













效果展示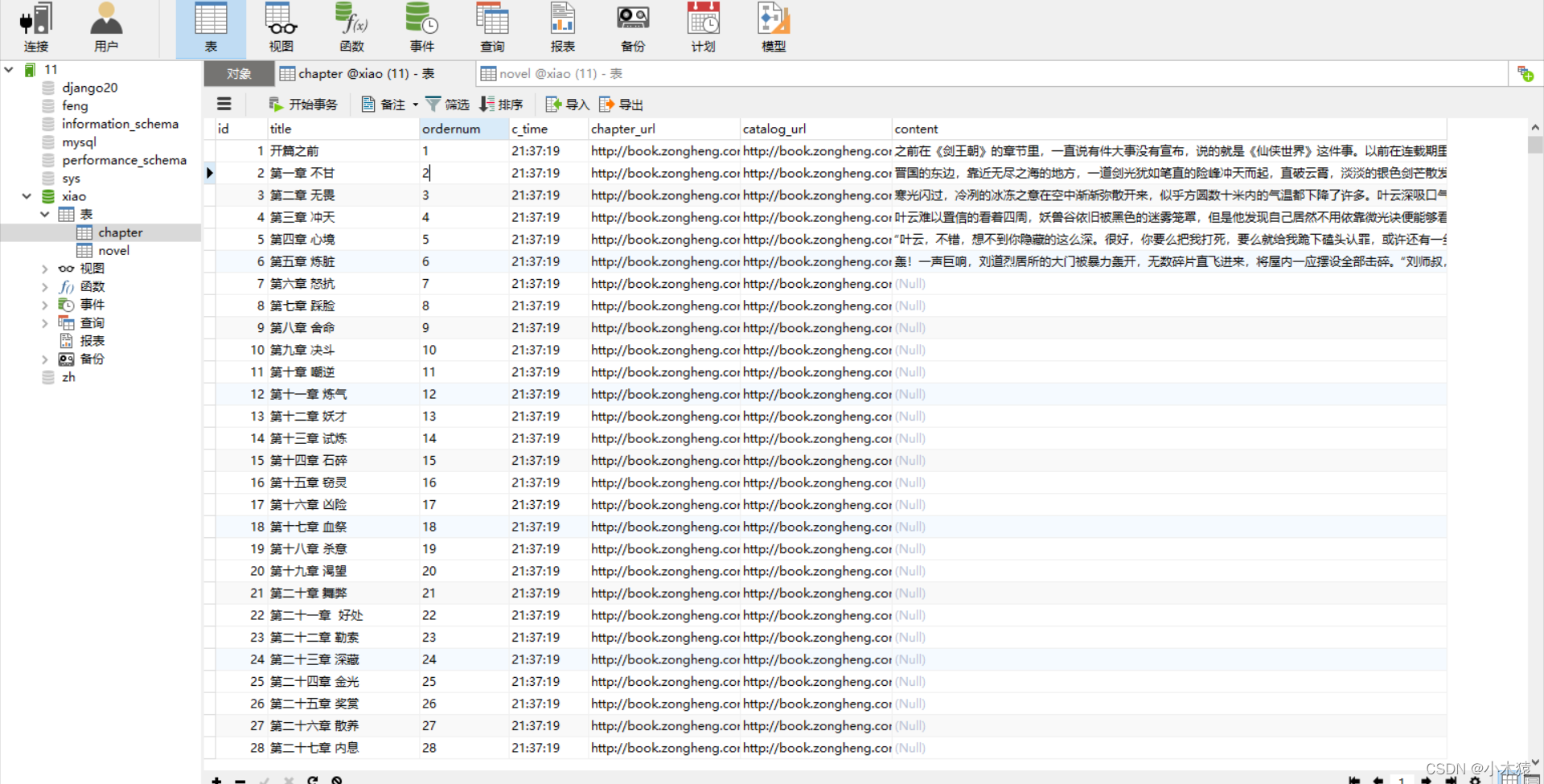

settings.py
# Scrapy settings for zongheng project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zongheng'
SPIDER_MODULES = ['zongheng.spiders']
NEWSPIDER_MODULE = 'zongheng.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'zongheng (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'zongheng.middlewares.ZonghengSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'zongheng.middlewares.ZonghengDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zongheng.pipelines.ZonghengPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
DATABASE_CONFIG={
"type":"mysql",
"config":{
"host":"127.0.0.1",
"port":3306,
"user":"root",
"password":"123456",
"db":"xiao",
"charset":"utf8"
}
}
LOG_FILE='aa.log'#输出日志
zh.py
# -*- coding: utf-8 -*-
import datetime
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import NovelItem, ChapterItem, ContentItem
class ZhSpider(CrawlSpider):
name = 'zh'
allowed_domains = ['book.zongheng.com']
start_urls = ['http://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html'] # 起始的url
# 定义爬取规则 1.提取url(LinkExtractor对象) 2.形成请求 3.响应的处理规则
rules = (
Rule(LinkExtractor(allow=r'http://book.zongheng.com/book/\d+.html', restrict_xpaths='//div[@class="bookname"]'),
callback='parse_book', follow=True, process_links="process_booklink"),
Rule(LinkExtractor(allow=r'http://book.zongheng.com/showchapter/\d+.html'), callback='parse_catalog',
follow=True, ),
Rule(LinkExtractor(allow=r'http://book.zongheng.com/chapter/\d+/\d+.html',
restrict_xpaths='//ul[@class="chapter-list clearfix"]'),
callback='get_content', follow=False, process_links="process_chpter"),
)
def process_booklink(self, links):
# 处理 LinkExtractor 提取到的url
for index, link in enumerate(links):
if index <= 2:
# print(index, link.url)
yield link
else:
return
def process_chpter(self, links):
for index, link in enumerate(links):
if index <= 5:
yield link
else:
return
def parse_book(self, response):
category = response.xpath('//div[@class="book-label"]/a/text()').extract()[1]
book_name = response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()
author = response.xpath('//div[@class="au-name"]/a/text()').extract()[0]
status = response.xpath('//div[@class="book-label"]/a/text()').extract()[0]
book_nums = response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]
description = ''.join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').re("\S+"))
c_time = datetime.datetime.now()
book_url = response.url
catalog_url = response.css("a").re('http://book.zongheng.com/showchapter/\d+.html')[0]
item = NovelItem()
item["category"] = category
item["book_name"] = book_name
item["author"] = author
item["status"] = status
item["book_nums"] = book_nums
item["description"] = description
item["c_time"] = c_time
item["book_url"] = book_url
item["catalog_url"] = catalog_url
yield item
def parse_catalog(self, response):
a_tags = response.xpath('//ul[@class="chapter-list clearfix"]/li/a')
chapter_list = []
catalog_url = response.url
for a in a_tags:
# print("解析catalog_url")
title = a.xpath("./text()").extract()[0]
chapter_url = a.xpath("./@href").extract()[0]
chapter_list.append((title, chapter_url, catalog_url))
item = ChapterItem()
