







线程池的作用&&线程池的使用
1、线程池的作用
为什么需要线程池:
- 线程的管理比较复杂(比如什么时候新增线程、什么时候减少空闲线程)
- 任务存取比较复杂(什么时候接受任务、什么时候拒绝任务、保证多线程不抢到同一个任务)
线程池的作用:轻松管理线程、协调任务的执行过程
如果还是不理解线程池的话,可以看下面一点"线程池"
2、线程池
什么是线程池?
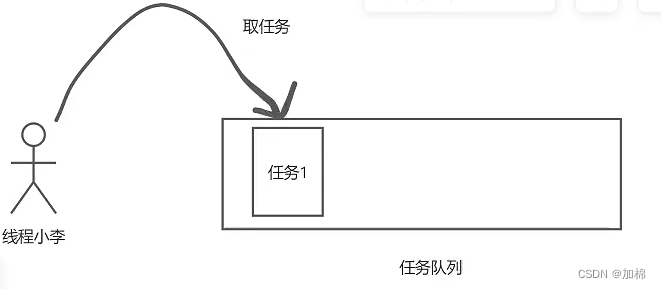
用户提交了一个任务,现在“线程小李”是不是可以取这个“任务1”去执行,每次只能取一个任务。

现在问题来了,又来了一个任务“任务2”,但是“线程小李”正在处理“任务1”,没办法处理“任务2”,这个时候如果是你你应该怎么办?
- 第一种方案:再叫一个“线程小鱼”来,“线程小鱼” 处理 “任务2”


然后又来一个任务,但是我们公司的员工没了。
这个时候该怎么办?
是不是可以有一个“任务队列”把任务记录下来。等“小李”或者“小鱼”处理完当前的任务后再取任务处理。
但是如果我们的任务队列满了怎么办?
i.可以把任务解决掉。
ii.把任务记录到数据库中,等有空闲资源再处理.
2. 第二种方案
如果"线程小李"处理速度很快,不需要再叫"线程小鱼"来,
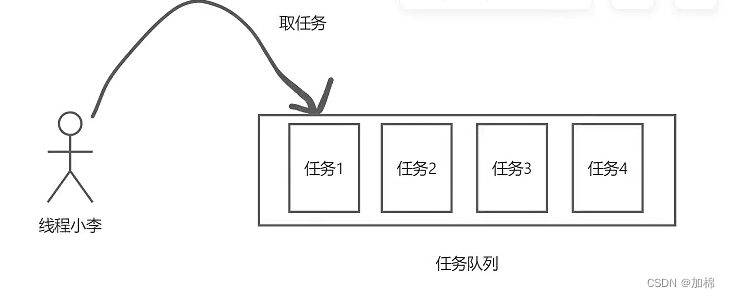
如果任务突然来了很多,我们临时叫了几个人.让他们帮助把任务处理掉。
但是到第二天,又没有什么任务了,我们是不是要减少人员。(就像外包,临时支持一下的感觉,并没有说让这几个人一直占用着我们的系统资源)。

通过上面的场景,我们会发现面临以下问题
面临的问题:什么时候新增线程,什么时候减少空闲线程
解决方案:线程池就是解决这个问题的.
- 线程的管理比较复杂(比如什么时候新增线程、什么时候减少空闲线程)
- 任务存取比较复杂(什么时候接受任务、什么时候拒绝任务、保证多线程不抢到同一个任务)
线程池的作用:轻松管理线程、协调任务的执行过程
3、线程池的创建和使用
3.1自己写线程池:
线程池的实现是很麻烦的,有些大厂的面试题会要我们实现线程池,这个时候就可以根据以上的流程来分析编写啦.(比如什么时候新增线程、什么时候减少空闲线程)
3.2使用Java提供的或者第三方提供的
不用自己写,如果是在Spring中,可以用ThreadPoolTaskExecutor配合Async注解来实现。(不太建议)
如果是在Java中,可以使用JUC并发编程包中的ThreadPoolExecutor来实现非常灵活地自定义线程池。
Java线程池有七大参数
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler
)
3.2.1线程池的参数含义
怎么确定线程池参数?结合实际情况(实际业务场景和系统资源)来测试调整,不断优化、
回归到该系统中,考虑该系统最脆弱的环节(系统的瓶颈)在哪里?
现有条件:比如AI生成能力的并发是允许4个任务同时去执行,AI能力允许20个任务排队
int corePoolSize(核心线程数):正常情况下,系统应该能同时工作的线程数(随时就绪状态)
int maximumPoolSize(最大线程数):极限情况下,线程池可容纳的最多线程
long keepAliveTime(空闲线程存活时间):非核心线程在没有任务的情况下,过多久要删除,释放无用的资源
TimeUnit unit(空闲线程存活时间的单位):分钟、秒
BlockingQueue workQueue(工作队列):用于存放给线程执行的任务的队列,该队列应当设置长度,不能为无限队列,那样也会占用额外的资源
ThreadFactory threadFactory(线程工厂):控制每个线程的生成、线程的属性(比如线程名)
RejectedExecutionHandler handler(拒绝策略):任务队列满的时候,采取什么措施。抛异常?不抛异常?自定义策略?
