,再对原对象的释放会导致一块空间被释放两次,产生段错误引起程序崩溃
31,重载、重写、隐藏
函数的重载是在一个作用域内,只有参数类型或参数个数不同。与返回值类型无关
重写是子类中重新定义的函数,其函数名,返回值类型,参数列表都和父类函数相同,并且父类的函数前面加了virtual关键字。
隐藏是指子类的函数屏蔽了与其同名的父类函数,只要同名不管参数列表是否一致,父类函数都会被隐藏。(参数列表不同,不管有无virtual关键字都是隐藏,参数列表相同,无virtual关键字,也是隐藏)
32,父类中的析构函数写成虚函数的原因
析构和构造函数都可以声明成虚函数,编译器不会报错。当析构一个指向子类的父类指针时,编译器可以根据虚函数表寻找到子类的析构进行调用,从而正确释放子类对象的资源。如果析构函数不生明成虚函数 在删除指向子类的父类指针时,只会调用父类的析构函数而不调用子类的析构函数,这样子类的对象就没有正确的释放,造成内存泄漏。
33,vector
vector的底层数据结构是数组,可以进行自动扩容(每次容量不够时会申请一块大小为原来容量二倍的内存,将原容器的元素拷贝到新容器中,并释放原空间,返回新空间的指针)如果频繁的扩容还是比较消耗性能的
34,vector和list的区别
vector拥有一块连续的空间,所以一些增删操作很麻烦,会造成内存块的拷贝,时间复杂度是O(n)但查询时间复杂度相对来说好一些 通过下标进行查询时 时间复杂度是O(1)
list是由双向链表实现的,内存空间是不连续的,只能通过指针访问数据,所以list的查询时间复杂度是O(n) 但由于链表的特点,能高效的插入和删除。
35,静态绑定与动态绑定
静态类型:对象在声明时采用的类型,在编译期确定
动态类型:通常是指一个指针或引用目前所指对象的类型,在运行期确定
静态绑定:绑定的是静态类型,所对应的函数或属性依赖于对象的静态类型,发生在编译期
动态绑定:绑定的是动态类型,所对应的函数或属性依赖于对象的动态类型,发生在运行期
36,unordered_map和map的区别
unordered_map是使用哈希表实现的,占用内存较多,查询速度较快O(1)
map底层是红黑树实现的(有自动排序的特性),插入删除查询时间复杂度都是O(long(n))
37,解决哈希冲突方法
开放地址法:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pn,将相应元素存入其中
开链法:为哈希码对应生成一个链表,插入元素时,如果哈希码冲突了,就将元素插入到链表(像在通讯录寻找联系人)
