









R和Python是目前最流行的两款高级编程语言,被大量运用于数据科学领域。两者都是开源的,也都有非常活跃的社区来支撑。那么问题来了:对于初学者,到底应该学哪个?
我的建议:看情况(it depends),选用何种编程语言,依赖于你的背景以及你的长期目标。换句话说:你是干啥的?以及你的目标是什么?
事实上,对于想从事数据科学的新手,R和Python可能是最好的/唯一的两个选择。哪个更好呢?
在这篇博客,我将介绍R和Python各自的优势以及两者间的PK。我将先介绍R,然后介绍Python,最后在文末总结我的观点。
1. R的优势
为了避免读者阅读疲劳,用两张R语言绘制的图来暖一下场:
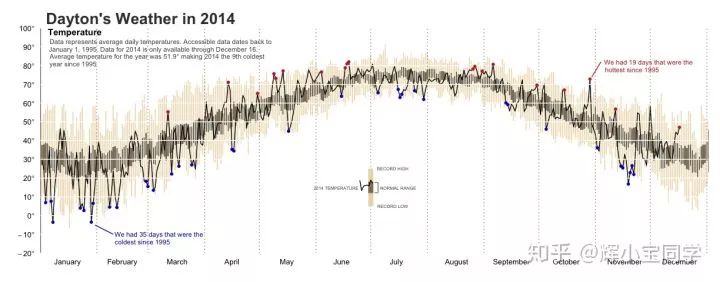
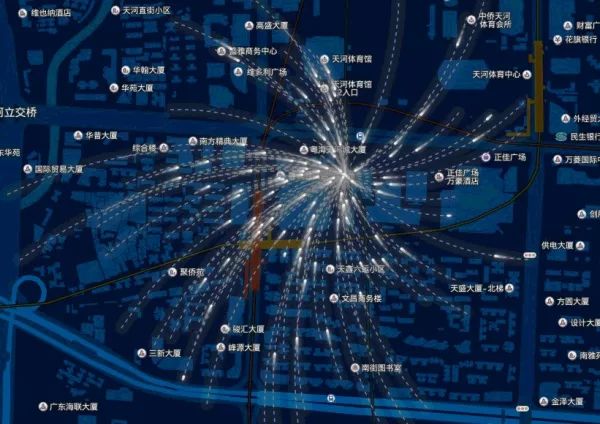
先简要介绍下R:
R语言由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman于1995设计出来(由于两人的名字均以 ‘R’ 字母开头,因此命名为R语言),现在由“R核心开发团队“负责开发。
虽然R主要用于数据分析、绘图以及数据挖掘,但也有人用作矩阵计算。其计算速度可媲美专用于矩阵计算的开源软件GNU Octave和商业软件MATLAB。
起初R主要在学术研究中使用,但近年来在企业界也表现突出,这使得R成为企业中使用的全球发展最快的统计语言之一。
我们看看什么情况下选R更好。
1.1 如果你的编程水平是菜鸟级,选R
如果你的编程经验有限,推荐先学R。
对于软件开发新手来说,Python可能不错,但是我认为R更适合数据科学新手。
但是数据科学和软件开发不是同一回事。
解释一下为什么。
这种差异可归结为:数据科学家使用编程语言的方式与软件开发者不一样。对于数据科学新手来说,程序(programs)应该是脚本(scripts),而不应该是软件(software)。
举个例子,我们用R语言处理一个叫Auto数据框(dataframe):
library(ISLR)
data(‘Auto’)
如果对R不熟悉,代码的具体意义可暂时不理会。
数据框是R语言中最常用的数据类型之一,以行列的形式排布,有点类似Excel表格。
在这个Auto数据框中有个weight变量,表示汽车的重量。我们想利用它来创建一个以公斤为单位的新变量weight_kg。
有很多方法可以实现这个任务。最容易想到的方法是:利用for循环遍历weight变量中的值,然后计算出新变量的值。听起来有点麻烦。
其实我们可以利用tidyverse包中已有的mutate函数直接计算出新变量的值:
mutate(Auto, weight_kg=weight*0.45)
再次提示,代码的意义可先不理会。
这个方法避免使用for循环,更简单。事实上,在R中要实现某种功能,只要你知道要用哪个函数和哪个包,实现将会变得非常简单。
在R中,你应该尽量使用已有函数和包来完成相关任务,没必要自己创建工具来处理任务。这意味着你不需要知道很多传统意义上的编程概念。事实上你应该避免使用这些概念,比如:for循环、类、面向对象编程以及其它软件开发概念。
总之,相比Python,由于R的数据处理工具开发得更好且更容易使用,我认为R更适合做数据处理。
其实Python也有很多工具来直接处理数据,比如pandas包,但是Python的包和语法具有‘软件开发’的味道,依赖于一些软件开发概念(像for循环、类和面向对象等等)。比如,当浏览一些Python书籍的时候,你仍会看到介绍for循环、类声明等。对于那些没有软件开发或计算机科学背景的新人来说,这些概念很难被理解。
相反,很多情况下即使没有任何编程经验,你也可以很好地使用R的各种工具。
1.2 对于数据科学任务,R的语法更直观形象
对于数据处理任务,很多时候R的语法会更简单。函数和参数的命名设计也更好,很容易记住和使用。
举个例子,我们将分别用R和Python来删掉Iris数据框中的两个变量(由于R和Python都有Iris数据框,因此我们使用这个数据框)。
我们来看看各自的语法:
Python
import seaborn as sns
import pandas as pd
iris = sns.load_dataset(‘iris’)
iris.drop([‘sepal_length’, ‘species’], axis = 1)