资源隔离策略:比如重要的任务(VIP任务)一个队列,普通任务一个队列,保证这两个队列互不干扰
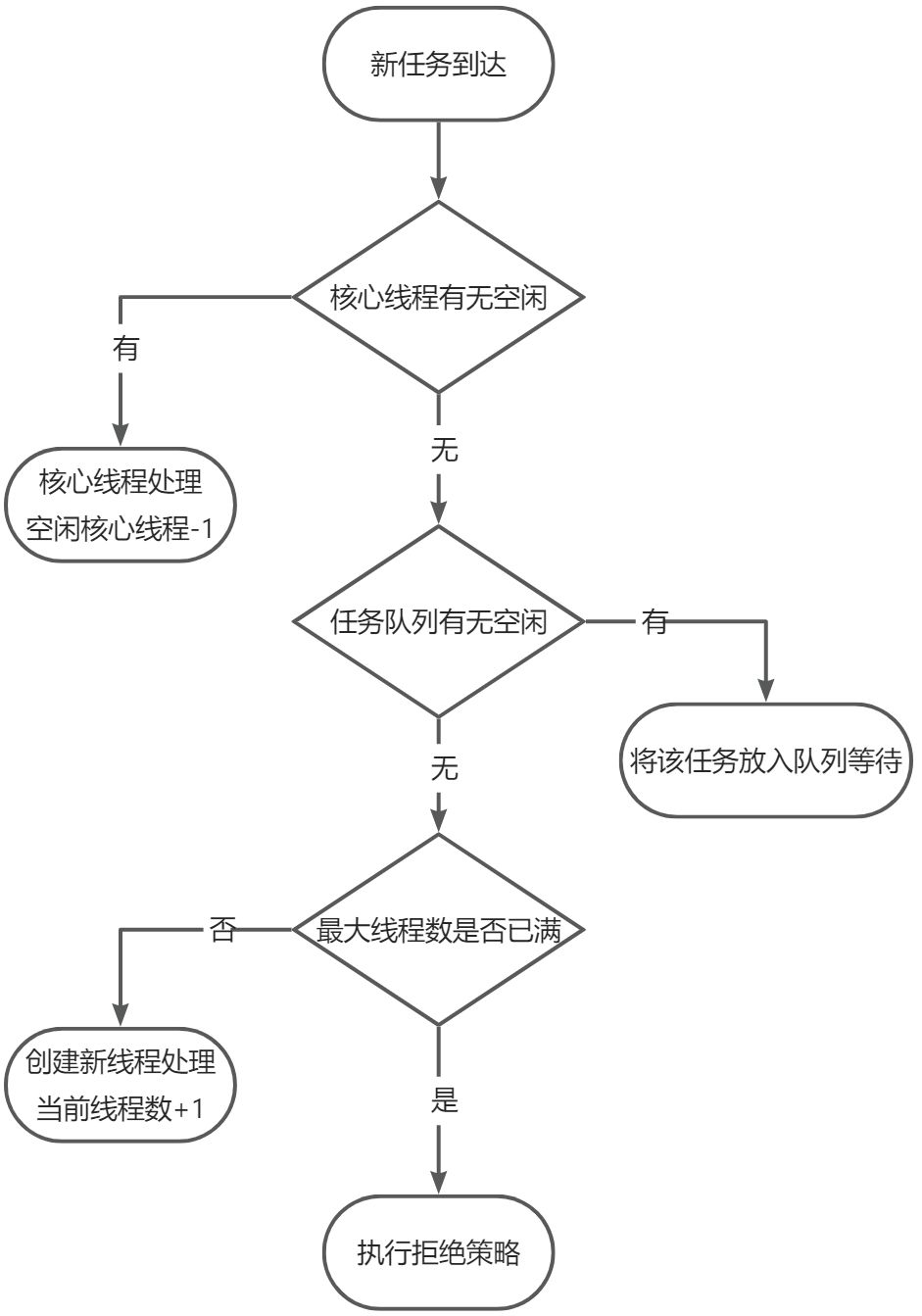
3.2.2线程池工作机制
这里有用例图解说版 和 流程图版的
用例图解说版:没那么直观,但也清晰,细节到位
流程图版:更清晰直观,当部分细节没有
推荐两个都看
用例图解说:
刚开始,没有任何的线程,也没有任何的任务:
来了一个任务,发现我们的员工还没有达到正式员工数(corePoolSize = 2),来一个员工直接处理这个任务
又来了一个任务,发现我们的员工还没有达到正式员工数(corePoolSize = 2),再来一个员工直接处理这个任务
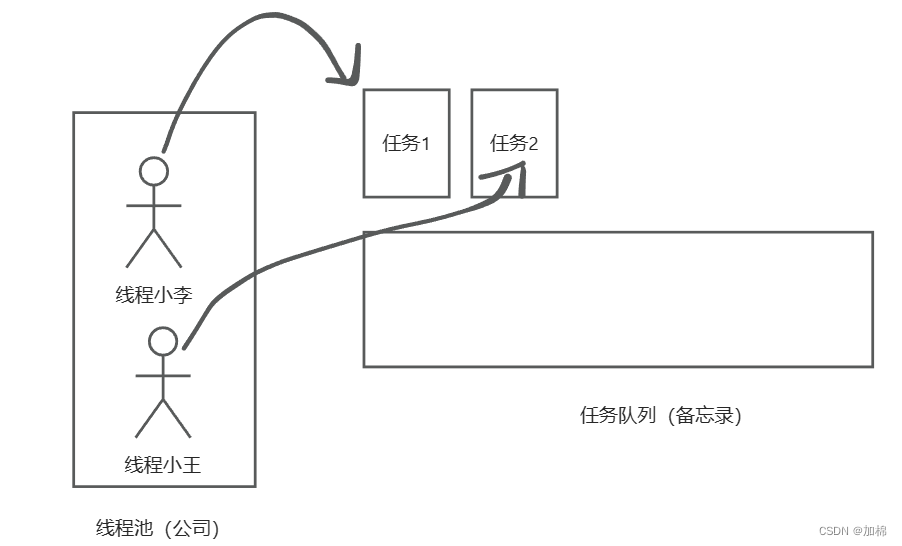
又来了一个任务,但是我们正式员工数已经满了(当前线程数 = corePoolSize = 2),任务放到队列(最大长度 workQueue.size 是 2)里等待,而不是再加新员工。
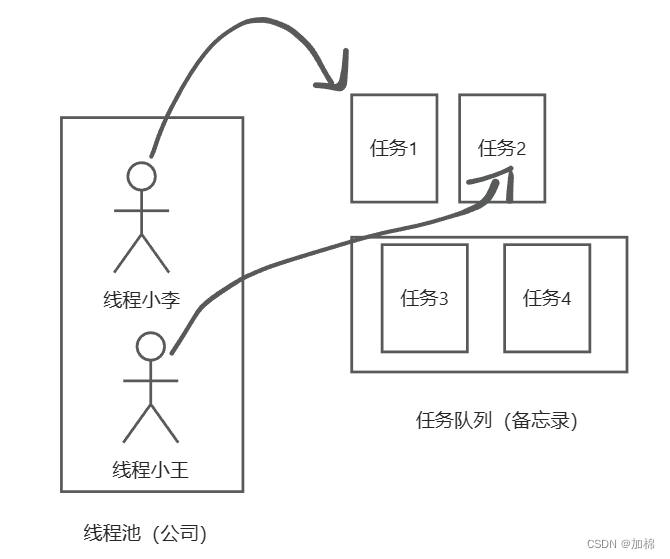
又来了一个任务,但是我们的任务队列已经满了(当前线程数 > corePoolSize = 2,已有任务数 = 最大长度 workQueue.size = 2),新增线程(maximumPoolSize = 4)来处理新任务,而不是丢弃任务
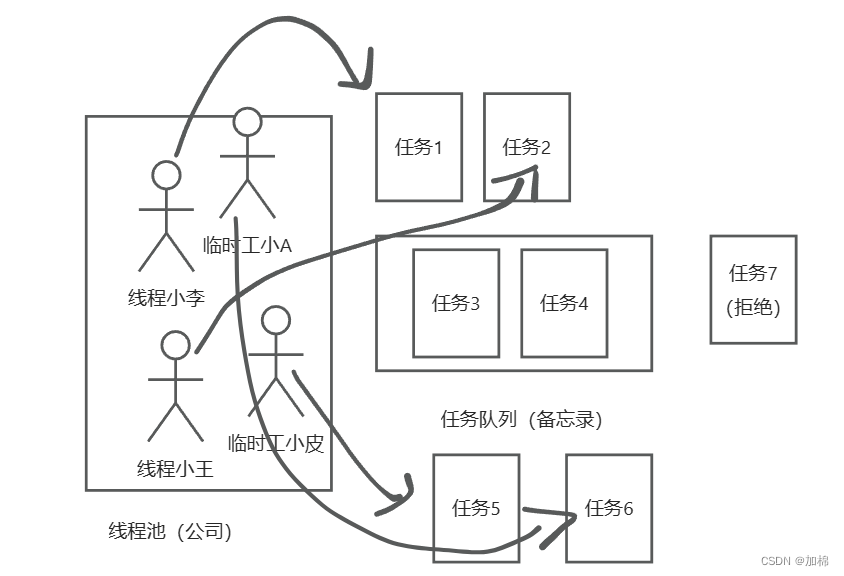
已经到了任务 7,但是我们的任务队列已经满了、临时工也招满了(当前线程数 = maximumPoolSize = 4,已有任务数 = 最大长度 workQueue.size = 2),调用 RejectedExecutionHandler 拒绝策略来处理多余的任务。
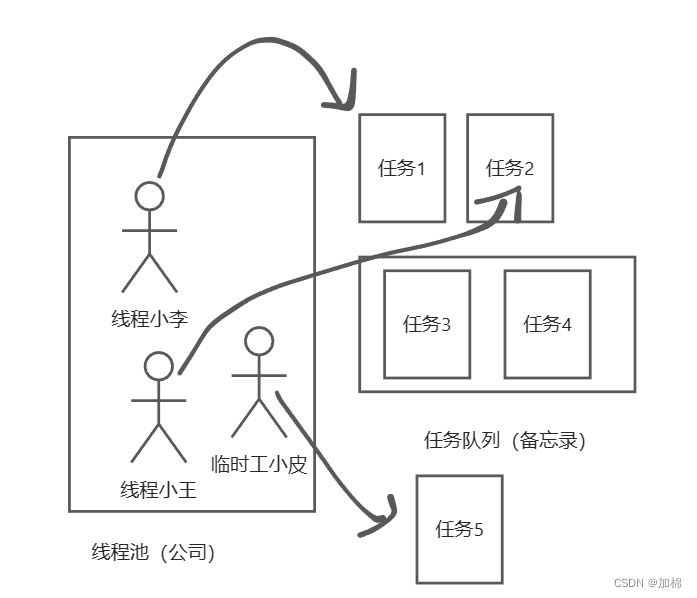
如果当前线程数超过 corePoolSize(正式员工数),又没有新的任务给他,那么等 keepAliveTime 时间达到后,就可以把这个线程释放。
流程图:
3.2.3线程池的参数如何设置
现有条件:比如AI生成能力的并发是允许4个任务同时去执行,AI能力允许20个任务排队