再哈希法:如果第一个哈希函数计算的哈希码发生冲突了,就采用第二个哈希函数重新计算哈希码,直到不冲突为止
公共地址法:在创建哈希表的同时,再额外创建一个公共溢出区,专门用来存放发生哈希冲突的元素。查找时,先从哈希表查,查不到再去公共溢出区查。
38,sort采用了什么排序
数据量大时采用快排,分段递归排序,一旦分段后的数量小于某个门槛 为避免快排的递归调用带来过大的额外负荷 就该用插入排序,如果递归层次过深 还会使用堆排 ---《STL源码剖析》
操作系统:
1,进程和线程的区别
进程是对运行时程序的封装,进程是最基本的分配资源单位,线程是最基本的执行单位
创建线程花销较大,创建线程花销较小
多进程比多线程更加稳定
进程拥有自己独立的空间地址,而同一进程下的所有线程共享进程的地址空间,全局变量,堆区(栈区不共享)
进程最少有一个线程,程序启动的时候会默认开启一个线程,这个线程被称为主线程
一个进程可以有多个线程
2,进程间通信方式
管道,信号,信号量,消息队列,共享内存,套接字
3,操作系统的内存管理
物理内存管理包括交换与覆盖,分页管理,分段管理和段页式管理等
虚拟内存管理包括细腻内存的概念,页面置换算法,页面分配策略等
4,死锁产生的必要条件
互斥:一个资源每次只能被一个进程使用
占有并请求:一个进程因请求资源而阻塞时,对已获得的资源保持不放
不可剥夺:进程已获得的资源,在未使用之前不能强行剥夺
循环等待:若干进程之间形成一种头尾相接的循环等待资源关系
5,僵尸进程和孤儿进程
僵尸进程:是指子进程完成并退出后父进程没有使用wait()或者waitpid()对他们进行回收,这些子进程就成为了僵尸进程,僵尸进程无法被杀死(killl),解决方法:结束它的父进程,使它成为僵尸孤儿进程,被init进程回收
孤儿进程是父进程退出后子进程还在执行,这时孤儿进程会被init进程回收,孤儿进程是一瞬间的状态。
6,线程间通信方式
互斥锁,读写锁,自旋锁,条件变量
读写锁(优先级随着ubuntu发生改变,16之前是写锁优先级高,20版本是读锁优先级高)
7,协程
协程就是子程序在执行时中断并转去执行别的子程序,在适当的时候又返回来执行 这种子程序间的跳转不是函数调用,也不是多线程执行 所以省去了线程切换的开销,效率很高 也不需要多线程间的锁机制 不会发生写冲突
8,协程的底层是怎么实现的?
协程进行中断跳转时将函数的上下文存放在其他位置中,而不是存放在函数堆栈里,当处理完其他事情跳转回来的时候,取回上下文继续执行原来的函数
9,进程的状态
执行态:进程分到CPU时间片,可以执行
就绪态:进程已经就绪,只要分配到CPU时间片就可以执行