R
library(dplyr)
select(iris, -sepal_length, -species)
为了删除变量,Python中使用了drop函数,而R中使用了select函数。我们来对比这两个函数(都在最后一行代码)的语法。
先讲Python,drop函数命名得很好,容易记住。但是参数设计得很复杂。
第一个参数是包含想要删除变量的列表,Python中用方括号[ ]代表列表。这里你必须要用方括号,而且变量一定要用引号’ ',要不然代码会运行错误。
对于初学者,经常会忘记使用方括号和引号,导致代码运行错误,也不知道为啥会出错,很是困惑。当时我学Python就是这种感觉。
再说下drop的第二个参数axis。初学者肯定会困惑,“天啊,啥是axis,它有什么用”,一脸懵逼。
事实上,在学Python的时候,你会碰到很多类似的情况,让初学者很困惑。
我们看看R是怎么处理的。
为了删除变量,R用了dplyr包中的select函数。函数名字取得一般,不如Python中drop。但是参数设计得很好,第一个参数是你想处理数据框;其它参数是你想要删除的变量,前面的负号-表示删除,变量之间用逗号,隔开,都非常形象。此外这里根本没有涉及drop中所谓的 ‘axis’ 概念。
总之,相比Python,在数据处理方面,R的语法更直观形象,写代码如同写伪代码一样,容易记住、编写和读懂。
1.3 在数据可视化方面,R非常优秀
可视化是选择数据分析软件的一个重要的标准。
除了擅长数据分析外,R的另外一个闪光点就是它的画图能力特别强,几乎可以绘制出所有类型的图。不信的话,你可以Google一下,输入 ‘R visualization’ 关键字。
此外,由于R是编程语言,批量作图也是特别方便。
对于数据可视化,R中有很多优秀的包(package),比如:
- 对于静态图,比如ggplot2,ggmap,Lattice
- 对于动态图,比如gganimate,REmap,animation
- 对于交互式图, 比如plotly,rCharts
不BB了,一图胜千言:
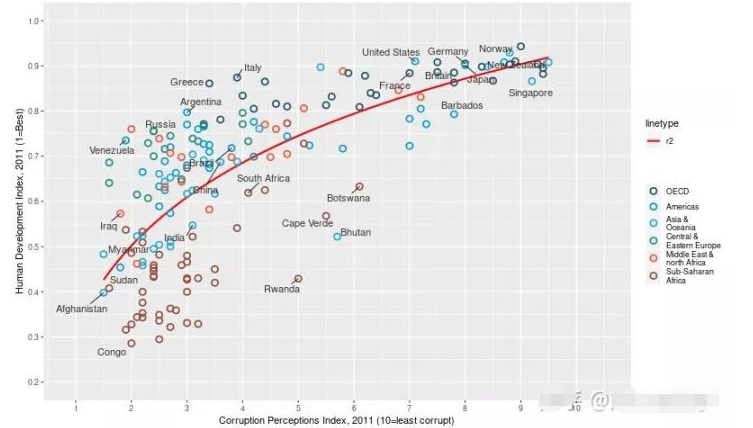
附上小编自己用R做的一个动画:
由于图片大小原因,动图演示地址:https://zhuanlan.zhihu.com/p/45740437
虽然Python也有一些不错的可视化库,如matplotlib,Seaborn,Bokeh和Pygal。但相比于R,呈现的结果并不总是那么顺眼。
1.4 在数据处理方面,R非常优秀
如果你的工作更多的是数据分析,我强烈推荐你使用R,尤其推荐你使用R中的tidyverse包。
tidyverse包是一组数据处理与可视化R包的集合体,其中的ggplot2, dplyr和stringr包都广为人知。
对于数据科学,tidyverse包提供【数据导入】→【数据整理】→【数据分析】→【数据可视化】一条龙服务。假如这些就是你的日常工作,那么恭喜你了,赶快使用这个包。
tidyverse的语法也非常易学、易记和易用。特别地,包中的各种函数都命名得非常贴切,不用特意去记住它们。比如:你想“过滤”你的数据集来创建一个子集,可以使用filter()函数;如果你想选择数据集的某一列,你可以使用select()函数。
此外,tidyverse包中的函数都被高度模块化了。每个函数只干一件事情,而且做得非常好。模块化让函数更容易学和使用。通过联合许多简单的tidyverse函数,完成一项复杂的数据处理任务变得非常容易。整个过程如同搭积木一样。
总之,相比Python,我认为R更擅长数据分析。
1.5 如果你有统计学基础,学R
如果你在做统计学方面的研究,建议你学R。
很多统计学的学生都在使用R,但是他们对程序编程知道的很少。如果你也是这种情况,我强烈建议你去学R。
貌似统计学家更喜欢使用R,比如当你看到一本统计学书籍时,你会发现他们使用的代码常常都是用R写的。很多统计学家都是R社区的贡献大牛。
基本上所有统计算法在R中都可以实现。因此,如果你想使用一些比较少见的统计学技术,你可能在R中更加容易找到它们。
1.6 R就业竞争力强
在大数据、数据分析师等相关招聘广告中,经常要求求聘者精通R。
根据三家权威机构2017年的统计数据 (https://link.zhihu.com/?target=https%3A//www.techrepublic.com/article/five-highly-paid-and-in-demand-programming-languages-to-learn-in-2018//),相比Python,R从业者的平均年薪会稍微高一点。