int corePoolSize(核心线程数):正常情况下,可以设置为2-4
int maximumPoolSize(最大线程数):设置为极限情况<=4
long keepAliveTime(空闲线程存活时间):一般为秒级或分钟级
TimeUnit unit(空闲线程存活时间的单位):分钟、秒
BlockingQueue workQueue(工作队列):结合实际情况去设置,可以设置为20
RejectedExecutionHandler handler(拒绝策略):抛异常,标记数据库的任务状态为“任务满了已拒绝”
一般情况下,任务分为IO密集型和计算密集型两种
计算密集型:吃CPU,比如音视频处理、图像处理、数学计算等,一般设置corePoolSize为CPU核心数+1(空余线程),可以让每个线程都能利用好CPU的每个核,而且线程之间不用频繁切换
IO密集型:吃带宽/内存/硬盘等资源,corePoolSize可以设置大一些,一般为2n左右,但是建议以IO能力为主
例:导入百万数据到数据库属于IO密集型任务
3.2.4调试
自定义线程池:
@Configuration
public class ThreadPoolExecutorConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
//自定义线程工厂
ThreadFactory threadFactory = new ThreadFactory() {
private int count = 1;
@Override
public Thread newThread(@NotNull Runnable r) {
Thread thread = new Thread(r);
thread.setName("线程" + count);
count++;
return thread;
}
};
//创建线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 4, 100, TimeUnit.SECONDS, new ArrayBlockingQueue<>(4), threadFactory);
return threadPoolExecutor;
}
提交任务到线程池:
/**
* 队列测试
*/
@RestController
@RequestMapping("/queue")
@Slf4j
public class QueueController {
@Resource
private ThreadPoolExecutor threadPoolExecutor;
//提交任务到线程池
@GetMapping("/add")
public void add(String name) {
CompletableFuture.runAsync(() -> {
log.info("任务执行中:" + name + ",执行人:" + Thread.currentThread().getName());
try {
Thread.sleep(600000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, threadPoolExecutor);
}
//获取线程池状态
@GetMapping("/get")
public String get() {
Map<String, Object> map = new HashMap<>();
int size = threadPoolExecutor.getQueue().size();
map.put("队列长度", size);
long taskCount = threadPoolExecutor.getTaskCount();
map.put("任务总数", taskCount);
long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();
map.put("已完成任务数", completedTaskCount);
int activeCount = threadPoolExecutor.getActiveCount();
map.put("正在工作的线程数", activeCount);
return JSONUtil.toJsonStr(map);
}
}















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