阻塞态:有IO事件或等待其他资源
10,IO模型
IO过程包括两个阶段(1)内核从IO设备读写数据 (2)进程从内核复制数据
阻塞IO:调用IO操作的时候,如果缓冲区空或者满 调用的进程或线程就会处于阻塞状态直到IO可用并完成数据拷贝
非阻塞IO:调用IO操作时内核会马上返回结果,如果IO不可用会返回错误 -一般轮询的使用 但当进程从内核拷贝数据时是阻塞的
IO多路复用:同时监听多个文件描述符,一旦某个描述符IO就绪(读或者写)就能够通知进程进行相应的IO操作,否则将进程阻塞在select或epoll语句上
同步IO:阻塞IO,非阻塞IO,IO多路复用都是同步IO。当进程从内核复制数据的时候都是阻塞的
异步IO:在检测IO是否可用和进程拷贝数据的两个阶段都是不阻塞的,进程可以做其他事情,当IO完成后内核会给进程发送一个信号
11,什么时候用多线程,什么时候用多进程
需要频繁创建和销毁的优先使用多线程
大量计算优先使用多线程,因为需要消耗CPU资源且切换频繁
拓展到多机分布使用多进程,多核分布使用多线程
12,select、poll、epoll
select把所有监听的文件描述符拷贝到内核中,挂起程序。当某个文件描述符可读或可写的时候,中断程序唤起进程,select将监听的文件描述符再次拷贝到用户空间,然后遍历子而写文件描述符找到可用的IO操作。select支持监听的文件描述符最大数量是1024 (缺点也很明显-就是大量的从用户态到内核态拷贝,还有轮询的遍历 文件描述符最大限制1024 唯一的优点是跨平台)
和select差不多 唯一的区别就是使用链表保存文件描述符 可监听的数量更多一些
epoll将文件描述符拷贝得到内核空间后使用红黑树进行维护,同时向内核注册每个文件描述符的回调函数,当某个文件描述符可读可写的时候,将这个文件描述符加到就绪链表里,并唤起进程,返回就绪链表到用户空间。(当监听大量文件描述符,且只有部分活跃时 使用epoll会明显提升性能)
epoll还支持水平触发(LT)和边缘触发(ET)
边缘触发模式-只有当文件描述符从未就绪变成就绪时,内核才会通过epoll进行通知,然后直到下一次变成就绪之前,不会再次重复通知。(大概就是,如果一次就绪通知过后不对这个描述符进行IO操作导致它变成未就绪,内核不会再次发送就绪通知) 优点是只通知一次,减少内核资源浪费,效率高 缺点是不能保存数据的完整 [一般采用轮询的方式]
水平触发模式-在这个模式下,如果文件描述符IO就绪 内核就会进行通知 如果不对它进行IO操作,只要有未操作的数据,内核就会一直通知,优点是可以保证数据可以完整输出,缺点是内核会一直通知 会不停的从内核态切换到用户态 资源浪费严重