item["chapter_list"] = chapter_list
yield item
def get_content(self, response):
chapter_url = response.url
content = ''.join(response.xpath('//div[@class="content"]/p/text()').extract())
c_time = datetime.datetime.now()
# 向管道传递数据
item = ContentItem()
item["chapter_url"] = chapter_url
item["content"] = content
yield item
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZonghengItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class NovelItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
category = scrapy.Field()
book_name = scrapy.Field()
author = scrapy.Field()
status = scrapy.Field()
book_nums = scrapy.Field()
description = scrapy.Field()
c_time = scrapy.Field()
book_url = scrapy.Field()
catalog_url = scrapy.Field()
class ChapterItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
chapter_list = scrapy.Field()
catalog_url = scrapy.Field()
class ContentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
chapter_url = scrapy.Field()pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from .items import NovelItem,ChapterItem,ContentItem
import datetime
from scrapy.exceptions import DropItem
class ZonghengPipeline(object):
#连接数据库
def open_spider(self,spider):
data_config = spider.settings["DATABASE_CONFIG"]
print("数据库内容",data_config)
if data_config["type"] == "mysql":
self.conn = pymysql.connect(**data_config["config"])
# self.conn = pymysql.connect( host=None, user=None, password="",
# database=None, port=0,)
self.cursor = self.conn.cursor()
spider.conn = self.conn
spider.cursor = self.cursor
#数据存储
def process_item(self, item, spider):
#1.小说信息存储
if isinstance(item,NovelItem):
sql="select id from novel where book_name=%s and author=%s"#确保数据中没有
self.cursor.execute(sql,(item["book_name"],item["author"]))
print('*' * 30)
if not self.cursor.fetchone():#如果这里没有找到
#写入小说数据
sql="insert into novel(category,book_name,author,status,book_nums,description,c_time,book_url,catalog_url)" \
"values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
#补充sql语句 并执行
self.cursor.execute(sql,(
item["category"],
item["book_name"],
item["author"],
item["status"],
item["book_nums"],
item["description"],
item["c_time"],
item["book_url"],
item["catalog_url"],
))
self.conn.commit()
return item
#2.章节信息存储
elif isinstance(item,ChapterItem):
#写入 目录信息
sql = "insert into chapter(title,ordernum,c_time,chapter_url,catalog_url) values(%s,%s,%s,%s,%s)"
data_list=[]
for index,chapter in enumerate(item["chapter_list"]):
c_time = datetime.datetime.now()
ordernum=index+1
title,chapter_url,catalog_url=chapter #(title, chapter_url, catalog_url)
data_list.append((title,ordernum,c_time,chapter_url,catalog_url))
self.cursor.executemany(sql,data_list) #[(),(),()]
self.conn.commit()
return item
#3.章节内容存储
elif isinstance(item, ContentItem):
sql="update chapter set content=%s where chapter_url=%s"
content=item["content"]
chapter_url=item["chapter_url"]
self.cursor.execute(sql,(content,chapter_url))
self.conn.commit()
print('-'*30)
return item
else:
return DropItem
#关闭数据库
def close_spider(self,spider):
data_config=spider.settings["DATABASE_CONFIG"]#setting里设置数据库
if data_config["type"]=="mysql":
self.cursor.close()
self.conn.close()


















 2171
2171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