从就业形势来看,目前大数据领域人才比较稀缺,因此R从业者的竞争力还是比较强的。
2. Python的优势
对于数据科学初学者,尽管我强烈推荐学R,但也不是唯一的选择。
对于某些人,Python可能是最好的选择。下面讲一下哪些情况下选择Python更好。
2.1 如果你有软件开发或计算机科学基础,学Python
如果你曾经有软件开发经验或者你是计算机科学专业的话,我认为Python会更适合你。因为你已经有编程经验了,使用Python会让你更舒服。
2.2 想开发软件,学Python
我已经说了R更擅长数据科学。如果你想建立软件系统的话,我认为Python更合适。Python的闪光点就是写软件,效率很高。就像一些专家所说的那样,写Python代码就如同写伪代码。
此外,Python是一门通用语言,基本啥都能干。然而R比较专,只是擅长统计分析和可视化。
我想澄清一下,不是说R不能写软件。只是更多人喜欢用Python去建立产品软件。因此作为数据科学家,如果你想创立软件系统,我觉得Python比R更合适。
2.3 想搞机器学习,学Python
如果你想长期从事机器学习方面的研究,我建议你学Python。
其实R也有机器学习生态系统。特别地,R的caret 包开发得很好,它有能力完成各种机器学习任务。比如:使用caret包建立回归模型(regression model)、支持向量机(SVM)、决策树(包括回归和分类)以及执行交叉验证(cross validation)等等。总之,R的机器学习生态系统发展得很好。
但是,Python在机器学习方面的支持出现更早。为实现各种不同机器学习方法,Python的scikit-learn库提供了一套更加简洁和易读的语法。而R中caret包的语法有时有点拙劣。尤其,caret包与Tidyverse包兼容得不是很好,输出的结果有时也很难处理。相反,Python的scikit-learn库与Python生态环境整合得很好。
市面上有关机器学习的书籍,其算法实现很多都是用Python写的。
总之,如果你想致力于机器学习,我认为Python会更好。
2.4 想搞深度学习,学Python
深度学习可谓是目前人工智能领域最热门的技术之一,而Python是深度学习使用最热门的语言。
大多数深度学习框架都有Python接口,比如:TensorFlow,Keras,Pytorch,Theano,MXNET等等。
Python与各框架兼容得非常好,拥有大量贡献者、搜索结果、相关书籍和学术文章;Github上的深度学习项目大多数都是用Python写的。如果你是刚入门深度学习的新手,使用Keras是不错的选择。
相比较,R对深度学习框架兼容方面表现不佳。因此如果你想专注深度学习,Python可能更适合。
3. 总结一下:
学R还是Python?主要还是依耐你的背景以及你的目标。
如果你没有任何编程经验,建议你先学R;如果你想学数据可视化,我认为R的ggplot2包是最好的工具;如果你想专门从事数据分析和数据挖掘,R表现更优秀。
如果你想成为机器学习专家,Python的scikit-learn库可以好好研究一下;如果你想开发软件系统,Python更合适。
还有一些其它因素可能影响你的决定,比如:
- 如果你的大多数同事或朋友都在使用某种语言,那么你可以也去学那门语言,因为遇到问题可随时咨询他们。
- 如果你想去的公司都在使用某种语言,你也可以学那门语言,到时候就不需任何相关培训了。
俗话说,技多不压身,你还有第三个选择:R和Python都学。实际上很多顶尖数据科学家这两门语言都会。不过对于新手,一次只学一门。同时学两门会让你很混乱,学习周期会拉长,事倍功半。
最后
作为一个IT的过来人,我自己整理了一些python学习资料,都是别人分享给我的,希望对你们有帮助。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、精品Python学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、Python练习题
检查学习结果。

七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