13,什么是上下文切换
对于单核CPU而言,在某一时刻只能执行一条CPU指令。上下文切换是一种将CPU资源从一个进程分配给另一个进程的机制,在切换的过程中 操作系统需要先存储当前进程的状态(包括内存空间的指针,当前执行完的指令...)再读入下一进程的状态,然后执行此进程
14,什么是用户态和内核态
用户态和内核态是操作系统的两种运行状态
处于内核态的CPU可以访问任意的数据,处于内核态的CPU可以从一个程序切换到另一个程序,并且占用CPU不会发生抢占情况。特权级为0级
处于用户态的CPU只能访问受限的访问内存,用户态下的CPU不允许独占,也就是说CPU能够被其他程序获取
那为什么要有用户态和内核态呢?主要是计算机中有一些比较危险的操作,比如设置时钟、内存清理(虚拟内存一方面也是为了防止用户有意或无意修改系统的内存 等着单独写)....,如果可以随意进行这些操作那系统肯定会不安全
用户态与内核态如何切换?系统调用
15,什么是内核
在计算机中,内核是一个计算机程序,是操作系统的核心 可以操控操作系统中所有的内容
计算机网络
1,OSI七层模型-TCP/IP四层模型
OSI-应用层 表示层 会话层 传输层 网络层 数据链路层 物理层(想好记一些就是“应表会传网数物“)
TCP/IP-应用层 传输层 网络层 数据链路层
2,建立TCP连接客户端与服务器的各个系统调用
tcp client:socket bind connect send receive
tcp server:socket bind listen accept receive send
关闭有close 和shutdown 使用close时只有当套接字的引用计数为0时才会终止连接,而shutdown可以直接关闭链接
3,TCP和UDP的区别
TCP是面向连接的协议,提供的是可靠传输 在收发数据前需要通过三次握手建立连接 使用ACK对收发的数据进行正确性检验。而UDP是无连接的协议。所以TCP比UDP来说更稳定 TCP更可靠 对系统资源的要求也高于UDP UDP的速度比TCP快
TCP提供流量控制和拥塞控制
TC数据包是没有边界的,是流式传输 会出现粘包的问题,UDP是独立的 不会出现粘包问题
TCP不是完全可靠的
4,UDP如何实现可靠传输
因为UDP是无连接的协议所以在传输层上无法保证可靠传输。要想实现可靠传输,只能从应用层实现 可以添加seq(初始序列号)/ack(确认应答)机制,重传机制和窗口确认机制
5,浏览器中输入URL后执行的过程
首先是域名解析,客户端使用DNS协议将URL解析为对应的IP地址
