







前言
LRU全称:Least Recently Used:最近最少使用策略,判断最近被使用的时间,距离目前最远的数据优先被淘汰,作为一种根据访问时间来更改链表顺序从而实现缓存淘汰的算法,它是redis采用的淘汰算法之一。redis还有一个缓存策略叫做LFU, 那么LFU是什么呢?我们本期来分下一下LFU:
一:LRU是什么
LFU,全称是:Least Frequently Used,最不经常使用策略,在一段时间内,数据被使用频次最少的,优先被淘汰。 最少使用 (LFU)是一种用于管理计算机内存的缓存算法。主要是记录和追踪内存块的使用次数,当缓存已满并且需要更多空间时,系统将以最低内存块使用频率清除内存.采用LFU算法的最简单方法是为每个加载到缓存的块分配一个计数器。每次引用该块时,计数器将增加一。当缓存达到容量并有一个新的内存块等待插入时,系统将搜索计数器最低的块并将其从缓存中删除(本段摘自维基百科)
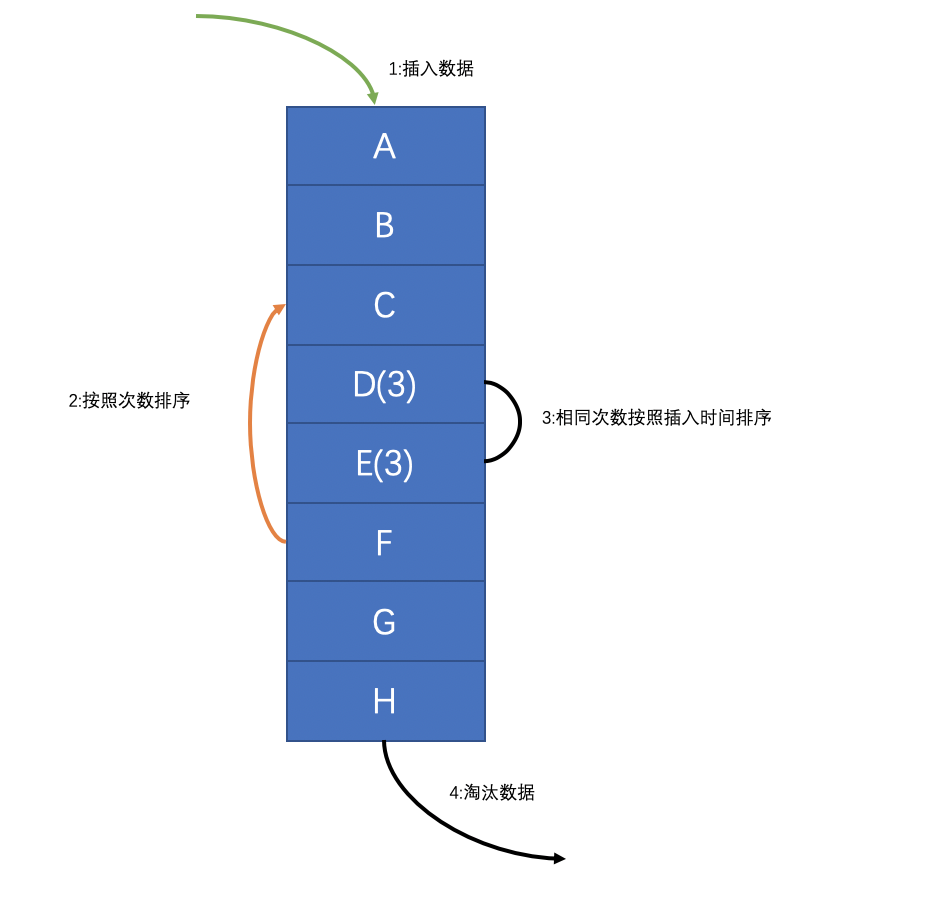
解释:上面这个图就是一个LRU的简单实现思路,在链表的开始插入元素,然后每插入一次计数一次,接着按照次数重新排序链表,如果次数相同的话,按照插入时间排序,然后从链表尾部选择淘汰的数据~
二:LRU实现
2.1 定义Node节点
Node主要包含了key和value,因为LFU的主要实现思想是比较访问的次数,如果在次数相同的情况下需要比较节点的时间,越早放入的越快 被淘汰,因此我们需要在Node节点上加入time和count的属性,分别用来记录节点的访问的时间和访问次数。其他的版本实现方式里有新加个内部类来记录 key的count和time,但是我觉得不够方便,还得单独维护一个map,成本有点大。还有一点注意的是这里实现了comparable接口,覆写了compare方法,这里 的主要作用就是在排序的时候需要用到,在compare方法里面我们首先比较节点的访问次数,在访问次数相同的情况下比较节点的访问时间,这里是为了 在排序方法里面通过比较key来选择淘汰的key
/**
* 节点
*/
public static class Node implements Comparable<Node>{
//键
Object key;
//值
Object value;
/**
* 访问时间
*/
long time;
/**
* 访问次数
*/
int count;
public Node(Object key, Object value, long time, int count) {
this.key = key;
this.value = value;
this.time = time;
t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