然后是建立TCP连接,客户端与服务器通过三次握手建立TCP连接
客户端向服务器发送http连接请求(http连接无需额外连接,直接通过已经建立的TCP连接发送)
服务器对客户端发来的http请求进行处理 并返回响应
客户端收到http响应,将结果渲染展示给用户
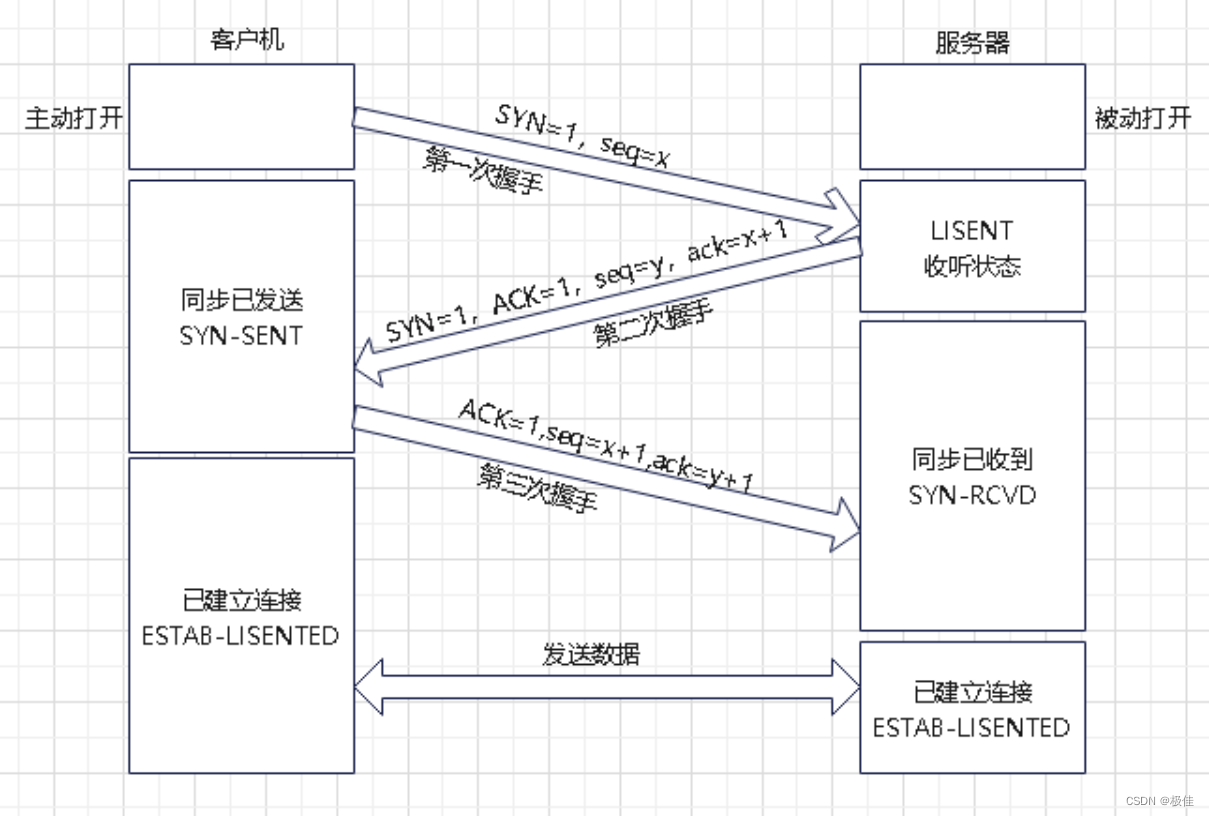
6,TCP的三次握手与四次挥手
假设握手和挥手请求都由客户端发起
第一次握手:首先客户端发送给服务器连接请求报文。这个报文中包含SYN(位于TCP头部的标志位中,如果置于一代表发起握手请求),seq(初始序列号[是递增的]) 发送后处于SYN-SENT状态
第二次握手:服务器收到请求后 处理请求并返回给客户端报文 报文中有ACK(确认应答位), SYN,自己的seq,还有一个小ack这个是客户端第一次的seq+1 处于SYN-RCVD状态
第三次握手:客户端收到服务器发来的信息后 看到小ack是自己的seq+1 就知道服务器收到了消息,这时客户端给服务器回了一个ACK报文,一个自己的初始序列号+1,还有一个小ack是服务器发来的seq+1
至此三次握手结束 双方可以进行通信 双方变成established状态
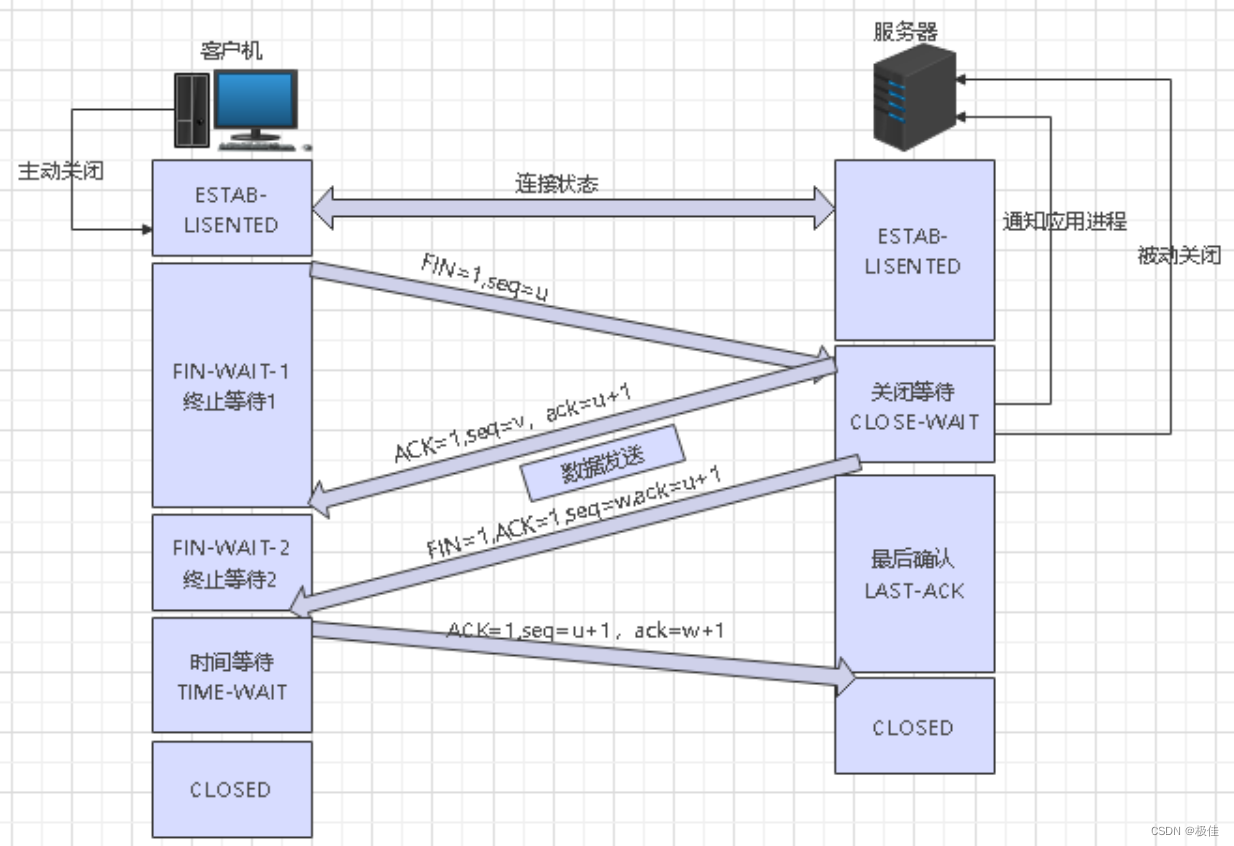
第一次挥手:当客户端没有数据要发送给服务器了 它会发送一个FIN报文,一个seq。告诉服务器"我已经没有数据要发给你了,但如果你要还想给我发数据的话,你就继续发 但是你得告诉我你收到我的关闭信息了" 进入FIN-WAIT1状态
第二次挥手:服务器收到客户端发来的FIN报文后 给客户端返回一个ACK信息,还有小ack=客户端seq+1,还有自己的初始序列号seq。服务器进入CLOSE-WAIT状态,而客户端收到之后处于FIN-WAIT2状态
第三次挥手:当服务器发完所有数据时,会给client发送一个FIN报文,告诉客户端说“我传完数据了,现在要关闭连接了” 然后服务器变成LAST-ACK状态 等着客户端最后的ACK信息
第四次挥手:当客户端收到信息后,对信息确认后会给服务器发送ACK信息,但是网络不一定是稳定的,它怕服务器收不到信息。客户端会进入TIME_WAIT状态(等待2MSL Linux下默认1MSL是30s)。万一服务器没收到ACK小心它还可以重传,而当server收到这个ACK信息后 就会正式关闭tcp连接了。而当客户端等待了2MSL时间还没有等到消息 它就知道服务器已经关闭连接了 ,于是它自己也断开了(就像有的时候先说分手的人不一定......)
7,为什么三次握手,两次可不可以?四次可不可以?
如果是两次的话 三次握手中最后一次缺失,服务器不能确定客户端的接收能力(会浪费资源)
三次握手才可以阻止历史重复连接的初始化(有足够的的上下文可以判断)
三次握手才可以同步双方的初始序列号
三次握手可以解决问题就没必要多一次握手浪费资源了
8,TIME_WAIT的意义
MSL是报文最大生存时间 是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃 TIME_WAIT等待2倍的MSL比较合理的解释是:网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待2倍MSL的时间
比如;如果被动关闭防没有收到断开连接的最后ACK报文,就会触发超时重传FIN报文,另一方接收到FIN后 会重发ACK给被动关闭方 一来一去正好2MSL。 (时间是从客户端收到FIN后发送ACK开始计时的如果在TIME_WAIT时间内,因为客户端的ACK没有传输到服务器,服务端又接收到了服务端重发的FIN报文,那么2MSL时间将重新计时)
9,TCP如何保证可靠性
确认应答+初始序列号
超时重传:当TCP发出一个报文后,会启动一个定时器 等待目的端确认收到这个报文段 如果不能及时收到确认的话 将重发这个报文
流量控制:TCP连接的每一方都有固定大小的缓冲空间,TCP接收端只允许发送发送端缓冲区能接收程度下的数据,当接收方来不及处理发送方的数据,能提示发送方降低发送速率,防止丢包现象。流量控制使用的是可变大小次奥的滑动窗口协议。
拥塞控制:当网络拥塞时,减少数据的发送。慢启动、拥塞避免、快速重传、快速恢复
发送方发送窗口大小=min(流量控制窗口,拥塞控制窗口)
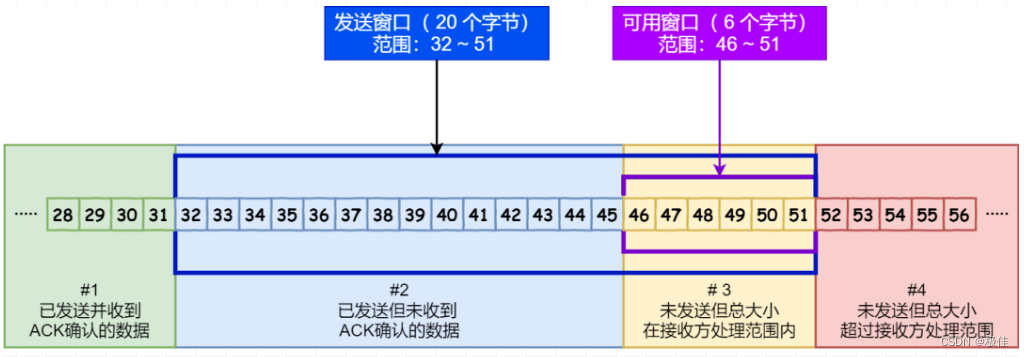
10,滑动窗口协议
TCP的滑动窗口用来控制发送方的发送速率,避免拥塞的发生。滑动窗口其实就是接收端缓冲区的大小。用来告诉发送方对它发送的数据有多大的缓冲空间。在接收方确认了数据序列之后,发送方的滑动窗口向后滑动,发送下一个数据。
11,TCP拥塞控制
发送方维持一个拥塞窗口cwnd。拥塞窗口的大小取决于网络的拥塞程度。拥塞控制有四个算法。
(1)慢启动:慢启动算法是当主机开始发送数据时,先以较小的拥塞窗口进行发送,然后每次翻倍。也就是说,由小到大逐渐增加拥塞窗口大小,是指数增长的。例:1,2,4,8,16,32
为了防止拥塞窗口增长过大引起网络拥塞,还有一个慢启动阈值ssthresh 当拥塞窗口的大小超过慢启动阈值时,停止慢启动算法启用拥塞避免算法
(2)拥塞避免:让拥塞窗口cwnd缓慢的增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwdn加1
(3)快速重传:当发送端连续收到三个重复的ack时,表述该数据段已经丢失需要重发。此时慢启动阈值ssh变为原来的一般,拥塞窗口cwnd变为ssh+3 然后启动拥塞避免算法。
(4)快恢复:当超过设定的时间没有收到某个报文段的ack时,表示网络拥塞 慢启动阈值ssh变为原来的一半,拥塞窗口cwdn=1 然后进入慢启动阶段
12,TCP/IP的粘包与避免
TCP采取的是流式传输,所以接收端在一次接收有可能接收多个包,而TCP粘包就是发送方的若干个数据包到达接收方的时候沾成了一个包,多个包首尾相接 无法区分。
导致TCP粘包的原因:
发送端等待缓冲区满才开始发送 造成粘包
接收方来不及接收缓冲区内的数据,造成粘包
tcp协议在发送较小的数据包时,会将几个包合成一个包后发送
避免粘包的措施:
通过编程 强制TCP发送数据,不必等到缓冲区满
设置固定长度的报文或者设置报文头部指示报文的长度
13,TCP的封包和拆包
封包:在发送数据包的时候为每个TCP数据包加上一个包头,将数据报文分为包头和包体两个部分,包头是一个固定长度的结构体,里面包含该数据包的总长度
拆包:接收方在接收到报文后提取包头中的长度信息进行截取
14,http与tcp的区别和联系
区别:http位于应用层,tcp位于传输层 建立一个TCP连接需要进行三次握手,而http连接是建立在tcp之上的,建立一个http请求通常包含请求和响应两个步骤
联系:http协议是建立在tcp协议基础之上的。当浏览器需要从服务器获取数据时,http会通过tcp建立起一个到服务器的连接通道,当本次请求需要的数据传输完毕后,http会立即将tcp连接断开。
15,Get和Post的区别
get不会修改服务器上的资源 而post有可能修改服务器的资源(从这点来看get安全)
get把请求附在url上,而post把参数附在http包的request body包体中(从这点来看post安全)
get产生一个TCP数据包;post产生两个TCP数据包。(对于get方式的请求,浏览器会把http header和data一并发送出去,服务器响应200。而对于post,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok)
get请求在url中传递的参数是有长度限制的,而post没有
get请求参数会被完整保留在浏览历史记录里,而post中的参数不会被保留
16,http和https的区别
http是超文本传输协议,信息是明文传输。https则是具有安全性的ssl加密传输协议
http的端口是80 https的端口是443
http的连接是无状态的(有好处有坏处),https协议是由http+ssl协议(ssl协议在应用层和传输层之间)构建的,可以进行加密传输,身份认证。比http协议安全
https协议需要ca证书
17,https的工作原理
客户使用https的URL访问服务器,要求与服务器建立ssl连接
服务器收到客户端请求后会将网站的证书信息(包含公钥)传送一份给客户端
客户端的浏览器与服务器开始协商ssl连接的安全等级
客户端的浏览器根据双方同意的安全等级建立会话密钥,然后利用服务器的公钥将会话密钥加密 并传送给服务器
服务器利用自己的私钥解密出会话密钥
服务器利用会话密钥加密与客户端之间的通信
---------------------------------------------------------------------------------------------------------------------------------
---------------第一篇博客 整体写的比较笼统 有很多地方没展开写---------------















 9387
9387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









